引言
緩存在日常開發中啟動至關重要的作用,由于是存儲在內存中,數據的讀取速度是非常快的,能大量減少對數據庫的訪問,減少數據庫的壓力。我們把緩存分為兩類:
分布式緩存,例如Redis:
優點:存儲容量更大、可靠性更好、可以在集群間共享
缺點:訪問緩存有網絡開銷
場景:緩存數據量較大、可靠性要求較高、需要在集群間共享
進程本地緩存,例如HashMap、GuavaCache:
優點:讀取本地內存,沒有網絡開銷,速度更快
缺點:存儲容量有限、可靠性較低、無法共享
場景:性能要求較高,緩存數據量較小
我們今天會利用Caffeine框架來實現JVM進程緩存。
初識Caffeine
Caffeine是一個基于Java8開發的,提供了近乎最佳命中率的高性能的本地緩存庫。目前Spring內部的緩存使用的就是Caffeine。GitHub地址:GitHub - ben-manes/caffeine: A high performance caching library for Java
Caffeine的性能非常好,下圖是官方給出的性能對比:
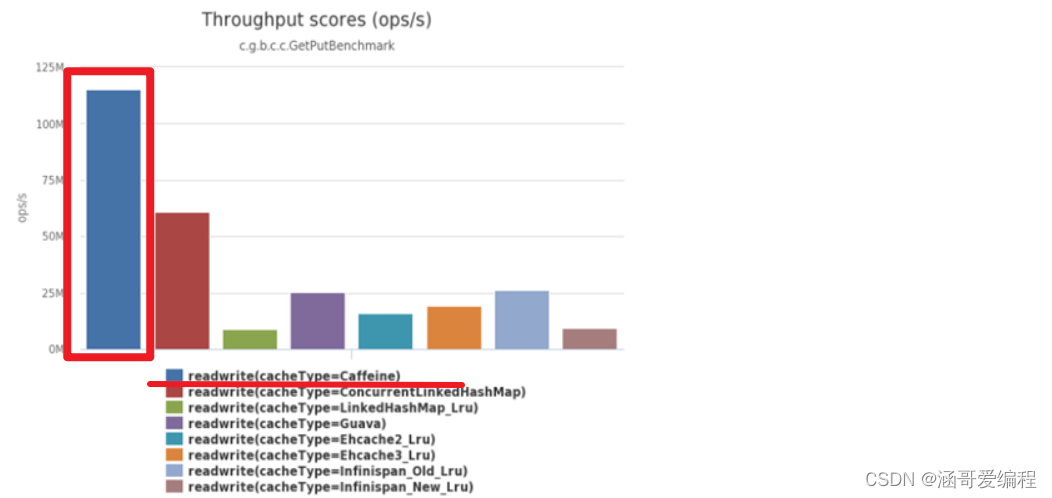
可以看到Caffeine的性能遙遙領先!
基本使用
首先導入依賴:
<dependency><groupId>com.github.ben-manes.caffeine</groupId><artifactId>caffeine</artifactId><version>2.7.0</version>
</dependency>@Test
void testBasicOps() {// 構建cache對象Cache<String, String> cache = Caffeine.newBuilder().build();// 存數據cache.put("gf", "迪麗熱巴");// 取數據String gf = cache.getIfPresent("gf");System.out.println("gf = " + gf);// 取數據,包含兩個參數:// 參數一:緩存的key// 參數二:Lambda表達式,表達式參數就是緩存的key,方法體是查詢數據庫的邏輯// 優先根據key查詢JVM緩存,如果未命中,則執行參數二的Lambda表達式String defaultGF = cache.get("defaultGF", key -> {// 根據key去數據庫查詢數據return "柳巖";});System.out.println("defaultGF = " + defaultGF);// 刪除緩存cache.invalidate("gf");
}Caffeine既然是緩存的一種,肯定需要有緩存的清除策略,不然的話內存總會有耗盡的時候。
三種緩存驅逐策略
-
基于容量:設置緩存的數量上限
// 創建緩存對象 Cache<String, String> cache = Caffeine.newBuilder().maximumSize(1) // 設置緩存大小上限為 1.build(); -
基于時間:設置緩存的有效時間
// 創建緩存對象 Cache<String, String> cache = Caffeine.newBuilder()// 設置緩存有效期為 10 秒,從最后一次寫入開始計時 .expireAfterWrite(Duration.ofSeconds(10)) .build(); -
基于引用:設置緩存為軟引用或弱引用,利用GC來回收緩存數據。性能較差,不建議使用。
注意:在默認情況下,當一個緩存元素過期的時候,Caffeine不會自動立即將其清理和驅逐。而是在一次讀或寫操作后,或者在空閑時間完成對失效數據的驅逐。
制作不易,喜歡的可以支持一下,每日都會分享編程知識!
)


















