一、ElasticSearch介紹
ES是一款非常強大的開源搜索引擎,可以幫我們從海量的數據中快速找到我們需要的內容。
ElasticSearch結合kibana、Logstash、Beats,也就是elastic stack(ELK),被廣泛運用在日志數據分析,實時監控等領域。
ES負責數據 存儲、計算、搜索數據。
LogStash和Beats負責 數據抓取。
Kibana 是數據可視化組件。
Lucence是ES的底層開發,java語言搜索引擎類庫,是Apache公司頂級項目。
Lucence優勢:
- 易擴展。
- 高性能。(基于倒排索引)
缺點:
- 只限于java語言開發。
- 學習難度高,曲線陡峭。
- 不支持水平擴展。
于是在lucence的基礎上,ES優點:
- 支持分布式,可水平擴展。
- 提供restful接口,被任何語言調用。
什么是ElasticSearch?
一個開源的分布式搜索引擎,可以實現日志搜索,日志統計,分析等。
什么是ElasticSearch Stack(ELK)?
是以es為核心,logStash和beats負責數據抓取,kibana數據可視化的技術棧。
二、索引
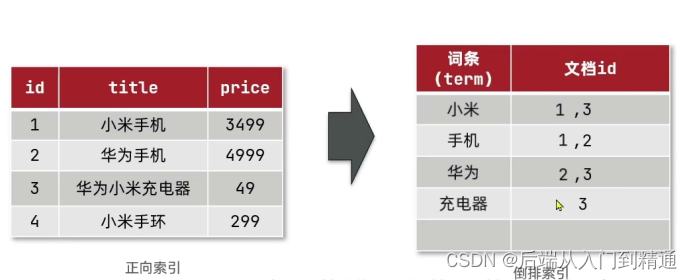
傳統數據庫采用 正向索引,而es采用 倒排索引。
如mysql采用正向索引,比如一個表里有id,這個自增id就屬于主鍵索引,也屬于正向索引,查詢非常快。
但如果查詢某個字段,這個字段叫title其中存儲著“明朝那些事”,這時候如果想查包含“那些”的title怎么查詢呢,即使title有索引,這時候用模糊查詢也會索引失效。
?
ElasticSearch采用倒排索引,倒排索引有兩個概念,文檔和詞條。
- 文檔(document):每條數據就是一個文檔。
- 詞條(term):文檔按照語義分成的詞語。
詞條的唯一性保證不會重復,對詞條創建索引。
查詢“華為手機”的過程:
- 先拆分這個搜索為詞條“華為”“手機”。
- 在倒排索引通過詞條創建的主鍵索引,快速找到“手機”對應id為1,2,“華為”對應id為2,3。
- 文檔id1,2,3可以查詢到對應的三條數據,通過聚簇索引快速查詢到結果集。
為什么叫倒排索引呢,因為平時數據庫我們是先通過id去找具體的值,而es的倒排索引我們通過次創建新的索引,所以先是去找值再找對應索引的具體值。
三、ES與mysql對比
文檔:
ElasticSearch是面向文檔存儲,可以是數據庫一條商品或者一個訂單信息。會被序列化成JSON格式存儲。
索引(index):
會把類型相同的索引放在一起,比如商品索引,用戶索引,訂單索引等。
- Mysql的table 對比與 es的索引index
索引就是文檔的集合,類似與數據庫的表。
- mysql的row對比與es的document
Document是json風格,row是一條條數據。
Mysql擅長事務,數據庫一致性和安全。
Es擅長海量數據搜索和計算。

—— Ajax 案例)

)





)


 研究(Matlab代碼實現))



)


霍夫線檢測+找出輪廓和外接矩形+改進旋轉)