文章目錄
- 背景
- 遷移方案調研
- 遷移過程
- 服務監控腳本定時任務暫停
- 本地副本服務啟動,在線服務下線
- MySQL 數據遷移
- Mongo 數據遷移
- 切換新數據庫 ip 本地服務啟動
- 數據庫連接驗證
- 服務打包部署
- 服務重啟
- 前端恢復正常
- 監控腳本定時任務啟動
- 舊服務器器容器關閉
- 遷移總結
背景
校園 e 站,一群大學生在畢業前夕,為打破信息差而開發的一個校園論壇。一個從零到一全靠一群大學生的滿腔熱忱而打造的一個前后端分離以小程序為最終展示載體的一個微服務架構體系的 App。并發量的初始定位為 w 級,使用到多級緩存、數據分庫等等前沿技術,當然這也是本次就是數據遷移的根本原因所在,架構過于龐大,用戶較少,資源空等率高,所以決定將服務縮容,降低運營成本。
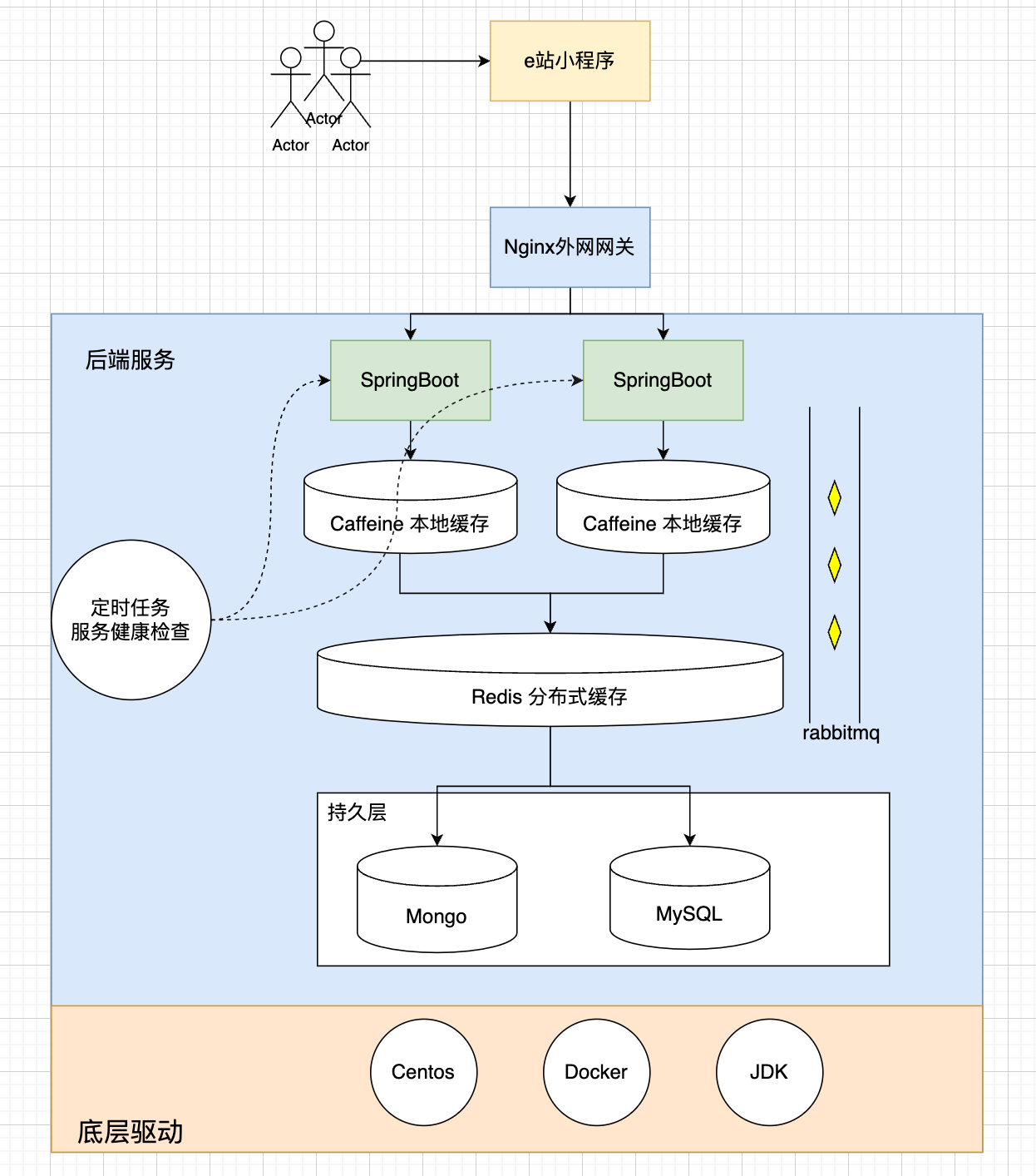
整體架構如上所示,本次需要遷移的數據重點為,Mongo 以及 MySQL 持久層數據。
遷移方案調研
因為持久層數據本身是通過 docker-compose進行容器編排加docker volume腳本啟動,所以調研到的方案大體可分為以下幾種:
- 在磁盤級別進行
volume遷移 - 以舊數據庫為主庫,新數據庫為從庫,進行主從同步
- 在應用層面使用應用本身的備份恢復功能進行數據遷移
三種方案的優缺點
| 方案 | 優點 | 缺點 |
|---|---|---|
