python數據建模數據集
There are useful Python packages that allow loading publicly available datasets with just a few lines of code. In this post, we will look at 5 packages that give instant access to a range of datasets. For each package, we will look at how to check out its list of available datasets and how to load an example dataset to a pandas dataframe.
有一些有用的Python程序包,僅需幾行代碼即可加載公共可用的數據集。 在本文中,我們將介紹5個可立即訪問一系列數據集的軟件包。 對于每個包,我們將研究如何檢查其可用數據集列表以及如何將示例數據集加載到pandas數據框 。
0. Python設置🔧 (0. Python setup 🔧)
I assume the reader (👀 yes, you!) has access to and is familiar with Python including installing packages, defining functions and other basic tasks. If you are new to Python, this is a good place to get started.
我假設讀者(👀,是的,您!)可以訪問并熟悉Python,包括安裝軟件包,定義函數和其他基本任務。 如果您不熟悉Python,那么這是一個入門的好地方。
I have used and tested the scripts in Python 3.7.1 in Jupyter Notebook. Let’s make sure you have the relevant packages installed before we dive in:
我在Jupyter Notebook中使用并測試了Python 3.7.1中的腳本。 在我們深入研究之前,請確保您已安裝相關的軟件包:
?? ?pydataset: Dataset package,?? ?seaborn: Data Visualisation package,?? ?sklearn: Machine Learning package,?? ?statsmodel: Statistical Model package and?? ?nltk: Natural Language Tool Kit package
???pydataset:數據集包,???seaborn:數據可視化包裝,???sklearn:機器學習包,???statsmodel:統計模型包and???NLTK:自然語言工具套件包
For each package, we will inspect the shape, head and tail of an example dataset. To avoid repeating ourselves, let’s quickly make a function:
對于每個包裝,我們將檢查示例數據集的shape , head和tail 。 為了避免重復自己,讓我們快速創建一個函數:
# Create a function to glimpse the data
def glimpse(df):
print(f"{df.shape[0]} rows and {df.shape[1]} columns")
display(df.head())
display(df.tail())Alright, we are ready to dive in! 🐳
好了,我們準備潛水了! 🐳
1. PyDataset📚 (1. PyDataset 📚)
The first package we are going look at is PyDataset. It’s easy to use and gives access to over 700 datasets. The package was inspired by ease of accessing datasets in R and aimed to bring that ease in Python. Let’s check out the list of datasets:
我們要看的第一個包是PyDataset 。 它易于使用,可訪問700多個數據集。 該軟件包的靈感來自于輕松訪問R中的數據集,并旨在將這種便利引入Python。 讓我們查看數據集列表:
# Import package
from pydataset import data# Check out datasets
