目錄
1、稀疏注意力機制(Sparse Attention)
1.1、核心問題:傳統注意力的 “效率瓶頸”
1.2、具體稀疏策略(詳細計算邏輯)
1.2.1、局部窗口稀疏(Local Window Sparse)
1.2.2、基于內容的稀疏選擇(Content-Based Sparse)
1.2.3、塊稀疏(Block Sparse)
1.3、優缺點
1.4、測試代碼
1.5、實驗結果
2、FlashAttention
2.1、核心問題:傳統注意力的 “內存瓶頸”
2.2、詳細計算邏輯(內存優化關鍵)
2.2.1、瓦片(Tiling)技術
2.2.2、分塊計算注意力
2.2.3、數值穩定性優化
2.2.4、顯存復用
2.3、數學公式
2.4、性能提升
2.5、完整代碼
3、多查詢注意力(Multi-Query Attention, MQA)
3.1、核心問題:多頭注意力的 “參數與推理瓶頸”
3.2、詳細改進邏輯
3.2.1、計算步驟對比
3.2.2、效率提升本質
3.3、與 GQA 的關系
3.4、優缺點
3.5、示例代碼
4、多頭潛在注意力(Multi-Head Latent Attention)
4.1、核心問題:傳統注意力的 “顯式依賴局限”
4.2、詳細計算邏輯
4.2.1、潛在變量的作用
4.2.2、多頭潛在機制
4.2.3、潛在變量的學習
4.3、優缺點
4.4、示例代碼
5、四種注意力的總結
6、信息處理:分離角色
6.1、?查詢(Query)、鍵(Key)、值(Value)的分工
6.2、為什么需要分離?
1、稀疏注意力機制(Sparse Attention)
1.1、核心問題:傳統注意力的 “效率瓶頸”
傳統的縮放點積注意力(Scaled Dot-Product Attention)計算復雜度是?O(n2)(n 為序列長度),當處理長序列(如文檔、視頻幀,n=10000 以上)時,計算量和內存占用會爆炸式增長(例如 n=10000 時,n2=1 億,n=10 萬時 n2=1 萬億),根本無法訓練或推理。
稀疏注意力機制的核心是:只計算序列中 “重要的少數” 元素之間的注意力,忽略大部分無關元素,將復雜度從 O (n2) 降到 O (n) 或 O (n log n),同時保留關鍵信息。
核心思想:
?
傳統注意力就像 “逐字閱讀一本書”,每句話都要和其他所有句子對比,效率很低。
稀疏注意力則像 “跳讀”:只關注重要的部分(如標題、圖表、關鍵詞),忽略無關內容,大幅提高閱讀速度。生活化比喻:
你在圖書館找一本關于 “人工智能” 的書。
- 傳統注意力:把整個圖書館的書都翻一遍,對比每本書和 “人工智能” 的關聯;
- 稀疏注意力:直接去計算機科學區(局部窗口),或者只看封面帶 “AI” 標簽的書(內容選擇),忽略其他區域。
適用場景:
長文本(如論文、小說)、長視頻分析、大規模數據處理
1.2、具體稀疏策略(詳細計算邏輯)
1.2.1、局部窗口稀疏(Local Window Sparse)
- 原理:每個元素只關注自身周圍固定窗口內的元素(類似人類 “視野有限”)。
-
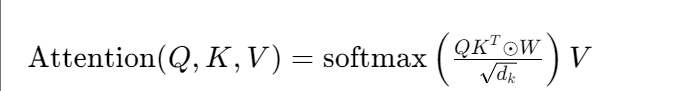
- 計算步驟:
① 將序列分成多個不重疊或重疊的窗口(如窗口大小為 w);
② 每個位置 i 只與 [i-w/2, i+w/2] 范圍內的位置計算注意力;
③ 窗口外的位置注意力權重直接設為 0。 - 例:Longformer 模型用的 “滑動窗口 + 全局令牌”,窗口大小通常設為 512,同時對特殊令牌(如 [CLS])計算全局注意力,兼顧局部細節和全局依賴。
1.2.2、基于內容的稀疏選擇(Content-Based Sparse)
- 原理:根據內容相似度動態選擇少數 “相關元素”(如只關注與當前元素語義相似的 top-k 個)。
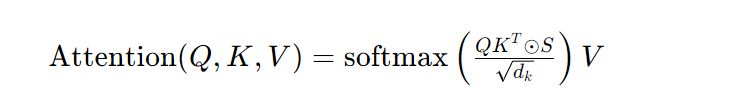
- 計算步驟:
① 對每個元素 i,計算與其他元素 j 的相似度(如);
② 只保留相似度最高的 k 個 j(k 遠小于 n),其余權重設為 0;
③ 對保留的 k 個權重做 softmax 歸一化。 - 例:RNN + 注意力的改進模型中,常通過這種方式減少長序列計算量。
1.2.3、塊稀疏(Block Sparse)
- 原理:將序列分成若干塊,只在部分塊之間計算注意力(塊內或跨塊的稀疏交互)。
- 計算步驟:
① 序列分塊:n = b×m(b 為塊數,m 為塊大小);
② 定義塊間交互矩陣(如對角線塊內計算,少數跨塊計算);
③ 塊內元素間計算注意力,跨塊只在允許的塊間計算。 - 例:BigBird 模型的 “塊稀疏 + 隨機稀疏 + 全局稀疏” 混合策略,既高效又保留全局依賴。
1.3、優缺點
- 優點:大幅降低長序列計算成本,可處理 10 萬級長度序列;
- 缺點:稀疏模式設計依賴先驗(如窗口大小、k 值),可能丟失重要依賴;實現復雜(需特殊掩碼處理)。
1.4、測試代碼
import torch
import torch.nn as nn
import torch.nn.functional as F
import time
import matplotlib.pyplot as plt
import numpy as np# 設置中文顯示
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False # 解決負號顯示問題# 實現一個簡化版的稀疏注意力機制
