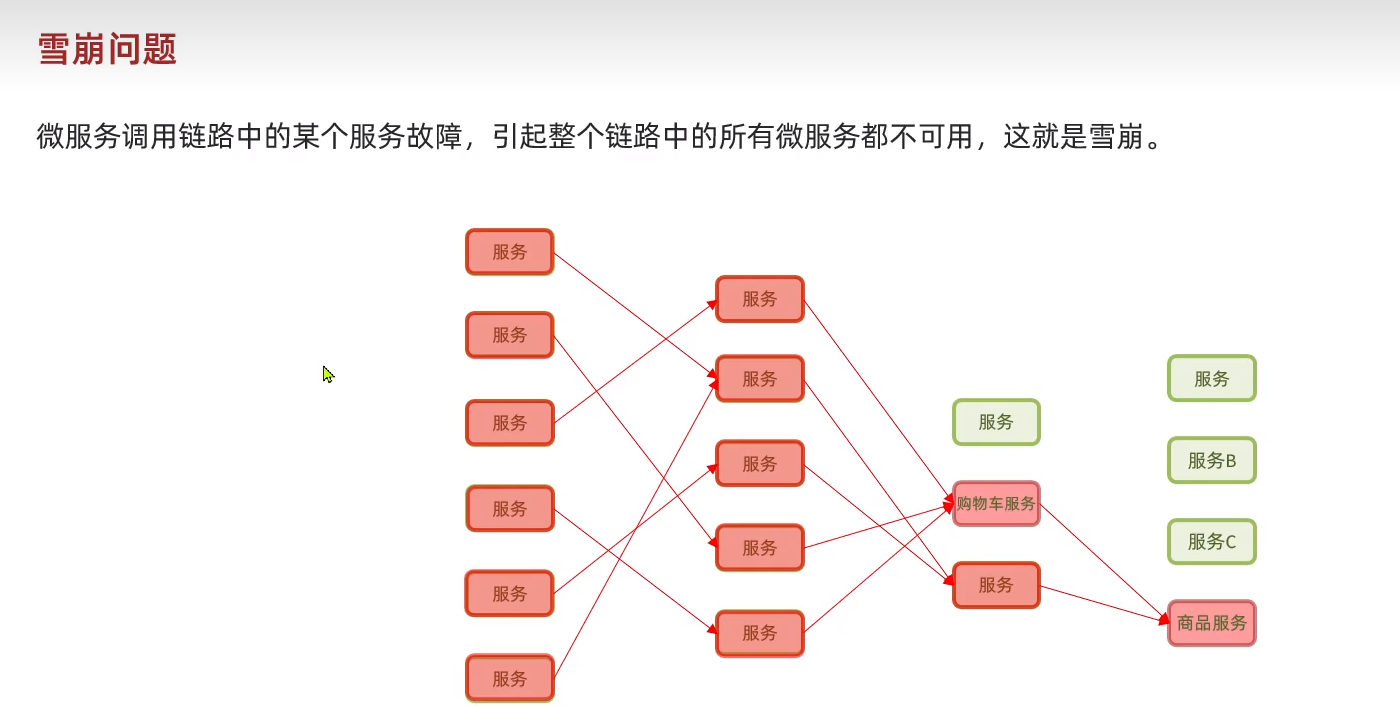
雪崩問題
在單體項目里面,如果某一個模塊出問題會導致整個項目都有問題。
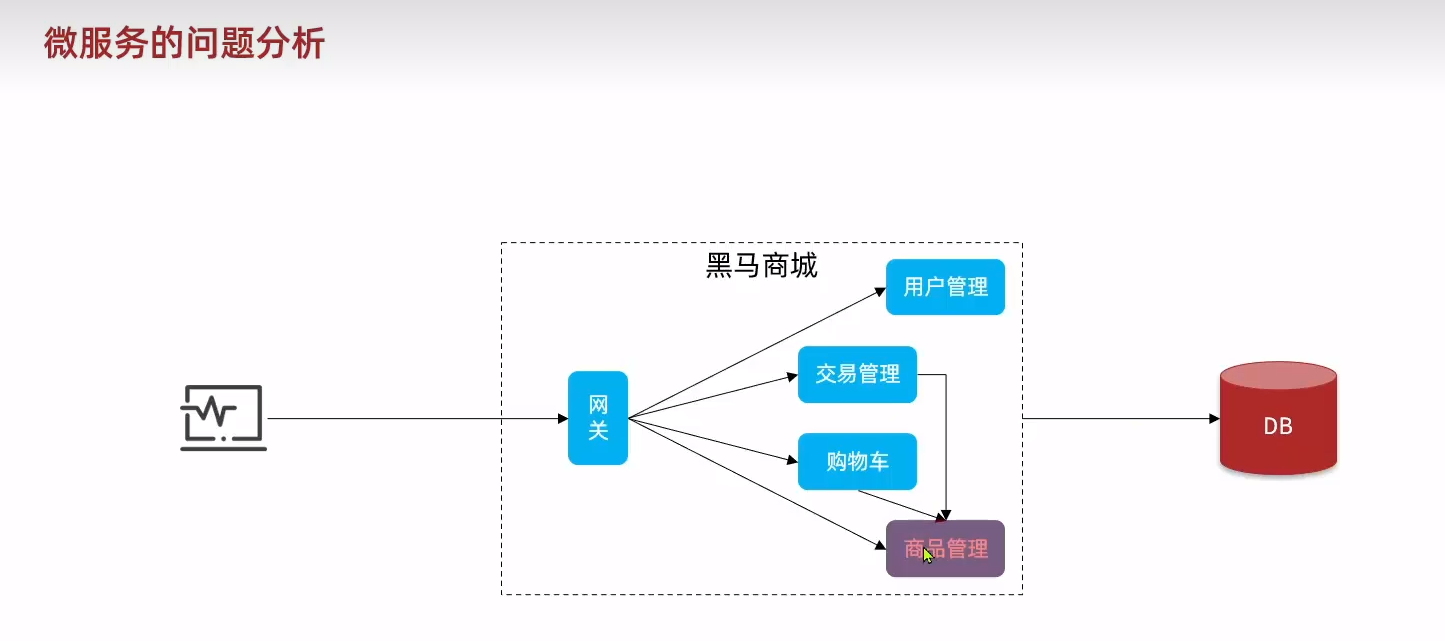
在微服務項目里面,單獨一個服務出問題理論上是不會影響別的服務的。?但是如果有別的業務需要調用這一個模塊的話還是會有問題。??
問題產生原因和解決思路
最初那只是一個小小的故障。后來隨著調用的服務越來越多,然后等待時消耗完了系統資源,然后就集體蹦了。