data()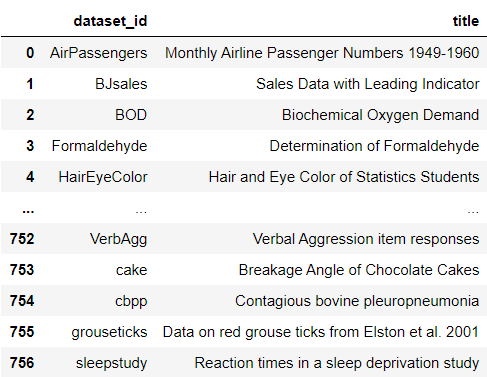
This returns a dataframe containing dataset_id and title for all datasets which you can browse through. Currently, there are 757 datasets. Now, let’s load the famous iris dataset as an example:
這將返回一個數據集,其中包含可瀏覽的所有數據集的dataset_id和標題 。 當前,有757個數據集。 現在,讓我們以著名的虹膜數據集為例:
# Load as a dataframe
df = data('iris')
glimpse(df)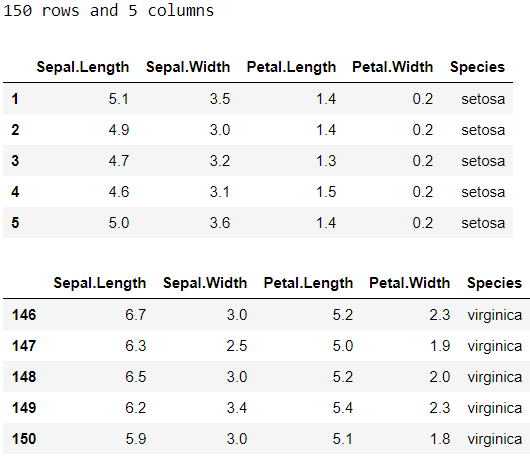
Loading a dataset to a dataframe takes only one line once we import the package. So simple, right? Something to note is that row index starts from 1 as opposed to 0 in this dataset.
導入包后,將數據集加載到數據框僅需一行。 很簡單,對吧? 需要注意的是,該數據集中的行索引從1開始,而不是0。
🔗 To learn more, check out PyDataset’s GitHub repository.
learn要了解更多信息,請查看PyDataset的GitHub存儲庫 。
2. Seaborn🌊 (2. Seaborn 🌊)
Seaborn is another package that provides easy access to example datasets. To find the full list of datasets, you can browse the GitHub repository or you can check it in Python like this:
Seaborn是另一個可以輕松訪問示例數據集的軟件包。 要查找數據集的完整列表,可以瀏覽GitHub存儲庫 ,也可以像這樣在Python中進行檢查:
# Import seaborn
import seaborn as sns# Check out available datasets
print(sns.get_dataset_names())
Currently, there are 17 datasets available. Let’s load iris dataset as an example:
當前,有17個數據集可用。 讓我們以加載虹膜數據集為例:
# Load as a dataframe
df = sns.load_dataset('iris')
glimpse(df)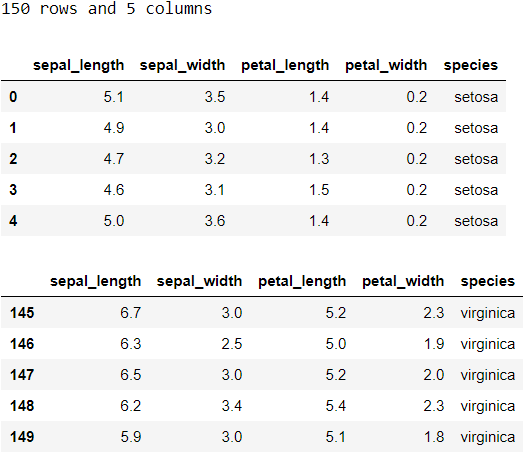
It also takes only one line to load a dataset as a dataframe after importing the package.
導入數據包后,只需一行即可將數據集作為數據框加載。
🔗 To learn more, check out documentation page for load_dataset.
learn要了解更多信息,請查看文檔頁面以獲取load_dataset 。
3. Scikit學習arn (3. Scikit-learn 📓)
Not only is scikit-learn awesome for feature engineering and building models, it also comes with toy datasets and provides easy access to download and load real world datasets. The list of toy and real datasets as well as other details are available here. You can find out more details about a dataset by scrolling through the link or referring to the individual documentation for functions. It’s worth mentioning that among the datasets, there are some toy and real image datasets such as digits dataset and Olivetti faces dataset.
