中國優秀開源軟件及企業調研報告
引言
當前中國開源生態呈現蓬勃發展態勢,技術創新領域尤為活躍,其中人工智能大模型成為開源動作的核心聚焦方向。2025年上半年,國內AI領域開源生態迎來密集爆發,頭部科技企業相繼推出重要開源舉措:6月30日,華為正式開源部分盤古大模型體系,百度同步推出文心大模型4.5系列模型的開源方案;阿里巴巴通過發布多版本開源大模型及運營魔搭社區構建起完善的開源生態體系;騰訊混元亦已開源其混合推理MoE模型Hunyuan-A13B及3D生成模型等。這些動態集中體現了中國企業在AI大模型領域的開源進展,構成國內開源生態技術創新熱點的重要組成部分。
主要開源企業及明星項目分析
華為
OpenHarmony(開源鴻蒙)
OpenHarmony作為全場景分布式操作系統,其核心技術優勢在于“彈性部署”“軟總線”及“一次開發、多端部署”的架構設計,能夠打破不同設備間的硬件壁壘,實現異構終端的跨端互聯、數據統一調度與服務協同。該系統以統一操作系統為底座,支持從嵌入式設備到智能終端的全場景適配,通過硬件互助與資源共享機制,構建安全可靠的端網云協同環境,有效解決傳統行業中“信息孤島”“設備協同難”等痛點,為行業數字化轉型提供技術支撐[1][2][3]。
在推動行業數字化轉型方面,OpenHarmony已在建筑、工業、電力、交通等多領域實現規模化落地。建筑領域,福州建總大廈作為全國首個基于OpenHarmony的智慧樓宇,通過“開鴻安全數字底座”與KaihongOS構建“智慧大腦”,實現空調燈光自動調節(預計節能率10%-15%,年減碳排放近百噸)、智慧安防(人臉識別入樓、軌跡追蹤)及應急保障(數字孿生逃生路線推送)等功能,設備壽命延長10%~15%,成為國產化技術在建筑領域的典范[4][5][6]。同時,《建筑開源鴻蒙技術框架白皮書》提出統一開放架構,涵蓋終端底座、端端互聯、端云協同及管理平臺,采用CoAP協議保障通信安全,定義標準化數據模型,推動建筑智能化全鏈路國產化,已規劃工程、產品、子系統等多維度標準體系[2][7][8]。
工業領域,OpenHarmony的分布式特性與高安全性被廣泛應用于工業控制場景。華龍訊達基于OpenHarmony開發的華龍工業操作系統(HualongOS),實現PLC、HMI、SCADA等設備互聯互通,支持“一次開發、多端部署”,其具身智能生產線可通過人機界面快速定制生產,驗證了對國外工業軟件的替代能力[9][10]。天罡智能研發的iiRobotOS則是國內首個基于OpenHarmony的工業機器人操作系統,已在珞石、埃夫特等企業完成驗證,提升機器人協作編程效率[11]。此外,電力行業的中國南方電網“電鴻”系統實現設備即插即用,超300家伙伴加入生態;交通領域的杭山東隧道落地智慧隧道解決方案,樹立全域數字化示范樣板[1][9]。
生態擴展方面,OpenHarmony 5.0 Release版本的發布標志著生態逐步成熟。軟通動力旗下鴻湖萬聯累計貢獻代碼超100萬行,投入超800人月參與社區建設,發布SwanlinkOS SDK推動架構模塊化,并推出搭載該系統的AI PC及智能交互平板,2025年進一步優化AI PC體驗,集成大模型應用與教育軟件移植[1][12]。行業合作方面,與南方科技大學等共建教學中心,與微展世聯合發布工業操作系統,在居民服務領域部署1.2萬臺社保自助終端,生態覆蓋芯片、模組、終端、應用等全產業鏈[1]。
商業化潛力方面,OpenHarmony已從技術驗證邁向規模商用。建筑領域,萬安智能與華為云合作推出基于OpenHarmony V5.0的空間單元智控器,實現IoT設備全域協同[13];油氣行業的智慧油站方案搭載LightBeeOS,支持消費者全程無接觸操作;養老領域的“幸福開鴻”方案通過彈性部署滿足多場景需求[9]。對比Android等系統,OpenHarmony以全場景分布式架構為核心差異,聚焦垂直行業數字化,強調設備互聯與數據安全,而Android更側重消費端移動應用生態,兩者在應用場景與技術定位上形成互補。隨著標準體系完善與示范應用推廣,OpenHarmony有望在工業互聯網、智慧城市等領域構建差異化競爭優勢。
盤古大模型
2025年6月30日,華為正式開源部分盤古大模型體系,這是其首次開源大模型,具體包括70億參數的盤古稠密模型、720億參數的盤古Pro MoE混合專家模型,以及配套的昇騰模型推理技術體系[14][15]。此前,在6月20日舉辦的華為開發者大會2025上,華為云已發布全面升級的盤古大模型5.5版本,其技術版圖覆蓋自然語言處理、計算機視覺、多模態理解等五大基礎模型領域[14]。
華為此舉的核心戰略意圖在于踐行昇騰生態戰略,通過開源推動大模型技術的研究與創新發展,加速人工智能在千行百業的應用與價值創造[15]。在技術路線上,盤古大模型展現出顯著特色,特別是720億參數的盤古Pro MoE混合專家模型,采用動態激活專家網絡的創新設計。該模型在參數量僅為720億、激活160億參數量的情況下,即可達到千億級模型的性能表現,體現了其在高效計算與性能優化方面的優勢[15]。
| 模型名稱 | 參數量(億) | 關鍵特性 | 適用場景 |
|---|---|---|---|
| 盤古稠密模型 | 70 | 部署門檻較低 | 智能客服、知識庫等輕量化場景 |
| 盤古Pro MoE混合專家模型 | 720 | 動態激活專家網絡設計,激活參數量160億,性能達千億級模型水平 | 高性能計算需求場景 |
| 數據來源:[15] |
為降低行業應用門檻,華為針對性地開源了70億參數的稠密模型,該模型部署門檻較低,適用于智能客服、知識庫等多樣化場景,能夠滿足不同行業的輕量化應用需求[15]。同時,配套開源的昇騰模型推理技術體系,進一步強化了盤古大模型與昇騰算力平臺的協同,有助于推動昇騰算力生態的建設與完善,為開發者和企業提供從模型到算力的全棧支持。
百度
文心大模型4.5系列
