關于緩存雪崩、擊穿、穿透的解決方案
- 前言
- 緩存雪崩
-
- 緩存雪崩的原因
- 解決方案
- 緩存擊穿
-
- 解決方案
- 緩存穿透
-
- 解決方案
-
- 布隆過濾器
-
- 布隆過濾器原理
- 布隆過濾器如何使用
- 在Java中使用布隆過濾器
前言
關于緩存異常,我們常見的有三個問題:緩存雪崩、緩存擊穿、緩存穿透。 這三個問題一旦發生,會導致大量請求直接落到數據庫層面。如果請求的并發量很大,會影響數據庫的運行,嚴重的會導致數據庫宕機。
為了避免異常帶來的損失,我們需要了解每種異常的原因以及解決方案,提高系統的可靠性。
緩存雪崩
緩存雪崩是指大量的應用請求無法在Redis緩存中進行處理,從而使得大量請求發送到數據庫層,導致數據庫壓力過大甚至宕機。
緩存雪崩的原因
第一個原因:同一時間緩存中的數據大面積過期。
具體來說,把熱點數據保存在緩存中,并且設置了過期時間,如果在某一個時刻,大量的Key同時過期,此時,應用再訪問這些數據的話,就會發生緩存缺失。然后應用就會把請求發送給數據庫,如果應用的并發請求量很大,(比如秒殺),那么數據庫的壓力也會很大,這會進一步影響到其他正常業務的請求處理。
如下圖所示: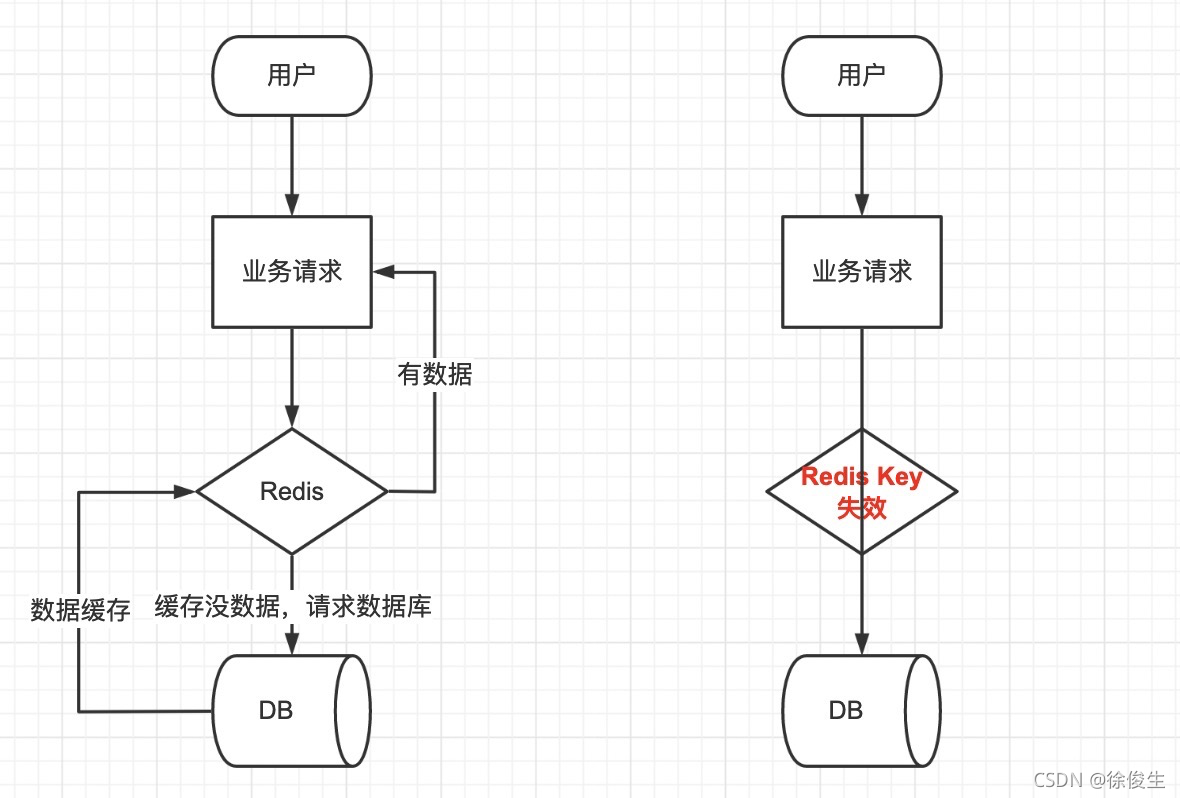
第二個原因:Redis 緩存實例發生故障宕機。
解決方案
1、解決熱點數據集中失效
針對大量數據集中失效帶來的緩存雪崩問題,可以用下面幾種方案解決:
- 均勻過期:給熱點數據設置不同的過期時間,給每個key的失效時間加一個隨機值;
- 設置熱點數據永不過期:不設置失效時間,有更新的話,需要更新緩存;
- 服務降級:指服務針對不同的數據采用不同的處理方式:
- 業務訪問的是非核心數據,直接返回預定義信息、空值或者報錯;
- 業務訪問核心數據,則允許訪問緩存,如果緩存缺失,可以讀取數據庫。
2、解決Redis實例宕機問題