解決方案
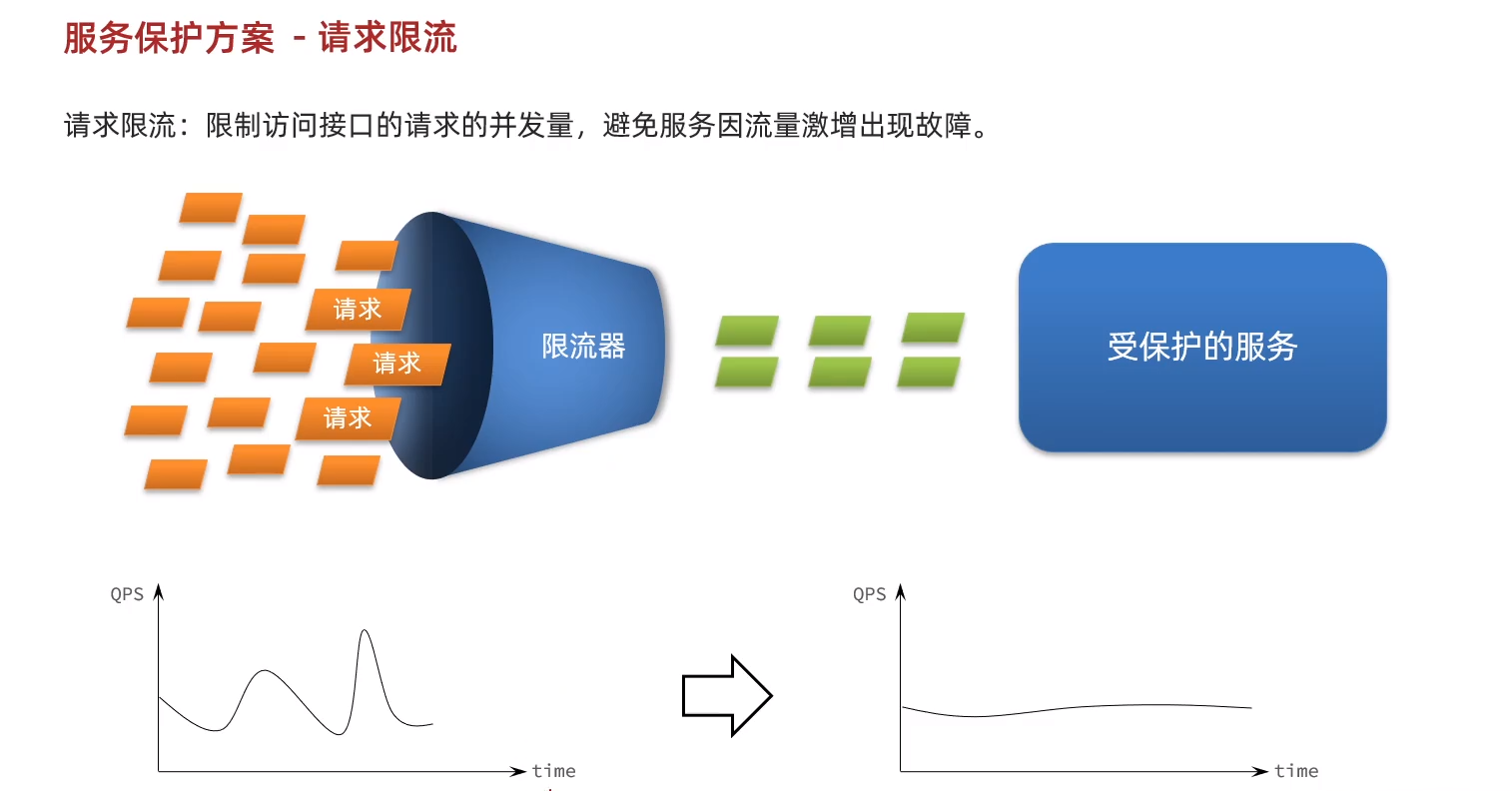
高并發引發的問題可以通過限流解決.
請求限流用于避免服務故障。
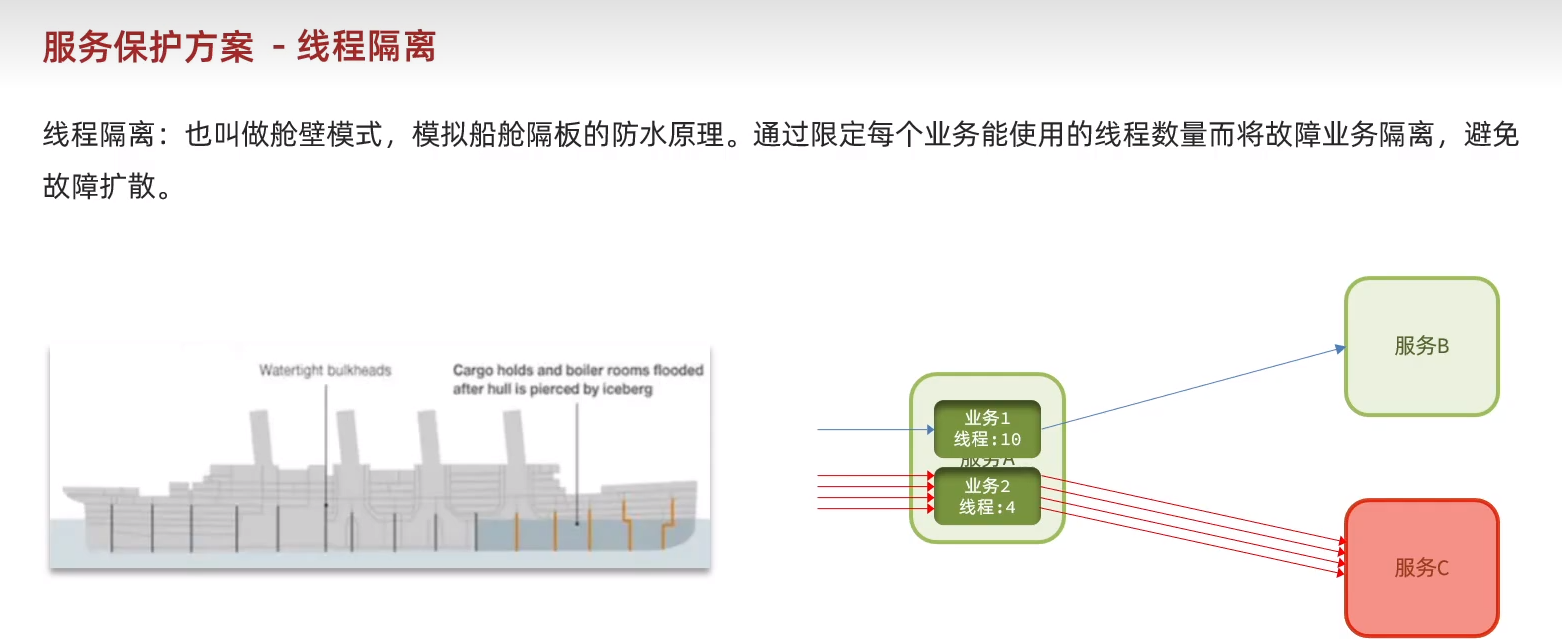
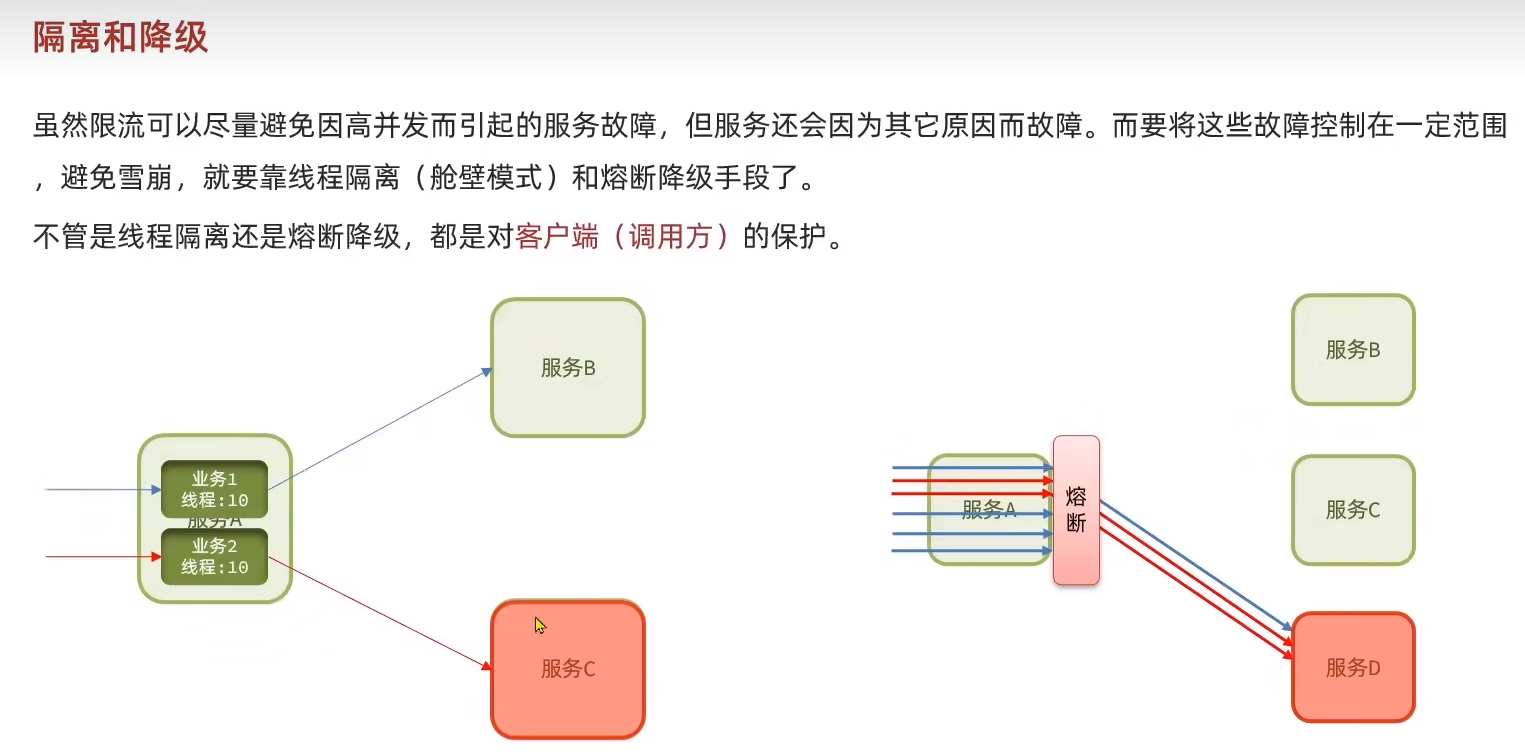
線程隔離用于避免故障擴散.限制了線程數之后這個服務就不會因為調用別的服務導致自身資源消耗殆盡。
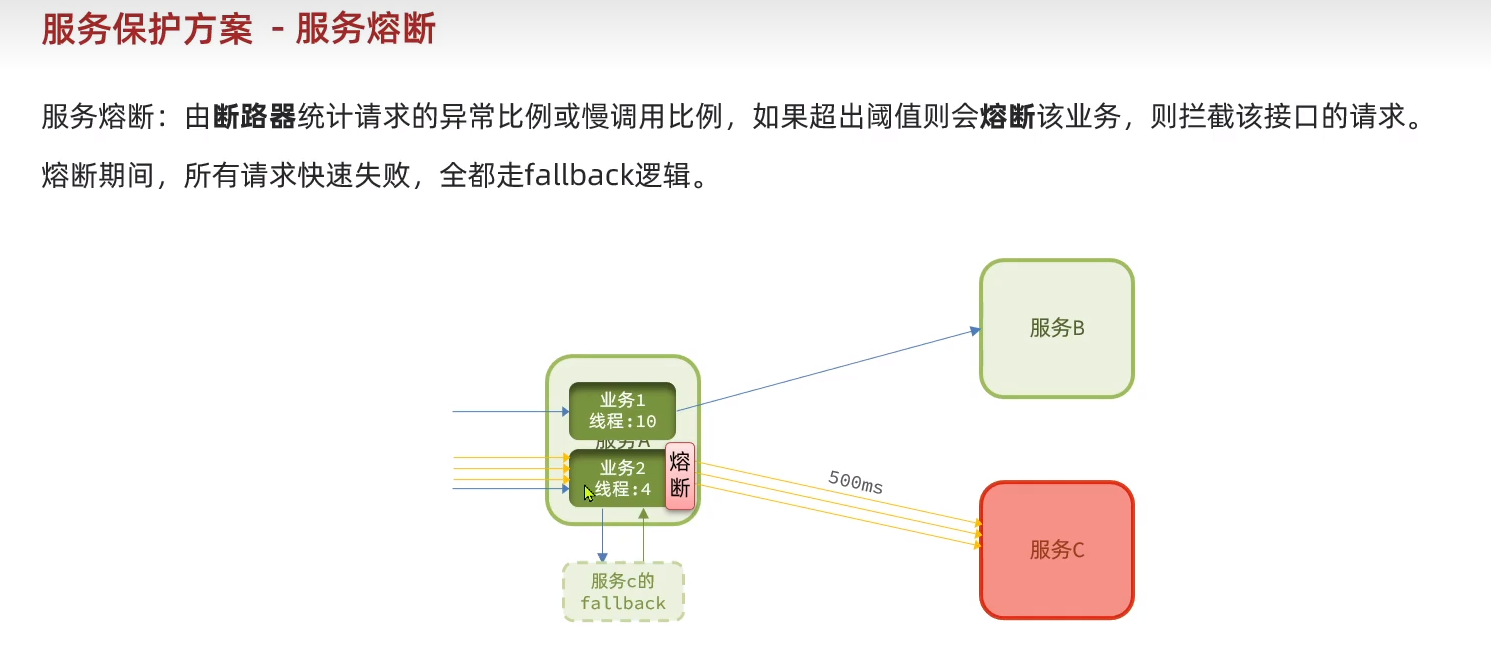
 ?為了防止線程資源一直被占用,這里還要做一個服務熔斷,讓出線程給別的服務。
?為了防止線程資源一直被占用,這里還要做一個服務熔斷,讓出線程給別的服務。
發生熔斷時直接走提前編寫的fallback邏輯。這個就是服務降級。舍棄一部分保證整個微服務群的健康。

技術實現

Sentinel
初識sentinel
可以在控制臺去配置限流規則,熔斷規則等等。

Sentinel 的使用可以分為兩個部分:
-
核心庫(Jar包):不依賴任何框架/庫,能夠運行于 Java 8 及以上的版本的運行時環境,同時對 Dubbo / Spring Cloud 等框架也有較好的支持。在項目中引入依賴即可實現服務限流、隔離、熔斷等功能。
-
控制臺(Dashboard):Dashboard 主要負責管理推送規則、監控、管理機器信息等。
?利用給好的jar包,在命令行用如下命令啟動
java -Dserver.port=8090 -Dcsp.sentinel.dashboard.server=localhost:8090 -Dproject.name=sentinel-dashboard -jar sentinel-dashboard.jar訪問http://localhost:8090頁面,就可以看到sentinel的控制臺了:

需要輸入賬號和密碼,默認都是:sentinel
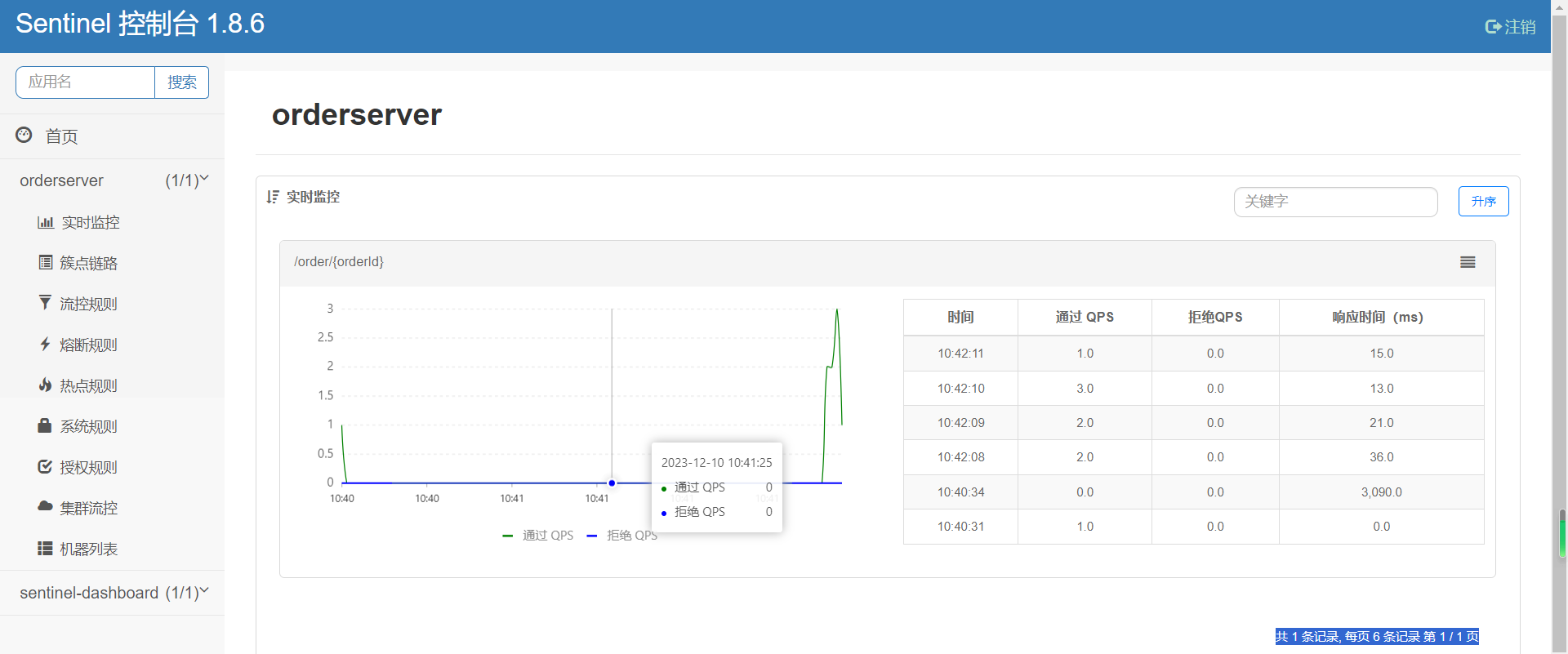
登錄后,即可看到控制臺,默認會監控sentinel-dashboard服務本身:

