筆記來源于:
https://www.youtube.com/watch?v=phQK8xZpgoU&t=172s
https://www.youtube.com/watch?v=XLyPFnephpY&t=645s
Machine/Deep Learning
機器學習概況來說,讓機器具備自動找函式的能力 (Machine Learning 約等于 Looking for function)
三種機器學習: 回歸,分類,生成式學習
函數輸出來進行分類
1、 回歸: 韓式的輸出是一個數值
例子:預測明天的PM2.5值
2、分類:函式的輸出是一個類別(選擇題)
例子:email過濾垃圾郵件,讓機器做一個選擇題
輸入是郵件,輸出是垃圾郵件/不是垃圾郵件
機器學習有一個更困難的問題: 結構化學習(Structured Learning),讓機器生成有結構的物件,例如影像,文字,又叫生成式學習(Generative Learning)
結構化學習,生成式學習是一門很難的技術,不知道什么時候才能達到生成式學習
不知道什么時候才能到達暗黑大陸
ChatGPT是哪一類呢?
chatgpt實際做的事情: 文字接龍,模型解的是分類的問題
使用者感受到的功能: 一個字一個字生成,可能感受到的是生成式學習
實際上,chatgpt要解的是生成式學習這個問題做下簡化,拆解成多個分類問題
生成式學習有很多個策略,有哪些?
機器學習就是讓機器找一個函式,那機器怎么找?

歸納成三個步驟,比較好理解
前置作業: 決定要找什么樣的函式,這個和技術無關,取決于你要做什么樣的應用
例子: 寶可夢,提升戰斗力,或者判斷是否是寶可夢
1、 設定范圍
找出候選函數的集合,就是model
深度學習中,類神經網絡的結構,例如CNN,RNN,Transformer等,指的就是不同的函式集合
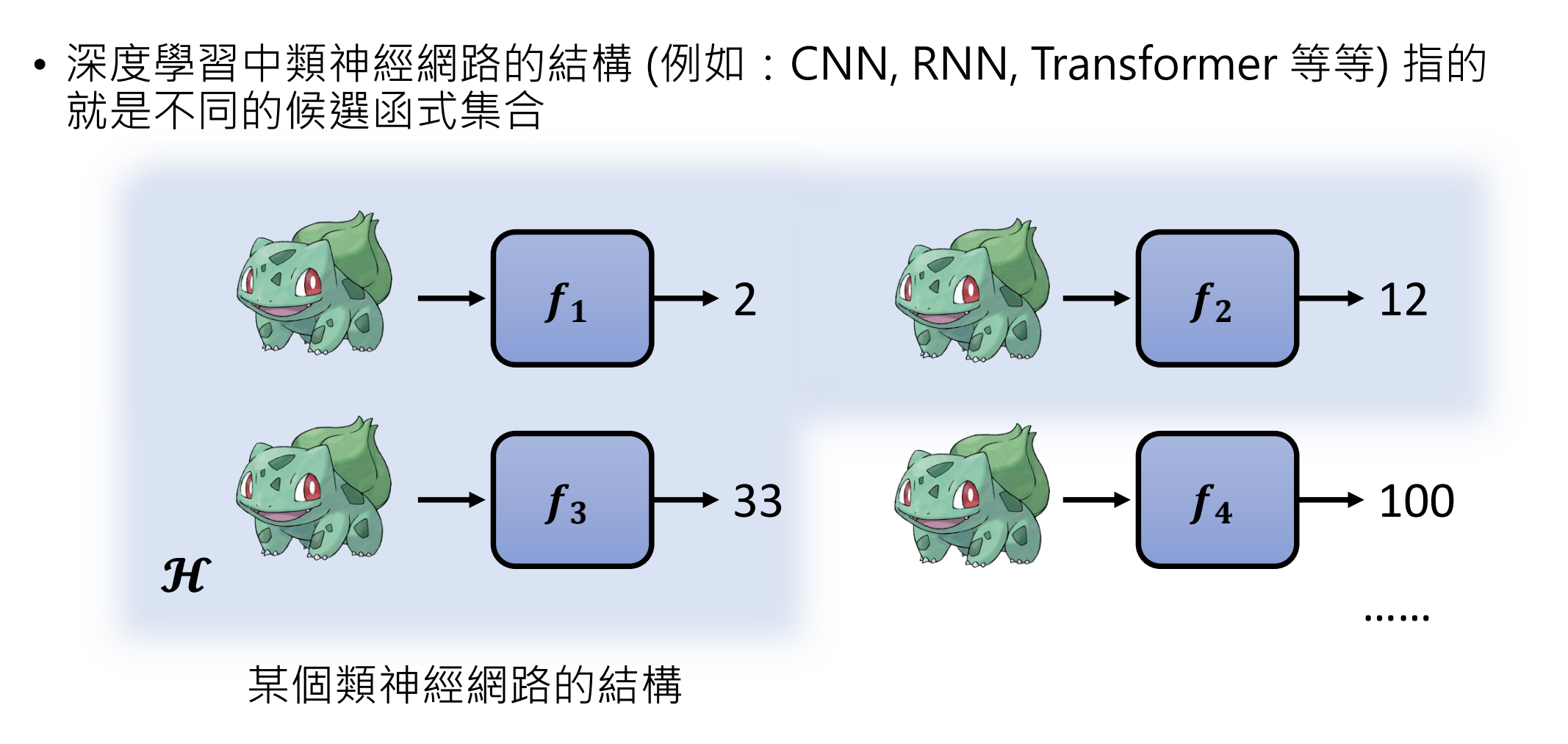
為什么類神經網絡的結構就是一個候選函式的集合?
視頻解析: https://www.youtube.com/watch?v=Dr-WRlEFefw