方案一: 實現服務熔斷或者請求限流機制
我們通過監測Redis以及數據庫實例所在服務器負載指標,如果發現Redis服務宕機,導致數據庫的負載壓力增大,我們可以啟動服務熔斷機制,暫停對緩存服務的訪問。
但是這種方法對業務應用的影響比較大,我們也可以通過限流的方式降低這種影響。
舉個例子:比如業務系統正常運行時,請求入口每秒最大允許進入的請求數是1萬個,其中9000請求個可以被緩存處理,余下1000個會發送給數據庫處理。
一旦發生雪崩,數據庫每秒處理的請求突然增加到1萬個,此時我們就可以啟動限流機制。在前端請求入口處,只允許每秒進入1000個請求,其他的直接拒絕掉。這樣就可以避免大量并發請求發送給數據庫。
方案二:事前預防
通過主從節點的方式構建 Redis 緩存高可靠集群。 如果 Redis 緩存的主節點故障宕機了,從節點還可以切換成為主節點,繼續提供緩存服務,避免了由于緩存實例宕機而導致的緩存雪崩問題。
緩存擊穿
緩存擊穿和緩存雪崩有點像,但是也有一點區別。
緩存雪崩是因為大面積的緩存失效,打崩了數據庫。而緩存擊穿是指某個訪問非常頻繁的熱點數據,大量并發請求集中在這一個點訪問,在這個Key失效的瞬間,持續的大并發就穿破緩存,直接請求數據庫,就像在一個屏障上鑿了一個洞。
解決方案
- 設置熱點數據永不過期:不設置失效時間,有更新的話,需要更新緩存;
- 加互斥鎖:單機可以使用
synchronized、lock,分布式可以使用lua腳本。
關于分布式鎖有興趣的同學可以看下這篇:Redis分布式鎖的正確打開方式
緩存穿透
緩存穿透指用戶要訪問的數據既不在緩存中也不在數據庫中,導致用戶每次請求該數據時都要去數據庫查一遍,然后返回空。
如果有惡意攻擊者不斷請求這種系統不存在的數據,會導致數據庫壓力過大,嚴重會擊垮數據庫。
解決方案
- 接口層增加校驗:用戶鑒權、參數校驗(請求參數是否合法、請求字段是否不存在等等);
