前言:StarRocks原名DorisDB,是新一代極速全場景MPP數據庫。StarRocks 是 Apache Doris 的 Fork 版本。StarRocks 連接的多種源。一是通過這個 CDC 或者說通過這個 ETL 的方式去灌到這個 StarRocks 里面;二是還可以去直接的和這些老的 kafka 或者是這種 TP 的數據庫或者這種 log 的話,直接可以進行灌入;三是 External table 目前支持這種 hive 、es、 MySQL ,當然這里邊還支持 hudi 和 Iceberg
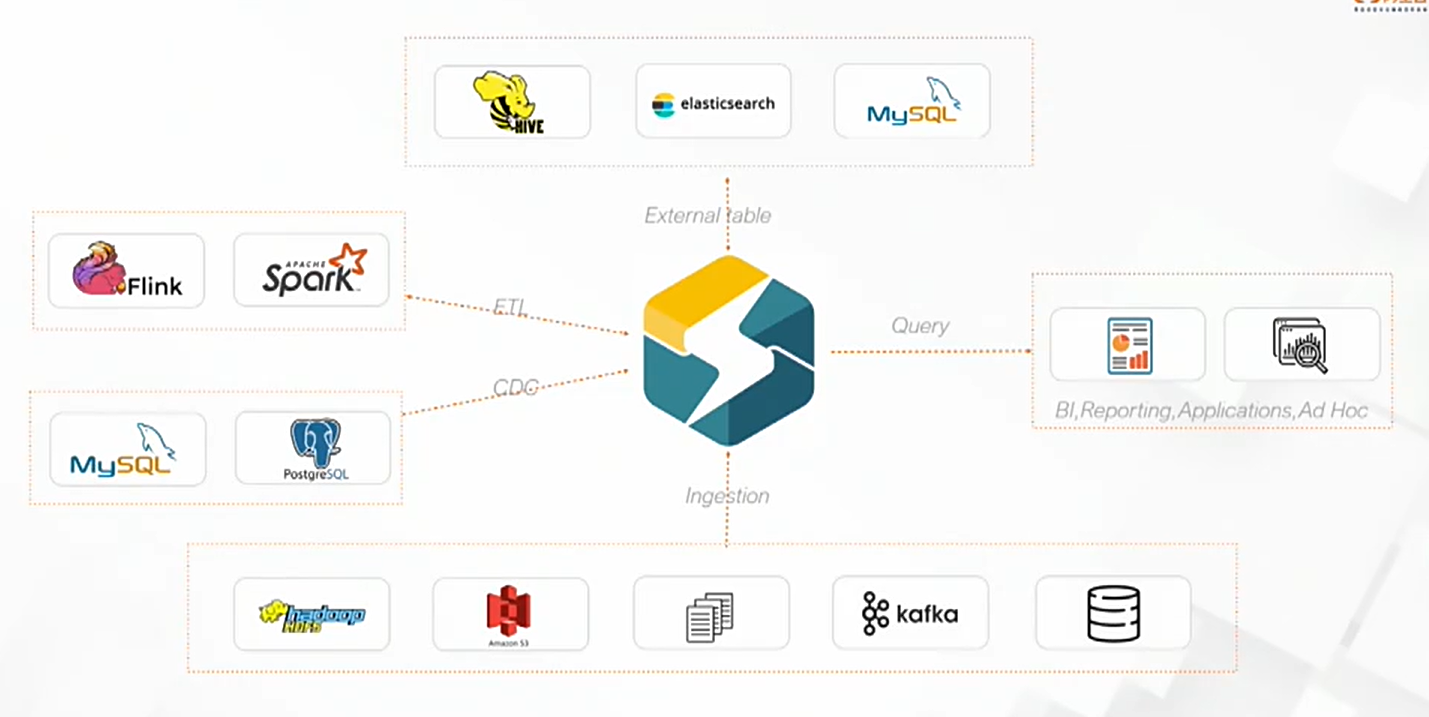
StarRocks官網:https://docs.starrocks.io/zh/docs/introduction/StarRocks_intro/
一、StarRocks簡介
1.1、StarRocks定義
StarRocks 是一款高性能分析型數據倉庫,使用向量化、MPP 架構、CBO、智能物化視圖、可實時更新的列式存儲引擎等技術實現多維、實時、高并發的數據分析。StarRocks 既支持從各類實時和離線的數據源高效導入數據,也支持直接分析數據湖上各種格式的數據。StarRocks 兼容 MySQL 協議,可使用 MySQL 客戶端和常用 BI 工具對接。同時 StarRocks 具備水平擴展,高可用、高可靠、易運維等特性。廣泛應用于實時數倉、OLAP 報表、數據湖分析等場景。
