科學價值 社交關系 大數據
A crucial part of building a product is understanding exactly how it provides your customers with value. Understanding this is understanding how you fit into the lives of your customers, and should be central to how you build on what already exists. It is a way of ensuring that every decision taken will be positive and ultimately improve the value you deliver.
構建產品的關鍵部分是準確了解產品如何為客戶提供價值。 了解這一點就是了解您如何適應客戶的生活,并且應該成為您如何基于已有資源構建的核心。 這是確保所做出的每個決定都是積極的并最終提高您提供的價值的一種方法。
In the last couple of months the value question has been hot on the lips of some of us at Jeff. Considering the current global situation and the resulting difficulty of continuing to expand a rapidly growing platform, it was a good moment to take a step back and really think about how our customers were taking advantage of “the good, good life”.
在過去的幾個月中,價值問題一直困擾著我們杰夫(Jeff)的某些人。 考慮到當前的全球形勢以及持續擴展快速增長的平臺所帶來的困難,現在是退后一步,真正考慮我們的客戶如何利用“美好,美好生活”的好時機。
我們如何到達這里 (How we got here)
The company wide project started with the new user experience team, who got data science involved after some early conversations. Understanding our service’s value was one of their first initiatives, and they saw that a necessary part of this was drawing the typical “customer journey”. These are the typical life cycles that users have on the platform and they help us clearly pinpoint the different moments where customers are delivered value. To draw this they needed a general overview of our different users’ behaviours.
公司范圍內的項目始于新的用戶體驗團隊,該團隊在進行了一些初期交談之后就參與了數據科學的研究。 了解我們服務的價值是他們的首批舉措之一,他們認為其中的必要部分正在吸引典型的“客戶旅程”。 這些是用戶在平臺上擁有的典型生命周期,它們可以幫助我們明確指出為客戶交付價值的不同時刻。 為此,他們需要對我們不同用戶的行為進行總體概述。
Getting in touch with the data science team to see if we could demystify some aspects, everyone quickly realised that one of the biggest challenges facing us was that most of the understanding of our company was dispersed, based on intuition, and not easily accessible. Hypotheses were unconfirmed, and complex topics were relatively unexplored. This is pretty typical for many organisations, especially when they are still young, rapidly changing, or don’t have a strong research culture.
與數據科學團隊聯系,看看我們是否可以揭開某些神秘面紗,每個人都Swift意識到,我們面臨的最大挑戰之一是,基于直覺,對我們公司的大多數理解是分散的,并且不易獲得。 假設尚未得到證實,而相對復雜的話題尚未得到探討。 這對于許多組織來說是非常典型的,尤其是當它們還很年輕,變化Swift或者沒有強大的研究文化時。
While this made the task at hand more difficult, it also has several repercussions for decision making. The first main issue is that teams are mostly blind to research not done by themselves, and are doomed to either waste time on ad hoc investigations, miss out on what other teams already know, or make decisions for the wrong reasons. The other is a struggle to gauge the impact of any changes to the platform. Should we encourage more users to subscribe? Is that more important than improving onboarding of new users? This is hard to understand on the fly and makes prioritising a vague process.
盡管這使手頭的任務變得更加困難,但對決策也有一些影響。 第一個主要問題是,團隊大多對自己無法完成的研究視而不見,并且注定要浪費時間進行臨時調查,錯過其他團隊已經知道的知識或出于錯誤的原因做出決定。 另一個是努力評估平臺任何更改的影響。 我們應該鼓勵更多的用戶訂閱嗎? 這比改善新用戶的加入更為重要嗎? 這是很難即時理解的,并且會使模糊的過程成為優先事項。
