運維的演進
人力運維階段
在IT產業的早期,服務器運維是通過各種Ad Hoc命令或者Shell腳本來完成基礎設施的自動化工作,這種方式對于簡單,一次性的工作很方便,但是對于復雜和長期的項目,后期的腳本維護非常麻煩。

自動化工具階段
現時的大型互聯網公司都已經有了成千上萬臺服務器,對于這么龐大體量的服務器規模,以往那種原始的人工運維方式顯然已經過時,大規模服務器的自動化快速運維就成為了不得不探討的課題。
目前Salt,Chef,Puppet和Ansible等配置管理工具是運維界非常流行的工具,它們定義了各自的語法規則來管理服務器,這些工具定義的代碼和Ad Hoc腳本語言非常相似,但是它們強制要求代碼具有結構化,一致性,和清晰的參數命名,它們能夠遠程管理大量的服務器,并且兼容早期的Ad hoc 腳本。
DevOps階段
隨著自動化維護的相關工具層出不窮,有些大公司已經把它上升到了戰略層面,并引入了各種各樣的自動化工具與自己的業務系統進行組裝。

自動化運維平臺ACM平臺的建設
從傳統業務轉型互聯網的蘇寧隨著業務量的上升,服務器本身的標準化掃描,內核批量升級,在備戰雙11大促時,運維會接入大量系統擴容,配置,全局變量設定等等操作也逐漸變得常態化,動輒上千臺的主機運維的工作已經不是通過堡壘機系統就可以輕松完成了。
并且隨著不斷有PAAS業務系統提出需要各種可定制化,標準化的服務器配置管理部署接口。開發一個可以批量化配置管理服務器的通用平臺就變得迫切起來。
底層工具的選取
目前市場上最主流的開源工具有
Puppet/Chef/Ansible/Saltstack四種,選型時在github的熱度排名如下:

而在實際開發的選取時優先會考慮以下兩點:
- 第一、語言的選擇(Puppet/Chef vs Ansible/Saltstack)
Puppet、Chef基于Ruby開發,Ansible、Saltstack基于Python(后期可做二次開發),所以拋棄較為老舊并且兼容性較差的Puppet和Chef - 第二、速度的選擇 (Ansible vs Saltstack)
運維的配置管理講究的是更快更穩,Ansible基于SSH協議傳輸數據,Saltstack使用消息隊列zeroMQ傳輸數據。
在Ansible、Saltstack的選擇中,有一些公司放棄Saltstack的主要原因是Saltstack需要安裝客戶端,在服務器有一定數量的情況下比較麻煩,而Ansible不需要安裝客戶端。但是目前的Ansible還存在以下難以解決的問題:
- 眾口難調:和業務特點相關的需求十分離散(有的重效率,有的看重流程的完備性,有的對易用性要求高)再加上需求方越來越多,沒有合適的通用開放性接口提供 restful API,功能交付的排隊會積壓嚴重。
- 性能差:當需要執行一個服務器數量級達到 K 級操作,Ansible的響應長達數十分鐘,并且還有比較高的錯誤率。
反觀SaltStack,它結合輕量級消息隊列(ZeroMQ)與Python第三方模塊構建。具備了配置管理、遠程執行、監控等功能,具有以下明顯的優勢:
- 速度極快
- 兼容性好
- 文檔詳細,并且開源社區跟Ansible一樣持續活躍
速度測試
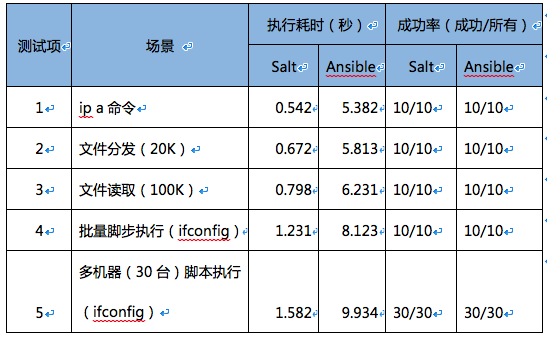
從表格中可以看出Ansible和SaltStack性能測試中,測試了Ansible和SaltStack在執行命令、分發文件、讀取文件和批量腳本執行等自動化運維場景下的性能,由耗時數據可以看出Ansible的響應速度比SaltStack要慢10倍左右。
經過的綜合論證考量,最終選擇了在大規模集群下,適用性最強的SaltStack作為蘇寧所有服務器的基礎管理工具。
使用穩定性的維護
由于早期版本的Saltstack的穩定性不高,各種版本之間也有兼容性問題,為了保證版本升級時保持可以向下兼容,團隊進行大量的驗證和測試后會把發現的bug向社區報告,經過不斷的溝通與協商,最終得到社區的認可并接受我們提出的修改建議,目前團隊也積極的參與新版本Salt的檢證測試與維護,有力的保障底層平臺的穩定性。
通用外部接口及WEB平臺的建設
由于Saltstack社區并沒有提供WEB管理界面,所有的操作都只能通過命令行操作,而API的調用也會暴露出用戶名密碼給外部系統,Master的安全性得不到保障。并且腳本的維護升級都十分的麻煩。
所以在選定底層管理工具后還需要開發一套ACM上層平臺,包裝出通用的接口對外提供服務,并且提供可視化的操作界面提供給主機運維團隊。
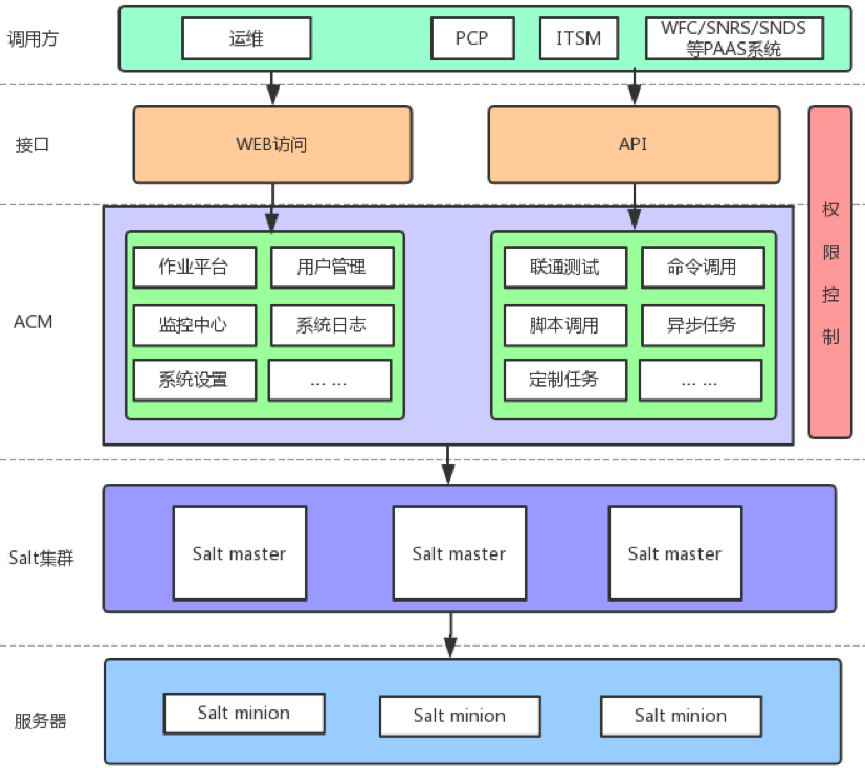
ACM提供了一套WEB系統供運維管理人員進行可視化的運維管理。實現了頁面化的腳本工具定義, 作業編排,作業執行,命令執行,報表分析等功能。
外部系統則可以通過ACM開放的API接口實現對底層Salt的調用,從而實現對安裝有Salt Minion Agent的機器進行配置管理。
并且在安全的設計上,平臺提供審計,命令黑名單,通道管理,Agent配置、用戶角色權限管理,并且僅允許授權過的外部系統接入ACM。
系統架構的演進
架構1.0
