hive 導入hdfs數據
Preceding pen down the article, might want to stretch out appreciation to all the wellbeing teams beginning from cleaning/sterile group to Nurses, Doctors and other who are consistently battling to spare the mankind from continuous Covid-19 pandemic over the globe.
在下一篇文章之前,不妨向從清潔/無菌小組到護士,醫生和其他一直在努力使人類免受全球Covid-19大流行的困擾的所有健康團隊表示感謝。
The fundamental target of this article is to feature how we can load or import data into Hive tables without explicitly execute the “load” command. Basically, with this approach Data scientists can query or even visualize directly on various data visualization tool for quick investigation in a scenario when raw data is continuously ingested to HDFS based Data lake from the external sources on a consistent schedule. Otherwise, “load” command would be required to execute furthermore for stacking the processed data into Hive’s table. Here we are considering an existing environment with the following components either set up on the Cloud or on-premise.
本文的基本目標是介紹如何在不顯式執行“ load”命令的情況下將數據加載或導入到Hive表中。 基本上,使用這種方法,當原始數據以一致的時間表從外部源連續攝取到基于HDFS的Data Lake時,數據科學家可以直接在各種數據可視化工具上進行查詢甚至可視化,以進行快速調查。 否則,將需要“ load”命令來進一步執行,以將處理后的數據堆疊到Hive的表中。 在這里,我們正在考慮具有以下組件的現有環境,這些組件在云端或本地設置。
- Multi-node Cluster where HDFS installed and configured. Hive running on top of HDFS with MySQL database as metastore. 已安裝和配置HDFS的多節點群集。 Hive在HDFS之上運行,并將MySQL數據庫作為metastore。
- Assuming raw data is getting dumped from multiple sources into HDFS Data lake landing zone by leveraging Kafka, Flume, customized data ingesting tool etc. 假設利用Kafka,Flume,定制數據提取工具等將原始數據從多個來源轉儲到HDFS Data Lake登陸區。
- From the landing zone, raw data moves to the refining zone in order to clean junk and subsequently into the processing zone where clean data gets processed. Here we are considering that the processed data stored in text files with CSV format. 原始數據從著陸區移至精煉區,以清理垃圾,然后移至處理區,在此處理干凈數據。 在這里,我們考慮將處理后的數據存儲在CSV格式的文本文件中。
Hive input is directory-based which similar to many Hadoop tools. This means, input for an operation is taken as files in a given directory. Using HDFS command, let’s create a directory in the HDFS using “$ hdfs dfs -mkdir <<name of the folder>>. Same can be done using Hadoop administrative UI depending upon user’s HDFS ACL settings. Now move the data files from the processing zone into newly created HDFS folder. As an example, here we are considering simple order data that ingested into the data lake and eventually transformed to consolidated text files with CSV format after cleaning and filtering. Few lines of rows are as follows
Hive輸入是基于目錄的,類似于許多Hadoop工具。 這意味著,操作的輸入將作為給定目錄中的文件。 使用HDFS命令,讓我們使用“ $ hdfs dfs -mkdir <<文件夾名稱>>在HDFS中創建一個目錄。 根據用戶的HDFS ACL設置,可以使用Hadoop管理UI進行相同的操作。 現在,將數據文件從處理區域移到新創建的HDFS文件夾中。 例如,這里我們考慮的是簡單的訂單數據,這些數據被導入到數據湖中,并在清洗和過濾后最終轉換為CSV格式的合并文本文件。 行的幾行如下
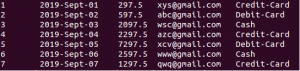
Next step is to create an external table in Hive by using the following command where the location is the path of HDFS directory that created on the previous step. here is the command we could use to create the external table using Hive CLI. The LOCATION statement in the command tells Hive where to find the input files.
下一步是使用以下命令在Hive中創建外部表,其中位置是在上一步中創建的HDFS目錄的路徑。 這是我們可以用來使用Hive CLI創建外部表的命令。 命令中的LOCATION語句告訴Hive在哪里找到輸入文件。

