js合并同類數組里面的對象
This is Part I of the two-part series dedicated to estimating customer lifetime value. In this post, I will describe how to estimate LTV, on a conceptual level, in order to explain what we’re going to be doing in Part II with the Python code.
這是由兩部分組成的系列的第一部分,該系列專門用于估計客戶生命周期價值。 在本文中,我將在概念上描述如何估計LTV,以解釋我們將在第二部分中使用Python代碼進行的工作。
First of all, why LTV? There are two reasons: creating a benchmark for customer acquisition costs (CAC) and comparing customers, e.g. if we’re targeting those who spend more or less than an average customer.
首先,為什么要使用LTV ? 原因有兩個:建立客戶獲取成本(CAC)基準并比較客戶,例如,如果我們針對的是那些花費高于或少于平均客戶的客戶。
Many sources talking about using churn or retention to estimate customer lifetime value (LTV), and while the core idea remains the same, approaches to its calculation differ dramatically. So, while any analyst will benefit from reading this article, its primary objective is to explain how historical retention data can be used to estimate LTV for customers. We are not going to use statistical techniques to estimate churn and build our predictions. Instead, we will be making use of historical retention, which is an easier place to start with.
許多消息來源都在談論使用流失率或保留率來估計客戶生命周期價值(LTV),盡管核心思想保持不變,但其計算方法卻大不相同。 因此,盡管任何分析師都將從閱讀本文中受益,但其主要目的是解釋如何使用歷史保留數據估算客戶的LTV 。 我們將不會使用統計技術來估計用戶流失并建立我們的預測。 相反,我們將利用歷史保留,這是一個更容易開始的地方。
Why retention? The issue with customer lifetime value is the customer lifetime. If we’re talking subscription-based service, an estimate for customer brought-in value is recurring revenue (RR), or the amount a customer pays for a subscription. If your customer has a possibility to skip a period, however, do not forget to adjust for that (estimate the average % of skips).
為什么保留 ? 客戶生命周期價值的問題是客戶生命周期 。 如果我們在談論基于訂閱的服務,則對客戶帶來的價值的估算是經常性收入(RR),即客戶為訂閱支付的金額。 但是,如果您的客戶有可能跳過某個時間段,請不要忘記對此進行調整(估計跳過的平均百分比)。
What we do not know is how long a new customer will stay within the business, so we are trying to make an educated guess based on earlier acquired customers. It is often suggested that we calculate lifetime as an overall metric for the whole customer base, which gives a confusing average: across customers who could have spent years with the business, at least potentially, and those customers who joined last week or yesterday. At the same time, while older cohorts are good for analysis, we’d like our metrics to be actionable, and hence, to make estimates for younger cohorts. A retention matrix, or a curve, visually represent how many of the acquired customers stayed with the business, continuing to generate revenue. It is based on actual data, so you can start identifying patterns and approximate those for newer customers. So, how?
我們不知道新客戶將在企業中停留多長時間,因此我們正在嘗試根據較早獲得的客戶做出有根據的猜測。 通常建議我們將生命周期作為整個客戶群的總體指標來計算,這會產生令人困惑的平均水平:可能已經花了數年時間(至少可能是花了數年時間)的客戶,以及上周或昨天加入的客戶。 同時,雖然年齡較大的人群很適合進行分析,但我們希望我們的指標可行,因此可以對年齡較小的人群進行估算。 保留矩陣或曲線直觀地表示有多少被收購的客戶留在公司,并繼續產生收入。 它基于實際數據,因此您可以開始識別模式并為新客戶估算模式。 又怎樣?
Cohorts and retention matrixBecause customers join the business at different times, there should be a way to “normalize” their retention. A simple example: 10% of the customers who joined a year ago are still with the business; however, 90% of last month’s customers are still with us. By no means, this implies that customers who joined last month are better (or worse) than the last year’s customers. They simply had less time to show how “sticky” or valuable your business is for them.
