原理
布隆過濾器數據結構
布隆過濾器是一個 bit 向量或者說 bit 數組,長這樣:

如果我們要映射一個值到布隆過濾器中,我們需要使用多個不同的哈希函數生成多個哈希值,并對每個生成的哈希值指向的 bit 位置 1。
例如針對值 “baidu” 和三個不同的哈希函數分別生成了哈希值 1、4、7,則上圖轉變為:
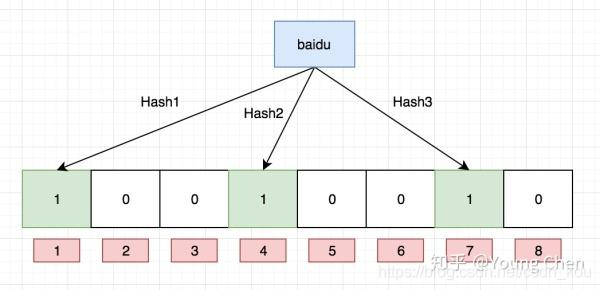
Ok,我們現在再存一個值 “tencent”,如果哈希函數返回 3、4、8 的話,圖繼續變為:
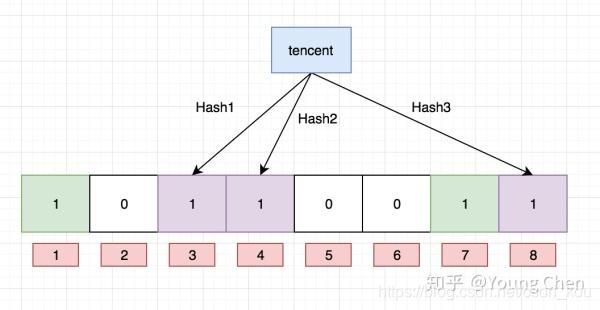
值得注意的是,4 這個 bit 位由于兩個值的哈希函數都返回了這個 bit 位,因此它被覆蓋了。
現在我們如果想查詢 “dianping” 這個值是否存在,哈希函數返回了 1、5、8三個值,結果我們發現 5 這個 bit 位上的值為 0,說明沒有任何一個值映射到這個 bit 位上,因此我們可以很確定地說 “dianping” 這個值不存在。
而當我們需要查詢 “baidu” 這個值是否存在的話,那么哈希函數必然會返回 1、4、7,然后我們檢查發現這三個 bit 位上的值均為 1,那么我們可以說 “baidu” 存在了么?答案是不可以,只能是 “baidu” 這個值可能存在。
這是為什么呢?答案跟簡單,因為隨著增加的值越來越多,被置為 1 的 bit 位也會越來越多,這樣某個值 “taobao” 即使沒有被存儲過,但是萬一哈希函數返回的三個 bit 位都被其他值置位了 1 ,那么程序還是會判斷 “taobao” 這個值存在。
作者:YoungChen__
鏈接:https://zhuanlan.zhihu.com/p/43263751
特點
- 可以判斷某一個數一定不存在
- 不可以判斷某一個數一定存在
應用場景
- 海量URL的去重
源碼實現
- 三個哈希函數
unsigned int SDBMHash(char *str, unsigned int size)
{unsigned int hash = 0;while (*str){// equivalent to: hash = 65599*hash + (*str++);hash = (*str++) + (hash << 6) + (hash << 16) - hash;}return (hash & 0x7FFFFFFF) % size;
}// RS Hash Function
unsigned int RSHash(char *str, unsigned int size)
{unsigned int b = 378551;unsigned int a = 63689;unsigned int hash = 0;while (*str){hash = hash * a + (*str++);a *= b;}return (hash & 0x7FFFFFFF) % size;
}// JS Hash Function
unsigned int JSHash(char *str, unsigned int size)
{unsigned int hash = 1315423911;while (*str){hash ^= ((hash << 5) + (*str++) + (hash >> 2));}return (hash & 0x7FFFFFFF) % size;
}
- 插入并給指定位置置1
void BFInsert(BloomFilter *pBF, const char *str)
{unsigned int i1 = pBF->func1(str, pBF->bm.size);unsigned int i2 = pBF->func2(str, pBF->bm.size);unsigned int i3 = pBF->func3(str, pBF->bm.size);BMSetOne(&(pBF->bm), i1);BMSetOne(&(pBF->bm), i2);BMSetOne(&(pBF->bm), i3);
}
優質參考文獻
https://www.jianshu.com/p/2104d11ee0a2
https://blog.csdn.net/championhengyi/article/details/72885500
https://baike.baidu.com/item/布隆過濾器/5384697?fr=aladdin





 Redis簡介)

redis搭建集群)




 redis持久化)

 Redis參數意義)

 主從復制和sentinel哨兵模式)

 監控Redis工作狀態-info命令)
