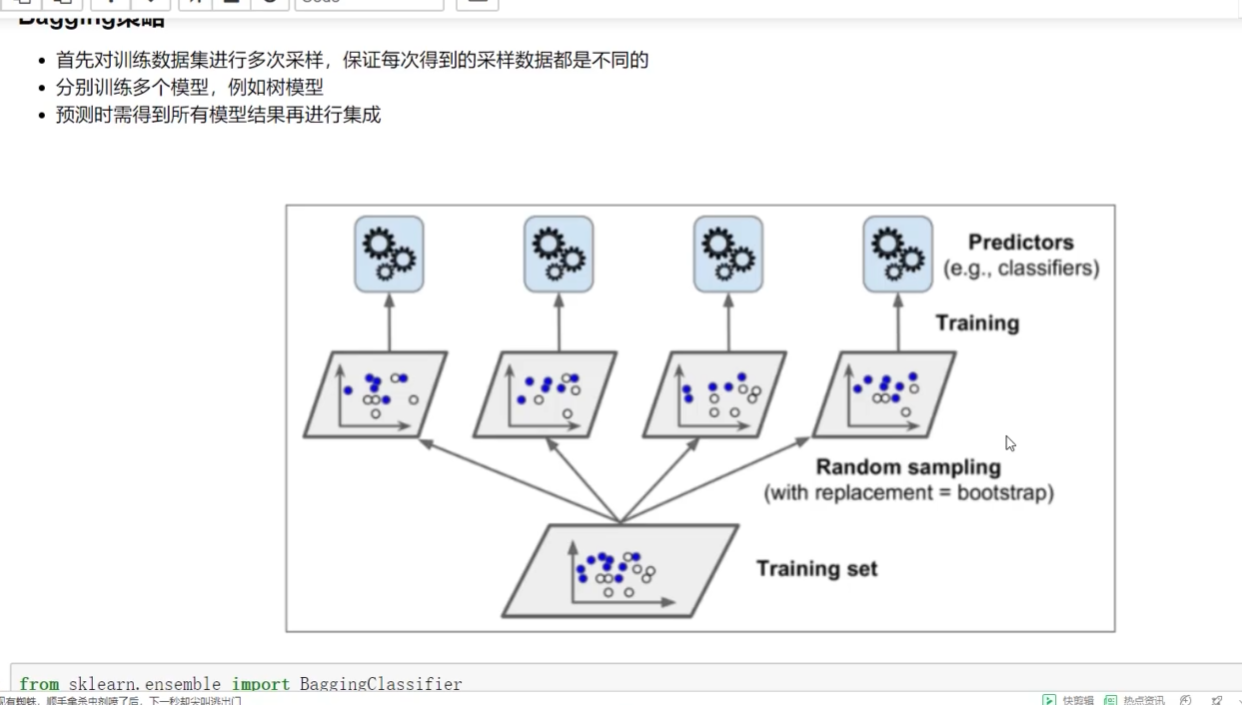
baggibg(rf隨機森林)? adaboostibg
用來展示
Project Jupyter | Home
展示源碼
Eclipse IDE | The Eclipse Foundation
Eclipse 下載 |Eclipse 基金會
?
教程8-Adaboost決策邊界效果_嗶哩嗶哩_bilibili
(23 封私信) 圖解機器學習神器:Scikit-Learn - 知乎
?
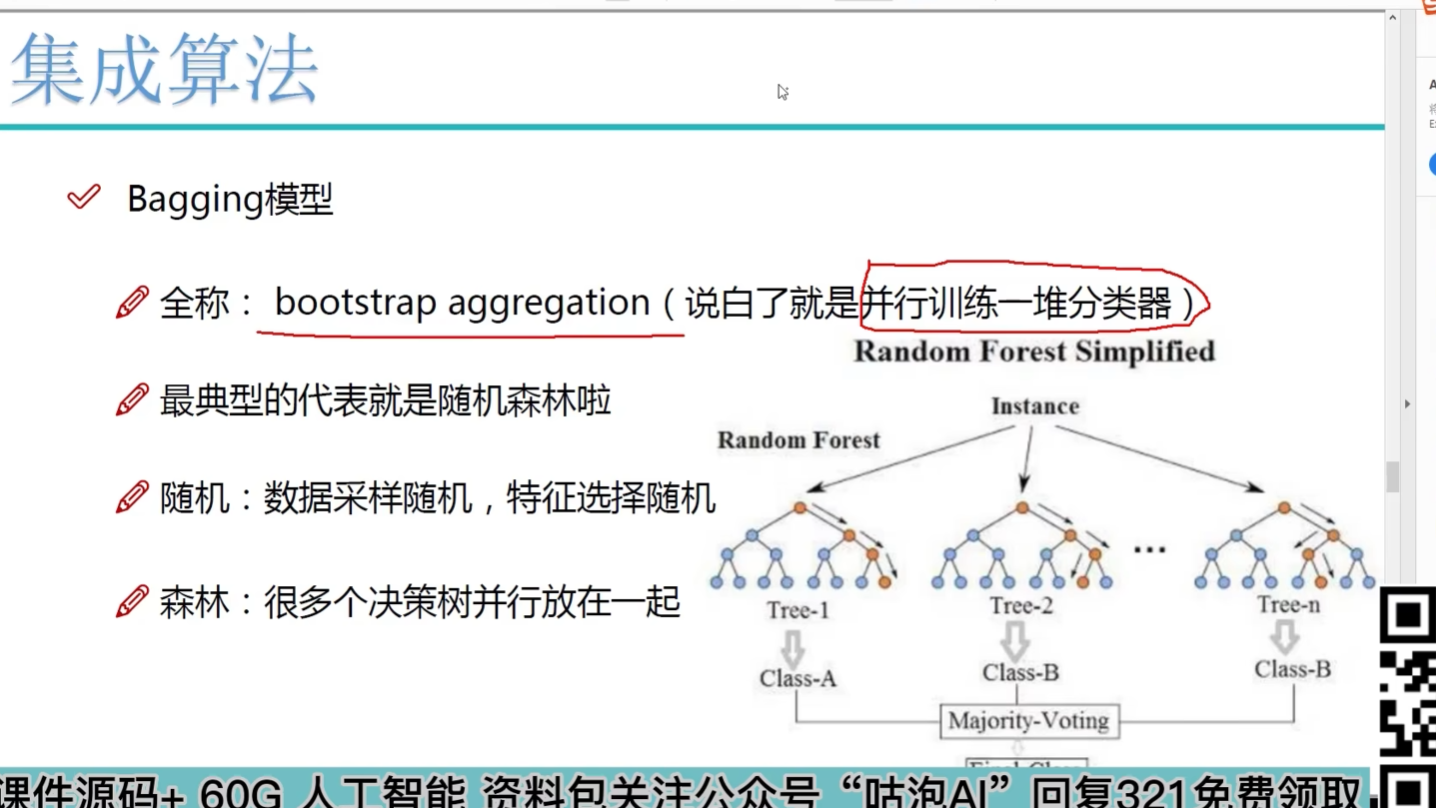
Bagging:取平均
隨機森林是典型
?

?
?
隨機:隨機樣本采樣? 隨機特征采樣? 自己測試不同比例值
森林:并行訓練一對分類器(樹)? 多個樹加在一起去平均
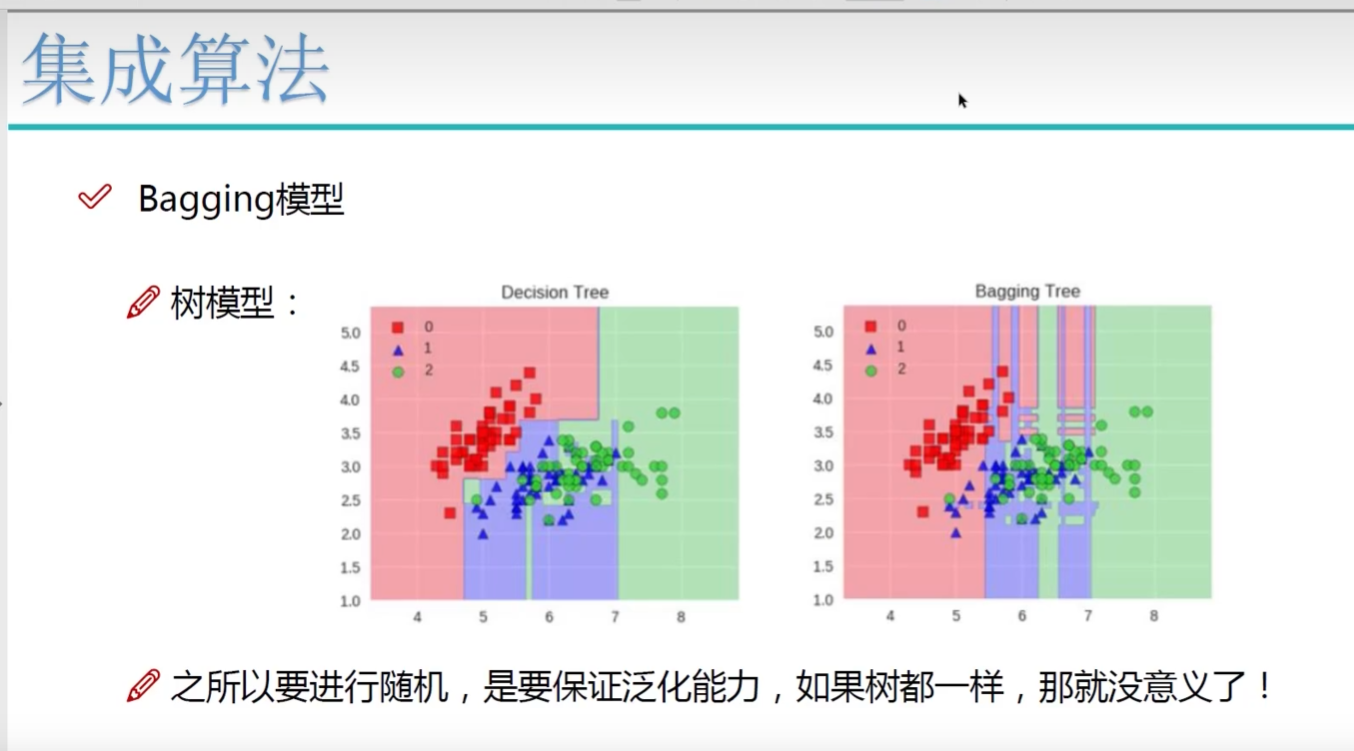
多樣性
二重:數據隨機采樣--
?

?
先取100個樣本:? 80的部分1? 80的部分2
再取100個里面的10個:6個分到部分1? ?6個分到部分2 (不同特征值)
樹不一樣? 根節點有什么特征??
全在用樹模型:
?
?
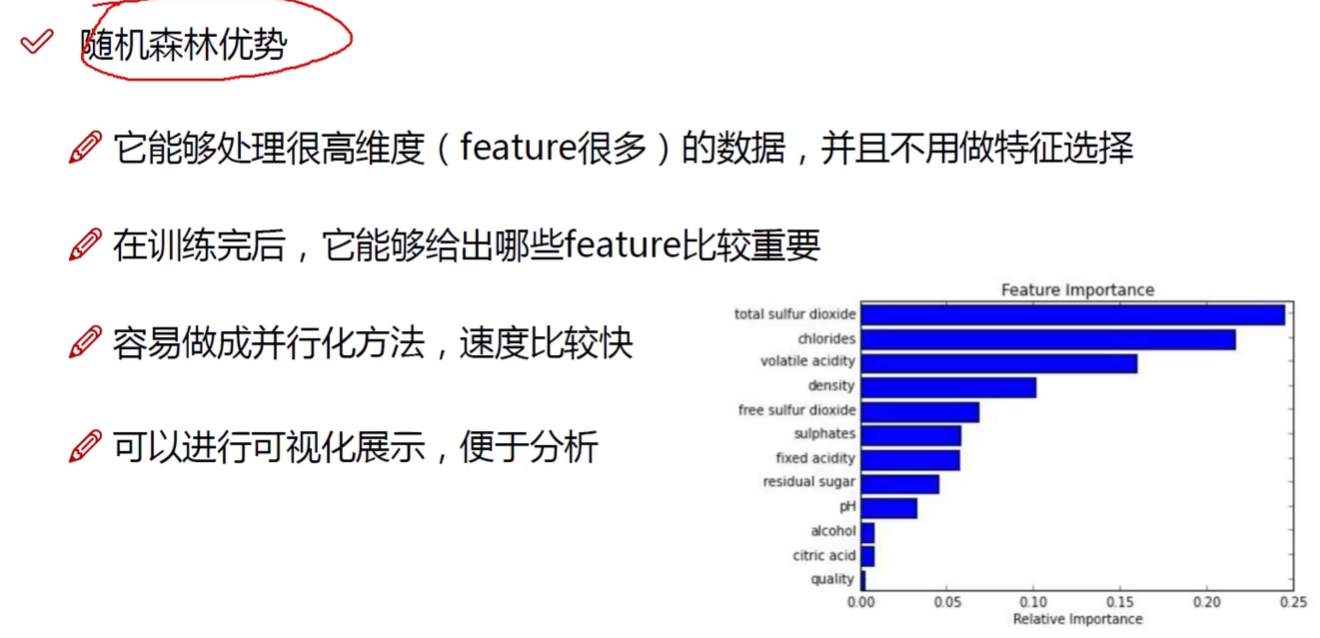
什么特征上做了什么事
隨機森林:可解釋性強 自動的特征選擇
神經網絡:無法解釋? 輸入輸出可知? 處理未知
?
?
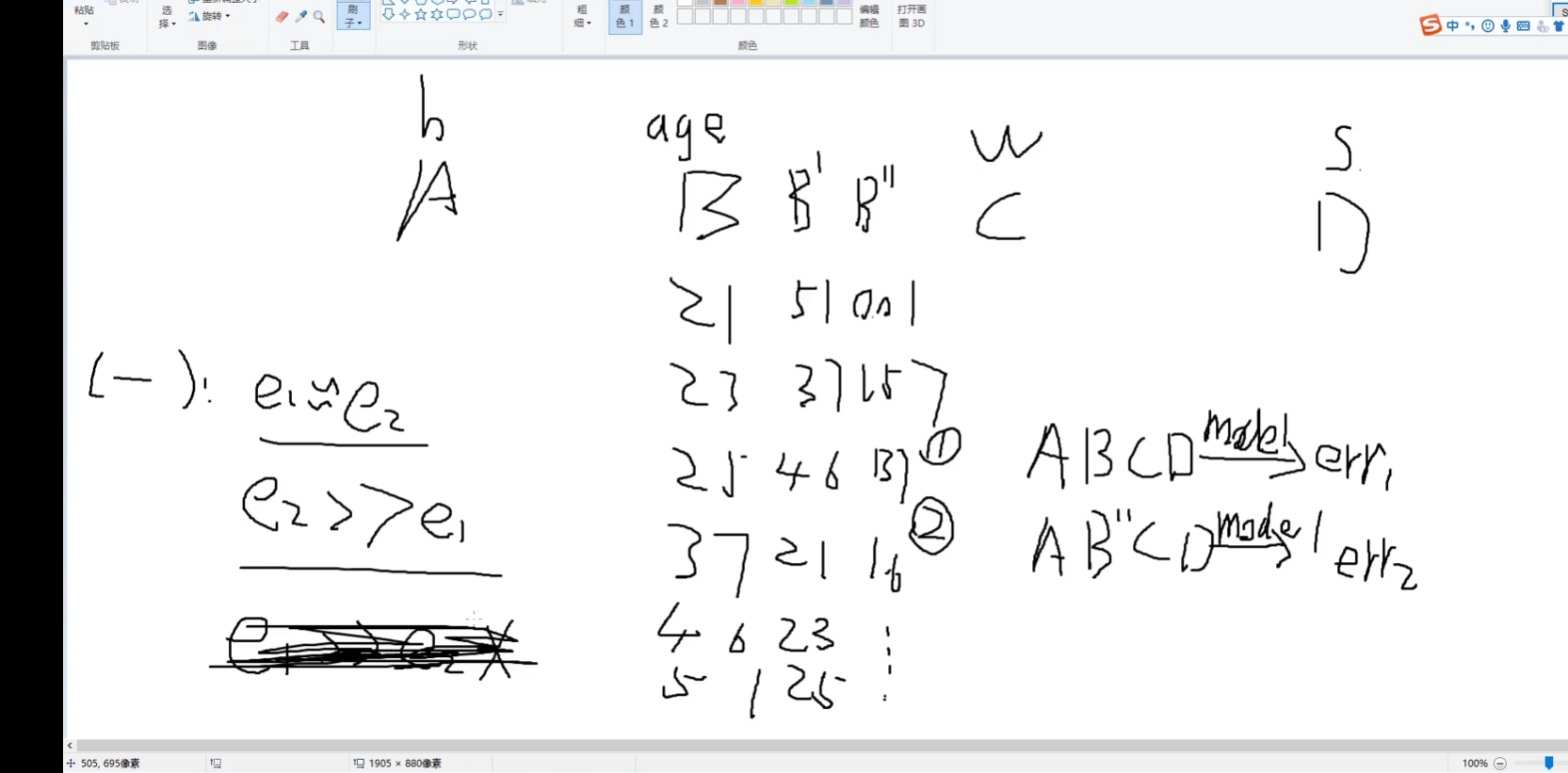
對B進行改變:? ? ?B丿? ? ? ? B丿丿
A,B,C,D類參數:如身高/體重....
error1? error2
e1≈e2? B沒用
e2>>e1? B有用
?
一些集成算法? 除了樹模型就不能再去集成了
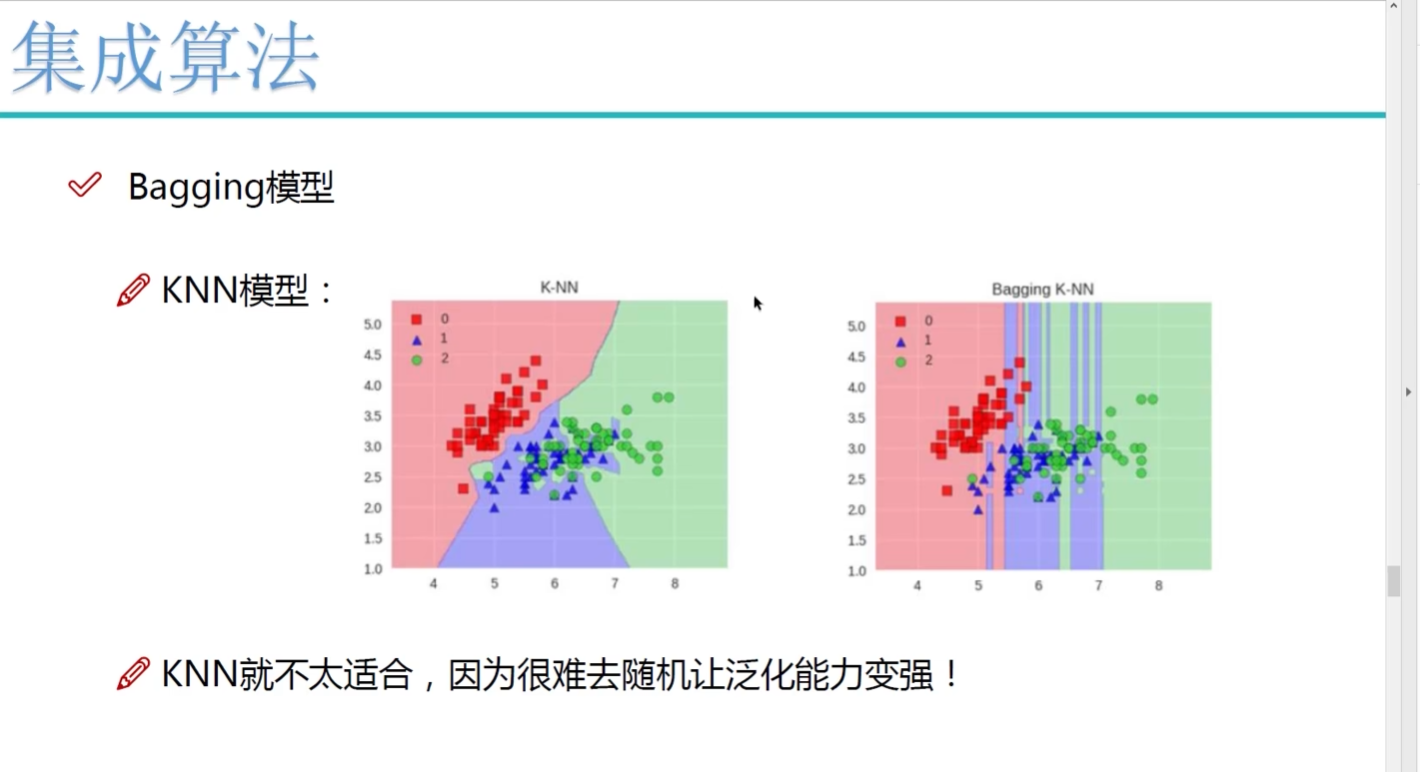
?
?
Boosting:提升
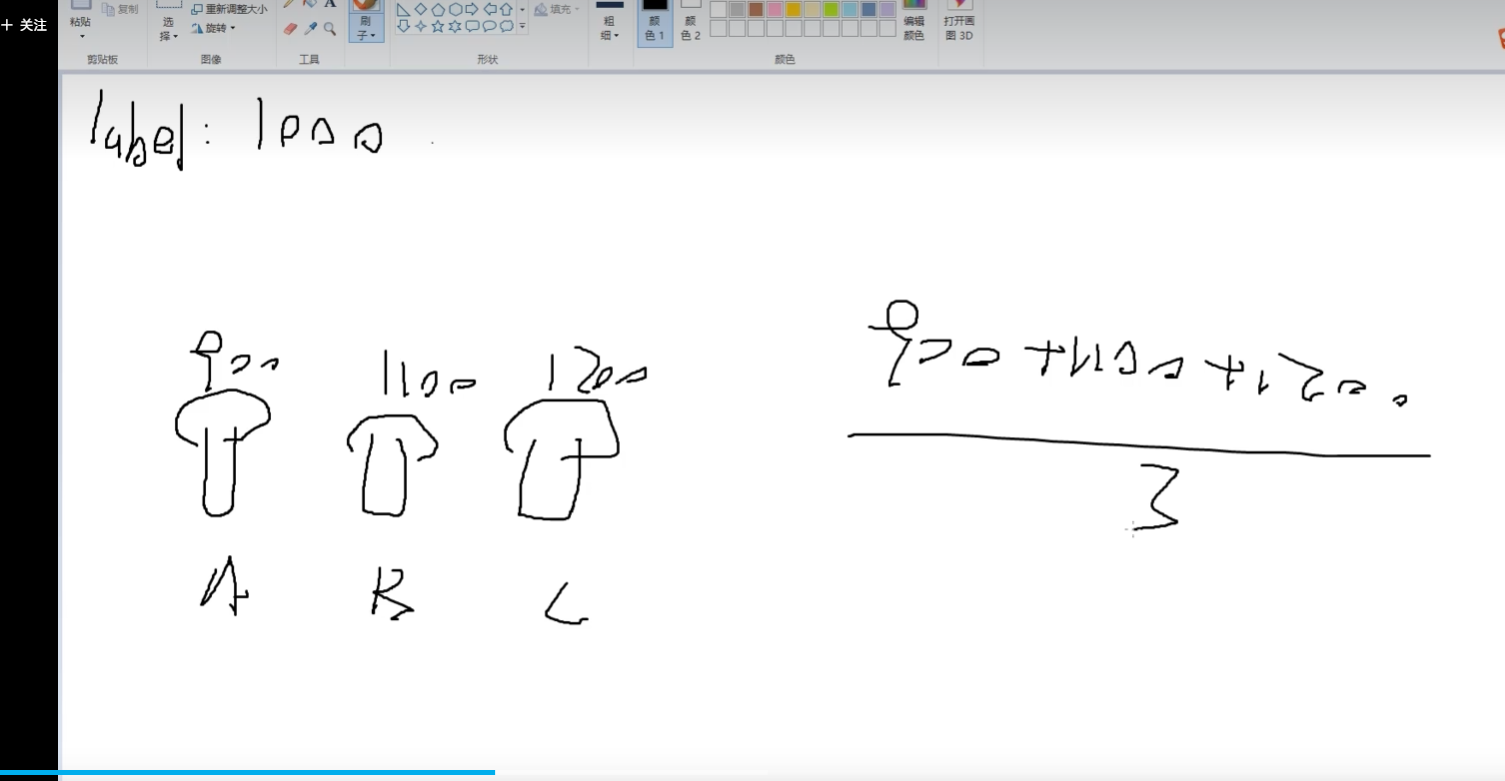
?
隨機森林:總和求均
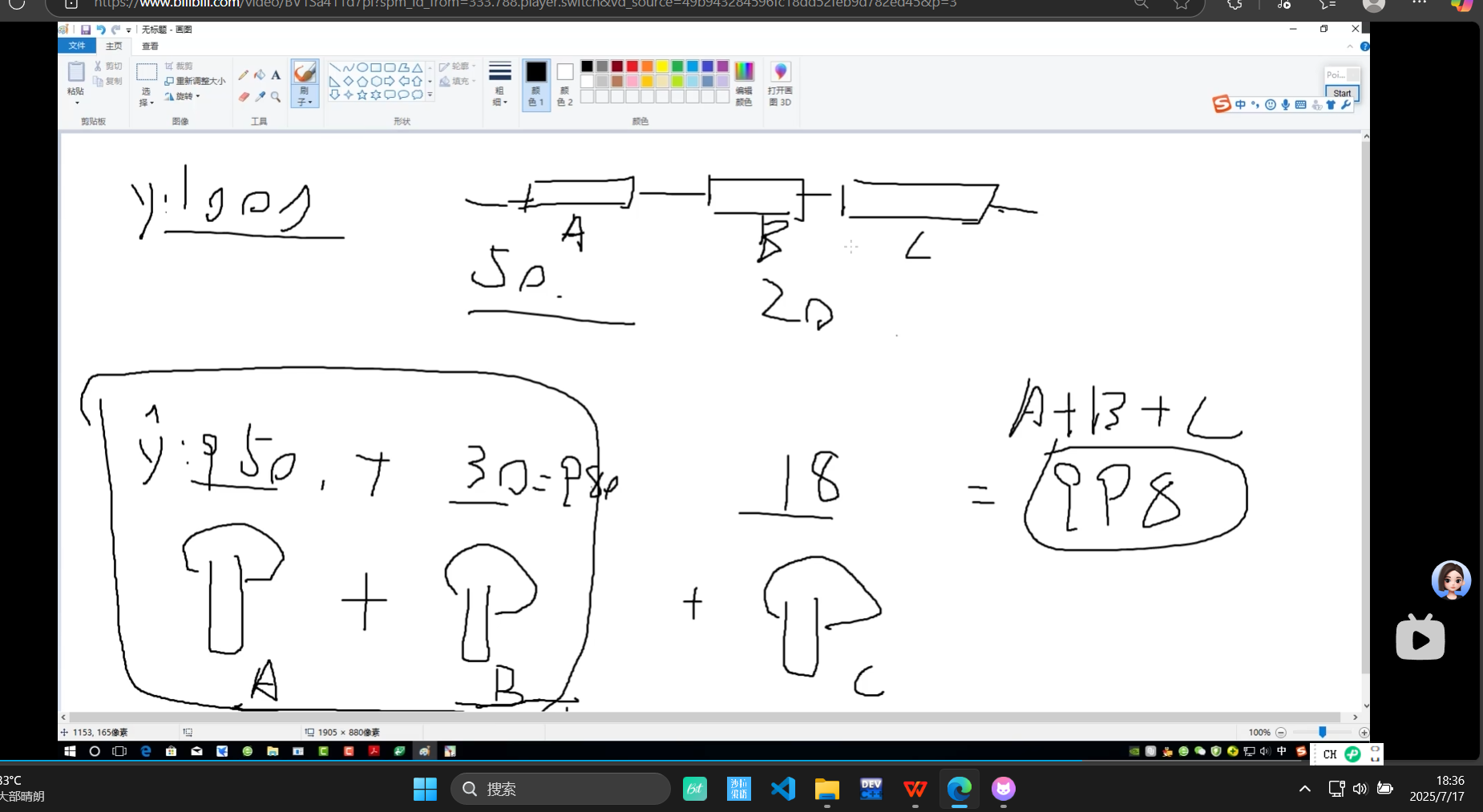
?
從100-預估950? ? ?剩下50中預估30? 剩下20中預估18
?