- 緩存空值/缺省值:發生緩存穿透時,我們可以在Redis中緩存一個空值或者缺省值(例如,庫存缺省值為0),這樣就避免了把大量請求發送給數據庫處理,保持了數據庫的正常運行。這種方法會存在兩個問題:
- 如果有大量的Key穿透,緩存空對象會占用寶貴的內存空間。針對這種情況可以給空對象設置過期時間。
- 設置過期時間之后,可能會有緩存與數據庫不一致的情況。
- 布隆過濾器:快速判斷數據是否存在,避免從數據庫中查詢數據是否存在,減輕數據庫壓力。
前面兩種方案比較好實現,接下面我們介紹下布隆過濾器。
布隆過濾器
布隆過濾器(Bloom Filter)是1970年由布隆提出的。它實際上是一個很長的二進制向量和一系列隨機映射函數。布隆過濾器可以用于檢索一個元素是否在一個集合中。
- 優點:空間效率和查詢時間都遠遠超過一般的算法。
- 缺點:有一定的誤識別率,刪除困難。
布隆過濾器原理
布隆過濾器本質上是一個初始值都為 0 的 二進制數組和 N 個哈希函數組成。
當我們想標記某個數據存在時(例如,數據x已被寫入數據庫),布隆過濾器會通過三個操作完成標記:
- 首先,使用 N 個哈希函數,分別計算這個數據的哈希值,得到 N 個哈希值。
- 然后,我們把這 N 個哈希值對 bit 數組的長度取模,得到每個哈希值在數組中的對應位置。
- 最后,我們把對應位置的 bit 位設置為 1,這就完成了在布隆過濾器中標記數據的操作。
如下圖所示: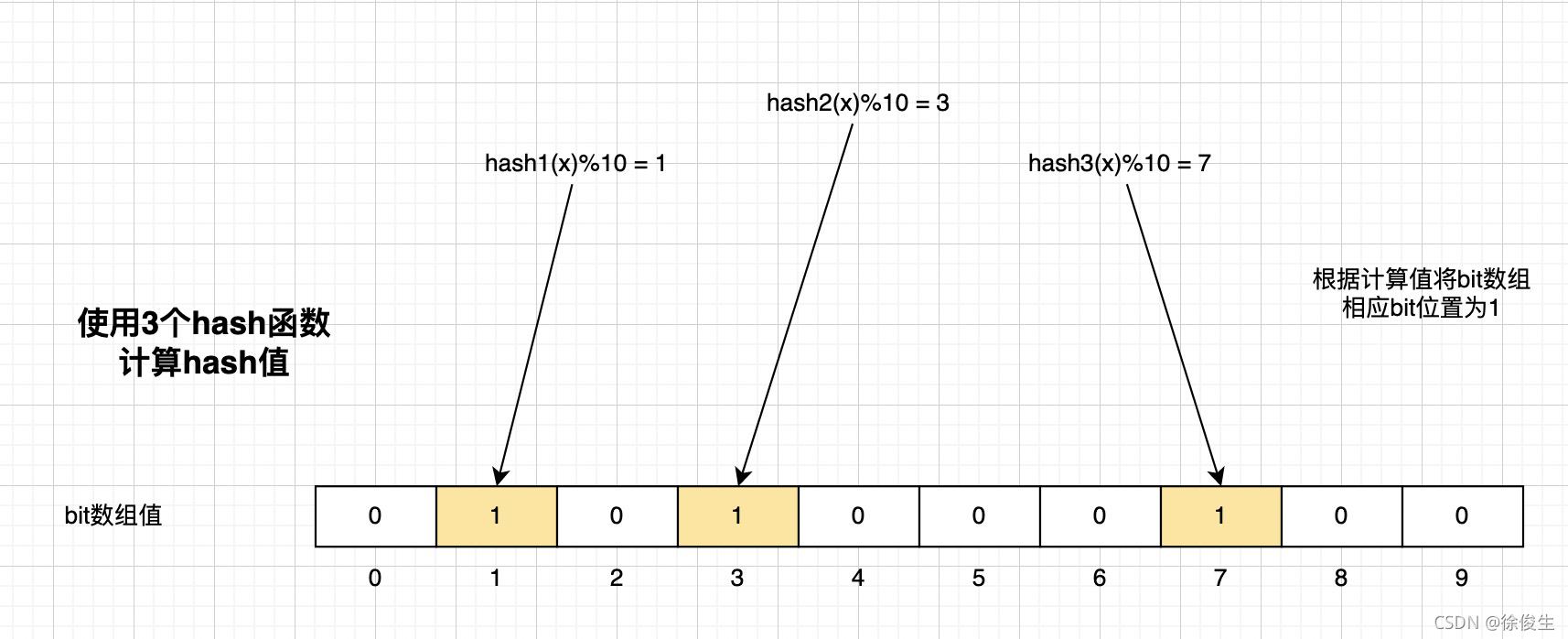
三次哈希,對應的二進制數組下標分別是 1、3、7,將原始數據從 0 變為 1。
同樣的,我們標記數據y的邏輯也是一樣的。如下圖: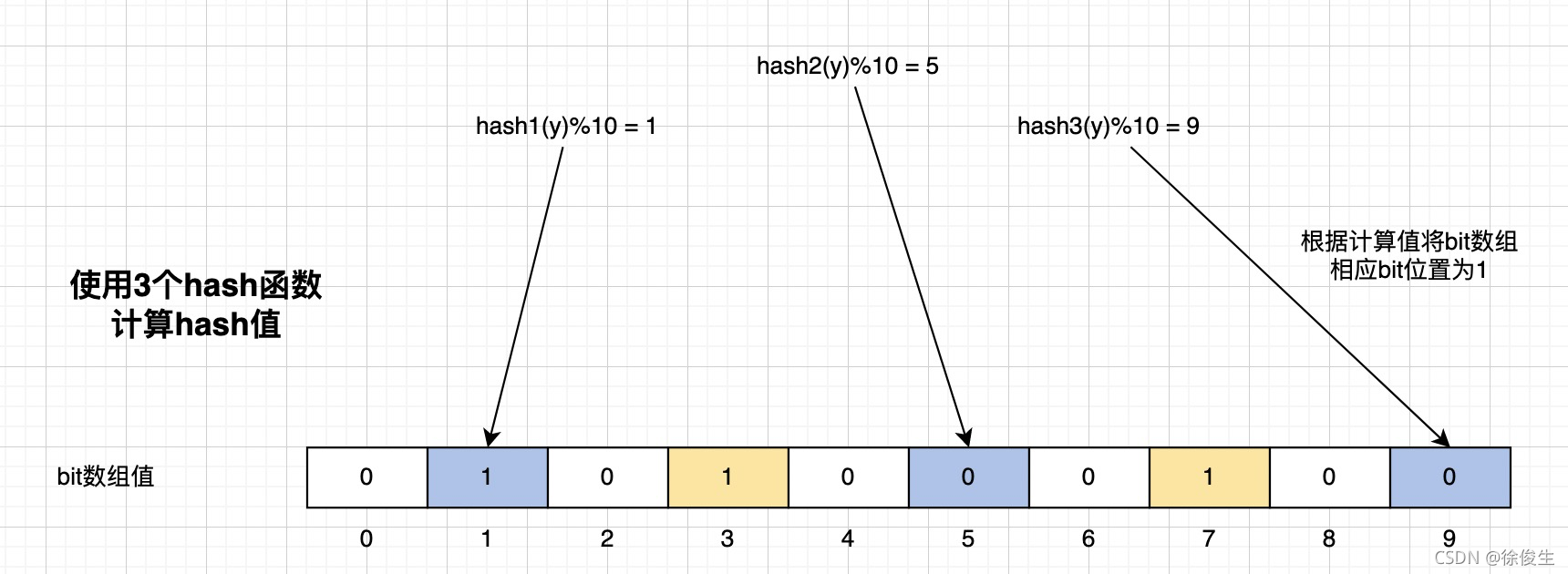
三次哈希,對應的二進制數組下標分別是 1、5、9,將原始數據從 0 變為 1。
