日常中我們見到的二叉樹應用有,Java集合中的TreeSet和TreeMap,C++ STL中的set、map,以及Linux虛擬內存的管理,以及B-Tree,B+-Tree在文件系統,都是通過紅黑樹去實現的。雖然之前寫過《再談堆排序:堆排序算法流程步驟透解—最大堆構建原理》但是二叉樹的基本性質,對我來說,從入門到放棄是搞了好幾回。本文推薦看原文。
樹的基本概念
樹(Tree):樹是一種數據結構,可以表示層次關系,它是由n(n>=1)個有限節點組成一個具有層次關系的集合。形狀像一棵倒掛的樹。
樹:不包含回路的連通無向圖(樹是一種簡單的非線性結構)
樹有著不包含回路這個特點,所以樹就被賦予了很多特性
一棵樹中任意兩個結點有且僅有唯一的一條路徑連通
一棵樹如果有n個結點,那它一定恰好有n-1條邊
在一棵樹中加一條邊將會構成一個回路
樹中有且僅有一個沒有前驅的結點稱為根結點
在對樹進行討論的時候將樹中的每個點稱為結點,
根結點|樹根(root):沒有父結點的結點,即樹最頂層的節點
葉結點|樹葉(Leaf):沒有子結點的結點(沒有子點的都稱為葉子)
內部結點|分支結點|樹枝(Subtree):除了根節點以外且擁有葉子節點,即一個結點既不是根結點也不是葉結點
集合概念理解樹
樹(Tree)是n(n>=0)個結點的有限集。在任意一棵非空樹中:
有且僅有一個特定的稱為根(Root)的結點;
當n>1時,其余結點可分為m(m>0)個互不相交的有限集T1,T2,T3,...Tm,其中每一個集合本身又是一棵樹,并且稱為根的子樹(Subtree)。
樹的基本特性
結點的子樹的根稱為該結點的孩子(Child)。相應的,該結點稱為孩子的雙親(Parent)。同一個雙親的孩子之間互稱兄弟(Sibling)。其雙親在同一層的結點互為堂兄弟。

樹的度
深度|高度(Depth):是指從根結點到這個結點的層數,根結點為第一層。每個結點都有深度,比如上圖左邊的樹的4號結點深度是3。
結點的度:結點擁有的子樹的數目稱為結點的度(Degree)。
樹的度:樹中結點的最大的度,即:是樹內各結點的度的最大值。
葉子的度:度為0的結點(tips:在任意一個二叉樹中,度為0的葉子結點總是比度為2的結點多一個)
分支的度:度不為0的結點
結點的層次(Level)
層次:根結點的層次為1,其余結點的層次等于該結點的雙親結點的層次加1
樹的高度:樹中結點的最大層次
有序樹與無序樹
樹中結點的各子樹看成從左至右是有次序的(即不能交換),則稱該樹為有序樹,否則稱為無序樹。在有序樹中最左邊的子樹的根稱為第一個孩子,最右邊的稱為最后一個孩子。
森林(Forest)
森林(Forest)是m(m>=0)棵互不相交的樹的集合。對樹中每個結點而言,其子樹的集合即為森林。
二叉樹
二叉樹(Binary Tree)是一種樹形結構,它的特點是每個節點最多只有兩個分支節點,一棵二叉樹通常由根節點,分支節點,葉子節點組成。而每個分支節點也常常被稱作為一棵子樹。
二叉樹是遞歸定義的,其結點有左右子樹之分。
二叉樹的基本概念:
二叉樹是一種非線性結構,二叉樹通常采用鏈式存儲結構,存儲結點由數據域和指針域(指針域:左指針域和右指針域)組成,二叉樹的鏈式存儲結構也稱為二叉鏈表,對滿二叉樹和完全二叉樹可按層次進行順序存儲
樹和二叉樹的三個主要差別
樹的節點個數至少為1,而二叉樹的節點個數可以為0
樹中節點的最大度數(節點數量)沒有限制,而二叉樹的節點的最大度數為2
樹的節點沒有左右之分,而二叉樹的節點有左右之分
二叉樹特點:
每個結點最多有兩顆子樹
左子樹和右子樹是有順序的,次序不能顛倒
即使某結點只有一個子樹,也要區分左右子樹
二叉樹可為空,空的二叉樹沒有結點,非空二叉樹有且僅有一個根節點
二叉樹基本性質:
