目錄
- 索引分片寫入原理
- 概念
- 索引寫入流程
- 常見性能優化
- 背景
- 常見性能優化
- 硬件資源優化
- 分片和副本優化
索引分片寫入原理
概念
-
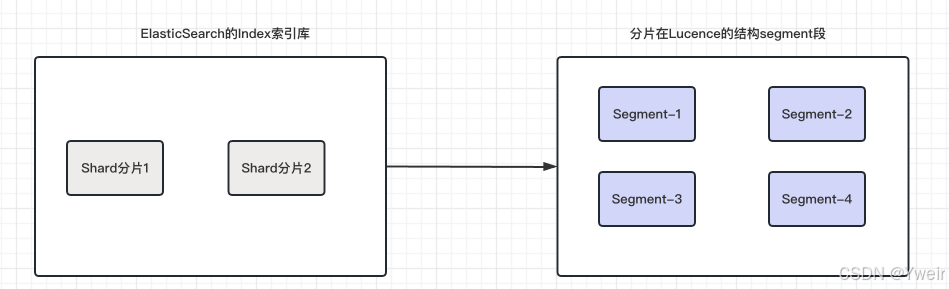
分片(shard)
- 分片是將索引數據分割成更小的、可分布式存儲和處理的單元
- 每個索引都由一個或多個分片組成,每個分片都是一個獨立的Lucene索引
-
段(segment)
- 段是Lucene索引的基本單元,每個分片都包含一個或多個段
- 段是不可變的,表示一定范圍內的文檔數據和相關的倒排索引,每一個Segment本質上就是一個倒排索引
- 總結
- 每個shard分片是一個lucene實例
- 每個分片由多個segment組成
- 每個segment占用內存,文件句柄
-
事務日志(Translog)
- 防止緩存中的
Segment還沒有來得及被commit到磁盤當中,就發生了一些意外,比如斷電等情況,導致數據丟失 - 引入
translog文件來保存這些記錄,新文檔先寫入內存 buffer 和 translog 文件,每個 shard 都對應一個 translog 文件 - 當
translog大到一定程度,將會發生一個commit操作也就是全量提交 translog也是先寫入 os cache 的,默認每隔 5 秒刷一次到磁盤中去- 所以默認情況下,可能有 5 秒的數據會僅僅停留在 buffer 或者 translog 文件的 os cache 中
- 如果此時機器掛了,會丟失 5 秒鐘的數據。但是這樣性能比較好,最多丟 5 秒的數據
- 也可以將 translog 設置成每次寫操作必須是直接 fsync 到磁盤,但是性能會差很多
- 防止緩存中的
-
刷新(Refresh)
- 將緩存中的文檔寫入Segment,并打開Segment,讓他可以被搜索的過程
- Refresh操作默認每秒執行一次, 將內存 buffer 的數據寫入到一個新 的 Segment 中
- 因此新加了一條數據,在下一秒就可以被搜索,也因此ES被稱為可以實時的搜索NRT
- 這個時候索引變成可被檢索的,寫入新Segment后 會清空內存buffer
- 經過了refresh間隔,將該時間段寫入的全部數據refresh成一個segment
- refresh過程是很消耗性能的,如果你的系統對實時性要求不高,可以通過API控制refresh的時間間隔
PUT /dp_shop
{"settings": {"refresh_interval": "30s" }
}
- 合并(merge)
- 每秒都會有新的segment生成,用不了多久segment的數量暴漲,每個段都將十分消耗文件句柄、內存、和cpu資源
- 系統無法忍受的,所以將零散的segment進行合并,ES通過后臺合并段解決這個問題
- ES因為會定期的把一些小的Segment或者沒用的Segment進行合并,減少存儲占用空間
- 小段被合并成大段,再合并成更大的段,然后將新的segment打開供搜索,舊的segment刪除
- 影響
- 每個segment的占據內存是隨著gc不會釋放掉的,導致系統內存不夠,進一步導致查詢超時等問題
- 查詢時會遍歷每個segment,過多的segment會導致查詢速度下降
- 刷盤(Flush)
- 實現文檔數據從文件系統緩存刷到磁盤的過程
- 會定期觸發,也可以當translog的數據達到某個上限的時候會進行一次flush操作
- 默認條件是,每 30 分鐘主動進行一次 flush,或者當 translog 文件大小大于 512MB主動進行一次 flush
- 配置
index.translog.flush_threshold_period和index.translog.flush_threshold_size
- 配置
- 在ES中, 要保證被索引的文檔能夠立即被搜索到, 有兩種方法:_refresh 或者 _ flush
索引寫入流程
- 當一個寫請求發送到ES后,ES會將數據寫入內存緩沖區(memory buffer)并添加事務日志
- 為了避免頻繁地將每條數據直接寫入硬盤文件,導致硬盤進行隨機寫入,而隨機寫入的效率較低,會對性能造成嚴重影響
- 在設計時,ES引入了Linux的高速緩存(File system cache)來提高寫入效率
- 當寫入請求發送到ES后,數據會被暫時寫入內存緩沖區,此時寫入的數據還不能立即被查詢到
- 默認,ES會每秒將內存緩沖區中的數據刷新到Linux的文件系統緩存中,并清空內存緩沖區,寫入的數據就可以被查詢到
- 這樣的設計可以避免頻繁進行隨機硬盤寫入,通過利用Linux的文件系統緩存,提高了Elasticsearch的寫入效率
- 關于translog和flush的一些配置項
//當發生多少次操作時進行一次flush。默認是 unlimited
index.translog.flush_threshold_ops
//當translog的大小達到此值時會進行一次flush操作。默認是512mb
index.translog.flush_threshold_size
//指定的時間間隔內如果沒有進行flush操作,進行一次強制flush操作 默認是30m