Adaboost:不斷切切? 讓數據有權重
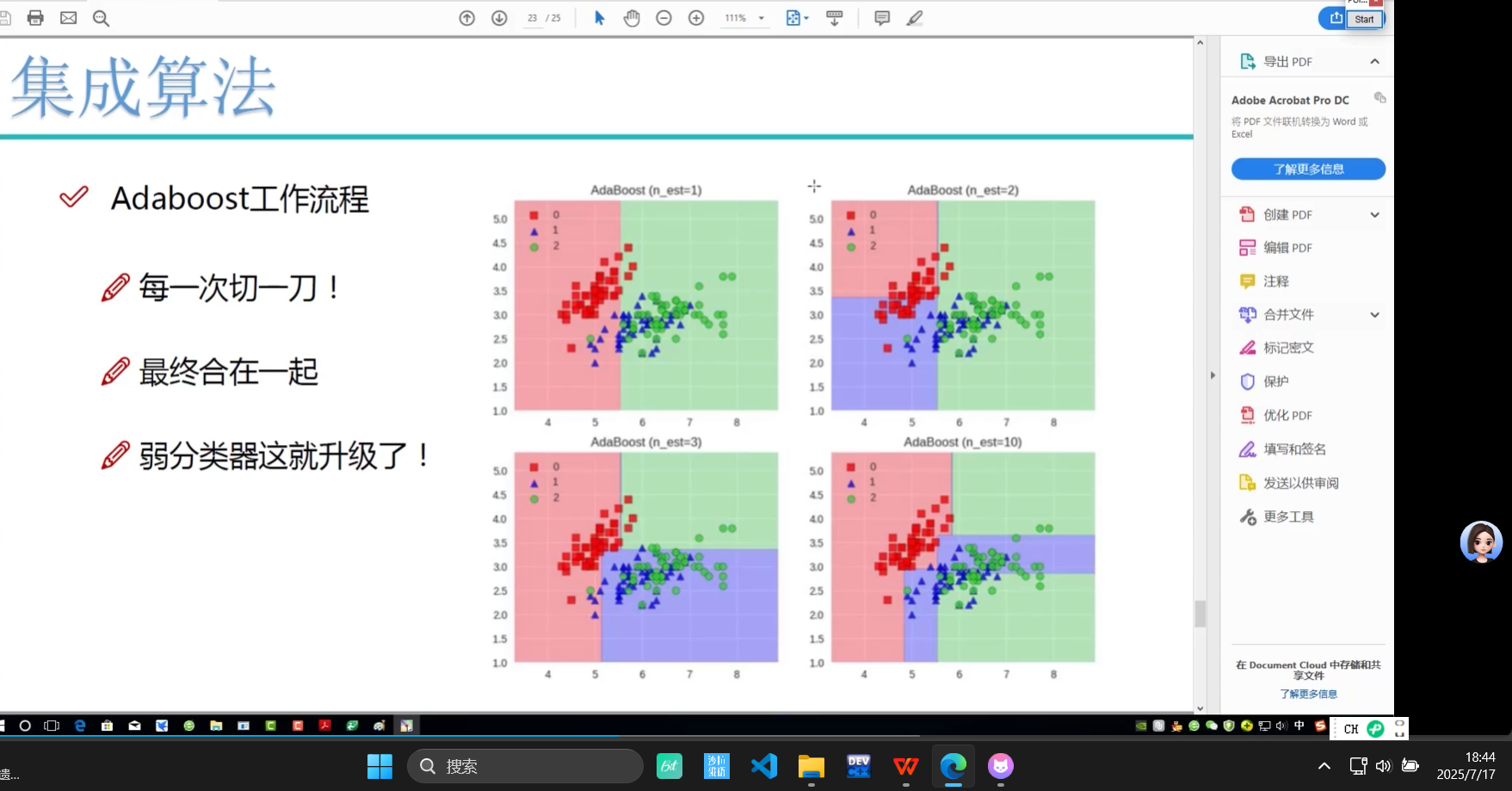
?
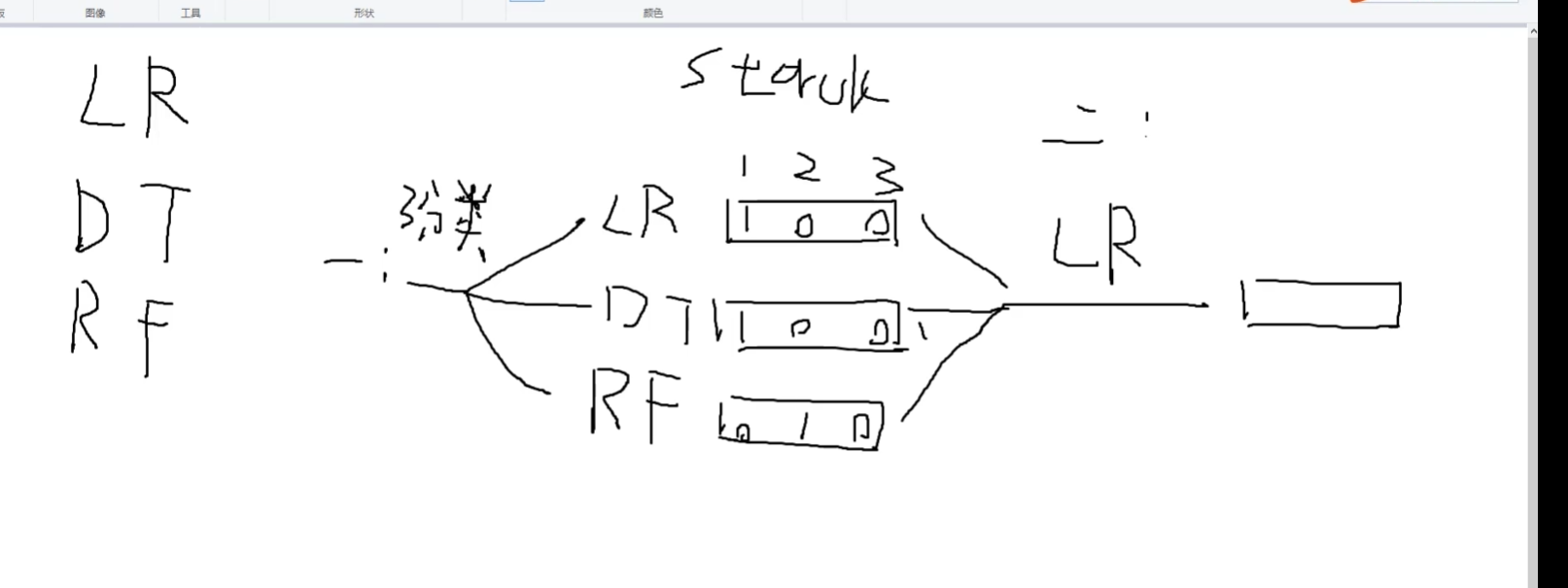
stacking:堆疊算法
LR:邏輯回歸
DT:決策樹
RF:random forest隨機森林
?
?
stacking:堆疊算法? 不常用
?
第一步多種? ? 算法LR/DT/RTF得到多種輸出
第二步? 就選一種算法得到一種輸出
?
?
?
?
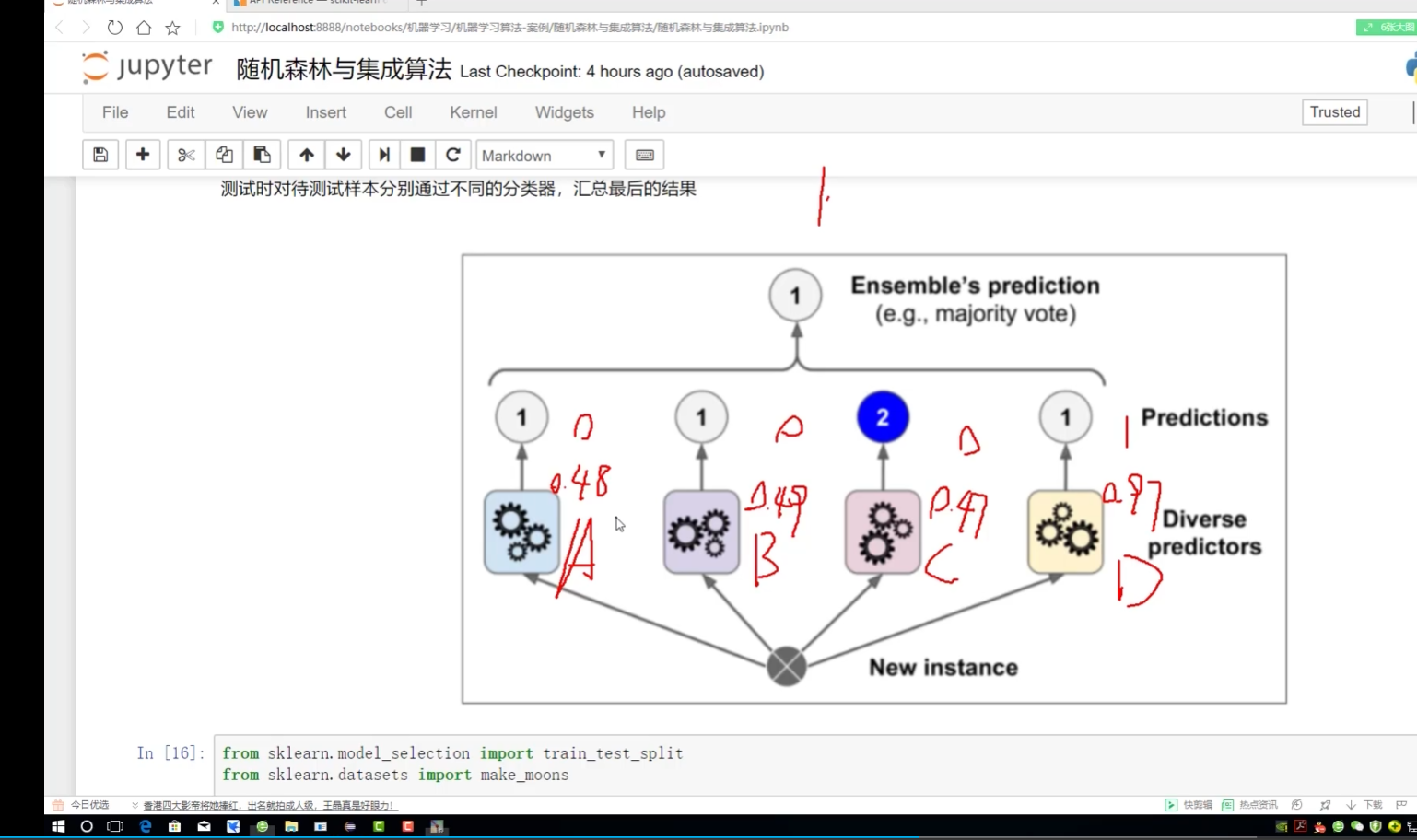
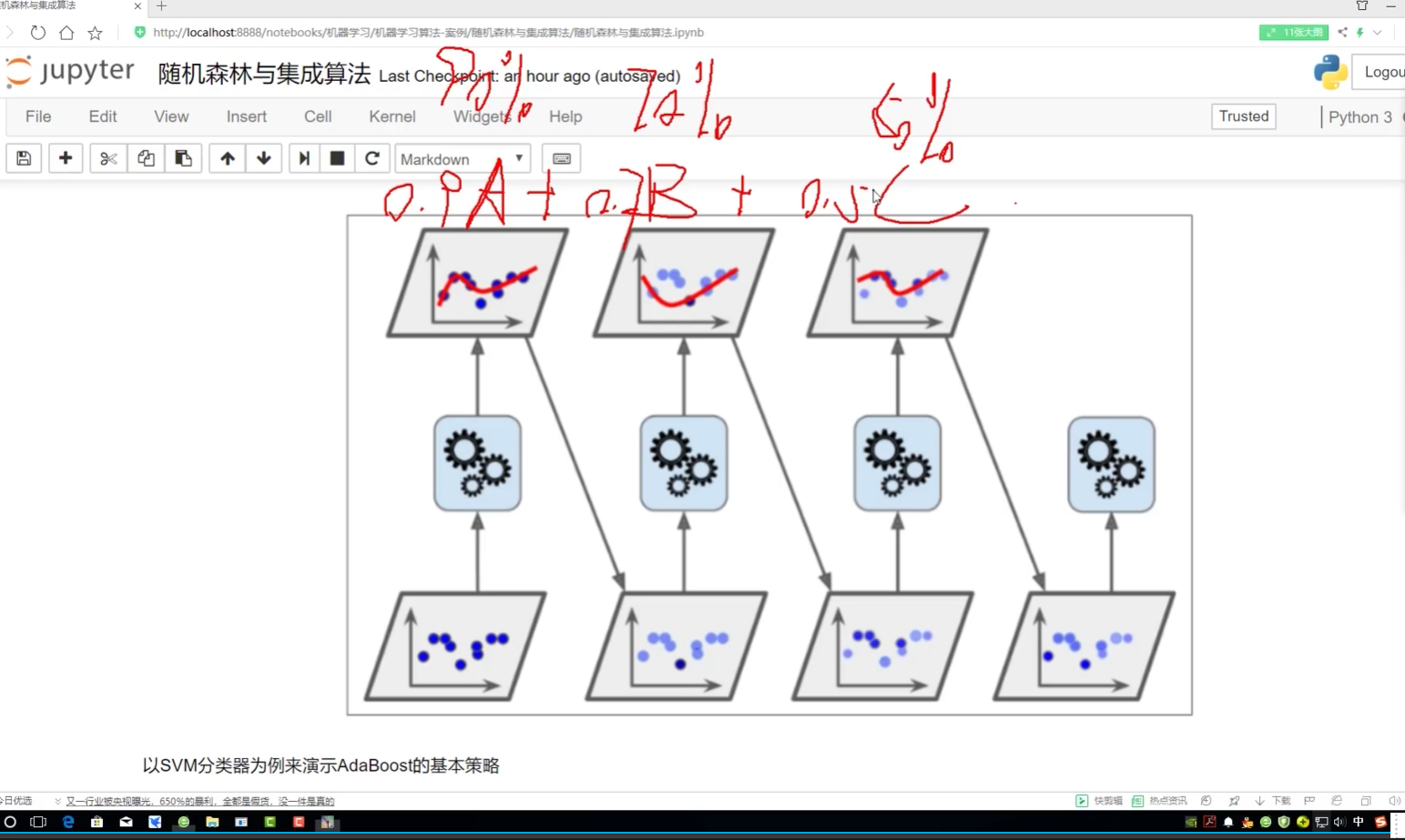
集成:3種
1.隨機森林式:并行
2.Boosting:提升? 一點一點去做? 234有關系??
3.stacking:
第一步多種????算法LR/DT/RTF得到多種輸出
第二步??就選一種算法得到一種輸出
?
集成算法思路:
軟投票:對概率加權平均
?
不認為類別:<0.5? ? ? 認為類別:>0.5
不想上課?
ABC:可能點名? D:非常可能會點名? ? soD? 會點名,去上課了
?
?
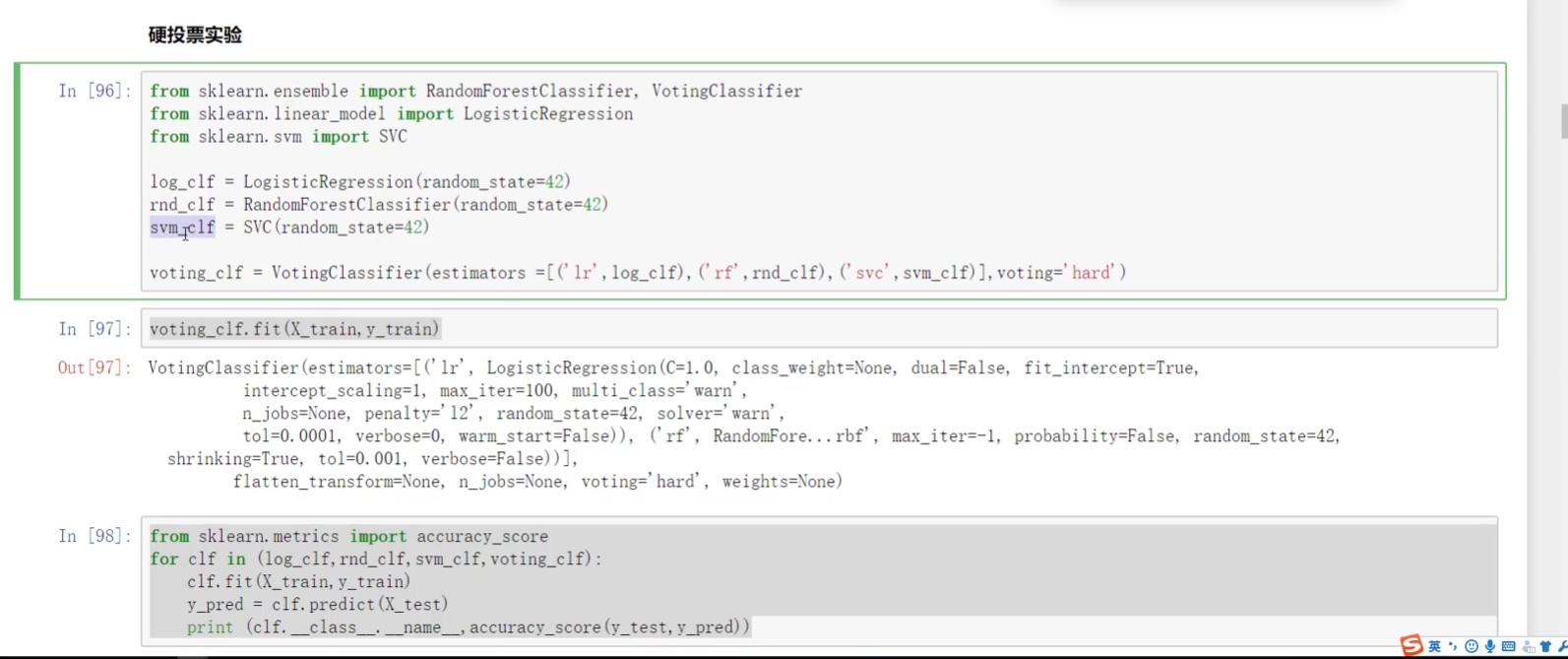
硬投票:只用結果
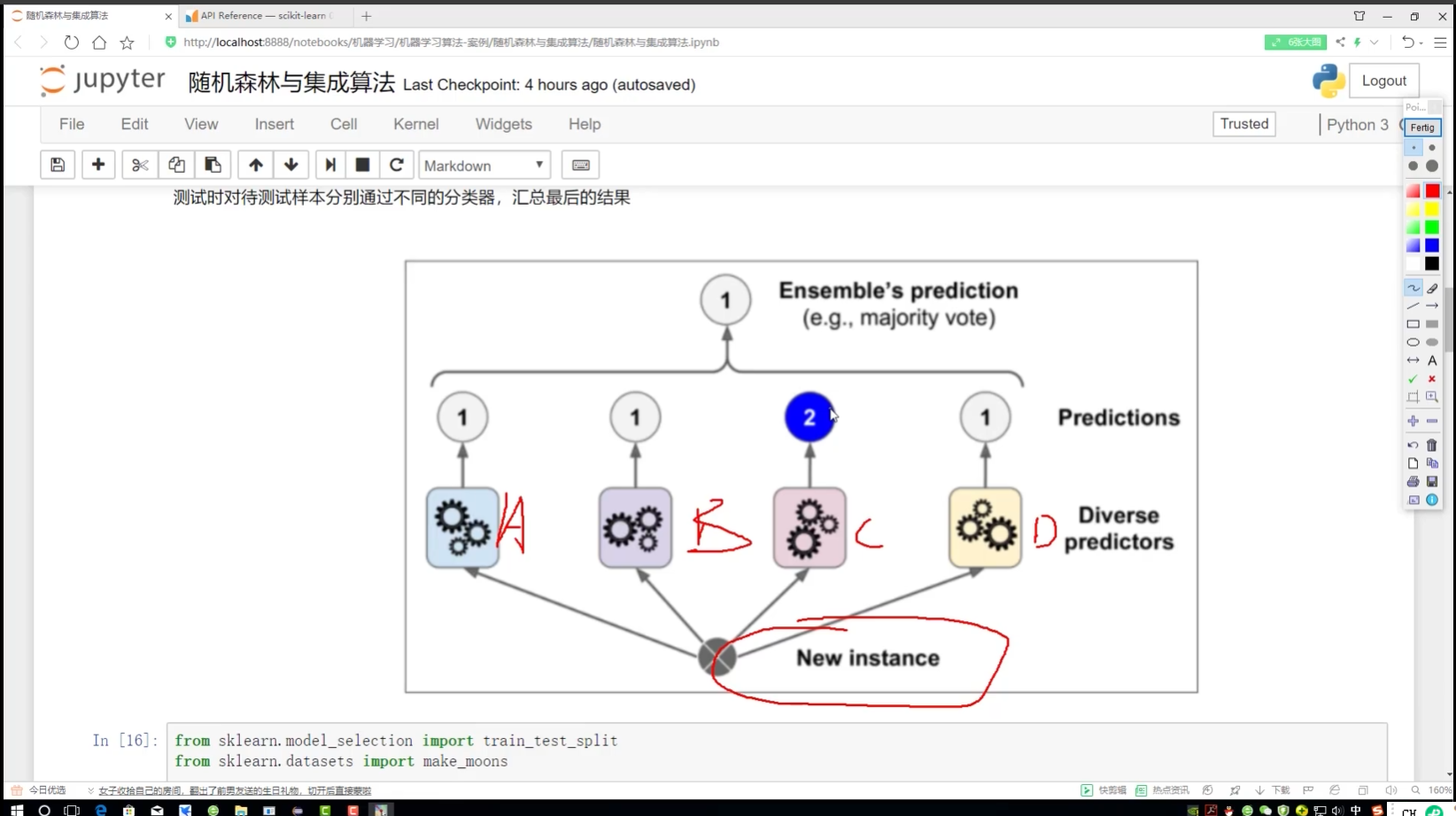
C∈2類? 2類太少? soC歸入1類
?
?
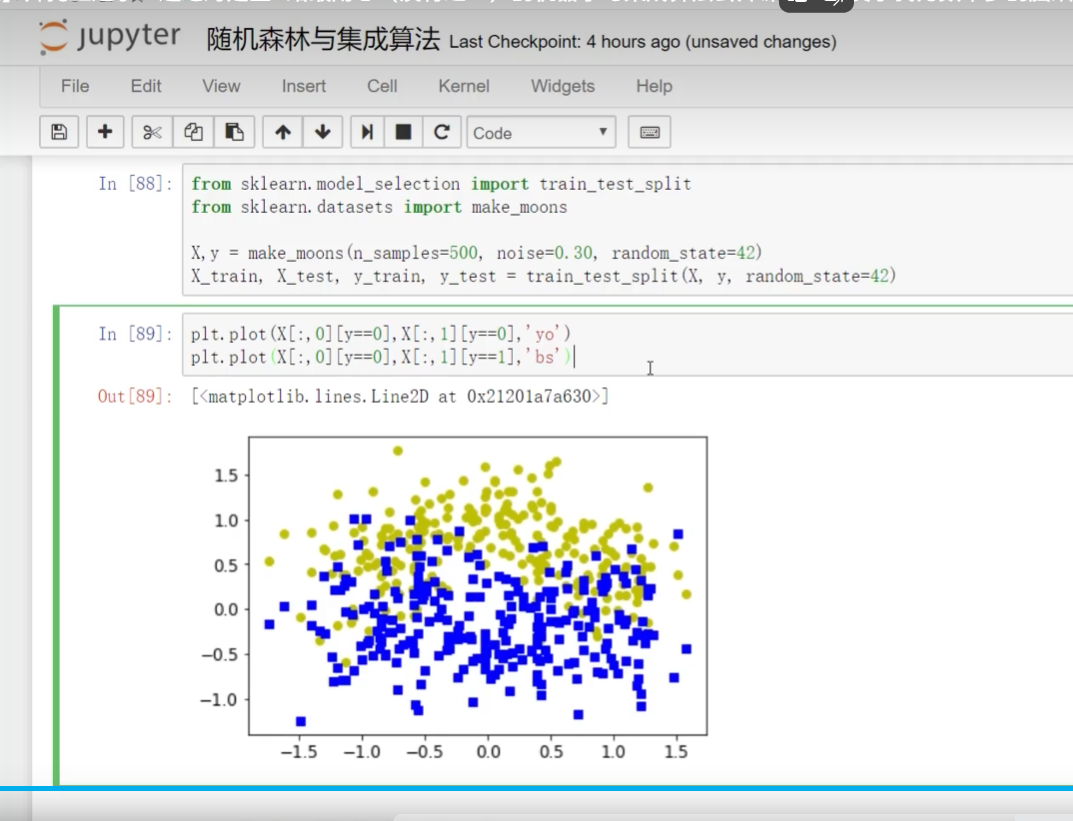
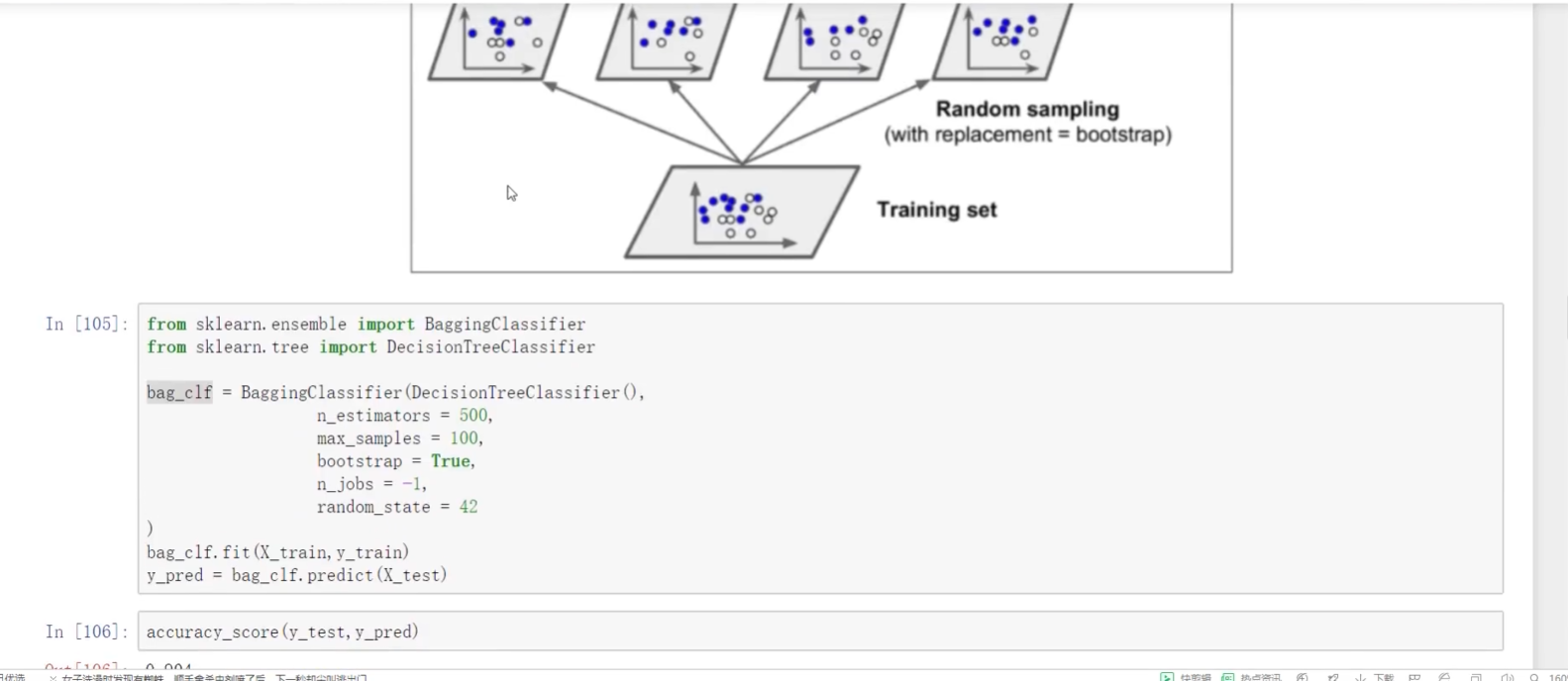
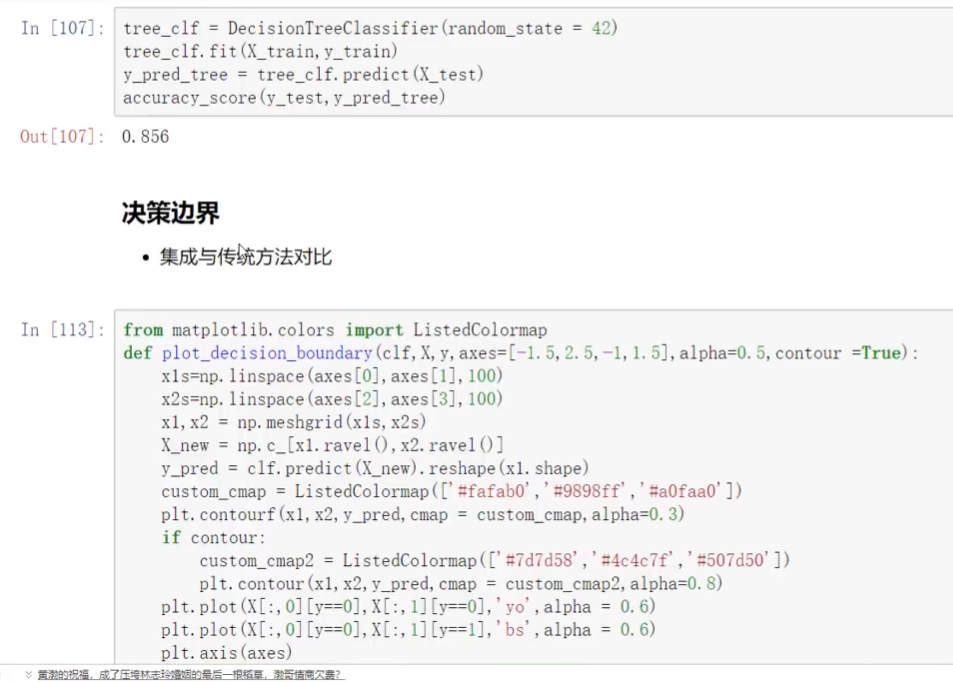
導入數據集selectio? ?split切分
?