With both of our teams being relatively young, we saw this as a good opportunity to not only analyse our value proposition, but also to deliver a broad, unified understanding that could be used by anyone in the company when it came to decision making.
由于我們的兩個團隊都相對年輕,我們認為這是一個很好的機會,不僅可以分析我們的價值主張,還可以提供廣泛,統一的理解,供公司中的任何人在決策時使用。
細分客戶 (Segmenting our customers)
One of the beautiful things about the data — user experience partnership is that both sides can readily contribute to a common goal in ways that the other cannot.
關于數據的美麗之處之一-用戶體驗合作關系是,雙方可以輕易以雙方無法做到的方式為共同的目標做出貢獻。
Part of the initial problem was understanding exactly what the status quo was — understanding what users come to us for. This is a daunting task, considering the thousands of different users with all of their peculiarities. As a data scientist however, detecting and quantifying diverse behaviours should be your bread and butter.
最初問題的一部分是確切地了解現狀-了解用戶向我們尋求什么。 考慮到成千上萬的不同用戶的特殊性,這是一項艱巨的任務。 但是,作為數據科學家,檢測和量化各種行為應該是您的頭等大事。
This seemed like a typical case that calls for a user segmentation, which is basically the division of users into different common behaviours. This classic concept is quite simple, but in practice, a good segmentation is nuanced and defined by a central trade off. For it to be useful, we need to design segments that contain specific, uniform behaviours, that all carry some business meaning. The trade off is that many tiny groups, created using all of the variables available to you, are all specific and uniform — but a few big groups designed using only a few company level KPIs are far, far easier to understand and use practically. The bonus difficulty is that there isn’t a single metric that will evaluate the quality of your segments.
這似乎是一個典型的案例,需要進行用戶細分 ,這基本上是將用戶劃分為不同的常見行為。 這個經典概念非常簡單,但是在實踐中,通過權衡取舍可以很好地細分和定義良好的細分。 為了使其有用,我們需要設計包含特定且統一的行為的細分市場,這些行為均具有一定的業務意義。 需要權衡的是,使用您可用的所有變量創建的許多小型小組都是特定且統一的,但是僅使用幾個公司級KPI設計的幾個大型小組實際上就容易得多,而且更容易理解和使用。 額外的困難在于,沒有一個可以評估細分受眾群質量的指標。
This problem typically arises when data scientists are too quick to shove a whole database into their favourite algorithm. In our particular case, the platform combines online, offline, subscribers, and occasional users — without even mentioning our other customers, the franchise owning partners — a lot of combinations and the need to create a more or less unified framework. Considering that to start with we were interested in a general overview of behaviour, we alleviated the dilemma by focusing on variables that reflect the core of the business, and by creating the segments focusing on interpretable “cut off” points — the limits we used to define different behaviour groups. All of this while taking into account the entire lifecycle of our users on the platform.
當數據科學家太快而無法將整個數據庫推入他們喜歡的算法時,通常會出現此問題。 在我們的特殊情況下,該平臺將在線,離線,訂戶和偶爾的用戶結合在一起-甚至沒有提及我們的其他客戶,特許經營擁有者-很多組合,而且需要創建或多或少統一的框架。 考慮到我們首先對行為的總體概況感興趣,因此我們通過關注反映業務核心的變量并創建關注可解釋的“截止”點的細分市場(我們過去的限制)來緩解困境。定義不同的行為組。 所有這些都考慮了平臺上用戶的整個生命周期。