參考資料:https://ruanyifeng.com/blog/2017/07/neural-network.html
近年來,計算機視覺慢慢由CNN轉向transform的趨勢

step1: 這個function其實就是一個Neural network
我們把一個Logistic Regression 稱之為Neuron,整個稱之為Neural Network。 也就是一個Neural network里面包含一大堆的Logistic Regression
每個Logistic Regression,它都有自己的weight和自己的bias,這些weight和bias集合起來,就是這個network的parameter

如何去連接不同的Neuron network? Full Connect Feedforward Network
通過不同的連接方式,就得到了不同的structure
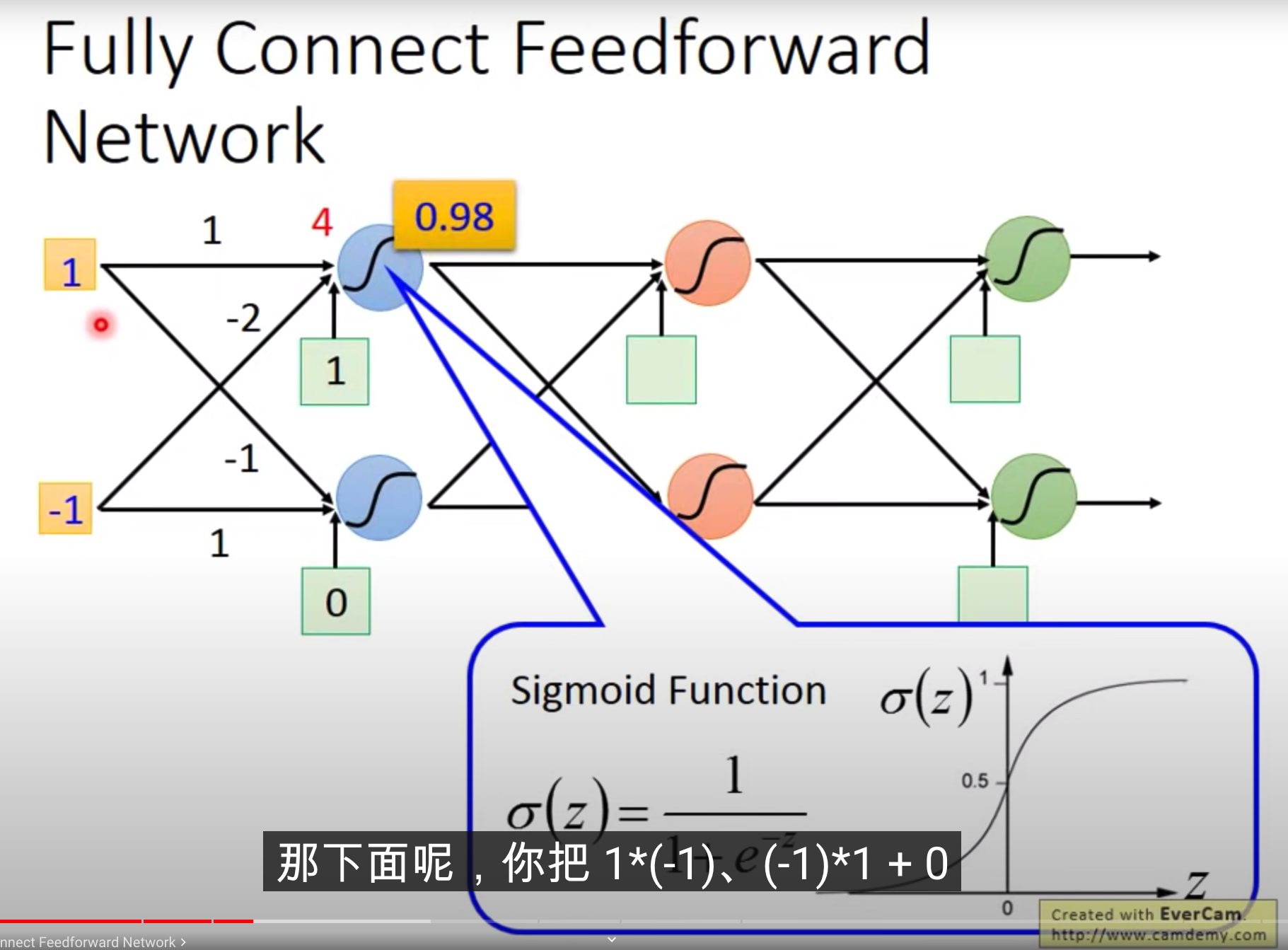