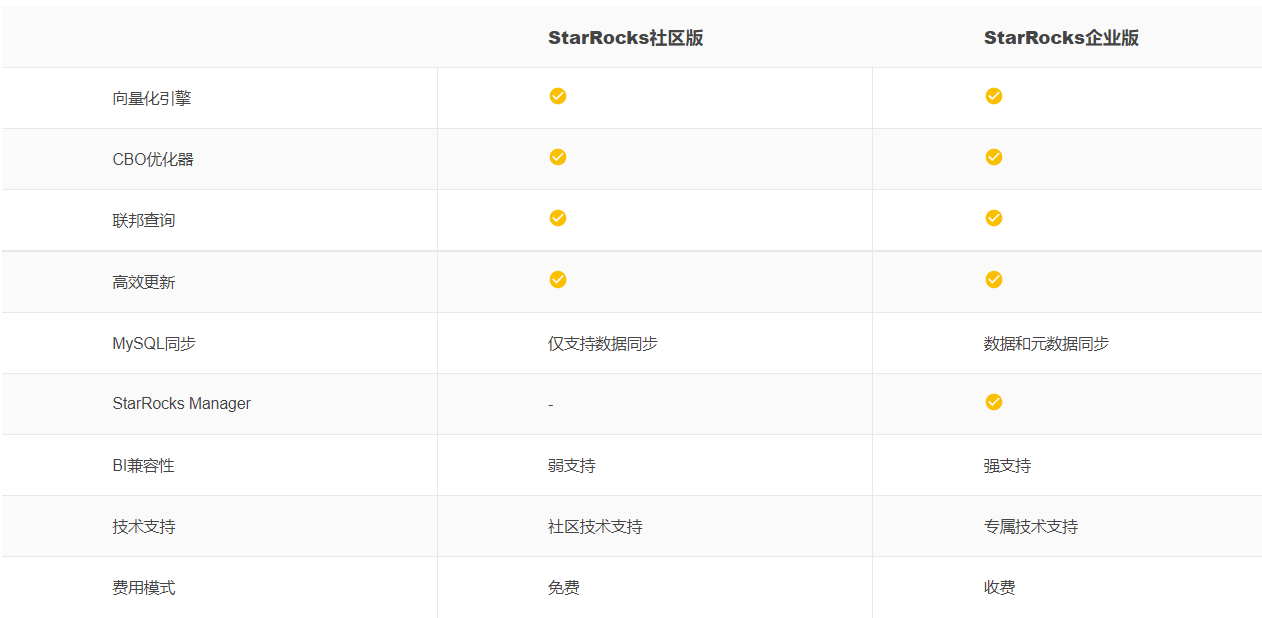
StarRocks 分為社區版和企業版,社區版為開源,企業版需付費使用。社區版支持了大部分的功能,但不支持StarRocks Manager(可視化運維監控平臺),在數據庫管理上不太方便。
StarRocks 是新一代極速全場景 MPP (Massively Parallel Processing) 數據庫。StarRocks 的愿景是能夠讓用戶的數據分析變得更加簡單和敏捷。用戶無需經過復雜的預處理,就可以用 StarRocks 來支持多種數據分析場景的極速分析。
StarRocks?架構簡潔,采用了全面向量化引擎,并配備全新設計的 CBO (Cost Based Optimizer) 優化器,查詢速度(尤其是多表關聯查詢)遠超同類產品。
StarRocks 能很好地支持實時數據分析,并能實現對實時更新數據的高效查詢。StarRocks 還支持現代化物化視圖,進一步加速查詢。
使用 StarRocks,用戶可以靈活構建包括大寬表、星型模型、雪花模型在內的各類模型。
StarRocks 兼容 MySQL 協議,支持標準 SQL 語法,易于對接使用,全系統無外部依賴,高可用,易于運維管理。StarRocks 還兼容多種主流 BI 產品,包括 Tableau、Power BI、FineBI 和 Smartbi。
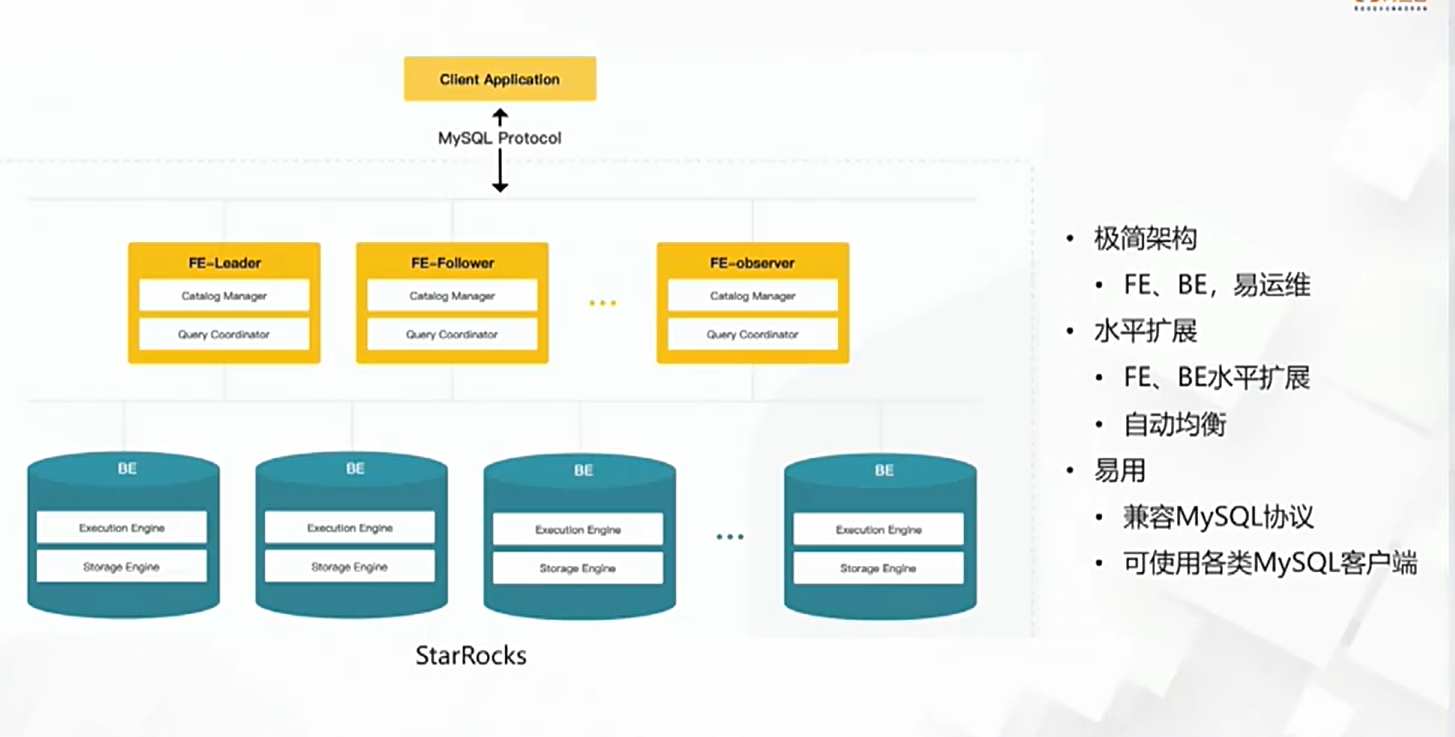
1.2、新一代彈性 MPP 架構