index.translog.flush_threshold_period
//多少時間間隔內會檢查一次translog,來進行一次flush操作,默認是5s
index.translog.interval
常見性能優化
背景
- 官方數據Elastic Search最高的性能可以達到,PB級別數據秒內相應
- 1PB=1024TB = 1024GB * 1024GB
- 但是很多小伙伴公司的Elastic Search集群,里面存儲了幾百萬或者幾千萬數據,但是ES查詢就很慢了
- 記住,ES數量常規是億級別為起點,之所以達不到官方的數據,多數是團隊現有技術水平不夠和業務場景不一樣
- 海量數據檢索領域榜單:https://db-engines.com/en/ranking/search+engine
常見性能優化
硬件資源優化
- 內存分配
- 將足夠的堆內存分配給Elasticsearch進程,以減少垃圾回收的頻率
- ElasticSearch推薦的最大JVM堆空間是30~32G, 所以分片最大容量推薦限制為30GB
- 30G heap 大概能處理的數據量 10 T,如果內存很大如128G,可在一臺機器上運行多個ES節點
- 比如業務的數據能達到200GB, 推薦最多分配7到8個分片
- 存儲器選擇
- 使用高性能的存儲器,如SSD,以提高索引和檢索速度
- SSD的讀寫速度更快,適合高吞吐量的應用場景
- CPU和網絡資源
- 根據預期的負載需求,配置合適的CPU和網絡資源,以確保能夠處理高并發和大數據量的請求
分片和副本優化
-
合理設置分片數量
- 過多的分片會增加CPU和內存的開銷,因此要根據數據量、節點數量和性能需求來確定分片的數量
- 一般建議每個節點上不超過20個分片
-
考慮副本數量
- 根據可用資源、數據可靠性和負載均衡等因素,設置合適的副本數量
- 至少應設置一個副本,以提高數據的冗余和可用性
- 不是副本越多,檢索性能越高,增加副本數量會消耗額外的存儲空間和計算資源
-
索引和搜索優化
- 映射和數據類型
- 根據實際需求,選擇合適的數據類型和映射設置
- 避免不必要的字段索引,盡可能減少數據在硬盤上的存儲空間
- 分詞和分析器
- 根據實際需求,選擇合適的分詞器和分析器,以優化搜索結果
- 了解不同分析器的性能特點,根據業務需求進行選擇
- 查詢和過濾器
- 使用合適的查詢類型和過濾器,以減少不必要的計算和數據傳輸
- 盡量避免全文搜索和正則表達式等開銷較大的查詢操作
- 映射和數據類型
-
緩存和緩沖區優化
- 緩存大小
- 在Elasticsearch的JVM堆內存中配置合適的緩存大小,以加速熱數據的訪問
- 可以根據節點的角色和負載需求來調整緩存設置
- 索引排序字段
- 選擇合適的索引排序字段,以提高排序操作的性能
- 對于經常需要排序的字段,可以為其創建索引,或者選擇合適的字段數據類型
- 緩存大小
-
監控和日志優化
- 監控集群性能
- 使用Elasticsearch提供的監控工具如Elastic Stack的Elasticsearch監控、X-Pack或其他第三方監控工具
- 實時監控集群的健康狀態、吞吐量、查詢延遲和磁盤使用情況等關鍵指標
- 配置日志級別和輪轉策略
- 根據需求配置Elasticsearch的日志級別和輪轉策略,以避免日志文件過大影響磁盤空間
- 并能方便故障排查和性能分析
- 監控集群性能
-
集群規劃和部署
- 多節點集群
- 使用多個節點組成集群,以提高數據的冗余和可用性。多節點集群還可以分布負載和增加橫向擴展的能力
- 節點類型和角色
- 根據節點的硬件配置和功能需求,將節點設置為合適的類型和角色
- 如數據節點、主節點、協調節點等,以實現負載均衡和高可用性
- 多節點集群
-
數據備份和恢復
- 定期備份數據
- 根據數據重要性和業務需求,定期備份Elasticsearch數據
- 可以使用snapshot和restore功能、在線備份工具或者文件系統級別的備份工具
- 定期備份數據
-
性能測試和優化
- 壓力測試
- 使用性能測試工具模擬真實的負載,評估集群的性能極限和瓶頸
- 根據測試結果,優化硬件資源、配置參數和查詢操作等
- 日常性能調優
- 通過監控指標和日志分析,定期評估集群的性能表現,及時調整和優化配置,以滿足不斷變化的需求
- 壓力測試
-
安全性和權限
- 啟用安全功能
- 在生產環境中,為了確保數據的安全性,啟用適當的安全功能,如訪問控制、身份驗證和傳輸加密等
- 權限控制
- 根據用戶角色和權限需求,設置合適的訪問控制策略。限制敏感數據的訪問權限,并定期審計用戶權限
- 啟用安全功能
-
升級和版本管理
- 計劃升級
- 定期考慮升級Elasticsearch版本,以獲取新功能、性能改進和安全修復
- 在升級過程中,確保備份數據并進行合理的測試
- 版本管理
- 跟蹤Elasticsearch的發行說明和文檔,了解新版本的特性和已知問題,并根據實際需求選擇合適的版本
- 計劃升級


(二))


:樹與二叉樹基礎 + 堆結構全解析)
)
)






—— Maven 打包瘦身和提速解決方案)
-> 認識Qt Creator)