1*1+(-1)*(-2)再加上bias 1,通過sigmoid function以后,計算得到值

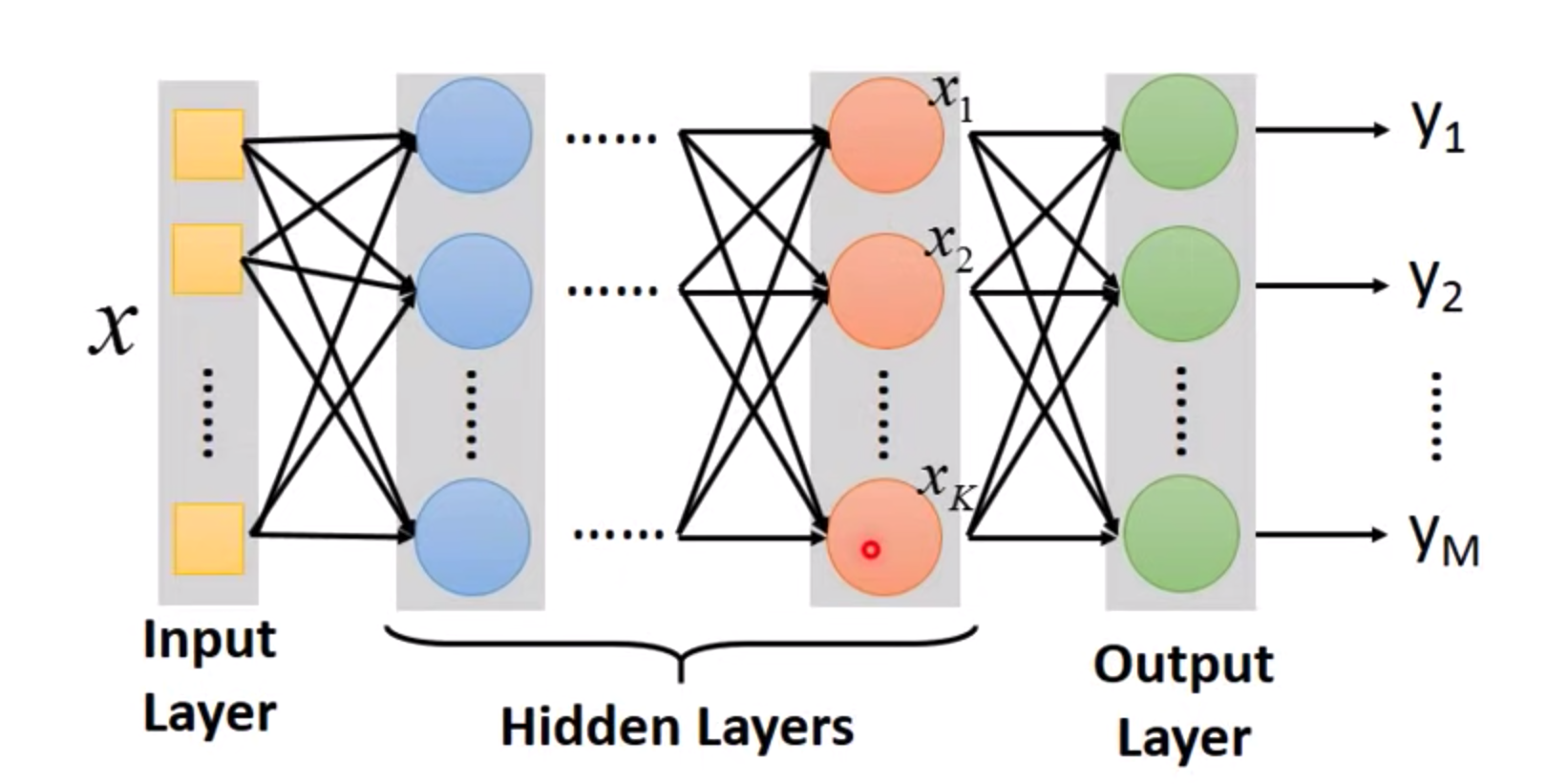
一個neural network你可以把它看作是一個function,input是一個vector,output也是一個vector
如果不知道參數 weight和bias,只是定出了這個network的structure,只是定義好了這個network怎么樣連接,
它其實就是定義了一個function set,我們可以給這個network設定不同的參數,它就變成了不同的function,把這些可能的function集合起來
我們就得到了一個function set

為什么我們要設定范圍? 為什么我們要選出候選函式的范圍? 為什么不把所有的函式納入進來?
1、標準訓練數據下,loss小,但是測試不好,例如是硬記答案,我們要找在各個環境都表現很好的函式。。。
2、 過濾掉不行的函式,所以一開始劃定范圍,不在這個范圍的直接淘汰,這個范圍也很有講究。。。