?ohorts和保留矩陣因為客戶在不同的時間加盟商,應該有一個方法來“正常化”的保留。 舉一個簡單的例子 :一年前加入的客戶中有10%仍在使用該業務; 但是,上個月90%的客戶仍在我們身邊。 這絕不意味著上個月加入的客戶比去年的客戶更好(或更差)。 他們只是很少的時間來展示您的業務對他們來說有多“粘”或有價值。
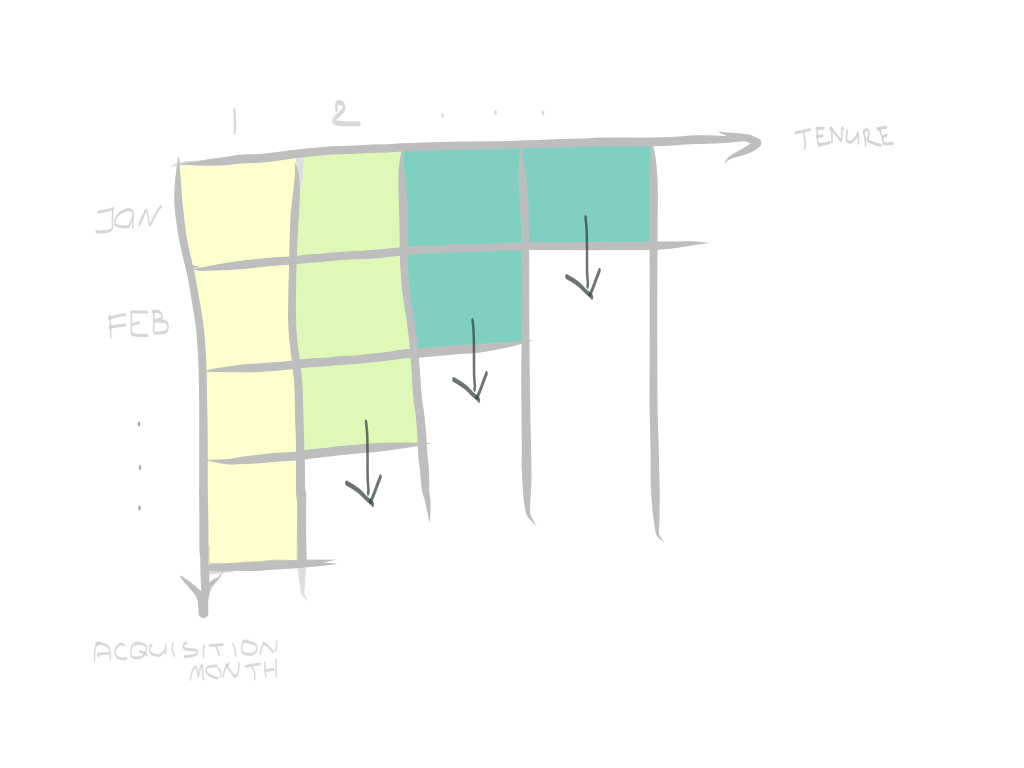
For this reason, we can (and should) split customers into cohorts (groups), based on the time they joined. Normally, cohorts and their retention are analyzed looking on a retention matrix, or similarly, a retention curve. In the matrix below, each square represents the proportion of originally acquired users that moved (re-ordered, re-subscribed) in the next month. For simplicity, I colour-coded them, as also shown below.
因此,我們可以(并且應該)根據客戶加入的時間將其分為多個群組。 通常,在保留矩陣或相似的保留曲線上分析隊列及其保留。 在下面的矩陣中,每個方塊代表下個月移動(重新排序,重新訂閱)的最初獲得用戶的比例。 為簡單起見,我對它們進行了顏色編碼,如下所示。
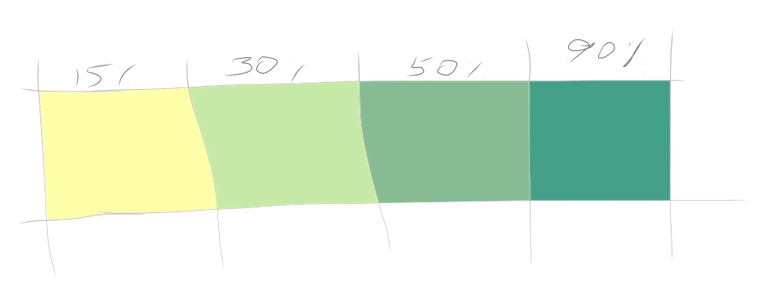
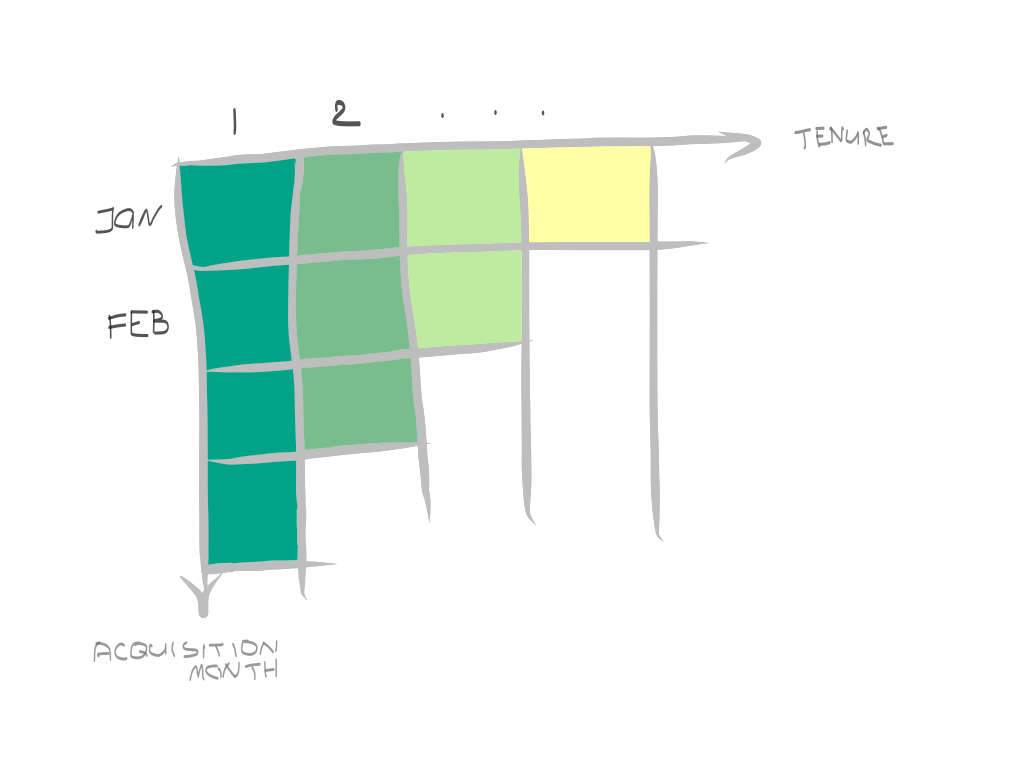
There are 2 axes: time joined, or the acquisition month (y-axis), and subsequent periods, or tenure (x-axis, weeks, months, years, whatever makes sense for the business). The first thing you would notice in most of the retention