百度在文心大模型的發展中展現了從閉源向開源的戰略轉變。2025年6月30日,百度正式開源文心大模型4.5系列,涵蓋10款不同參數規模的模型,包括47B、3B激活參數的混合專家(MoE)模型及0.3B參數的稠密型模型,實現了預訓練權重與推理代碼的完全開源[14][15]。該系列在技術上實現了多模態理解與輕量化部署的突破,針對MoE架構提出創新性的多模態異構模型結構,適用于從大語言模型向多模態模型的持續預訓練范式,其關鍵技術包括多模態混合專家模型預訓練、訓練推理框架及針對模態的后訓練等,在保持或提升文本任務性能的基礎上顯著增強了多模態理解能力[15]。
性能表現上,文心多模態后訓練模型在視覺常識、多模態推理、視覺感知等主流多模態大模型評測中表現優于閉源的OpenAI o1;輕量模型文心4.5-21B-A3B-Base的文本模型效果與同量級的Qwen3相當[15]。此外,文心大模型4.5系列的獨立自研技術比例、模型類型多樣性及參數規模豐富度均處于行業領先水平[14]。
Apache HugeGraph
Apache HugeGraph 作為 Apache 基金會下首個融合圖數據庫、圖計算與圖 AI 能力的開源系統,在技術架構上展現出顯著領先性。其核心優勢在于實現了 OLTP(在線事務處理)與 OLAP(在線分析處理)的一體化支持,能夠同時滿足實時圖數據查詢與大規模圖計算需求,這一特性使其在圖計算與 AI 融合領域具備獨特競爭力[16]。技術兼容性方面,HugeGraph 全面支持 Apache TinkerPop 3 框架,并兼容 Gremlin 和 Cypher 兩種主流圖查詢語言,可無縫對接多種大數據組件,為企業級復雜場景下的多源數據整合與分析提供了靈活支撐[16]。
與國際同類產品(如 Neo4j)相比,HugeGraph 的差異化優勢體現在“數據庫+計算+AI”的深度融合能力。傳統圖數據庫多聚焦于單一事務處理或分析場景,而 HugeGraph 通過一體化架構設計,可直接支撐 AI 模型對圖數據的實時訪問與計算下推,減少數據流轉開銷。例如,在 2025 年 GLCC 編程夏令營中,百度安全圍繞 HugeGraph 發布的課題涵蓋 AI 倉庫智能化改造、存儲引擎升級(如 RocksDB Plus 應用)及圖計算下推實現等方向,進一步驗證了其在 AI 融合與高性能存儲領域的技術深耕[16]。
開源社區活躍度方面,HugeGraph 通過持續輸出技術課題與激勵機制(如單個課題最高獎勵 12000 元)吸引開發者參與核心功能迭代,顯示出項目在技術演進上的社區驅動力[16]。商業化潛力層面,其多語言支持、大數據生態兼容性及一體化處理能力,使其具備成為企業級圖數據庫解決方案的基礎條件,尤其適用于需要實時圖分析與 AI 建模結合的復雜業務場景(如金融風控、社交網絡分析等)。
阿里巴巴
通義千問Qwen系列
在開源大模型競賽中,阿里巴巴通義團隊通過快速迭代與生態共建相結合的策略鞏固市場地位。截至2025年6月,該團隊已開源200多款大模型,通義千問Qwen系列的衍生模型數量突破13萬,超越美國Llama模型,全球下載量超過3億次,在HuggingFace社區2024年全球模型下載量中占比超30%,顯示出其在生態構建上的顯著成效[15]。性能方面,Qwen系列通過豐富的衍生模型數量形成差異化競爭力,其開源策略中“所有模型均免費使用”的條款進一步降低了開發者使用門檻,推動了模型的廣泛應用與生態擴展[15]。
Dubbo
Dubbo作為阿里巴巴開源的微服務框架,其技術演進歷程反映了從傳統分布式服務治理到云原生架構的適配過程。該框架起源于2008年阿里巴巴內部的SOA解決方案,2011年正式開源(2.0.7版本),2017年重啟開源維護,并于2020年啟動Dubbo 3.0版本研發,標志著向云原生服務治理平臺的轉型[17]。在版本迭代方面,2.x系列為經典穩定版本,其中2.6.x側重穩定性優化與兼容性改進,2.7.x引入元數據中心、配置中心支持(如Apollo、Nacos)及異步化改進;3.x系列則聚焦云原生能力建設,3.0版本(2021年發布)推出應用級服務發現、統一路由規則、Triple協議(兼容gRPC,支持HTTP/2和流式通信)及Kubernetes、Service Mesh等云原生支持,3.1版本(2022年)強化服務網格集成(如Istio)與可觀測性,3.2版本(2023年)進一步優化云原生支持、增強流量治理(流量控制、熔斷、降級)并擴展多語言支持(Go、Rust等)[18]。
在云原生時代,Dubbo與Spring Cloud的競爭力對比體現在多維度。遠程調用方式上,Dubbo基于RPC協議,采用自定義數據格式與原生TCP通信,具有速度快、效率高的優勢,但需進行序列化和反序列化;Spring Cloud則基于HTTP協議,消息封裝雖較臃腫,但具備跨語言、跨平臺特性[18]。核心組件方面,兩者差異顯著:
| 核心組件 | Dubbo | Spring Cloud |
|---|---|---|
| 服務注冊中心 | zookeeper | Spring Cloud Netflix Eureka |
| 服務調用方式 | RPC | REST API |
| 服務網關 | 無 | Spring Cloud Netflix Zuul |
| 斷路器 | 不完善 | Spring Cloud Netflix Hysrix |
| 分布式配置 | 無 | Spring Cloud Config |
| 分布式追蹤系統 | 無 | Spring Cloud Sleuth |
| 消息總線 | 無 | Spring Cloud Bus |
| 數據流 | 無 | Spring Cloud Stream(基于Redis,Rabbit,Kafka實現的消息微服務) |
| 批量任務 | 無 | Spring Cloud Task |
生態與社區活躍度方面,Spring Cloud憑借更完善的組件生態(如服務網關、分布式配置中心)和更高的更新頻率,社區活躍度相對更高,問題解決效率與資料豐富度占優;Dubbo生態雖涵蓋注冊中心(Nacos、Zookeeper等)、配置中心(Apollo、Nacos等)及監控工具(Prometheus、Grafana等),但整體生態完整性與社區更新頻率略遜[18][19]。