3、這個范圍選擇有標準的數學理論支撐,參見視頻:
卷積神經網絡:https://www.youtube.com/watch?v=OP5HcXJg2Aw
淺談機器學習原理:https://www.youtube.com/watch?v=_j9MVVcvyZI

2、 設定標準
設定一個評估函式好壞的標準
怎么設定一個最好的標準,loss越小,代表函數最好,loss越大,代表不好
這個loss設定怎么來呢? 自己來設置
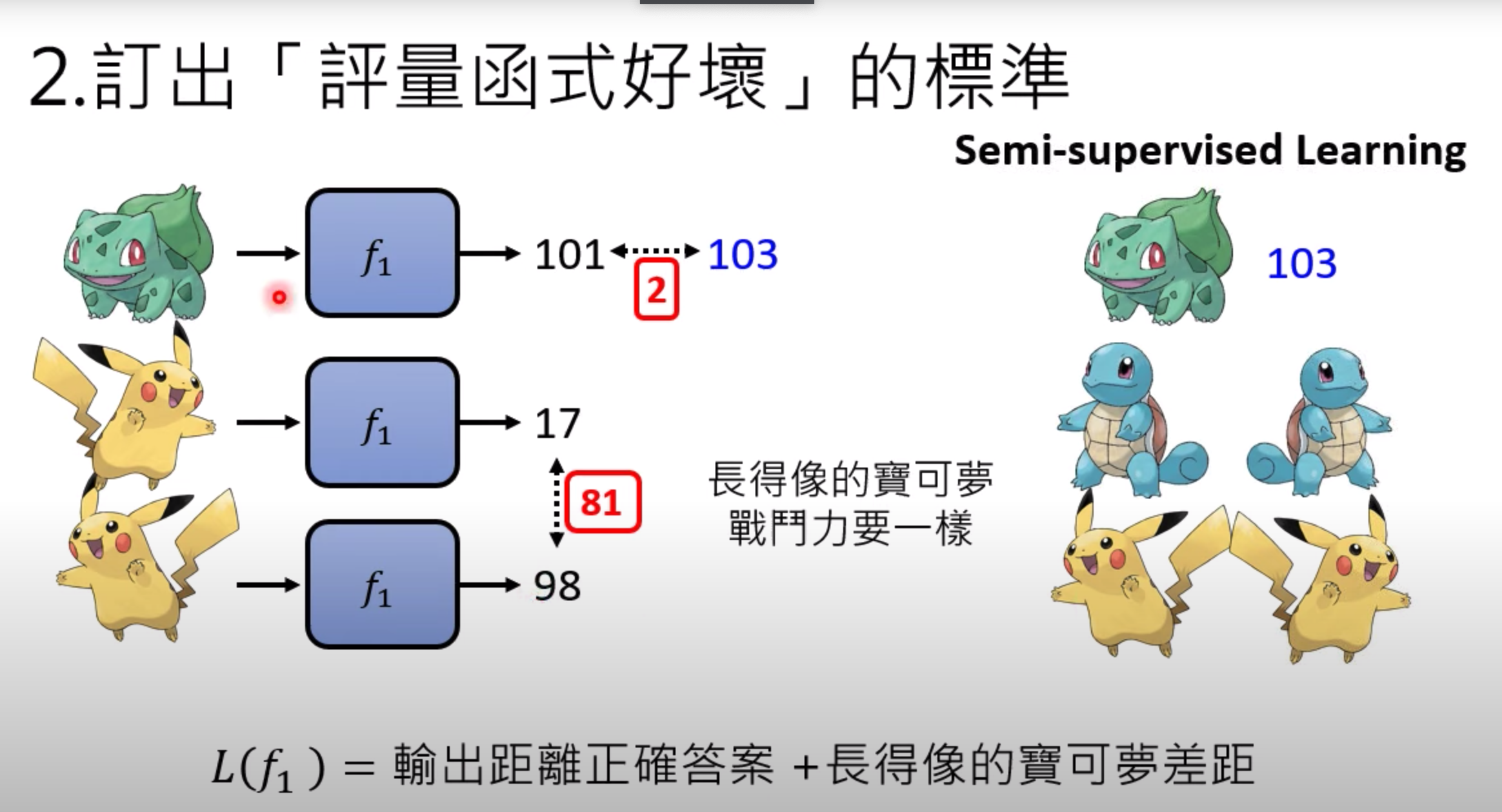
例子:寶可夢,戰斗力
專業人士設置標準答案,根據函式的輸出和標準答案的差距,所有的差距加起來代表函式的好壞

L(f1)=15 入參為函式,大L也是一個函式,用來計算函式的好壞
怎么樣來定義這個loss function?
假設有另外的情況,有部分的數據有標準答案,路邊抓過來一些寶可夢,那怎么來評估戰斗力?這種情況下
怎么來評估這些沒有正確標注的寶可夢的戰斗力?