在二叉樹的第k層上,至多有2^(k-1)個結點,k=1時,只有一個根節點,2^(k-1) = 2^0 = 1
深度為k的二叉樹至多有2^k-1個節點,k=2時,2^k-1 = 2^2 - 1 = 3個節點
如果總結點數為n0,度為2(子樹數目為2)的節點數為n2,則n0=n2+1
度為0的結點n0(即葉子結點)總是比度為2的結點多一個,即n0=n2+1
具有n個結點的完全二叉樹的深度至少為[log2n]+1,其中[log2n]表示log2n的整數部分
有N個結點的完全二叉樹各結點如果用順序方式存儲,如數組存儲
left = index * 2 + 1,
right = index * 2 + 2
序數 >= floor(N/2)都是葉子節點
給定N個節點,能構成h(N)種不同的二叉樹,其中h(N)為卡特蘭數的第N項,h(n)=C(2*n, n)/(n+1)。
設有i個枝點,I為所有枝點的道路長度總和,J為葉的道路長度總和J=I+2i。
二叉樹中有兩種特殊的二叉樹:滿二叉樹、完全二叉樹
完全二叉樹:
第一種解釋:完全二叉樹是指最后一層左邊是滿的,右邊可能滿也可能不滿,然后其余層都是滿的(這句話不太好理解),看下面第二種解釋
第二種解釋:除第h層外,其他各層(1到h-1)的結點數都達到最大個數,第h層從右向左連續缺若干結點,則這個二叉樹就是完全二叉樹
也就是說如果一個結點有右子結點,那么它一定也有左子結點
第三種解釋:除最后一層外,每一層上的節點數均達到最大值,在最后一層上只缺少右邊的若干結點
深度為k的,有n個結點的二叉樹,當且僅當其每一個結點都與深度為k的滿二叉樹中編號從1至n的結點一一對應時,稱之為完全二叉樹。
完全二叉樹的兩個特性:
具有n個結點的完全二叉樹的深度為Math.floor(㏒? n) + 1;
如果對一棵有n個結點的完全二叉樹(其深度為Math.floor(log_2 n) + 1)的結點按層序編號(從第1層到第Math.floor(log_2 n) + 1,每層從左到右),則對任一結點(1<=i<=n)有:
如果i=1,則結點i是二叉樹的根,無雙親;如果i>1,則其雙親parent(i)是結點Math.floor(i/2)。
如果2i > n,則結點i無左孩子(結點i為葉子結點);否則其左孩子LChild(i)是結點2i.
如果2i + 1 > n,則結點i無右孩子;否則其右孩子RChild(i)是結點2i + 1;
滿二叉樹:
滿二叉樹:一顆深度為k且有2^k - 1個節點的二叉樹稱為滿二叉樹。
二叉樹中每個內部結點都有存在左子樹和右子樹(或者說滿二叉樹所有的葉結點都有同樣的深度)
滿二叉樹也是一種完全二叉樹,但完全二叉樹不一定是滿二叉樹。
二叉堆
二叉堆由一棵完全二叉樹來表示其結構,可用數組來表示。二叉堆需要滿足:
二叉堆的父節點的鍵值總是大于或等于(小于或等于)任何一個子節點的鍵值
當父節點的鍵值大于或等于(小于或等于)它的每一個子節點的鍵值時,稱為最大堆(最小堆)
注:最大堆:父結點>=子結點,最小堆:父結點=,
堆的實現通過構造二叉堆(binary heap),實為二叉樹的一種;由于其應用的普遍性,當不加限定時,均指該數據結構的這種實現。
二叉搜索樹(二叉查找樹、二叉排序樹)
二叉查找樹(Binary Search Tree,BST),又稱為有序二叉樹,排序二叉樹。每個結點都符合:?父結點>右子結點>左子結點。
二叉查找樹中對于目標節點的查找過程類似與有序數組的二分查找,并且查找次數不會超過樹的深度。
二叉搜索樹的特性:
若任意節點的左子樹不空,則左子樹上所有節點的值均小于它的根節點的值;
若任意節點的右子樹不空,則右子樹上所有節點的值均大于它的根節點的值;
任意節點的左、右子樹也需要滿足左邊小于右邊的性質
沒有鍵值相等的節點。
二叉搜索樹主要的幾個操作:
查找(search)
插入(insert)