| 磁盤 | 暫時想不到,可能是看起來很牛 | 技術要求高,容易出現兼容性問題 |
| 主從 | 停機時間短 | 需要改動兩次服務啟動腳本(主從搭建時,從庫切主庫) |
| 備份恢復 | 操作簡單,風險低 | 停機時間較長 |
在綜合考慮下,選擇了方案三進行備份恢復。
原因也很簡單,生產級別一般都是選擇風險最低且操作簡單的方式,因為不管你有多牛,也沒辦法保證遷移過程不會出現一點問題~
遷移過程
服務監控腳本定時任務暫停
本地副本服務啟動,在線服務下線
MySQL 數據遷移
遇到的第一個問題是,導出的文件壓縮前 38M zip 壓縮后依然 3.9 M,遠大于 phpmyadmin 允許上傳的 2M ,此時有兩個方案:一是調大數據導入的文件大小限制,二是減少數據量。按道理正常使用數據,不應該那么大,畢竟用戶量不大,且主要數據存在 mongo 中,在查詢了之后發現,有一個請求時間監控的表數據量達到 50W
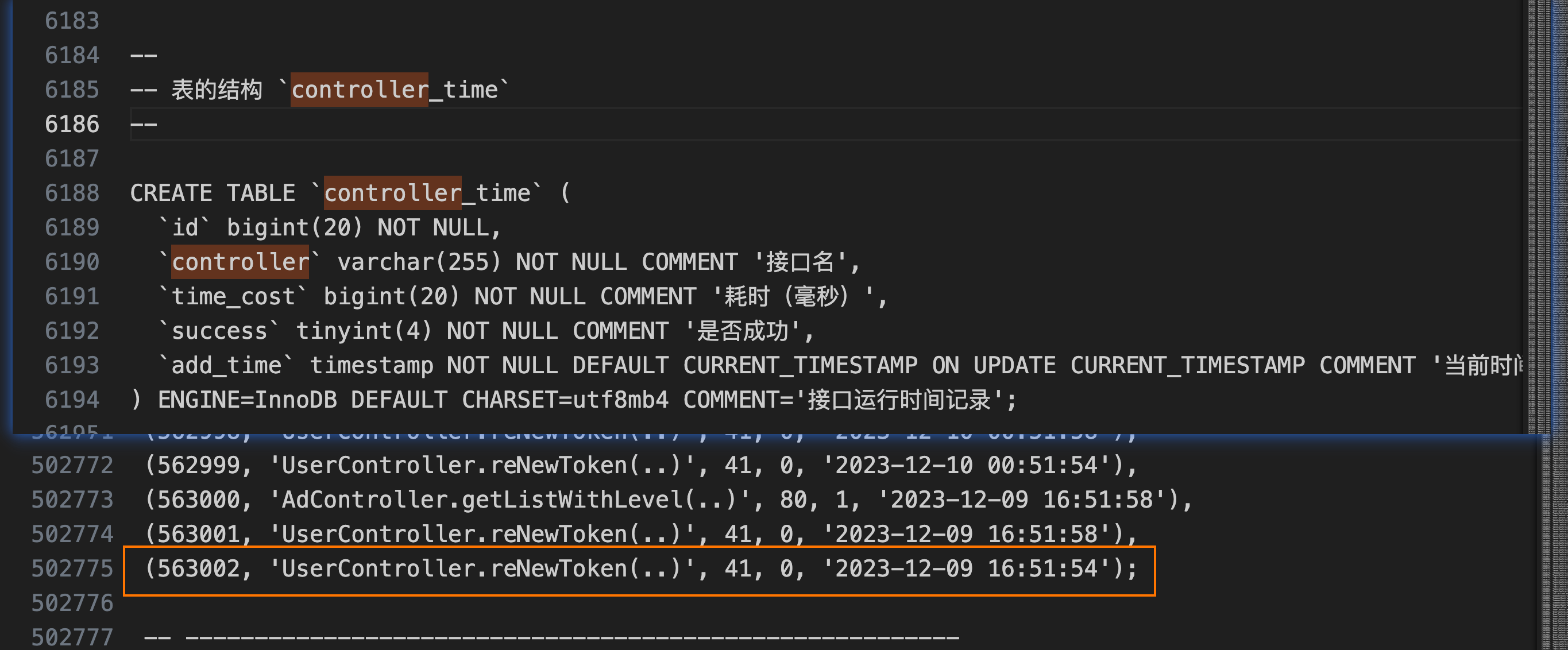
執行 sql 將數據壓縮,
-- 數據平均
insert into controller_time(controller, time_cost, success) SELECT controller, AVG(time_cost) as time_cost, successFROM controller_time where id < 563003GROUP BY controller, success