第一步,把寶可夢丟到這個函式里面,如果有返回,則使用
沒有的話,我們可以定一些假設,長得像寶可夢的戰斗力要一樣
(那怎么定義長得像呢? 比如像素的相似度 這個你自己來根據資料來靈活定義)
一個好的函式,可以評估出沒有標注過的數據
問題: 在訓練數據上面評估的loss函數小,但是在訓練數據上面不一定好
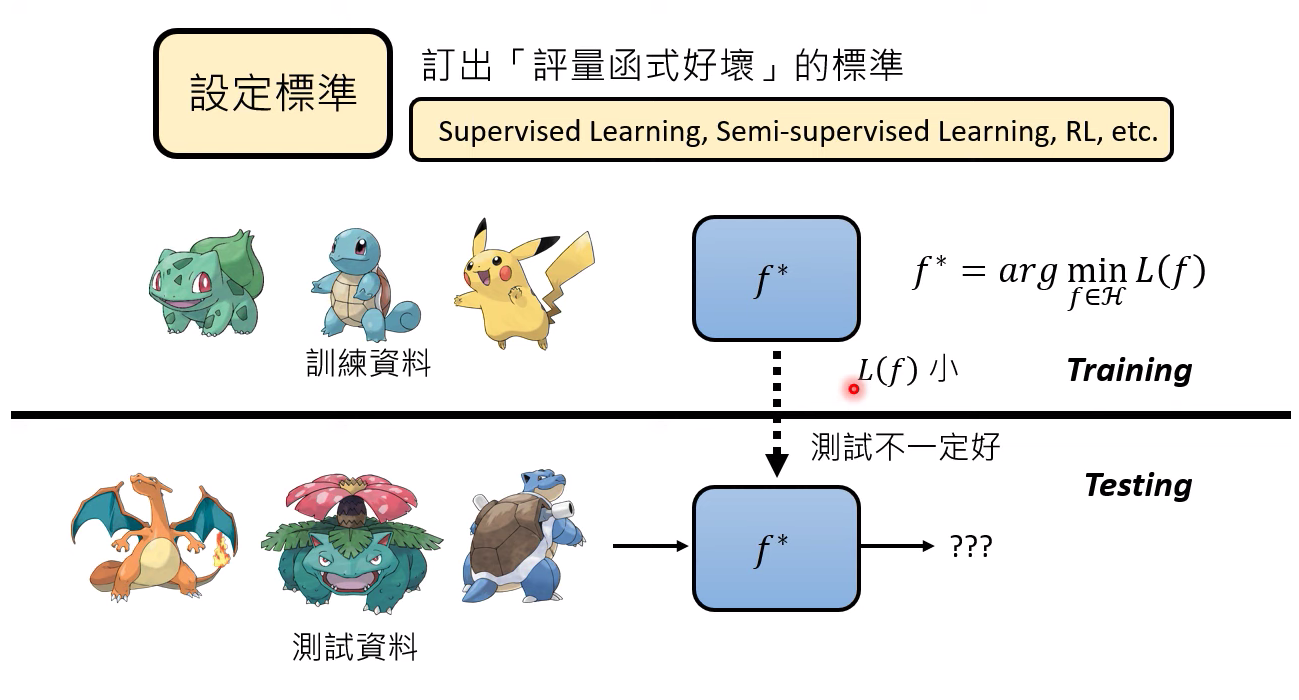
可能的原因是什么呢?
1、 數據量太小
2、有很多其他的理論知識。。。。
怎么解決?
我們在Loss上做一些額外的考量,如Regularization,具體做法原理視頻沒講。。。。。。。
3、 達成目標
找出最好的函式,什么叫做好呢? 就是上面的loss,loss越小,函式越好
這個找出函式最佳的方式叫做Optimization

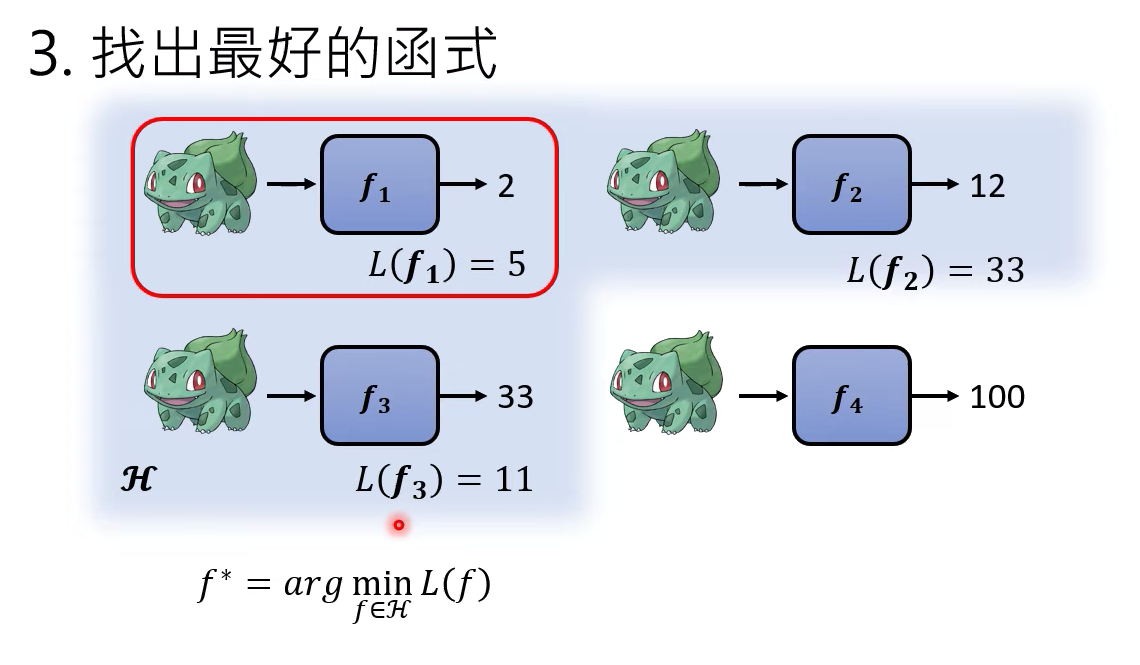
如何進一步去找最好評估的loss函式,可以學習下這幾個視頻。。。我沒來的及學習

最佳化演算法
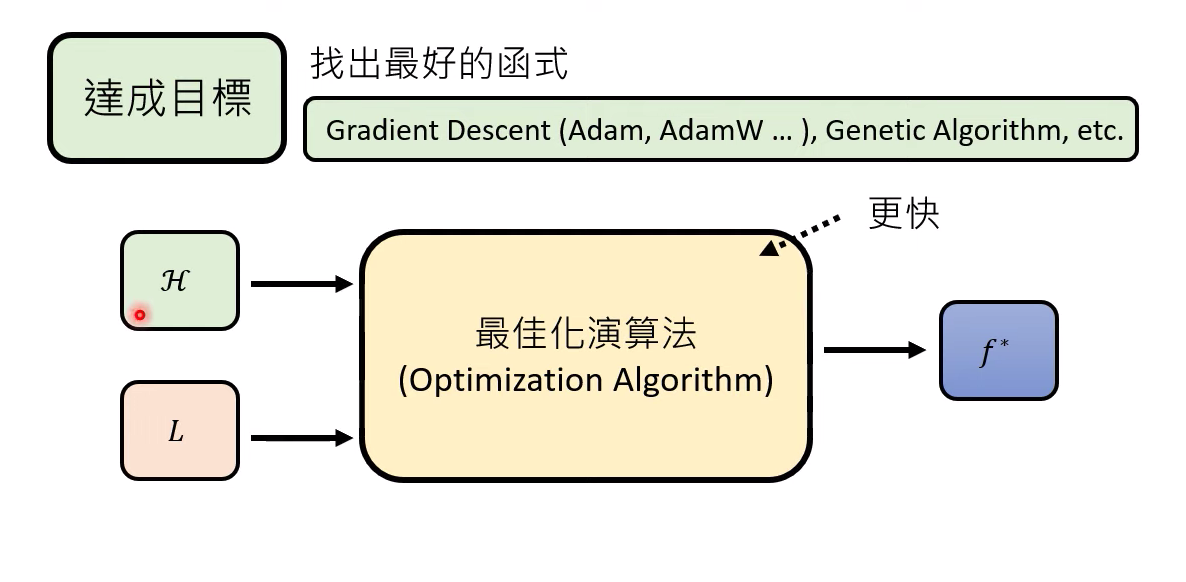
什么是達成目標比較好的方式?
把最佳化演算法看作一個巨大的funciton,輸入是定義好的函式集合 H和評估函式好壞的標準L,
輸出一個最好的函式,這個函式在大L里面的值越小越好
怎么評估這個function的好壞?
1、 我們期待這個function能夠在同樣輸入H和L的前提下,越快輸出越好
2、有時候需要L(f*)越小越好,但是通常找不出大L最低的function(不清楚為啥。。。。),但是我們期待最佳化演算法找出來的L(f*) 越低越好
我們需要先設定 Learning Rate,Batch Size,How to Init,這些就叫做超參數,純手工去調(技術活)
參數狗。。。 不是類神經網絡里面的參數

一個好的最佳化演算法,我們期待最佳化演算法對于超參數不敏感。。。。這樣就可以用預設值了
--------------------------------------------------------------------------------------------------------------------------------
覆蓋優化 - 附代碼)




)













