redis的高可用(主從復制和哨兵模式)
redis的性能管理:redis的數據緩存在內存當中
INFO memory:查看redis內存使用情況
used_memory:1800800:redis中數據占用的內存
used_memory_rss:5783552:redis向操作系統申請的內存
used_memory_peak:1800800:redis使用內存的峰值
系統巡檢:硬件巡檢,數據庫,nginx,redis,docker,k8s
redis-cli info memory | grep ratio:過濾內存碎片
內存碎片率:used_memory_rss/used_memory
系統已經分配給了redis,但是redis未能夠有效利用的內存
allocator_frag ratio:1.19
分配器碎片的比例,redis主進程調度時產生的內存,比例越小越好,值越高,內存的浪費越多
allocator_rss_ratio:7.15
分配器占用物理內存的比例,告訴你主進程調度執行時占用了多少物理內存
rss_overhead_ratio:0.31
RSS是向系統申請的內存空間,redis占用物理空間額外的開銷比例,比例越低越好,redis實際占用的物理內存和向系統申請的內存越接近,額外的開銷就越低
mem_fragmentation_ratio:3.33
內存碎片的比例,越低越好,內存的使用率越高
碎片可以自動清理(手動清理redis-cli memory purge和自動清理在配置文件redis最后一行添加activedefrag yes)
設置redis的最大內存閥值:(在/etc/redis/6379.conf中568行maxmemory 1gb)
一旦到達閥值,自動清理碎片,開啟key的回收機制
key回收的策略:(要先設置上面的閥值)
配置文件redis/5379.conf,598行增加
maxmemory-policy volatile-lru:使用redis內置的LRU算法,把已經設置了過期時間的鍵值對中淘汰數據,移除最近最少使用鍵值對(針對已經設置了過期時間的鍵值對)
maxmemory-policy volatile-ttl:已經設置了過期時間的鍵值對,從當中挑選一個即將過期的鍵值對
maxmemory-policy volatile-random:從已經設置了過期時間的鍵值對當中,挑選數據隨機淘汰鍵值對(對設置了過期時間的鍵值對進行隨機移除)
allkeys-lru:LRU算法當中,對所有的鍵值對進行淘汰,移除最少使用的鍵值對(針對所有的鍵值對)(慎用)
allkeys-random:從所有鍵值對當中任意選擇數據進行淘汰(慎用或別用)
maxmemory-policy noeviction:禁止鍵值對回收(不擅長任何鍵值對,直到redis把內存塞滿,寫不了,報錯為止)
在工作當中,一定要給redis占用內存設置閥值
面試題:
redis占用的內存的效率問題如何解決?
1、日常巡檢當中,對redis的占用情況做監控
2、設置redis占用系統內存的閥值(在/etc/redis/6379.conf中568行maxmemory 1gb),避免占用系統全部內存
3、內存碎片清理(手動清理redis-cli memory purge和自動清理在配置文件redis最后一行添加activedefrag yes)
4、設置合適的key回收機制
maxmemory-policy noeviction:禁止鍵值對回收(不擅長任何鍵值對,直到redis把內存塞滿,寫不了,報錯為止)
maxmemory-policy volatile-lru:使用redis內置的LRU算法,把已經設置了過期時間的鍵值對中淘汰數據,移除最近最少使用鍵值對(針對已經設置了過期時間的鍵值對)
redis雪崩(緩存雪崩):
大量的應用請求無法在redis緩存當中處理,請求會全部發送到后臺數據庫,數據庫并發能力本身就差。一旦高并發,數據庫會很快崩潰
redis集群大面積故障
redis緩存中,大量數據同時過期,大量的請求無法得到處理
redis實例宕機
解決方案:
事前:采用高可用架構,防止整個緩存故障。主從復制和哨兵模式 redis集群
事中:在國內用的比較多哥方式:HYSTRIX,熔斷,降級,限流三個手段來降低雪崩發生之后的損失。
數據庫不死即可,慢可以,但是不能沒有響應
事后:redis備份,快速緩存預熱
redis的緩存擊穿:
緩存擊穿主要是熱點數據緩存過期,或者被刪除,多個請求并發訪問數據,請求也是轉發到數據庫了,導致數據庫的性能快速下降
經常被請求的緩存數據,最好設置為永不過期
redis的緩存穿透:
緩存中沒有數據,數據庫也沒有對應數據,但是有用戶一直在發起這個都沒有的請求,而且請求的數據格式很大
一般這種情況就是黑客利用漏洞進行攻擊,壓垮應用數據庫
redis的集群:
1、持久化
2、高可用 ?主從復制 ?哨兵模式 ?集群
主從復制:主從復制是redis實現高可用的基礎,哨兵模式和集群都是在主從復制的基礎之上實現高可用
??????????主從復制實現數據的多機備份,以及讀寫分離(主服務器負責寫,從服務器只能讀)
??????????缺陷:故障無法自動恢復,需要人工干預,無法實現寫操作的負載均衡
主從復制的工作原理:
- 主節點(master)從節點(slave)組成,數據復制是單向的,只能從主節點到從節點