matrices is that retention tends to fade away as the tenure increases, although the rate might be different. The matrix alone can be used to compute the average actualized lifetime for a cohort, or an average amount of time a customer in a cohort used your product. This calculation simply the sum of retention by row.
有2個軸:加入時間或獲取月份 (y軸)以及后續期間或任期 (x軸,周,月,年,對業務有意義)。 在大多數保留矩陣中,您會注意到的第一件事是,保留期會隨著任期的增加而逐漸消失,盡管比率可能有所不同。 單獨的矩陣可用于計算同類群組的平均實際壽命,或同類群組中的客戶使用您的產品的平均時間。 此計算只是保留的總和。
Another thing that you will quickly notice here is that the matrix will always be half-empty, and our first aim is to figure out the question marks below:
您很快會在這里注意到的另一件事是矩陣將始終為半空,我們的首要目標是找出以下問號:
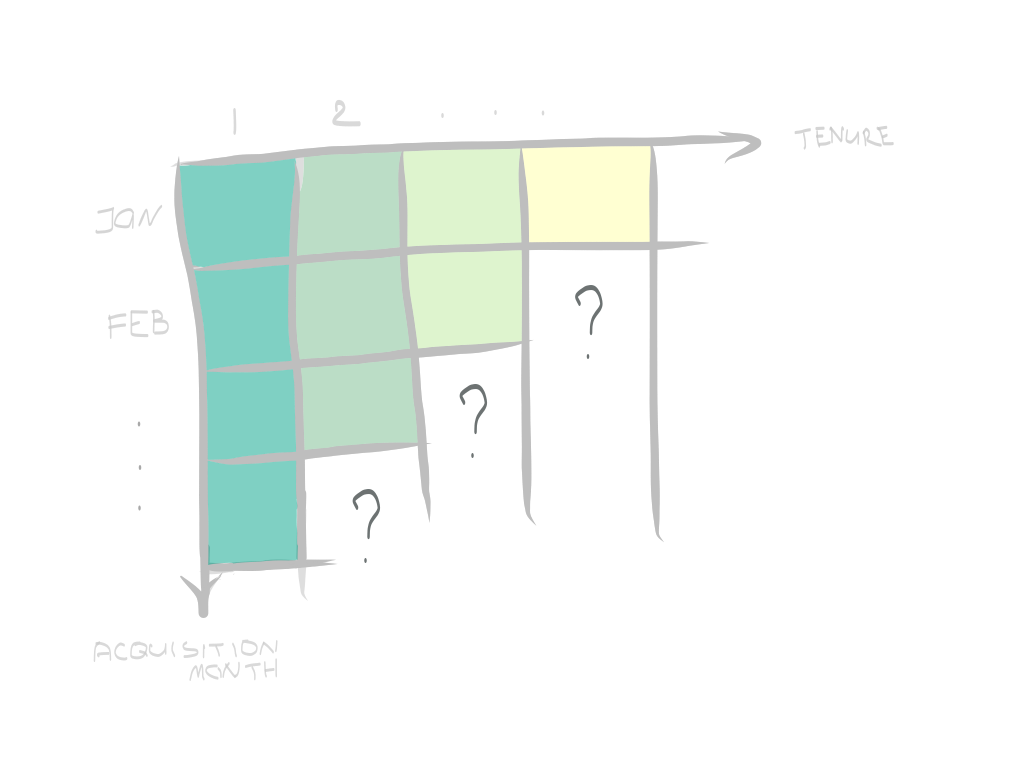
Obviously, that’s because younger cohorts have had a lesser actualized lifetime. Ideally, we’d love to know the lifetime (and value) for them. And still, how?
顯然,這是因為年輕的人群實際壽命較短。 理想情況下,我們很想知道他們的生命(和價值)。 而且,如何?