下圖是StarRocks 的架構,這個架構就是有一個 FE 和 BE ,而這個 FE 有幾個模塊。第一個模塊就是 catter log 的一個模塊,就是他會存這個原數據,然后他還有一個 planner ,相當于所有的 MySQL 的第一站全部打到 FE 里,然后 FE 進行 SQL 的整個的解析,到最后的這個分布式的物理的 plan 的生成,然后都搞完之后真正的做整個的這個計算,是要在 BE 里去做計算的。
他整個的這個架構是非常簡單的,就是說在 FE 目前是一個稍微老一些的,因為這個其實是從 Doris 演化過來的,所以這是一個當時 Doris 有的時候還沒有這個 raft 的這種玩法,但是現在社區 StarRocks 要慢慢的把 FE 改成這種基于 raft 的這種結構,它是目前現在是基于 Borken DB的,但是可以認為跟 raft 也差不太多,他是幾臺高可用的 FE 再加上這種 BE 。 BE 實際上做的就是這種 Execution Engine 還有這種存儲引擎 storage engine 基本他就是這兩個大的模塊。實際上整個鏈路就是 MySQL 第一條打到查詢的時候打到 FE ,FE 再把這個 SQL 文本翻譯成這個分布式的執行計劃,分布式的執行計劃的數據都是按這種 buget 的方式去存到 BE 里。這一個這張表或者說查的這些 SQL 都命中了哪些 tablet ,會把這個相應的 SQL 的執行引擎給他搞到這個 BE 上,然后 BE 算完之后再回給 FE ,大概整個就是這么一個數據流。
1.3、StarRocks適用場景?