 ?
?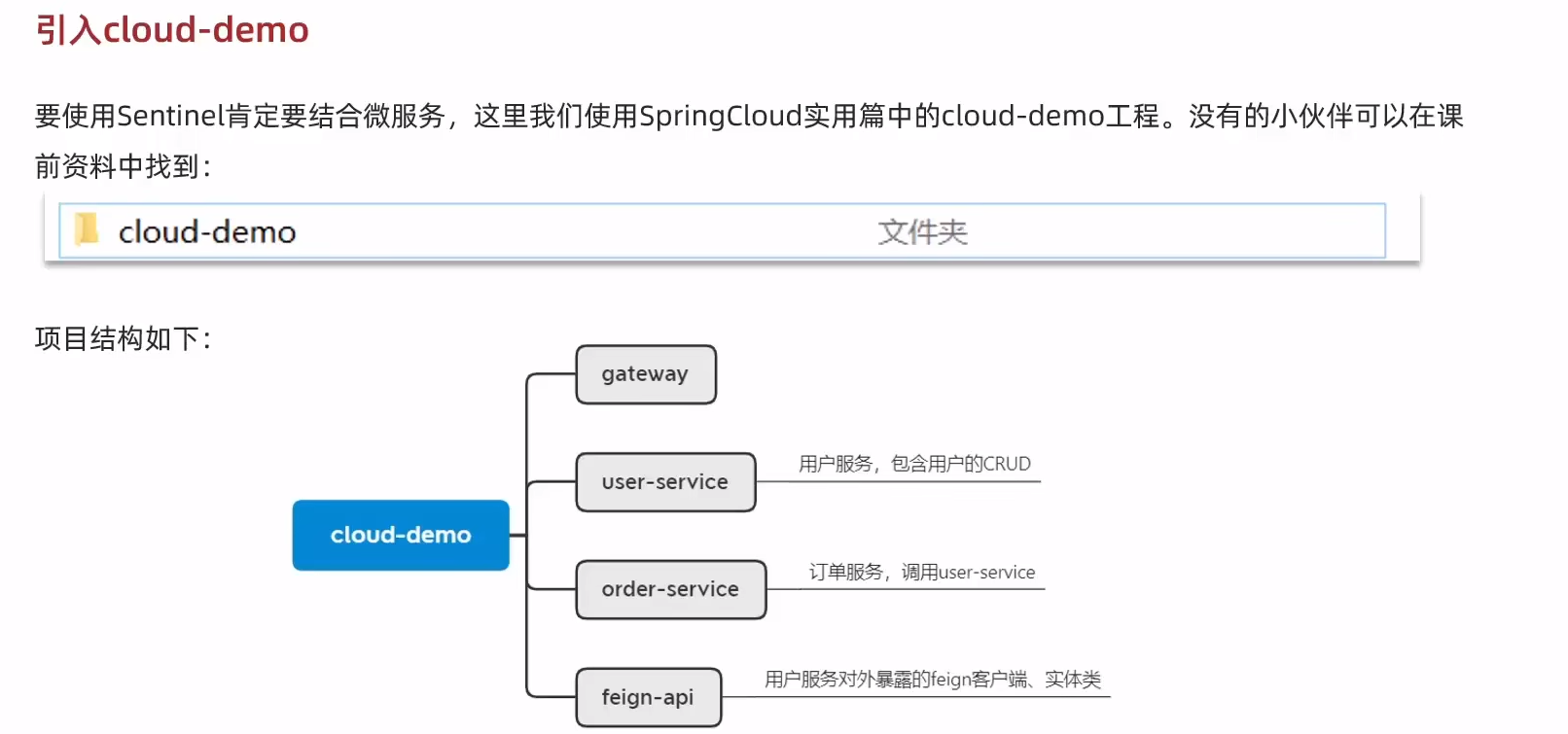
微服務整合

訪問一次之后,就可以順利被監控了。?

docker部署
拉取鏡像
docker pull docker.io/bladex/sentinel-dashboard創建容器
docker run --name sentinel -d -p 8858:8858 -d 鏡像id
然后剩下的就是改改ip+端口,都是和上面一樣的使用方法。
這個東西應該就是讓微服務自己把自己的狀況快照發送到sentinel,然后由sentinel根據定義的規則決定是否限流熔斷等等。不是由sentinel主動發起監控,不然云服務器里面的sentinel怎么可能監控的到我本地的運行項目。
tmd,搞錯了。這個玩意沒辦法從云端監控我的本地項目,只有第一次是本地項目主動發起的。剩下的都是要由sentinel發起監控.
請求限流
快速入門
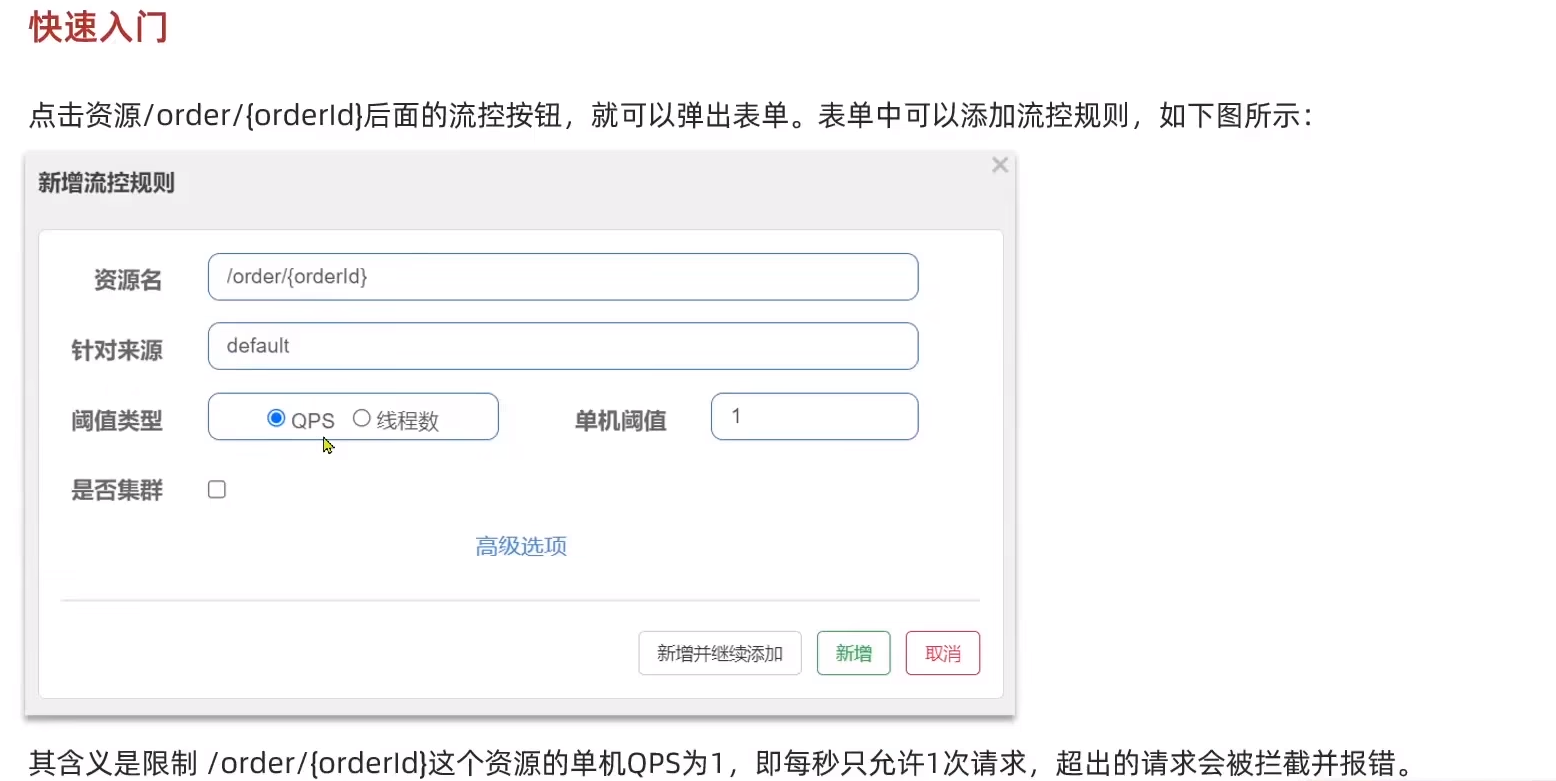
可以看見,設置每秒一條之后,多出的請求會被sentinel攔截。?
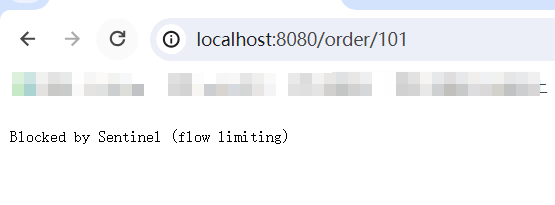
添加一個每秒10的閾值之后使用jmeter進行50條線程2s內跑完的任務進行壓力測試。
結果無誤,2s內只有20條請求正常響應,剩下的全都被異常處理了。
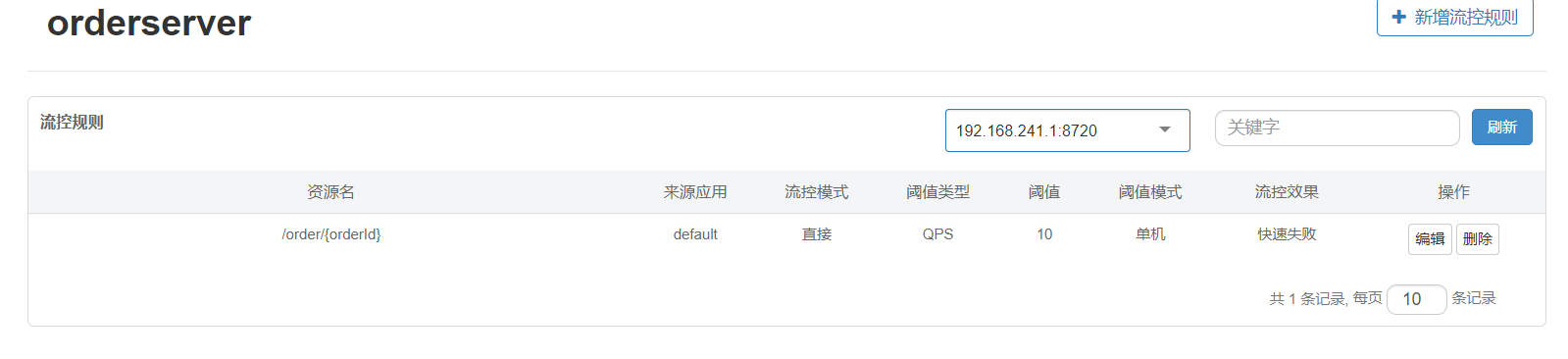