;-- 刪除舊數據
delete from controller_time where id < 563003;
controller_time 數據壓縮后導出文件 4.5M 壓縮后 359K,導入新數據庫約十秒。
Mongo 數據遷移
進入 新機器 容器內,到 /usr/bin目錄調用,容器已有的 mongo命令
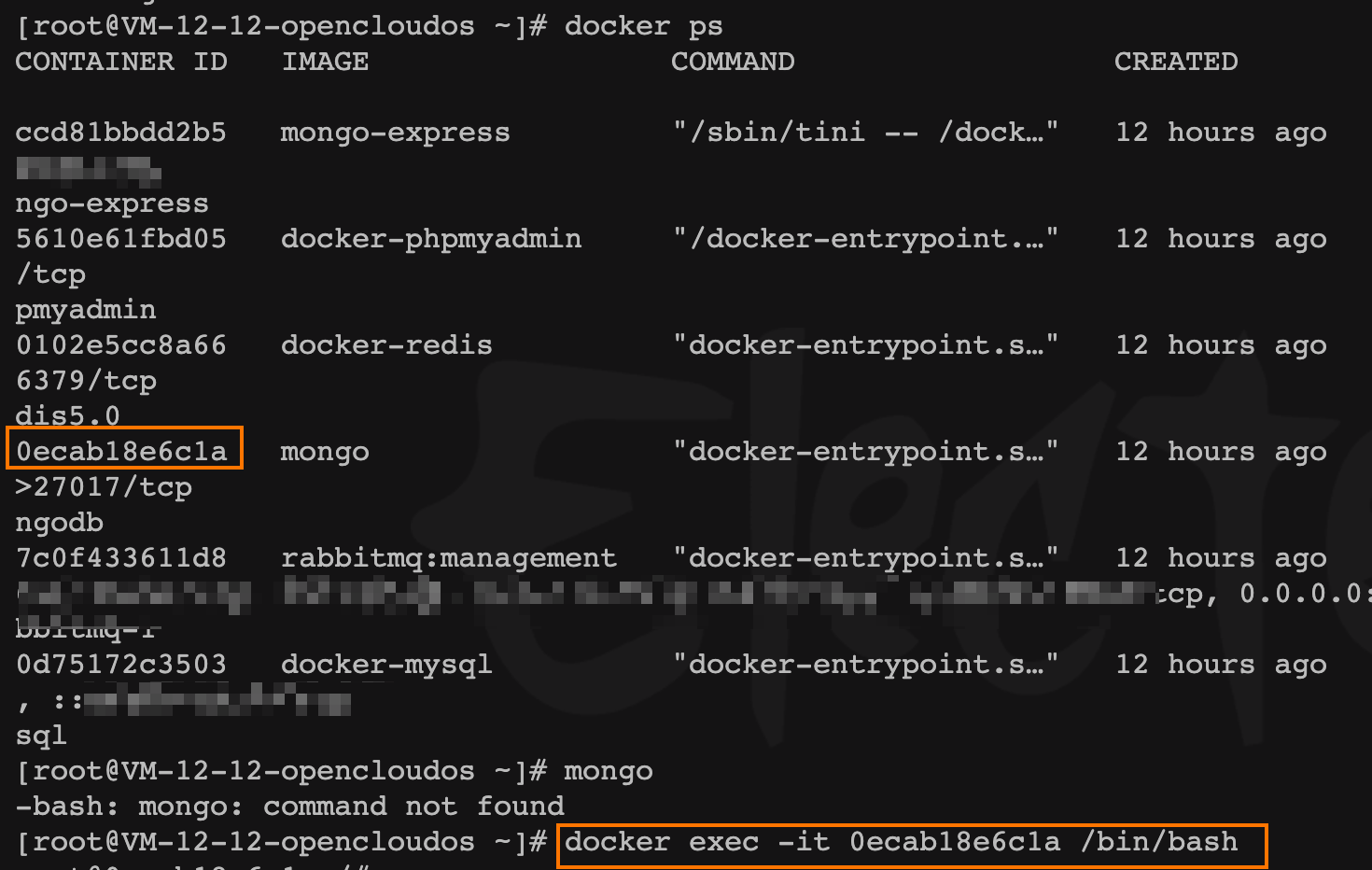
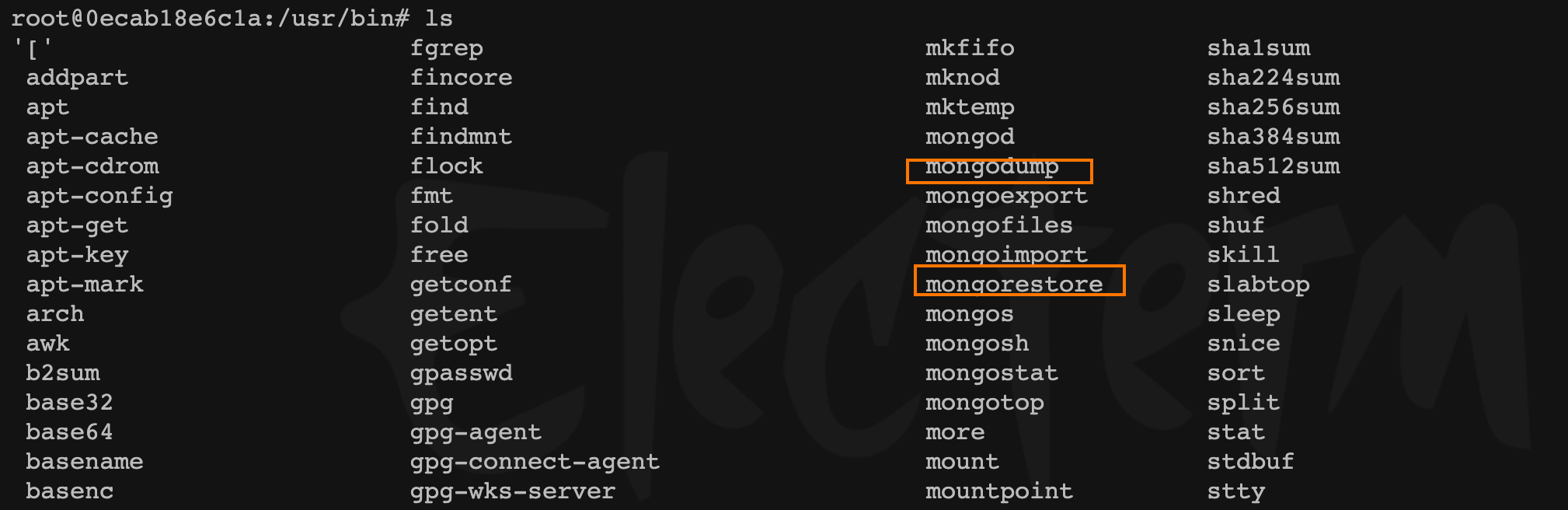
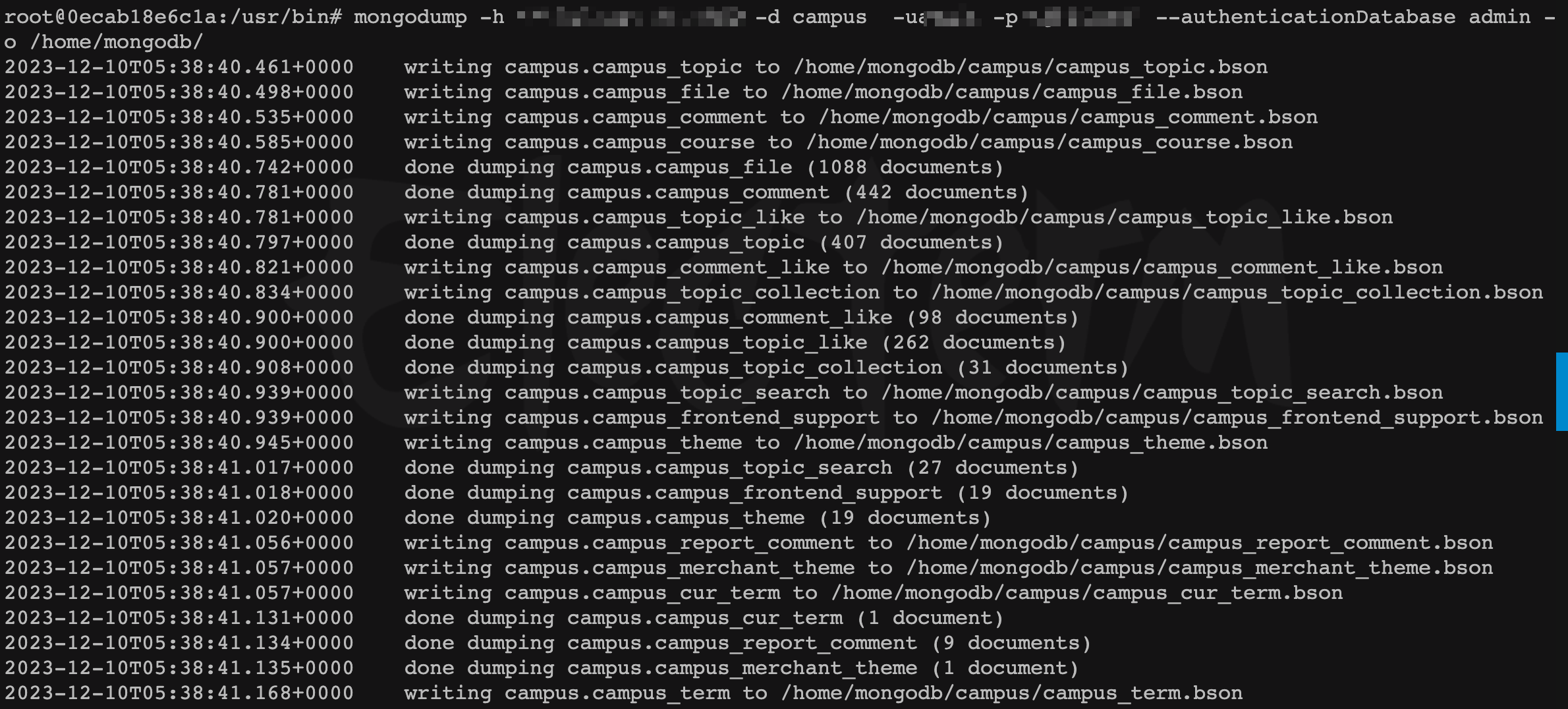
- 將遠程
mongo(舊的數據庫)數據備份到新機器容器內