StarRocks 可以滿足企業級用戶的多種分析需求,包括 OLAP (Online Analytical Processing) 多維分析、定制報表、實時數據分析和 Ad-hoc 數據分析等。
(1)OLAP 多維分析?
利用 StarRocks 的 MPP 框架和向量化執行引擎,用戶可以靈活的選擇雪花模型,星型模型,寬表模型或者預聚合模型。適用于靈活配置的多維分析報表,業務場景包括:
-
用戶行為分析
-
用戶畫像、標簽分析、圈人
-
高維業務指標報表
-
自助式報表平臺
-
業務問題探查分析
-
跨主題業務分析
-
財務報表
-
系統監控分析
(2)實時數據倉庫?
StarRocks 設計和實現了 Primary-Key 模型,能夠實時更新數據并極速查詢,可以秒級同步 TP (Transaction Processing) 數據庫的變化,構建實時數倉,業務場景包括:
-
電商大促數據分析
-
物流行業的運單分析
-
金融行業績效分析、指標計算
-
直播質量分析
-
廣告投放分析
-
管理駕駛艙
-
探針分析APM(Application Performance Management)
(3)高并發查詢?
StarRocks 通過良好的數據分布特性,靈活的索引以及物化視圖等特性,可以解決面向用戶側的分析場景,業務場景包括:
-
廣告主報表分析
-
零售行業渠道人員分析
-
SaaS 行業面向用戶分析報表
-
Dashboard 多頁面分析
(4)統一分析?
-
通過使用一套系統解決多維分析、高并發查詢、預計算、實時分析查詢等場景,降低系統復雜度和多技術棧開發與維護成本。
-
使用 StarRocks 統一管理數據湖和數據倉庫,將高并發和實時性要求很高的業務放在 StarRocks 中分析,也可以使用 External Catalog 和外部表進行數據湖上的分析。
二、StarRocks特性
StarRocks的架構設計融合了MPP數據庫,以及分布式系統的設計思想,具有以下特性:
架構精簡
StarRocks內部通過MPP計算框架完成SQL的具體執行工作。MPP框架本身能夠充分的利用多節點的計算能力,整個查詢并行執行,從而實現良好的交互式分析體驗。 StarRocks集群不需要依賴任何其他組件,易部署、易維護,極簡的架構設計,降低了StarRocks系統的復雜度和維護成本,同時也提升了系統的可靠性和擴展性。
標準SQL
StarRocks支持標準的SQL語法,包括聚合、JOIN、排序、窗口函數和自定義函數等功能。StarRocks可以完整支持TPC-H的22個SQL和TPC-DS的99個SQL。StarRocks還兼容MySQL協議語法,可使用現有的各種客戶端工具、BI軟件訪問StarRocks,對StarRocks中的數據進行拖拽式分析。
全面向量化引擎
StarRocks的計算層全面采用了向量化技術,將所有算子、函數、掃描過濾和導入導出模塊進行了系統性優化。通過列式的內存布局、適配CPU的SIMD指令集等手段,充分發揮了現代CPU的并行計算能力,從而實現亞秒級別的多維分析能力。
智能查詢優化
StarRocks通過CBO優化器(Cost Based Optimizer)可以對復雜查詢自動優化。無需人工干預,就可以通過統計信息合理估算執行成本,生成更優的執行計劃,大大提高了Adhoc和ETL場景的數據分析效率。
聯邦查詢
StarRocks支持使用外表的方式進行聯邦查詢,當前可以支持Hive、MySQL、Elasticsearch三種類型的外表,用戶無需通過數據導入,可以直接進行數據查詢加速。
高效更新
StarRocks支持多種數據模型,其中更新模型可以按照主鍵進行upsert/delete操作,通過存儲和索引的優化可以在并發更新的同時實現高效的查詢優化,更好的服務實時數倉的場景。
智能物化視圖
StarRocks支持智能的物化視圖。用戶可以通過創建物化視圖,預先計算生成預聚合表用于加速聚合類查詢請求。StarRocks的物化視圖能夠在數據導入時自動完成匯聚,與原始表數據保持一致。并且在查詢的時候,用戶無需指定物化視圖,StarRocks能夠自動選擇最優的物化視圖來滿足查詢請求。
