ControlNet從原理到實戰
- ControlNet原理
- ControlNet應用于大型預訓練擴散模型
- ControlNet訓練過程
- ControlNet示例
- 1 `ControlNet`與`Canny Edge`
- 2. `ControlNet`與`Depth`
- 3. `ControlNet`與`M-LSD Lines`
- 4. `ControlNet`與`HED Boundary`
- ControlNet實戰
- Canny Edge實戰
- Open Pose
- 小結
- 參考資料
ControlNet是一種通過添加額外條件來控制擴散模型的神經網絡結構。它提供了一種增強穩定擴散的方法,在文本到圖像生成過程中使用條件輸入,如涂鴉、邊緣映射、分割映射、pose關鍵點等。可以讓生成的圖像將更接近輸入圖像,這比傳統的圖像到圖像生成方法有了很大的改進。

論文地址:https://arxiv.org/pdf/2302.05543.pdf
代碼地址:https://github.com/lllyasviel/ControlNet
WebUI extention for ControlNet: https://github.com/Mikubill/sd-webui-controlnet
論文核心:本文介紹了 ControlNet,這是一種端到端的神經網絡架構,用于學習大型預訓練文本到圖像擴散模型(在我們的實現中為 Stable Diffusion)的條件控制。 **ControlNet 通過鎖定大型預訓練模型的參數并復制其編碼層,保留了該大型模型的質量和能力。這種架構將大型預訓練模型視為學習各種條件控制的強大主干網絡。**可訓練的副本和原始鎖定的模型通過零卷積層連接,權重初始化為零,以便在訓練過程中逐漸增長。這種架構確保在訓練開始時不會向大型擴散模型的深層特征添加有害噪聲,并保護可訓練副本中的大型預訓練主干網絡免受此類噪聲的破壞。
關鍵點:
(1)提出了ControlNet,這是一種神經網絡架構,可以通過有效的微調將空間局部化的輸入條件添加到預訓練的文本到圖像擴散模型中。
(2)展示了預訓練的ControlNets以控制Stable Diffusion,其條件包括Canny邊緣、霍夫線、用戶涂鴉、人體關鍵點、分割圖、形狀法線、深度以及卡通線條繪圖;
(3)通過與幾種替代架構進行比較的消融實驗來驗證該方法的有效性。
ControlNet原理
ControlNet的基本結構如下所示:
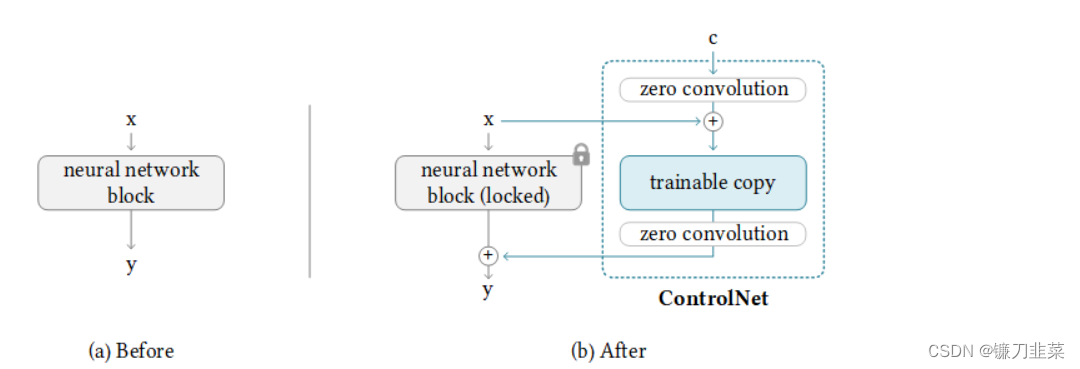
從圖中可以看出,ControlNet的基本結構由一個對應的原先網絡的神經網絡模塊和兩個“零卷積”層組成。在之后的訓練過程中,會“鎖死”原先網絡的權重,只更新ControlNet基本結構中的網絡“副本”和零卷積層的權重。這些可訓練的網絡“副本”將學會如何讓模型按照新的控制條件來生成結果,而被“鎖死”的網絡則會保留原先網絡已經學會的所有知識。這樣即使用來訓練ControlNet的訓練集規模較小,被“鎖死”網絡原本的權重也能確保擴散模型本身的生成效果不受影響。
ControlNet基本結構中的零卷積層是一些權重和偏置都被初始化為0的1×1卷積層。訓練剛開始的時候,無論新添加的控制條件是什么,這些零卷積層都只輸出0,因此ControlNet不會對擴散模型的生成結果造成任何影響。但隨著訓練過程的深入,ControlNet將學會逐漸調整擴散模型原先的生成過程,使得生成的圖像逐漸向新添加的控制條件靠近。
問題1:如果一個卷積層的所有參數都為0,輸出結果也為0,那么它怎么才能正常進行權重的迭代呢?
假設有一個簡單的神經網絡層: y = w x + b y=wx+b y=wx+b,已知 ? y ? w = x , ? y ? x = w , ? y ? b = 1 \frac{\partial y}{\partial w}=x,\frac{\partial y}{\partial x}=w,\frac{\partial y}{\partial b}=1 ?w?y?=x,?x?y?=w,?b?y?=1,假設權重 w w w為0,輸入x不為0,則有: ? y ? w ≠ 0 , ? y ? x = 0 , ? y ? b ≠ 0 \frac{\partial y}{\partial w}\ne 0,\frac{\partial y}{\partial x}=0,\frac{\partial y}{\partial b}\ne 0 ?w?y?=0,?x?y?=0,?b?y?=0這意味著只要輸入x不為0,梯度下降的迭代過程就能正常地更新權重 w w w,使 w w w不再為0,于是得到: ? y ? x ≠ 0 \frac{\partial y}{\partial x}\ne 0 ?x?y?=0即,在經過若干迭代之后,這些零卷積層將逐漸變成具有正常權重的普通卷積層。