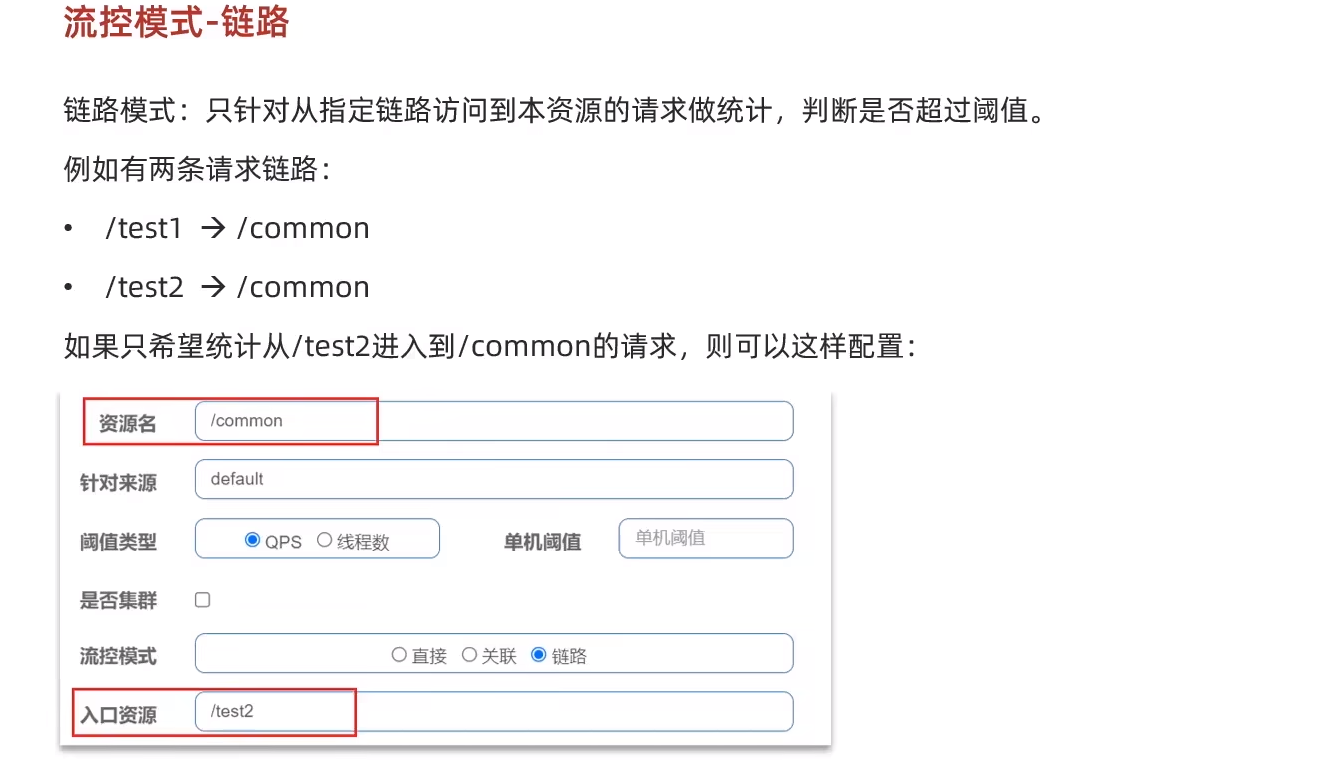
流控模式

關聯?
關聯模式:這個模式是在某兩個業務差不多同時發生時,通過限流其中一個業務的方式為另一個業務讓行。?

 ?然后給query加流控規則,當update1s超過5個請求時對query限流。
?然后給query加流控規則,當update1s超過5個請求時對query限流。
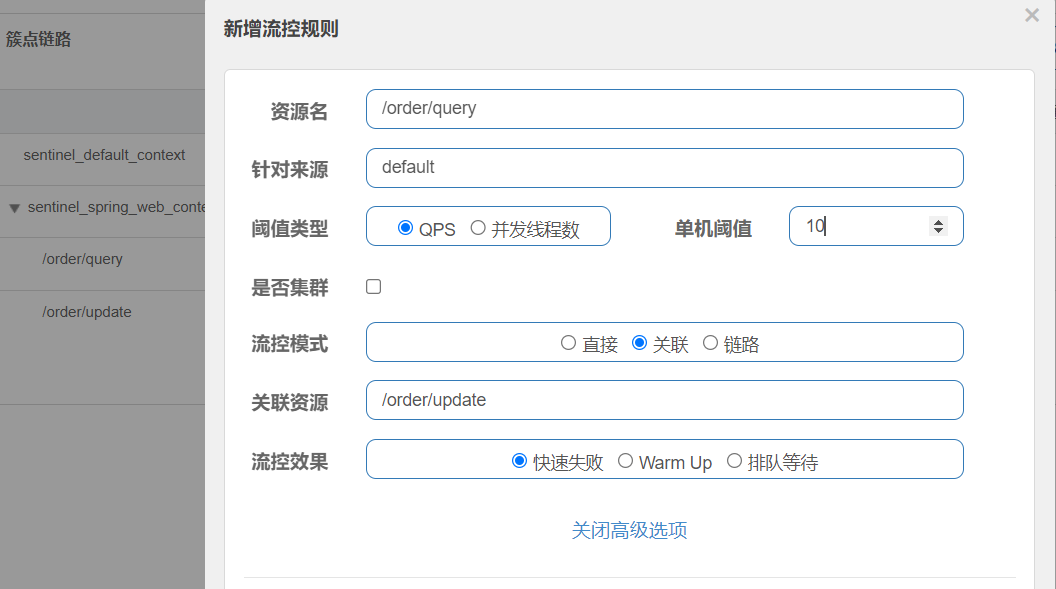
jmeter測試,1000個線程100s執行完,也就是每秒10個請求.? 可以的看見query被限流了。

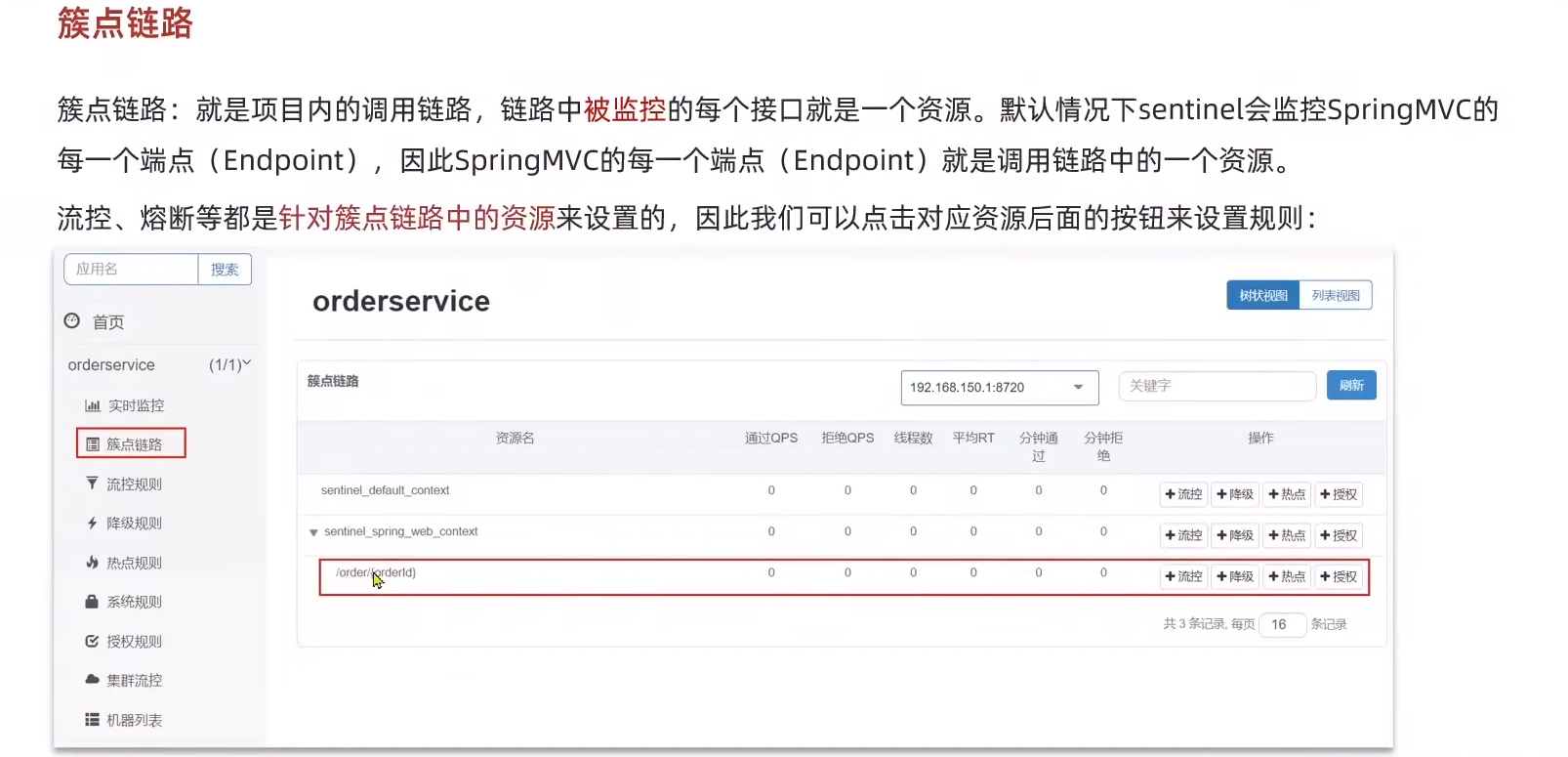
鏈路

sentinel默認只會監控controller的資源,所以要用到sentinel的注解。
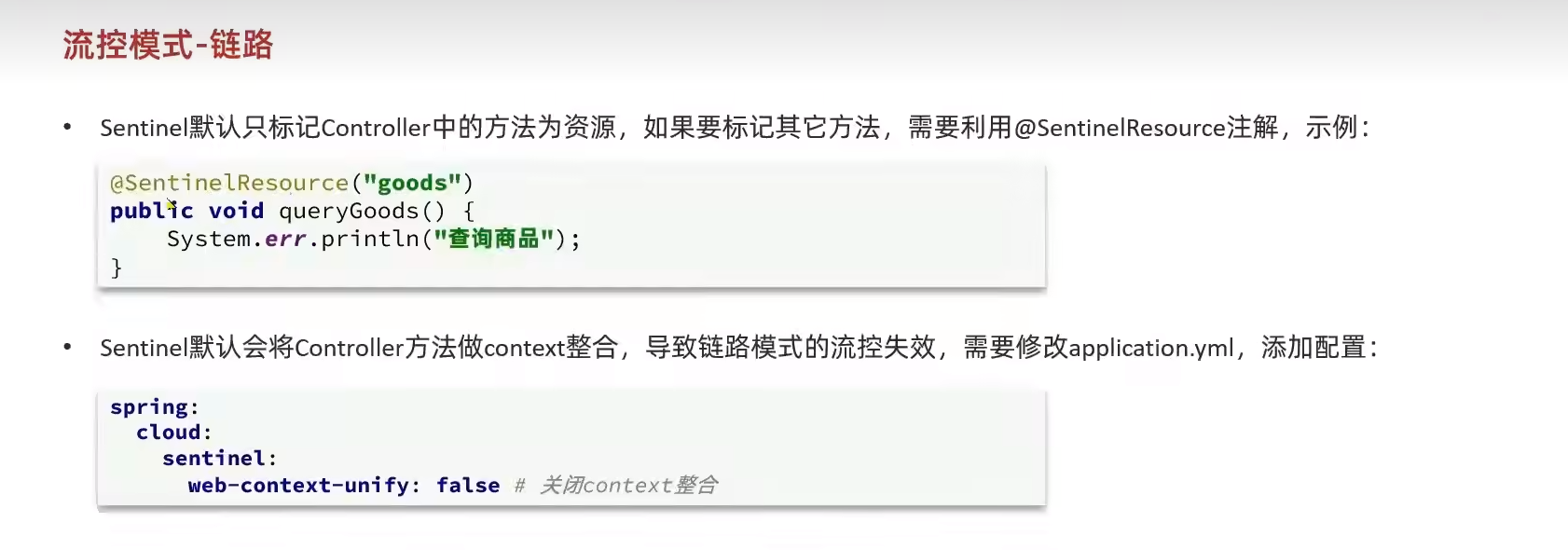 ?鏈路模式中,是對不同來源的兩個鏈路做監控。但是sentinel默認會給進入SpringMVC的所有請求設置同一個root資源,會導致鏈路模式失效。
?鏈路模式中,是對不同來源的兩個鏈路做監控。但是sentinel默認會給進入SpringMVC的所有請求設置同一個root資源,會導致鏈路模式失效。
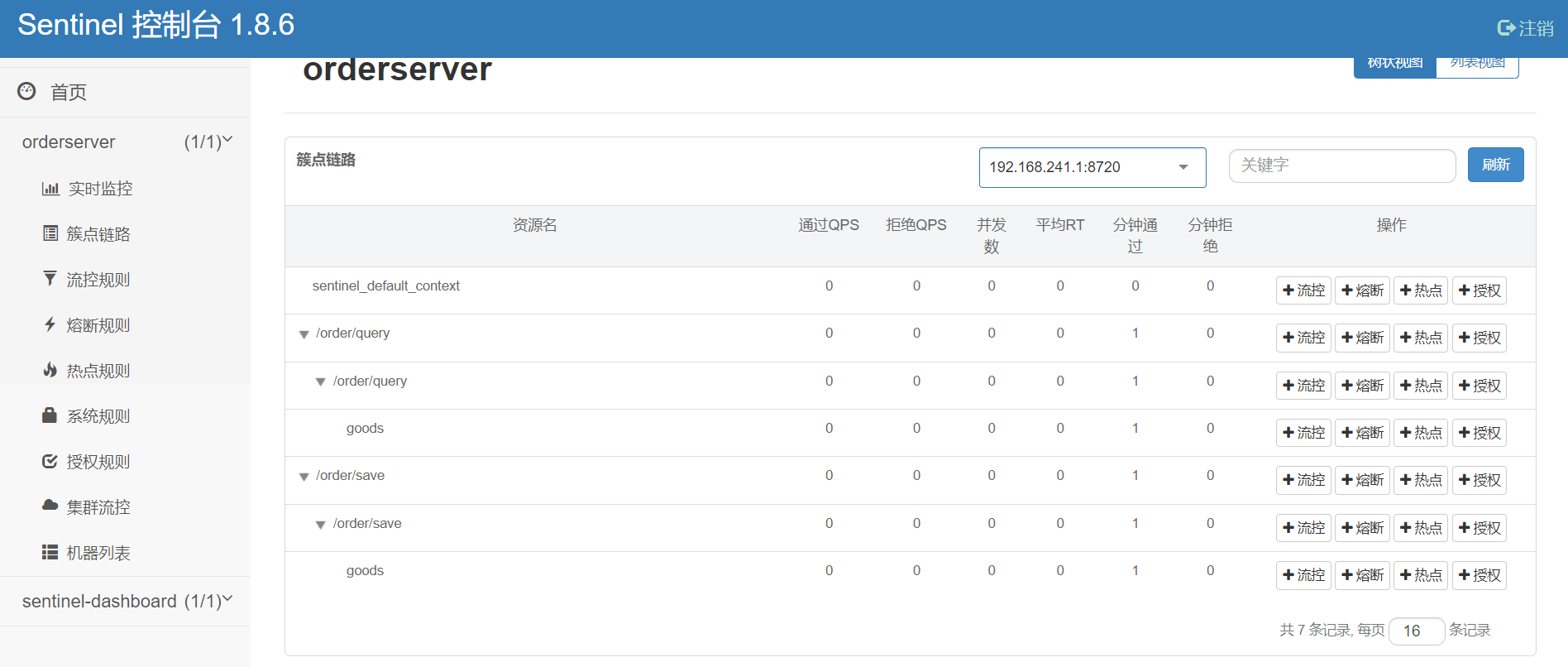
?重新配置之后可以看見,service層的資源也被監控了。為其中一個goods設置流控。