Dubbo社區呈現活躍與挑戰并存的特點。截至相關統計,其GitHub星標數達40290,擁有超過600位contributor、57位committer,近一年日均提交約60個commits,外部代碼貢獻量已超過阿里內部,全球微服務框架排名第五[17][20]。為保障代碼質量,社區采用單測、集成測試(dubbo-samples)、性能測試(dubbo-benchmark)及code review機制,但單測存在耗時過長(如Ubuntu和Windows環境下JDK8/11測試常超時)、多注冊中心混合場景覆蓋不足等問題,其中與Zookeeper相關的測試用例耗時顯著,例如:
| Testcase | Time elapsed(s) |
|---|---|
| org.apache.dubbo.rpc.protocol.dubbo.ArgumentCallbackTest | 76.013 |
| org.apache.dubbo.config.spring.ConfigTest | 61.33 |
| org.apache.dubbo.config.spring.schema.DubboNamespaceHandlerTest | 50.437 |
| org.apache.dubbo.config.spring.beans.factory.annotation.ReferenceAnnotationBeanPostProcessorTest | 44.678 |
| org.apache.dubbo.rpc.cluster.support.AbstractClusterInvokerTest | 29.954 |
| org.apache.dubbo.remoting.zookeeper.curator.CuratorZookeeperClientTest | 25.847 |
| org.apache.dubbo.config.spring.beans.factory.annotation.MethodConfigCallbackTest | 25.635 |
| org.apache.dubbo.registry.client.event.listener.ServiceInstancesChangedListenerTest | 24.866 |
| org.apache.dubbo.remoting.zookeeper.curator5.Curator5ZookeeperClientTest | 19.664 |
此外,社區還面臨入門門檻高、官網資料不全、網上源碼級分享少、框架部署復雜等挑戰[20][21]。
在行業滲透率方面,Dubbo已廣泛應用于電商、金融等關鍵領域。阿里巴巴內部各業務線(淘寶、考拉、餓了么、釘釘、達摩院等)已全量或分批上線Dubbo 3.0版本;外部企業中,金融領域的工商銀行、平安健康,電商領域的網易考拉,以及VIVO、當當、瓜子二手車、去哪兒、芒果TV、TCL、海爾等均大量采用該框架,登記企業用戶超200個,生態合作伙伴達30多個[17][20][22]。
PingCAP
TiDB
TiDB是由PingCAP開發的開源分布式關系型數據庫,自2015年在GitHub創建以來,已發展至v8版本,持續保持在國產數據庫市場前列,以HTAP(混合事務/分析處理)能力著稱,適用于對實時分析和事務處理要求較高的業務場景[23][24]。作為國內活躍開源項目,其技術優勢主要體現在兼容性、彈性擴展、架構先進性及多模態處理能力等方面[25]。
技術層面,TiDB兼容MySQL協議和SQL語法,可直接復用MySQL生態工具與應用,降低遷移成本[24][26]。彈性擴展能力突出,支持通過添加節點實現存儲與處理能力的線性擴展,結合智能分片、負載均衡及故障自動遷移機制,可動態應對業務增長[24]。HTAP架構是其核心特性,通過TiFlash列式存儲組件與向量化執行引擎,實現同一系統內OLTP與OLAP workload的一體化處理,滿足實時數據分析需求[24][26]。此外,TiDB采用云原生架構,支持公有云、私有云及混合云部署,通過TiDB Operator實現自動化運維,并具備高可用性(多副本機制與節點故障自動切換)[24]。在AI時代,TiDB積極拓展向量搜索能力,自v6.0 TiFlash開源后,逐步支持向量存儲(最高16383維)、HNSW索引算法(特定場景準確率達98%)及性能優化,最新LTS版本(v8.5.0)進一步提升向量距離計算效率與數據更新場景下的查詢性能,新增CPU使用率監控指標,強化AI就緒能力[26][27]。
國產替代方面,TiDB在金融、醫療等核心系統領域成效顯著。針對金融行業核心交易場景,v8.5 LTS版本通過優化I/O抖動(影響降至十分之一)、動態擴縮容機制及更新性能(提升500%),并支持多租戶資源組劃分,滿足金融業務高并發、高可用需求[24]。在醫療領域,TiDB被集成至臨床一體化信息系統,作為核心數據庫平臺承接基礎業務與數據中臺的數據流通,通過“多庫合一、資源統一調度”實現業務資源彈性分配與隔離,支撐門診、電子病歷等系統高并發訪問,解決傳統數據庫資源孤島與擴展瓶頸問題,實現醫療核心系統國產化替代[28]。其“自主開源、架構先進、PB級擴展、全場景、異構遷移友好”的優勢,成為國產化替代的重要選擇[28]。
國際化布局上,TiDB全球影響力持續提升。DB-Engines排名從2019年的150–160區間躍升至全球數據庫總榜前100名,在關系型數據庫中排名第38位,僅次于Singlestore,超越Google Spanner[27]。2024年全球業務翻倍增長,服務超4000家企業,覆蓋25個國家和地區,典型客戶包括北美的Pinterest、日本的Rakuten、亞太的NinjaVan與Flipkart、EMEA地區的Bolt等[27]。其全球化戰略以“本地化(Local for local)”為核心,通過開源模式觸達用戶,并構建本地化服務支撐體系,如2025年印度TiDB User Day India大會上,Flipkart等客戶分享實踐經驗[27]。此外,TiDB連續三年入選Gartner Peer Insights“Voice of the Customer”云數據庫報告,并在日本市場連續三年被選為工程師最想使用的數據庫之一,彰顯國際市場認可度[27]。