ControlNet應用于大型預訓練擴散模型
以Stable Diffusion為例,介紹如何將ControlNet應用于大型預訓練擴散模型以實現條件控制。Stable Diffusion本質上是一個U-Net,包含編碼器、中間塊和跳連接解碼器。編碼器和解碼器都包含12個塊,而整個模型包含25個塊,包括中間塊。在這25個塊中,8個塊是下采樣或上采樣卷積層,而其他17個塊是主塊,每個主塊包含4個ResNet層和2個Vision Transformer(ViT)。每個ViT包含幾個交叉注意力和自注意力機制。如下圖所示:
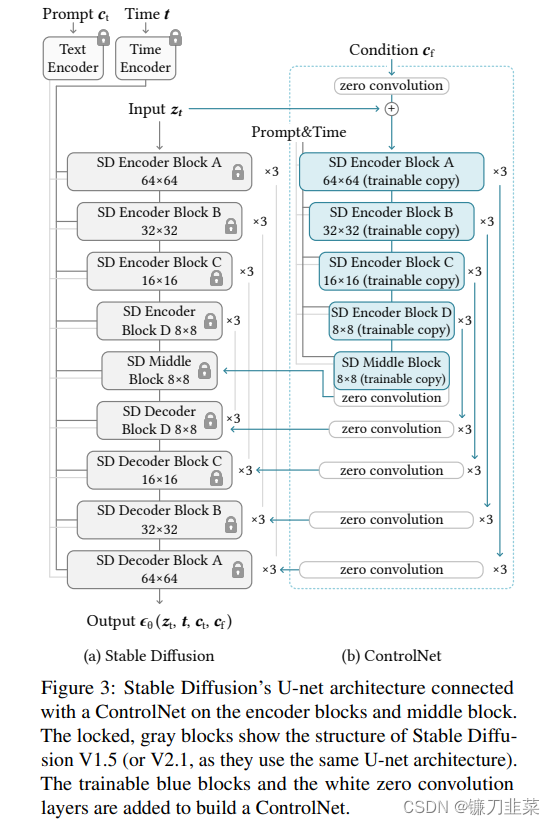
“SD Encoder Block A”包含4個ResNet層和2個ViT,而“×3”表示該塊重復三次。文本提示使用CLIP文本編碼器進行編碼,擴散時間步使用帶有位置編碼的時間編碼器進行編碼。
將ControlNet結構應用于U-Net的每個編碼器級別(圖3b)。具體而言,使用ControlNet創建Stable Diffusion的12個編碼塊和1個中間塊的訓練副本。12個編碼塊分布在4個分辨率(64×64, 32×32,16×16,8×8)中,每個分辨率復制3次。輸出被添加到U-Net的12個跳連接和1個中間塊中。由于Stable Diffusion是典型的U-Net結構,這種ControlNet架構可能適用于其他模型。
這種連接ControlNet的方式在計算上是高效的——由于鎖定副本的參數被凍結,在微調過程中,原始鎖定編碼器不需要進行梯度計算。這種方法加快了訓練速度并節省GPU內存。
ControlNet實際上使用訓練完成的Stable Diffusion模型的編碼器模塊作為自己的主干網絡,而這樣一個穩定又強大的主干網絡,則保證了ControlNet能夠學習到更多不同的控制圖像生成的方法。
ControlNet訓練過程
給定一個輸入圖像 z 0 z_0 z0?,圖像擴散算法會逐步向圖像添加噪聲,并生成一個噪聲圖像 z t z_t zt?,其中 t t t表示添加噪聲的次數。給定一組條件,包括時間步 t t t、文本提示 c t c_t ct?以及特定于任務的條件 c f c_f cf?,圖像擴散算法會學習一個網絡 ? θ \epsilon _\theta ?θ?來預測添加到噪聲圖像 z t z_t zt?上的噪聲,公式如下:
L = E z 0 , t , c t , c f , ? ~ N ( 0 , 1 ) [ ∣ ∣ ? ? ? θ ( z t , t , c t , c f ) ∣ ∣ 2 2 ] \mathcal{L}=\mathbb{E}_{z_0,t,c_t,c_f,\epsilon \sim \mathcal{N}(0,1)}[||\epsilon -\epsilon _{\theta}(z_t,t,c_t,c_f)||_2^2] L=Ez0?,t,ct?,cf?,?~N(0,1)?[∣∣???θ?(zt?,t,ct?,cf?)∣∣22?]
其中 L \mathcal{L} L是整個擴散模型的總體學習目標。該學習目標直接用于利用 ControlNet 對擴散模型進行微調。
訓練一個附加到某個Stable Diffusion模型上的ControlNet的過程大致如下:
(1)收集想要對其附加控制條件的數據集和對應的Prompt。假如想訓練一個通過人體關鍵點來對擴散模型生成的人體進行姿態控制的ControlNet,則首先需要收集一批人物圖片,并標注好這批人物圖片的Prompt以及對應的人體關鍵點的位置。
(2)將Prompt輸入被“鎖死”的Stable Diffusion模型,并將標注好的圖像控制條件(如人體關鍵點的標注結果)輸入ControlNet,然后按照穩定擴散模型的訓練過程迭代ControlNet block的權重。
(3)在訓練過程中,隨機地將50%的文本提示語替換為空白字符串,這樣做旨在“強制”網絡從圖像控制條件中學習更多的語義信息。
(4)訓練結束后,便可以使用ControlNet對應的圖像控制條件(如輸入的人體關鍵點)來控制擴散模型生成符合條件的圖像。
在訓練過程中,隨機用空字符串替換50%的文本提示 c t c_t ct?。這種方法提高了ControlNet直接從輸入條件圖像中識別語義(例如邊緣、姿態、深度等)的能力,作為提示的替代。在訓練過程中,由于零卷積不會給網絡添加噪聲,模型應該始終能夠預測高質量的圖像。我們觀察到模型并沒有逐漸學習控制條件,而是在優化步驟少于10K時突然成功地遵循輸入條件圖像。如下圖所示,稱這種現象為“突然收斂現象”。