流批一體
StarRocks支持實時和批量兩種數據導入方式,支持的數據源有Kafka、HDFS、本地文件,支持的數據格式有ORC、Parquet和CSV等,StarRocks可以實時消費Kafka數據來完成數據導入,保證數據不丟不重(exactly once)。StarRocks也可以從本地或者遠程(HDFS)批量導入數據。
極簡運維
StarRocks具有高可用易擴展的特性,元數據和數據都是多副本存儲,并且集群中服務有熱備,多實例部署,避免了單點故障。集群具有自愈能力,可彈性恢復,節點的宕機、下線、異常都不會影響StarRocks集群服務的整體穩定性。
StarRocks采用分布式架構,存儲容量和計算能力可近乎線性水平擴展。StarRocks單集群的節點規模可擴展到數百節點,數據規模可達到10PB級別。 擴縮容期間無需停服,可以正常提供查詢服務。 另外StarRocks中表模式熱變更,可通過一條簡單SQL命令動態地修改表的定義,例如增加列、減少列、新建物化視圖等。同時,處于模式變更中的表也可也正常導入和查詢數據。
StarRocks是一個自治的系統。節點的上下線,集群擴縮容都可通過一條簡單的SQL命令來完成。
三、StarRocks優勢
極速SQL查詢
- 全新的向量化執行引擎,亞秒級查詢延時,單節點每秒可處理多達100億行數據。
- 強大的MPP執行框架,支持星型模型和雪花模型,極致的Join性能。
- 綜合查詢速度比其他產品快10-100倍
- 查看性能測試報告
實時數據分析
- 新型列式存儲引擎,支持大規模數據實時寫入,秒級實時性保證。
- 支持業務指標實時聚合,加速實時多維數據分析。
- 新型讀寫并發管理模式,可同時高效處理數據讀取和寫入。
高并發查詢
- 靈活的資源分配策略,每秒可支持高達1萬以上的并發查詢。
- 可高效支持數千用戶同時進行數據分析。
極簡運維
- 支持在大數據規模下進行在線彈性擴展,擴容不影響線上業務。集群可擴展至數百節點,PB量級數據。
集群運行高度自治化,故障自恢復,運維成本低。
國產核心軟件
- 完全自主創新,全球領先。
- 更完善的本地化專家服務體系。
四、StarRocks VS ClickHouse
| 指標 | ClickHouse | StarRocks |
|---|---|---|
| MPP架構 | Scatter-Gather模式,聚合操作依賴單點完成,操作數據量大時有瓶頸 | 現代化MPP架構,可以實現多層聚合、大表Join |
| 架構 | 依賴ZooKeeper進行DDL和Replica同步 | 內置分布式協議進行元數據同步Master/Follower/Observer節點類型 |
| 事務性 | 100萬以內原子性,DDL無事務保證 | 事務保證數據ACID |
| 數據規模 | 單集群 < 10PB | 單集群 < 10PB |
| 標準SQL的支持 | 不支持標準的SQL語言 | 支持,兼容Mysql協議 |
| 分布式Join | 不支持Join,僅支持大寬表模式 | 支持主流分布式Join,不僅支持大寬表模型,還支持星型和雪花模型 |
| 高并發查詢 | 不支持高并發 | 支持高并發 |
| 外表 | 支持MySQL/Hive的表 | 外查MySQL/ES/Hive的表 |
| Exactly Once語義 | 不支持事務,無法保證數據寫入不丟不重 | 支持事務,可實現數據不丟不重 |
| 集群擴容 | 擴容需人工操作,工作量巨大,且影響線上服務 | 擴容只需要遷移部分數據分片,系統自動完成,不影響線上服務 |
| 運維要求 | 依賴ZK,運維和維護成本高 | 不依賴外部系統,極簡運維 |
參考鏈接:
什么是 StarRocks | StarRocks
StarRocks調研
開源大數據 OLAP 引擎最佳實踐 | 學習筆記(二)-阿里云開發者社區



方法的傳參和使用)



)






)




