php如何減緩gc
With more people now than ever relying on social media to stay updated on current events, there is an ethical responsibility for hosting companies to defend against false information. Disinformation, which is a type of misinformation that is intended to manipulate and mislead, can create unrest and panic. Other types of misinformation such as rumors and hoaxes, if left unchecked, also has the potential to bring mental and physical harm to unwary readers. The key to stopping the spread of misinformation is taking swift action against them since they have the tendency to travel very quickly. In fact, studies show that falsehood spreads exponentially faster than the truth (source). Social media companies have put in place protocols to limit the virality of inaccurate content, but they only take effect once the content has been reviewed by third-party fact-checking partners. Therefore, the focus is on rapid assessment of veracity. We’ve seen remarkable ingenuity from technology companies in this capacity. Namely, the use of Machine Learning algorithms to complement fact-checking programs for identifying inaccurate content. However, this is yet to be a complete solution. In this article, we’ll study the process and explore how it might evolve.
如今,比以往任何時候都更多的人依賴社交媒體來了解最新新聞,因此托管公司有道德責任承擔防范虛假信息的責任。 虛假信息是一種旨在操縱和誤導的虛假信息,會引起騷動和恐慌。 如果不加以制止,其他類型的錯誤信息,例如謠言和惡作劇,也有可能給粗心的讀者帶來精神和身體上的傷害。 阻止錯誤信息傳播的關鍵是對它們采取Swift的行動,因為它們傾向于快速傳播。 實際上,研究表明,虛假的傳播速度比真相的傳播速度快( 來源 )。 社交媒體公司已經制定了協議來限制不準確內容的病毒性,但是只有在第三方事實檢查合作伙伴對內容進行審核后,它們才會生效。 因此,重點是對準確性進行快速評估。 我們已經看到技術公司在此方面具有非凡的創造力。 即,使用機器學習算法來補充事實檢查程序,以識別不正確的內容。 但是,這尚未成為一個完整的解決方案。 在本文中,我們將研究該過程并探討其可能如何發展。
如何識別錯誤信息 (How Misinformation is Identified)
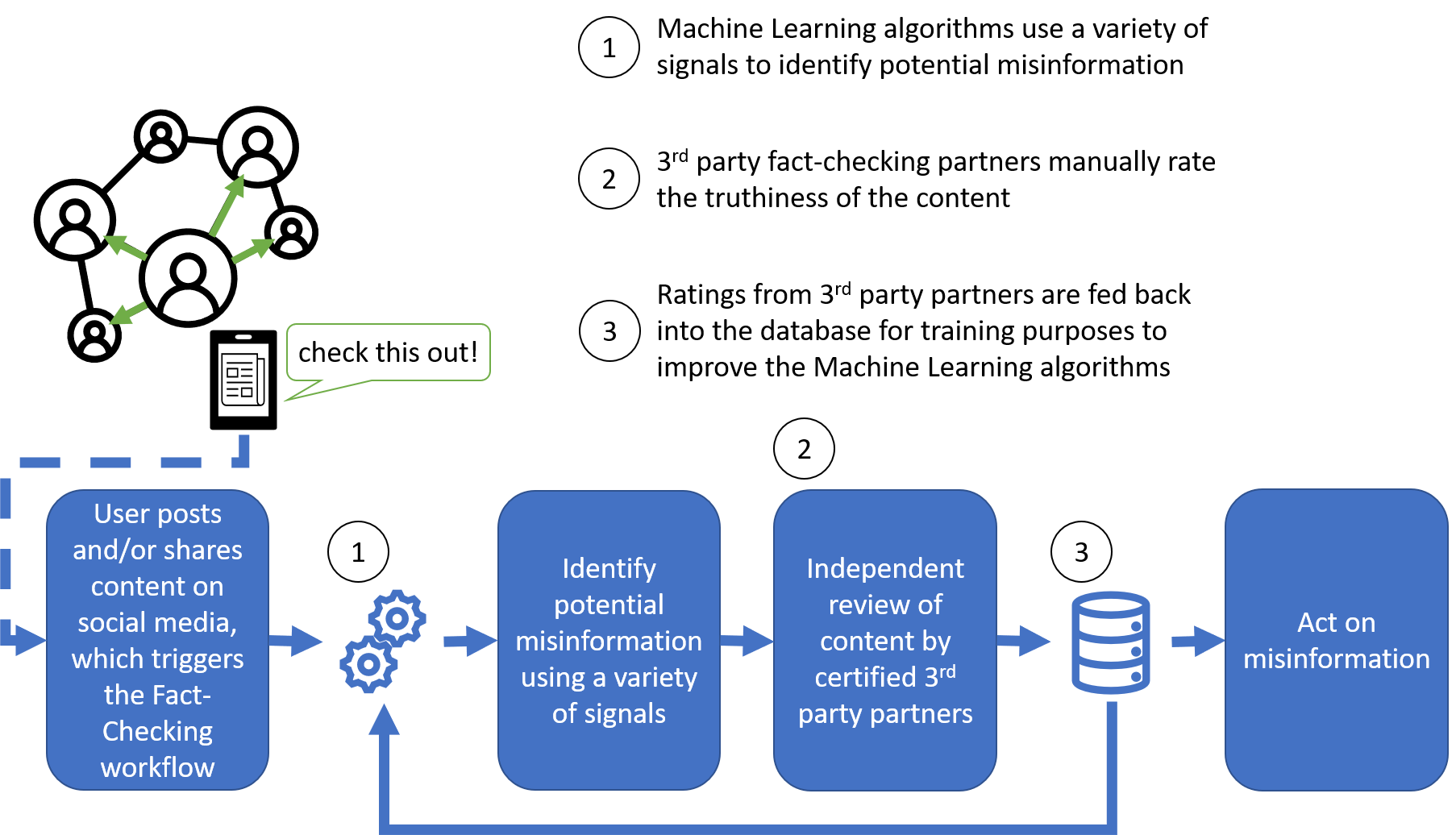
