Memcached和Redis作為兩種Inmemory的key-value數據庫,在設計和思想方面有著很多共通的地方,功能和應用方面在很多場合下(作為分布式緩存服務器使用等)?也很相似,在這里把兩者放在一起做一下對比的介紹
??
基本架構和思想
?
首先簡單介紹一下兩者的架構和設計思路
?
Memcached
?
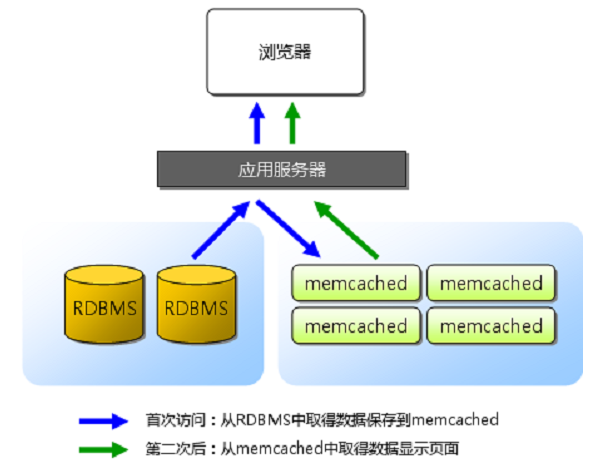
Memcached采用客戶端-服務器的架構,客戶端和服務器端的通訊使用自定義的協議標準,只要滿足協議格式要求,客戶端Library可以用任何語言實現。
?
從用戶的角度來說,服務器維護了一個鍵-值關系的數據表,服務器之間相互獨立,互相之間不共享數據也不做任何通訊操作。客戶端需要知道所有的服務器,并自行負責管理數據在各個服務器間的分配。
?
在服務器端,內部的數據存儲,使用基于Slab的內存管理方式,有利于減少內存碎片和頻繁分配銷毀內存所帶來的開銷。各個Slab按需動態分配一個page的內存(和4Kpage的概念不同,這里默認page為1M),page內部按照不同slab class的尺寸再劃分為內存chunk供服務器存儲KV鍵值對使用