Two good examples are the frequency and number of orders for a user. The frequency is easily divisible into interpretable “categories”, like users who order once a week or once a month — especially since this lines up with how our subscriptions work. Looking at how many users followed different behaviours, we can easily make more or fewer frequency segments like this. The number of orders was a bit more complicated. We saw that the more orders a user had, the more likely they were to be retained long term, but only marginally. Comparing users with more than 5 and 20 orders, for example, we saw that while users with more than 5 were slightly less likely to churn, there were way more of them than those with over 20. We accepted this trade off to define a “retained users” segment that had plenty of customers, only marginally losing out on uniformity of behaviour.
兩個好的例子是用戶的訂單頻率和數量。 頻率很容易劃分為可解釋的“類別”,例如每周或每月訂購一次的用戶-尤其是因為這與我們的訂閱工作方式保持一致。 觀察有多少用戶遵循不同的行為,我們可以輕松地像這樣創建更多或更少的頻率段。 訂單數量稍微復雜一些。 我們看到用戶擁有的訂單越多,則越有可能長期保留訂單,但僅保留一部分訂單。 例如,比較訂單數量超過5和20的用戶,雖然用戶數量超過5的用戶流失的可能性略小,但與用戶數量超過20的用戶相比,用戶流失的可能性更大。我們接受了這種權衡來定義“擁有大量客戶的“保留用戶”細分受眾群,但在行為統一性方面僅微不足道。
This approach meant different behaviour groups are easy to understand and immediately relevant to current strategy, while being defined in a purposeful and meaningful way thanks to our interpretable “cut offs”. For example, it becomes very clear how much we stand to gain from converting new users to “retained” users, the potential target audience for subscription up-selling (frequently ordering users without a subscription), as well as how users’ behaviour evolves (how they move from one segment to another over time).
這種方法意味著不同的行為群體易于理解,并與當前策略直接相關,同時由于我們可解釋的“臨界值”,以有目的和有意義的方式對其進行了定義。 例如,非常清楚的是,從將新用戶轉換為“保留”用戶,潛在地進行訂閱向上銷售(經常訂購沒有訂閱的用戶)的目標受眾以及用戶行為的演變,我們將獲得多少收益(隨著時間的推移,它們如何從一個細分轉移到另一個細分)。
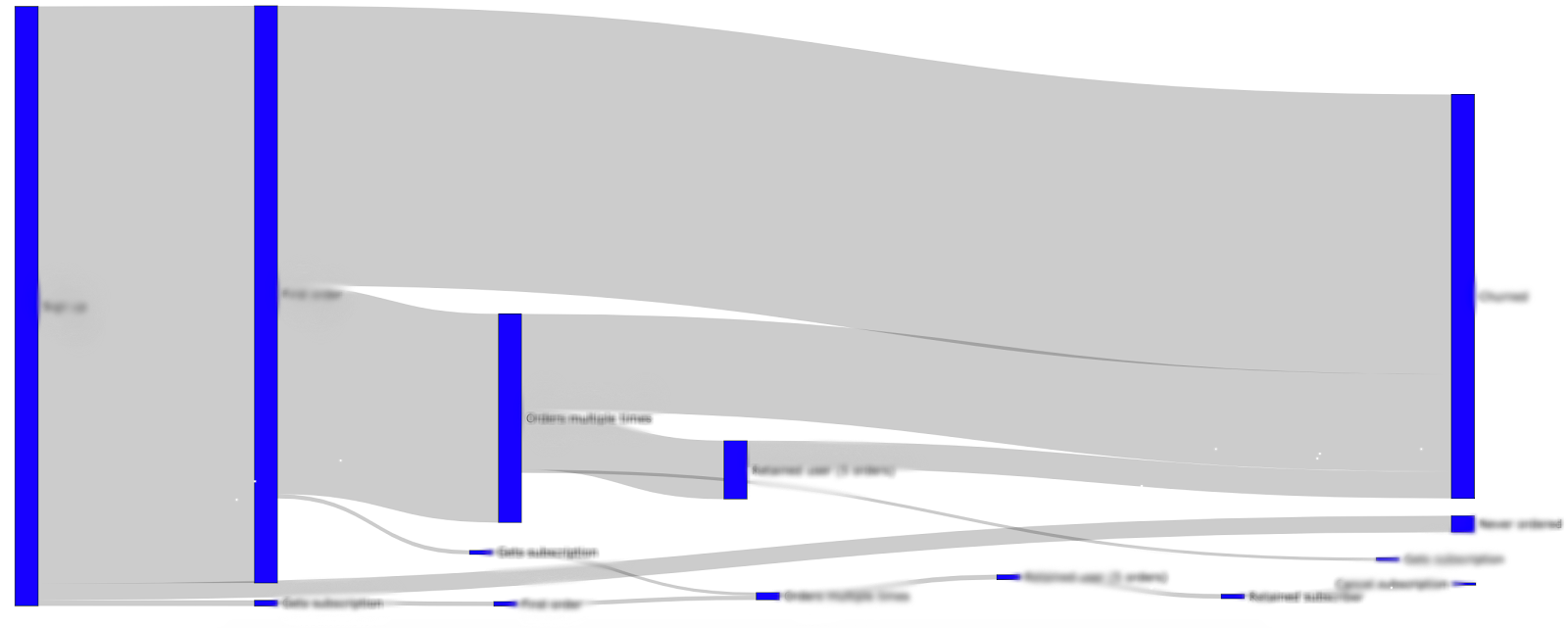
Throughout the process of building our segments, we also adopted a methodology of continuously delivering concrete insights about what we were finding, ranging from how long users take to make their first order, to how much subscribers contribute to the financial health of a hub. These were all key pieces of knowledge that we found to be missing when we started the project. The continuous delivery of these conclusions gave our young team plenty of low hanging fruit to make some quick impact.
在構建細分市場的整個過程中,我們還采用了一種方法,不斷對發現的結果提供具體的見解,范圍從用戶下達第一筆訂單所需的時間到訂戶對樞紐財務狀況的貢獻有多大。 這些都是我們在開始項目時發現缺少的關鍵知識。 這些結論的不斷傳遞使我們的年輕團隊垂涎三尺,可以Swift產生影響。
The next step specific to our segments is to understand how they can best be used directly to improve the development of new features and strategy. We are also in the process of understanding how they might be useful for our franchise partners, so that they can improve how they run their businesses.
我們細分市場的下一步是了解如何最好地將其直接用于改進新功能和策略的開發。 我們也在了解它們對我們的特許合作伙伴可能有用的方式,以便他們可以改善其業務運作方式。
用戶體驗和我們的價值主張 (User experience and our value proposition)