流控效果
warm up

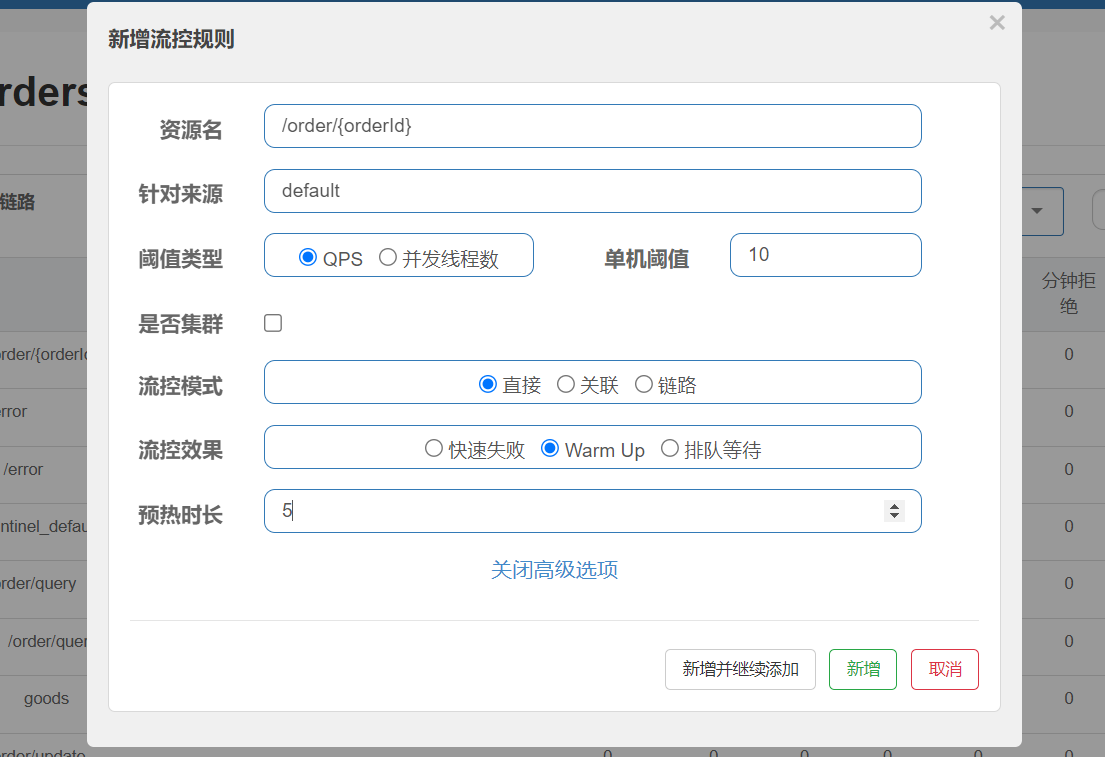
使用jmeter進行200個線程20s的壓測,初始時成功的只有3個,說明初始閾值就是3,20s里后面每一秒內能通過的線程數也是組件上升。
排隊等待

?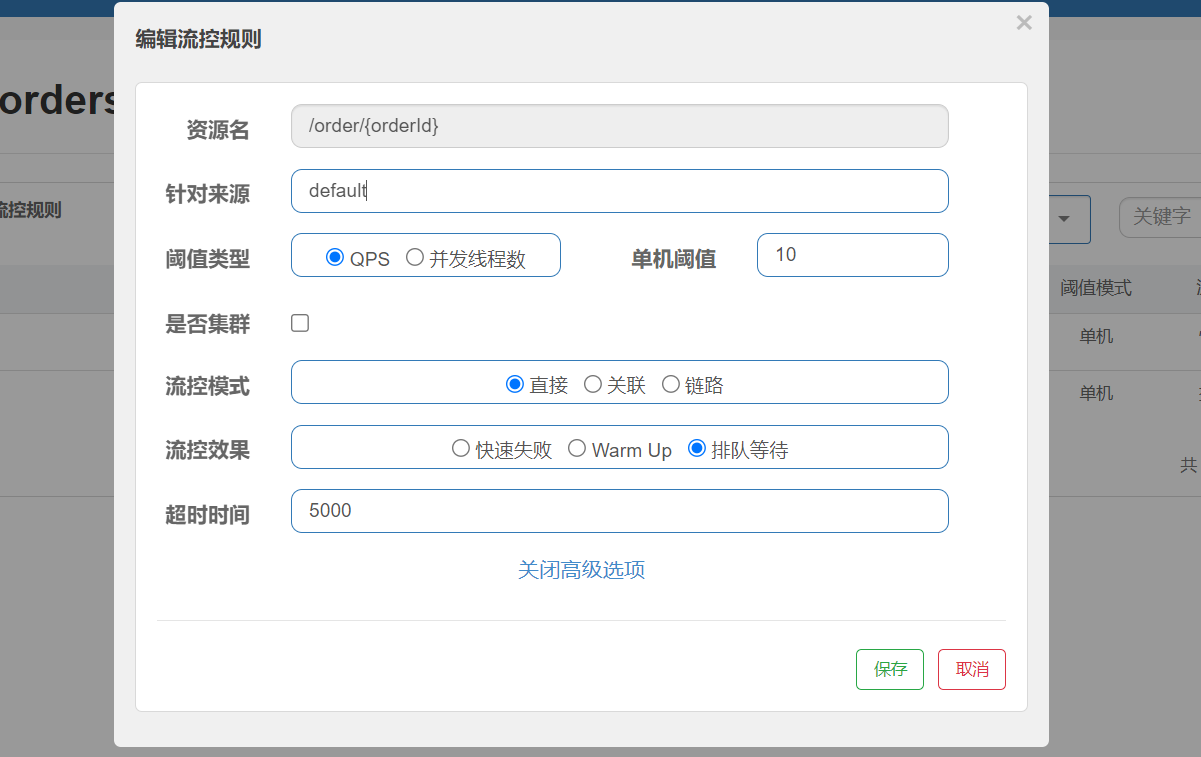
使用jemter進行300個線程20s執行完的壓測,qps是15.可以看見,后面大多數請求的響應時間都是接近5s了。這里起到了一個流量整形的作用。


熱點參限流
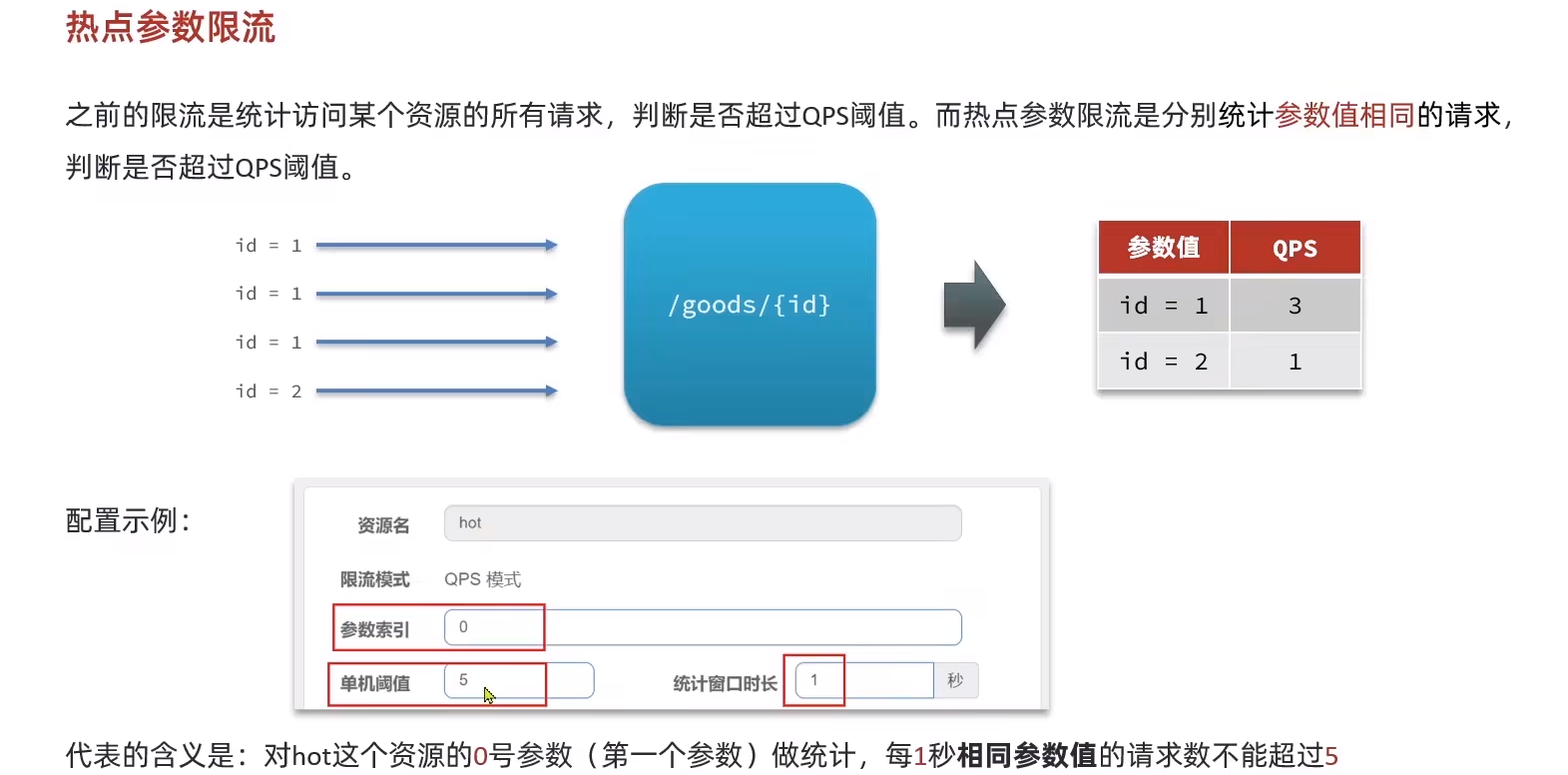
 ?只有那些通過@SentinelResource注解配置的資源才有效。
?只有那些通過@SentinelResource注解配置的資源才有效。