圖4:突然收斂現象。 由于零卷積,ControlNet 在整個訓練過程中始終預測高質量的圖像。 在訓練過程中的某個步驟(例如,以粗體標記的 6133 個步驟),模型突然學會遵循輸入條件。
ControlNet示例
本小節將介紹一些已經訓練好的ControlNet示例,都來自Huggingface。
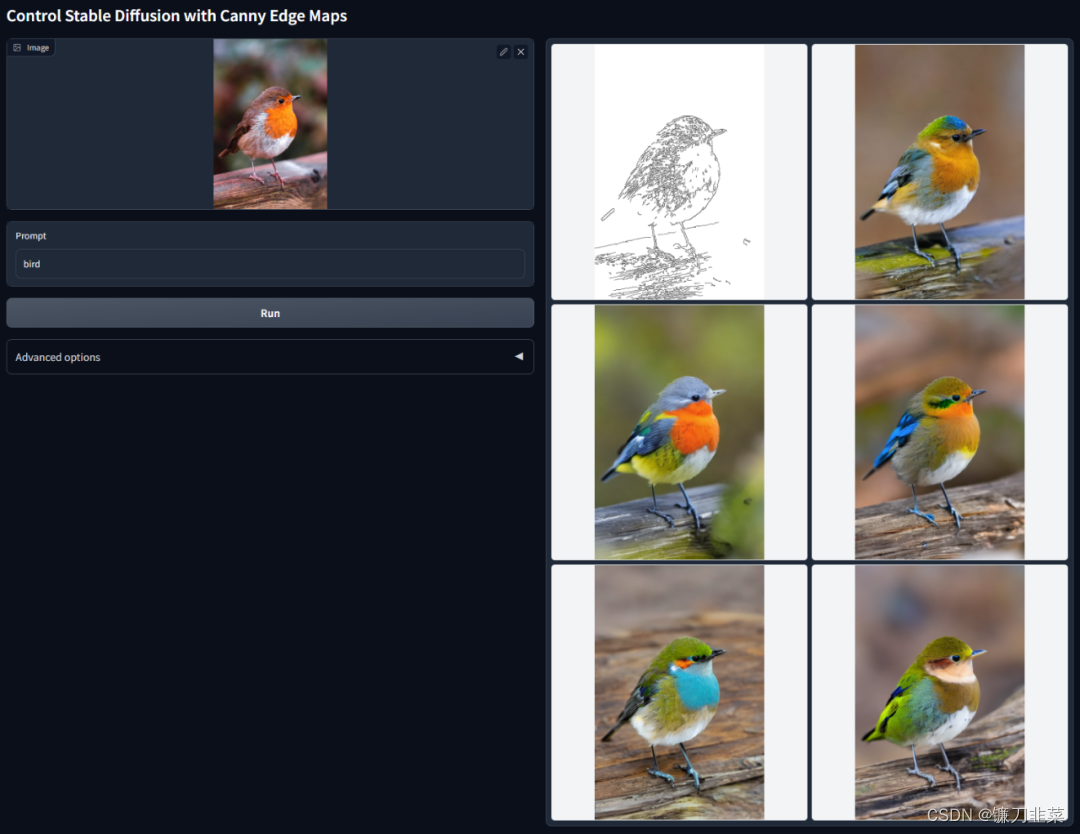
1 ControlNet與Canny Edge
Canny Edege是一種多階段的邊緣檢測算法,該算法可以從不同的視覺對象中提取有用的結構信息,從而顯著降低圖像處理過程中的數據處理量,ControlNet與Canny Edge結合使用的效果如下圖所示:
2. ControlNet與Depth
ControlNet 深度預處理器是用于處理圖像中的深度信息的工具。它可以用于計算圖像中物體的距離、深度圖等。Depth map是跟原圖大小一樣的存儲了深度信息的灰色尺度( gray scale )圖像,白色表示圖像距離更近,黑色表示距離更遠。
-
MiDaS深度信息估算
MiDaS 深度信息估算,是用來控制空間距離的,類似生成一張深度圖。一般用在較大縱深的風景,可以更好表示縱深的遠近關系。 -
LeReS深度信息估算
LeReS 深度信息估算比 MiDaS 深度信息估算方法的成像焦點在中間景深層,這樣的好處是能有更遠的景深,其中距離物品邊緣成像會更清晰,但近景圖像的邊緣會比較模糊,具體實戰中需用哪個估算方法可根據需要靈活選擇。
示例:通過提取原始圖像中的深度信息,可以生成具有同樣深度結構的圖。

