python算法和數據結構
To
至
Leonardo da Vinci
達芬奇(Leonardo da Vinci)
介紹 (Introduction)
The purpose of this article is to give you a panorama of data structures and algorithms in Python. This topic is very important for a Data Scientist in order to help him or her to design and solve machine learning models in a more effective way.
本文的目的是為您提供Python數據結構和算法的全景圖。 為了幫助數據科學家以更有效的方式設計和求解機器學習模型,該主題對于數據科學家而言非常重要。
We will see together with practical examples the built-in data structures, the user-defined data structures, and last but not least I will introduce you to some algorithms like traversal algorithms, sorting algorithms, and searching algorithms.
我們將與實際示例一起查看內置數據結構,用戶定義的數據結構,最后但并非最不重要的一點是,我將向您介紹一些算法,例如遍歷算法,排序算法和搜索算法。
So, let’s get started!
所以,讓我們開始吧!
第一部分:導入數據結構 (Part I: Bult-in Data Structures)
As the name suggests, data structures allow us to organize, store, and manage data for efficient access and modification.
顧名思義,數據結構使我們能夠組織,存儲和管理數據,以進行有效的訪問和修改。
In this part, we are going to take a look at built-in data structures. There are four types of built-in data structures in Python: list, tuple, set, and dictionary.
在這一部分中,我們將研究內置數據結構。 Python中有四種類型的內置數據結構:列表,元組,集合和字典。
List
清單
A list is defined using square brackets and holds data that is separated by commas. The list is mutable and ordered. It can contain a mix of different data types.
列表使用方括號定義,并包含用逗號分隔的數據。 該列表是可變的和有序的。 它可以包含不同數據類型的混合。
out:
出:
january['january', 'february', 'march', 'april', 'may', 'june', 'july']['birthday', 'february', 'march', 'april', 'may', 'june', 'july', 'august', 'september', 'october', 'november', 'december']Below there are some useful functions for the list.
下面是該列表的一些有用功能。
out:
出:
What
is
your
favourite
painting
?Who-is-your-favourite-artist-?out:
出:
['Chagall', 'Kandinskij', 'Dalí', 'da Vinci', 'Picasso', 'Warhol', 'Basquiat']Tuple
元組
A tuple is another container. It is a data type for immutable ordered sequences of elements. Immutable because you can’t add and remove elements from tuples, or sort them in place.
元組是另一個容器。 它是元素的不可變有序序列的數據類型。 不可變,因為您無法在元組中添加和刪除元素,也無法對其進行排序。
out:
出:
The dimensions are 7 x 3 x 1Set
組
Set is a mutable and unordered collection of unique elements. It can permit us to remove duplicate quickly from a list.
Set是可變且無序的唯一元素集合。 它可以允許我們從列表中快速刪除重復項。
out:
出:
{1, 2, 3, 5, 6}
False
BasquiatDictionary
字典
Dictionary is a mutable and unordered data structure. It permits storing a pair of items (i.e. keys and values).
字典是一種可變且無序的數據結構。 它允許存儲一對項目(即鍵和值)。
As the example below shows, in the dictionary, it is possible to include containers into other containers to create compound data structures.
如下例所示,在字典中,可以將容器包含在其他容器中以創建復合數據結構。
out:
出:
In a Sentimental Mood
Lacrimosa第二部分:用戶定義的數據結構 (Part II: User-Defined Data Structures)
Now I will introduce you three user-defined data structures: ques, stack, and tree. I assume that you have a basic knowledge of classes and functions.
現在,我將向您介紹三種用戶定義的數據結構:ques,stack和tree。 我假設您具有有關類和函數的基本知識。
Stack using arrays
使用數組堆疊
The stack is a linear data structure where elements are arranged sequentially. It follows the mechanism L.I.F.O which means last in first out. So, the last element inserted will be removed as the first. The operations are:
堆棧是線性數據結構,其中元素按順序排列。 它遵循LIFO機制,即先進先出。 因此,插入的最后一個元素將被刪除為第一個元素。 操作是:
- Push → inserting an element into the stack 按下→將元素插入堆棧
- Pop → deleting an element from the stack 彈出→從堆棧中刪除元素