class SparseAttention(nn.Module):def __init__(self, embed_dim, num_heads, window_size=5, random_size=0):super().__init__()self.embed_dim = embed_dimself.num_heads = num_headsself.head_dim = embed_dim // num_headsself.window_size = window_size # 局部窗口大小self.random_size = random_size # 隨機選擇的元素數量self.q_proj = nn.Linear(embed_dim, embed_dim)self.k_proj = nn.Linear(embed_dim, embed_dim)self.v_proj = nn.Linear(embed_dim, embed_dim)self.out_proj = nn.Linear(embed_dim, embed_dim)def forward(self, x):batch_size, seq_len, _ = x.shape# 計算Q, K, V# self.q_proj(x) 就像比較 “蘋果” 和 “橙子” 的甜度,需要先將它們的特征(如糖分含量)轉換到同一度量單位(如克 / 100g),# 否則 “一個蘋果” 和 “一個橙子” 的直接對比沒有意義。q = (self.q_proj(x) #線性投影:將輸入x映射到查詢空間.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2))k = self.k_proj(x).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)v = self.v_proj(x).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)# 創建稀疏注意力掩碼mask = torch.zeros(seq_len, seq_len, device=x.device)# 1. 局部窗口注意力for i in range(seq_len):start = max(0, i - self.window_size)end = min(seq_len, i + self.window_size + 1)mask[i, start:end] = 1# 2. 隨機稀疏注意力(可選)if self.random_size > 0 and self.random_size < seq_len:for i in range(seq_len):random_indices = torch.randperm(seq_len, device=x.device)[:self.random_size]mask[i, random_indices] = 1# 確保對角線始終為1(自己關注自己)mask.fill_diagonal_(1)# 計算注意力得分并應用掩碼attn_scores = torch.matmul(q, k.transpose(-2, -1)) / (self.head_dim ** 0.5)masked_attn_scores = attn_scores.masked_fill(mask.unsqueeze(0).unsqueeze(0) == 0, -1e9)attn_weights = F.softmax(masked_attn_scores, dim=-1)# 應用注意力權重output = torch.matmul(attn_weights, v)output = output.transpose(1, 2).contiguous().view(batch_size, seq_len, self.embed_dim)return self.out_proj(output)# 實現標準注意力機制作為對比
class StandardAttention(nn.Module):def __init__(self, embed_dim, num_heads):super().__init__()self.embed_dim = embed_dimself.num_heads = num_headsself.head_dim = embed_dim // num_headsself.q_proj = nn.Linear(embed_dim, embed_dim)self.k_proj = nn.Linear(embed_dim, embed_dim)self.v_proj = nn.Linear(embed_dim, embed_dim)self.out_proj = nn.Linear(embed_dim, embed_dim)def forward(self, x):batch_size, seq_len, _ = x.shapeq = self.q_proj(x).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)k = self.k_proj(x).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)v = self.v_proj(x).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)attn_scores = torch.matmul(q, k.transpose(-2, -1)) / (self.head_dim ** 0.5)attn_weights = F.softmax(attn_scores, dim=-1)output = torch.matmul(attn_weights, v)output = output.transpose(1, 2).contiguous().view(batch_size, seq_len, self.embed_dim)return self.out_proj(output)# 測試函數