遍歷(transverse)
二叉查找樹的性質:對二叉查找樹進行中序遍歷,即可得到有序的數列。 二叉查找樹的高度決定了二叉查找樹的查找效率。
二叉排序樹與堆的區別
在二叉排序樹中,某結點的右孩子結點的值一定大于該結點的左孩子結點的值;在堆中卻不一定,堆只是限定了某結點的值大于(或小于)其左右孩子結點的值,但沒有限定左右孩子結點之間的大小關系。
即
二叉堆:父結點>=子結點||父結點=,
排序樹:父結點>右子結點>左子結點
在二叉排序樹中,最小值結點是最左下結點,其左指針為空;最大值結點是最右下結點,其右指針為空。在大根堆中,最小值結點位于某個葉子結點,而最大值結點是大根堆的堆頂(即根結點)。
堆是為了實現排序而設計的一種數據結構,它不是面向查找操作的,因而在堆中查找一個結點需要進行遍歷,其平均時間復雜度是O(n)。
二叉排序樹是為了實現動態查找而設計的數據結構,它是面向查找操作的。對于目標節點的查找過程類似與有序數組的二分查找,在二叉排序樹中查找一個結點的平均時間復雜度是O(log n);
設節點數目為n,樹的深度為h,假設樹的每層都被塞滿(第L層有2^L個節點,層數從1開始),則根據等比數列公式可得h=log(n+1)。即最好的情況下,二叉查找樹的查找效率為O(log n)。當二叉查找樹退化為單鏈表時,比如,只有右子樹的情況,如下圖所示,此時查找效率為O(n)。
總之,二叉查找樹越是“矮胖”,也就是每層盡可能地被“塞滿”(每個父節點均有兩個子節點)時,查找效率越高。
每層都被塞滿時,查找效率最高,最高為O(log n)。
當二叉查找樹退化為單鏈表時,查找效率最低,最低為O(n)。
為了解決二叉查找樹退化為單鏈表時查找效率低下的問題,引入了平衡二叉樹(AVL)。
平衡二叉樹(Balanced binary tree)
平衡二叉樹定義:平衡二叉樹(Balanced Binary Tree)又被稱為AVL樹(有別于AVL算法),且具有以下性質:它是一 棵空樹或它的左右兩個子樹的高度差的絕對值不超過1,并且左右兩個子樹都是一棵平衡二叉樹。平衡二叉樹的常用算法有紅黑樹、AVL樹等。在平衡二叉搜索樹中,我們可以看到,其高度一般都良好地維持在O(log2n),大大降低了操作的時間復雜度。
最小二叉平衡樹的節點的公式如下:F(n)=F(n-1)+F(n-2)+1
這個類似于一個遞歸的數列,可以參考Fibonacci數列,1是根節點,F(n-1)是左子樹的節點數量,F(n-2)是右子樹的節點數量。
從平衡二叉樹的性質可知,平衡二叉樹就是避免了二叉查找樹退化為單鏈表的極端情況。二叉查找樹的查找、插入、刪除較好時間復雜度是O(log n),最差是O(n)。二叉平衡樹保證查找、插入、刪除的時間復雜度穩定在O(log n)下。
總結:
完全二叉樹是效率很高的數據結構,堆是一種完全二叉樹或者近似完全二叉樹,所以效率極高,像十分常用的排序算法、Dijkstra算法、Prim算法等都要用堆才能優化,二叉排序樹的效率也要借助平衡性來提高,而平衡性基于完全二叉樹。這里推薦閱讀《講透學爛二叉樹一:樹和圖的概念以及二叉樹的基本性質》
平衡查找樹之AVL樹
AVL樹定義:AVL樹是最先發明的自平衡二叉查找樹。AVL樹得名于它的發明者 G.M. Adelson-Velsky 和 E.M. Landis,他們在 1962 年的論文 "An algorithm for the organization of information" 中發表了它。在AVL中任何節點的兩個兒子子樹的高度最大差別為1,所以它也被稱為高度平衡樹,n個結點的AVL樹最大深度約1.44log2n。查找、插入和刪除在平均和最壞情況下都是O(logn)。增加和刪除可能需要通過一次或多次樹旋轉來重新平衡這個樹。這個方案很好的解決了二叉查找樹退化成鏈表的問題,把插入,查找,刪除的時間復雜度最好情況和最壞情況都維持在O(logN)。但是頻繁旋轉會使插入和刪除犧牲掉O(logN)左右的時間,不過相對二叉查找樹來說,時間上穩定了很多。