螞蟻集團
隱語SecretFlow
隱語SecretFlow是由螞蟻集團旗下螞蟻密算于2022年7月開源的可信隱私計算框架,在隱私計算領域展現出顯著的技術包容性與實用性。該框架支持多方安全計算(MPC)、聯邦學習(FL)、可信執行環境(TEE)等當前主流隱私計算技術,能夠滿足不同場景下的數據安全協作需求,體現了其在技術整合與兼容性方面的領先性[16]。
在數據要素市場化進程中,隱語SecretFlow已在銀行、醫療、保險、政務、互聯網營銷等多個關鍵行業實現應用,有效推動了數據在“可用不可見”前提下的流通與價值釋放,為打破數據孤島、促進跨主體數據協作提供了技術支撐,成為數據要素市場化配置的重要基礎設施[16]。
螞蟻集團通過開源隱語SecretFlow,積極構建了由高校、企業及開源社區共同參與的協作生態。例如,在GLCC 2025編程夏令營中,隱語項目設置了Kuscia基于帶寬調度實現、SCQL多余RunSQL語句優化等技術課題,吸引開發者參與框架的迭代優化,這一舉措不僅有助于提升項目的技術成熟度,更體現了其通過開源模式凝聚行業共識、推動隱私計算技術標準化的戰略意圖[16]。
Ant Design
Ant Design是螞蟻集團開源的企業級UI設計語言與React組件庫,自2015年發布以來持續迭代,截至2025年已更新至v5.25.2版本,GitHub星標數達89.5k,每月NPM下載量超4000萬次,是GitHub中文排行榜中的熱門UI框架,其生態影響力在國內外前端領域均表現突出[29][30]。
在設計體系標準化方面,Ant Design基于統一設計體系構建,支持全場景組件覆蓋與靈活定制。核心特性包括80+基礎組件(如按鈕、輸入框、導航等)、數據組件(表格、樹狀圖、圖表等)、高級組件(動態表單生成與驗證、復雜日期選擇器等)及實驗性組件(Web3、低代碼場景探索),并通過Less實現主題配置,支持自定義色彩、字體、間距等設計tokens,內置暗黑模式一鍵切換,全程提供TypeScript接口定義與智能提示,確保開發過程中的設計一致性與規范性[30]。
多端適配與跨框架支持是Ant Design的重要優勢。針對移動端與跨框架需求,其衍生項目Ant Design Blazor持續優化,2025年發布的1.1.0版本新增Table組件條紋樣式、樹形結構延遲加載、列索引設置等功能,修復行分組響應異常,并支持SVG字符串自定義與Typography組件標題級別擴展;1.4.2版本進一步聚焦組件穩定性與性能,優化Tabs、Table、Form等核心組件在wasm渲染模式下的加載速度,修復固定頭/列樣式錯位等問題,同時新增eu_ES巴斯克語支持,完善國際化能力[31][32][33]。此外,Ant Design Pro作為企業級Web應用開發框架,基于React技術棧集成umi、dva狀態管理,支持響應式布局設計,覆蓋金融、電商、內部OA系統等多場景,提供開箱即用的UI解決方案[34]。
Ant Design顯著提升了國內前端開發效率。其組件庫通過按需加載(Tree Shaking)與虛擬滾動(Virtual Scrolling)優化性能,減少打包體積并提升大數據列表渲染效率;Ant Design Pro內置Mock服務、完整國際化解決方案及UI測試流程,支持模塊化設計與動態配置,例如2025年發布的Ant Design Pro v6正式版提供動態菜單與權限控制教程,涵蓋項目搭建、路由配置、權限校驗等核心功能,助力開發者快速構建企業級后臺管理系統[30][35]。
在國際競爭力方面,Ant Design憑借龐大的社區支持、高頻迭代能力與多語言適配(如完善da_DK Form文案),成為全球前端開發者廣泛使用的組件庫之一。其持續的功能升級(如v5.13.0版本為Form、Cascader等組件新增variant屬性,優化Table隱藏列與Select最大可選配置)與問題修復(如修復Segmented、Checkbox等組件樣式問題),進一步鞏固了其在國際市場的技術競爭力[30][36]。
飛致云
MaxKB
MaxKB(Max Knowledge Brain)是飛致云推出的基于大語言模型(LLM)和檢索增強生成(RAG)技術的開源企業級智能體平臺,遵循GPLv3開源協議,GitHub Star總數超12萬,截至2025年5月全網累計下載量已突破50萬次,日均安裝下載量超過1000次,在企業知識管理、智能服務等領域展現出顯著價值[37][38][39]。
在企業知識管理中,MaxKB通過多項核心功能構建價值體系。其RAG檢索增強能力支持文檔上傳(如Markdown、PDF、DOCX等格式及ZIP打包上傳)、在線爬取、智能文本拆分(按標題層級拆分,單段最長4096字符)與向量化處理,可有效減少大模型幻覺,提升知識問答準確性[39][40]。內置工作流引擎與函數庫支持復雜業務流程編排,例如通過MCP工具調用節點和AI對話節點的Streamable HTTP協議支持,滿足智能客服、項目管理等場景的靈活需求[37][41]。同時,其零編碼嵌入能力可快速集成至網站、釘釘、企業微信、CRM等第三方系統,賦予外部系統智能問答能力,顯著提升企業內部知識獲取效率與客戶服務響應速度[38][41]。目前,MaxKB已在多領域落地應用,如高校領域的中國農業大學“小鵡哥”、東北財經大學“小銀杏”,醫療領域的解放軍總醫院智能問答系統,企業領域的中鐵水務知識庫助手、中核西儀研究院“西儀睿答”等[38]。
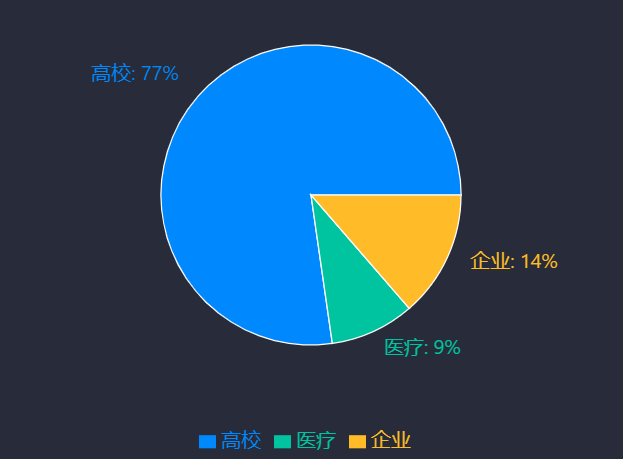
在大模型集成方面,MaxKB秉持“模型中立”原則,支持多類型大模型靈活對接與混合使用,包括本地私有大模型(如Llama 3、Qwen 2)、國內公共大模型(如DeepSeek、通義千問、智譜AI、百度千帆、Kimi)及國外公共大模型(如OpenAI、Azure OpenAI、Gemini),并支持動態切換模型供應商以適配不同場景需求[38][39][41]。其中,“DeepSeek+MaxKB”組合已在教育領域形成典型應用模式,例如天津外國語大學、北京建筑大學等17所高校及福建省廈門第六中學等中小學,將其應用于教學輔助、學術研究、校園服務、行政辦公、財務管理、招生等場景,通過DeepSeek的模型能力與MaxKB的知識管理能力協同,提升教育服務智能化水平[37]。