def test_attention():# 設置測試參數embed_dim = 512num_heads = 8seq_lens = [100, 500, 1000, 2000, 3000] # 測試不同序列長度window_sizes = [5, 10, 20, 50] # 測試不同窗口大小# 存儲結果sparse_times = {ws: [] for ws in window_sizes}standard_times = []mem_usage = {ws: [] for ws in window_sizes}for seq_len in seq_lens:# 創建隨機輸入x = torch.randn(1, seq_len, embed_dim)# 測試標準注意力standard_attn = StandardAttention(embed_dim, num_heads)start_time = time.time()with torch.no_grad():standard_output = standard_attn(x)standard_times.append(time.time() - start_time)# 測試不同窗口大小的稀疏注意力for ws in window_sizes:sparse_attn = SparseAttention(embed_dim, num_heads, window_size=ws)start_time = time.time()with torch.no_grad():sparse_output = sparse_attn(x)sparse_times[ws].append(time.time() - start_time)# 計算內存占用(以參數數量近似)mem_usage[ws].append(seq_len * seq_len * ws / (seq_len * seq_len) * 100) # 稀疏度百分比# 繪制結果plt.figure(figsize=(12, 5))# 繪制時間對比圖plt.subplot(1, 2, 1)plt.plot(seq_lens, standard_times, 'o-', label='標準注意力')for ws in window_sizes:plt.plot(seq_lens, sparse_times[ws], 'o-', label=f'稀疏注意力 (窗口={ws})')plt.xlabel('序列長度')plt.ylabel('計算時間 (秒)')plt.title('不同序列長度下的注意力計算時間')plt.legend()plt.grid(True)# 繪制稀疏度對比圖plt.subplot(1, 2, 2)for ws in window_sizes:plt.plot(seq_lens, mem_usage[ws], 'o-', label=f'窗口={ws}')plt.axhline(y=100, color='r', linestyle='--', label='標準注意力')plt.xlabel('序列長度')plt.ylabel('相對內存占用 (%)')plt.title('不同窗口大小的稀疏度')plt.legend()plt.grid(True)plt.tight_layout()plt.savefig('attention_comparison.png')plt.show()# 打印一些關鍵結果print("序列長度為3000時的計算時間對比:")print(f"標準注意力: {standard_times[-1]:.4f}秒")for ws in window_sizes:print(f"稀疏注意力 (窗口={ws}): {sparse_times[ws][-1]:.4f}秒")print(f" 速度提升: {standard_times[-1] / sparse_times[ws][-1]:.2f}倍")print(f" 內存占用: {mem_usage[ws][-1]:.2f}%")if __name__ == "__main__":test_attention()1.5、實驗結果
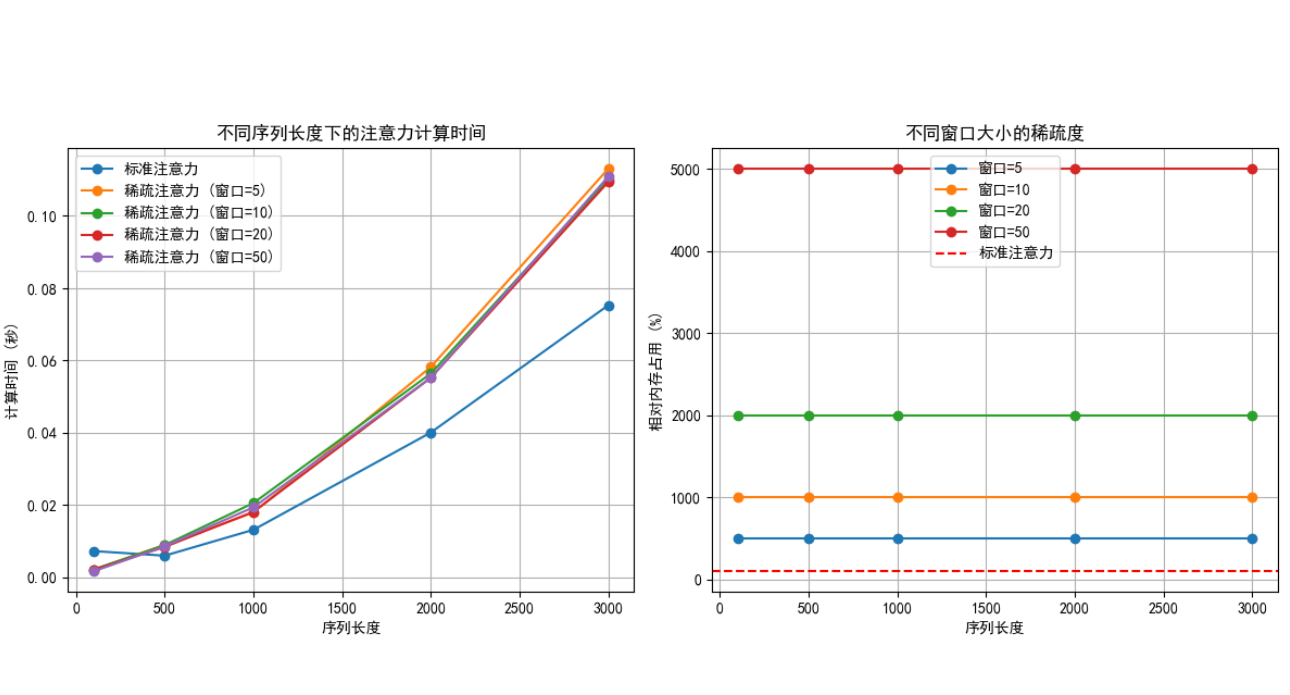
左:窗口越小,計算時間越短,但可能損失部分全局信息(需在效率與性能間權衡)。
右:窗口大小直接決定了稀疏程度,窗口 = 5 的稀疏度遠高于窗口 = 50。
2、FlashAttention
2.1、核心問題:傳統注意力的 “內存瓶頸”
傳統注意力計算時,會產生中間大矩陣(如 是 n×n 矩陣),當 n=1 萬時,該矩陣占用約 400MB(float32),若 n=10 萬則達 40GB,遠超 GPU 顯存。即使能計算,頻繁的內存讀寫也會拖慢速度(內存帶寬比計算速度慢得多)。
FlashAttention 的核心是:通過 “分塊計算 + 內存高效調度”,避免存儲完整中間矩陣,在有限顯存內高效計算注意力,同時保持結果與傳統注意力一致。
核心思想:
?