早期采用Order Master + Syndic+Minion的三層架構模式,當時全蘇寧的OS虛機+物理服務器總數大概在1萬左右,Salt的原生架構還能勉強支撐。
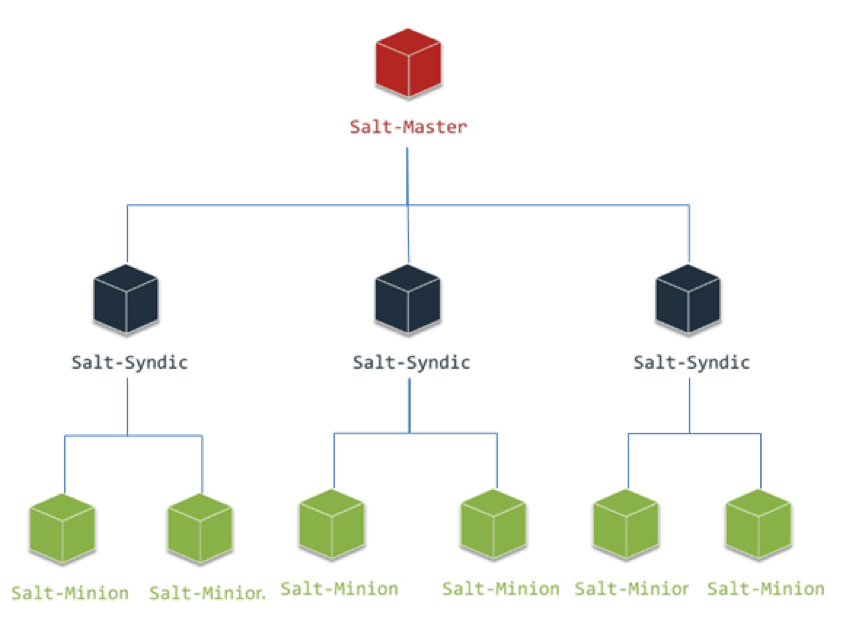
但隨著集團轉型的持續進行,線上業務量的急速上升,大促前上線的服務器數量也以近乎每天一千臺的速度上升,接入ACM的系統也從僅有的兩三個,每天幾百個總請求量,快速上升到幾十個系統,一天有近萬個配置任務;此時系統的問題也逐步暴露出來,比如任務返回慢,一個同步任務執行需要5秒以上的調用時間;原生架構下Order Master在并發任務量大時,系統壓力過高,任務失敗率也超過10%
團隊每天都花費大量時間應對客戶苦不堪言,業務方也是經常提出抱怨,由于業務量提升的倒逼,Salt-Minion又是集團默認的唯一基礎運維Agent,除了我們沒有人可以承擔下自動化配置管理的工作。于是乎ACM進行了整個系統的重新設計。
架構2.0-兩層化拆分
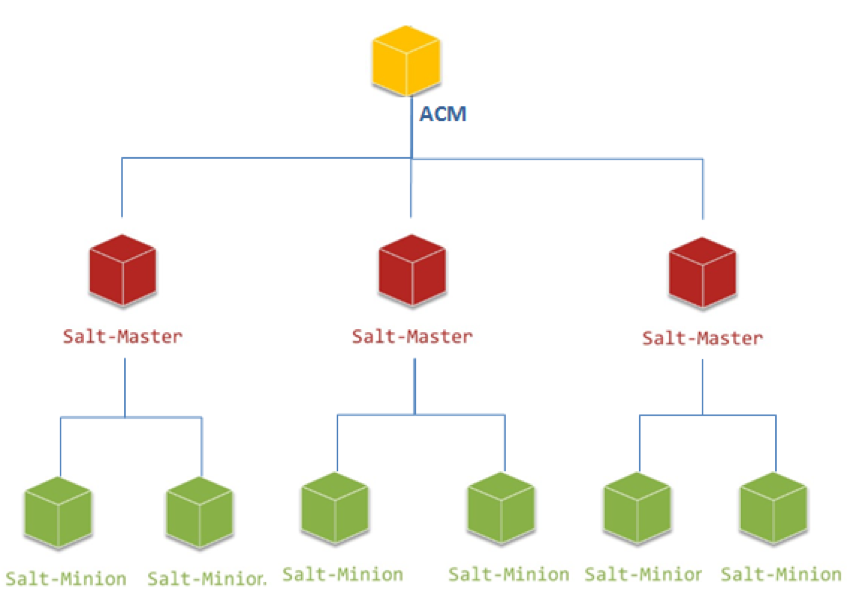
經過反復研究跟論證,ACM可以改造成直接充當Order Master的角色,對服務器發起配置任務時,ACM可以通過安裝記錄直接查詢到Minion掛載在哪臺Master上,直接對需要的Master發起調用,任務如果是多臺機器,后期也通過ACM進行結果的聚合。
由于ACM本身就是JBoss集群,這樣做不僅解決了單臺Order Maser負擔太重的問題,還大大加快了請求的響應時間,從原來的五秒+響應提升到了毫秒級響應,解決了原生架構中官方必須開銷的Syndic等待時間。
架構2.1-Salt Master的高可用化
在實際生產環境中如果發生了某一臺Salt Master宕機的情況,就會有約2K的機器失去控制,人工的進行Master恢復長達幾十分鐘,對于一些業務的調用是不可以接受的。
所以Master迫切的需要進行高可用化的改造,而改造的過程中又需要解決以下幾個問題:
- Minion如何探測到Master宕機,并進行快速切換。
- 當Minion探測到主Master宕機后如何切換到備Master。
- 如何解決主備Master之間Salt-key復制的問題,尤其是當主Master關聯新的Minion,新Minion的Salt-key如何同步給備Master。
方案1
采用Saltstack原生的高可用方案,Mutil-Master+Failover-Minion。
Mutil-Master: Saltstack從0.16.0版本開始支持,提供Minion可以連接多Master的功能特性.