主從復制的實驗:
(主)打開配置文件:vim /etc/redis/6379.conf
70行 IP地址改為0.0.0.0,讓所有的主機都可以使用
137行 daemonize yes打開
700行 appendonly no打開變成yes
重啟配置文件:/etc/init.d/redis_6379 restart
(從)打開配置文件:vim /etc/redis/6379.conf
70行 IP地址改為0.0.0.0,讓所有的主機都可以使用
137行 daemonize yes打開
288行添加一行replicaof 192.168.233.11 6379
700行 appendonly no打開變成yes
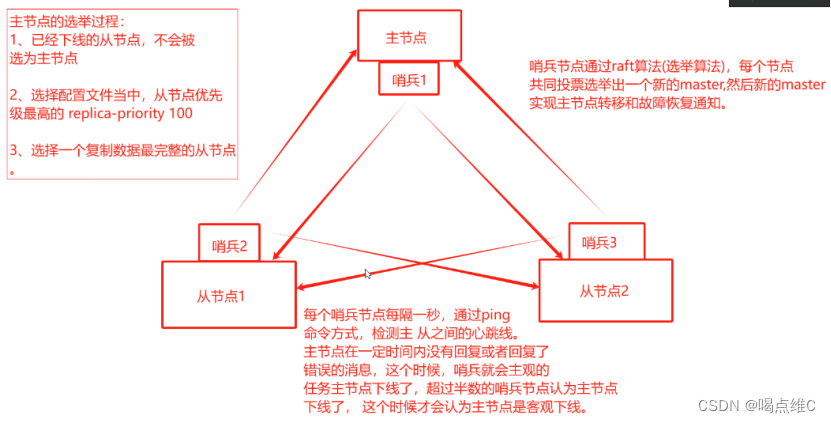
哨兵模式:先有主從再有哨兵
在主從復制的基礎之上,實現主節點故障的自動切換
哨兵模式的原理:
哨兵:分布式系統,用于在主從結構之間,對每臺redis的服務進行監控
主節點出現故障時,從節點通過投票的方式選擇一個新的master
哨兵模式也需要至少三個節點
哨兵模式的結構:
哨兵節點:監控,不存儲數據
數據節點:主節點和從節點,都是數據節點
主:192.168.233.11
從:192.168.233.12
從:192.168.233.13
哨兵模式的實驗:
(主)cd /opt/
cd redis-5.0.7/
vim sentinel.conf
17行注釋取消掉protected-mode no
26行daemonize no改成yes
36行logfile "/var/log/sentinel.log"
65行dir "/var/lib/redis/6379"
84行sentinel monitor mymaster 192.168.233.11 6379 2
啟動配置文件redis-sentinel sentinel.conf &
redis-cli -p 26379 info Sentinel
ps -elf | grep redis
(從)cd /opt/
cd redis-5.0.7/
vim sentinel.conf
17行注釋掉protected-mode no
26行 daemonize no改為yes
36行logfile "/var/log/sentinel.log"
65行dir "/var/lib/redis/6379"
84行sentinel monitor mymaster 192.168.233.11 6379 2
啟動配置文件redis-sentinel sentinel.conf &
: Region Of Interest(有興趣區域/找重點))









)


——獲取和為k的子數組)




】)
:常用基礎組件)