傳統注意力計算時,會頻繁在 “草稿紙”(高速內存)和 “書架”(低速內存)之間搬數據,浪費時間。
FlashAttention重新設計了 “打草稿” 的順序,讓你一次性在草稿紙上算完所有步驟,再放回書架,減少來回折騰。生活化比喻:
你要做一頓飯:
- 傳統方法:每切一個菜,就把刀放回刀架,再從冰箱拿食材,切完又放回去,反復跑冰箱和操作臺;
- FlashAttention 方法:一次性把所有需要的食材從冰箱拿出來放在操作臺上,切完所有菜再統一收拾,減少來回跑的時間。
效果:
速度提升 2-4 倍,內存占用減少,尤其適合處理超長序列(如 10 萬詞的文檔)。
2.2、詳細計算邏輯(內存優化關鍵)
2.2.1、瓦片(Tiling)技術
- 將 Q、K、V 分塊(如切成大小為 B 的瓦片),每次只處理一小塊數據,避免完整矩陣加載。
- 例:Q∈R^(n×d),切成 Q1, Q2, ..., Qp(每塊 B×d);K、V 同理切成 K1~Kp, V1~Vp。
2.2.2、分塊計算注意力
- 傳統注意力:
→ softmax → 與 V 相乘;
- FlashAttention 分兩步:
① 計算 “塊級,逐塊計算與
的相似度(
),同時實時計算 softmax 的中間值(最大值和總和),避免存儲完整
② 分塊更新輸出:用塊級 softmax 結果與相乘,逐步累加得到最終輸出
。
2.2.3、數值穩定性優化
- 傳統 softmax 可能因數值溢出導致精度問題,FlashAttention 在分塊計算時實時跟蹤每塊的最大值,通過 “減最大值” 避免指數爆炸,同時保留足夠精度。
2.2.4、顯存復用
- 中間結果(如塊級 QK^T、softmax 中間值)只在寄存器 / 共享內存中臨時存儲,計算完立即釋放,不占用全局顯存。
2.3、數學公式

2.4、性能提升
- 速度:比 PyTorch 原生注意力快 2-4 倍(長序列時更明顯);
- 內存:可處理 n=16 萬的序列(傳統注意力在 n=1 萬時就會 OOM);
- 精度:通過數值優化,結果與傳統注意力誤差小于 1e-5。
2.5、完整代碼
"""
文件名: 2.3.2
作者: 墨塵
日期: 2025/7/19
項目名: dl_env
備注:
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
import time
import matplotlib.pyplot as plt
import numpy as np
from torch.profiler import profile, record_function, ProfilerActivity# 設置中文顯示
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]
plt.rcParams["axes.unicode_minus"] = False # 解決負號顯示問題# 嘗試導入 FlashAttention(需先安裝 flash-attn 庫)
try:from flash_attn.flash_attention import FlashAttentionflash_available = Trueprint("FlashAttention 庫已成功導入")
except ImportError:flash_available = Falseprint("未找到 FlashAttention 庫,請通過 'pip install flash-attn' 安裝")# --------------------------- 1. 標準注意力機制 ---------------------------
# 先計算完整的注意力權重矩陣,再一次性與 V 相乘:
class StandardAttention(nn.Module):"""標準縮放點積注意力,用于與 FlashAttention 對比"""def __init__(self, embed_dim, num_heads):super().__init__()self.embed_dim = embed_dimself.num_heads = num_headsself.head_dim = embed_dim // num_heads# 線性投影層self.q_proj = nn.Linear(embed_dim, embed_dim)self.k_proj = nn.Linear(embed_dim, embed_dim)self.v_proj = nn.Linear(embed_dim, embed_dim)self.out_proj = nn.Linear(embed_dim, embed_dim)def forward(self, q, k, v, attn_mask=None, dropout_p=0.0):"""標準注意力計算流程:1. 計算 Q、K 的點積得到注意力分數2. 應用掩碼(如果有)3. 應用 softmax 轉換為概率分布4. 對 V 進行加權聚合"""batch_size, seq_len_q, _ = q.shapeseq_len_k = k.shape[1]# 計算注意力分數attn_scores = torch.matmul(q.view(batch_size, seq_len_q, self.num_heads, self.head_dim),k.view(batch_size, seq_len_k, self.num_heads, self.head_dim).transpose(1, 2)) / (self.head_dim ** 0.5) # 縮放防止梯度消失# 應用掩碼(如果提供)if attn_mask is not None:attn_scores = attn_scores.masked_fill(attn_mask.unsqueeze(1) == 0, -1e9)# 應用 softmax 和 dropoutattn_weights = F.softmax(attn_scores, dim=-1)attn_weights = F.dropout(attn_weights, p=dropout_p, training=self.training)# 加權聚合 Voutput = torch.matmul(attn_weights,v.view(batch_size, seq_len_k, self.num_heads, self.head_dim))# 重塑并通過輸出投影層output = output.transpose(1, 2).contiguous().view(batch_size, seq_len_q, self.embed_dim)return self.out_proj(output)# --------------------------- 2. FlashAttention 包裝器 ---------------------------
# 計算完一個分塊的注意力權重后,立即與對應分塊的 V 相乘并累加結果
class FlashAttentionWrapper(nn.Module):"""FlashAttention 包裝器,保持與標準注意力相同的接口"""def __init__(self, embed_dim, num_heads):super().__init__()self.embed_dim = embed_dimself.num_heads = num_headsself.head_dim = embed_dim // num_heads# FlashAttention 模塊self.flash_attn = FlashAttention(causal=False) # 非因果注意力# 線性投影層(與標準注意力一致)self.q_proj = nn.Linear(embed_dim, embed_dim)self.k_proj = nn.Linear(embed_dim, embed_dim)self.v_proj = nn.Linear(embed_dim, embed_dim)self.out_proj = nn.Linear(embed_dim, embed_dim)def forward(self, q, k, v, attn_mask=None, dropout_p=0.0):"""FlashAttention 前向傳播:1. 將輸入投影到 Q、K、V 空間2. 調整維度順序以適應 FlashAttention 接口3. 通過 FlashAttention 計算注意力4. 重塑并通過輸出投影層"""batch_size, seq_len_q, _ = q.shape# 投影到 Q、K、V 空間q = self.q_proj(q)k = self.k_proj(k)v = self.v_proj(v)# 調整維度為 (batch, seq_len, num_heads, head_dim)q = q.view(batch_size, seq_len_q, self.num_heads, self.head_dim)k = k.view(batch_size, seq_len_q, self.num_heads, self.head_dim) # 假設 seq_len_k == seq_len_qv = v.view(batch_size, seq_len_q, self.num_heads, self.head_dim)# 轉換為 FlashAttention 所需的格式 (batch, seq_len, num_heads, head_dim)q = q.transpose(1, 2) # (batch, num_heads, seq_len, head_dim)k = k.transpose(1, 2)v = v.transpose(1, 2)# 計算 FlashAttention# 注意:FlashAttention 輸入格式為 (batch, seq_len, num_heads, head_dim)# 在實際使用 FlashAttention 時,分塊大小(block size)通常不需要我們手動設定,# 而是由庫內部根據硬件(如 GPU 型號)和序列長度自動優化選擇。