The conditions to check:
檢查條件:
- overflow condition → this condition occurs when we try to put one more element into a stack that is already having maximum elements. 溢出條件→當我們嘗試將一個以上的元素放入已經具有最大元素的堆棧中時,就會發生這種情況。
- underflow condition →this condition occurs when we try to delete an element from an empty stack. 下溢條件→當我們嘗試從空堆棧中刪除元素時,將發生這種情況。
out:
出:
5
True
[10, 23, 25, 27, 11]
overflow
11
27
25
23
10
underflowQueue using arrays
使用數組排隊
The queue is a linear data structure where elements are in a sequential manner. It follows the F.I.F.O mechanism that means first in first out. Think when you go to the cinema with your friends, as you can imagine the first of you that give the ticket is also the first that step out of the line. The mechanism of the queue is the same.
隊列是線性數據結構,其中元素按順序排列。 它遵循先進先出的先進先出機制。 想想當您和朋友一起去電影院時,您可以想象到,第一個出票的人也是第一個跳出界限的人。 隊列的機制是相同的。
Below the aspects that characterize a queue.
在表征隊列的方面之下。
Two ends:
兩端:
- front → points to starting element 前面→指向起始元素
- rear → points to the last element 后→指向最后一個元素
There are two operations:
有兩個操作:
- enqueue → inserting an element into the queue. It will be done at the rear. 入隊→將元素插入隊列。 它將在后部完成。
- dequeue → deleting an element from the queue. It will be done at the front. 出隊→從隊列中刪除元素。 它將在前面完成。
There are two conditions:
有兩個條件:
- overflow → insertion into a queue that is full 溢出→插入已滿的隊列
- underflow → deletion from the empty queue 下溢→從空隊列中刪除
out:
出:
[2, 3, 4, 5]
[3, 4, 5]Tree (general tree)
樹(普通樹)
Trees are used to define hierarchy. It starts with the root node and goes further down, the last nodes are called child nodes.
樹用于定義層次結構。 它從根節點開始,然后向下延伸,最后一個節點稱為子節點。
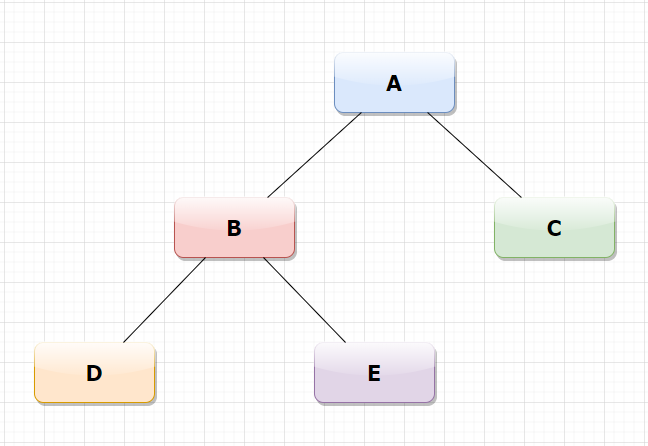
In this article, I focus on the binary tree. The binary tree is a tree data structure in which each node has at most two children, which are referred to as the left child and the right child. Below you can see a representation and an example of the binary tree with python where I constructed a class called Node and the objects that represent the different nodes( A, B, C, D, and E).
在本文中,我重點介紹二叉樹。 二叉樹是一種樹數據結構,其中每個節點最多具有兩個子節點,稱為左子節點和右子節點。 在下面,您可以看到python二進制樹的表示形式和示例,在其中構造了一個名為Node的類,并表示了代表不同節點(A,B,C,D和E)的對象。
Anyway, there are other user-defined data structures like linked lists and graphs.
無論如何,還有其他用戶定義的數據結構,例如鏈表和圖形。
第三部分:算法 (Part III: Algorithms)
The concept of the algorithm has existed since antiquity. In fact, the ancient Egyptians used algorithms to solve their problems. Then they taught this approach to the Greeks.
自上古以來,算法的概念就存在了。 實際上,古埃及人使用算法來解決他們的問題。 然后他們向希臘人教授了這種方法。
The word algorithm derives itself from the 9th-century Persian mathematician Mu?ammad ibn Mūsā al-Khwārizmī, whose name was Latinized as Algorithmi. Al-Khwārizmī was also an astronomer, geographer, and a scholar in the House of Wisdom in Baghdad.
算法一詞源于9世紀的波斯數學家Mu?ammadibnMūsāal-Khwārizmī ,其名稱被拉丁化為Algorithmi。 Al-Khwārizmī還是天文學家,地理學家,也是巴格達智慧之家的學者。
As you already know algorithms are instructions that are formulated in a finite and sequential order to solve problems.
如您所知,算法是按有限順序排列的指令來解決問題。
When we write an algorithm, we have to know what is the exact problem, determine where we need to start and stop and formulate the intermediate steps.
在編寫算法時,我們必須知道確切的問題是什么,確定需要在哪里開始和停止以及制定中間步驟。
There are three main approaches to solve algorithms:
有三種主要的算法求解方法:
- Divide et Impera (also known as divide and conquer) → it divides the problem into sub-parts and solves each one separately Divide et Impera(也稱為“分而治之”)→將問題分為幾個部分,分別解決每個問題
- Dynamic programming → it divides the problem into sub-parts remembers the results of the sub-parts and applies it to similar ones 動態編程→將問題劃分為多個子部分,記住子部分的結果并將其應用于相似的部分
- Greedy algorithms → involve taking the easiest step while solving a problem without worrying about the complexity of the future steps 貪婪算法→包括在解決問題的同時采取最簡單的步驟,而無需擔心未來步驟的復雜性
Tree Traversal Algorithm
樹遍歷算法
Trees in python are non-linear data structures. They are characterized by roots and nodes. I take the class I constructed before for the binary tree.
python中的樹是非線性數據結構。 它們的特征是根和節點。 我采用之前為二叉樹構造的類。
Tree Traversal refers to visiting each node present in the tree exactly once, in order to update or check them.
樹遍歷是指只訪問樹中存在的每個節點一次,以更新或檢查它們。
There are three types of tree traversals:
有三種類型的樹遍歷:
- In-order traversal → refers to visiting the left node, followed by the root and then the right nodes. 有序遍歷→指先訪問左節點,然后依次訪問根節點和右節點。
Here D is the leftmost node where the nearest root is B. The right of root B is E. Now the left sub-tree is completed, so I move towards the root node A and then to node C.
這里D是最左邊的節點,其中最近的根是B。根B的右邊是E。現在左側的子樹已完成,因此我朝根節點A移動,然后向節點C移動。
out:
出:
D
B
E
A
C- Pre-order traversal → refers to visiting the root node followed by the left nodes and then the right nodes. 順序遍歷→是指先訪問根節點,然后再訪問左節點,再訪問右節點。
In this case, I move to the root node A and then to the left child node B and to the sub child node D. After that I can go to the nodes E and then C.
在這種情況下,我先移至根節點A,然后移至左子節點B,再移至子子節點D。之后,我可以先移至節點E,然后移至C。
out:
出:
A
B
D
E
C- Post-order traversal → refers to visiting the left nodes followed by the right nodes and then the root node 后順序遍歷→是指先訪問左側節點,然后再訪問右側節點,然后再訪問根節點
I go to the most left node which is D and then to the right node E. Then, I can go from the left node B to the right node C. Finally, I move towards the root node A.
我先去最左邊的節點D,再去右邊的節點E。然后,我可以從左邊的節點B到右邊的節點C。最后,我向根節點A移動。
out:
出:
D
E
B
C
ASorting Algorithm
排序算法
The sorting algorithm is used to sort data in some given order. It can be classified in Merge Sort and Bubble Sort.
排序算法用于按給定順序對數據進行排序。 可以分為合并排序和氣泡排序。
Merge Sort → it follows the divide et Impera rule. The given list is first divided into smaller lists and compares adjacent lists and then, reorders them in the desired sequence. So, in summary from unordered elements as input, we need to have ordered elements as output. Below, the code with each step described.
合并排序→遵循除法和Impera規則 。 給定的列表首先被分成較小的列表,并比較相鄰列表,然后按所需順序對其進行重新排序。 因此,總之,無序元素作為輸入,我們需要有序元素作為輸出。 下面,用每個步驟描述代碼。
out:
出:
input - unordered elements: 15 1 19 93
output - ordered elements:
[1, 15, 19, 93]- Bubble Sort → it first compares and then sorts adjacent elements if they are not in the specified order. 冒泡排序→如果不按指定順序對相鄰元素進行排序,則首先進行比較,然后對它們進行排序。
out:
出:
[1, 3, 9, 15]- Insertion Sort → it picks one item of a given list at the time and places it at the exact spot where it is to be placed. 插入排序→它會同時選擇給定列表中的一項并將其放置在要放置的確切位置。
out:
出:
[1, 3, 9, 15]There are other Sorting Algorithms like Selection Sort and Shell Sort.
還有其他排序算法,例如選擇排序和外殼排序 。
Searching Algorithms
搜索算法
Searching algorithms are used to seek for some elements present in a given dataset. There are many types of search algorithms such as Linear Search, Binary Search, Exponential Search, Interpolation Search, and so on. In this section, we will see the Linear Search and Binary Search.