?所以要現在controller的資源上面添加注解。

重啟后可以看見hot的簇點鏈路。
 ?在左側的熱點規則那里進行配置才會有高級選項.然后如下配置
?在左側的熱點規則那里進行配置才會有高級選項.然后如下配置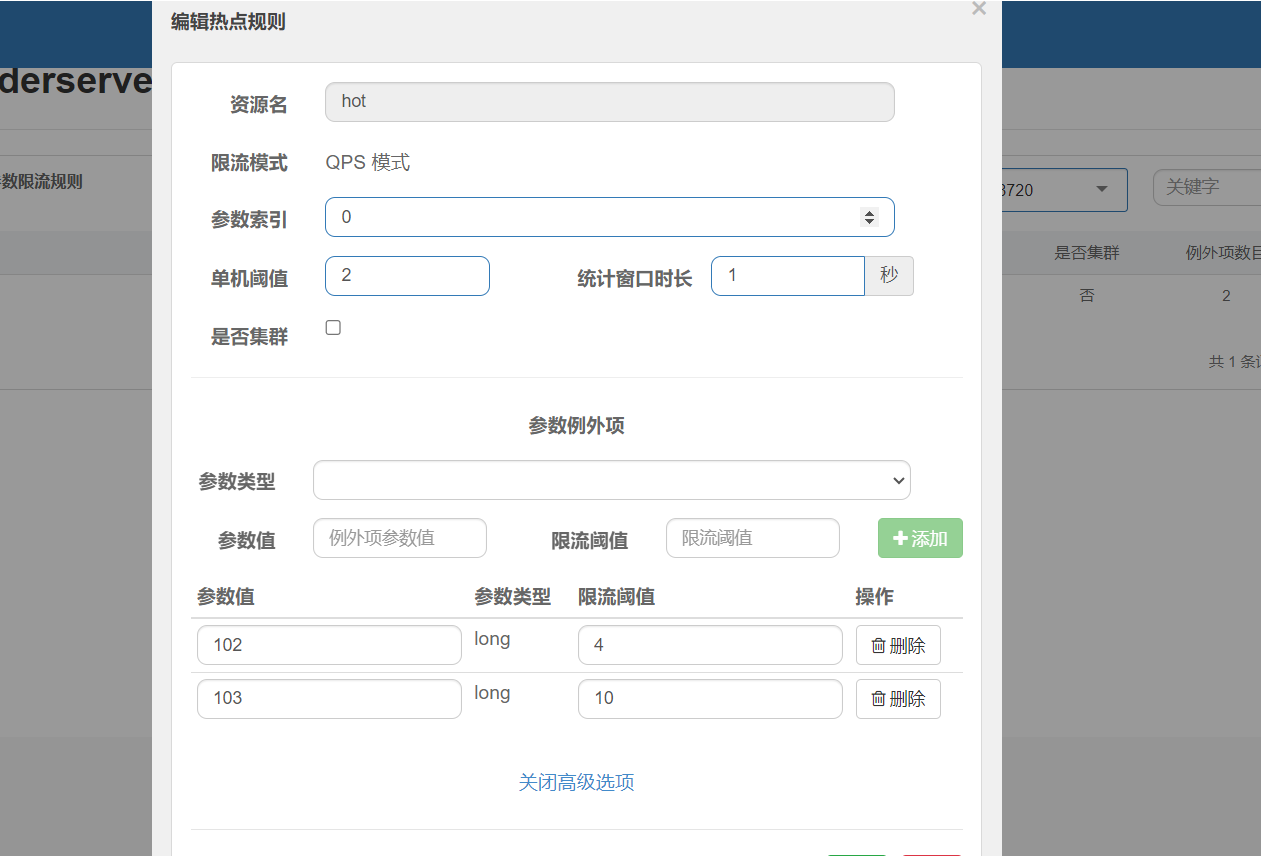
使用jmeter發起3個500線程100s的請求,分別對應三種參數,qps為5.
然后結果如下,jmeter中101的是每秒2個成功,102是每秒4個,103是全部。

隔離和降級
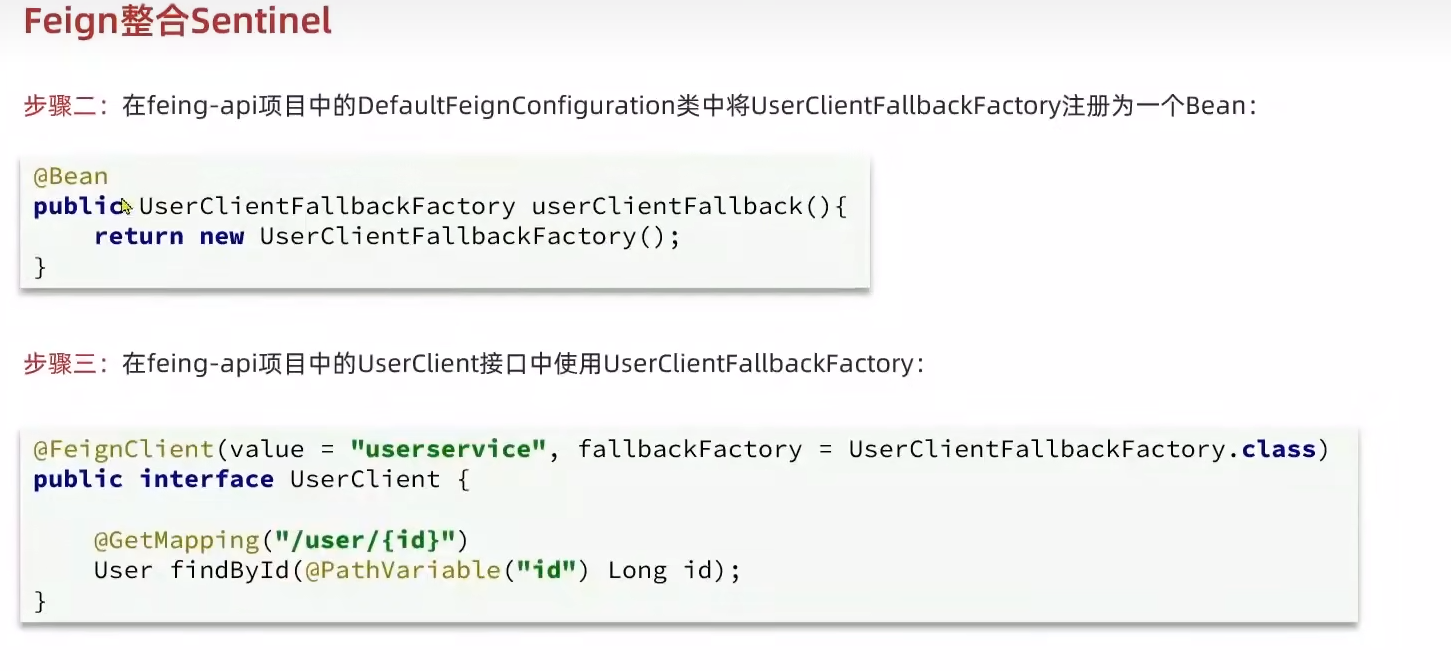
FeginClient整合Sentinel
例如在查詢訂單的時候,會發起遠程調用去查詢用戶信息。這里就可以編寫調用失敗后的降級邏輯。


?這里啟動時會有一個循環依賴的錯誤。
這里要在order-service服務里面自動注入UserClient時加上@Lazy注解。
或者是在啟動類里添加@ComponentScan來掃描feign的包.兩個方法都可以
@Autowired@Lazyprivate UserClient userClient;這里運行時也還是會有循環依賴的報錯.要將父工程里面的springcloud版本號改成SR8。這次才是真正解決問題.加上@Lazy只是延遲問題發生的時機。
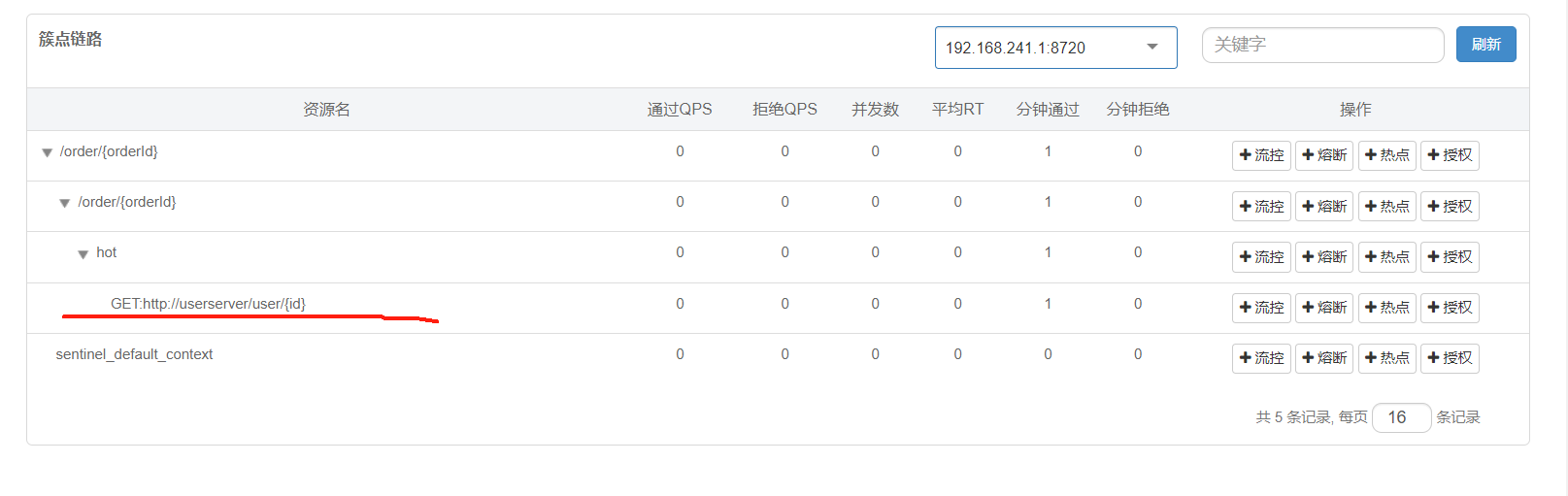
這次在service層的hot下終于可以看見利用feign發起遠程調用的接口了。
 ?
?
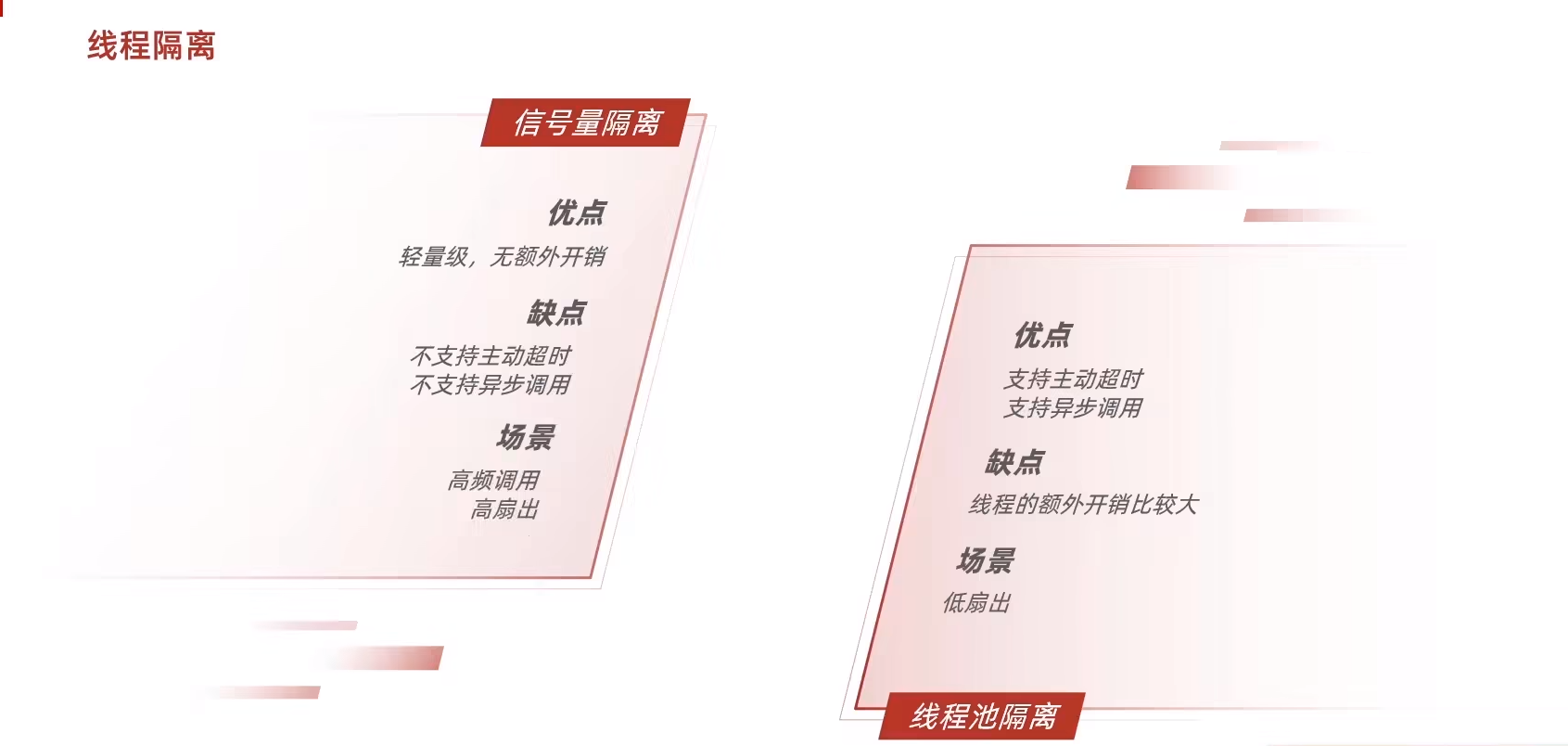
線程隔離(艙壁模式)