# 輸出格式也相同output, _ = self.flash_attn(q, k, v,dropout_p=dropout_p if self.training else 0.0)# 重塑并通過輸出投影層output = output.transpose(1, 2).contiguous().view(batch_size, seq_len_q, self.embed_dim)return self.out_proj(output)# --------------------------- 3. 測試函數 ---------------------------
def test_flash_attention():"""測試并對比 FlashAttention 和標準注意力的性能"""if not flash_available:print("無法運行測試:未找到 FlashAttention 庫")return# 設置測試參數embed_dim = 512num_heads = 8head_dim = embed_dim // num_headsbatch_size = 4seq_lens = [100, 500, 1000, 2000, 4000, 8000] # 測試不同序列長度dropout = 0.1# 設備選擇(FlashAttention 在 GPU 上效果最佳)device = torch.device("cuda" if torch.cuda.is_available() else "cpu")print(f"使用設備: {device}")# 存儲結果standard_times = []flash_times = []speedups = []# 創建模型standard_attn = StandardAttention(embed_dim, num_heads).to(device)flash_attn = FlashAttentionWrapper(embed_dim, num_heads).to(device)# 設置為評估模式standard_attn.eval()flash_attn.eval()# 預熱(讓 CUDA 初始化)x = torch.randn(batch_size, 100, embed_dim, device=device)with torch.no_grad():_ = standard_attn(x, x, x)_ = flash_attn(x, x, x)# 測試不同序列長度for seq_len in seq_lens:print(f"\n測試序列長度: {seq_len}")# 創建隨機輸入q = torch.randn(batch_size, seq_len, embed_dim, device=device)k = torch.randn(batch_size, seq_len, embed_dim, device=device)v = torch.randn(batch_size, seq_len, embed_dim, device=device)# 測試標準注意力torch.cuda.synchronize() # 同步 GPUstart_time = time.time()with torch.no_grad():for _ in range(10): # 多次運行取平均_ = standard_attn(q, k, v, dropout_p=dropout)torch.cuda.synchronize() # 同步 GPUstandard_time = (time.time() - start_time) / 10standard_times.append(standard_time)print(f"標準注意力耗時: {standard_time:.6f} 秒")# 測試 FlashAttentiontorch.cuda.synchronize()start_time = time.time()with torch.no_grad():for _ in range(10): # 多次運行取平均_ = flash_attn(q, k, v, dropout_p=dropout)torch.cuda.synchronize()flash_time = (time.time() - start_time) / 10flash_times.append(flash_time)print(f"FlashAttention 耗時: {flash_time:.6f} 秒")# 計算加速比speedup = standard_time / flash_timespeedups.append(speedup)print(f"加速比: {speedup:.2f}x")# 使用 PyTorch Profiler 分析內存和計算量with profile(activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA],record_shapes=True,) as prof:with record_function("standard_attention"):_ = standard_attn(q, k, v)print("\n標準注意力性能分析:")print(prof.key_averages().table(sort_by="cuda_time_total", row_limit=5))with profile(activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA],record_shapes=True,) as prof:with record_function("flash_attention"):_ = flash_attn(q, k, v)print("\nFlashAttention 性能分析:")print(prof.key_averages().table(sort_by="cuda_time_total", row_limit=5))# 繪制性能對比圖plt.figure(figsize=(12, 5))# 繪制時間對比圖plt.subplot(1, 2, 1)plt.plot(seq_lens, standard_times, 'o-', label='標準注意力')plt.plot(seq_lens, flash_times, 'o-', label='FlashAttention')plt.xlabel('序列長度')plt.ylabel('計算時間 (秒)')plt.title('不同序列長度下的計算時間對比')plt.legend()plt.grid(True)# 繪制加速比圖plt.subplot(1, 2, 2)plt.plot(seq_lens, speedups, 'o-', color='green')plt.xlabel('序列長度')plt.ylabel('加速比 (標準/Flash)')plt.title('FlashAttention 相對于標準注意力的加速比')plt.grid(True)plt.tight_layout()plt.savefig('flash_attention_comparison.png')plt.show()# 打印總結print("\n===== 性能總結 =====")for i, seq_len in enumerate(seq_lens):print(f"序列長度 {seq_len}:")print(f" 標準注意力: {standard_times[i]:.6f} 秒")print(f" FlashAttention: {flash_times[i]:.6f} 秒")print(f" 加速比: {speedups[i]:.2f}x")# --------------------------- 4. 主函數 ---------------------------
if __name__ == "__main__":test_flash_attention()3、多查詢注意力(Multi-Query Attention, MQA)
3.1、核心問題:多頭注意力的 “參數與推理瓶頸”
傳統多頭注意力(Multi-Head Attention, MHA)中,每個頭有獨立的 Q、K、V 投影矩陣(共 3h×d 參數,h 為頭數),且推理時每個頭需獨立計算 K、V,導致:
- 參數多:h=16 時,K、V 投影參數是 MQA 的 16 倍;
- 推理慢:生成式模型解碼時,每次需處理 h 組 K、V 緩存,內存占用大,并行效率低。
核心思想:
?