?
Memcached的基本應用模型如下圖所示
?
?
?
?
Redis
?
Redis的基本應用模式和上圖memcached的基本相似,不難發現網上到處都是關于redis是否可以完全替代memcached使用的問題
?
Redis內部的數據結構最終也會落實到key-Value對應的形式,不過從暴露給用戶的數據結構來看,要比memcached豐富,除了標準的通常意義的鍵值對,Redis還支持List,Set,?Hashes,Sorted Set等數據結構
?
基本命令
?
Memcached的命令或者說通訊協議非常簡單,Server所支持的命令基本就是對特定key的添加,刪除,替換,原子更新,讀取等,具體包括?Set, Get, Add, Replace, Append, Inc/Dec?等等
?
Memcached的通訊協議包括文本格式和二進制格式,用于滿足簡單網絡客戶端工具(如telnet)和對性能要求更高的客戶端的不同需求
?
Redis的命令在KV(String類型)上提供與Memcached類似的基本操作,在其它數據結構上也支持基本類似的操作(當然還有這些數據結構所特有的操作,如Set的union,List的pop等)而支持更多的數據結構,在一定程度上也就意味著更加廣泛的應用場合
?
除了多種數據結構的支持,Redis相比Memcached還提供了許多額外的特性,比如Subscribe/publish命令,以支持發布/訂閱模式這樣的通知機制等等,這些額外的特性同樣有助于拓展它的應用場景
?
Redis的客戶端-服務器通訊協議完全采用文本格式(在將來可能的服務器間通訊會采用二進制格式)
?
?
事務
?
redis通過Multi / Watch /Exec等命令可以支持事務的概念,原子性的執行一批命令。在2.6以后的版本中由于添加了對Script腳本的支持,而腳本固有的是以transaction事務的方式執行的,并且更加易于使用,所以不排除將來取消Multi等命令接口的可能性
?
Memcached的應用模式中,除了increment/decrement這樣的原子操作命令,不存在對事務的支持
?
數據備份,有效性,持久化等
?
memcached不保證存儲的數據的有效性,Slab內部基于LRU也會自動淘汰舊數據,客戶端不能假設數據在服務器端的當前狀態,這應該說是Memcached的Feature設定,用戶不必太多關心或者自己管理數據的淘汰更新工作,當然是否適合你的應用,取決于具體的需求,它也可能成為你需要精確自行控制Cache生命周期的一個障礙
?
Memcached也不做數據的持久化工作,但是有許多基于memcached協議的項目實現了數據的持久化,例如memcacheDB使用BerkeleyDB進行數據存儲,但本質上它已經不是一個Cache Server,而只是一個兼容Memcached的協議key-valueData Store了
?
Redis可以以master-slave的方式配置服務器,Slave節點對數據進行replica備份,Slave節點也可以充當Read only的節點分擔數據讀取的工作
?
Redis內建支持兩種持久化方案,snapshot快照和AOF?增量Log方式。快照顧名思義就是隔一段時間將完整的數據Dump下來存儲在文件中。AOF增量Log則是記錄對數據的修改操作(實際上記錄的就是每個對數據產生修改的命令本身),兩種方案可以并存,也各有優缺點,具體參見http://redis.io/topics/persistence
?
以上Redis的數據備份持久化方案等,如果不需要,為了提高性能,也完全可以Disable
?
?
性能
?
性能方面,兩者都有一些自己考慮和實現
?
Memcached
?
memcached自身并不主動定期檢查和標記哪些數據需要被淘汰,只有當再次讀取相關數據時才檢查時間戳,或者當內存不夠使用需要主動淘汰數據時進一步檢查LRU數據
?
?
Redis
?
Redis為了減少大量小數據CMD操作的網絡通訊時間開銷 RTT (Round Trip Time),支持pipeline和script技術
?
- 所謂的pipeline就是支持在一次通訊中,發送多個命令給服務器批量執行,帶來的代價是服務器端需要更多的內存來緩存查詢結果。
- Redis內嵌了LUA解析器,可以執行lua?腳本,腳本可以通過eval等命令直接執行,也可以使用script load等方式上傳到服務器端的script cache中重復使用
?
這兩種方式都可以有效地減少網絡通訊開銷,增加數據吞吐率
?
對于KV的操作,Memcached和Redis都支持Multiple的Get和Set命令(Memcached的Multiple Set命令貌似只在二進制的協議中支持),這同樣有利于性能的提升
?
實際性能方面,網上有很多測試比較,給出的結果各不相同,這無疑和各種測試的測試用例,測試環境,和測試時具體使用的客戶端Library實現有關。但是總體看下來,比較靠譜的結論是在kv類操作上,兩者的性能接近,Memcached的結構更加簡單,理論上應該會略微快一些。
?
?
集群
?
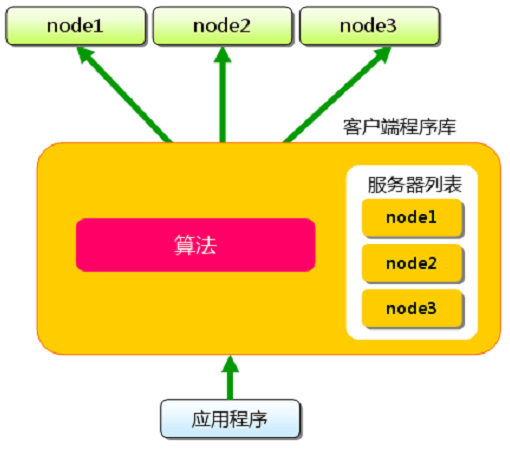
memcached的服務器端互相完全獨立,客戶端通常通過對鍵值應用Hash算法決定數據的分區,為了減少服務器的增減對Hash結果的影響,導致大面積的緩存失效,多數客戶端實現了一致性hash算法
?
Redis計劃在服務器端內建對集群的支持,但是目前代碼還處于alpha階段(貌似已經Design了兩三年了?)在此之前,同樣可以認為每個Redis服務器實例相互之間是完全獨立的,需要依靠客戶端處理分區算法和可用服務器列表管理的工作。
?
?
Redis官方推薦的用于Sharding的客戶端程序庫是Twitter的開源項目?Twemproxy,?Twemproxy同時支持Memcached和Redis的文本通訊協議。
?
需要注意的是,Redis的許多命令在集群環境下是不能正確運行的,例如set的交集,以及跨節點的事務操作等等,因為目前的Redis集群設計,根本目標也就是服務器之間互相匯報一下存活狀態,以及對數據做榮譽備份平衡負載等而已,本質上對數據的跨節點操作并不提供任何額外支持,所以在數據服務的層面上來說,各個服務器依舊是完全獨立的。
?
這些操作如果一定要實現,當然可以通過客戶端代碼來實現(效率有多高且不說),類似的問題memcached集群當然也會遇上,但是原本memcached就不支持復雜的操作和數據類型,許多運算邏輯原本就是由客戶端代碼或應用程序自己處理的。
?
?
MR類批處理應用
?
提供指定范圍的遍歷操作,是支持類似MapReduce這樣的批處理應用邏輯的關鍵之一,但是要在基于hash方式存儲的數據結構的基礎上提供這樣的支持并不容易(或者說要實現高效的范圍或遍歷操作并不容易)
?
Redis支持Scan操作用于遍歷數據集,這一操作基于其內部數據結構及實現的限制,可以保證在Scan開始時的所有數據都能被獲取到,但是不能保證不返回重復的數據,這需要由客戶端來檢查,或者客戶端對此無所謂。Scan操作還支持Match條件用來過濾鍵值,雖然存在一定的局限性,例如match條件的比較是在獲取數據之后再執行的,效率是一個問題,更明顯的問題是不能保證每次scan的iterate過程都能返回同樣數量的有效數據。
?
對于范圍操作,Redis的Ordered Set支持在插入時指定數據的分數(Score)用于排序,而后支持在指定Score范圍內的各種操作,雖然由于不支持基于字符串的或自定義的基準的Range操作,這樣的范圍操作應用起來有很大的局限性(或者說需要滿足特定的應用模式),但是還是比沒有好了
?
Memcached核心協議本身不支持任何范圍類的操作,也沒有對遍歷操作的支持,甚至不存在官方合法的列舉所有Key的操作,這當然很大程度上源于其設計思想和精簡的架構
?
不過還是有一些兼容memcached協議的服務器實現了范圍類操作,具體格式可以參考?https://code.google.com/p/memcached/wiki/RangeOps?所建議的標準
?
此外Redis的Hashes數據結構,在一定程度上可以滿足獲取特定子集數據的應用邏輯需求。
?
綜上來說,如果要實現類似HBase支持的scan操作,不論是Redis還是memcached都無法做到,但是對于Redis來說,能否用于批處理類應用,不能一概而論,取決于具體的數據的格式邏輯和使用方式。通過適當的調整應用程序使用數據的方式,還是有可能在一定程度上實現對MR類批處理,或范圍查詢類應用邏輯的支持的。而對于鍵值分布在一個較大的連續空間,數量不確定,同時又無法很好的映射為數值進而使用ordered set來處理的這樣一些數據結構,應該還是很難高效的分區遍歷的




)













)