低扇出就是這個服務需要調用的服務較少。
線程池的做法是會開啟獨立線程的,而信號量的做法則不會。
 ?
?
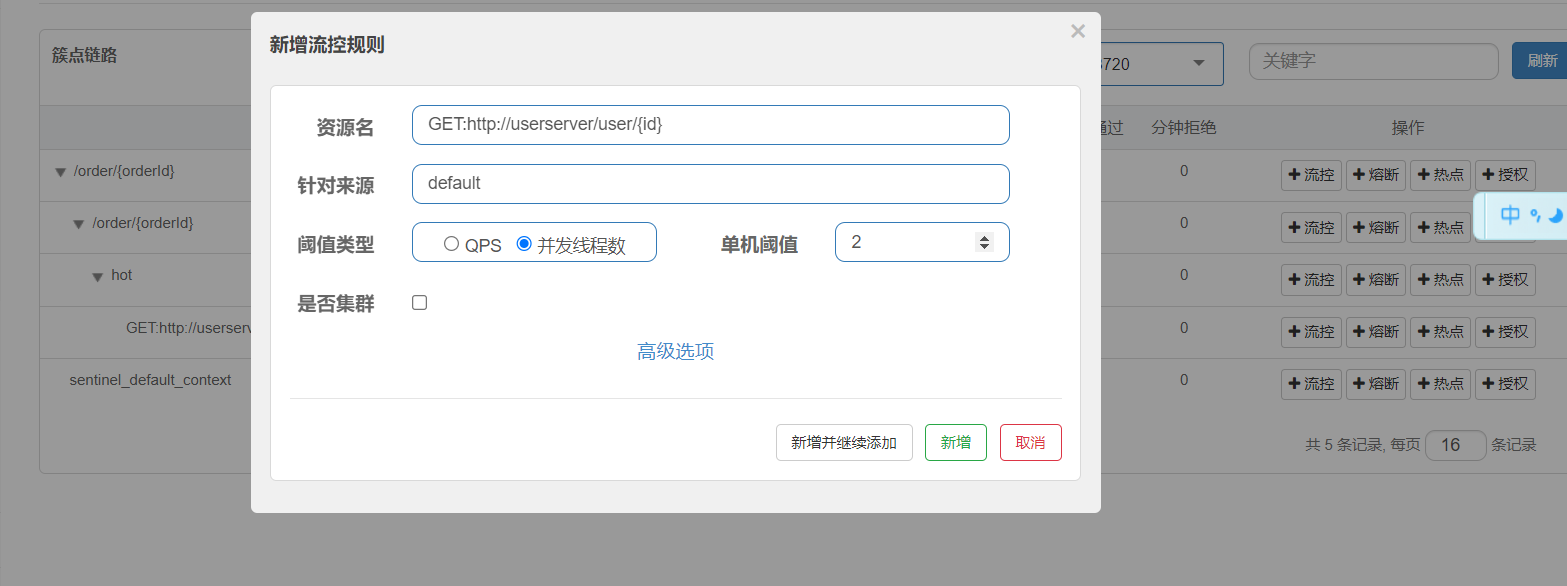
在jmeter中開啟10個線程要求0s內完成。理論上是由8個線程會被拒絕的.
但是因為前面做了降級處理,會返回一個空對象而不是報錯所以在控制臺才可以看見報錯的日志信息。不多不少,正好8個.?

 ?
?
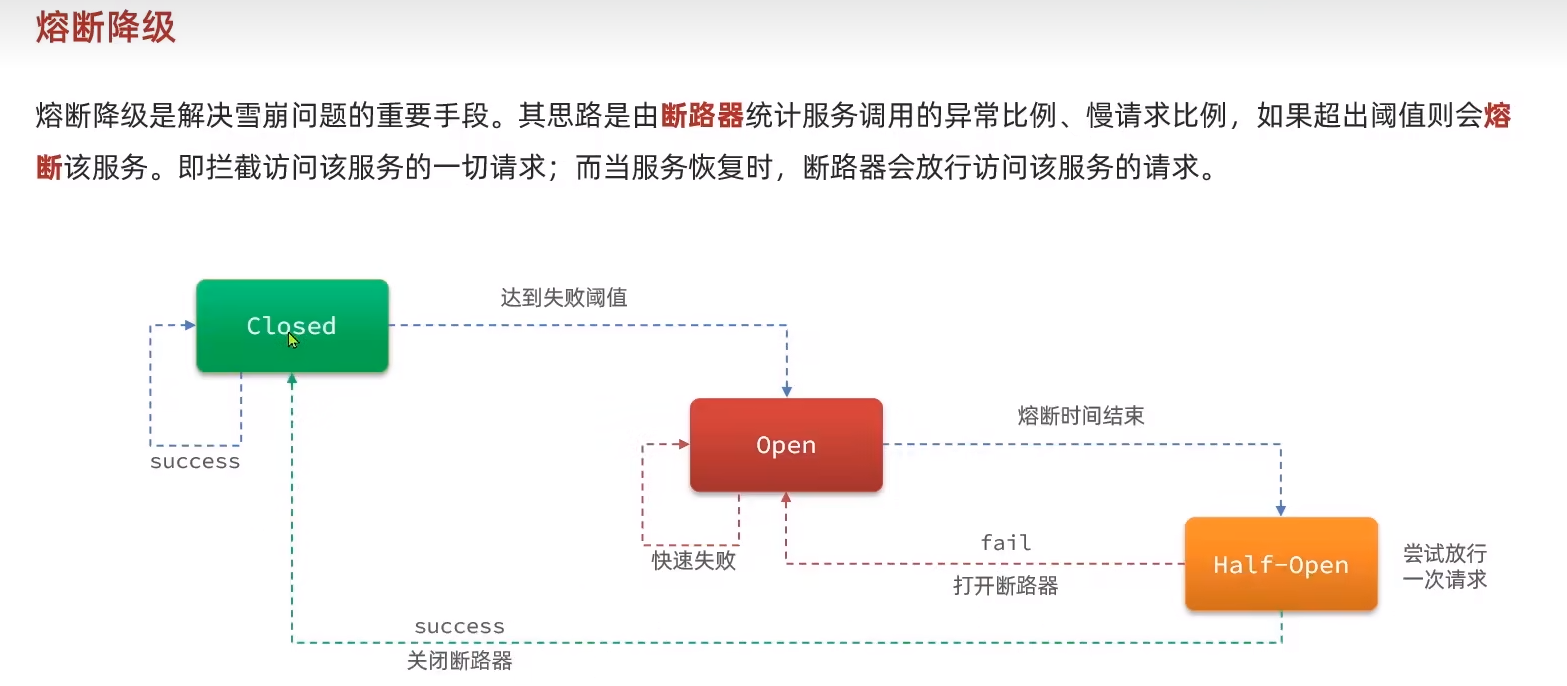
熔斷降級
下面是sentinel斷路器的三個狀態和狀態之間的切換。需要配置的兩個重要參數有,熔斷持續時間和熔斷的閾值。
慢調用??