AVL樹的自平衡操作——旋轉
AVL樹最關鍵的也是最難的一步操作就是旋轉。旋轉主要是為了實現AVL樹在實施了插入和刪除操作以后,樹重新回到平衡的方法。
平衡二叉樹-AVL樹(LL、RR、LR、RL旋轉)
讓AVL樹重新平衡的操作叫做旋轉(Rotate),旋轉操作是樹的基本操作也是其中一個難點,對于旋轉,使用結點上下移動反而會好理解一點,失衡結點的BF為2或-2,注意這個失衡結點一般取的是最小失衡結點,

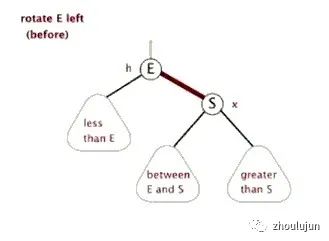
AVL樹在實現上需要在每個結點中保留高度信息,或者使用平衡因子(Balanced Factor),簡稱BF,每個結點的平衡因子等于左子樹的高度減去右子樹的高度,因此平衡值只有三種-1,+1和0。AVL樹主要是在增加或刪除結點后需要重新計算平衡因子,調整樹的結構使其重新平衡。
二叉樹不平衡的四種情況
首先要確定中心結點,即最小失衡結點A,其平衡因子的絕對值為2,主要有四種不平衡的情況:
(1)在A的左兒子B的左子樹插入,又稱為LL;
(2)在A的左兒子C的右子樹插入P,又稱為LR;
(3)在A的右兒子C的左子樹插入P,又稱為RL;
(4)在A的右兒子B的右子樹插入,又稱為RR。
要記住兩個重要節點,一個是失衡結點,另一個是失衡結點的兒子,該兒子在失衡路徑上,旋轉操作則是依據失衡結點的兒子為中心,對失衡結點進行下移動。在這四種失衡情況中(1)和(4)是一樣的,(2)和(3)是一樣的,前者使用單旋轉,后者使用雙旋轉。
AVL樹單旋轉和雙旋轉
在進行旋轉操作時,首先要找到最小失衡結點,判斷失衡的類型,然后選擇旋轉的類型,如何判斷呢?根據上面的圖片中的結點A,BF為2確定為左兒子左邊L,根據左兒子的BF為-1,則確定為R,此時屬于不平衡情況(2),使用雙旋轉,下面詳細介紹單旋轉和雙旋轉的四種旋轉方式。
平衡的二叉搜索樹的分類:
平衡的二叉搜索樹一般分為兩類:
嚴格維護平衡的,樹的高度控制在log2n,使得每次操作都能使得時間復雜度控制在O(logn),例如AVL樹,紅黑樹;
非嚴格維護平衡的,不能保證每次操作都控制在O(logn),但是每次操作均攤時間復雜度為O(logn),例如伸展樹。
伸展樹(Splay Tree)
伸展樹(Splay Tree),是一種二叉搜索樹(Binary Search Tree,又稱二叉排序樹Binary Sort Tree),由丹尼爾·斯立特(Daniel Sleator)和 羅伯特·恩卓·塔揚(Robert Endre Tarjan)在1985年發明。
伸展樹的基本概念
AVL樹在每次刪除或添加結點時都需要使用旋轉操作平衡二叉樹,以獲得最好的查找效率,伸展樹是另一種二叉樹,它不需要高度或平衡因子這些平衡信息。伸展樹使用另一種方式實現高效率的查找,不平衡但要求每次操作的那個結點旋轉到根結點上來,這樣下次查找它就能達到最快效率了,這是根據計算機的局部原理,當一塊數據被訪問后,此后段時間內也會該數據或附近的數據也會被再次用到。這也就是說,進行增加、刪除、查找等操作都需要將本次操作的結點或附近結點旋轉到根結點上,可對所有操作都調整,或只針對查找進行調整。
伸展樹進行M次操作,其時間復雜度為O(M logN),而普通二叉樹最壞情況為O(N),連續M次操作為O(M*N)。如果一個算法M次操作的時間為O(MF(N)),則O(F(N))稱為該算法的攤還時間或攤還代價,伸展樹的攤還代價為O(logN)。
伸展樹的實現原理