在2025年7月,MaxKB 還推出了v2(詳見 https://maxkb.cn/docs/v2/ )版本,支持了完整的 RBAC + 訪問控制,同時持續加大了開發的力度,企業數字化的業務范圍在不斷地擴大。
從飛致云開源生態構建策略來看,MaxKB與JumpServer(運維審計)、1Panel(服務器管理面板)等開源工具形成互補,共同完善DevOps生態布局。MaxKB聚焦企業知識管理與智能交互層,通過輕量化部署(支持Docker一鍵啟動及Ubuntu/CentOS離線部署,最低配置2C/4GB)、開放API及LDAP單點登錄等特性,降低與其他DevOps工具的集成門檻[39][40]。其系統架構采用Vue.js/Logicflow前端、Python/Django后端,集成Langchain與PostgreSQL/pgvector向量數據庫,技術棧與飛致云現有開源工具保持兼容性,為用戶提供從基礎設施管理到知識智能化應用的全鏈路開源解決方案支持[39]。
VAST AI
TripoSG/TripoSF
VAST在3D生成領域實現了多項技術突破,其核心項目TripoSG與TripoSF構建了高保真、高效率的3D內容生成基礎能力。TripoSG作為高保真3D形狀生成基礎模型,具備高保真生成(清晰幾何特征、精細表面細節及復雜結構網格)、語義一致性(準確反映輸入圖像語義與外觀)、強泛化性(支持真實圖像、卡通、草圖等多風格輸入)及魯棒性能(復雜拓撲輸入生成連貫形狀)等關鍵特性[42]。技術架構上,TripoSG率先將基于校正流(Rectified Flow, RF)的Transformer架構應用于3D形狀生成,融合跳躍連接增強設計,并通過獨立交叉注意力機制注入全局(CLIP)和局部(DINOv2)圖像特征;其先進變分自編碼器(VAE)采用符號距離函數(SDFs)進行幾何表示,引入SDF損失、表面法線引導及程函方程損失的混合監督訓練策略,基于200萬精心策劃的圖像-SDF對數據集訓練,實現小模型規模下的高性能[42][43]。TripoSF則作為新一代三維基礎模型,聚焦高分辨率三維重建和生成任務,提供SOTA級基礎組件,其VAE預訓練模型及推理代碼已同步開源[43]。此外,VAST的技術進展還體現在Tripo 2.0模型中,該模型采用融合DiT和U-Net的復合架構,實現10秒生成形狀幾何、10秒生成紋理及PBR,驗證了3D大模型的Scaling Law,在匿名測試中效果領先[44][45]。
在開源策略方面,VAST以“模型權重+推理代碼”的全鏈路開源模式顯著降低了3D創作行業門檻。2025年3月,VAST正式開源TripoSG與TripoSF,其中TripoSG的15億參數模型(非MoE版本,2048 token潛空間運行)權重、推理代碼及交互式演示通過GitHub和Hugging Face向AI社區開放,TripoSF的VAE預訓練模型及推理代碼亦同步發布[43]。此前,VAST已與Stability AI合作開源3D基礎模型TripoSR(0.5秒單圖生3D),并開源單張圖像生成3D場景模型MIDI、多視角圖像生成模型MV-Adapter,后續還計劃開源三維部件補全、通用三維模型綁定生成等模型,形成覆蓋3D生成全流程的開源體系[43][45]。這一策略使開發者與創作者可直接獲取高性能工具,減少技術壁壘,推動3D內容創作從專業領域向大眾普及。
| 項目名稱 | 發布時間 | 技術特性 | 開源平臺 |
|---|---|---|---|
| TripoSR | 2024年3月 | 0.5秒完成單圖生3D模型 | GitHub, Hugging Face |
| MIDI | 2024年 | 單張圖像生成3D場景模型 | GitHub |
| MV-Adapter | 2024年 | 多視角圖像生成模型 | GitHub |
| TripoSG | 2025年3月 | 15億參數3D生成模型,圖像到3D生成任務領先 | GitHub, Hugging Face |
| TripoSF | 2025年3月 | 高分辨率三維重建基礎組件 | GitHub, Hugging Face |
| 三維部件補全模型 | 2025年4月 | 三維部件補全技術 | 計劃開源 |
| 模型綁定生成模型 | 2025年4月 | 通用三維模型綁定生成 | 計劃開源 |
注:加粗項目為2025年核心開源版本
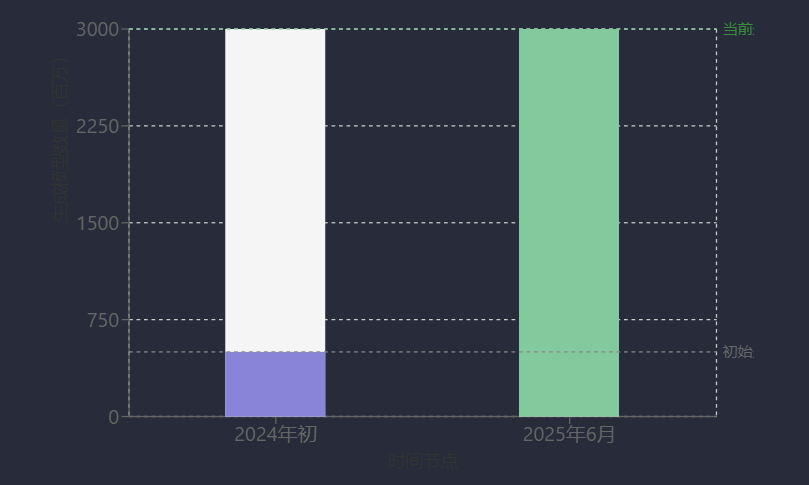
3D內容生成在多場景展現出顯著商業化潛力,VAST已通過產品矩陣實現規模化應用。在應用場景上,其技術支持游戲、動畫、3D打印、工業設計等領域的二次編輯,以及骨骼綁定、動作生成、場景生成等動態內容創作[44]。產品層面,大眾級創作工具Tripo累計生成超3000萬個3D模型,用戶超300萬;針對PGC場景的一站式3D工作臺Tripo Studio自2024年下半年推出后,截至2025年6月收入達60萬美元/月[46]。當前VAST占據超70%的3D AI內容生成市場份額,服務300多大客戶及2萬多中小客戶,目標構建3D UGC內容平臺,推動3D創作大眾化[45]。投資機構普遍看好其商業化前景,如達晨財智認為文生3D是“新文明”最后一環,看好2C方向改變生活方式;春華創投則期待其探索更多3D創作可能[47]。
競爭格局方面,3D生成領域呈現“初創企業領跑、巨頭加速入局”的態勢。VAST憑借技術先發優勢和開源生態構建,目前處于行業領先地位,但其面臨抖音、騰訊、阿里等互聯網巨頭發力3D大模型的競爭壓力,行業整體仍需應對商業化路徑驗證的考驗[46]。不過,VAST核心團隊背景深厚(如CTO梁鼎為清華博士,50+論文、100+專利;首席科學家曹炎培為清華博士,騰訊ARC實驗室前領導),且已完成數億元融資,為其技術迭代與商業化拓展提供支撐[44][47]。
技術領域專題分析
人工智能與大模型