傳統多頭注意力就像 “10 個人同時查資料”,每個人都帶一套完整的工具(Q、K、V),浪費資源。
多查詢注意力讓 10 個人共享同一套 “K 和 V 工具”,只保留各自的 “Q 工具”,既節省資源,又不影響效率。生活化比喻:
10 個學生做小組作業,需要查資料、整理筆記、寫報告:
- 傳統方法:每個學生都帶一套完整的詞典、筆記本、電腦(Q、K、V);
- MQA 方法:10 個學生共用一套詞典和筆記本(K、V),但每人保留自己的電腦(Q),分工協作。
優勢:
參數減少,推理速度提升(尤其適合生成式模型,如 ChatGPT),節省顯存。
3.2、詳細改進邏輯
MQA 的核心:多個頭共享同一組 K 和 V,只保留多頭 Q,大幅減少參數和計算量。
3.2.1、計算步驟對比
- 傳統 MHA:
① 多頭投影:;
② 每個頭計算注意力:;
③ 拼接所有,投影輸出。
- MQA:
① 多頭 Q 投影:Q_h = Q?W_Qh(h=1..H);
② 共享 K、V 投影:K = K?W_K, V = V?W_V(僅 1 組);
③ 每個頭用共享的 K、V 計算:A_h = softmax (Q_hK^T/√d) V;
④ 拼接 A_h,投影輸出。
3.2.2、效率提升本質
- 參數:K、V 投影參數從 H×d2 降為 d2(減少 H 倍);
- 推理緩存:生成式模型中,K、V 緩存從 H 組降為 1 組,內存占用減為 1/H,解碼速度提升(因緩存讀寫減少)。
3.3、與 GQA 的關系
Grouped-Query Attention(GQA)是 MQA 的折中:將 H 個頭分成 G 組,每組共享 1 組 K、V(MQA 是 G=1 的特例,MHA 是 G=H 的特例)。例如 H=16, G=4,則 4 組 K、V,兼顧效率和性能。
3.4、優缺點
- 優點:參數少、推理快(尤其生成任務),適合大模型部署;
- 缺點:共享 K、V 可能損失部分表達能力(多頭多樣性降低),需通過調優補償(如增加頭數 H)。
- 應用:PaLM、GPT-4、LLaMA 2 等大模型廣泛采用(GQA 更常見,平衡效率和性能)。
3.5、示例代碼
import torch
import torch.nn as nn
import torch.nn.functional as Fclass MultiQueryAttention(nn.Module):"""多查詢注意力 (Multi-Query Attention, MQA) 模塊與標準多頭注意力不同,MQA中所有查詢頭共享相同的鍵和值投影矩陣,從而顯著減少參數量和內存占用,同時保持模型性能。論文參考: "Fast Transformer Decoding: One Write-Head is All You Need"https://arxiv.org/abs/1911.02150"""def __init__(self, embed_dim: int, # 輸入嵌入維度num_heads: int, # 查詢頭數量head_dim: int = None, # 每個頭的維度dropout: float = 0.0, # Dropout概率bias: bool = True, # 是否使用偏置項):super().__init__()# 檢查參數有效性self.embed_dim = embed_dimself.num_heads = num_headsself.head_dim = head_dim if head_dim is not None else embed_dim // num_heads# 確保維度匹配assert self.head_dim * num_heads == embed_dim, "embed_dim必須能被num_heads整除"# 查詢投影: 為每個頭創建獨立的投影矩陣self.q_proj = nn.Linear(embed_dim, num_heads * self.head_dim, bias=bias)# 鍵和值投影: 所有頭共享相同的投影矩陣# 這是MQA與標準多頭注意力的核心區別self.k_proj = nn.Linear(embed_dim, self.head_dim, bias=bias)self.v_proj = nn.Linear(embed_dim, self.head_dim, bias=bias)# 輸出投影self.out_proj = nn.Linear(num_heads * self.head_dim, embed_dim, bias=bias)# Dropout層self.dropout = nn.Dropout(dropout)# 縮放因子 (用于縮放點積注意力)self.scale = self.head_dim ** -0.5def forward(self, query: torch.Tensor, # 查詢張量 [batch_size, seq_len, embed_dim]key: torch.Tensor, # 鍵張量 [batch_size, seq_len, embed_dim]value: torch.Tensor, # 值張量 [batch_size, seq_len, embed_dim]attn_mask: torch.Tensor = None, # 注意力掩碼 [batch_size, seq_len, seq_len]):"""前向傳播過程"""batch_size, seq_len, _ = query.shape# 1. 線性投影# 查詢投影后形狀: [batch_size, seq_len, num_heads * head_dim]q = self.q_proj(query)# 鍵和值投影后形狀: [batch_size, seq_len, head_dim]k = self.k_proj(key)v = self.v_proj(value)# 2. 重塑查詢張量為多頭形式# 形狀變為: [batch_size, seq_len, num_heads, head_dim]q = q.view(batch_size, seq_len, self.num_heads, self.head_dim)# 3. 調整維度順序以便計算注意力分數# 查詢形狀: [batch_size, num_heads, seq_len, head_dim]q = q.transpose(1, 2)# 鍵和值形狀: [batch_size, seq_len, head_dim]# 注意: 鍵和值不需要多頭維度,所有頭共享相同的鍵值矩陣# 4. 