綜上,伸展樹不需要AVL樹的平衡信息,高度或BF,它是一個普通二叉查找樹,它的出發點是:頻繁查找一個深結點X,會造成花費的時間過多,采取的辦法是:將樹在X處展開,將該結點旋轉到根結點,自下向上單旋轉,對訪問路徑上的每個結點和父結點進行單旋轉,這樣頻繁訪問結點即可大大減少時間,但是執行M次操作仍然至少需要M*N的時間(最壞情況單鏈表為N)。
伸展樹在實現上可使用上面說的單旋轉,根據目標結點,全部使用單旋轉,但是效率并不好,例如單鏈表的情況,依次插入1、2、3、4、5,其效率并不好,結點4深度依然比較深,如下圖:
為了解決這個問題,我們采取一種特別的實現,根據三種情況進行旋轉:
(1)當前結點只有父親結點,使用單旋轉,很明顯這種情況的父親結點為根結點;
(2)當前結點有父親結點和祖父結點,呈之字形,例如當前結點是父親結點的右兒子,父親結點是祖父結點的左兒子。之字形的情況進行一次AVL雙旋轉,如下圖:
當前結點有父親結點和祖父結點,呈一字形,也就是類似LL和RR的情況,但是并不是使用單旋轉,而是進行一字形對稱旋轉。假設祖父結點是根結點,那么讓當前結點X成為根結點,父親結點稱為X的右兒子,祖父結點成為父親結點的右兒子,X的原右兒子成為父親的左兒子,父親結點的右兒子成為祖父結點的左兒子,下圖是一個例子:
相對于僅僅使用單旋轉,新實現方法的效率更高,使用新的旋轉方式,對1、2、3、4、5的單鏈表情況在5處展開的過程如下圖:
平衡二叉樹之紅黑樹
紅黑樹的定義:
紅黑樹是一種自平衡二叉查找樹,是在計算機科學中用到的一種數據結構,典型的用途是實現關聯數組。它是在1972年由魯道夫·貝爾發明的,稱之為"對稱二叉B樹",它現代的名字是在 Leo J. Guibas 和 Robert Sedgewick 于1978年寫的一篇論文中獲得的。它是復雜的,但它的操作有著良好的最壞情況運行時間,并且在實踐中是高效的: 它可以在O(logn)時間內做查找,插入和刪除,這里的n是樹中元素的數目。
紅黑樹和AVL樹一樣都對插入時間、刪除時間和查找時間提供了最好可能的最壞情況擔保。這不只是使它們在時間敏感的應用如實時應用(real time application)中有價值,而且使它們有在提供最壞情況擔保的其他數據結構中作為建造板塊的價值;例如,在計算幾何中使用的很多數據結構都可以基于紅黑樹。此外,紅黑樹還是2-3-4樹的一種等同,它們的思想是一樣的,只不過紅黑樹是2-3-4樹用二叉樹的形式表示的。
紅黑樹的性質:
紅黑樹是每個節點都帶有顏色屬性的二叉查找樹,顏色為紅色或黑色。在二叉查找樹強制的一般要求以外,對于任何有效的紅黑樹我們增加了如下的額外要求:
性質1. 節點是紅色或黑色。
性質2. 根是黑色。
性質3. 所有葉子都是黑色(葉子是NIL節點)。
性質4. 每個紅色節點必須有兩個黑色的子節點。(從每個葉子到根的所有路徑上不能有兩個連續的紅色節點。)
性質5. 從任一節點到其每個葉子的所有簡單路徑都包含相同數目的黑色節點。
設平衡二叉樹的深度為N,則N%2=0結點為黑色,N%2=1結點為紅色。
下面是一個具體的紅黑樹的圖例:
這些約束確保了紅黑樹的關鍵特性: 從根到葉子的最長的可能路徑不多于最短的可能路徑的兩倍長。結果是這個樹大致上是平衡的。因為操作比如插入、刪除和查找某個值的最壞情況時間都要求與樹的高度成比例,這個在高度上的理論上限允許紅黑樹在最壞情況下都是高效的,而不同于普通的二叉查找樹。
要知道為什么這些性質確保了這個結果,注意到性質4導致了路徑不能有兩個毗連的紅色節點就足夠了。最短的可能路徑都是黑色節點,最長的可能路徑有交替的紅色和黑色節點。因為根據性質5所有最長的路徑都有相同數目的黑色節點,這就表明了沒有路徑能多于任何其他路徑的兩倍長。
紅黑樹這段內容來自maybe2030?整理自wiki百科之紅黑樹的內容
B-樹(B-Tree)