ExtrapolationOne of the easy approaches would be to fill the values for newer customers based on averaging of previous cohorts’ performance. Because averaging retention directly might be too rough and disconnected from actuals for newer cohorts, we can make use of marginal retention. That’s different from cohort retention as it’s retention period-over-period (e.g., month-over-month or week-over-week). The period will depend on your business cycle.
簡單的方法電子 xtrapolation之一將是填補值基于以前的同伙性能的平均較新的客戶。 因為直接平均保留可能太粗略,并且對于較新的同類而言與實際不符,所以我們可以利用邊際保留。 這與同類群組的保留不同,因為不同時期的保留期不同(例如,逐月或逐周)。 期限取決于您的業務周期。
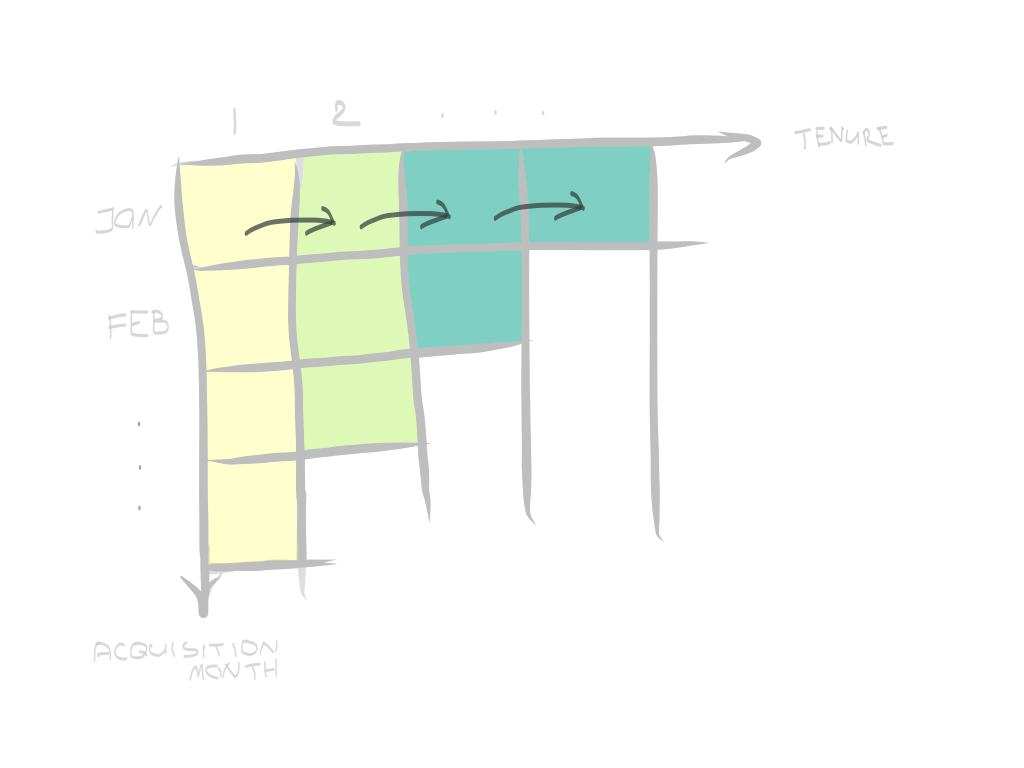
Once we know the marginal retention for cohorts that have their values actualized, we “drag them down” to extrapolate for younger cohorts, element by element. As an option, we can be using a simple average of the last N cohorts, starting from the earliest cohort, or the first rows in the matrix below. This way, you’ll have a moving average of N rows for row numbers N and higher, and an average of all previous values for rows N-1 and lower. You can use it as a blueprint and make it more convoluted, including seasonality aspects, your assumptions about future changes, etc.