If the command worked, an OK will be printed and upon executing Hive query, Hive engine fetches the data internally from these input text files by leveraging processing engine Map Reducer or other like Spark, Tez etc. Ideally, Spark or Tez can be configured as a processing engine in hive-site.xml in order to improve the data processing speed for a huge volume of input files.
如果該命令有效,則將打印OK,并且在執行Hive查詢時,Hive引擎可利用處理引擎Map Reducer或其他諸如Spark,Tez等從這些輸入文本文件內部獲取數據。理想情況下,Spark或Tez可配置為hive-site.xml中的處理引擎,以提高大量輸入文件的數據處理速度。
Once the table creation is successful, we can cross-check it on “ metastore” schema in the MySQL database. To perform that, log in to MySQL CLI which might be running on a different node in the cluster and then connect to the “metastore” database as well as pulls records from “TBLS” table. This displays the created Hive table information.
一旦表創建成功,我們就可以在MySQL數據庫的“ metastore”模式中對其進行交叉檢查。 要執行此操作,請登錄到可能正在集群中其他節點上運行MySQL CLI,然后連接到“元存儲”數據庫并從“ TBLS”表中提取記錄。 這將顯示創建的Hive表信息。
The import can be verified through the Hive’s CLI by listing the first few rows in the table.
可以通過Hive的CLI列出表中的前幾行來驗證導入。
hive> Select * from OrderData;
蜂巢>從OrderData中選擇*;
Additionally, “ analyze compute statistics “ command could be executed in Hive CLI to view the detail information of jobs that runs on that table.
另外,可以在Hive CLI中執行“ 分析計算統計信息 ”命令,以查看在該表上運行的作業的詳細信息。
The primary advantage with this approach is, data can be query, analyze etc within a minimum span of time without additionally perform explicit data loading operation. Also helps the Data scientists to check the quality of data before running their machine learning jobs on the data lake or cluster. You could read here how to install and configure Apache Hive on multi-node Hadoop cluster with MySQL as Metastore.
這種方法的主要優點是,可以在最短的時間范圍內查詢,分析數據,而無需另外執行顯式的數據加載操作。 還可以幫助數據科學家在數據湖或集群上運行其機器學習作業之前檢查數據質量。 您可以在此處閱讀如何在以MySQL作為Metastore的多節點Hadoop集群上安裝和配置Apache Hive。

Written byGautam Goswami
由 Gautam Goswami 撰寫

Enthusiastic about learning and sharing knowledge on Big Data and related headways. Play at the intersection of innovation, music and workmanship.
熱衷于學習和共享有關大數據和相關進展的知識。 在創新,音樂和Craft.io的交匯處演奏。
Originally published at https://dataview.in on August 4, 2020.
最初于 2020年8月4日 在 https://dataview.in 上 發布 。
翻譯自: https://medium.com/@gautambangalore/an-alternative-way-of-loading-or-importing-data-into-hive-tables-running-on-top-of-hdfs-based-data-d3eee419eb46
hive 導入hdfs數據
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/388093.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/388093.shtml 英文地址,請注明出處:http://en.pswp.cn/news/388093.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

)
對Faster R-CNN的理解(1)

大數據業務學習筆記_學習業務成為一名出色的數據科學家

postman 請求參數為數組及JsonObject
對稱二叉樹 個人題解)
領扣(LeetCode)對稱二叉樹 個人題解

python 開發api_使用FastAPI和Python快速開發高性能API

Purley平臺Linpak測試,從踏坑開始一步步優化
——目錄結構)
基于easyui開發Web版Activiti流程定制器詳解(一)——目錄結構

HDOJ 2037:今年暑假不AC_大二寫
——文件列表)
基于easyui開發Web版Activiti流程定制器詳解(二)——文件列表

杭電oj2047-2049、2051-2053、2056、2058

Power BI:M與DAX以及度量與計算列

git 基本命令和操作
——頁面結構(上))
基于easyui開發Web版Activiti流程定制器詳解(三)——頁面結構(上)

bzoj 4300 絕世好題 —— 思路
——頁面結構(下))
基于easyui開發Web版Activiti流程定制器詳解(四)——頁面結構(下)

梯度下降法優化目標函數_如何通過3個簡單的步驟區分梯度下降目標函數

FFmpeg 是如何實現多態的?
——Draw2d詳解(一))
基于easyui開發Web版Activiti流程定制器詳解(五)——Draw2d詳解(一)