B-樹和下面的B+樹是相當有用和比較重要的樹數據結構(B-樹和B樹的叫法是一樣的),B樹,概括來說是一個一般化的二叉查找樹,可以擁有多于2個子節點。與自平衡二叉查找樹不同,B-樹為系統最優化大塊數據的讀和寫操作。B-tree算法減少定位記錄時所經歷的中間過程,從而加快存取速度。這種數據結構常被應用在數據庫和文件系統的實作上。
B-樹的基本概念
B-樹也是一種平衡樹,稱為M路平衡查找樹(并不是二叉的,M=2就是平衡二叉查找樹),M稱為階數或度數或叉數或最多子樹數,指的是一個結點擁有最多的兒子數。上面一直提到關鍵字域,關鍵字用于確定結點的分布規則,又稱為鍵值,和數據庫表的主鍵和唯一鍵是一樣的。1個關鍵字最多有2個兒子,如二叉樹,M階平衡樹的關鍵字數為M-1,在B-樹的數據結構實現上,主要是使用關鍵字數M-1,可使用數組存儲,或設計其它的容器如鏈式數據結構,其中3階B樹又叫2-3樹,4階B樹又叫2-3-4樹,如下圖是一個3階B叉樹:
B-tree樹即B樹,B即Balanced,平衡的意思。因為B樹的原英文名稱為B-tree,而國內很多人喜歡把B-tree譯作B-樹,其實,這是個非常不好的直譯,很容易讓人產生誤解。如人們可能會以為B-樹是一種樹,而B樹又是另一種樹。而事實上是,B-tree就是指的B樹。
B樹的搜索,從根結點開始,如果查詢的關鍵字與結點的關鍵字相等,那么就命中;否則,如果查詢關鍵字比結點關鍵字小,就進入左兒子;如果比結點關鍵字大,就進入當前兄弟節點的右邊節點(二叉樹就是右節點)
B-樹的主要特性如下:
每個結點的兒子數為2~M,為什么不是至少1個?因為B樹的生長方向是自底向上,在分裂的時候不會造成只有1個兒子,為什么最大為M?因為階數為M為最大兒子數,其關鍵字數最大為M-1;
非根非葉子結點的兒子數為[M/2]~M,[]為向上取整,或使用ceil()函數,這個不用太注意,實際上只要你正確操作B樹不會發生異常的情況;
所有樹葉的深度都相同,這就是說B樹總是平衡的。
首先要指出,以上B-樹只是一個參考的規范并不是絕對標準,你可以根據自己的需求自己設計,這里的M一直指的都是每個結點的最大兒子數,而在我們的代碼中更直接的是使用關鍵字數,關鍵字數等于M-1,要注意是否混淆了。
B樹的主要數據存儲在所有結點上,和一般的二叉樹是一樣的,在二叉樹上一個關鍵字對應一個數據對象,B樹中H個關鍵字對應有H個數據對象,也就是說關鍵字和數據對象的數量是相同的。如果使用的是數據對象中的成員作為數據關鍵字,則在節點中可以直接聲明一個數據對象的數組存儲(或者其它類型的容器),否則自定義創建一個關鍵字數組,另外再創建數據對象數組,這樣會相當麻煩(實際可以在數據對象中創建虛擬關鍵字,在結點聲明)。
B-樹的搜索,從根結點開始,對結點內的關鍵字(有序)序列進行二分查找,如果命中則結束,否則進入查詢關鍵字所屬范圍的兒子結點;重復,直到所對應的兒子指針為空,或已經是葉子結點;
B樹的特性
定義任意非葉子結點最多只有M個兒子;且M>2;
根結點的兒子數為[2,M];
除根結點以外的非葉子結點的兒子數為[M/2,M];
每個結點存放至少M/2-1(取上整)和至多M-1個關鍵字;(至少2個關鍵字)
非葉子結點的關鍵字個數=指向兒子的指針個數-1;
非葉子結點的關鍵字:K[1],K[2],…,K[M-1];且K[i]
非葉子結點的指針:P[1],P[2],…,P[M];其中P[1]指向關鍵字小于K[1]的子樹,P[M]指向關鍵字大于K[M-1]的子樹,其它P[i]指向關鍵字屬于(K[i-1],K[i])的子樹;
所有葉子結點位于同一層;
B+樹(B+Tree)
B樹和B+樹的主要應用在于數據庫開發,例如MySQL的索引引擎就是使用B+樹實現的,如此看來,使用數據庫的目的除了數據持久化就是索引了,如果數據庫失去了索引功能,那么和一般的文件訪問也就區別不大了。說到數據庫,這里稍微討論一下相關的內容,數據庫文件是存儲在硬盤上的,程序訪問數據需要調用外設硬件去讀取硬盤上的數據,一次讀取操作稱為一次IO操作,IO操作是比較耗時的,因此提高數據訪問的速度也就是要降低IO操作的次數。