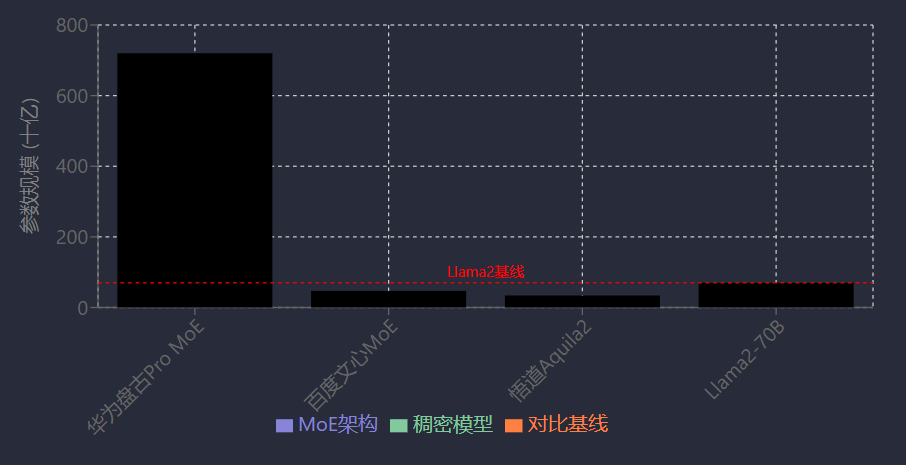
國內大模型開源生態呈現多維度競爭格局,頭部科技企業與創新團隊共同推動技術多樣化發展。華為、百度等企業于2025年6月集中開源核心模型體系:華為首次開源盤古大模型體系,涵蓋70億參數稠密模型、720億參數Pro MoE混合專家模型及昇騰推理技術體系;百度同步開源文心大模型4.5系列的10款模型,包含47B、3B激活參數MoE模型與0.3B參數稠密模型,并全量開放預訓練權重與推理代碼[14]。阿里通義團隊則通過長期積累形成規模優勢,已開源200多款模型,其通義千問Qwen衍生模型數量超13萬,下載量突破3億次[15]。此外,悟道·天鷹Aquila大語言模型系列升級至Aquila2,新增340億參數成員,其開源全家桶包含基礎模型、對話模型、SQL模型及語義向量模型等,在22項綜合評測中超越Llama2-70B等同類模型[48];VAST AI聚焦3D大模型領域,Tripo系列(Tripo 1.0、Tripo 2.0)通過優化生成速度與質量推動行業技術收斂[44];DeepSeek于2025年初開源的R1推理模型及Janus Pro多模態模型,兩周內GitHub Star新增超15萬,覆蓋185個國家和地區開發者[49]。
| 企業 | 開源模型 | 參數規模 | 技術特點 | 來源 |
|---|---|---|---|---|
| 華為 | 盤古大模型體系 | 70億參數(稠密)<br>720億參數(Pro MoE) | 首次開源大模型體系,含昇騰推理技術 | [14] |
| 百度 | 文心大模型4.5系列 | 10款模型<br>含47B/3B MoE<br>0.3B稠密 | 全量開放預訓練權重與推理代碼 | [14] |
| 阿里 | 通義系列 | 200+開源模型<br>13萬+衍生模型 | 通義千問Qwen下載量超3億次 | [15] |
| 悟道 | Aquila2系列 | 340億參數(34B) | 22項評測領先Llama2-70B,支持16K上下文 | [48] |
| VAST | Tripo系列 | - | 10秒生成3D模型,累計生成3000萬+模型 | [44] |
| DeepSeek | R1+Janus Pro | - | 兩周新增Star超15萬,覆蓋185國 | [49] |
技術路線方面,國內大模型呈現MoE架構與稠密模型并行發展態勢。MoE(混合專家模型)以其參數規模優勢成為重要方向,如華為盤古Pro MoE模型達720億參數,百度文心4.5系列包含47B激活參數MoE模型,通過動態激活專家網絡提升性能[14][15]。稠密模型則通過算法優化實現高效性能,例如Aquila2-34B基座模型以僅1/2參數量、2/3訓練數據量超越Llama2-70B,其創新的NLPE(非線性位置編碼)和分段式Attention算子,將上下文長度擴展至16K(34B-16K版本在LongBench任務中接近GPT-3.5),并支持32K長度續寫[48]。此外,3D大模型領域探索3D+2D融合技術路線,如VAST的Tripo系列支持10秒生成帶紋理及PBR的3D模型[44]。
國際市場影響力方面,國內開源大模型通過主流平臺逐步拓展全球覆蓋。悟道·天鷹系列模型在HuggingFace平臺(huggingface.co/BAAI)開源,其AquilaChat2-34B被稱為當前最強開源中英雙語對話模型[48]。DeepSeek的R1模型開源10天進入中國OpenRank Top 62位,企業榜單全球排名第86位,美國開發者占比15.7%(僅次于中國的24.4%),主要參與使用與技術觀望[49]。阿里通義千問Qwen衍生模型下載量超3億次,顯示其在國際開發者社區的滲透力[15]。
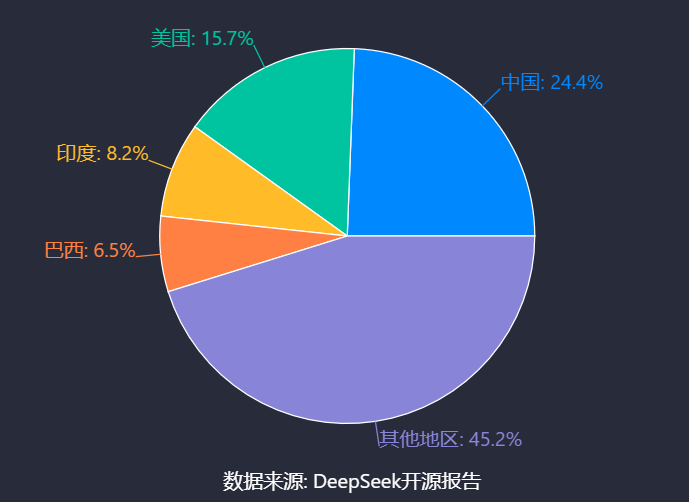
開源模式顯著推動AI技術普惠與產業落地。在技術普惠層面,企業通過開放核心能力降低應用門檻:華為、百度全量開放模型權重與推理代碼,VAST開源threestudio、Wonder3D等算法框架,推動3D行業技術收斂[14][44];GitHub熱門項目如awesome-deepseek-integration(聚合300+工具)、dify(LLMOps平臺)等覆蓋AI開發全鏈路需求[50]。產業落地方面,開源工具與模型已在多領域實現規模化應用:MaxKB基于LLM+RAG技術,支持多模型集成與業務邏輯編排,應用于智能客服、企業知識庫[38][40];騰訊Angel機器學習平臺處理速度較LightLDA提速5倍以上,其聯邦學習平臺Angel PowerFL支持千億級數據計算,已落地金融、醫療行業[51];VAST的Tripo2.0推動3D內容創作工具發展,預示下一代互聯網3D交互場景的普及可能[47]。
數據庫
近年來,中國國產分布式數據庫在技術創新與行業應用中取得顯著進展,形成以OceanBase、TiDB、openGauss等為代表的多元產品體系,并在金融、運營商等核心領域加速替代進程。開源模式通過社區協作與生態共建,成為推動技術迭代與市場滲透的關鍵力量。
技術優勢與特性演進
國產分布式數據庫在架構設計、多模態處理及易用性優化上展現核心競爭力。OceanBase通過持續產品迭代強化分布式能力,其OCP 4.3.5-CE社區版支持OBKV-Redis監控、180天數據恢復區間等20余項改進,并推出桌面版降低部署門檻,集成向量能力與數組函數擴展功能[52][53]。TiDB作為原生分布式關系型數據庫,憑借HTAP架構與向量化計算引擎提升性能,支持16383維向量存儲及HNSW索引算法,可構建RAG解決方案滿足多模態數據需求,2025年v8版本進一步針對金融場景優化,將I/O抖動影響降低、更新性能提升500%[24][26][28]。openGauss 7.0.0版本引入oGRAC多寫架構與DataVec向量數據庫能力,通過存算分離架構實現多節點并行訪問與RAG技術支持,結合輕量級鎖與全局頁級MVCC技術提升高并發處理能力[54];時序數據庫領域如TDengine以高效物聯網數據處理為特色,GitHub星標達13.9K,集群版開源后連續6天全球趨勢榜第一[55];圖數據庫Apache HugeGraph則支持數千億頂點邊存儲與Gremlin/Cypher查詢,實現OLTP+OLAP融合[16]。