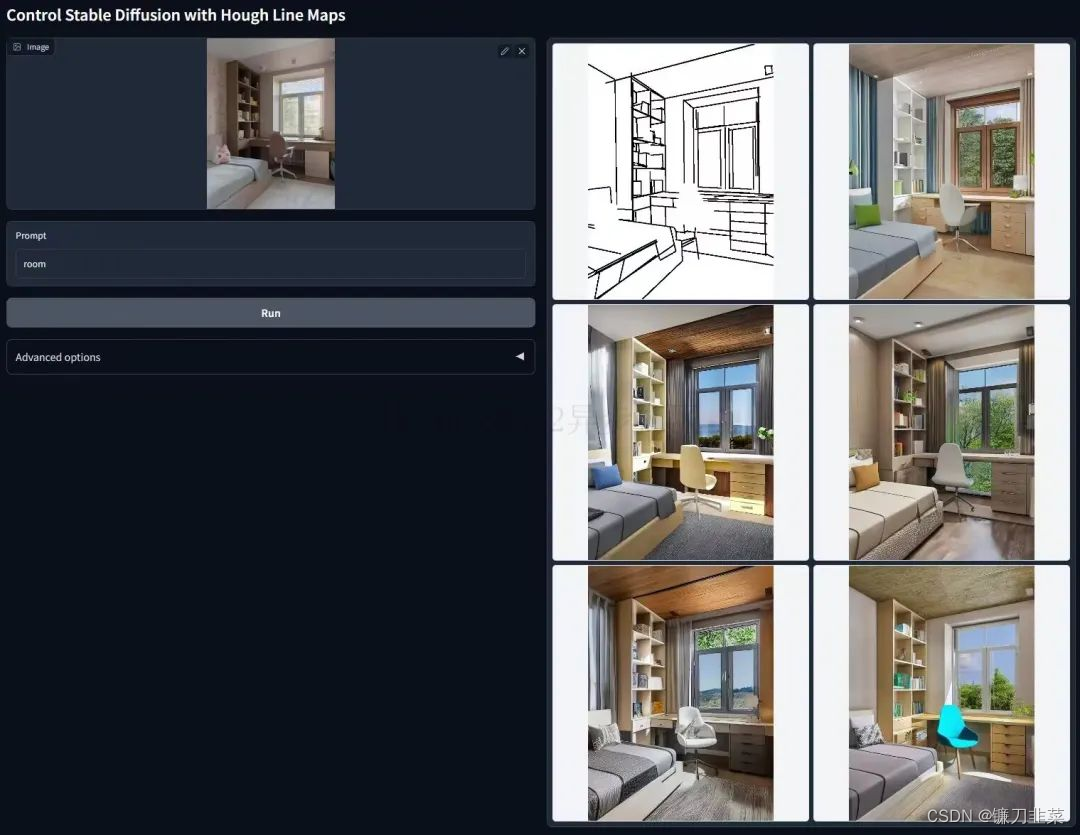
3. ControlNet與M-LSD Lines
M-LSD Lines是另一種輕量化的邊緣檢測算法,擅長提取圖像中的直線線條。訓練在M-LSD Lines上的ControlNet適合室內環境方面的圖片。ControlNet與M-LSD Lines結合使用的效果,如下圖所示:
4. ControlNet與HED Boundary
HED Boundary可以保持輸入圖像更多信息,訓練在HED Boundary上的ControlNet適合用來重新上色和進行風格重構。ControlNet與HED Boundary結合使用的效果,如下圖所示:

除了以上這些,ControlNet還可以:
- 訓練在涂鴉畫上的ControlNet能讓Stable Diffusion模型學會如何將兒童涂鴉轉繪成高質量的圖片。
- 訓練在人體關鍵點上的ControlNet能讓擴散模型學會生成指定姿態的人體。
- 語義分割模型旨在提取圖像中各個區域的語義信息,常用來對圖像中的人體、物體、背景區域等進行劃分。訓練在語義分割數據上的ControlNet能讓穩定擴散模型生成特定結構的場景圖。
- 諸如深度圖、Normal Map、人臉關鍵點等,同樣可以使用ControlNet。
ControlNet實戰
ControlNet 模型可以在使用小數據集進行訓練。然后整合任何預訓練的穩定擴散模型來增強模型,來達到微調的目的。ControNet 的初始版本帶有以下預訓練權重。
Canny edge— 黑色背景上帶有白色邊緣的單色圖像。Depth/Shallow areas— 灰度圖像,黑色代表深區域,白色代表淺區域。Normal map— 法線貼圖圖像。Semantic segmentation map——ADE20K 的分割圖像。HED edge— 黑色背景上帶有白色軟邊緣的單色圖像。Scribbles— 黑色背景上帶有白色輪廓的手繪單色涂鴉圖像。OpenPose(姿勢關鍵點)— OpenPose 骨骼圖像。M-LSD— 僅由黑色背景上的白色直線組成的單色圖像。
Canny Edge實戰
安裝需要的庫:
!pip install -q diffusers transformers xformers git+https://github.com/huggingface/accelerate.git
為了對應選擇的ControlNet,還需要安裝兩個依賴庫來對圖像進行處理,以提取不同的圖像控制條件:
!pip install -q opencv-contrib-python
!pip install -q controlnet_aux
圖像示例:
from diffusers import StableDiffusionControlNetPipeline
from diffusers.utils import load_imageimage = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/input_image_vermeer.png")
image