一旦我們知道了實現了其價值的同類群體的邊際保留率 ,我們就會“拖拉他們”以逐個元素推斷年輕的同類群體。 作為一種選擇,我們可以使用從最早的隊列或下面矩陣的第一行開始的最后N個隊列的簡單平均值。 這樣,行號為N或更高的行將具有N行的移動平均值,而行號N-1或更低的行將具有所有先前值的平均值。 您可以將其用作藍圖,并使其更加復雜,包括季節性因素,對未來變化的假設等。
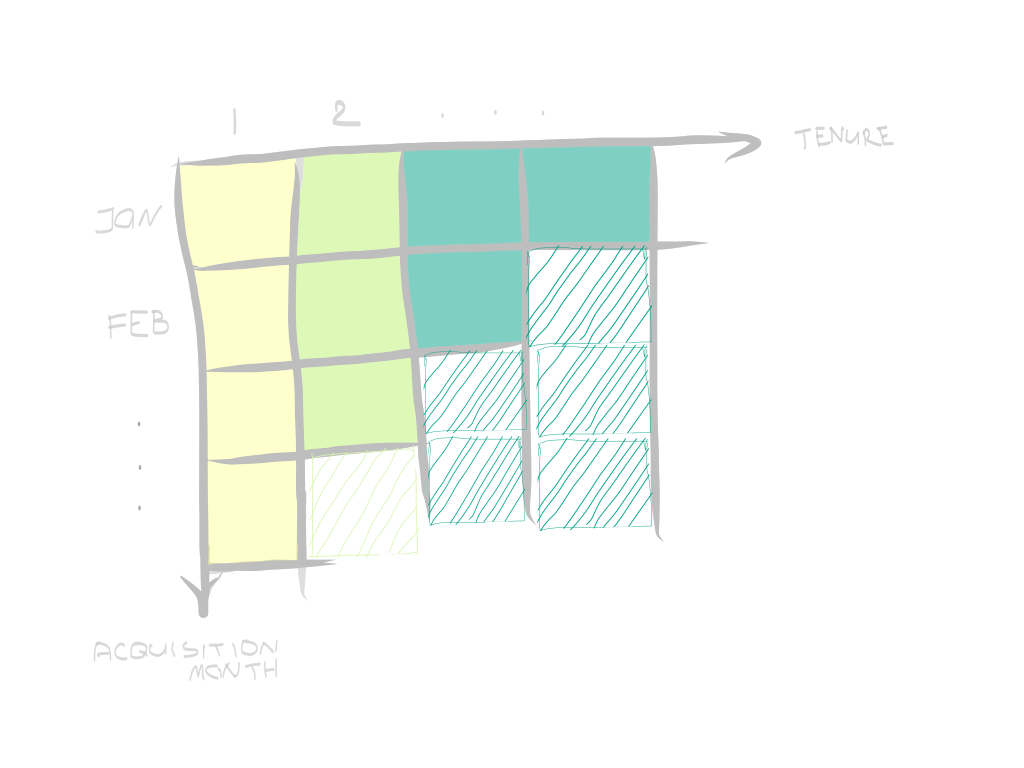
As a result, your matrix will be filled with actual values of marginal retention above the diagonal and estimates below the diagonal. In our case, the latter is moving averages with a window of min 1, max N, depending on a row number.