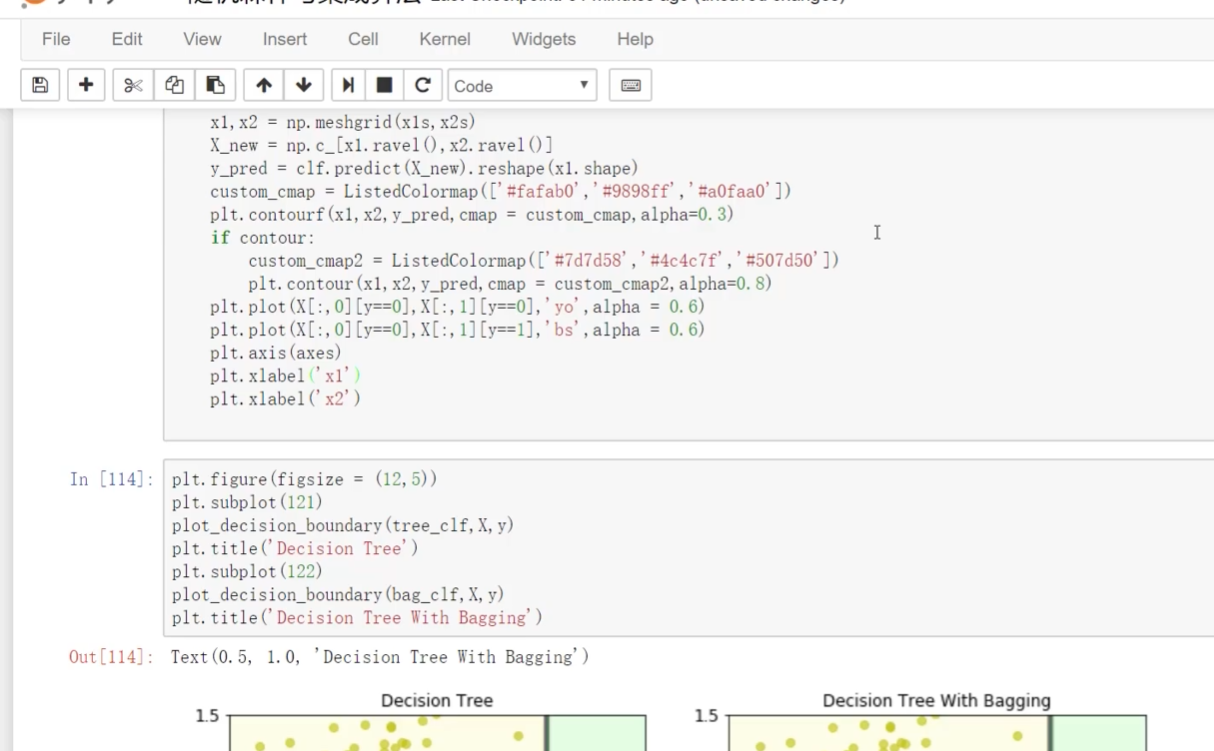
加了一個alpha:突出程度
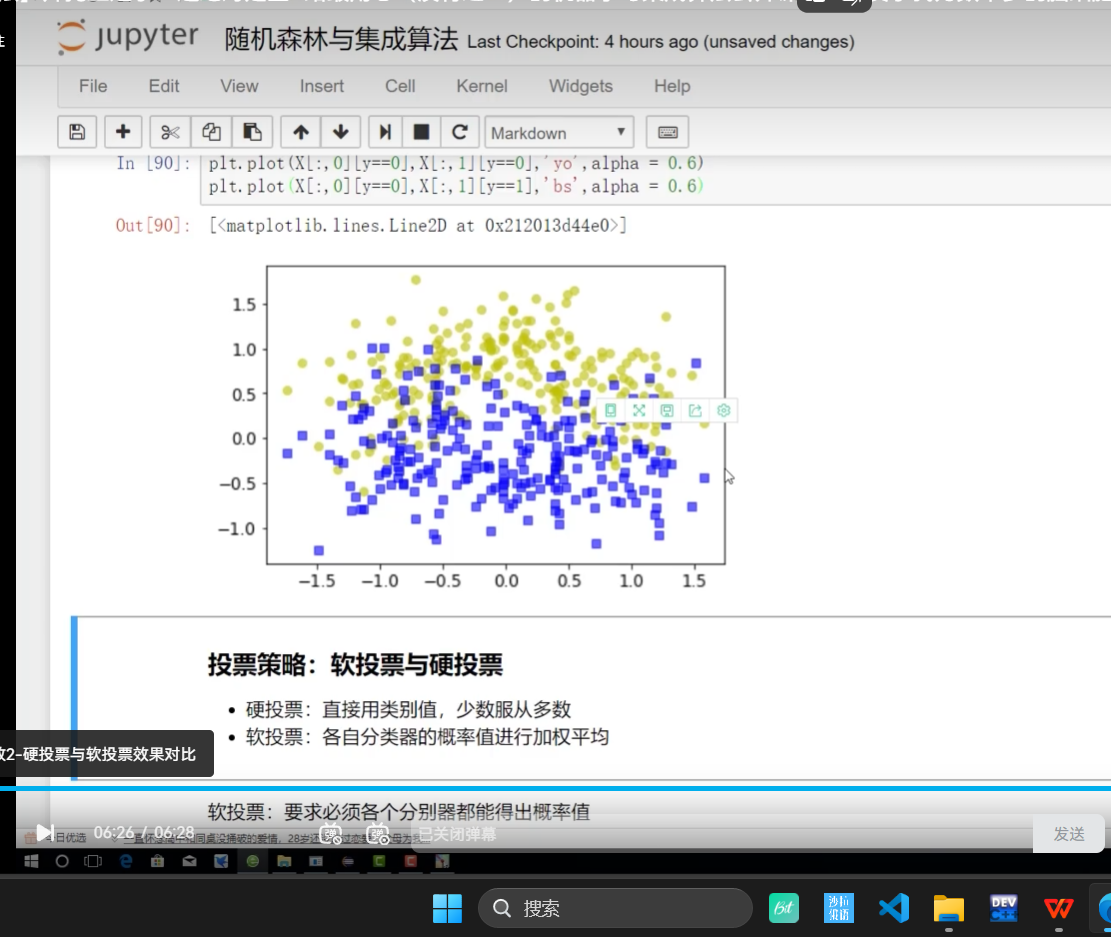
?
選算法+選類別值
?
找分類任務的投票器
?
?
?
?
?
?
clf分類器
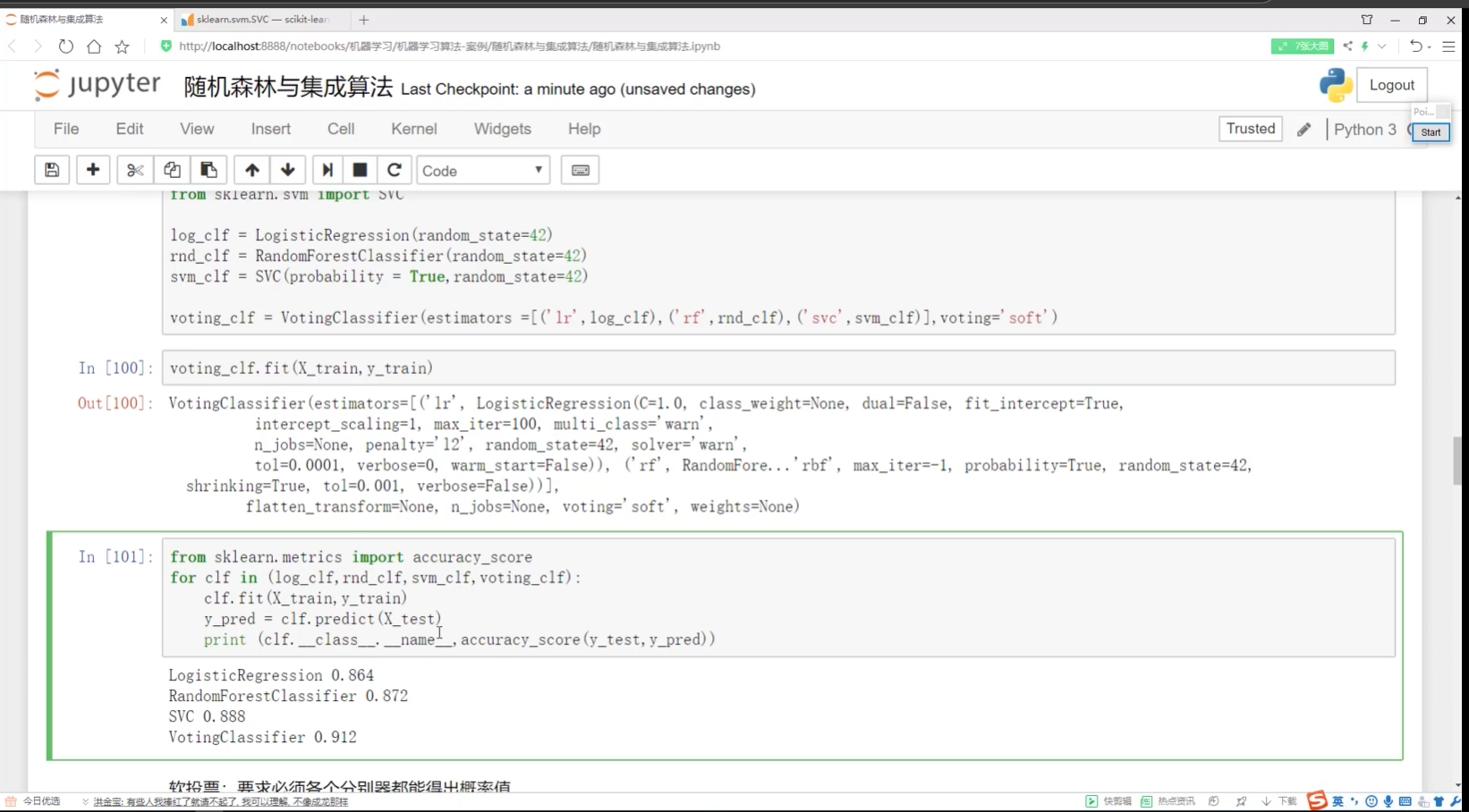
軟投票:必須各個分類器都得到概率值
?
?
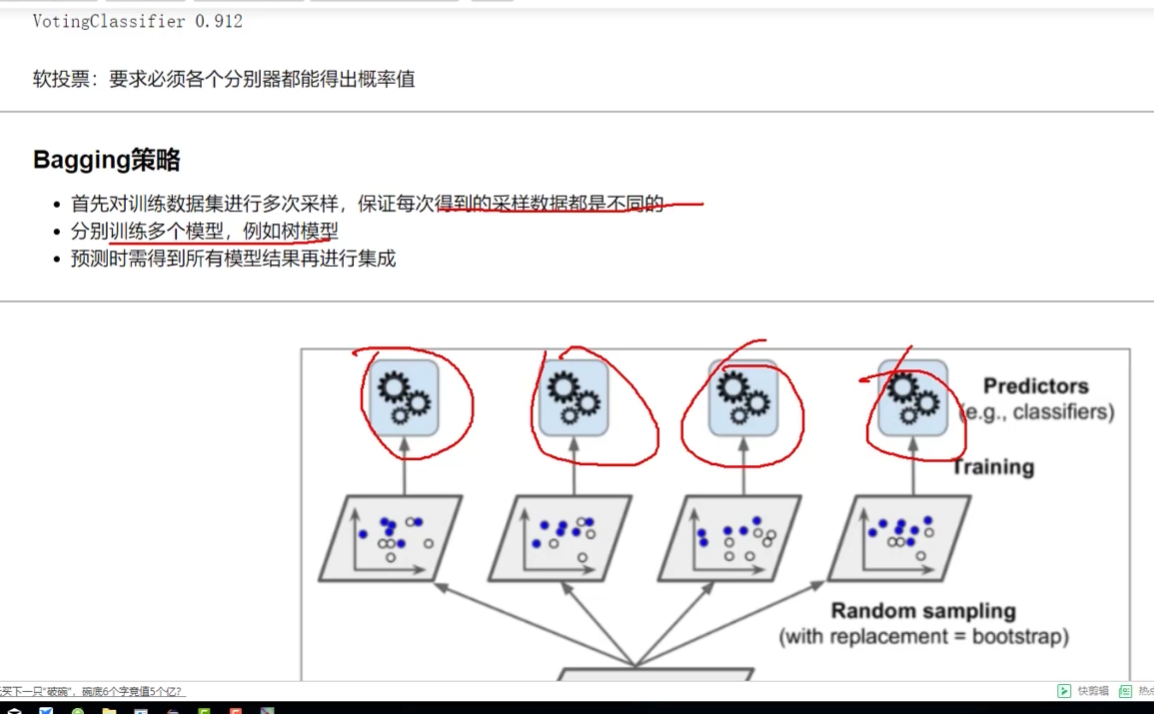
?
?
?
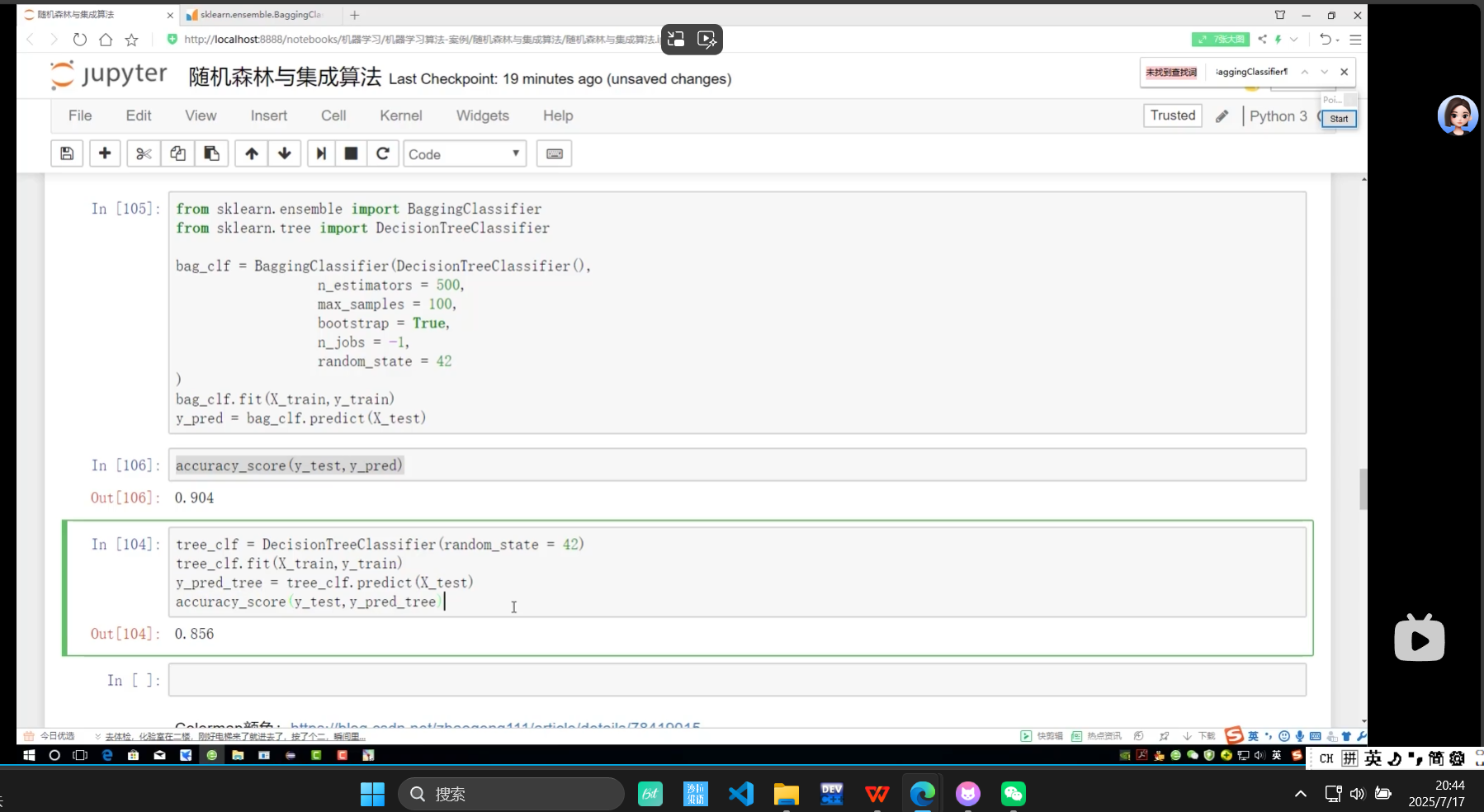
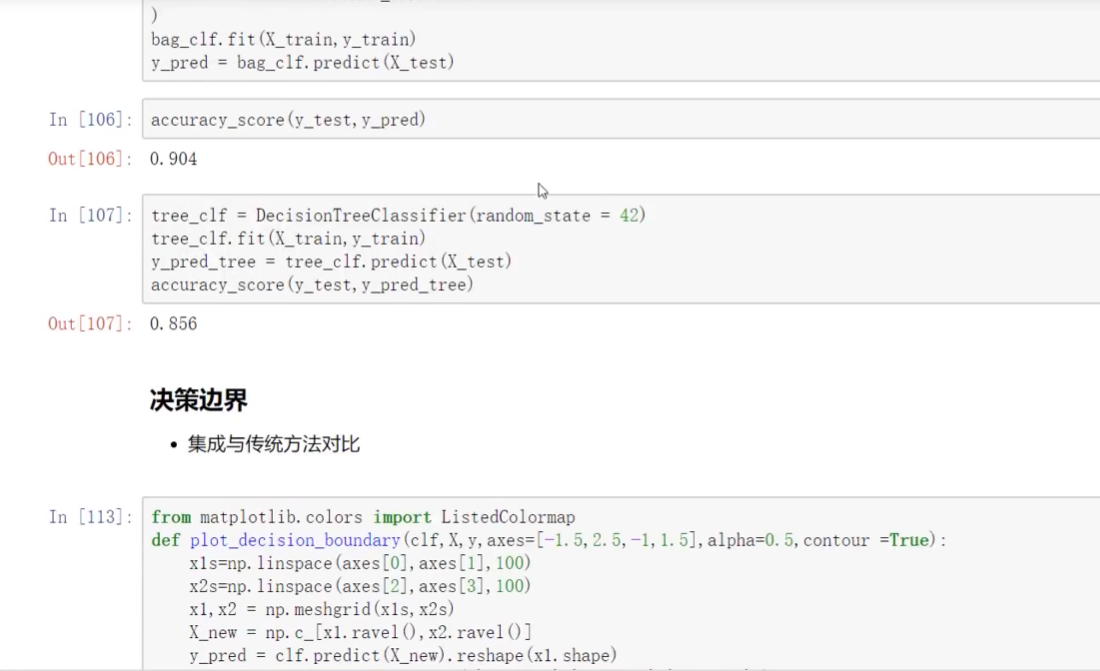
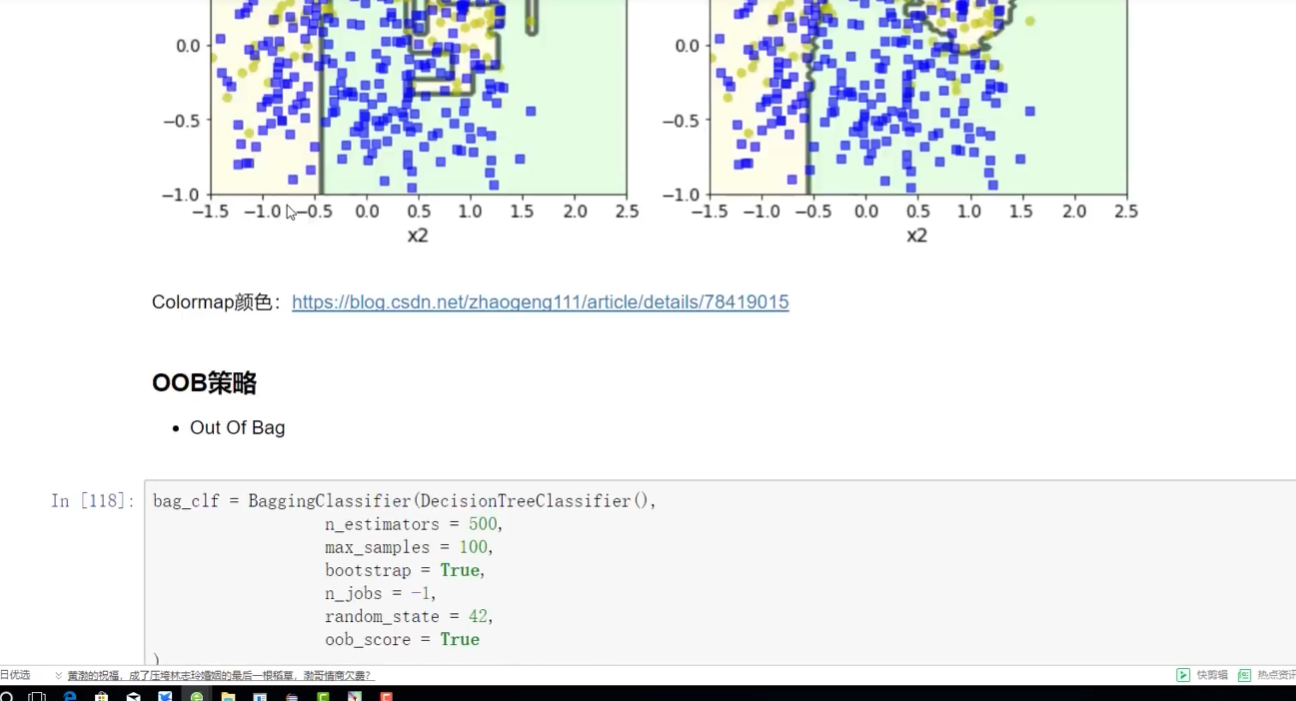
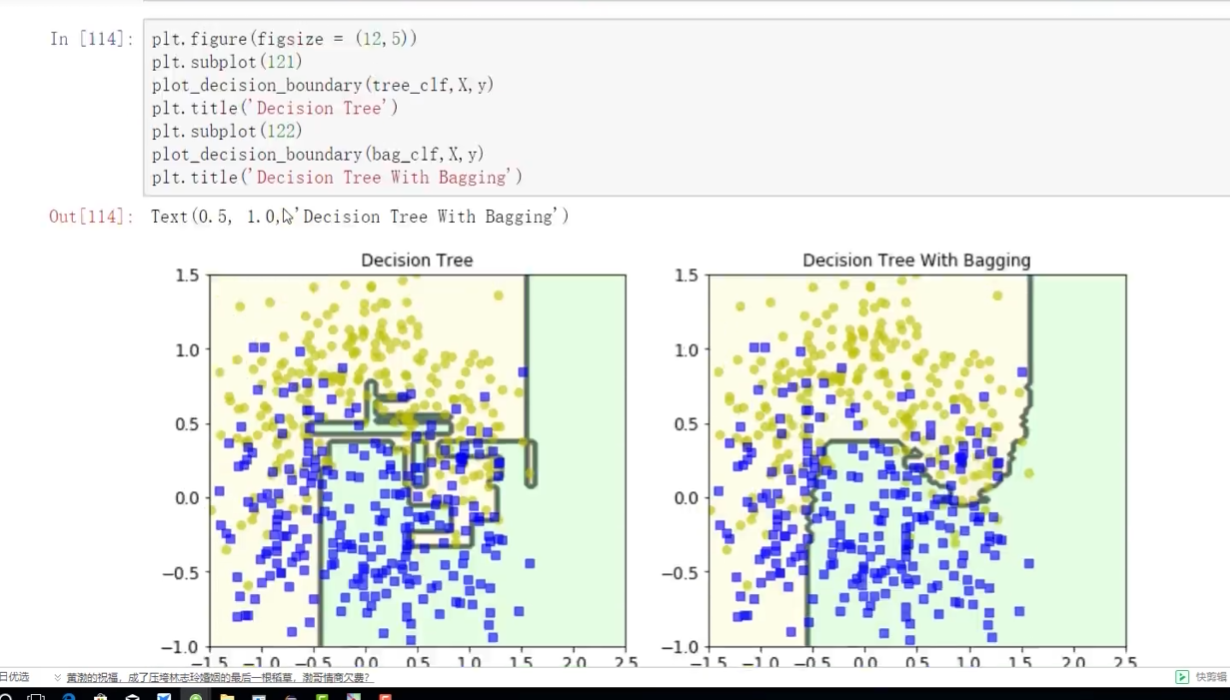
上面有bagging? 下面是沒有bagging
?
?
?
?
?
?
?
?
?
?
?
?
?

?
?
帶bagging的更好些
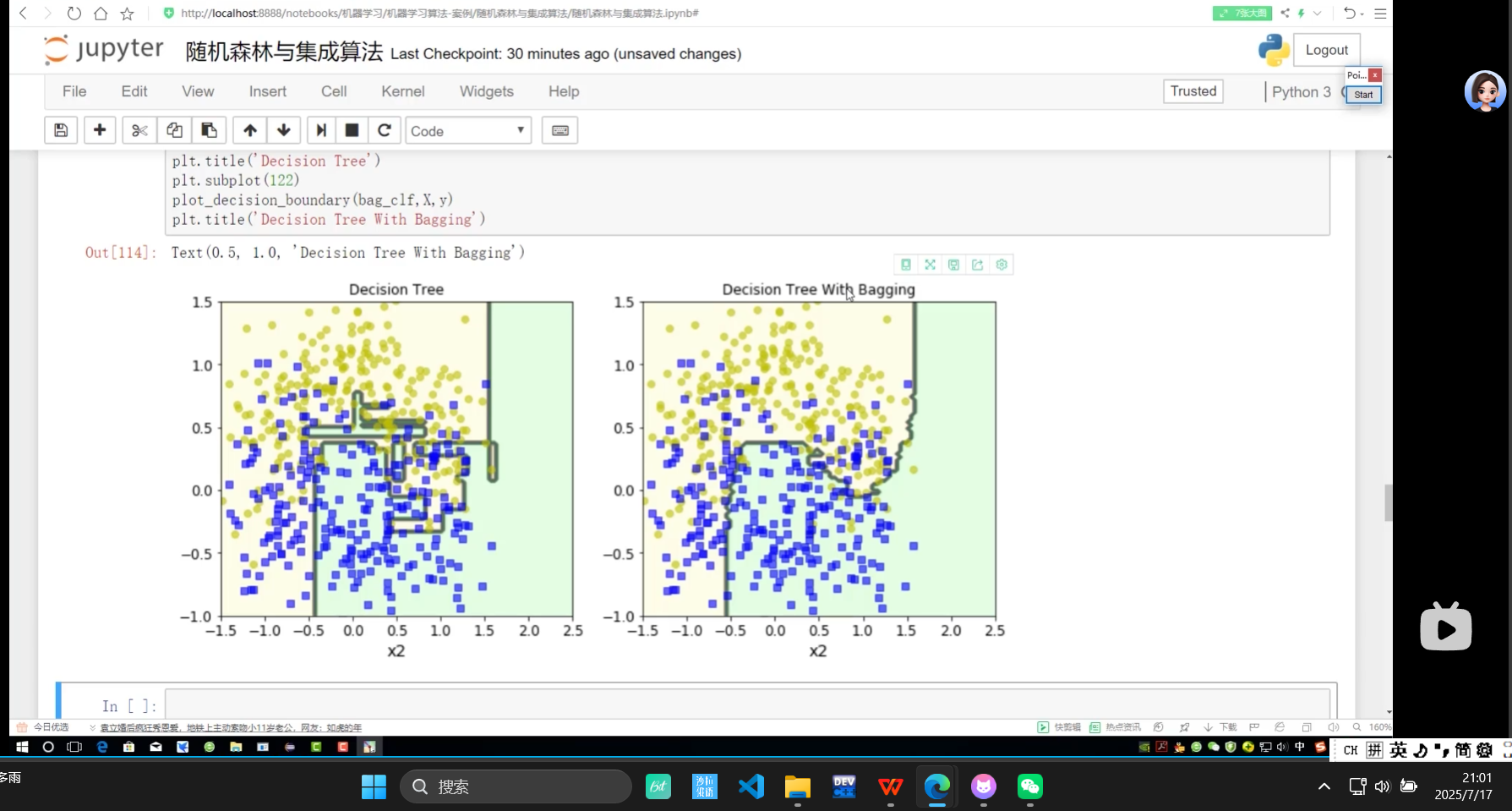
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
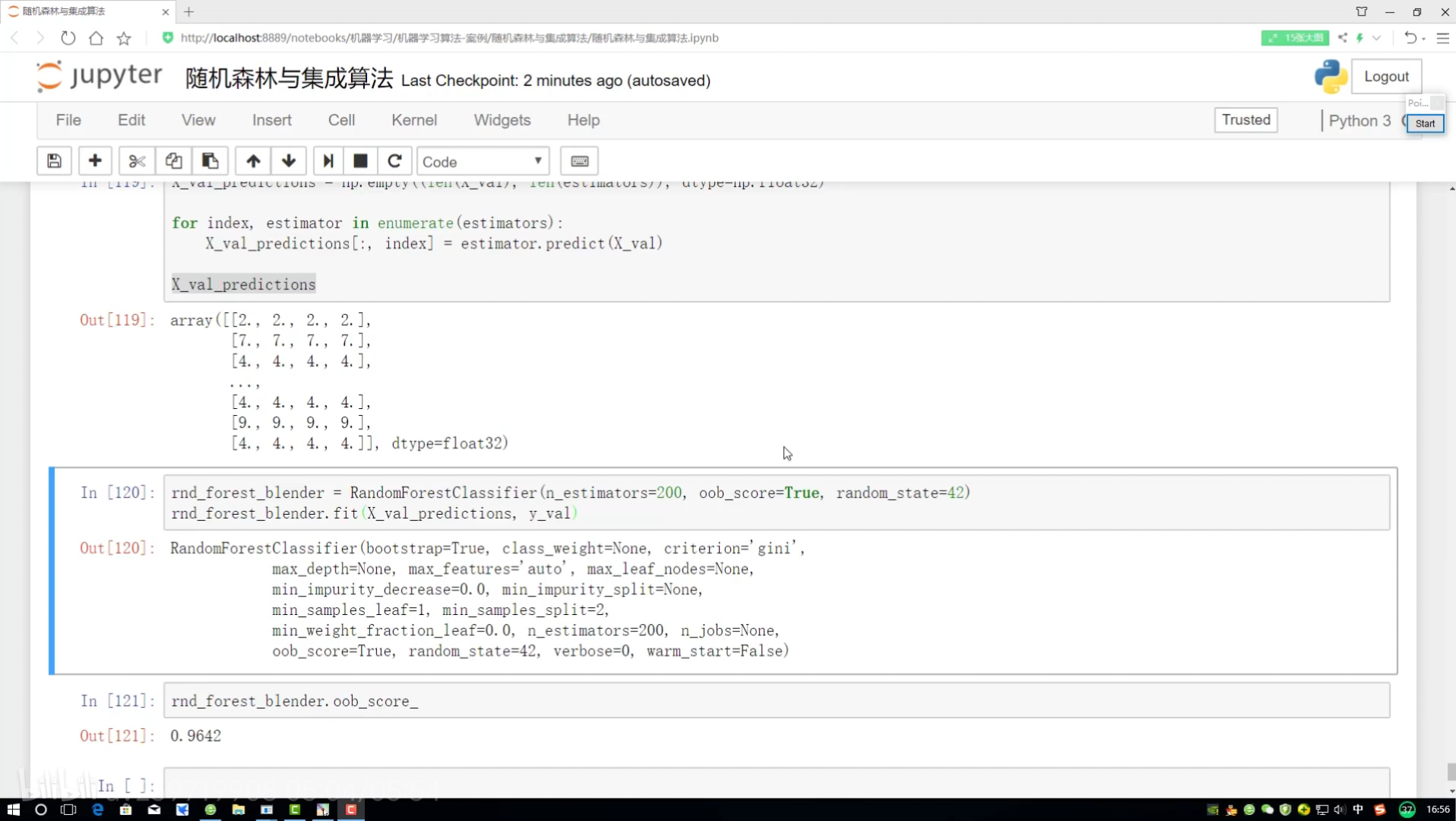
OOB:代辦數據 out of bag
加權平均
?