The process of evaluating the content’s accuracy begins with an internal screening of potential falsehood. This involves the utilization of Automation and Machine Learning models to pick up various signals. If the content is determined to potentially be misinformation, it’s routed to fact-checking partners for further review. After manual research and/or consultation with the primary source, a content rating is assigned. The resulting rating notifies the social media company if action needs to be taken. Further, the rating also helps train the Machine Learning models to become better at catching misinformation in the future. Below is how Machine Learning contributes to the process:
評估內容準確性的過程始于對潛在虛假性的內部篩選。 這涉及利用自動化和機器學習模型來拾取各種信號。 如果確定內容可能是錯誤信息,則將其發送給事實檢查合作伙伴以進行進一步檢查。 在對主要來源進行人工研究和/或咨詢后,會分配內容分級。 如果需要采取行動,則由此產生的評級將通知社交媒體公司。 此外,該等級還有助于訓練機器學習模型,使其在將來更好地捕捉錯誤信息。 以下是機器學習對流程的貢獻:
- The prediction models significantly reduce the number of reviews third-party fact-checking partners need to perform 預測模型大大減少了第三方事實檢查合作伙伴需要執行的審閱次數
- Finding duplicate or near-duplicate content frees up capacity for fact-checking partners to review new instances of misinformation 查找重復或幾乎重復的內容可釋放事實檢查合作伙伴查看新的錯誤信息實例的能力
It’s quite a robust process, but not one without challenges. Below are the main challenges for this process:
這是一個強大的過程,但并非沒有挑戰。 以下是此過程的主要挑戰:
- The large and growing number of active users makes the platform a target for coordinated propaganda attacks, bringing urgency and heavy workload for the fact-checking program 大量活躍用戶使該平臺成為協調宣傳攻擊的目標,為事實檢查程序帶來了緊迫性和繁重的工作量
- The scarcity of verified deceptive content to be used as the corpora for predictive classification model training is a roadblock for Machine Learning methods. This is further exacerbated by the desire to have more narrow categories of “truthiness” since they require different treatments, thus diluting the available data 缺乏可用于預測分類模型訓練的經過驗證的欺騙性內容是機器學習方法的障礙。 由于對“真實性”的分類更窄,因此它們的需求進一步加劇,因為它們需要不同的處理方式,從而稀釋了可用數據