s cikit學習不僅對于功能工程和構建模型非常棒,而且還包含玩具數據集,并提供了輕松訪問下載和加載現實世界數據集的便利。 玩具和真實數據集的列表以及其他詳細信息可在此處獲得 。 您可以通過滾動鏈接或參考各個函數的文檔來查找有關數據集的更多詳細信息。 值得一提的是,在這些數據集中,有一些玩具和真實圖像數據集 例如數字數據集和Olivetti人臉數據集 。
Now, let’s look at how to load real dataset with an example:
現在,讓我們來看一個示例如何加載真實數據集:
# Import package
from sklearn.datasets import fetch_california_housing# Load data (will download the data if it's the first time loading)
housing = fetch_california_housing(as_frame=True)# Create a dataframe
df = housing['data'].join(housing['target'])
glimpse(df)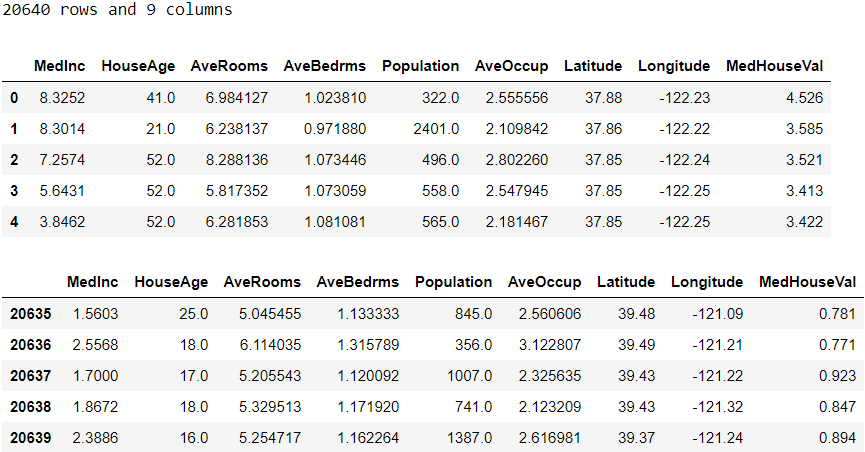
Here’s how to load an example toy dataset, iris:
這是如何加載示例玩具數據集iris的方法 :
# Import package
from sklearn.datasets import load_iris# Load data
iris = load_iris(as_frame=True)# Create a dataframe
df = iris['data'].join(iris['target'])# Map target names (only for categorical target)
df['target'].replace(dict(zip(range(len(iris['target_names'])), iris['target_names'])), inplace=True)
glimpse(df)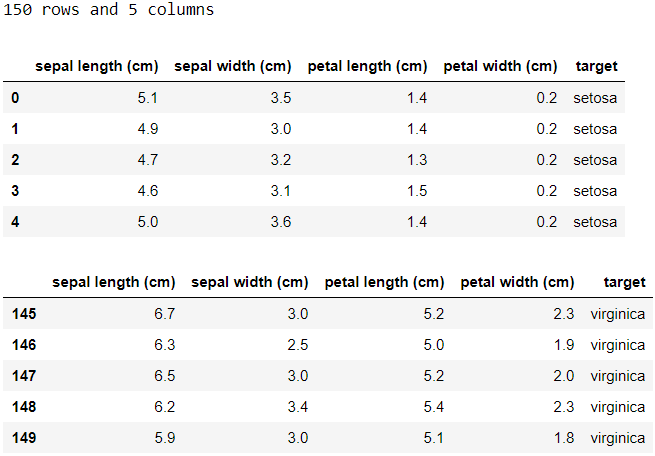
💡 If you get an error regarding the as_frame argument, either update your sklearn version to 0.23 or higher or use the script below:
💡如果在as_frame參數方面遇到錯誤,請將sklearn版本更新為0.23或更高版本,或使用以下腳本:
# Import packages
import pandas as pd
from sklearn.datasets import load_iris# Load data
iris = load_iris()# Create a dataframe
X = pd.DataFrame(iris['data'], columns=iris['feature_names'])
y = pd.DataFrame(iris['target'], columns=['target'])
df = X.join(y)# Map target names (only for categorical target)
df['target'].replace(dict(zip(range(len(iris['target_names'])), iris['target_names'])), inplace=True)
glimpse(df)🔗 For more information, check out scikit-learn’s documentation page.
🔗有關更多信息,請查看scikit-learn的文檔頁面 。
4.統計模型📔 (4. Statsmodels 📔)
Another package through which we can access data is statsmodels. Available built-in datasets are listed here on their website. Let’s pick ‘United States Macroeconomic data’ as an example and load it:
statsmodels是我們可以通過其訪問數據的另一個包。 可用內置的數據集列在這里他們的網站上。 讓我們以“美國宏觀經濟數據 ”為例并加載它:
# Import package
import statsmodels.api as sm# Load data as a dataframe
df = sm.datasets.macrodata.load_pandas()['data']