?
?
?
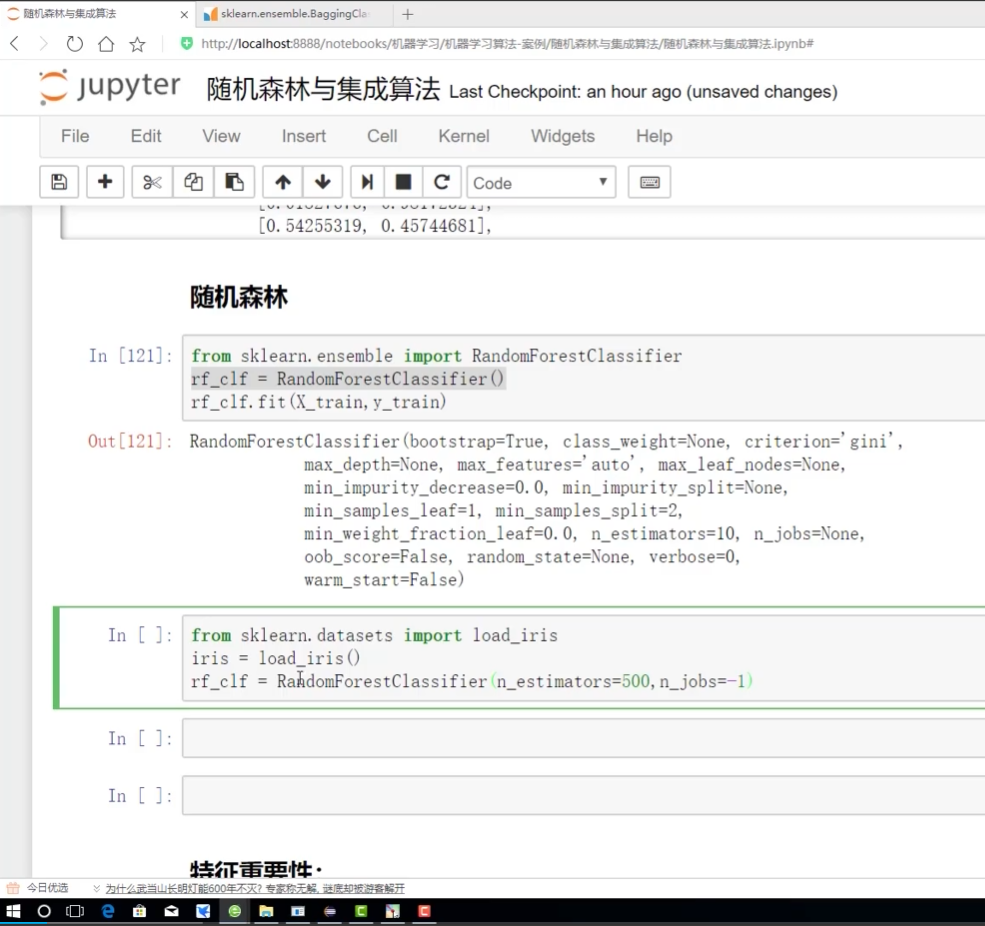
寫train 讓他們有屬性可以調用? 屬性里面有一個:特征多樣性
?
但上面X1,X2不好分辨
先實例化樹模型
.fit當前數據? 找到data? 找到標簽? .zip? 結合完當前對象? .feature
?
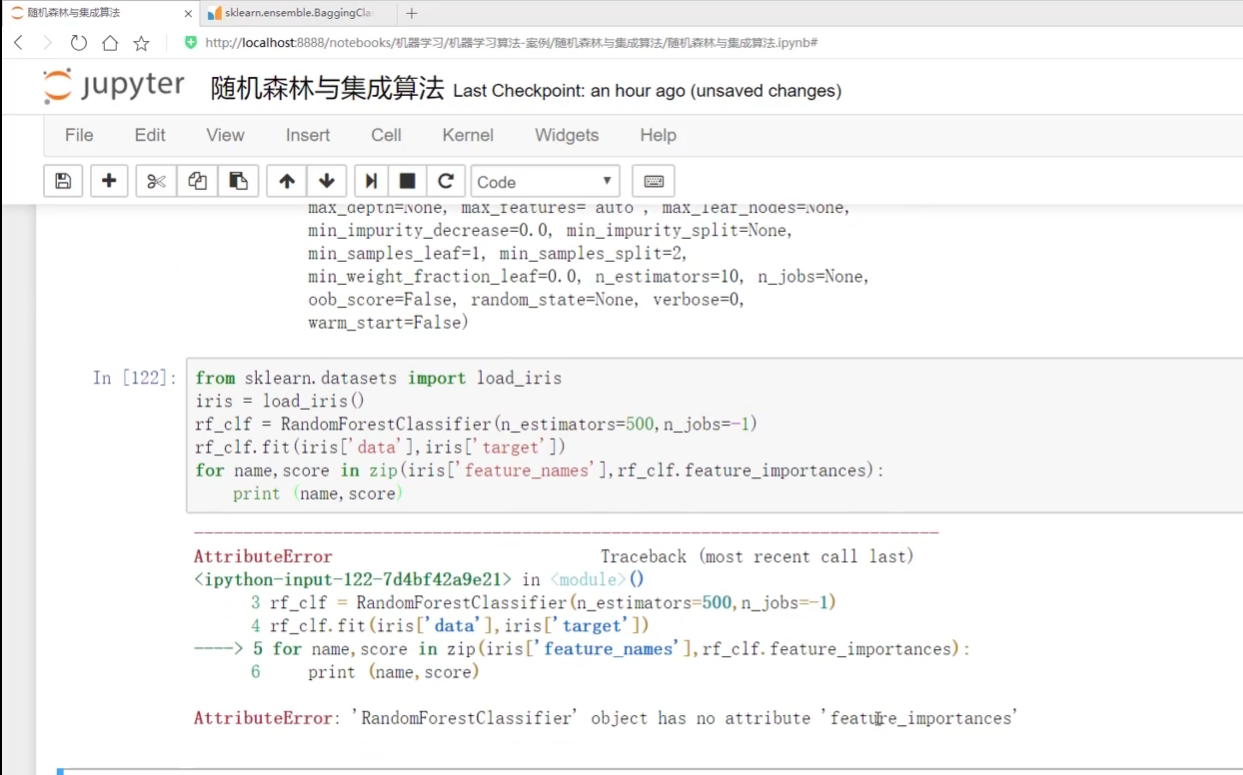
Importances后面有個杠
?
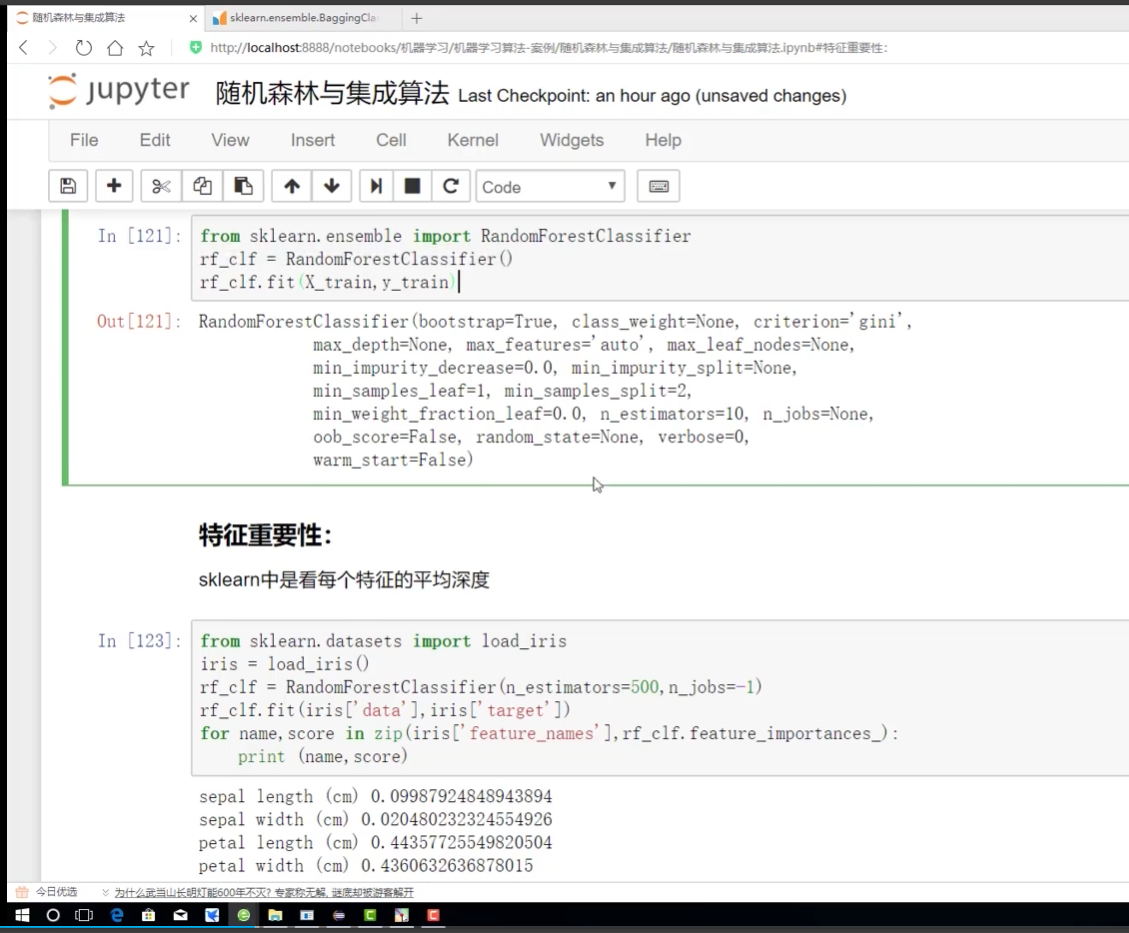
sklearn 做法
數據越重要:越前? 離根節點越近?
?
?
?
?
?
?
?
?
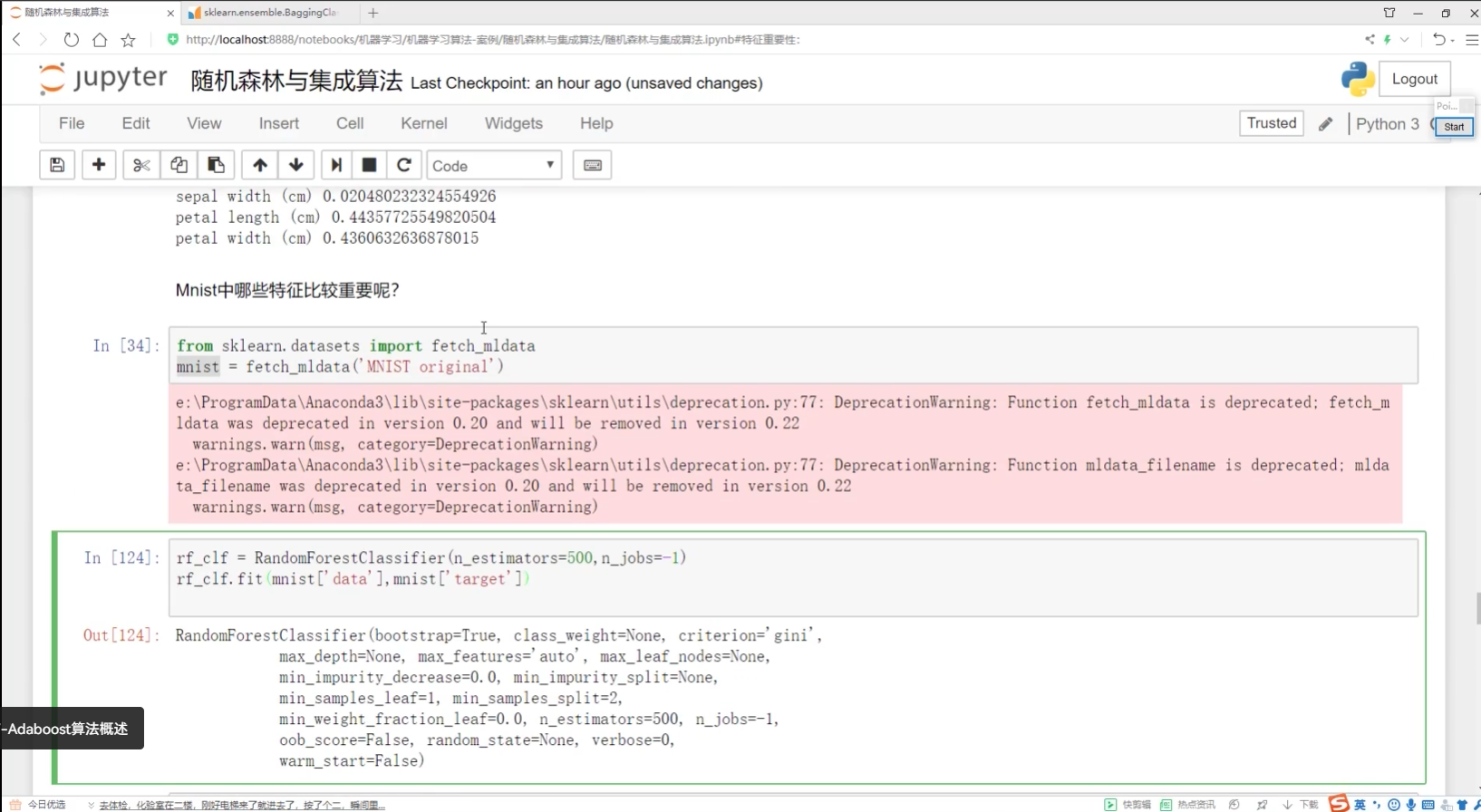
創建了MNIST? 做隨機森林? 看特征多樣性
_.shapes? ?784個點--每一個點的特征多樣性都可以算
?
畫熱度圖
熱度圖的圖像展示
展示當前圖像
指定顏色,默認顏色,
off去掉坐標軸
?
?
?
colorbar:深色代表什么? 淺色代表什么
?
?
?
boosting:串聯 一步步做
adaboost:調整權重-建模-調整權重-建模
像是整張試卷? 現在做錯題本? 對的題權重變小? 搓的題目權重變大
?
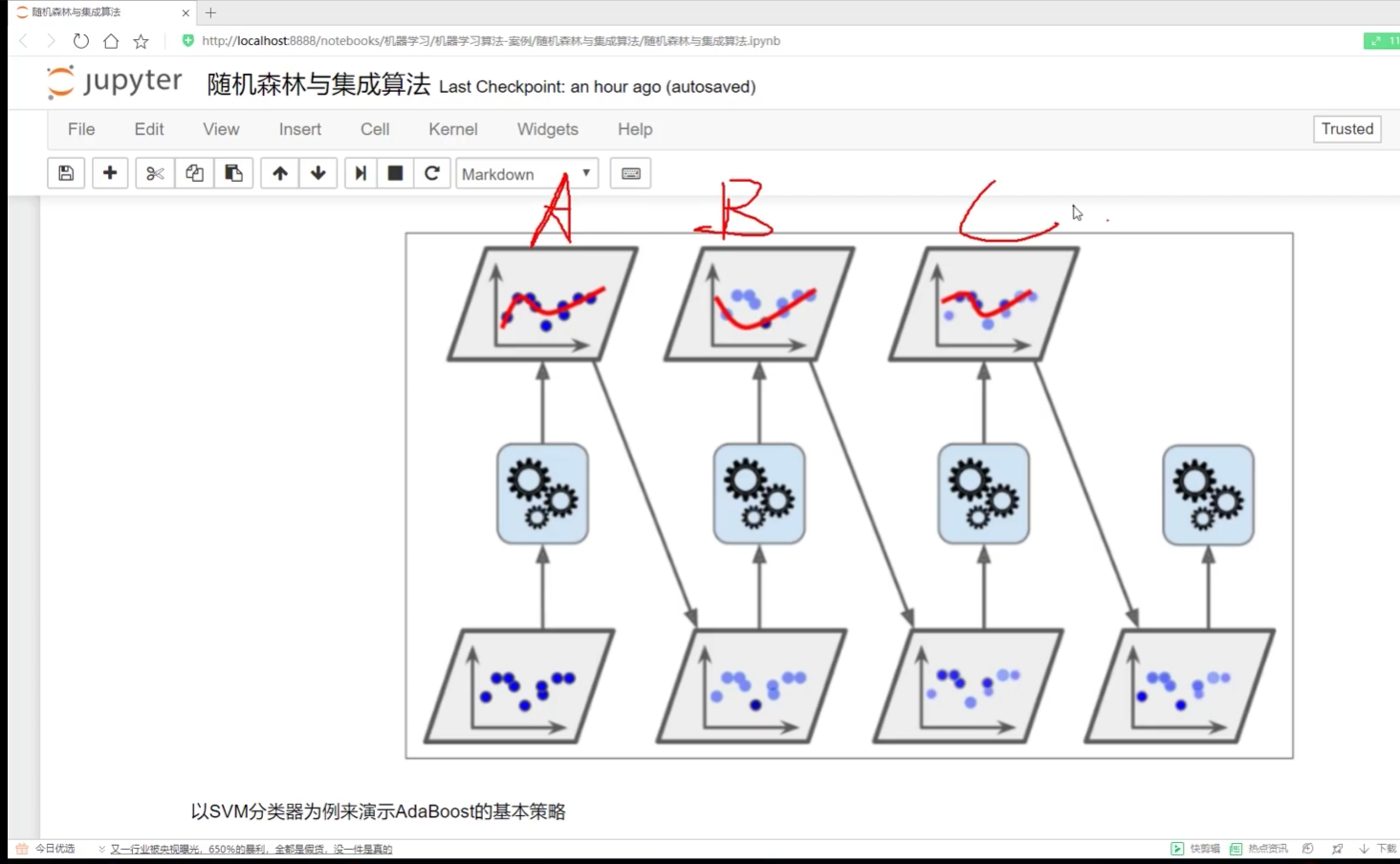
加權求和? 模型效果好--權重越大
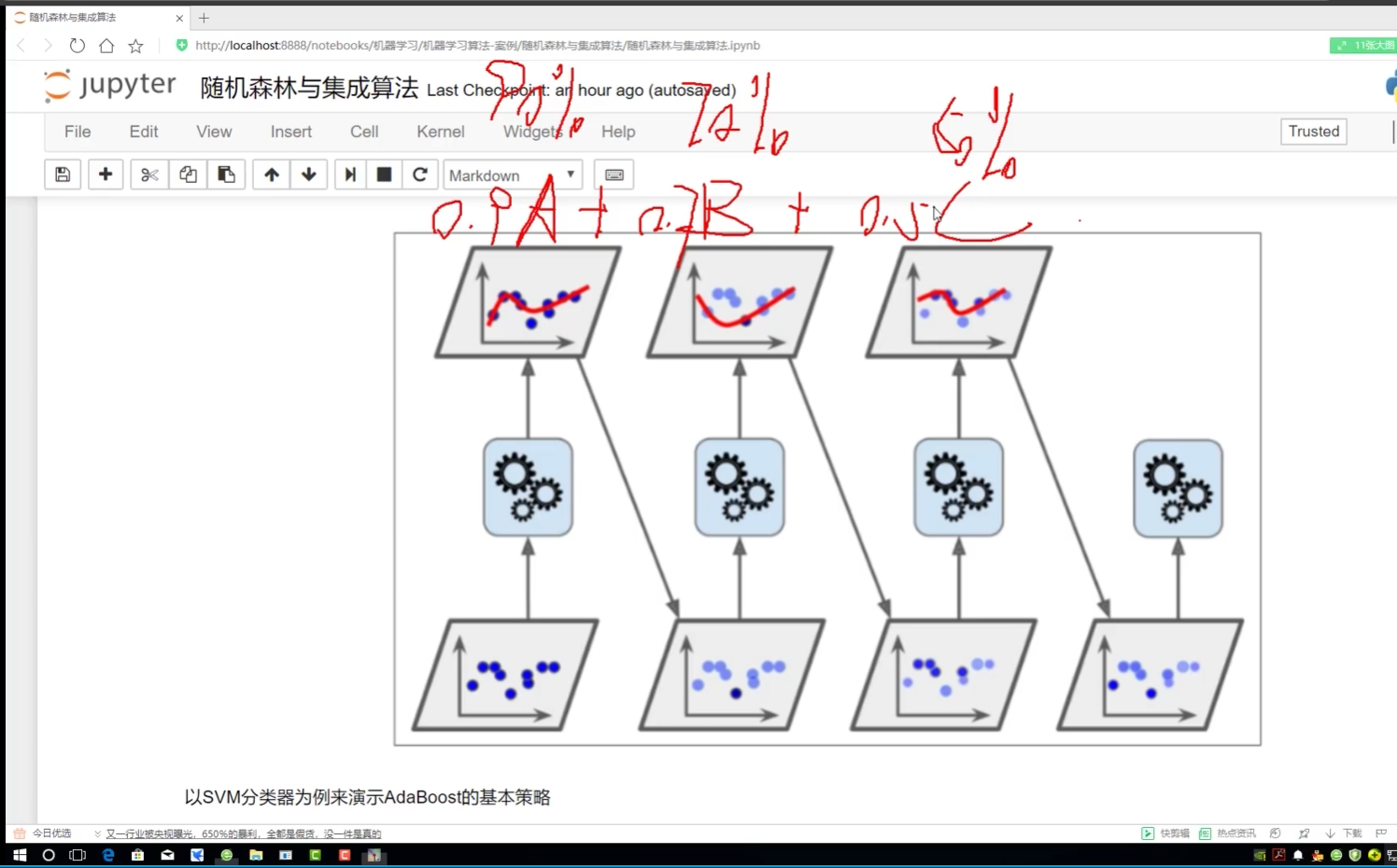
?
?
?
?