下標 1,之前已經被操作設置成 1,則本次認為是哈希沖突,不需要改動。
Hash 規則:如果在 Hash 后,原始位它是 0 的話,將其從 0 變為 1;如果本身這一位就是 1 的話,則保持不變。
正是因為存在哈希沖突,導致布隆過濾器的判斷存在誤差。
因為哈希沖突的存在,導致布隆過濾器不能輕易刪除數據,存在誤刪的風險。
布隆過濾器減少誤差的方法:
- 增加二進制位數組的長度,這樣hash后的數據會更加離散化,出現沖突的概率會大大降低;
- 增加Hash的次數,變相的增加數據特征,特征越多,沖突的概率越小。
布隆過濾器如何使用
比如,當查詢一件商品的緩存信息時,我們首先要判斷這件商品是否存在。
- 通過三個哈希函數對商品id計算哈希值;
- 然后,在布隆數組中查找訪問對應的位值,0或1;
- 判斷,三個值中,只要有一個不是1,那么我們認為數據是不存在的。
如下圖: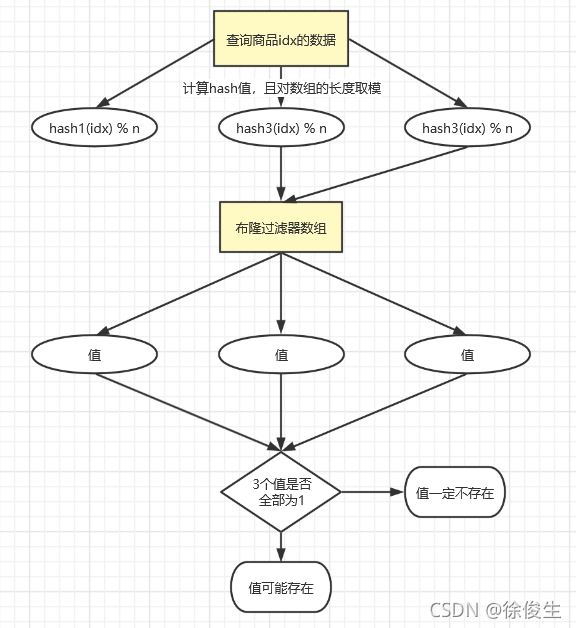
注意:布隆過濾器只能精確判斷數據不存在情況,對于存在我們只能說是可能,因為存在Hash沖突情況,當然這個概率非常低。
在Java中使用布隆過濾器
至于在Java應用中使用布隆過濾器,我們可以通過Redisson實現,它內置了布隆過濾器。
首先引入依賴:
<dependency><groupId>org.redisson</groupId><artifactId>redisson</artifactId><version>3.15.0</version>
</dependency>
代碼示例:
import org.redisson.Redisson;