Failover-Minion: Minion定期檢測Master的可用性,當發現Master不可用時,則在一定時間切換到備用Master上。
主要的配置項如下:
# multi-MasterMaster: - 10.27.135.188 - 10.27.135.189# 設置為failover Minion Master_type: failover # 探測Master的間隔,單位為秒Master_alive_interval: \u0026lt;seconds\u0026gt; 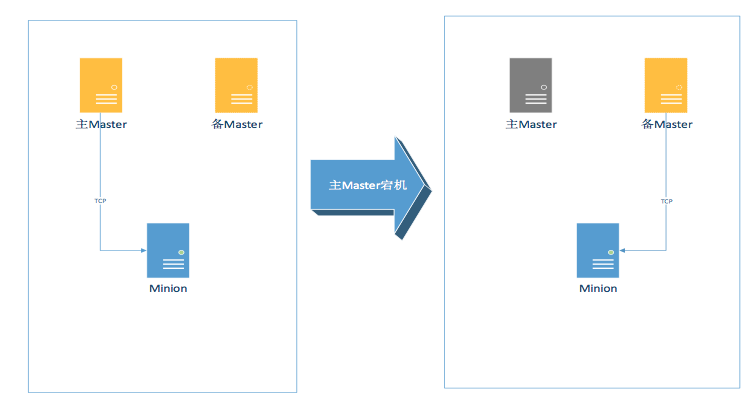
該方案的優點是基于SaltStack原生的高可用支持,不需別的組合方案進行支撐,理論上可以實現Master的高可用,但是經過實際的驗證和測試,存在一些明顯的不足:
- Minon在啟動的時候會隨機連接一臺Master,假如此時連接的Master恰好宕機,Minion不會再隨機選擇另外一臺Master,從而導致連接失敗的情況。
- Minion 檢測間隔,根據Master_alive_interval的設置時間,Minion會主動對現有的Master進行TCP連接一次檢查,查看Master是否響應。如果探測間隔設置過長,則可能影響到切換的時效;如果探測間隔設置過短,在大規模服務器場景下,則在短時間內產生過多的網絡請求,對Master主機以及網絡帶寬產生巨大沖擊,相當于一次DDOS攻擊。
- 假如需要更換Master的IP或者追加新的Master的IP,則需要對該Master下的所有的Minon進行配置變更,更恐怖的是Minion需要重啟才能生效。
- Salt-key同步沒有提供解決方案。
方案2
經過不停實驗,發現Master可以通過由Keepalived維護的VIP對外提供Salt服務,平時VIP綁定在主Master,當主Master宕機時VIP漂移至備Master,主備Master通過lsyncd共享Salt-key文件。
**注:Keepalived軟件主要是通過VRRP協議實現高可用功能的。VRRP是Virtual Router RedundancyProtocol(虛擬路由器冗余協議)的縮寫,VRRP出現的目的就是為了解決靜態路由單點故障問題的,它能夠保證當個別節點宕機時,整個網絡可以不間斷地運行。
所以,Keepalived 一方面具有配置管理LVS的功能,同時還具有對LVS下面節點進行健康檢查的功能,另一方面也可實現系統網絡服務的高可用功能。**
在實際運行時,Minion會主動向Master(VIP)發起注冊,每5分鐘檢測一次跟Master的TCP連接,如果連接被沖斷則重新發起TCP握手,建立TCP長連接;當主Master發生宕機,Keepalived檢測到后將VIP漂移至備用Master,Minion最多在5分鐘后將向備用Master的VIP發起TCP連接請求,并重新掛起長連接,等待Master發起任務。