對每個樣本進行權重賦值
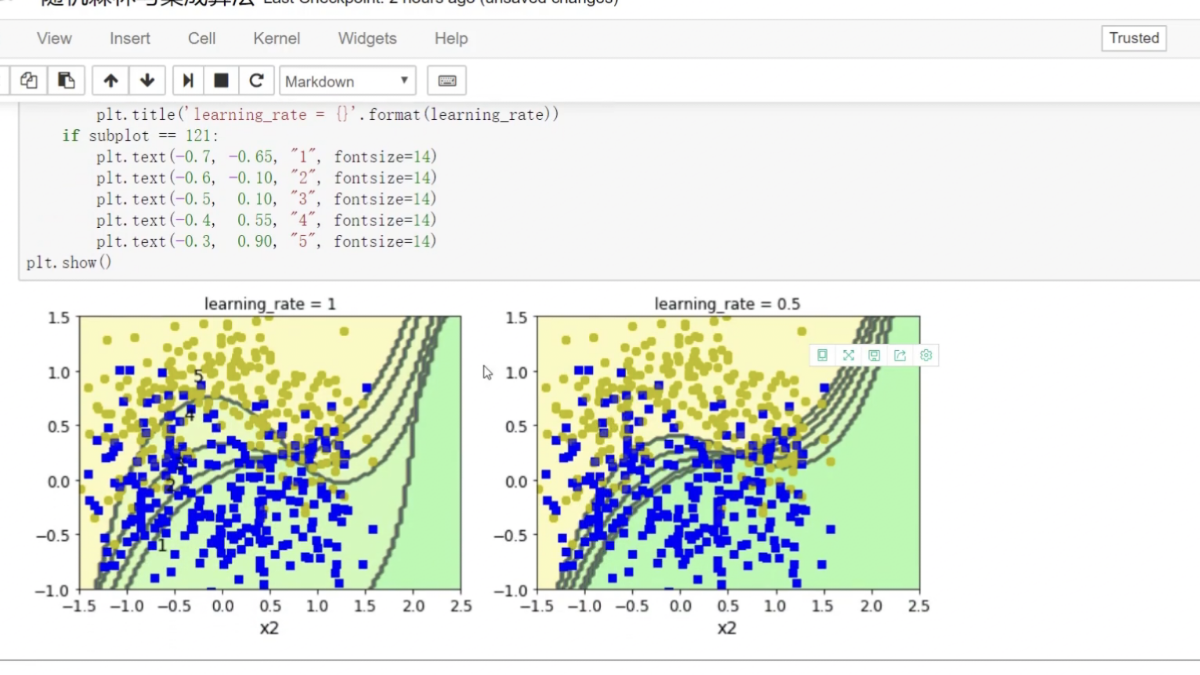
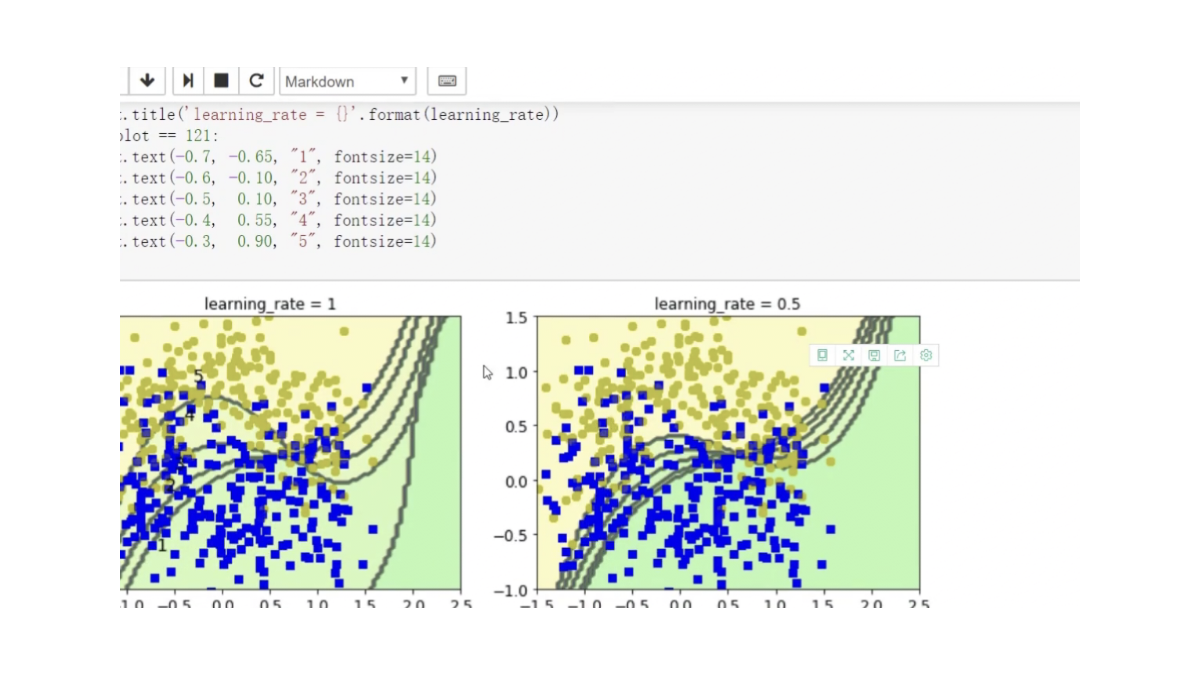
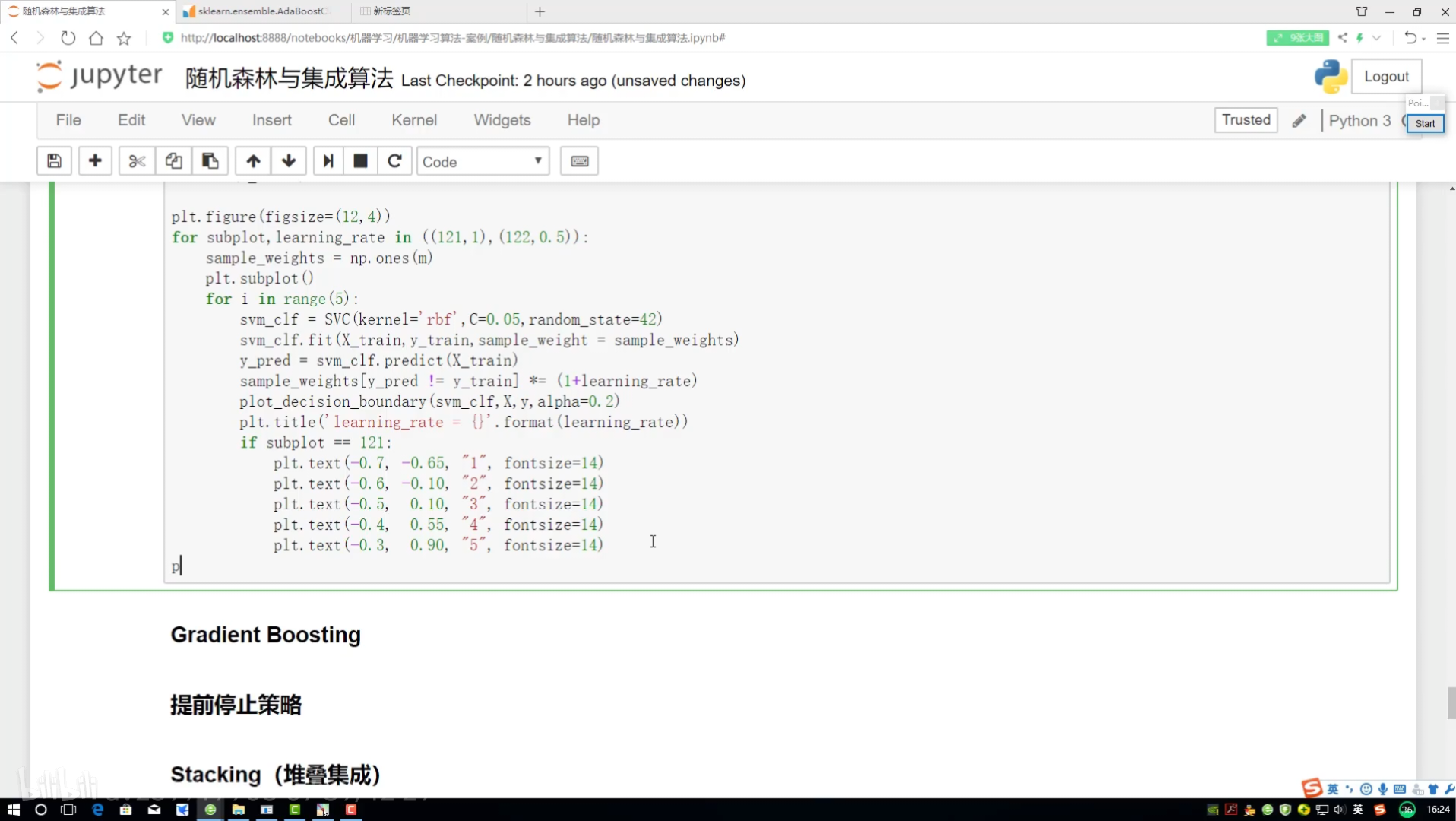
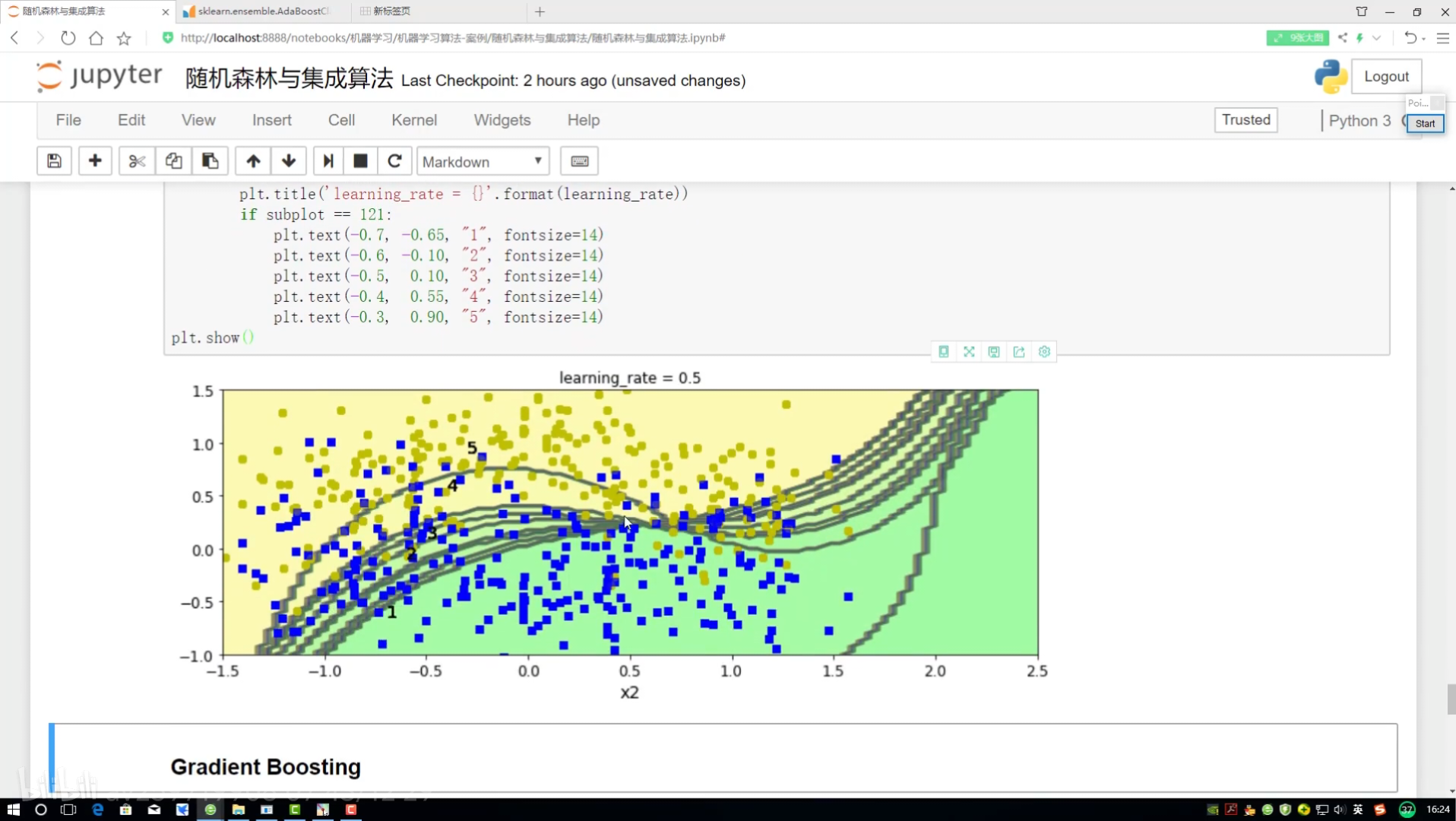
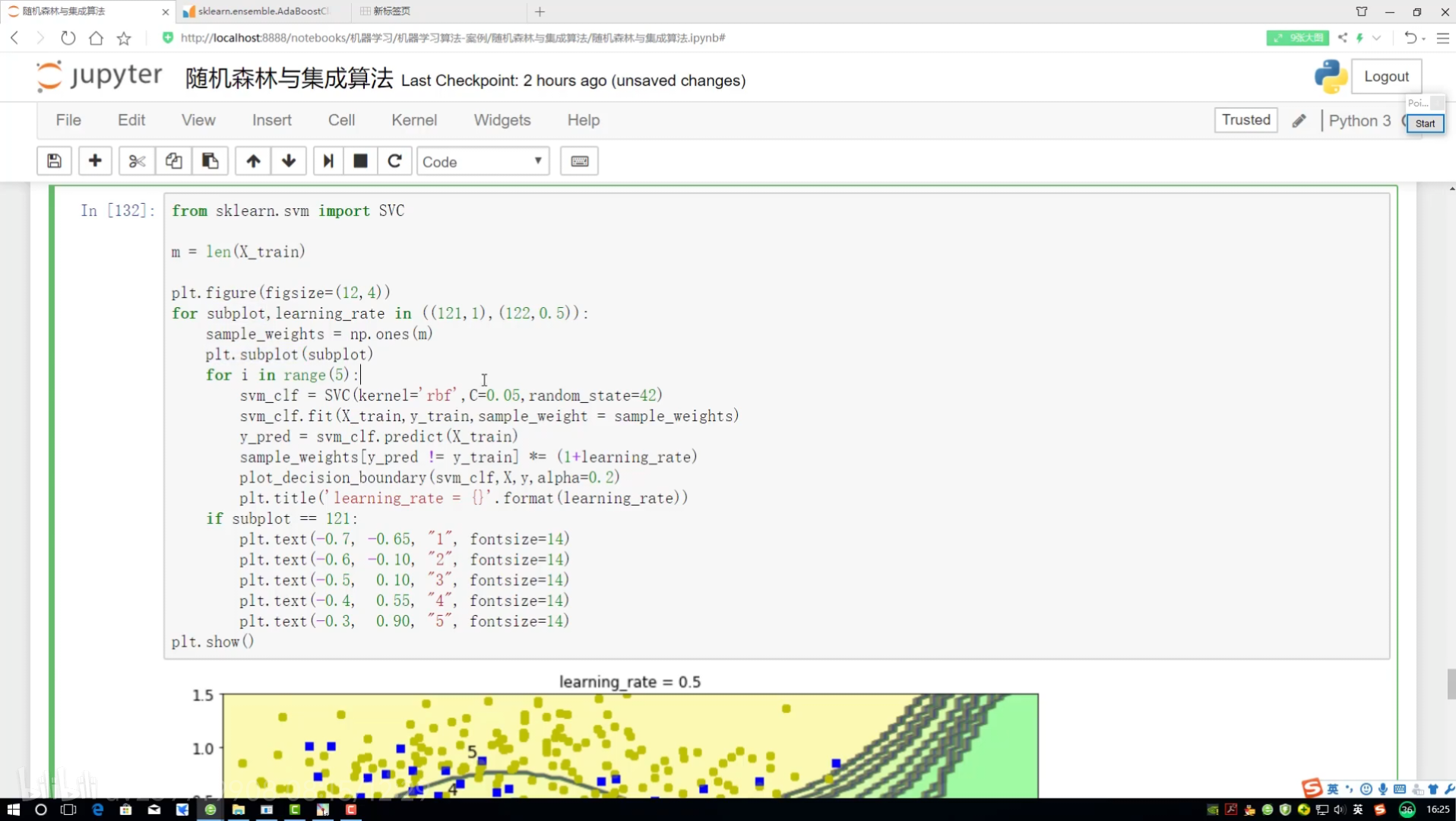
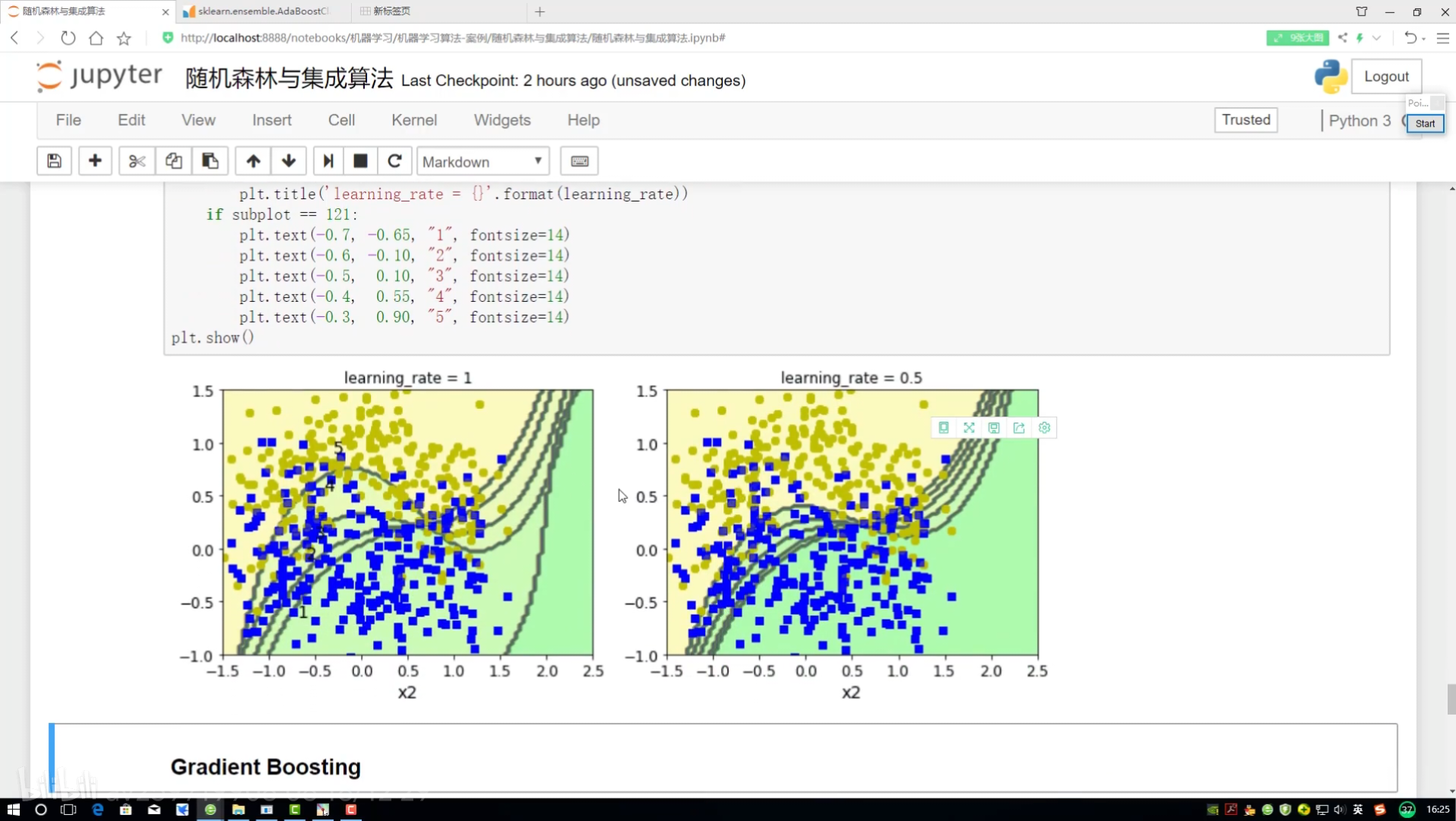
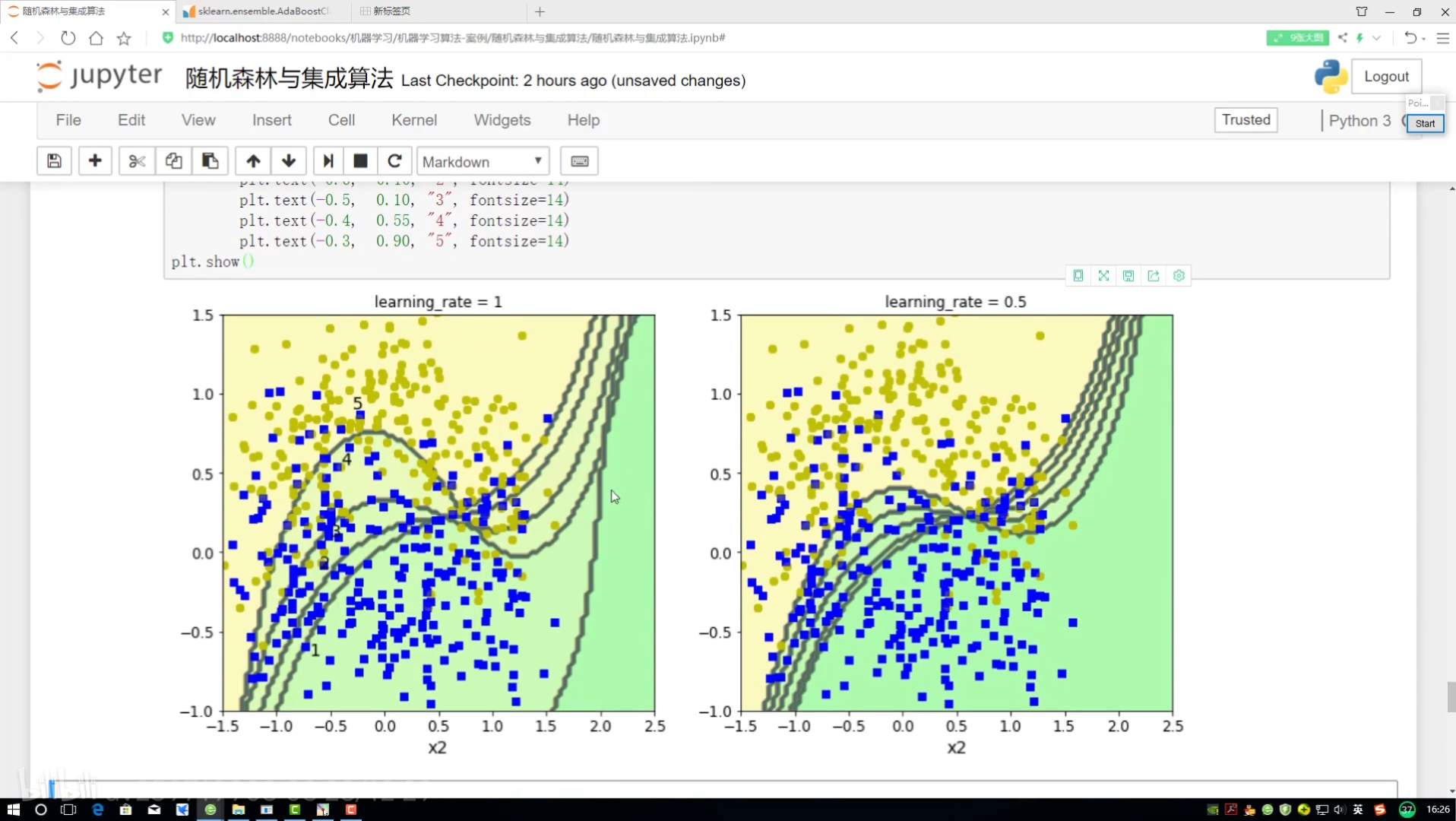
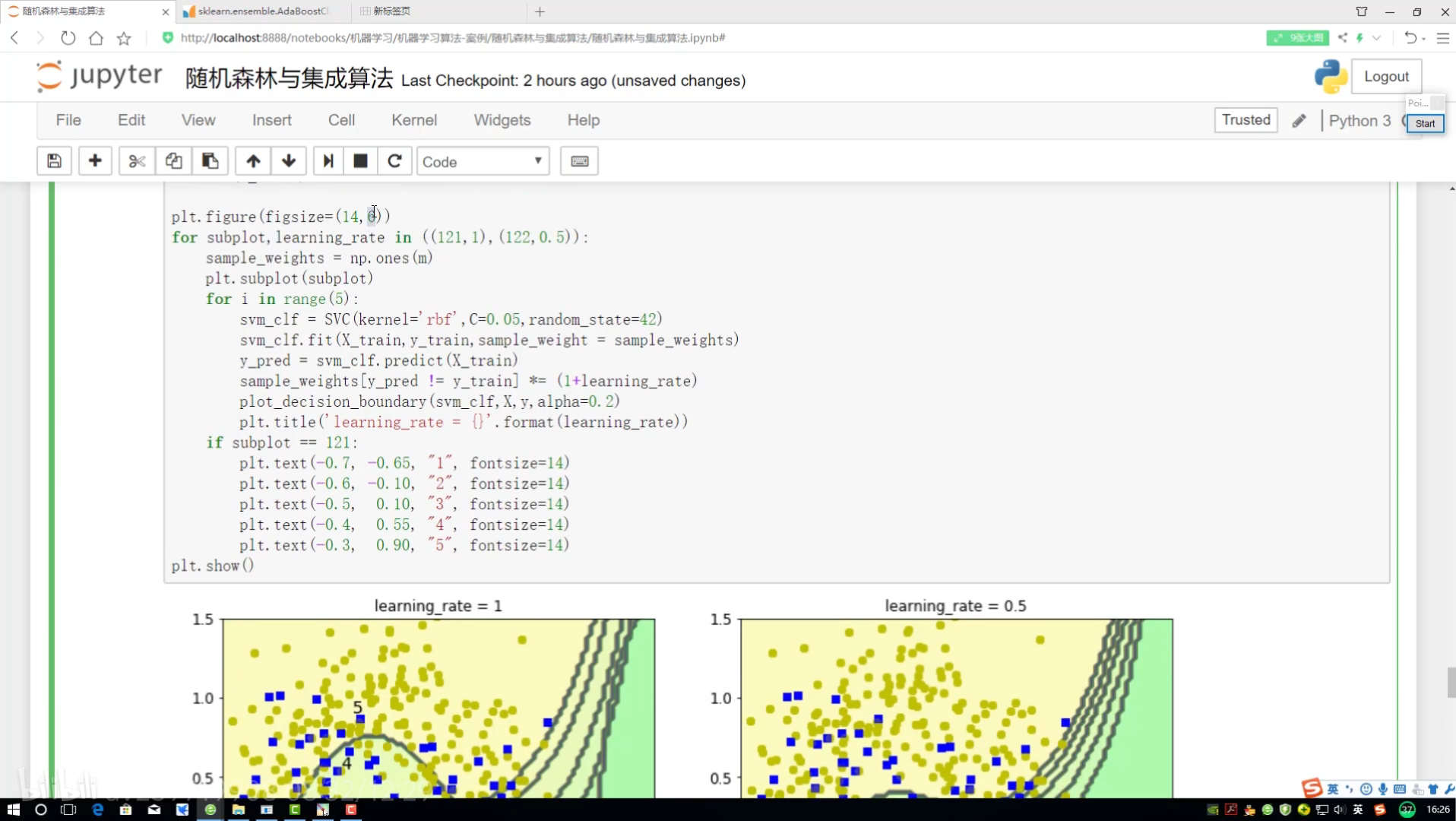
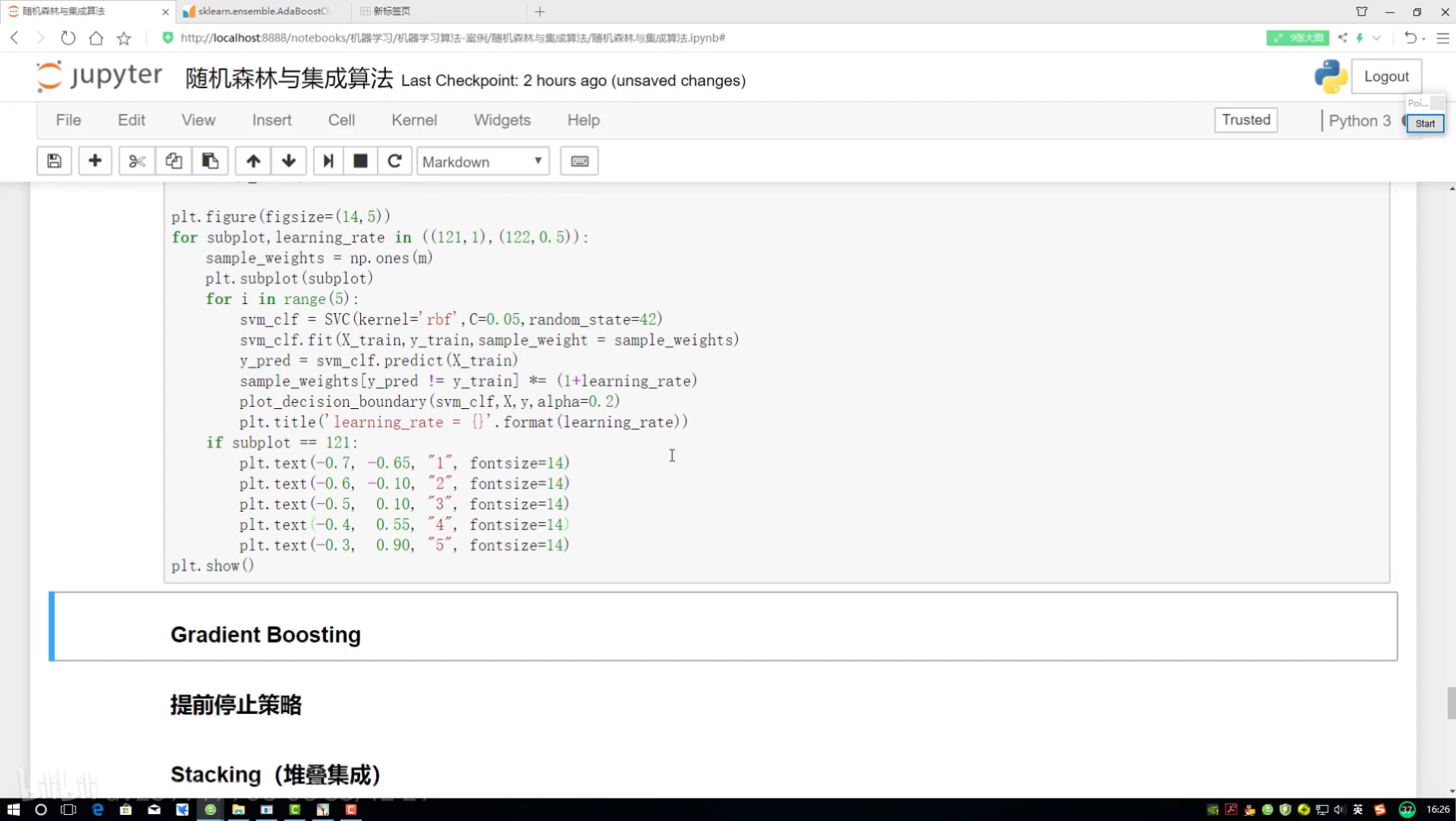
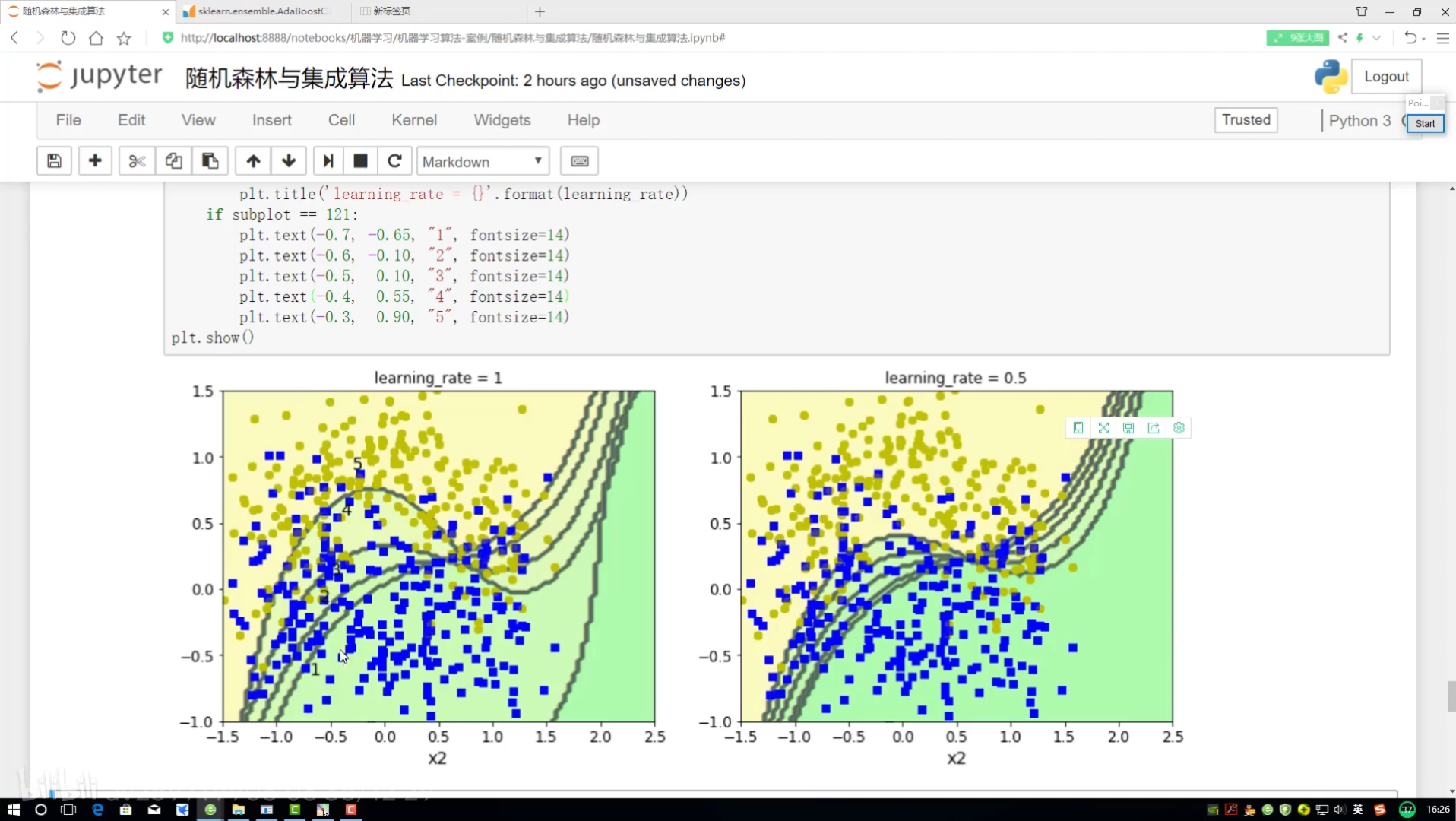
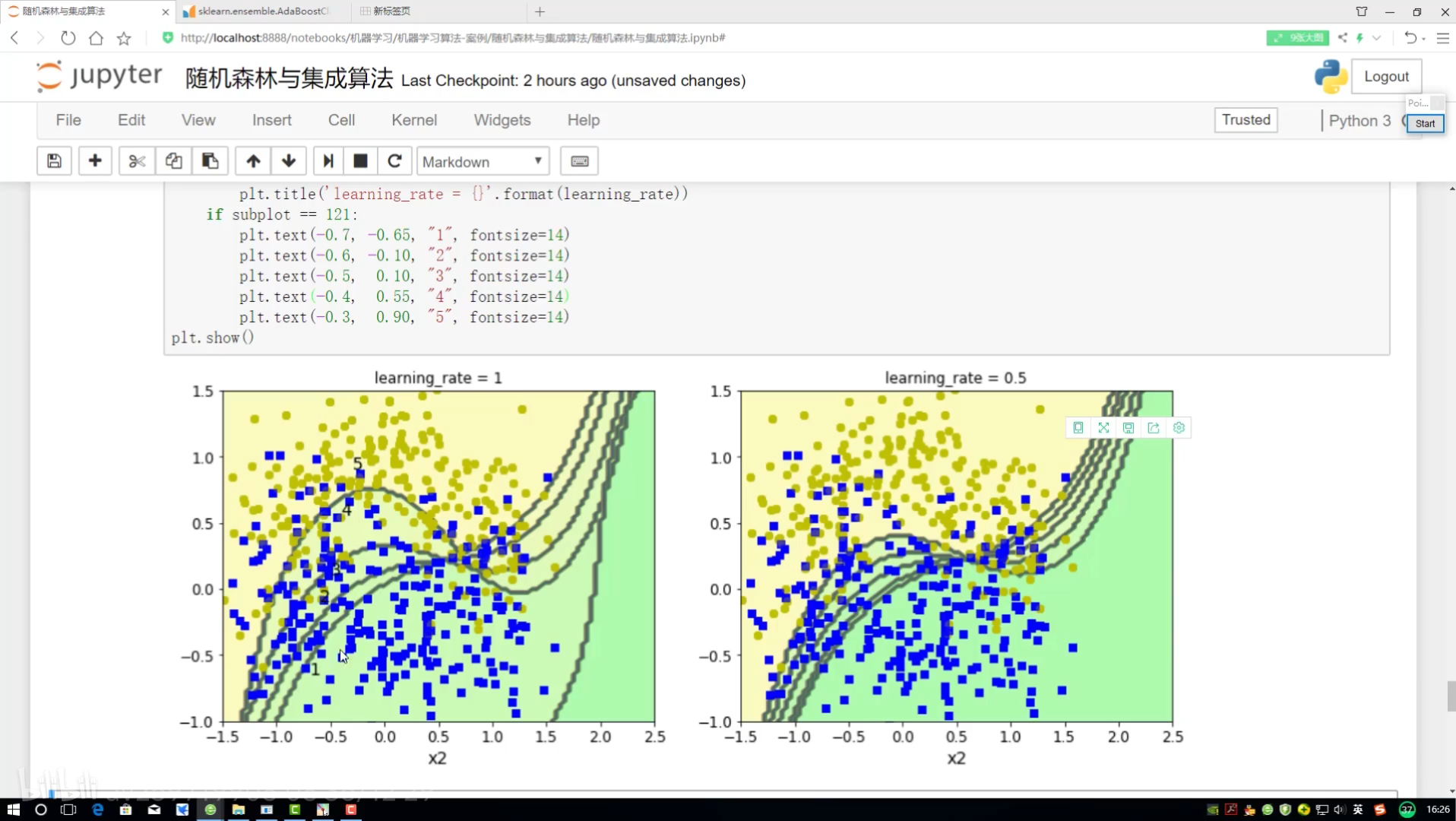
邊畫圖邊展示? 畫12*4圖
不同調節力度對結果影響? 樣本權重(更新速度?)(更新幅度)
kernel--和函數? rbf:高斯和函數 C:軟間隔
實例化指定SVM的分類器clf
.fit一下(X_train,Y_train)
研究樣本的權重項為多少
預測當前結果來展示
!=? ?不等? ?就是做錯的? 權重放大=(1+學習率)
找到定義畫決策邊界的函數
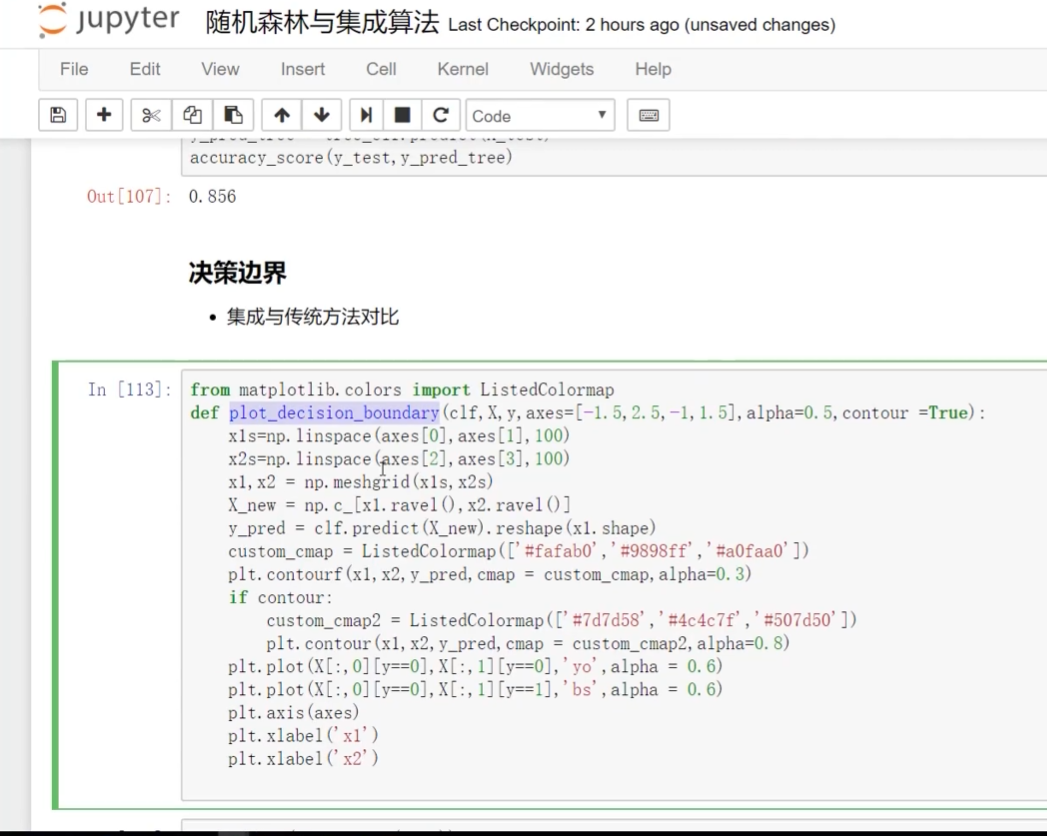
?