?
發生熔斷之后成功阻塞了這個接口。?
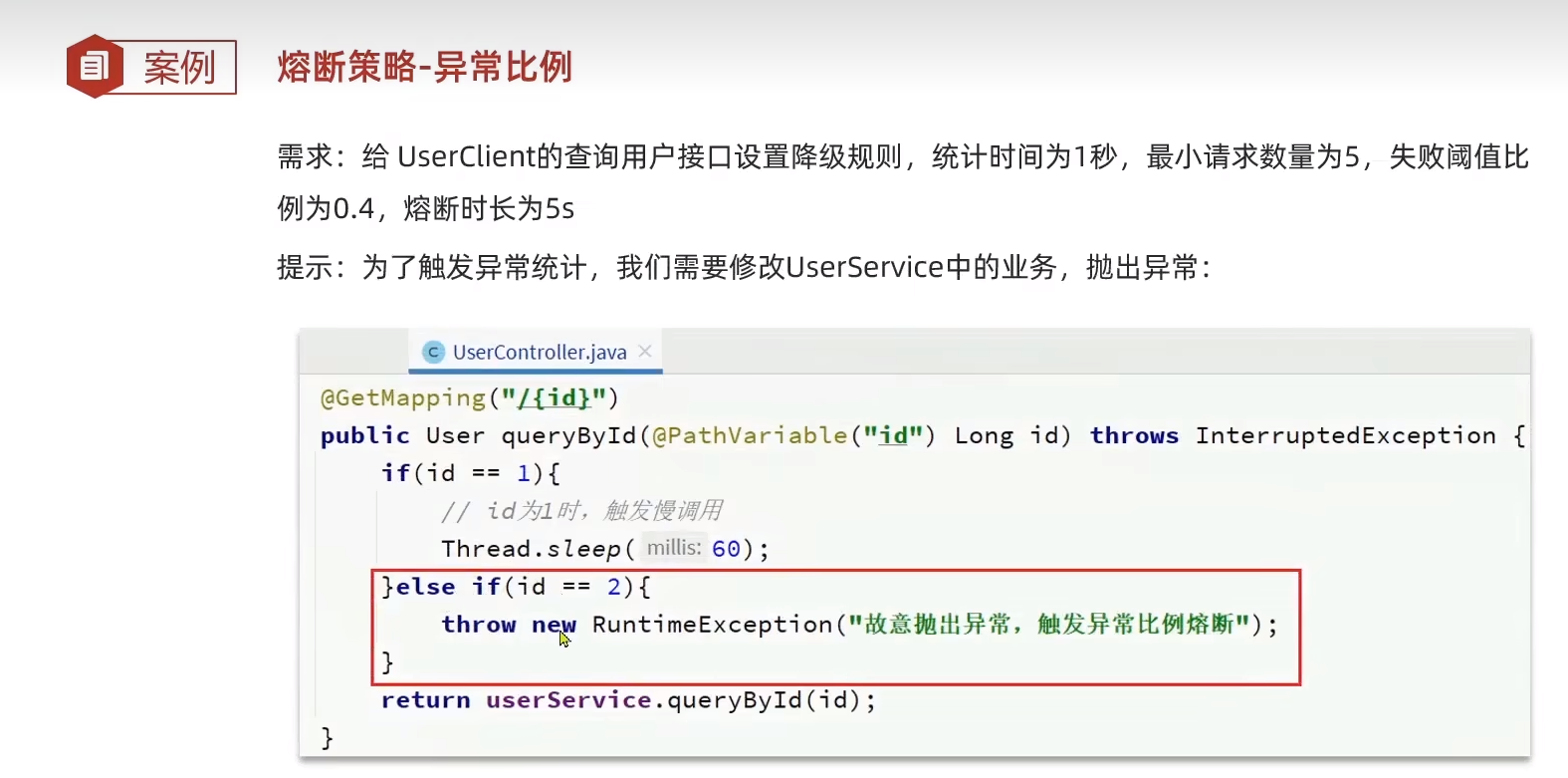
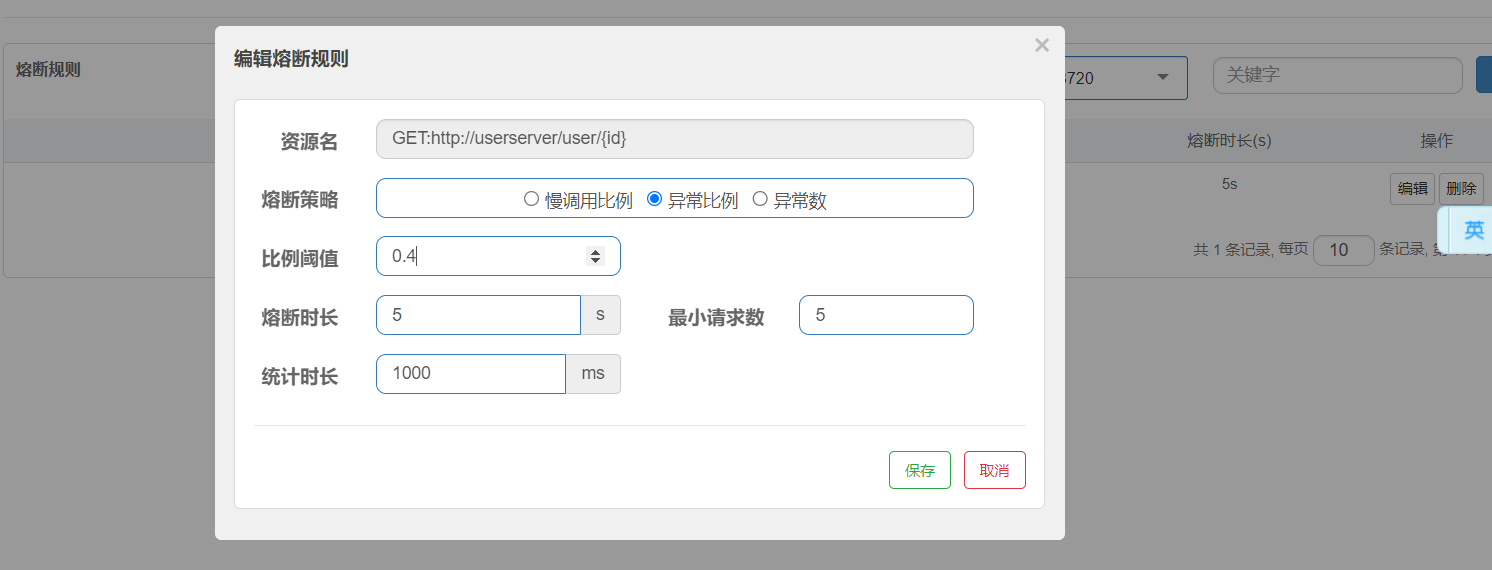
 異常比例、異常數
異常比例、異常數
 ?
?
 ?
?
授權規則
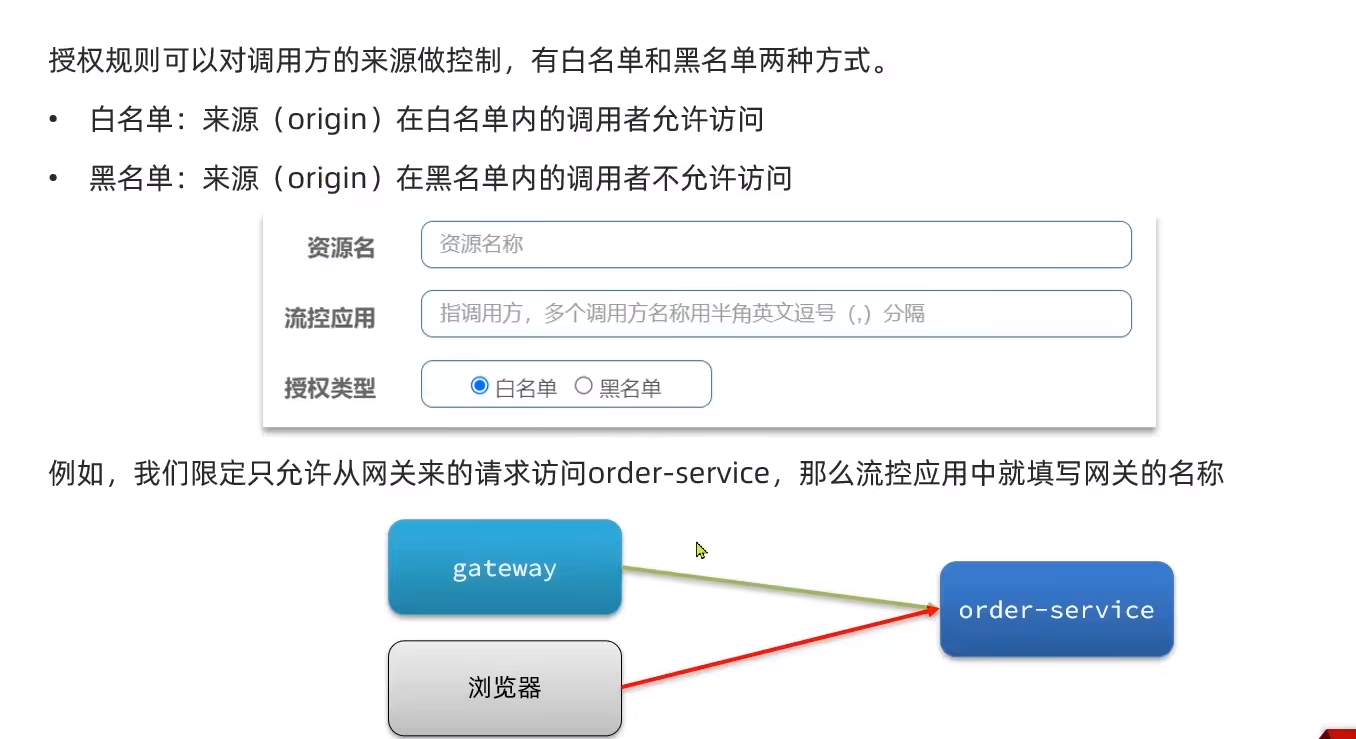
 ?
?

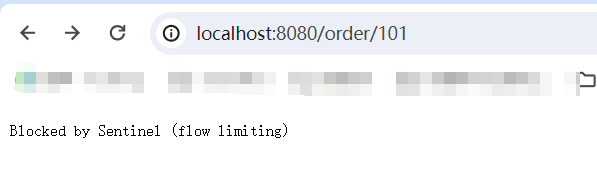
測試,然后嘗試直接訪問order-service時就會報錯.
然后通過gateway網關訪問就可以正常訪問

自定義異常結果
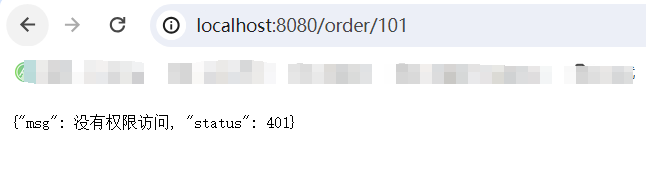
修改返回的限流異常為授權攔截.
通過實現下面的接口將所有不同類型的異常分別處理。


 ?
?
@Component
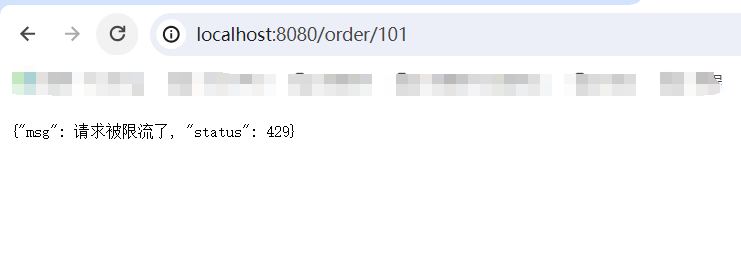
public class SentinelExceptionHandler implements BlockExceptionHandler {@Overridepublic void handle(HttpServletRequest request, HttpServletResponse response, BlockException e) throws Exception {String msg = "未知異常";int status = 429;if (e instanceof FlowException) {msg = "請求被限流了";} else if (e instanceof ParamFlowException) {msg = "請求被熱點參數限流";} else if (e instanceof DegradeException) {msg = "請求被降級了";} else if (e instanceof AuthorityException) {msg = "沒有權限訪問";status = 401;}response.setContentType("application/json;charset=utf-8");response.setStatus(status);response.getWriter().println("{\"msg\": " + msg + ", \"status\": " + status + "}");}
}
 規則持久化
規則持久化
sentinel把規則保存在內存里,重啟就會自動丟失。
規則管理模式




實現push模式
一、修改order-service服務
1.引入依賴
在order-service中引入sentinel監聽nacos的依賴:
<dependency><groupId>com.alibaba.csp</groupId><artifactId>sentinel-datasource-nacos</artifactId>
</dependency>2.配置nacos地址
在order-service中的application.yml文件配置nacos地址及監聽的配置信息:
spring:cloud:sentinel:datasource:flow:nacos:server-addr: localhost:8848 # nacos地址dataId: orderservice-flow-rulesgroupId: SENTINEL_GROUPrule-type: flow # 還可以是:degrade、authority、param-flowflow是持久化的,defrade是降級的
二、修改sentinel-dashboard源碼
SentinelDashboard默認不支持nacos的持久化,需要修改源碼。
tmd,看著教程巨幾把麻煩,以后用服務器廠商提供的應該也不用我來搞這些,就不做了,以后有需求再來看吧.
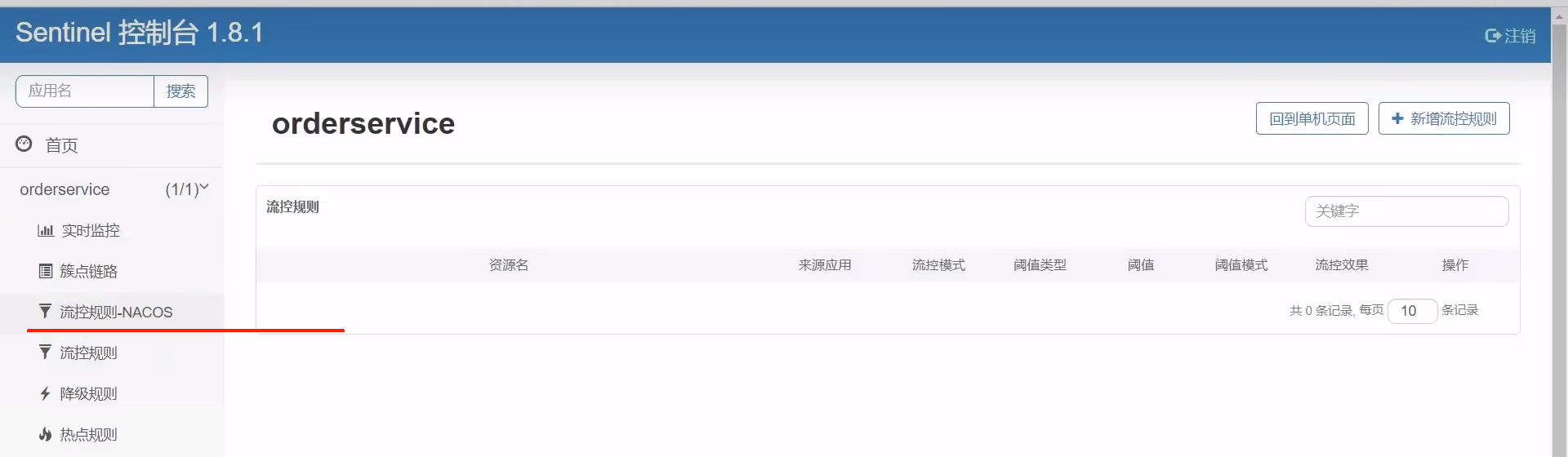
可以看見最后實現效果如下,在指定頁面添加的規則就會自動持久化到nacos.

ChatGPT OpenAI API 免代理調用方式(通過 Cloudflare 的 AI Gateway))
實驗四:CSS3布局應用)
 修改文本位置(label) 南丁格爾圖(roseType))



—ndarray屬性》)




方法的傳參和使用)



)