計算注意力分數 (點積)# 形狀: [batch_size, num_heads, seq_len, seq_len]attn_scores = torch.matmul(q, k.transpose(-2, -1)) * self.scale# 5. 應用注意力掩碼 (如果提供)if attn_mask is not None:# 確保掩碼維度匹配if attn_mask.dim() == 2:attn_mask = attn_mask.unsqueeze(0).unsqueeze(1) # [1, 1, seq_len, seq_len]elif attn_mask.dim() == 3:attn_mask = attn_mask.unsqueeze(1) # [batch_size, 1, seq_len, seq_len]# 將掩碼位置的值設為負無窮 (softmax后接近0)attn_scores = attn_scores.masked_fill(attn_mask == 0, -1e9)# 6. 應用softmax獲取注意力權重# 形狀: [batch_size, num_heads, seq_len, seq_len]attn_weights = F.softmax(attn_scores, dim=-1)# 7. 應用dropoutattn_weights = self.dropout(attn_weights)# 8. 加權聚合值# 值形狀: [batch_size, seq_len, head_dim]# 輸出形狀: [batch_size, num_heads, seq_len, head_dim]output = torch.matmul(attn_weights, v.unsqueeze(1)) # 擴展維度以匹配多頭# 9. 重塑輸出并通過線性層# 形狀: [batch_size, seq_len, num_heads * head_dim]output = output.transpose(1, 2).contiguous().view(batch_size, seq_len, -1)# 最終輸出形狀: [batch_size, seq_len, embed_dim]return self.out_proj(output)4、多頭潛在注意力(Multi-Head Latent Attention)
4.1、核心問題:傳統注意力的 “顯式依賴局限”
傳統注意力(包括多頭、稀疏版)依賴 “顯式成對交互”( 與
的相似度),但:
- 長序列中,顯式交互仍可能遺漏全局隱式依賴(如 “貓” 和 “狗” 的關聯不通過直接相似,而通過 “動物” 這個隱概念);
- 多頭注意力的 “頭” 是獨立的,缺乏對 “頭間關聯” 的建模。
多頭潛在注意力的核心:引入 “潛在變量”(Latent Variable)捕捉全局隱式依賴,同時用多頭機制建模不同維度的潛在結構。
核心思想:
傳統注意力只關注 “表面關聯”(如 “蘋果” 和 “水果”),忽略 “隱藏關聯”(如 “蘋果” 和 “健康” 通過 “維生素” 關聯)。
多頭潛在注意力引入 “潛在變量”,就像在大腦中創建 “隱藏文件夾”,專門存放這些隱藏關聯。生活化比喻:
你整理照片:
- 傳統方法:按 “人物”“風景”“美食” 分類(顯式標簽);
- 多頭潛在方法:除了顯式分類,還創建 “隱藏文件夾”,自動關聯 “運動→健康→健身房”“旅行→相機→回憶” 等隱藏關系。
作用:
捕捉更深層的語義關聯,提升復雜任務(如長文本理解、跨模態推理)的效果。
4.2、詳細計算邏輯
4.2.1、潛在變量的作用
- 潛在變量 z∈R^k(k 遠小于 n):壓縮全局信息,作為 “隱式中介” 傳遞序列中不直接交互的元素依賴。
- 例:z 可理解為 “全局語義向量”,每個元素既關注顯式相似元素,也關注 z 包含的隱式全局信息。
4.2.2、多頭潛在機制
- 每個頭有獨立的潛在變量 z_h(h=1..H),建模不同維度的隱式依賴;
- 計算步驟:
① 多頭投影:,
,
(同 MHA);
② 顯式注意力:;
③ 潛在注意力:(
通過學習捕捉全局模式);
④ 融合:(或通過門控機制融合);
⑤ 拼接多頭結果,輸出最終序列表示。
4.2.3、潛在變量的學習
能輔助重構原始序列信息;
- 或結合變分推斷:
4.3、優缺點
- 優點:捕捉顯式 + 隱式依賴,提升長序列全局建模能力;多頭潛在變量增加表達多樣性;
- 缺點:引入潛在變量增加模型復雜度(需學習 z_h 的先驗 / 分布);訓練不穩定(潛在變量難優化)。
- 應用:少樣本學習、長文本理解(如文檔摘要)、跨模態建模(如圖文隱式關聯)。
4.4、示例代碼
import torch
import torch.nn as nn
import torch.nn.functional as Fclass MultiHeadLatentAttention(nn.Module):"""多頭潛在注意力 (Multi-Head Latent Attention) 模塊與標準多頭注意力不同,MLA引入了可學習的潛在變量 (latent variables),這些潛在變量作為查詢 (Query) 來關注輸入序列,使模型能夠從輸入中提取更抽象的表示。常用于變分自編碼器 (VAE)、生成對抗網絡 (GAN) 等生成模型。核心思想: 使用可學習的潛在變量作為"探針",主動從輸入中提取信息,而非僅依賴輸入自身的交互。"""def __init__(self, embed_dim: int, # 輸入嵌入維度num_heads: int, # 注意力頭數量num_latents: int, # 潛在變量數量latent_dim: int = None, # 潛在變量維度dropout: float = 0.0, # Dropout概率):super().