?
?
?
boundary:對樣本權重進行更改
kernel:和函數 讓特征量變化演示結果更好
軟間隔
?
 ?
?
 ?
?
 ?
?
 ?
?
 ?
?
 ?
?
 ?
?
 ?
?
 ?
?
 ?
?
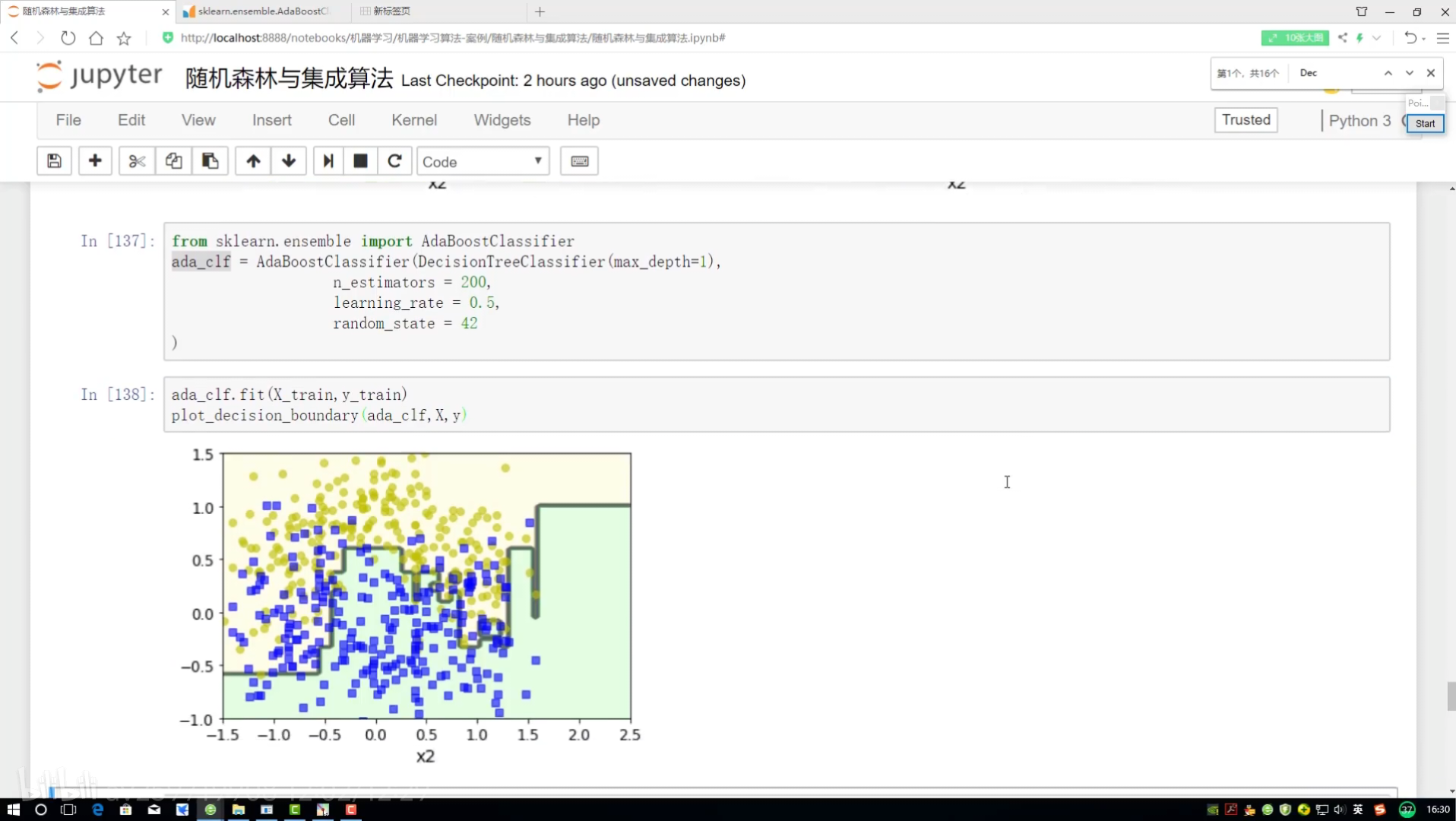
?adaboost:權重項不同? 集成算法對比
學習率:樣本函數衰減程度
多少輪
?
 ?
?
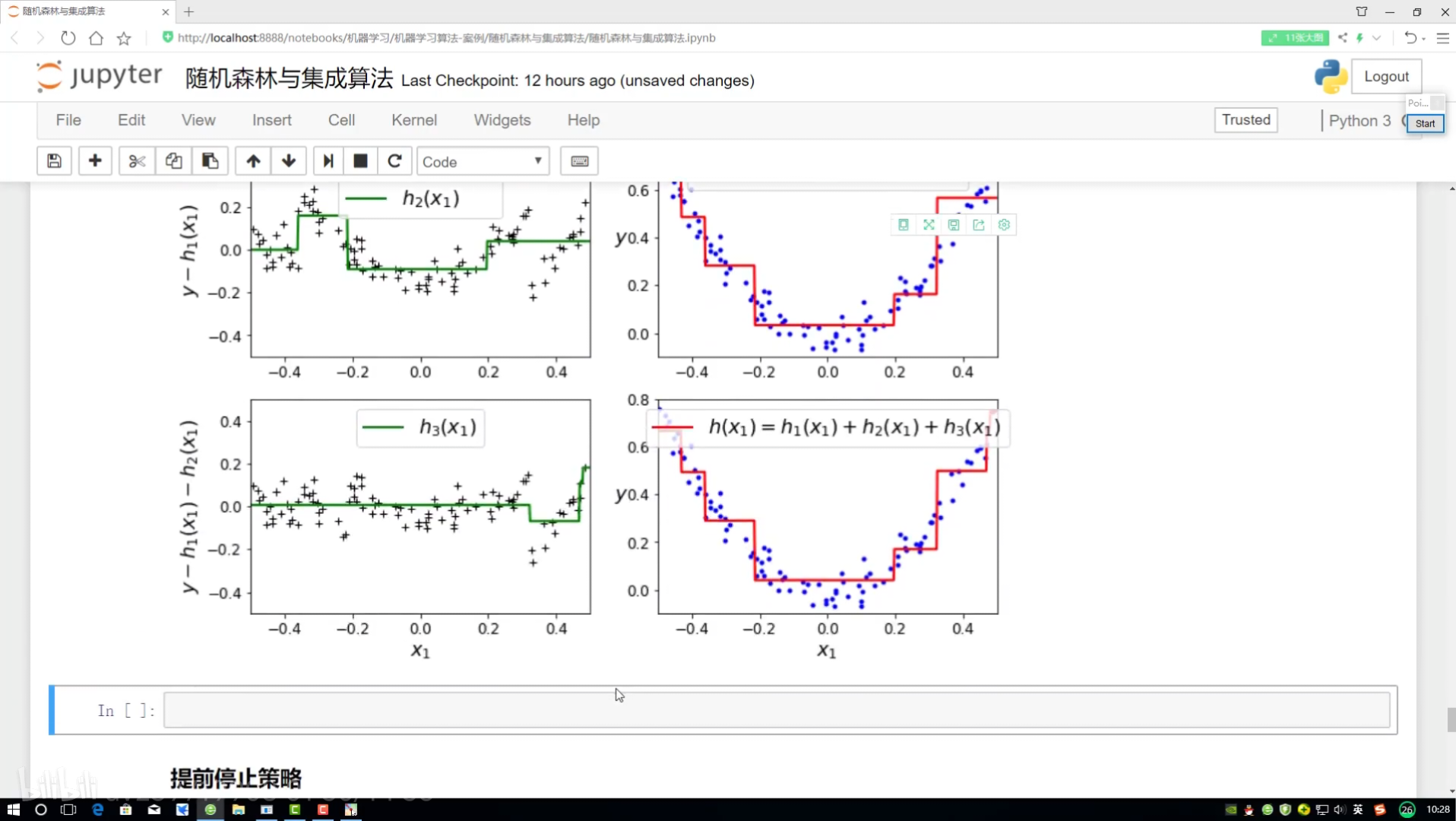
?提升策略:
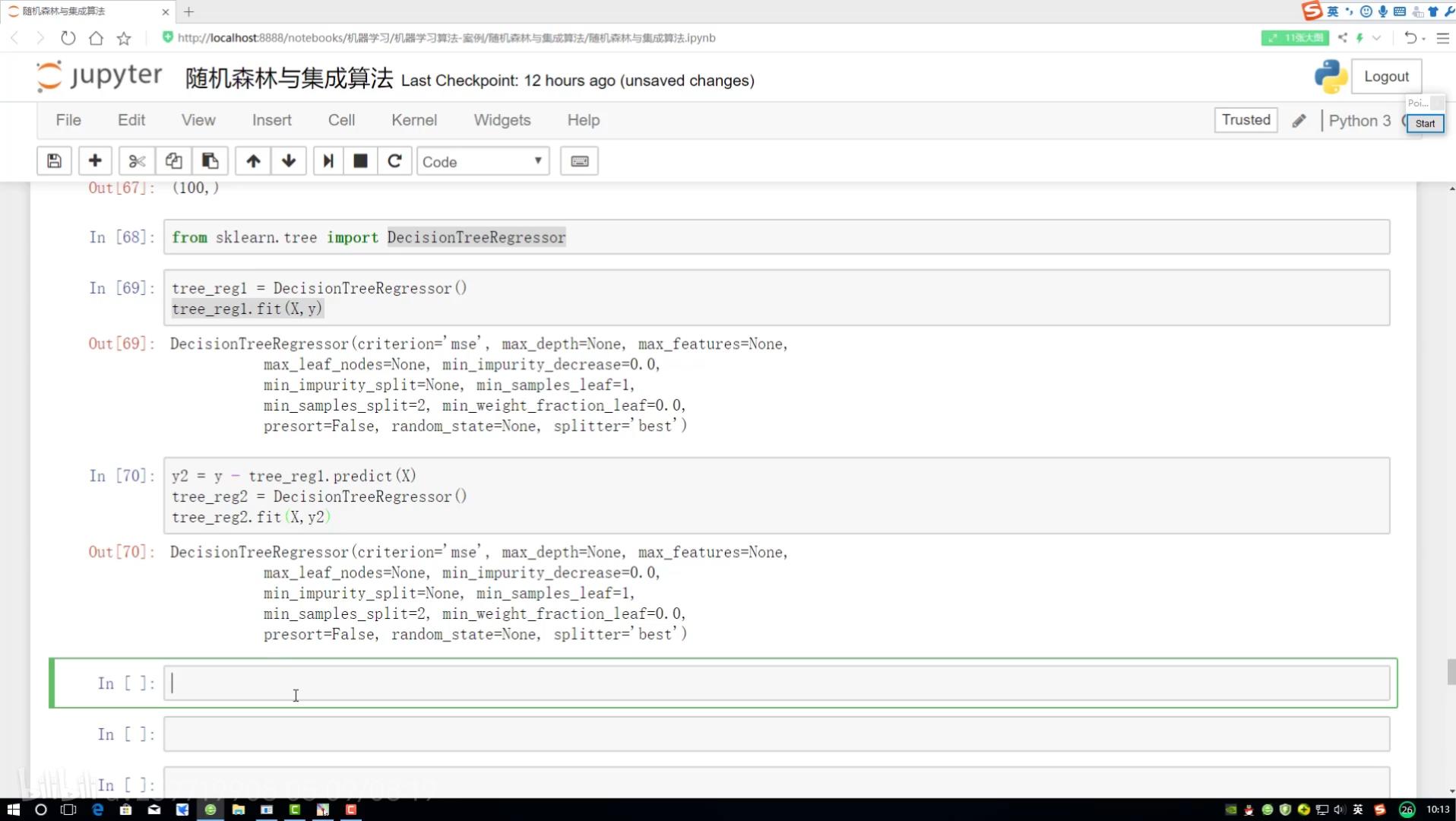
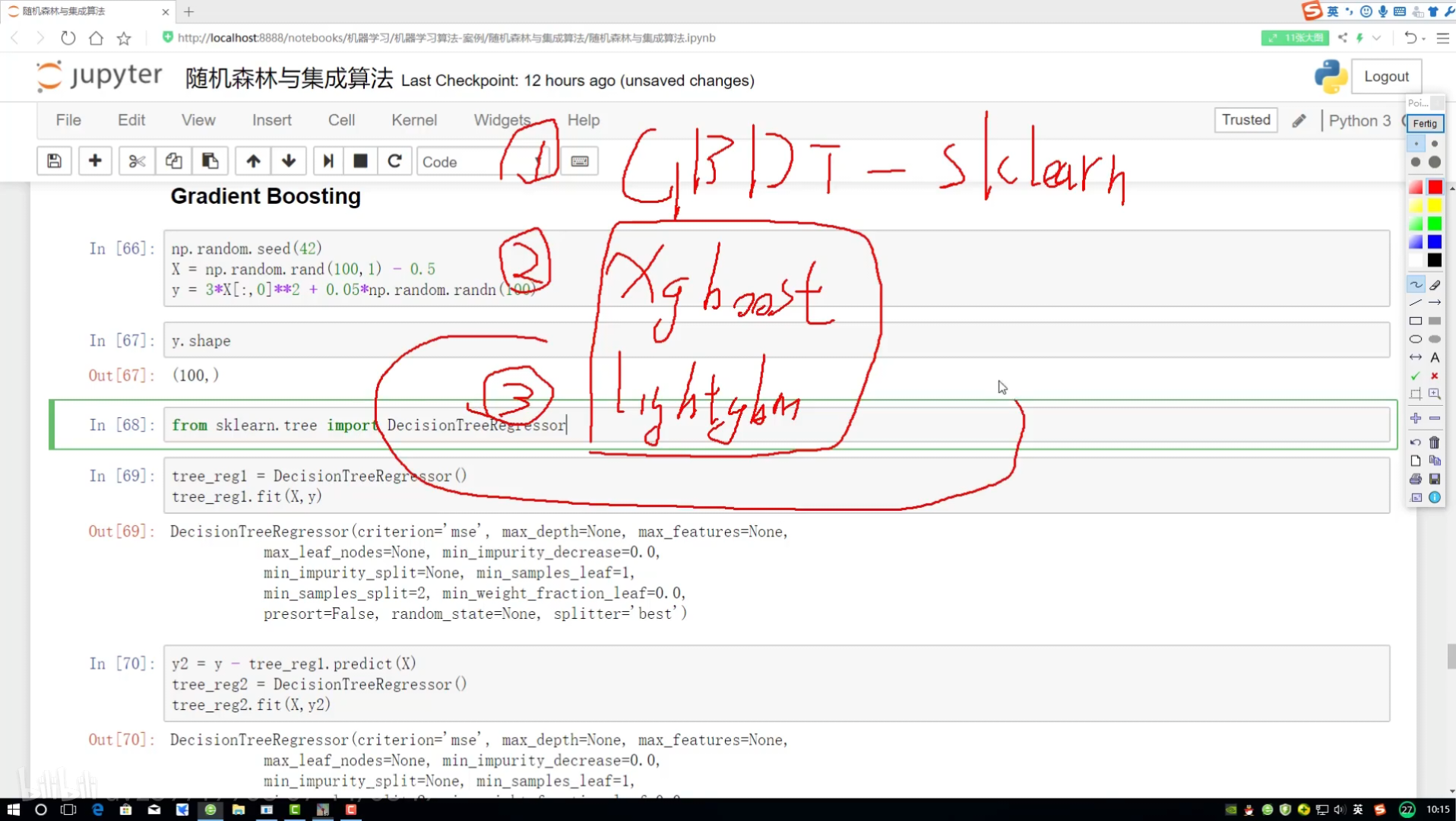
GBDT梯度提升決策樹
種子 隨機進行數據集構建
?
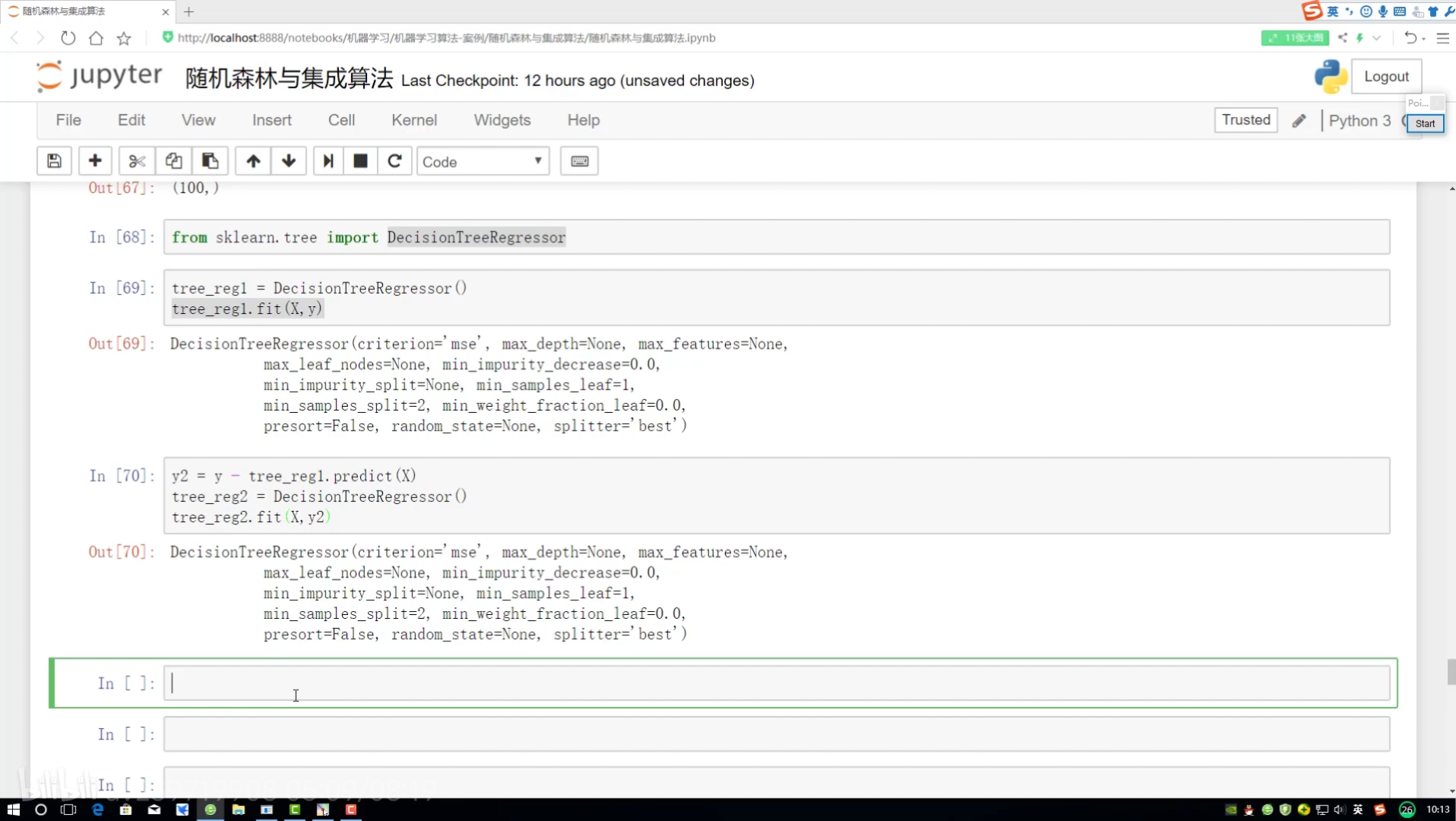
?分別給預測結果 所有值加起來
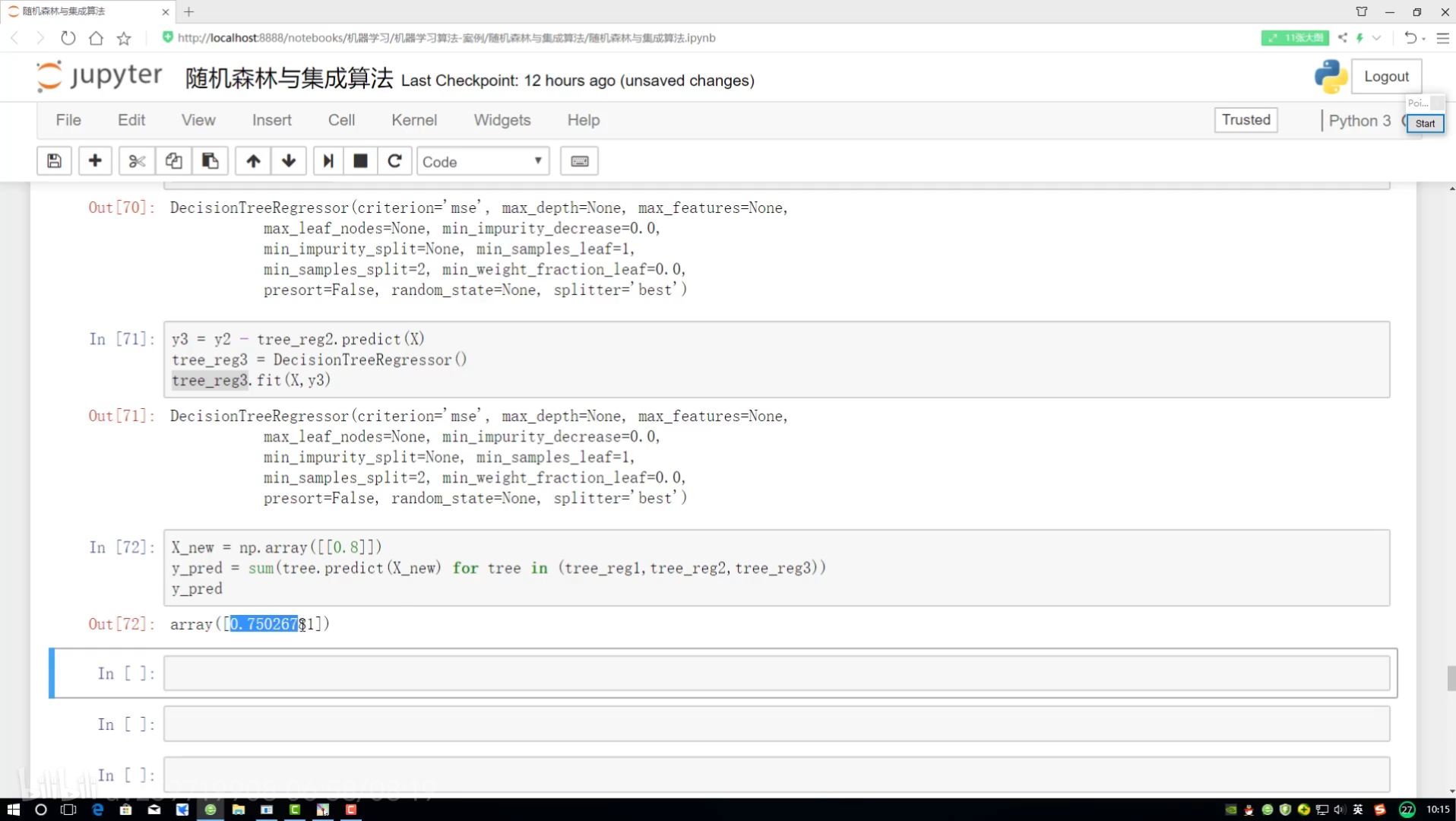
?
?
 ?
?
 ?
?
 ?
?
 ?
?
?
?
?