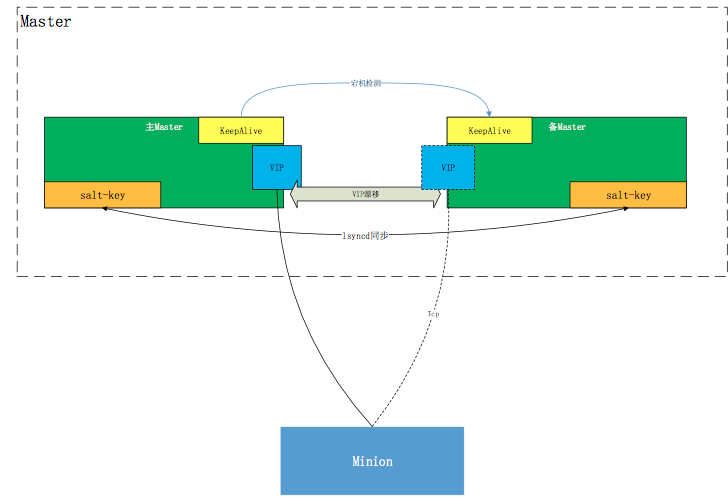
該方案的需要安裝額外的軟件對高可用進行支撐,由Keepalived對Master進行宕機檢測,由lsyncd保證Salt-key的實時同步。這樣做的好處是可以避免的方案1的諸多不足。首先,Minion端識別到的是虛擬的Master的IP地址,所以Master底層的IP地址的變化對Minion端是無感知的,Minion既不需要更改配置也不需要重啟;其次,Keepalived的檢活機制是對本網段內的D類地址進行檢測,并設置了唯一的虛擬路由ID,檢測間隔控制在5秒以內,所以不會對集團網絡造成沖擊;最后由lsyncd對Salt-key進行同步,既保證了安全性,又避免了多個Master之間Salt-key同步的問題。
至此,通過以上的混合解決方案,成功的實現的Salt Master宕機自檢測自動遷移的高可用方案,目前新港環境下的服務器已經全部由采用高可用架構的Salt集群接管。

總結
現在的ACM已經基本滿足集團在日常以及大促的批量規模調用。
- 目前ACM已經最大支持K級服務器的同步調用。
- ACM同步簡單任務的調用平均開銷時間約200ms。
- 平臺日均調用量已經接近50萬次。
- 請求成功率99.99%。
展望
隨著系統可靠性得到保障,接入系統和調用量將會越來越高,以后怎么應對日均百萬,千萬級的任務調用也提上日程。
未來的AIOps對ACM這種基礎配置服務平臺也會提出的更高要求,因為當指揮監測系統在采集決策所需的數據,做出分析、決策后,ACM則需要擔當起執行動作的工具,利用自動化腳本/命令去執行AI大腦的決策。
目前Saltstack已經管理了十五萬+的服務器,當Salt調用失敗時,?可能是因為機器本身宕機、防火墻限制,七層網絡不通、系統負載過高、磁盤滿了等等各種,這些原因會造成Salt調用失敗,我們希望提前對Salt故障問題作出預警,并能夠智能的定位問題和解決問題。
而目Salt在批量執行時也有一定的概率產生任務結果的丟失,因為所有任務的返回結果時都需要客戶端主動推回服務器,在批量任務大時,少數機器的返回結果會丟失。
這些課題我們后續也將繼續研究,探索!
作者簡介
徐洋,十年高可用Linux集群、服務器虛擬化建設經驗,現為蘇寧易購IT總部技術經理。擅長Linux服務器故障診斷與排除,在數據同步、SHELL腳本、Linux系統安全等方面有深入研究,精通服務器集群配置管理的自動化、高可用化技術。











創建線程最大個數)



)