mongodump -h <remote_ip>:<remote_port> -d <database> -u<user_name> -p<user_password> --authenticationDatabase admin -
o /home/mongodb/
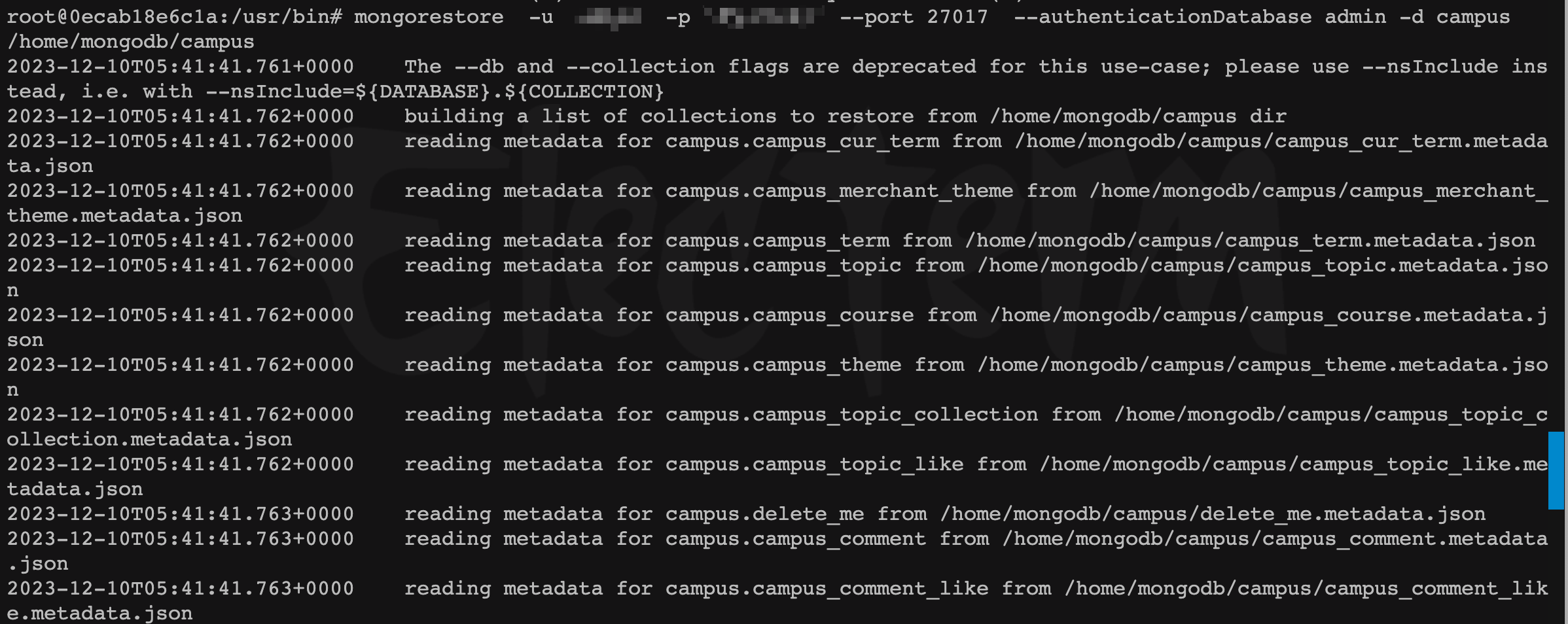
- 數據恢復到新
mongo
mongorestore -u <local_user_name> -p <user_password> --port 27017 --authenticationDatabase admin -d <database>
/home/mongodb/