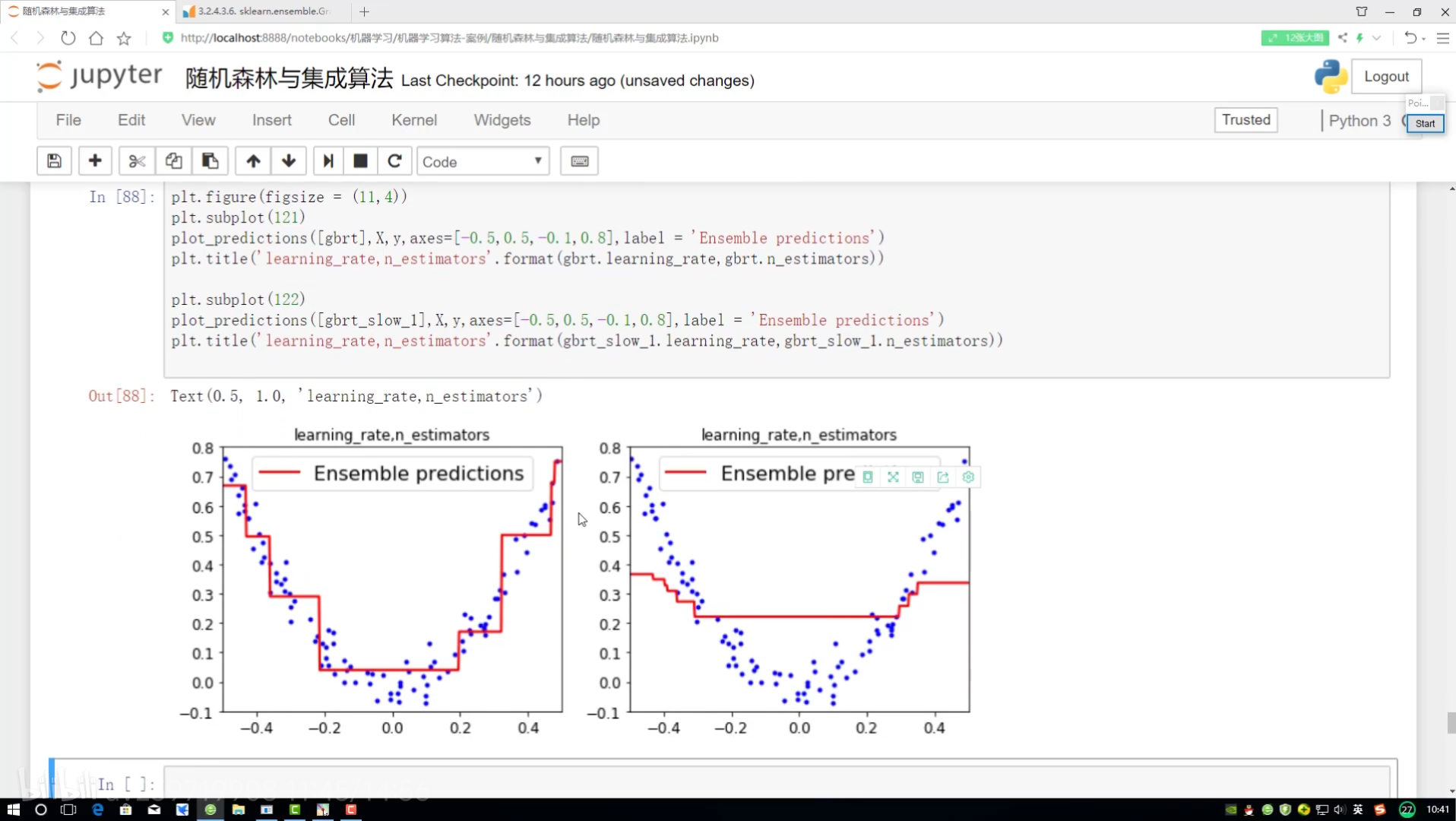
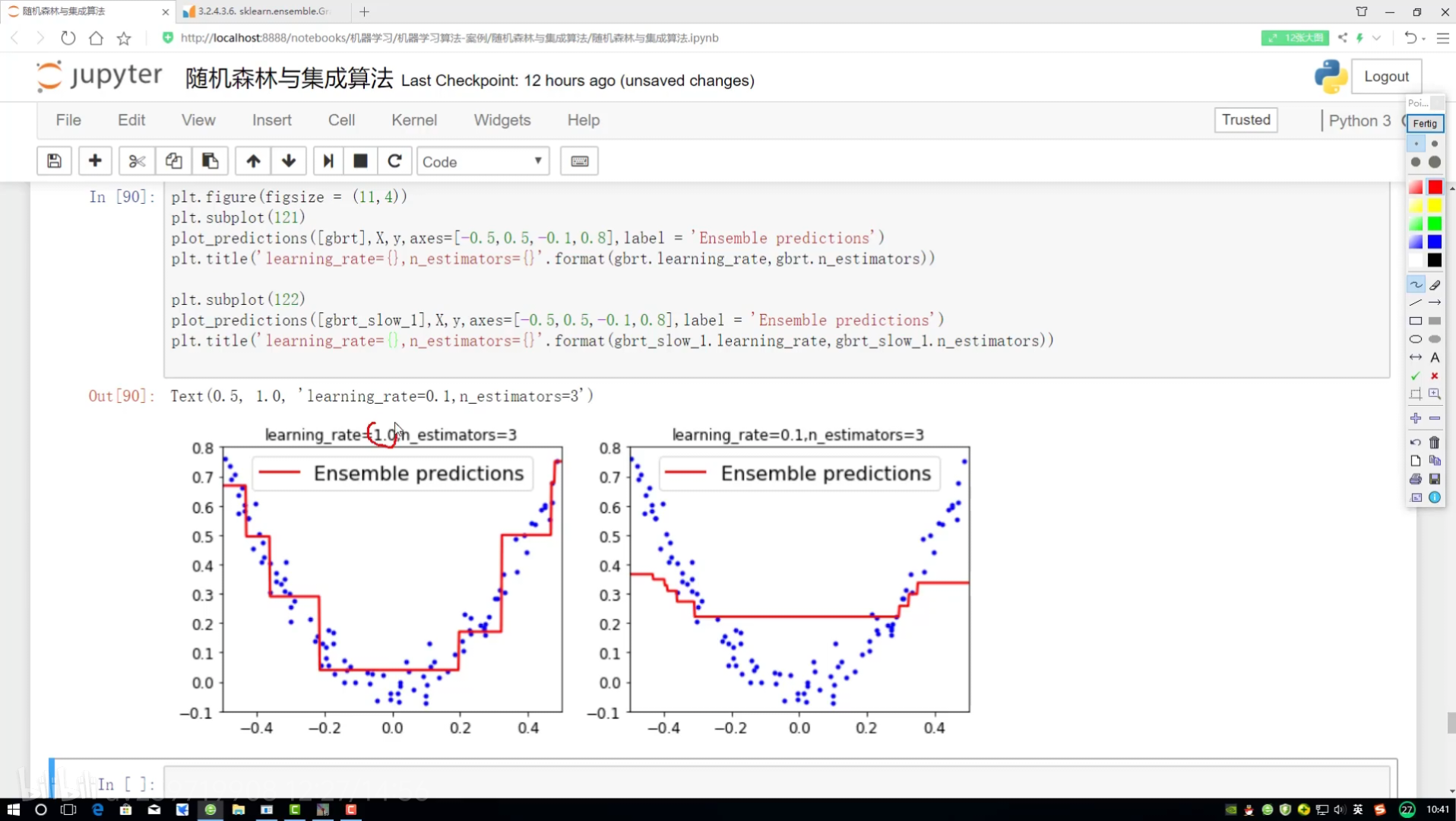
?集成參數對比分析:
?
?拿到測試數據點
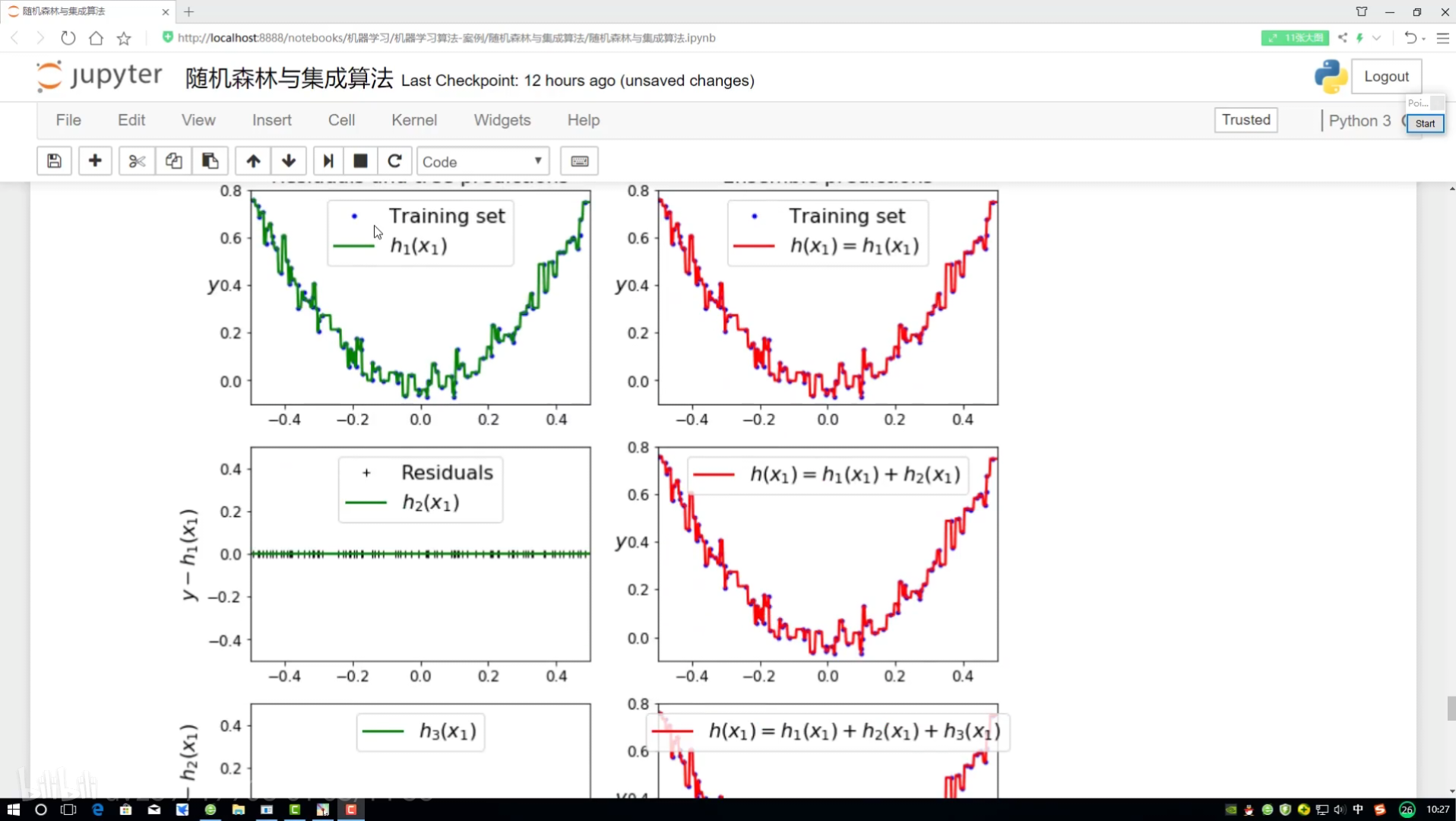 ?
?
?
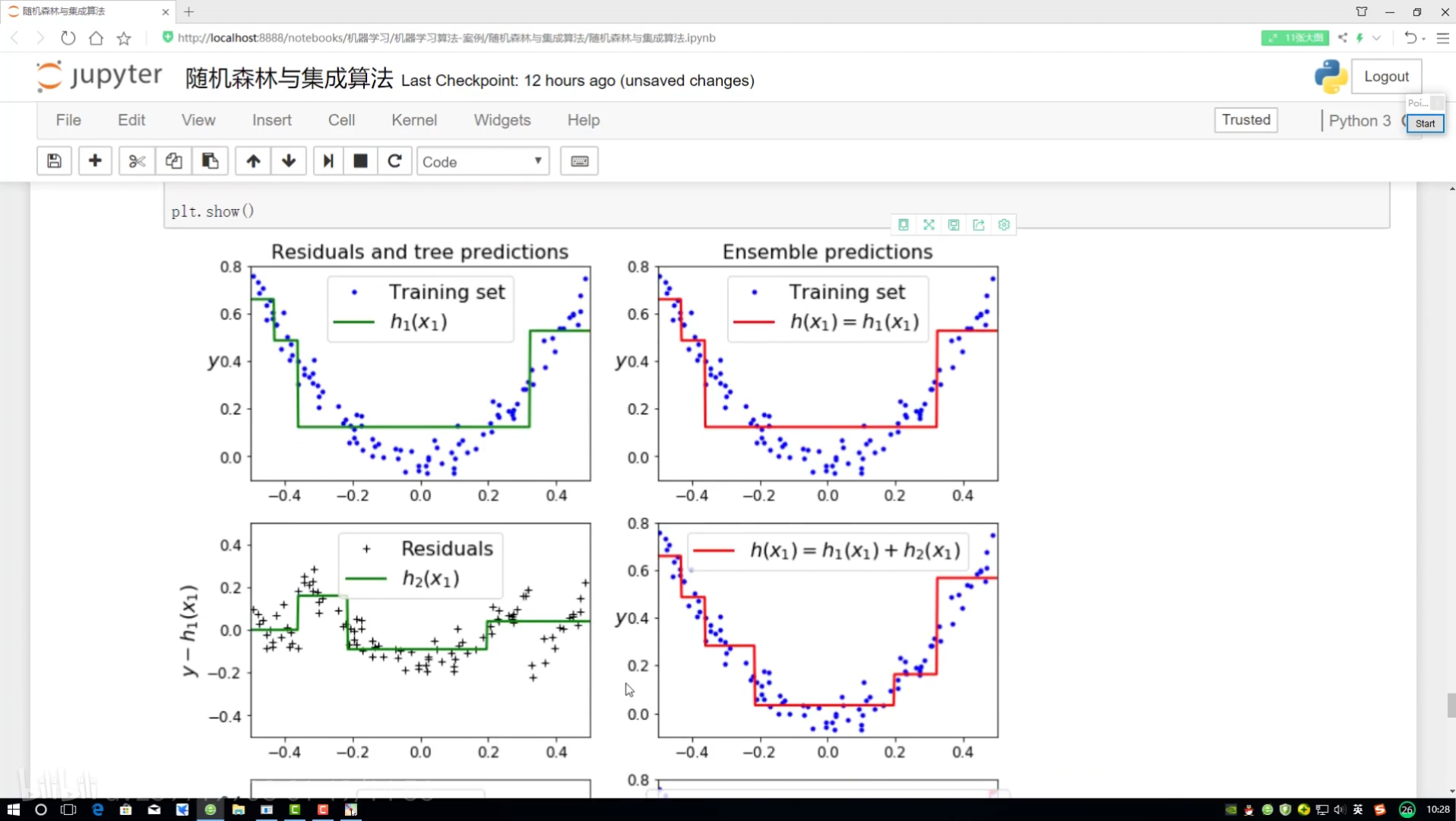
修改深度
 ?
?
?
?
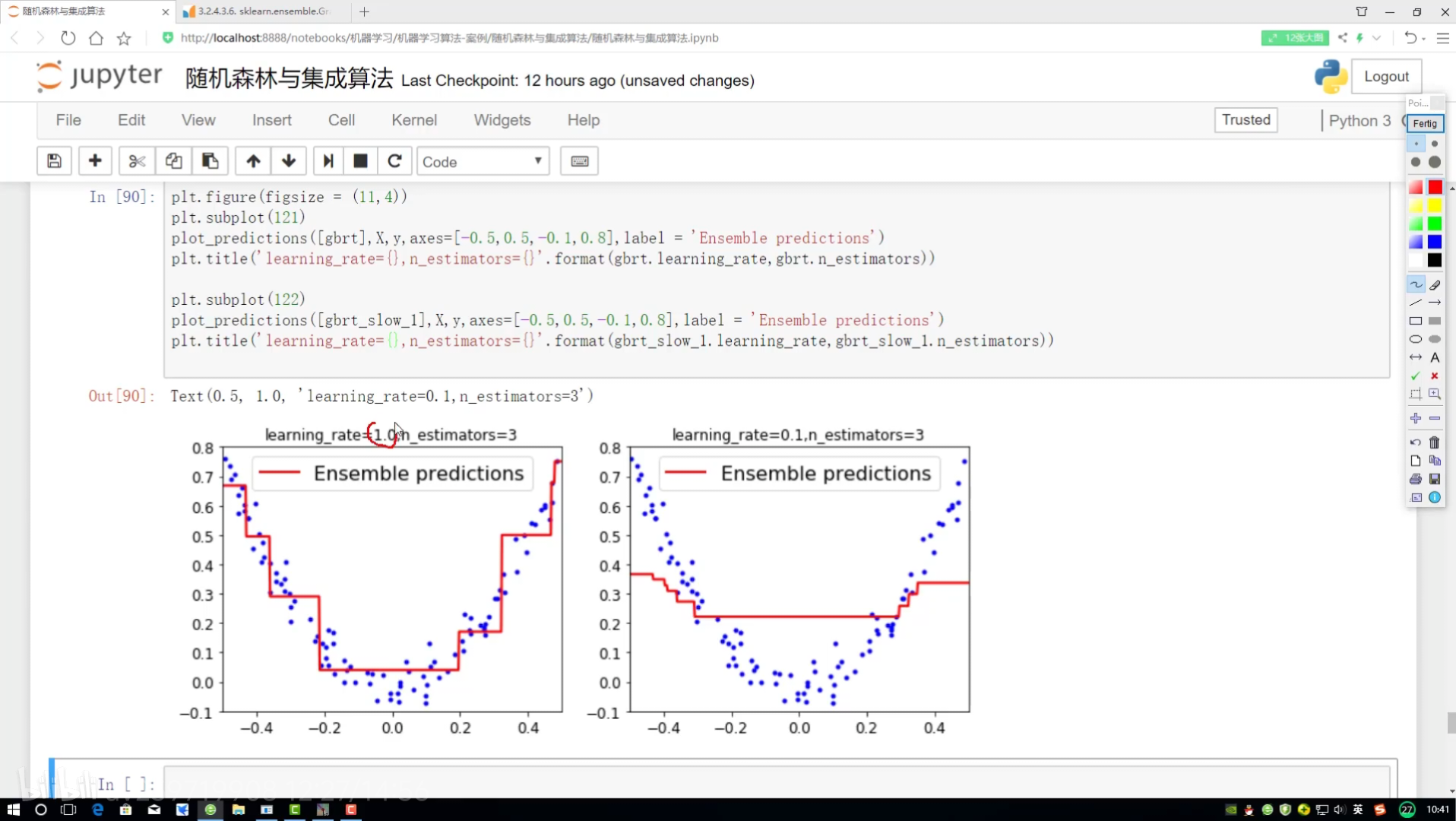
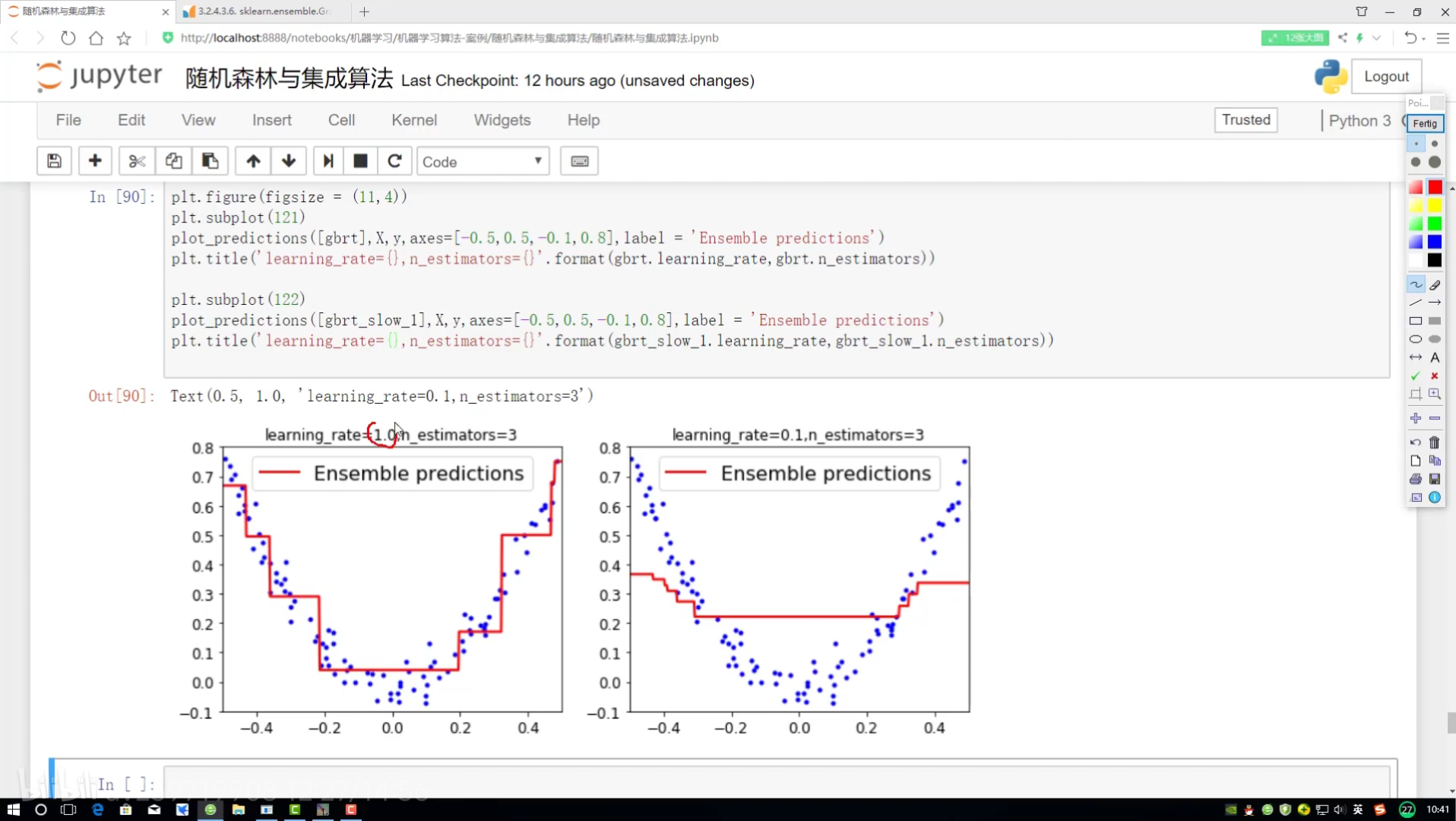
1.0? ->? 0.1
?
沒有實際打印值
?
rate后面?{}
?
?
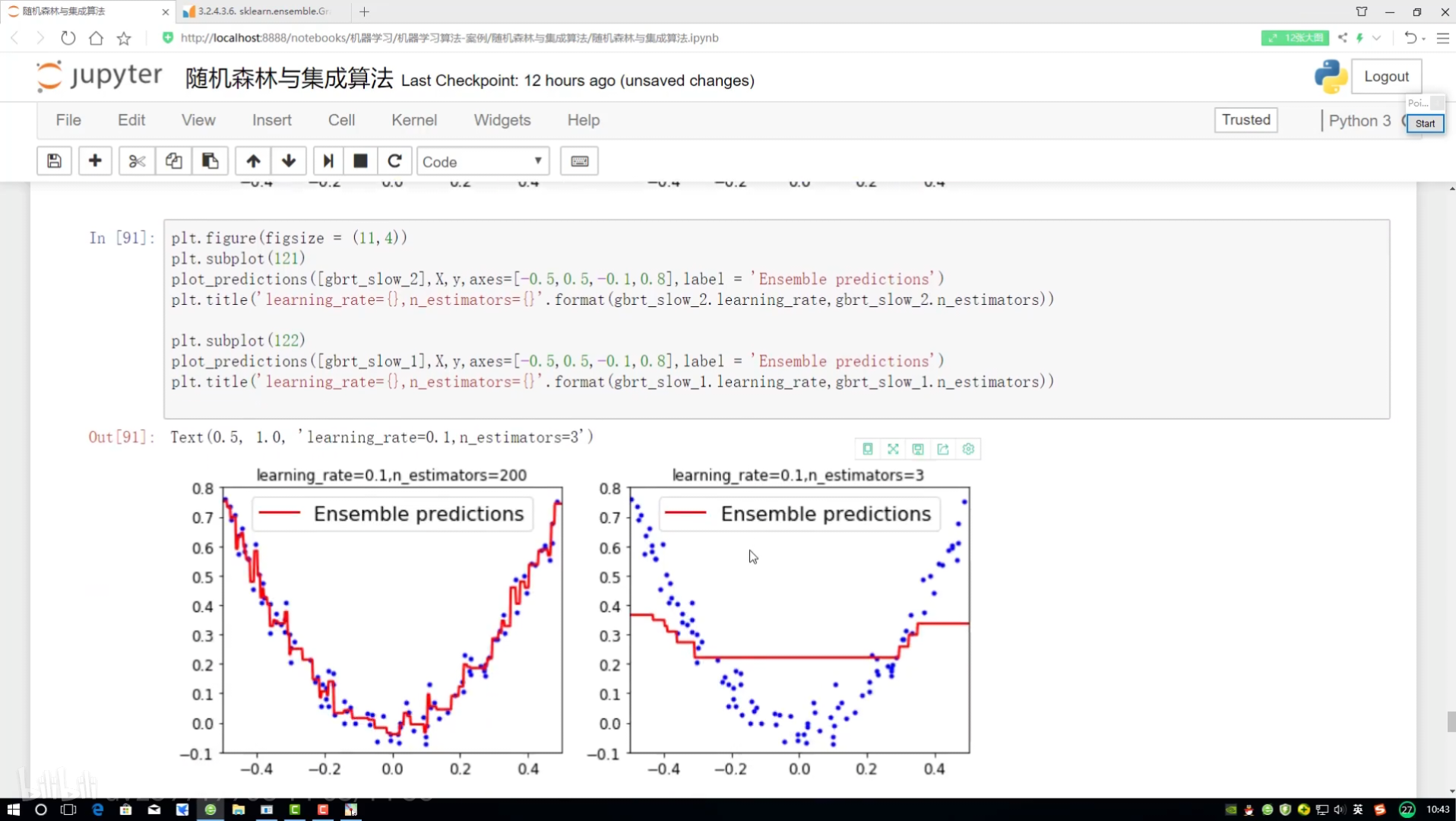
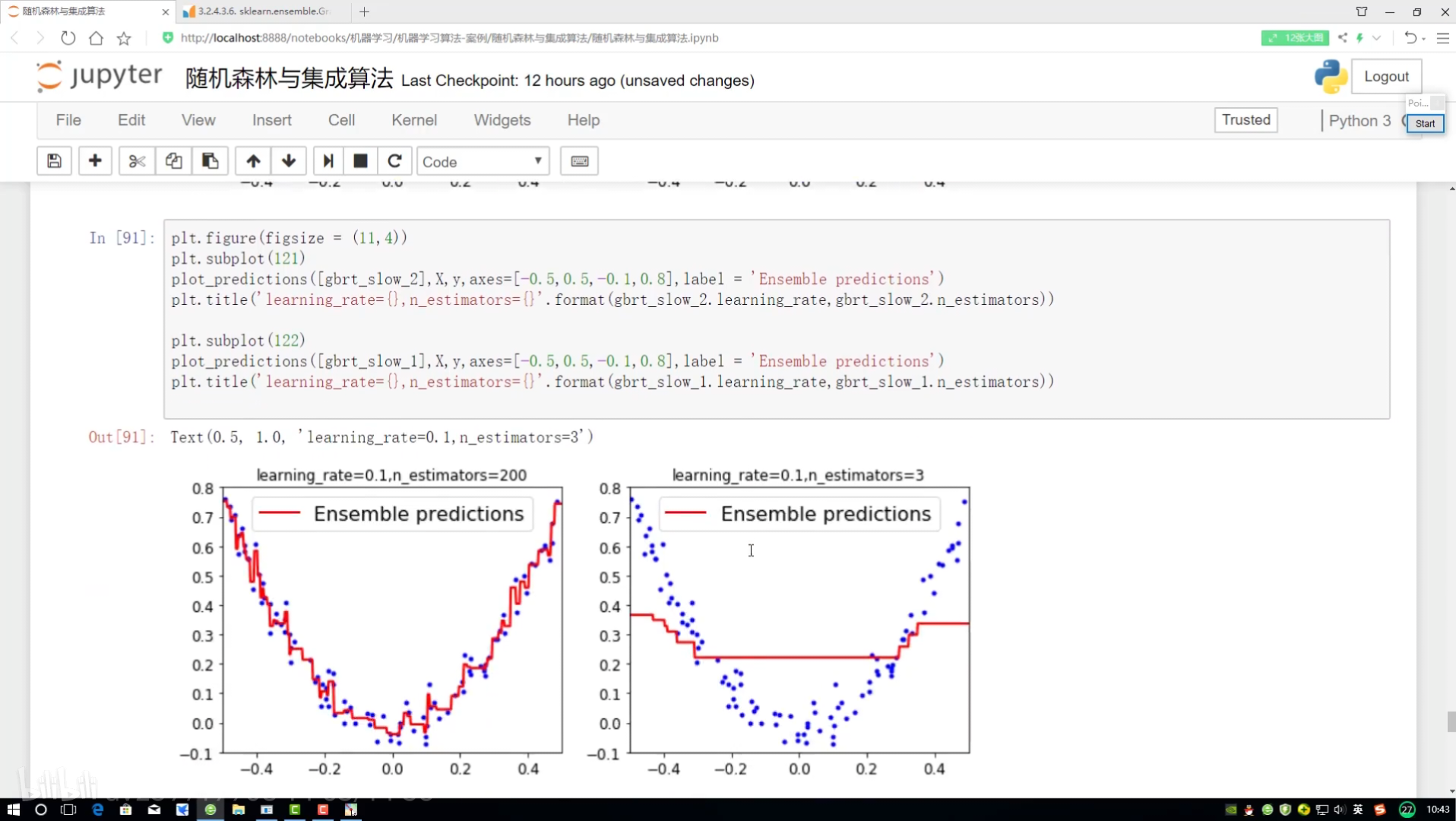
第二組對比實驗:
?
全部改成2
?
?
 ?
?