首先,使用這張圖片發送給Canny Edge邊緣提取器,預處理一下:
import cv2
from PIL import Image
import numpy as npimage = np.array(image)low_threshold = 100
high_threshold = 200# 提取圖片邊緣線條
image = cv2.Canny(image, low_threshold, high_threshold)
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
canny_image = Image.fromarray(image)
canny_image

接下來,載入runwaylml/stable-diffusion-v1-5模型以及能夠處理Canny Edge的ControlNet模型。同時,為了節約計算資源以及加快推理速度,決定使用半精度(torch.dtype)的方式來讀取模型:
# 使用半精度節約計算資源,加快推理速度
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel
import torchdevice = "cuda" if torch.cuda.is_available() else "cpu"
print(device)
controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float32).to(device)
pipe = StableDiffusionControlNetPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float32).to(device)
然后,使用當前速度最快的擴散模型調度器——UniPCMultistepScheduler。該調度器能顯著提高模型的推理速度。
# 使用速度最快的擴散模型調度器UniPCMultistepScheduler
from diffusers import UniPCMultistepSchedulerpipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
定義一個圖片顯示布局的函數:
def image_grid(imgs, rows, cols):assert len(imgs) == rows * colsw, h = imgs[0].sizegrid = Image.new("RGB", size=(cols * w, rows * h))grid_w, grid_h = grid.sizefor i, img in enumerate(imgs):grid.paste(img, box=(i % cols * w, i // cols * h))return grid
生成一些人物肖像,這些肖像與上面的圖片姿勢一樣:
prompt = ", best quality, extremely detailed"
prompt = [t + prompt for t in ["Sandra Oh", "Kim Kardashian", "rihanna", "taylor swift"]]
generator = [torch.Generator(device=device).manual_seed(2) for i in range(len(prompt))]output = pipe(prompt,canny_image,negative_prompt=["monochrome, lowres, bad anatomy, worst quality, low quality"] * len(prompt),generator=generator,num_inference_steps=30,
)image_grid(output.images, 2, 2)

Open Pose
第二個有趣的應用是從一張圖片中提取身體姿態,然后用它生成具有完全相同的身體姿態的另一張圖片。這里使用Open Pose ControlNet做姿態遷移。
首先,下載一些瑜伽圖片:
urls = ["yoga1.jpeg", "yoga2.jpeg", "yoga3.jpeg", "yoga4.jpeg"]
imgs = [load_image("https://huggingface.co/datasets/YiYiXu/controlnet-testing/resolve/main/" + url) for url in urls]
image_grid(imgs, 2, 2)