glimpse(df)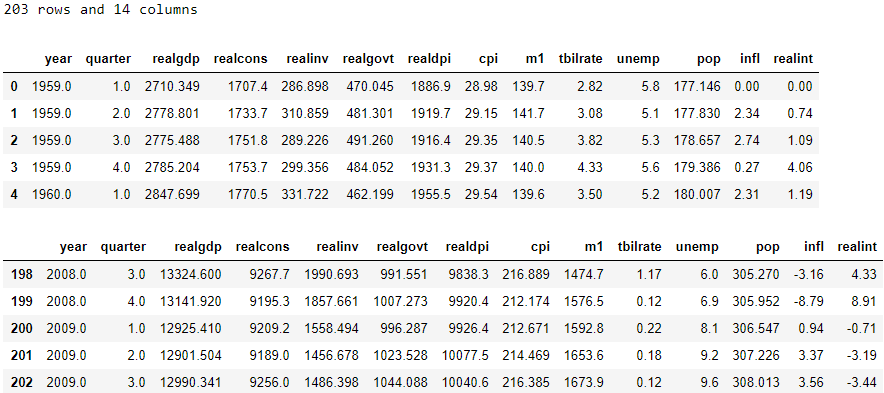
As you may have noticed, the name we used to access ‘United States Macroeconomic data’ is macrodata. To find the equivalent name for other datasets, have a look at the end of the URL for that dataset documentation. For instance, if you click on ‘United States Macroeconomic data’ in Available Dataset section and look at the address bar in your browser, you will see ‘macrodata.html’ at the end of URL.
您可能已經注意到,我們用來訪問“美國宏觀經濟數據 ”的名稱是macrodata 。 要查找其他數據集的等效名稱,請查看該數據集文檔的URL末尾。 例如,如果單擊“ 可用數據集”部分中的“美國宏觀經濟數據”,然后在瀏覽器中查看地址欄,則URL末尾將顯示“ macrodata.html” 。
Statsmodels also allows loading datasets from R with the get_rdataset function. The list of available datasets are here. Using iris dataset as an example, here is how we can load the data:
Statsmodels還允許使用get_rdataset函數從R加載數據集。 可用數據集列表在此處 。 以鳶尾花數據集為例,以下是我們如何加載數據的方法:
# Load data as a dataframe
df = sm.datasets.get_rdataset(dataname='iris', package='datasets')['data']
glimpse(df)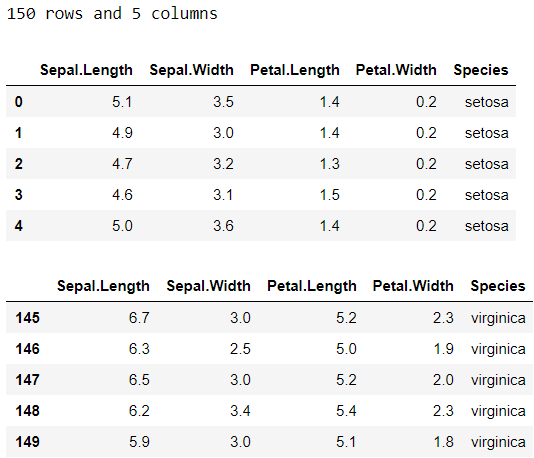
🔗 For more information, check out documentation page for datasets.
🔗有關更多信息,請查看文檔頁面以獲取數據集。
5.自然語言工具包| NLTK📜 (5. Natural Language Toolkit | NLTK 📜)
This package is slightly different from the rest because it provides access only to text datasets. Here’s the list of text datasets available (Psst, please note some items in that list are models). Using the id, we can access the relevant text dataset from NLTK. Let’s take Sentiment Polarity Dataset as an example. Its id is movie_reviews. Let’s first download it with the following script:
該軟件包與其他軟件包略有不同,因為它僅提供對文本數據集的訪問。 這是可用的文本數據集的列表(Psst,請注意該列表中的某些項目是模型)。 使用id ,我們可以從NLTK訪問相關的文本數據集。 讓我們以“ 情感極性數據集 ”為例。 它的id是movie_reviews 。 首先使用以下腳本下載它:
# Import package
import nltk# Download the corpus (only need to do once)
nltk.download('movie_reviews')If it is already downloaded, running this will notify that you have done so. Once downloaded, we can load the data to a dataframe like this:
如果已經下載,運行此命令將通知您已完成下載。 下載后,我們可以將數據加載到這樣的數據框中:
# Import packages
import pandas as pd
from nltk.corpus import movie_reviews# Convert to dataframe
documents = []
for fileid in movie_reviews.fileids():