__init__()# 參數校驗self.embed_dim = embed_dimself.num_heads = num_headsself.num_latents = num_latentsself.latent_dim = latent_dim if latent_dim is not None else embed_dim# 確保維度可被頭數整除assert self.latent_dim % num_heads == 0, "latent_dim必須能被num_heads整除"self.head_dim = self.latent_dim // num_heads# 初始化可學習的潛在變量# 形狀: [num_latents, latent_dim]self.latents = nn.Parameter(torch.randn(num_latents, self.latent_dim))# 投影層self.q_proj = nn.Linear(self.latent_dim, self.latent_dim) # 潛在變量投影為查詢self.k_proj = nn.Linear(embed_dim, self.latent_dim) # 輸入投影為鍵self.v_proj = nn.Linear(embed_dim, self.latent_dim) # 輸入投影為值self.out_proj = nn.Linear(self.latent_dim, embed_dim) # 輸出投影# Dropout和縮放因子self.dropout = nn.Dropout(dropout)self.scale = self.head_dim ** -0.5def forward(self, x: torch.Tensor, # 輸入序列 [batch_size, seq_len, embed_dim]mask: torch.Tensor = None # 可選的注意力掩碼 [batch_size, seq_len]) -> torch.Tensor:"""前向傳播過程"""batch_size, seq_len, _ = x.shape# 1. 準備查詢 (Query): 從潛在變量生成# 形狀: [batch_size, num_latents, latent_dim]q = self.q_proj(self.latents).unsqueeze(0).expand(batch_size, -1, -1)# 2. 準備鍵 (Key) 和值 (Value): 從輸入生成# 形狀: [batch_size, seq_len, latent_dim]k = self.k_proj(x)v = self.v_proj(x)# 3. 將張量重塑為多頭形式# 形狀: [batch_size, num_heads, num_latents, head_dim]q = q.view(batch_size, self.num_latents, self.num_heads, self.head_dim).transpose(1, 2)# 形狀: [batch_size, num_heads, seq_len, head_dim]k = k.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)v = v.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)# 4. 計算注意力分數 (點積)# 形狀: [batch_size, num_heads, num_latents, seq_len]attn_scores = torch.matmul(q, k.transpose(-2, -1)) * self.scale# 5. 應用注意力掩碼 (如果提供)if mask is not None:# 擴展掩碼維度以匹配注意力分數mask = mask.unsqueeze(1).unsqueeze(1) # [batch_size, 1, 1, seq_len]attn_scores = attn_scores.masked_fill(mask == 0, -1e9)# 6. 應用softmax獲取注意力權重# 形狀: [batch_size, num_heads, num_latents, seq_len]attn_weights = F.softmax(attn_scores, dim=-1)attn_weights = self.dropout(attn_weights)# 7. 加權聚合值# 形狀: [batch_size, num_heads, num_latents, head_dim]output = torch.matmul(attn_weights, v)# 8. 重塑并通過輸出投影層# 形狀: [batch_size, num_latents, latent_dim]output = output.transpose(1, 2).contiguous().view(batch_size, self.num_latents, self.latent_dim)# 最終輸出形狀: [batch_size, num_latents, embed_dim]return self.out_proj(output)5、四種注意力的總結
| 機制 | 核心優化點 | 類比場景 | 典型優勢 |
|---|---|---|---|
| 稀疏注意力 | 減少計算量(只關注重要部分) | 跳讀一本書 | 長序列處理效率提升 |
| FlashAttention | 優化內存訪問順序 | 一次性準備好所有食材再做飯 | 速度快、省顯存 |
| 多查詢注意力 | 共享參數(K/V) | 小組作業共享工具 | 推理速度快、參數少 |
| 多頭潛在注意力 | 捕捉隱藏關聯 | 創建隱藏文件夾整理照片 | 深層語義理解能力更強 |
- 稀疏注意力:少看(只看關鍵部分)—— 像讀長文章只看段落首尾句,抓重點省時間。
- FlashAttention:快算(不改邏輯只提速)—— 像用計算器算算術,和手算結果一樣,但速度快 10 倍。
- 多查詢注意力:共享算(共用參數)—— 像辦公室共用打印機,多人用一臺也不耽誤事,還省成本。
- 多頭潛在注意力:壓縮算(先提煉核心再處理)—— 像把長視頻先轉成文字摘要,再根據摘要找片段,既懂全局又抓細節。
6、信息處理:分離角色
6.1、?查詢(Query)、鍵(Key)、值(Value)的分工
- 查詢(Q):表示 “當前 token 在找什么”,類似于 “問題”。
- 鍵(K):表示 “每個 token 有什么”,類似于 “答案的索引”。
- 值(V):表示 “每個 token 實際攜帶的信息”,類似于 “答案內容”。
6.2、為什么需要分離?
-
類比搜索引擎:
- 查詢(Q):用戶輸入的搜索關鍵詞(如 “深度學習”)。
- 鍵(K):網頁的標簽或索引(如標題、關鍵詞)。
- 值(V):網頁的實際內容。
搜索引擎通過比較 Q 和 K 的相似度,從 V 中提取相關信息。注意力機制同理:通過 Q 和 K 的點積計算相似度,從 V 中加權聚合信息。












:結合生活案例,介紹 10 種常見模型)





 1233. 刪除子文件夾 (排序))