補充:安裝mediapipe
!pip install mediapipe
MediaPipe 是一款由 Google Research 開發并開源的多媒體機器學習模型應用框架。在谷歌,一系列重要產品,如 YouTube、Google Lens、ARCore、Google Home 以及 Nest,都已深度整合了 MediaPipe。MediaPipe大有用武之地,可以做物體檢測、自拍分割、頭發分割、人臉檢測、手部檢測、運動追蹤,等等。基于此可以實現更高級的功能。
MediaPipe 的核心框架由 C++ 實現,并提供 Java 以及 Objective C 等語言的支持。MediaPipe 的主要概念包括數據包(Packet)、數據流(Stream)、計算單元(Calculator)、圖(Graph)以及子圖(Subgraph)。
- 數據包是最基礎的數據單位,一個數據包代表了在某一特定時間節點的數據,例如一幀圖像或一小段音頻信號;
- 數據流是由按時間順序升序排列的多個數據包組成,一個數據流的某一特定時間戳(Timestamp)只允許至多一個數據包的存在;而數據流則是在多個計算單元構成的圖中流動。
- MediaPipe 的圖是有向的——數據包從數據源(Source Calculator或者 Graph Input Stream)流入圖直至在匯聚結點(Sink Calculator 或者 Graph Output Stream) 離開。
然后使用controlnet_aux中的Open Pose預處理器提取瑜伽的身體姿勢:
from controlnet_aux import OpenposeDetectormodel = OpenposeDetector.from_pretrained("lllyasviel/ControlNet")
poses = [model(img) for img in imgs]
image_grid(poses, 2, 2)
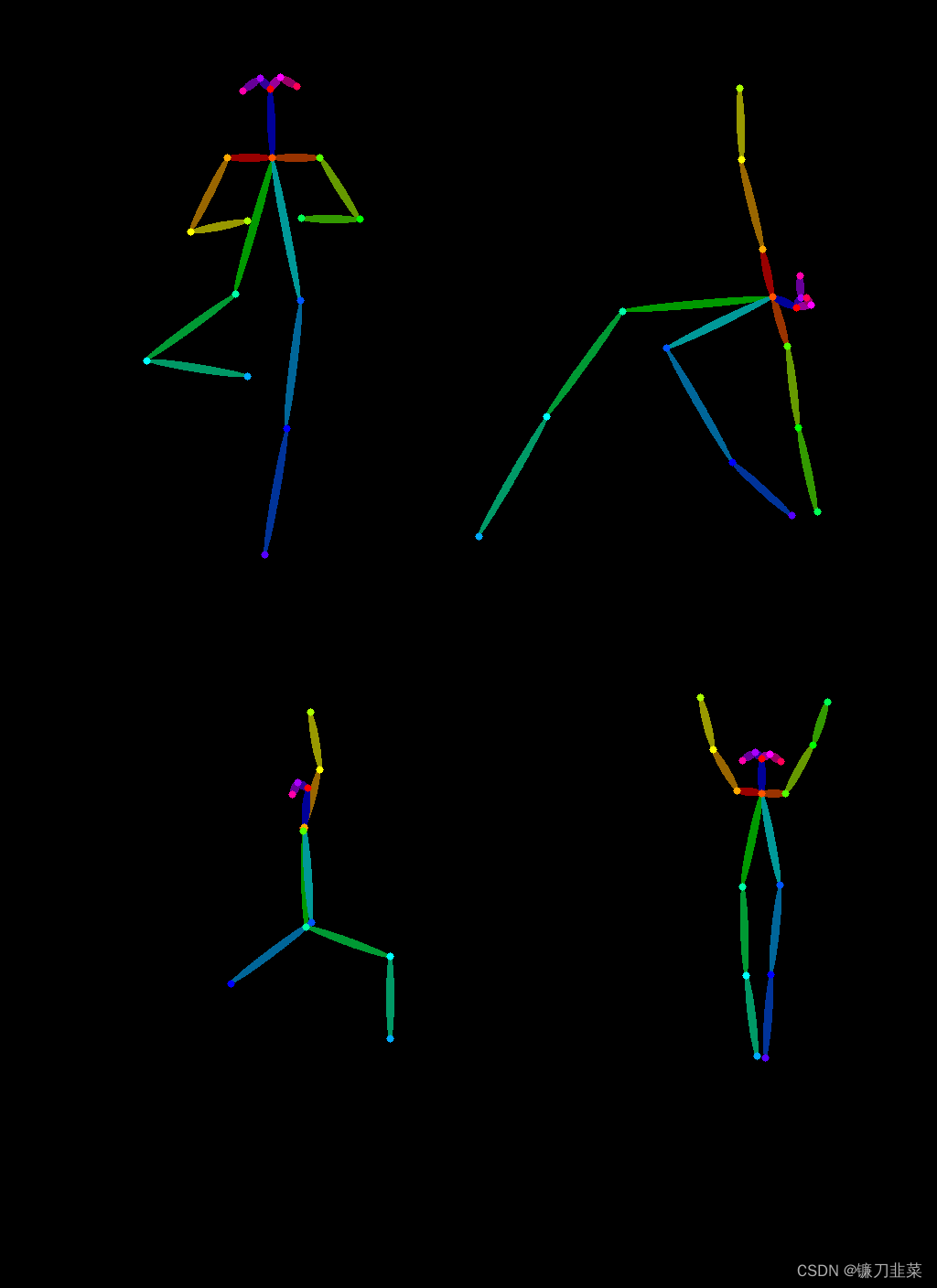
接下來使用Open Pose ControlNet生成一些正在做瑜伽的超級英雄的圖片:
from diffusers import ControlNetModel, UniPCMultistepScheduler, StableDiffusionControlNetPipelinecontrolnet = ControlNetModel.from_pretrained("fusing/stable-diffusion-v1-5-controlnet-openpose", torch_dtype=torch.float16)model_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionControlNetPipeline.from_pretrained(model_id,controlnet = controlnet,torch_dtype=torch.float16
)pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()
pipe.enable_xformers_memory_efficient_attention()
生成圖片:
generator = [torch.Generator(device='cpu').manual_seed(2) for i in range(4)]
prompt = "super-hero character, best quality, extremely detailed"
output = pipe([prompt] * 4,poses,negative_prompt=["monochrome, lowres, bad anatomy, worst quality, low quality"] * 4,generator=generator,num_inference_steps=20,
)
image_grid(output.images, 2, 2)