tag, filename = fileid.split('/')
documents.append((tag, movie_reviews.raw(fileid)))
df = pd.DataFrame(documents, columns=['target', 'document'])
glimpse(df)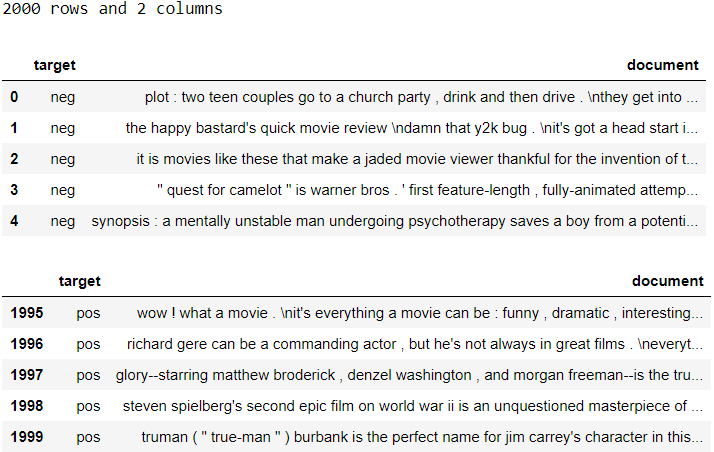
There is no one size fits all approach when converting text data from NLTK to a dataframe. This means you will need to look up the appropriate way to convert to a dataframe on a case-by-case basis.
將文本數據從NLTK轉換為數據框時,沒有一種適合所有情況的方法。 這意味著您將需要根據具體情況查找適當的方法以轉換為數據框。
🔗 For more information, check out this resource on accessing text corpora and lexical resources.
🔗欲了解更多信息,請查看該資源的訪問語料庫和詞匯資源。
There you have it, 5 packages that allow easy access to datasets. Now you know how to load datasets from any of these packages. It’s possible that datasets available in these packages could change in future but you know how to find all the available datasets, anyway! 🙆
那里有5個軟件包,可輕松訪問數據集。 現在您知道了如何從任何一個軟件包中加載數據集。 這些軟件包中可用的數據集將來可能會更改,但是您仍然知道如何查找所有可用的數據集! 🙆
Thank you for reading my post. Hope you found something useful ??. If you are interested, here are the links to some of my other posts:??? 5 tips for pandas users????? How to transform variables in a pandas DataFrame?? TF-IDF explained?? Supervised text classification model in Python
感謝您閱讀我的帖子。 希望你找到了有用的??。 如果您有興趣,這里是指向我其他一些文章的鏈接:??? 給熊貓用戶的5條提示 ????? 如何在熊貓DataFrame中轉換變量 ??TF -IDF解釋了 ??Python中的監督文本分類模型
Bye for now 🏃💨
再見for
翻譯自: https://towardsdatascience.com/datasets-in-python-425475a20eb1
python數據建模數據集
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/388123.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/388123.shtml 英文地址,請注明出處:http://en.pswp.cn/news/388123.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

打開editor的接口討論

【三角函數】已知直角三角形的斜邊長度和一個銳角角度,求另外兩條直角邊的長度...


usgs地震記錄如何下載_用大葉草繪制USGS地震數據

Springboot 項目中 xml文件讀取yml 配置文件

eclipse 插件打包發布

無法獲取 vmci 驅動程序版本: 句柄無效

數據可視化 信息可視化_更好的數據可視化的8個技巧

分布式定時任務框架Elastic-Job的使用

Memcached和Redis

第4章 springboot熱部署 4-1 SpringBoot 使用devtools進行熱部署

border-radius 漲知識的寫法

ibm python db_使用IBM HR Analytics數據集中的示例的Python獨立性卡方檢驗

Oracle優化檢查表
)
spring分布式事務學習筆記(2)

sql 左聯接 全聯接_通過了解自我聯接將您SQL技能提升到一個新的水平

如何查看linux中文件打開情況

hadoop windows

Ocelot中文文檔入門