在金融與運營商等核心行業的替代進展
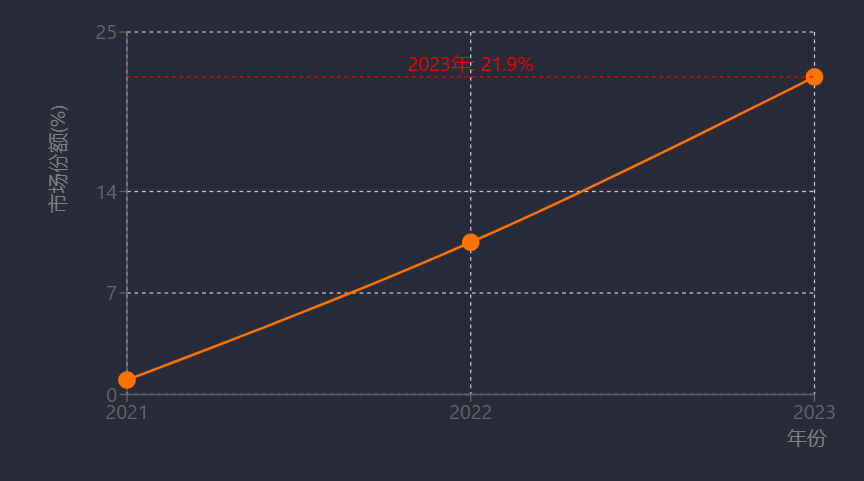
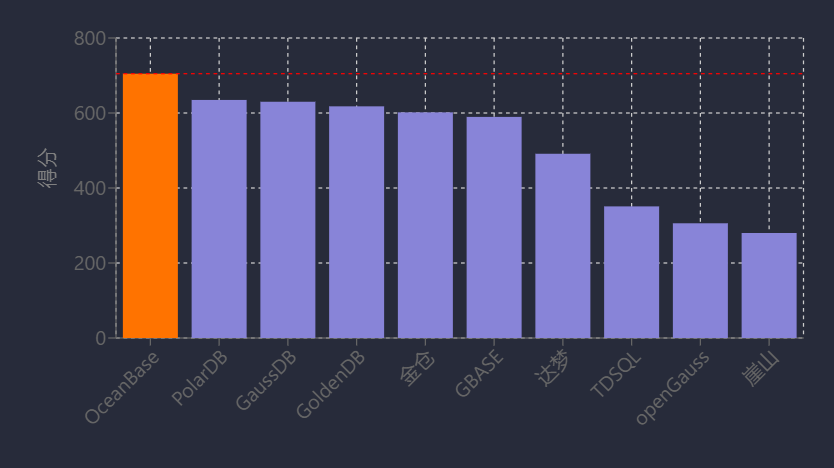
國產數據庫在關鍵行業的替代已從試點走向規模化應用。金融領域,騰訊云TDSQL中標招商銀行2025-2028年度許可采購項目,其分布式事務處理專利保障金融交易穩定性;OceanBase落地東莞銀行項目招標預算1110萬元,TiDB通過性能優化切入核心交易場景[56][57]。運營商領域替換成效顯著:中國移動采購達夢、TiDB等五類數據庫共2582套,青海公司數智云原生系統100%替換為自研磐維數據庫,部署21節點集群將數據遷移時長縮短至50分鐘;中移動全域核心系統規模上線openGauss,民生銀行亦實現openGauss核心系統規模化部署[54][56][58]。政務與能源領域,金倉數據庫中標新疆移動自主可控替換項目及寧波市司法局26套系統采購,國能集團基于openGauss開發CERDB支撐云平臺與電商系統[23][54]。市場數據顯示,2023年本地部署關系型數據庫外資廠商市占率降至37.1%;openGauss市場份額從2021年1%躍升至2023年21.9%[54][56];2025年4月中國數據庫排行榜中OceanBase以領先第二名近70分登頂,PolarDB集成大模型實現AI算力擴展,GaussDB、金篆信科GoldenDB等進入前五[23]。
開源模式對生態建設的促進作用
開源社區通過技術共享與開發者賦能加速生態擴張。OceanBase推出“DBA實戰營在線體驗平臺”,提供零門檻集群管理(租戶創建、副本擴縮容)、故障演練(節點宕機切換)等實驗環境,并復現金融電商典型用例;發起“隱藏技能挖掘計劃”鼓勵創意應用開發,2025年社區版本下載量增長超25%[54][59][60]。openGauss采用Mulan PSL-2.0許可證,opengauss-server倉庫吸引109名貢獻者,通過92個子倉庫構建連接器、文檔等完整生態,海量數據基于其開發Vastbase G100并實現醫療核心系統落地[54][61][62]。TiDB社區活躍度位居前列,開展多地實踐分享活動并入選《2025年度中國數據庫優秀廠商圖譜》,其云原生工具鏈(TiProxy、TiUP)與Apache Spark等組件集成完善[24][63]。遷移工具生態同步發展:OMS V4.2.8-CE社區版支持MySQL、TiDB等到OceanBase的全量/增量遷移,并新增Hive數據寫入能力[64]。開源模式不僅降低技術門檻,更通過人才培養(如OceanBase OBCA/OBCP認證、TiDB高校特訓營)與伙伴合作(OceanBase“伙伴主導戰略”)推動產業協同,2024年國內活躍開源數據庫項目已覆蓋關系型(openGauss)、時序(TDengine)分布式(TiDB)等全品類[25][56][59]。
操作系統
開源鴻蒙(OpenHarmony)作為面向物聯網場景的開源操作系統,其差異化競爭力核心在于分布式架構、彈性部署能力及統一數字底座技術。技術特性方面,其通過KaihongOS實現“彈性部署”與“軟總線”技術,支持跨設備異構互聯與算力共享;HiHopeOS提供可視化與自動化探測功能,LightBeeOS則擴展了操作范圍能力,形成多場景適配的技術體系[1][12]。此外,原子化服務架構支持低代碼開發,端到端安全防護(設備認證、數據加密、指令校驗)滿足行業安全標準,進一步強化了其技術優勢[65]。
在打破“數據孤島”方面,開源鴻蒙通過分布式軟總線與統一數據模型實現設備跨端協同。以智慧樓宇場景為例,福州建總大廈基于KaihongOS連接3195個異構設備(涵蓋空調、照明、安防等十多個子系統),形成“超級設備”管理模式,解決了硬件協同與數據割裂問題,實現能耗管理、人員跟蹤等19個場景的智能調度[4][5][65]。建筑開源鴻蒙操作系統還通過標準化CoAP通信協議、設備發現注冊機制及統一數據模型(定義設備關鍵信息、服務、事件和特征),為設備互聯與數據互通提供技術支撐[8][66]。
推動產業數字化進程中,開源鴻蒙已在工業、電力、水利、智慧城市等多領域實現深度應用。工業領域,天罡智能基于開源鴻蒙開發國內首個工業機器人實時操作系統iiRobotOS,支持多機器人統一編程與復雜協作;龍芯生態伙伴推出“龍架構+開源鴻蒙”工業控制操作系統,包括華夏天信礦鴻操作系統(MineHarmony)、中電啟明星星鴻EOS操作系統及華龍迅達華龍工業操作系統(HualongOS),后者實現工業控制設備互聯互通與“一次開發、多端部署”[9][10][11][67]。此外,中國南方電網“電鴻”、蘇州水利智慧聯調聯控等項目也驗證了其在能源、市政等領域的數字化價值[9]。
與Android、iOS等面向消費電子的移動操作系統不同,開源鴻蒙聚焦物聯網與工業場景,其滲透潛力呈現“工業領域快速拓展、消費電子場景化突破”的特點。工業領域,依托全棧自主體系與高安全性,已形成從機器人控制到工業互聯網的完整解決方案,吸引誠邁科技等企業參與生態建設[11]。消費電子領域,雖暫未大規模進入手機市場,但其在智慧樓宇、智能家居等場景通過原子化服務與跨設備協同構建差異化體驗,如《建筑開源鴻蒙互聯參考架構》白皮書支撐智能建造、智慧工地等場景創新,未來有望通過“超級設備”模式向消費電子延伸[3][65]。生態層面,超300家伙伴加入電鴻物聯產業鏈,鴻湖萬聯與海思等芯片廠商深化協作,為其跨領域滲透提供底層支撐[1]。
前端與低代碼
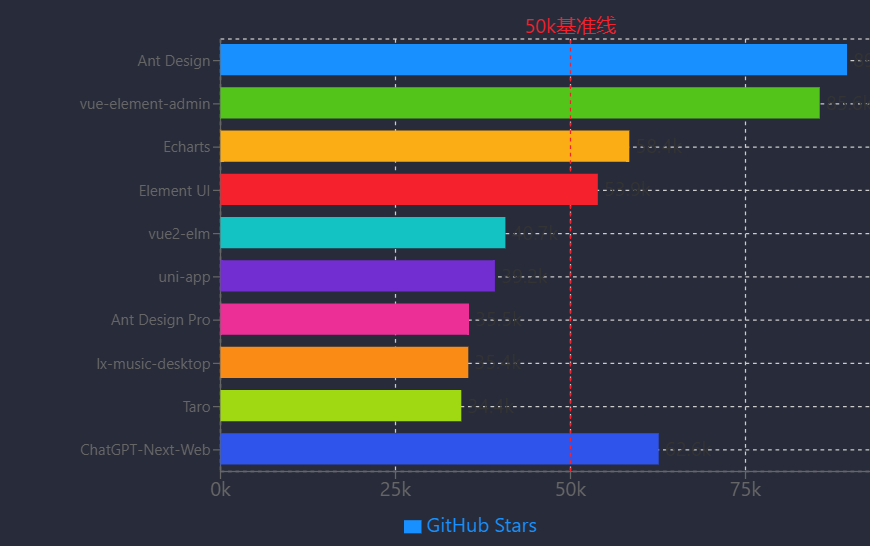