關于ControlNet更多的使用方法,可以參考如下:
- lllyasviel/sd-controlnet-depth
- lllyasviel/sd-controlnet-hed
- lllyasviel/sd-controlnet-normal
- lllyasviel/sd-controlnet-scribbl
- lllyasviel/sd-controlnet-seg
- lllyasviel/sd-controlnet-openpose
- lllyasviel/sd-controlnet-mlsd
小結
ControlNet是一種神經網絡結構,它學習大型預訓練的文本到圖像擴散模型的帶條件控制。它重用源模型的的大規模預訓練層來構建一個深度且強大的編碼器,以學習特定條件。原始模型和可訓練的副本通過“零卷積”層連接,這些“零卷積”層可以消除訓練期間的噪音。大量實驗證明,ControlNet可以有效控制帶有單個或多個條件以及帶/不帶提示的Stable Diffusion。在多樣化條件數據集上的結果展示出,ControlNet結構可能適用于更廣泛的條件,并促進相關應用。
參考資料
- ICCV2023最佳論文–斯坦福大學文生圖模型ControlNet,已開源!
- T2I-Adapter
- https://openai.wiki/controlnet-guide.html
- https://h1cji9hqly.feishu.cn/docx/YioKdqC0oo7XThxvW1ccOmbunEh
- lllyasviel/ControlNet
- 萬字長文解讀Stable Diffusion的核心插件—ControlNet
- ControlNet原理&使用實操
- ControlNet v1.1: A complete guide
- 使用ControlNet 控制 Stable Diffusion
- ubuntu + conda 的 stable-diffusion-webui 安裝筆記
- Python中讀取圖片的6種方式
- MediaPipe 集成人臉識別,人體姿態評估,人手檢測模型

![[linux] kaggle 數據集用linux下載](http://pic.xiahunao.cn/[linux] kaggle 數據集用linux下載)

)





)

 高階函數詳解)

![[wp]“古劍山”第一屆全國大學生網絡攻防大賽 Web部分wp](http://pic.xiahunao.cn/[wp]“古劍山”第一屆全國大學生網絡攻防大賽 Web部分wp)





)