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;public class RedissonBloomFilter {public static void main(String[] args) {Config config = new Config();config.useSingleServer().setAddress("redis://127.0.0.1:6379");RedissonClient client = Redisson.create(config);RBloomFilter<String> bloomFilter = client.getBloomFilter("test-bloom-filter");// 初始化布隆過濾器,數組長度100W,誤判率 1%bloomFilter.tryInit(1000000L, 0.01);// 添加數據bloomFilter.add("Shawn");// 判斷是否存在System.out.println(bloomFilter.contains("xujunson"));System.out.println(bloomFilter.contains("Shawn"));}
}運行結果:
false // 肯定不存在
true // 可能存在,有1%的誤判率
好了,以上就是關于緩存異常的整理。跟緩存雪崩、緩存擊穿這兩類問題相比,緩存穿透的影響更大一些,需要重點關注一下。
---------------------
作者:徐俊生
來源:CSDN
原文:https://blog.csdn.net/D812359/article/details/120648158
版權聲明:本文為作者原創文章,轉載請附上博文鏈接!
內容解析By:CSDN,CNBLOG博客文章一鍵轉載插件

:介紹)

JavaScript 互操作 —— 生命周期和內存泄漏)
)



控件和它的成員)







)

) is too old to check APIs compiled with API 26;)