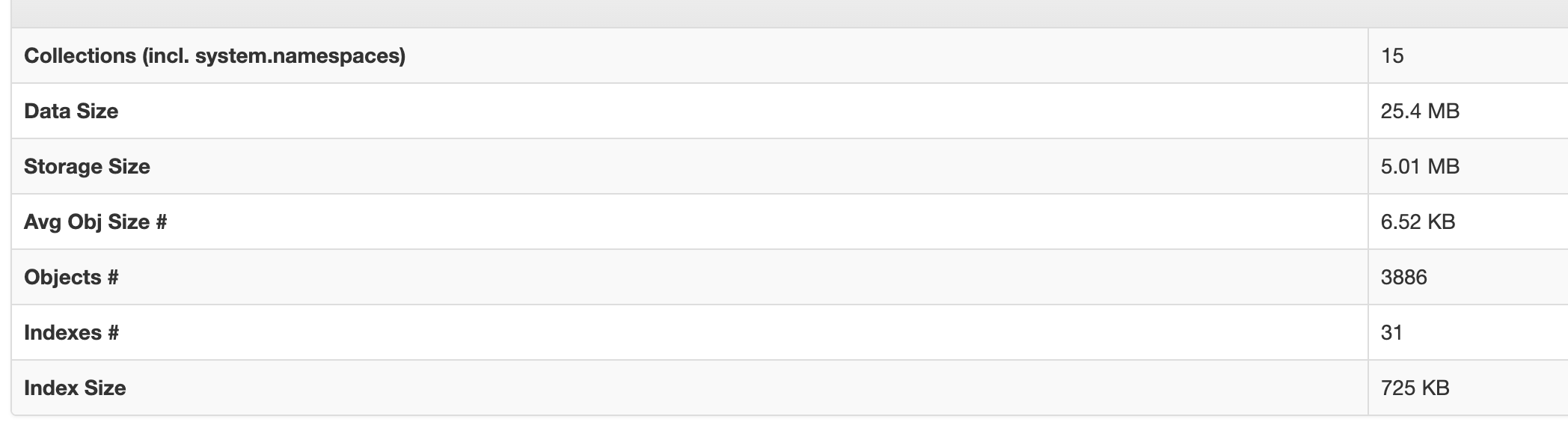
- 數據恢復結果
切換新數據庫 ip 本地服務啟動
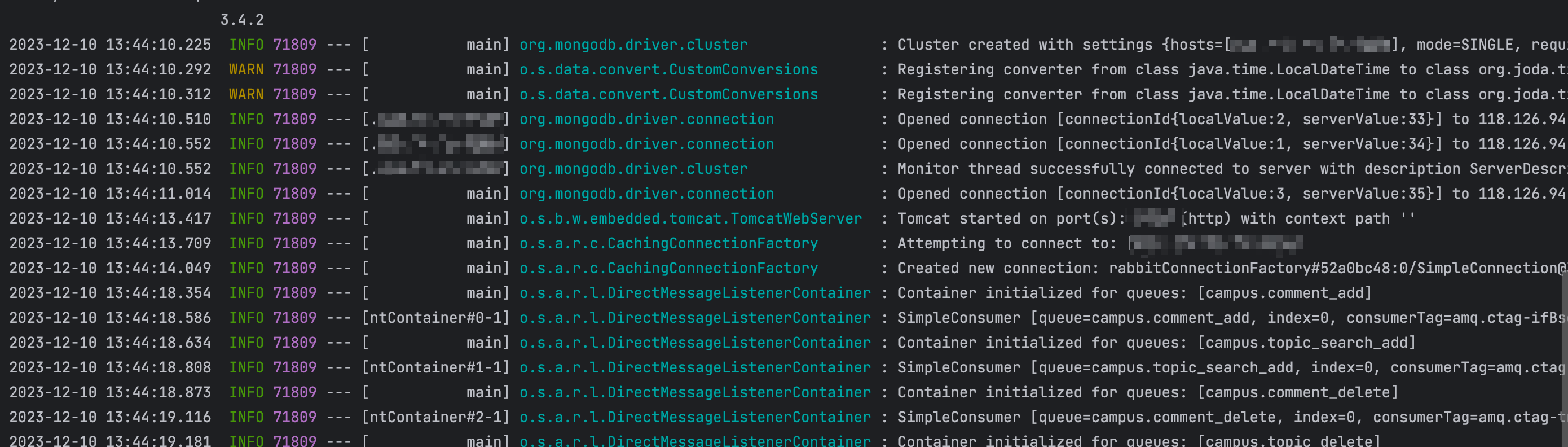
數據庫連接驗證
服務打包部署
mvn clean install package
服務重啟

前端恢復正常
監控腳本定時任務啟動
舊服務器器容器關閉
遷移總結
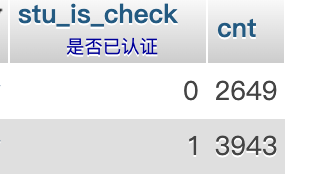
總涉及用戶 6592 個用戶,其中已通過校園認證的用戶 3943 ,全部數據遷移完畢,服務恢復于 13:47 總耗時約 17 分鐘。



覆蓋優化 - 附代碼)




)