結果,矩陣將被對角線上方的邊際保留的實際值填充,對角線下方的估算值被填充。 在我們的例子中,后者是窗口最小為1,最大為N的移動平均數,具體取決于行數。
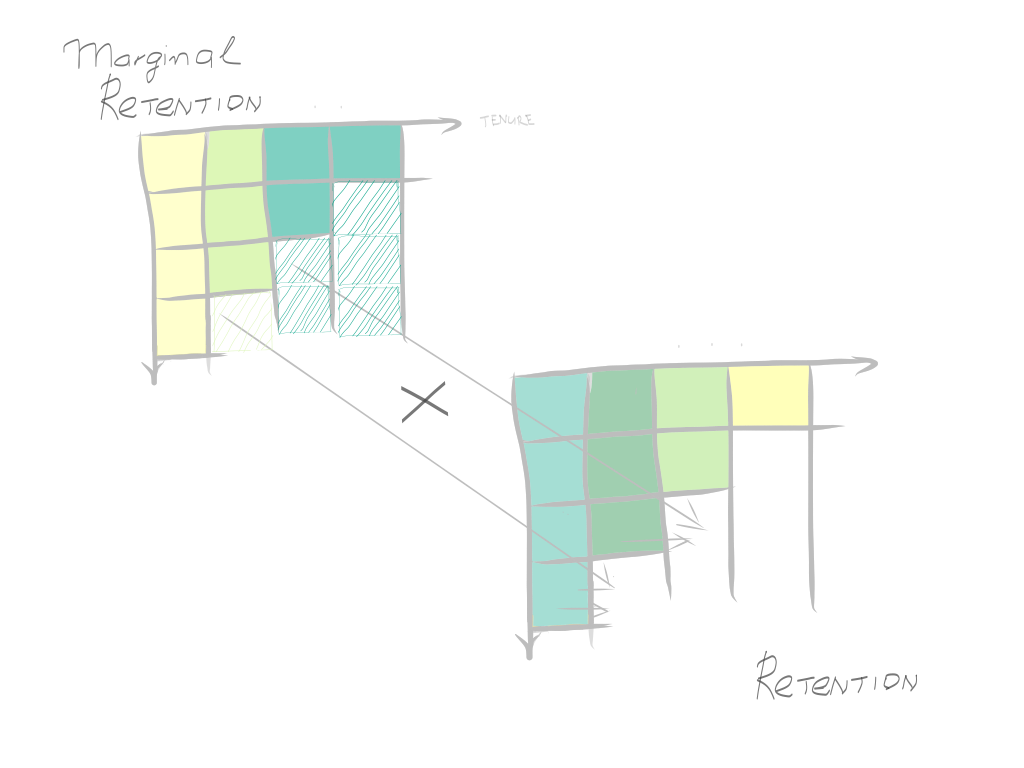
After you’ve got the whole square matrix populated, we can extrapolate retention. It can be done element-wise by “dragging it right”: 1) multiplying the last value in the retention matrix by the next-column value in the marginal retention matrix, which will update the retention estimate in a retention matrix 2) repeating the same procedure for the entire row, taking the last retention estimate in a row and multiplying it by the next value in a marginal retention matrix.
在填充整個方陣后,我們可以推斷保留率。 可以通過“向右拖動”來 逐個元素地完成:1)將保留矩陣中的最后一個值乘以邊際保留矩陣中的下一個列值,這將更新保留矩陣中的保留估計值2)重復執行對整個行執行相同的過程,將一行中的最后一個保留估計值乘以邊際保留矩陣中的下一個值。
This way, we have a fully populated retention matrix with actual values above the diagonal and the estimates below the diagonal. Average lifetime estimate for a cohort is just a sum of retentions for the cohort. (If you want me to describe why it is true, please comment below or highlight and comment, I would like to keep the current post more to the point).
這樣,我們得到了一個完全填充的保留矩陣,其實際值在對角線以上,而估計值在對角線以下。 同類群組的平均壽命估算值只是該同類群組的保留人數之和。 ( 如果您想讓我描述為什么如此,請在下面發表評論或突出顯示并發表評論,我想讓當前的帖子更多地指向重點 )。
ValueThe value we’re talking about should ideally reflect the recurring amount generated by a customer, net of operational costs associated with delivering a service or a product to a customer. For example, if you are in a delivery business, you’d want to exclude delivery costs. If you need to maintain infrastructure for a customer, you’d exclude that. Any discounts that typically apply to a payment, should be considered, so we can arrive at gross margin. Be careful though, if you have first-time customer offers, make sure to not extrapolate those discounts into the future as it will significantly lower your lifetime value.