相對于物理磁盤而言,數據的最小單位為扇區,一般512字節,相對文件系統而言,一次IO操作讀取的數據大小目前可達到4K,也就是8個扇區。假如一個結點為4K,N個結點,最多深度為O(log N),底數為M/2,加入一個結點存儲200個關鍵字,一百萬個結點只需讀取幾次即可,而關鍵字的查詢速度也是對數時間O(log M),如此你可以發現使用B樹或B+樹的功能強大。
B+樹基本概念
B+樹和B樹的定義是等價的,其中有的定義是兒子數比關鍵字數小1,這個不是很重要,完全可以自定義。
B+的搜索與B-樹也基本相同,區別是B+樹只有達到葉子結點才命中(B-樹可以在非葉子結點命中),其性能也等價于在關鍵字全集做一次二分查找;
B+的性質:
1.所有關鍵字都出現在葉子結點的鏈表中(稠密索引),且鏈表中的關鍵字恰好是有序的;
2.不可能在非葉子結點命中;
3.非葉子結點相當于是葉子結點的索引(稀疏索引),葉子結點相當于是存儲(關鍵字)數據的數據層;
4.更適合文件索引系統。
B+和B樹不同之處
B+樹主要分為索引結點和葉子結點,索引結點為內部結點,主要用于存儲關鍵字,不再存儲數據,這樣一個索引結點的空間就小多了(一次IO操作可以讀取更多的關鍵字),葉子節點是數據記錄存儲的地方。索引結點中的關鍵字按升序排列。
B+樹每個葉子結點保存相鄰葉子結點的指針(雙向鏈表),這樣因為葉子結點中的關鍵字也是按升序排列的,那么B+樹不僅可以提供隨機訪問,還可以進行范圍訪問,因此使用B+樹實現索引引擎會比B樹更有優勢。
非葉子結點的子樹指針與關鍵字個數相同;
非葉子結點的子樹指針P[i],指向關鍵字值屬于[K[i], K[i+1])的子樹(B-樹是開區間);
為所有葉子結點增加一個鏈指針;
所有關鍵字都在葉子結點出現;
注意,只有葉子結點才存儲實際數據,MySQL的InnoDB引擎直接在葉子結點存儲數據本身,而MyISAM引擎則是在葉子結點存儲數據的邏輯地址,前者的方式稱為聚簇索引,后者稱為非聚簇索引,下面是這兩種索引結構的粗略圖:
B+樹的搜索與B樹也基本相同,區別是B+樹只有達到葉子結點才命中(B樹可以在非葉子結點命中),其性能也等價于在關鍵字全集做一次二分查找;
B*樹
B*樹是B+樹的變體,在B+樹的非根和非葉子結點再增加指向兄弟的指針,將結點的最低利用率從1/2提高到2/3。
B*樹定義了非葉子結點關鍵字個數至少為(2/3)*M,即塊的最低使用率為2/3(代替B+樹的1/2);
B+樹的分裂:當一個結點滿時,分配一個新的結點,并將原結點中1/2的數據復制到新結點,最后在父結點中增加新結點的指針;B+樹的分裂只影響原結點和父結點,而不會影響兄弟結點,所以它不需要指向兄弟的指針;
所以,B*樹分配新結點的概率比B+樹要低,空間使用率更高。
前綴樹(Tire樹)
Tire樹稱為字典樹,又稱單詞查找樹,Trie樹,是一種樹形結構,是一種哈希樹的變種。典型應用是用于統計,排序和保存大量的字符串(但不僅限于字符串),所以經常被搜索引擎系統用于文本詞頻統計。它的優點是:利用字符串的公共前綴來減少查詢時間,最大限度地減少無謂的字符串比較,查詢效率比哈希樹高。
Tire樹的三個基本性質:
根節點不包含字符,除根節點外每一個節點都只包含一個字符;
從根節點到某一節點,路徑上經過的字符連接起來,為該節點對應的字符串;
每個節點的所有子節點包含的字符都不相同。
Tire樹的應用:
前綴樹里面可以存一堆字符串,也可以說是一堆單詞,存完之后我們可以輕松判斷一個指定的字符串是否出現過。”比如說對于某一個單詞,我們要詢問它的前綴是否出現過。這樣hash就不好搞了,而用trie還是很簡單“。例如:給你100000個長度不超過10的單詞。對于每一個單詞,我們要判斷他出沒出現過,如果出現了,求第一次出現在第幾個位置。
串的快速檢索
給出N個單詞組成的熟詞表,以及一篇全用小寫英文書寫的文章,請你按最早出現的順序寫出所有不在熟詞表中的生詞。
在這道題中,我們可以用數組枚舉,用哈希,用字典樹,先把熟詞建一棵樹,然后讀入文章進行比較,這種方法效率是比較高的。
“串”排序
給定N個互不相同的僅由一個單詞構成的英文名,讓你將他們按字典序從小到大輸出。用字典樹進行排序,采用數組的方式創建字典樹,這棵樹的每個結點的所有兒子很顯然地按照其字母大小排序。對這棵樹進行先序遍歷即可。
最長公共前綴
對所有串建立字典樹,對于兩個串的最長公共前綴的長度即他們所在的結點的公共祖先個數,于是,問題就轉化為求公共祖先的問題。
關于算法相關的詳細代碼,查看github.com/zhoulujun/al
參考文章:
[Data Structure] 數據結構中各種樹 https://www.cnblogs.com/maybe2030/p/4732377.html#_label3
你真的懂樹嗎?二叉樹、AVL平衡二叉樹、伸展樹、B-樹和B+樹原理和實現代碼詳解 www.srcmini.com/1315.html
伸展樹(Splay Tree)進階 - 從原理到實現?https://www.cnblogs.com/dilthey/p/9379652.html#splay-2.1
二叉樹的遍歷(前序、中序、后序、已知前中序求后序、已知中后序求前序)?https://www.cnblogs.com/lanhaicode/p/10390147.html
js數據結構-二叉樹(二叉堆)https://segmentfault.com/a/1190000017761929
圖的基本概念,圖的遍歷、拯救007?https://www.cnblogs.com/hi3254014978/p/9535276.html
小白學數據結構——二、樹與堆(基本概念及二叉樹、二叉堆的python實現)?https://blog.csdn.net/qq_33414271/article/details/78506632
如果子結果編號為i,求其父節點編號?https://blog.csdn.net/qingmengwuhen1/article/details/51926409?utm_source=blogxgwz5
常見數據結構(二)-樹(二叉樹,紅黑樹,B樹)?https://segmentfault.com/a/1190000007173881
js 中二叉樹的深度遍歷與廣度遍歷(遞歸實現與非遞歸實現)?https://www.jianshu.com/p/5e9ea25a1aae
平衡二叉樹-AVL樹(LL、RR、LR、RL旋轉)?https://www.cnblogs.com/ybf-yyj/p/9513706.html
數據結構----樹及二叉樹的遍歷JS?https://blog.csdn.net/qq_43043859/article/details/101347877
https://www.cnblogs.com/guxuanqing/p/10540551.html
轉載本站文章《講透學爛二叉樹(二):圖中樹的定義&各類型樹的特征分析》,請注明出處:https://www.zhoulujun.cn/html/theory/algorithm/TreeGraph/8282.htmlulujun.cn/html/theory/algorithm/TreeGraph/8282.htm

)
)
學習筆記七——多層框架定位與智能等待)
?)



)










)