- “Bad actors” who hide misleading context behind genuine content are hard to detect. For example, a Meme can use text layered on top of a photo or video to form deceitful content 在真實內容后隱藏誤導性上下文的“壞演員”很難被發現。 例如,一個Meme可以使用在照片或視頻上分層的文字來構成欺騙性內容
- Satirical may be misunderstood by people and are even more difficult for computers 諷刺語可能會被人們誤解,并且對于計算機而言甚至更加困難
仔細檢查篩選過程 (A Closer Look at the Screening Process)
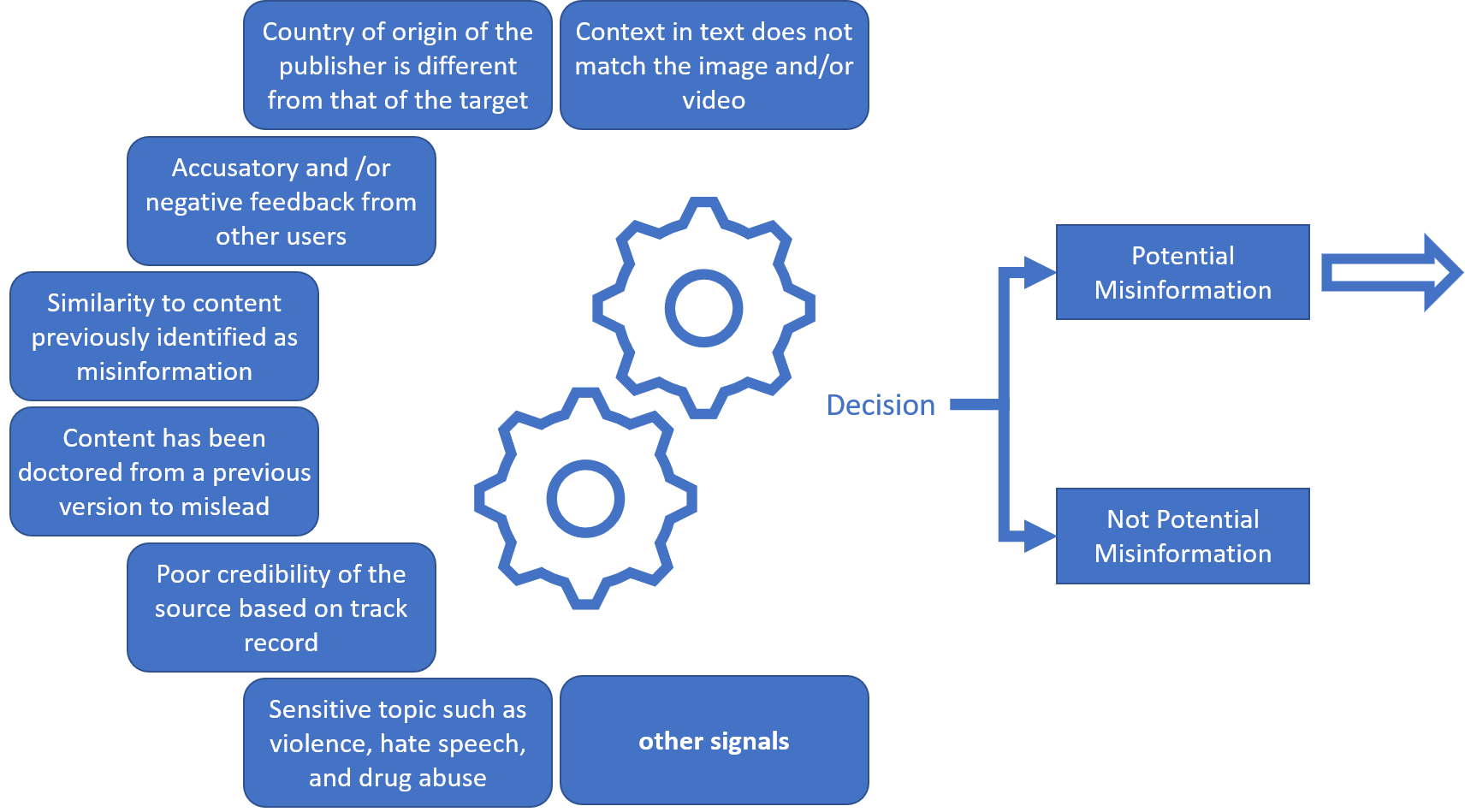
開發中 (In Development)
Technology companies are working to improve this process by significantly expanding their databases that will help them build Artificial Intelligence to combat sophisticated attacks such as “deep fakes” and “weaponized memes”. The effectiveness of the algorithms and models largely depend on the having a diverse data set to train on. Fortunately, with the wide collaboration across the technology community in terms of data sharing, the models are becoming better at understanding content. Nevertheless, this is work in progress.
科技公司正在努力通過顯著擴展其數據庫來改善此過程,這將幫助它們構建人工智能來對抗復雜的攻擊,例如“深造假”和“武器化模因”。 算法和模型的有效性在很大程度上取決于要訓練的多樣化數據集。 幸運的是,隨著整個技術社區在數據共享方面的廣泛合作,這些模型在理解內容方面變得越來越好。 盡管如此,這項工作仍在進行中。
推薦建議 (Recommendations)
There are considerations that should be explored to make immediate improvements. One recommendation that I’m exploring is the prioritization and specialization of contents for third-party fact-checkers. We can perform A/B testing to compare the turn-over and overall virality to measure the impact of these measures.
應該探索一些考慮因素以立即進行改進。 我正在探索的一項建議是對第三方事實檢查者的內容進行優先級劃分和專業化處理。 我們可以進行A / B測試,以比較周轉率和整體病毒性來衡量這些措施的影響。
- Prioritization of dangerous content that have a propensity to spread before they become viral 優先確定容易傳播的易于傳播的危險內容