價值 ,我們正在談論的價值大約應該理想地反映客戶產生的重復量,用網提供服務或產品給客戶相關的運營成本 。 例如,如果您從事送貨業務,則希望排除送貨費用。 如果您需要維護客戶的基礎架構,則可以將其排除在外。 應該考慮通常適用于付款的任何折扣,這樣我們才能得出毛利率。 但是,請務必小心,如果您有首次客戶優惠,請確保不要將這些折扣推算到將來,因為這將大大降低您的終生價值。
If the above seems complicated, consider starting with gross revenue instead of margin and work from there. I see value in starting with a top line and working your way to a gross margin, so further on you can make educated assumptions about revenue dynamics in your business, given its different components. It can also be a good starting point for LTV modelling if you want to assume the impact of your marketing or product improvement efforts.
如果上述情況看起來很復雜,請考慮從總收入而不是利潤開始,然后從那里開始。 我認為從營收開始并不斷提高毛利率是很有價值的,因此,鑒于其組成部分的不同,您可以就業務收入動態做出有根據的假設。 如果您想承擔營銷或產品改進工作的影響,這也可以成為LTV建模的一個很好的起點。
Life Time ValueAfter we’ve nailed the above, lifetime value estimate is just a product of lifetime and value, on a cohort basis. You can take a simple or weighted average to give more weight to newer cohorts or cohorts with more customers.
大號 IFE時間價值后,我們已經釘在上面,終身價值估計只是一個壽命和價值的產品,隊列基礎上。 您可以采用簡單或加權平均值,以將更多權重分配給較新的同類群組或具有更多客戶的同類群組。
And there we have it!
我們終于得到它了!
In essence, we’ve made use of cohort retention and marginal retention to extrapolate the former onto newer cohorts. An interesting fact that is not always apparent is that lifetime will be a sum of retention for a cohort, across the tenure axis.
本質上,我們利用了同類群組保留和邊際保留,將前者外推到較新的同類群組中。 一個有趣的事實(并非總是很明顯)是,終身將是整個研究小組在任期軸上的保留總和。
Sources: there’s a very straightforward and comprehensive explanation of the topic in this blog post
來源:此博客文章對此主題有非常直接而全面的解釋
Thanks for reading this post and getting this far! Hope it was helpful and if you have any comments, please leave them below.
感謝您閱讀這篇文章,并走了很遠! 希望對您有所幫助,如果您有任何意見,請在下面保留。
You can also contact me on LinkedIn: https://www.linkedin.com/in/areusova/ (mention that you’re coming from this Medium post).
您也可以在LinkedIn上與我聯系: https : //www.linkedin.com/in/areusova/ (提及您來自此Medium帖子)。
Or Twitter https://twitter.com/khunreus.
或Twitter https://twitter.com/khunreus 。
翻譯自: https://medium.com/swlh/estimating-customer-lifetime-value-via-cohort-retention-de960e2ee5b1
js合并同類數組里面的對象
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/388172.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/388172.shtml 英文地址,請注明出處:http://en.pswp.cn/news/388172.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章




com編程創建快捷方式中文_如何以編程方式為博客創建wordcloud?

ETL技術入門之ETL初認識
 的內部運行機制分析)
ActiveSupport::Concern 和 gem 'name_of_person'(300?) 的內部運行機制分析

Python 3.8.0a2 發布,面向對象編程語言

基于plotly數據可視化_如何使用Plotly進行數據可視化

關于Oracle實時數據庫的優化思路

【轉】使用 lsof 查找打開的文件


數據科學與大數據是什么意思_什么是數據科學?

C#制作、打包、簽名、發布Activex全過程

用Python創建漂亮的交互式可視化效果

CCF 201809-1 買菜


Hadoop 2.0集群配置詳細教程

php如何減緩gc_管理信息傳播-使用數據科學減緩錯誤信息的傳播
![[UE4]刪除UI:Remove from Parent](http://pic.xiahunao.cn/[UE4]刪除UI:Remove from Parent)
[UE4]刪除UI:Remove from Parent