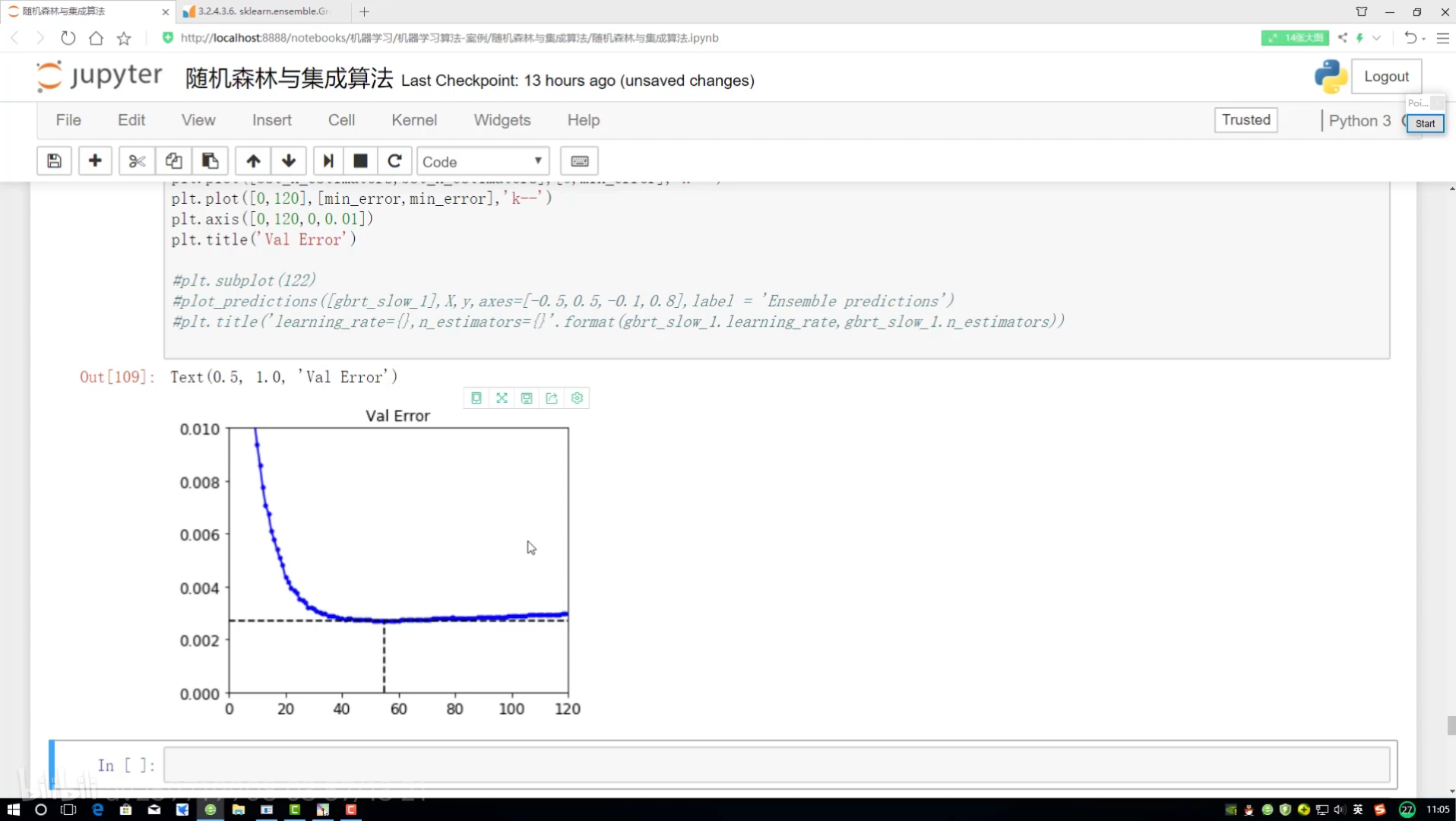
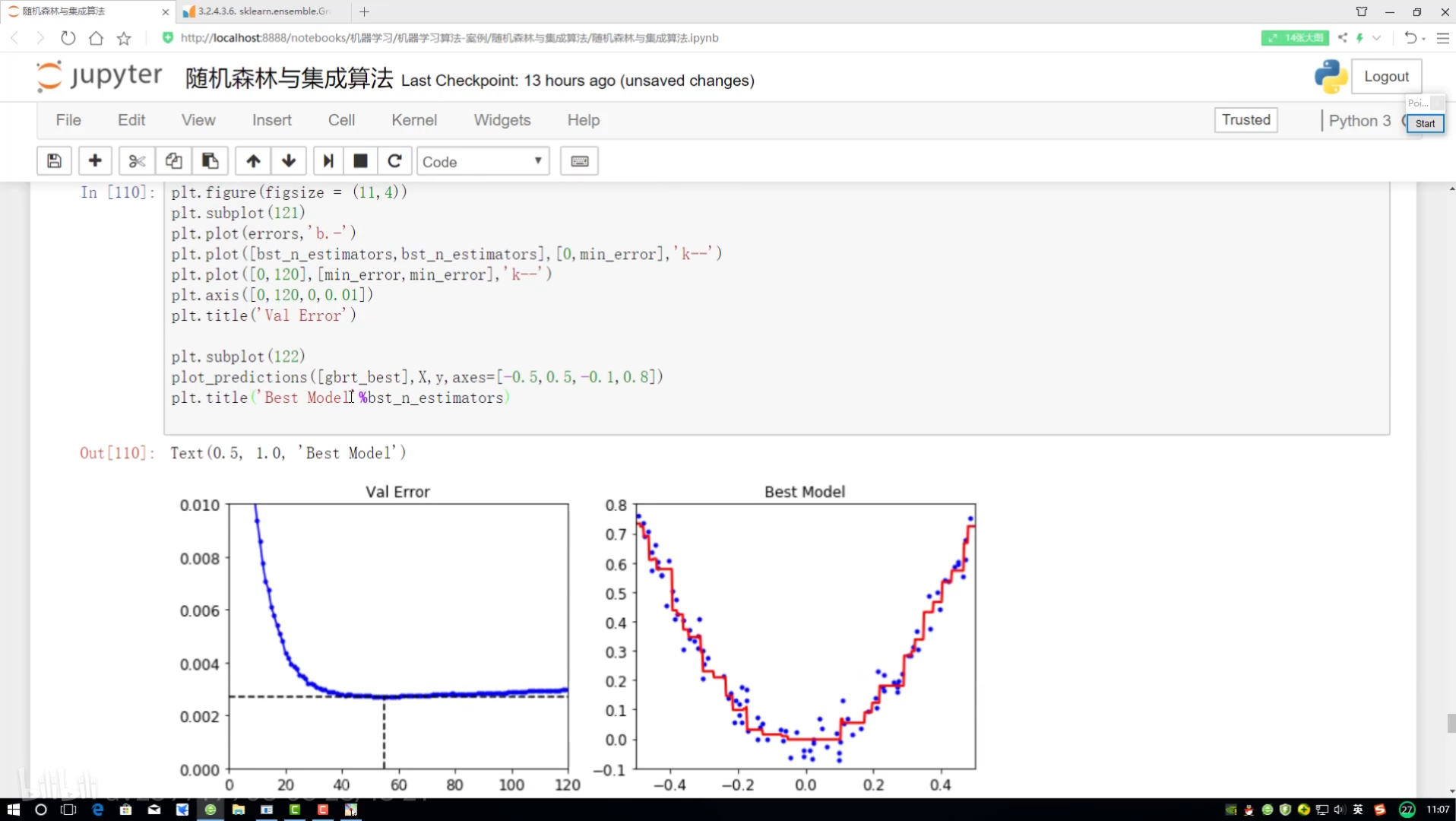
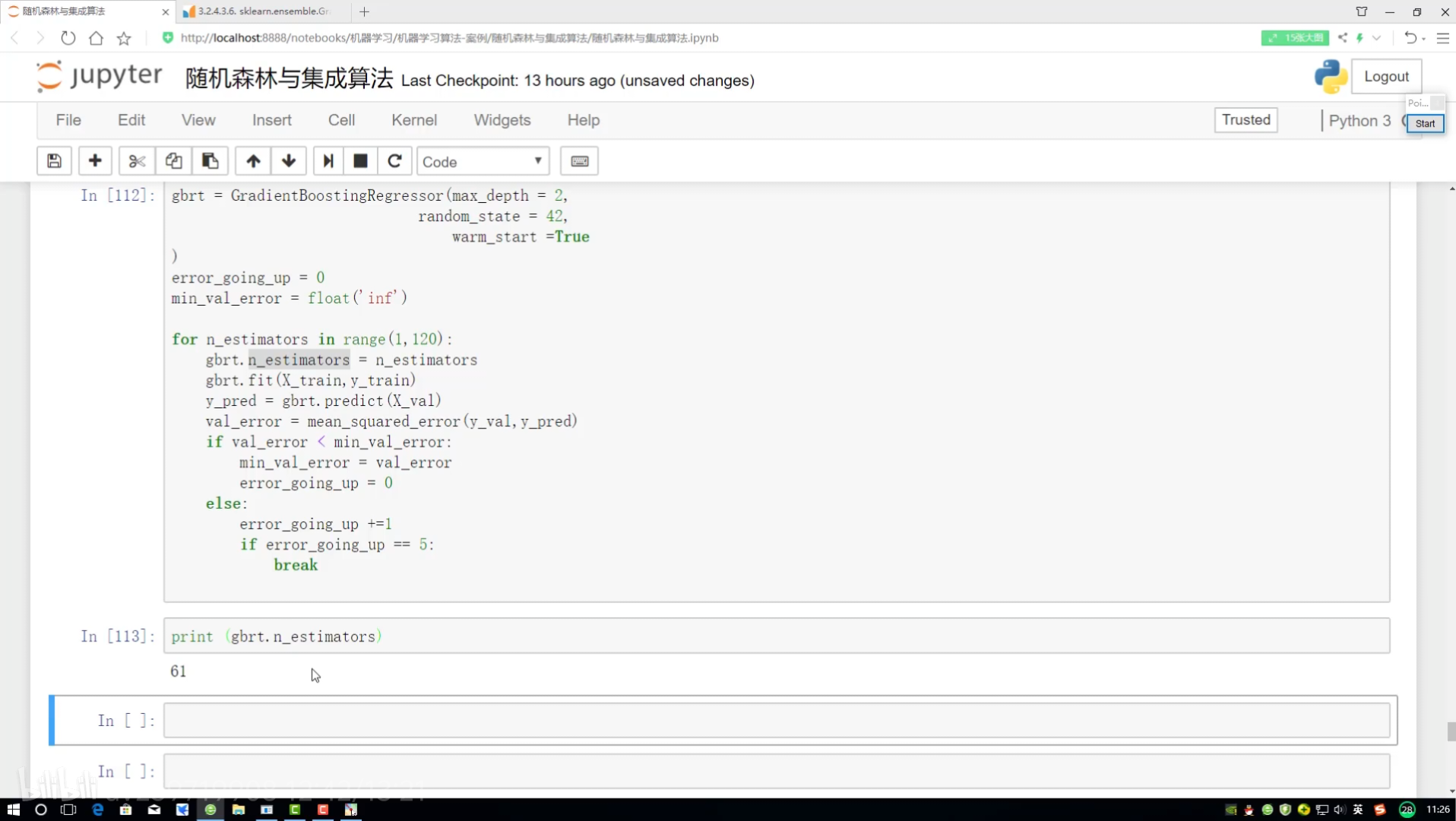
模型提前停止策略
?
.fit? xtrain實例化
?
?
停止方案實施:
?
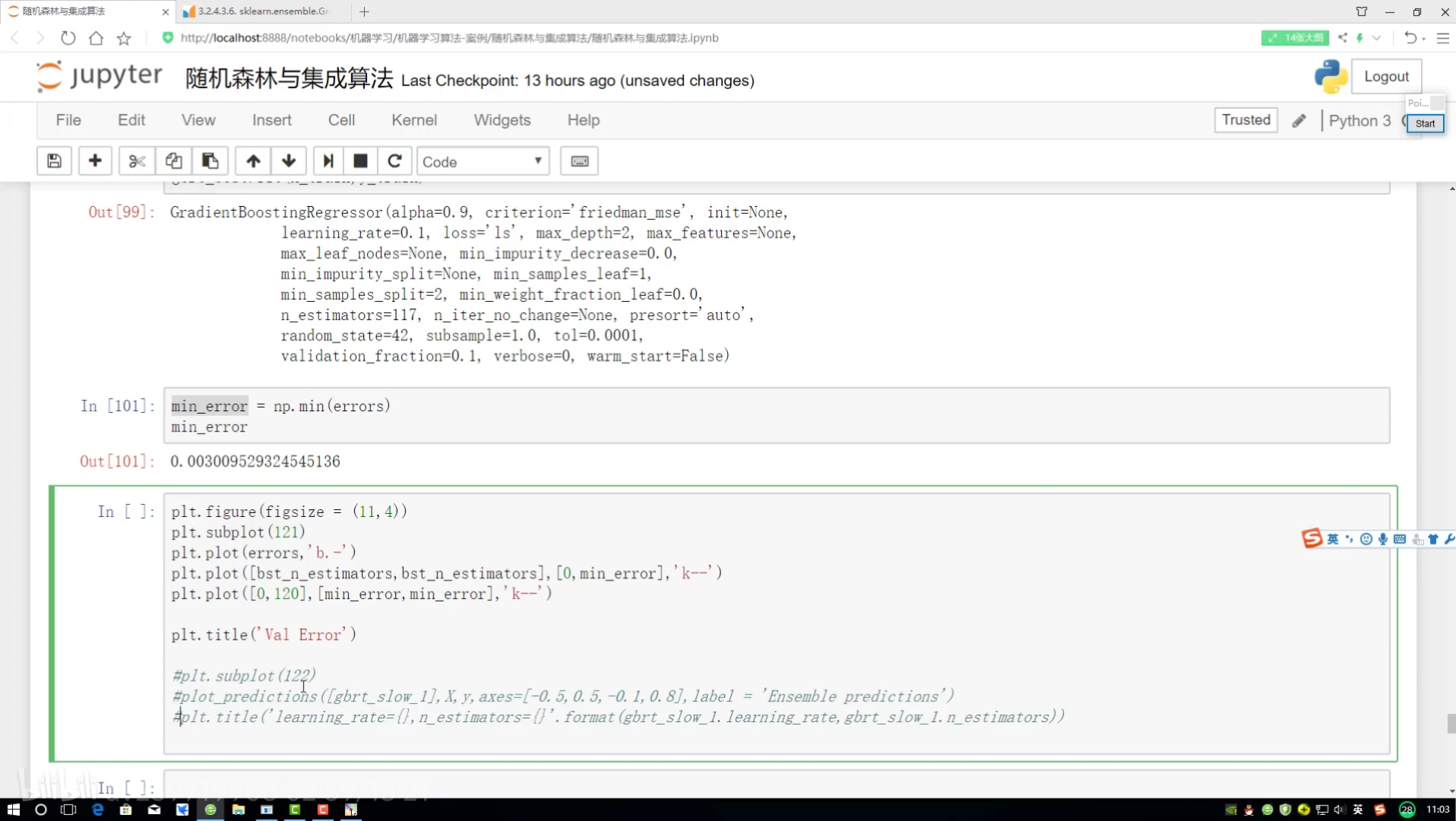 ?
?
?
 ?
?
 ?
?
?
?
?
?
設置上限 若連續5次都沒得到上升
?
stacking:堆疊集成
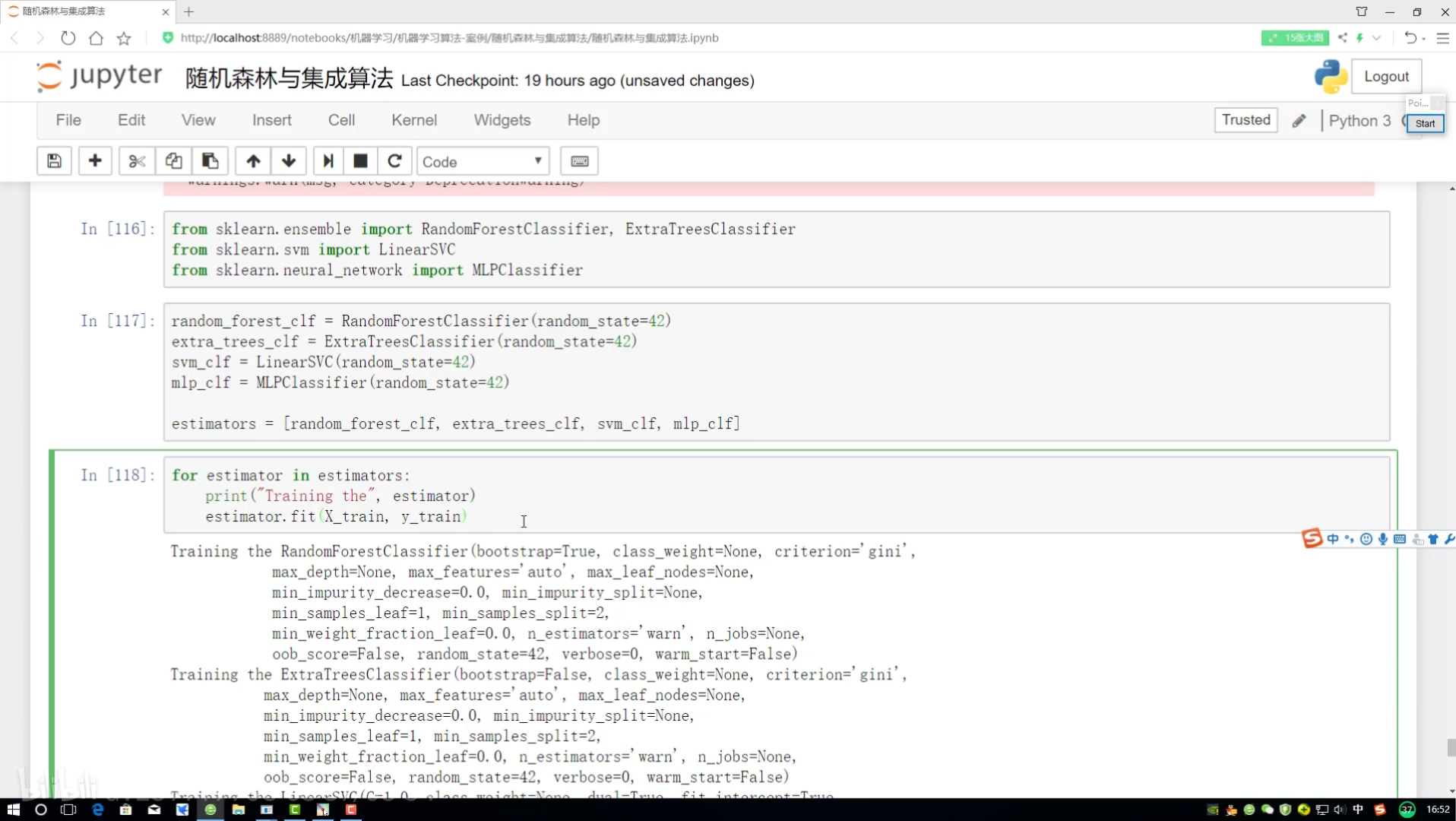
經過不同的算法(分類器)ABC
rf:隨機森林
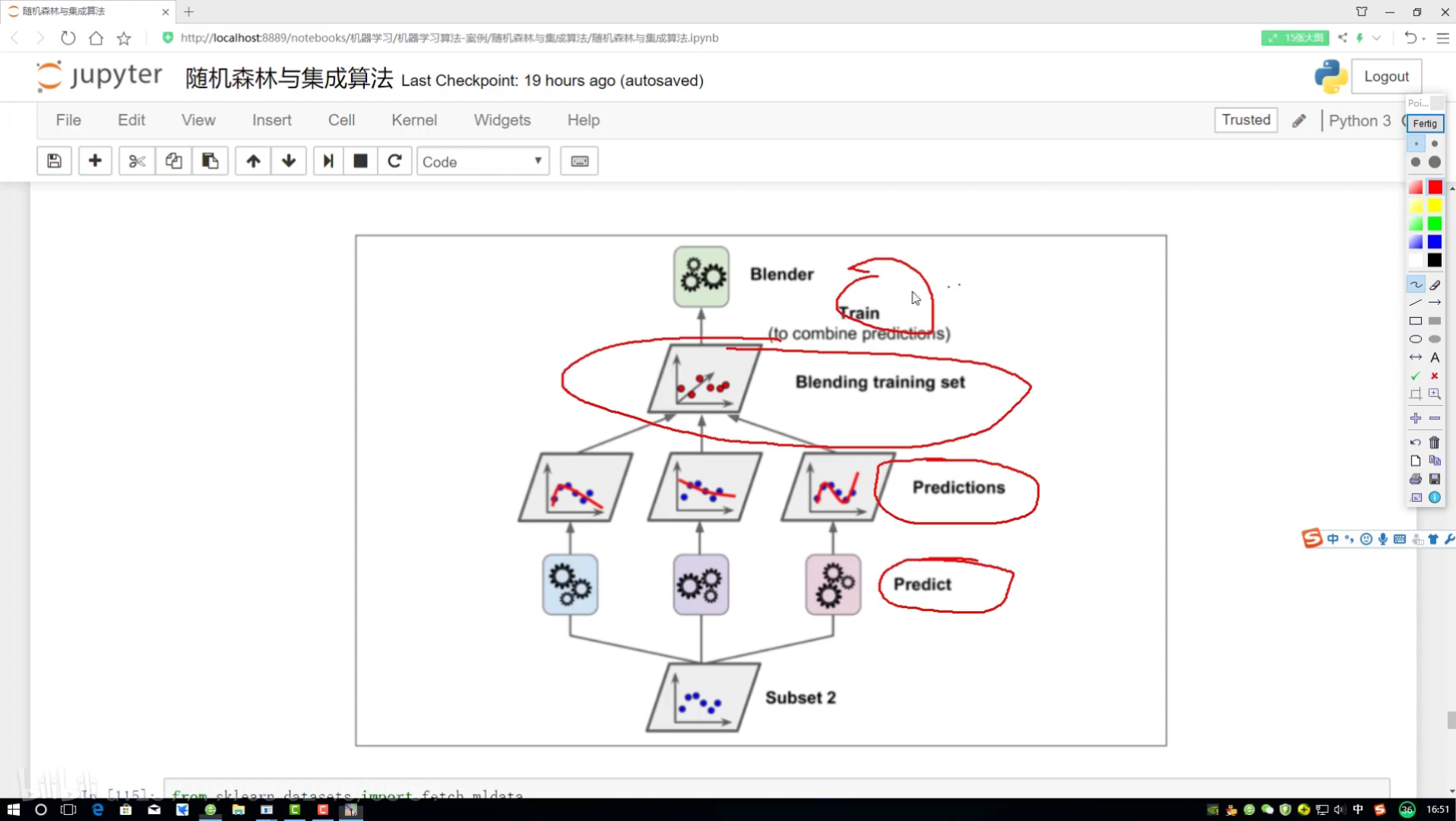
?
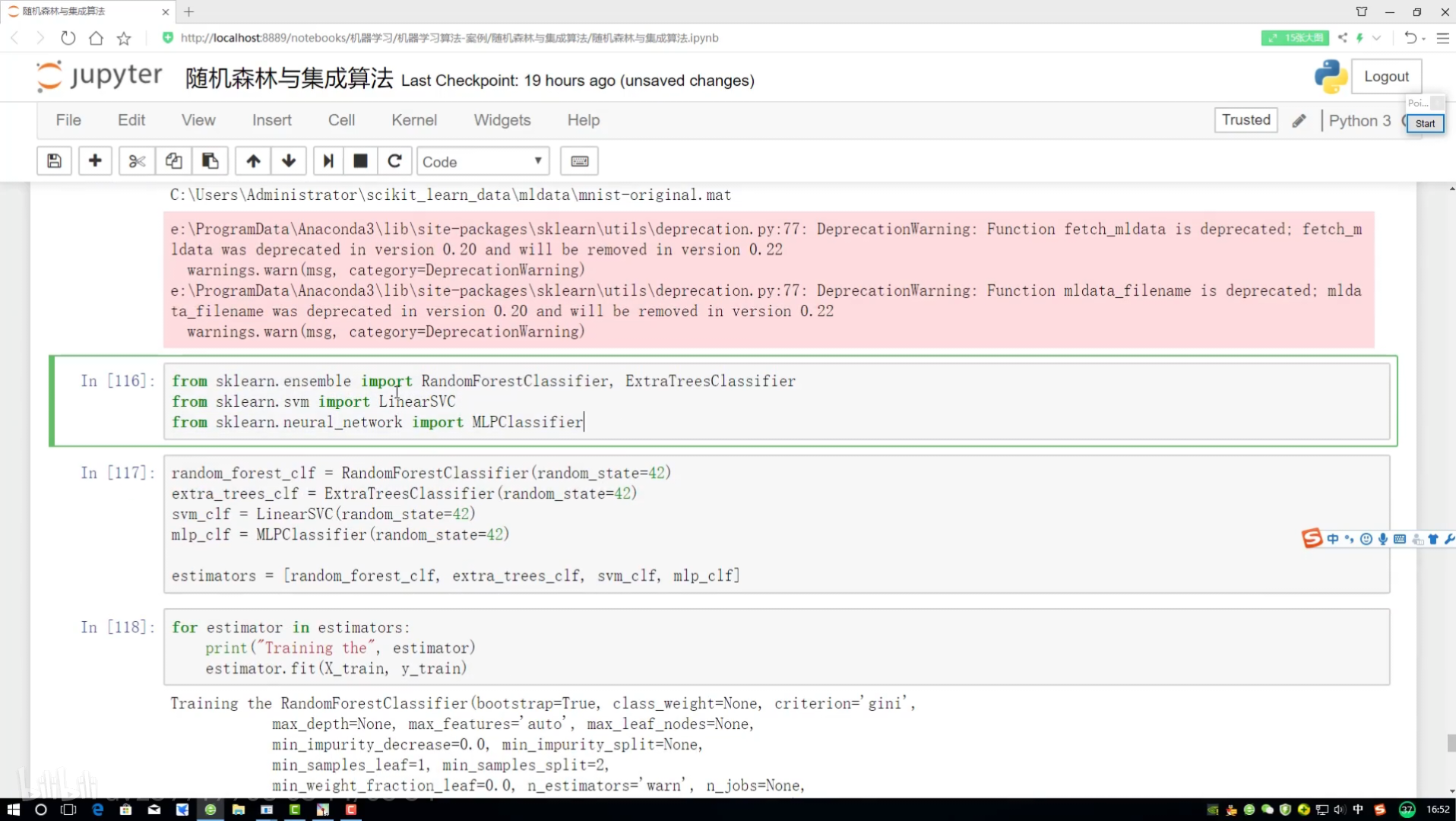
數據集切分
116選擇不同分類器
 ?
?
 ?
?
 ?
?
 ?
?
 ?
?
 ?
?
 ?
?
 ?
?
 ?
?
 ?
?
?
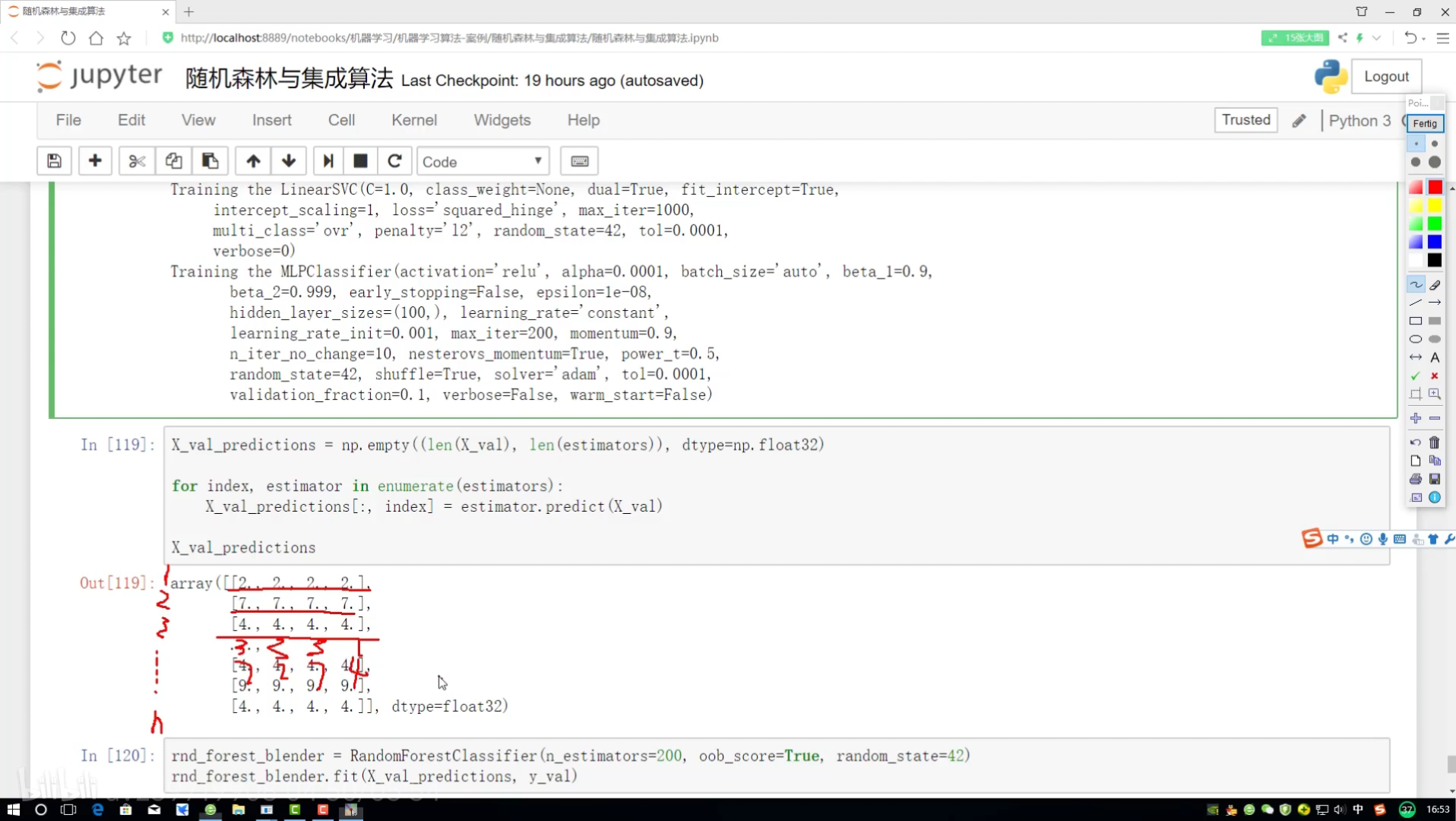
1階段結果變成2階段特征
?
?
?





的通用方案)





)


)