- Specialization of content directs content to third-party fact-checkers within their area of expertise to cut the amount of time require to review 內容的專業化將內容定向到其專業領域內的第三方事實檢查人員,以減少審核所需的時間
摘要 (Summary)
Infodemic is a disease that has plague us long before the recent health crisis. Without proper management, it can do tremendous harm to our society. Thankfully, there are technological tools to help us mitigate those risks. We reviewed the fact-checking progress and specifically how Machine Learning is being applied in this use case.
信息病是在最近的健康危機之前很久困擾我們的疾病。 如果沒有適當的管理,它將對我們的社會造成巨大傷害。 值得慶幸的是,有技術工具可以幫助我們減輕這些風險。 我們回顧了事實檢查的進展,特別是在此用例中如何應用機器學習。
翻譯自: https://towardsdatascience.com/managing-infodemics-slowing-the-spread-of-misinformation-b8b74e3e2618
php如何減緩gc
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/388154.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/388154.shtml 英文地址,請注明出處:http://en.pswp.cn/news/388154.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章
![[UE4]刪除UI:Remove from Parent](http://pic.xiahunao.cn/[UE4]刪除UI:Remove from Parent)
[UE4]刪除UI:Remove from Parent

MySQL基礎部分總結

BZOJ2503: 相框

泰坦尼克號 數據分析_第1部分:泰坦尼克號-數據分析基礎

Imperva開源域目錄控制器,簡化活動目錄集成
)
2018.10.24 NOIP模擬 小 C 的序列(鏈表+數論)

vba數組dim_NDArray — —一個基于Java的N-Dim數組工具包

Nodejs教程08:同時處理GET/POST請求

關于position的四個標簽

python算法和數據結構_Python中的數據結構和算法

CSS:元素塌陷問題

Celery介紹及常見錯誤

python dash_Dash是Databricks Spark后端的理想基于Python的前端

js里的數據類型轉換

Eclipse 插件開發遇到問題心得總結

/src/applicationContext.xml

在Python中查找子字符串索引的5種方法
![[LeetCode] 3. Longest Substring Without Repeating Characters 題解](http://pic.xiahunao.cn/[LeetCode] 3. Longest Substring Without Repeating Characters 題解)
[LeetCode] 3. Longest Substring Without Repeating Characters 題解

WPF中MVVM模式的 Event 處理