With these findings, we were able to get rid of the vague, general context that we started with, and replace it with a detailed, specific overview of the different customer behaviours. This allowed the user experience team to start to really flesh out their understanding of the user journey, adding new paths, expanding on existing ones, and supplementing the design with concrete statistics on behaviour. We could now understand where we are fulfilling our promised value, where we are not, and where users are finding value in unexpected ways.
有了這些發現,我們就擺脫了最初的含糊,籠統的背景,而用不同的客戶行為的詳細,詳細的概述代替了它。 這樣,用戶體驗團隊就可以開始真正充實他們對用戶旅程的理解,添加新路徑,擴展現有路徑,并通過行為的具體統計數據來補充設計。 現在,我們可以了解我們在哪里實現了承諾的價值,在哪里沒有實現,以及用戶在哪里以意想不到的方式找到價值。
Having reached this point, the user experience team is also in a much better position to plan future research activity. They can interview our customers and ask exactly why they do certain things, and deliver the company insights that data science alone could not. It allows us to understand the motivations behind user behaviour, including external factors that affect this.
到此為止,用戶體驗團隊也可以更好地計劃未來的研究活動。 他們可以采訪我們的客戶,并確切詢問他們為什么要做某些事情,并提供僅憑數據科學無法做到的公司見解。 它使我們能夠了解用戶行為的動機,包括影響用戶行為的外部因素。
We are confident that this will be the first major step on our way to fully understand how we improve the lives of our customers. By taking advantage of data science’s ability to summarise how users behave, user experience is able to both fully understand the customer journey with the service, as well as round off our overall understanding with their own differential research. This puts us well on the path to understanding what role Jeff plays in the lives of its customers, and will hopefully drive real, research backed improvements to the service in the future.
我們相信,這將是我們全面了解如何改善客戶生活的第一步。 通過利用數據科學總結用戶行為的能力,用戶體驗既可以全面了解客戶使用該服務的旅程,又可以通過他們自己的差異研究來完善我們的整體理解。 這使我們能夠更好地理解Jeff在客戶生活中所扮演的角色,并有望在未來推動對服務進行真正的,研究支持的改進。
We will be sure to post an update on how things are going in the near future, but in the meantime don’t hesitate to get in touch if you have any questions, comments, or feedback!
我們一定會發布一個更新的事情是如何在不久的將來打算,但在此期間不要猶豫 取得聯系 ,如果您有任何疑問,意見或反饋!
翻譯自: https://medium.com/jeff-tech/the-value-of-a-service-data-science-and-user-experience-investigate-the-good-good-life-cdc7044e06a7
科學價值 社交關系 大數據
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/388103.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/388103.shtml 英文地址,請注明出處:http://en.pswp.cn/news/388103.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

在Ubuntu下創建hadoop組和hadoop用戶

day06 hashlib模塊

vs azure web_在Azure中遷移和自動化Chrome Web爬網程序的指南。

hadoop eclipse windows


netstat 在windows下和Linux下查看網絡連接和端口占用

selenium 解析網頁_用Selenium進行網頁搜刮

)
代理ARP協議(Proxy ARP)

hive 導入hdfs數據_將數據加載或導入運行在基于HDFS的數據湖之上的Hive表中的另一種方法。

)
對Faster R-CNN的理解(1)

大數據業務學習筆記_學習業務成為一名出色的數據科學家

postman 請求參數為數組及JsonObject
對稱二叉樹 個人題解)
領扣(LeetCode)對稱二叉樹 個人題解

python 開發api_使用FastAPI和Python快速開發高性能API

Purley平臺Linpak測試,從踏坑開始一步步優化
——目錄結構)
基于easyui開發Web版Activiti流程定制器詳解(一)——目錄結構

HDOJ 2037:今年暑假不AC_大二寫
——文件列表)