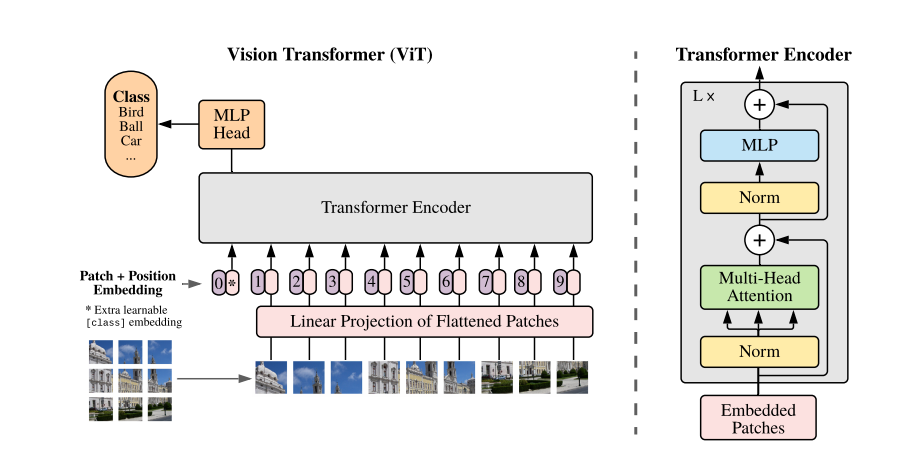
?當我們取到一張圖片,我們會把它劃分為一個個patch,如上圖把一張圖片劃分為了9個patch,然后通過一個embedding把他們轉換成一個個token,每個patch對應一個token,然后在輸入到transformer encoder之前還要經過一個class token,帶有分類信息,然后加上位置信息如圖123456789。
Transformer Encoder由右圖所示的部分組成,一共L個,然后再輸出到MLP Head,然后做一個分類。
?當我們取到一張圖片,我們會把它劃分為一個個patch,如上圖把一張圖片劃分為了9個patch,然后通過一個embedding把他們轉換成一個個token,每個patch對應一個token,然后在輸入到transformer encoder之前還要經過一個class token,帶有分類信息,然后加上位置信息如圖123456789。
Transformer Encoder由右圖所示的部分組成,一共L個,然后再輸出到MLP Head,然后做一個分類。
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/diannao/91831.shtml 繁體地址,請注明出處:http://hk.pswp.cn/diannao/91831.shtml 英文地址,請注明出處:http://en.pswp.cn/diannao/91831.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!



)
)









)