搜索算法用于尋找給定數據集中存在的某些元素。 有很多類型的搜索算法,例如線性搜索,二進制搜索,指數搜索,插值搜索等。 在本節中,我們將看到線性搜索和二進制搜索。
- Linear Search → in a single-dimensional array we have to search a particular key element. The input is the group of elements and the key element that we want to find. So, we have to compare the key element with each element of the group. In the following code, I try to seek element 27 in our list. 線性搜索→在一維數組中,我們必須搜索特定的關鍵元素。 輸入是元素組和我們要查找的關鍵元素。 因此,我們必須將關鍵元素與組中的每個元素進行比較。 在下面的代碼中,我嘗試在列表中查找元素27。
out:
出:
'not fund'- Binary Search → in this algorithm, we assume that the list is in ascending order. So, if the value of the search key is less than the element in the middle of the list, we narrow the interval to the lower half. Otherwise, we narrow to the upper half. We continue our check until the value is found or the list is empty. 二進制搜索→在此算法中,我們假定列表按升序排列。 因此,如果搜索關鍵字的值小于列表中間的元素,則將間隔縮小到下半部分。 否則,我們縮小到上半部分。 我們繼續檢查,直到找到該值或列表為空。
out:
出:
False
True結論 (Conclusion)
Now you have an overview of data structures and algorithms. So, you can start going to a deeper understanding of algorithms.
現在,您將概述數據結構和算法。 因此,您可以開始對算法進行更深入的了解。
The beautiful image of the Vitruvian Man I have chosen for this article is not casual. The drawing is based on the correlation of the ideal human body in relation to geometry. In fact, for this representation, Leonardo da Vinci was inspired by Vitruvius who described the man’s body as the ideal body to determine the correct proportion in architecture.
我為本文選擇的維特魯威人的美麗形象并非隨隨便便。 該圖基于理想人體與幾何體的相關性。 實際上,對于這種表示形式,達芬奇(Leonardo da Vinci)的靈感來自維特魯威(Vitruvius) ,他將男人的身體描述為理想的身體,可以確定建筑中正確的比例。
For what concerns algorithms, the Vitruvian Man hides a secret algorithm used by the artists for centuries to certify that their works were inspired by the divine proportion.
關于算法,《維特魯威人》(Vitruvian Man)隱藏了藝術家幾個世紀以來一直在使用的秘密算法,以證明他們的作品是受神圣比例啟發的。
Sometimes I like to think that maybe Leonardo da Vinci, through his wonderful works, wanted to define the most important algorithm which is the algorithm of life.
有時我想認為達芬奇(Leonardo da Vinci)通過他的出色著作想要定義最重要的算法,即生命算法。
Thanks for reading this. There are some other ways you can keep in touch with me and follow my work:
感謝您閱讀本文。 您可以通過其他方法與我保持聯系并關注我的工作:
Subscribe to my newsletter.
訂閱我的時事通訊。
You can also get in touch via my Telegram group, Data Science for Beginners.
您也可以通過我的電報小組“ 面向初學者的數據科學”進行聯系 。
翻譯自: https://towardsdatascience.com/data-structures-algorithms-in-python-68c8dbb19c90
python算法和數據結構
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/388144.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/388144.shtml 英文地址,請注明出處:http://en.pswp.cn/news/388144.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

CSS:元素塌陷問題

Celery介紹及常見錯誤

python dash_Dash是Databricks Spark后端的理想基于Python的前端

js里的數據類型轉換

Eclipse 插件開發遇到問題心得總結

/src/applicationContext.xml

在Python中查找子字符串索引的5種方法
![[LeetCode] 3. Longest Substring Without Repeating Characters 題解](http://pic.xiahunao.cn/[LeetCode] 3. Longest Substring Without Repeating Characters 題解)
[LeetCode] 3. Longest Substring Without Repeating Characters 題解

WPF中MVVM模式的 Event 處理

Eclipse 插件開發 向導

線性回歸 假設_線性回歸的假設

ES6模塊與commonJS模塊的差異


Eclipse 簡介和插件開發天氣預報

趣味數據故事_壞數據的好故事

Linux 4.1內核熱補丁成功實踐

python分句_Python循環中的分句,繼續和其他子句

eclipse plugin 菜單
![[翻譯 EF Core in Action 2.0] 查詢數據庫](http://pic.xiahunao.cn/[翻譯 EF Core in Action 2.0] 查詢數據庫)
[翻譯 EF Core in Action 2.0] 查詢數據庫