前端框架與低代碼平臺作為企業數字化轉型的關鍵技術支撐,通過組件化、模塊化及可視化開發模式顯著提升開發效率,推動業務快速迭代。在前端框架領域,以Ant Design系列為代表的開源項目形成了完整的技術生態:Ant Design作為企業級React UI組件庫,不僅提供豐富的基礎組件,還通過實驗性組件探索低代碼等新興場景,為界面開發提供高效解決方案[30];其衍生框架Ant Design Pro 5.0進一步整合預置模板與最佳實踐,支持數據分析儀表板、復雜表單處理等核心業務場景,并具備多設備響應式顯示與國際化部署能力,可快速搭建企業級Web應用[34]。2024年國產開源前端項目Top 10(按GitHub Star數排序)顯示,Ant Design(89.5k)、vue-element-admin(85.6k)、Echarts(58.4k)等項目廣泛覆蓋React/Vue技術棧、數據可視化及跨端開發等領域,其中uni-app(39.2k)支持多端發布,Taro(34.4k)實現跨框架開發,通過技術標準化降低協作成本,提升大規模應用開發效率。
低代碼平臺通過可視化拖拽、預構建模塊與AI能力融合,進一步降低開發門檻,賦能企業數字化轉型。JeecgBoot AI低代碼平臺整合人工智能技術,提供拖拽式操作與預構建AI模塊,支持零代碼快速搭建ERP、CRM、OA等復雜業務系統,核心功能涵蓋自動化流程、數據集成與一鍵部署,顯著降低開發成本并提升效率,應用場景覆蓋智能客服、圖像識別等領域[68]。GitHub開源低代碼項目中,NocoBase(11.2k Star)基于插件架構與數據模型驅動設計,支持私有部署與數據密集型業務系統開發;APITable(12.6k Star)以API為中心,實現6000+應用集成與數據流自動化;LowCodeEngine(14.2k Star)由阿里巴巴前端團隊開發,通過模塊化設計與拖放開發模式,提供豐富UI組件庫支持[69]。這些平臺通過簡化開發流程,使非專業開發者也能參與應用構建,加速企業數字化落地。
開源生態在標準化與定制化之間的平衡是技術可持續發展的關鍵。Ant Design系列通過持續迭代實現標準化與靈活性的統一:Ant Design Blazor 1.1.0通過參數標準化(字符串轉枚舉)提升代碼可維護性,同時支持Icon自定義SVG與Typography組件升級,增強設計自由度[32];Ant Design 5.13.0版本優化Tabs、Table等核心組件的穩定性與性能,擴展形態變體并強化國際化支持,既保障組件行為一致性,又滿足多樣化業務場景需求[36]。低代碼平臺方面,LowCodeEngine的模塊化設計與NocoBase的插件架構,均以標準化核心框架為基礎,允許開發者通過插件擴展功能,實現“基礎能力標準化、業務需求定制化”的協同模式,為企業提供靈活且可控的開發工具鏈。
社區與生態建設
社區活躍度分析
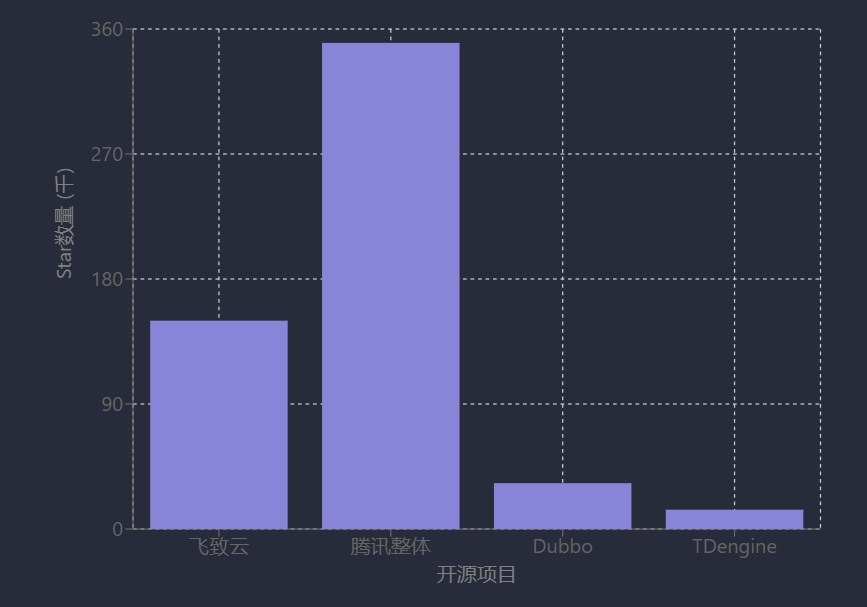
國內開源項目社區活躍度呈現多樣化發展態勢,核心量化指標(如GitHub Star數、開發者規模、下載量等)顯示部分項目已具備較高的社區基礎。例如,飛致云旗下開源項目GitHub Star總數超過150,000個,其1Panel應用商店2025年5月下載量達200,502次;RT-Thread聚集全球近30萬開發者,吸引近萬家企業客戶[37][70]。騰訊整體開源項目超120個,Star數累計超35萬,曾進入GitHub周榜前十,其中Angel項目獲6200 Star,超100家公司和機構開發者參與生態建設[51]。TDengine、DeepSeek等項目亦表現活躍,TDengine在GitHub上擁有13.9K Star、3.6K Fork,日克隆代碼人數超100;DeepSeek新增Star超15萬(覆蓋185個國家和地區),活躍開發者1679人,中國、美國、印度為主要來源[49][55]。
數據來源: [
“https://juejin.cn/post/7510077145404063807”,
“https://blog.csdn.net/tencent__open/article/details/116725184”,
“https://blog.csdn.net/u012562943/article/details/108376954”,
“https://cloud.tencent.com/developer/article/1743791?areaSource=106000.18”
]
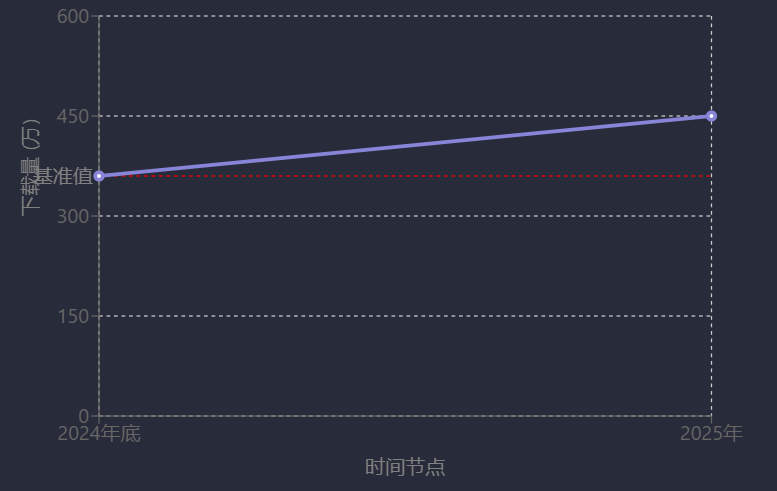
在垂直領域,AI與數據庫項目社區活躍度尤為突出。通義千問Qwen在HuggingFace社區2024年全球模型下載量中占比超30%,總量超3億,衍生模型數量超13萬[15];openGauss社區版本下載量從2024年底的360萬增長至2025年的450萬,漲幅超25%[54];MaxKB日均下載量超1000次,廣泛應用于智能客服、教育等領域[40]。
數據來源: [“https://tech.sina.cn/2025-07-14/detail-inffmtuu4812596.d.html”]
企業主導的開源項目通過多樣化運營模式提升社區活力。OceanBase社區構建了“用戶組+技術討論+激勵活動”的立體運營體系:通過OUG用戶組(OceanBase User Group)策劃線上線下聚會,SIG前沿哨(Special Interest Group)開展AI4DBA主題交流會等技術討論,并發起“隱藏技能挖掘計劃”等活動,邀請開發者分享創意應用,設置社區周邊獎勵[53][71]。同時,該社區持續推出學習資源,如2024年升級《DBA從入門到實踐》、2025年推出“DBA實戰營”,通過場景化教學和認證獎勵提升用戶參與度[60]。Dubbo作為阿里主導的微服務框架,社區運營以技術迭代和外部貢獻為核心,擁有33k stars、21k forks,57位committer及379位contributor,外部貢獻占比超阿里內部,全球微服務框架排名第五,近年3.x系列通過多個重要版本增強功能與性能[17][72]。此外,GoldenDB通過開放社區推動生態落地,DolphinDB推出技能認證高校特訓營,軟通動力累計向OpenHarmony社區貢獻代碼超100萬行,均體現企業在社區建設中的主動投入[12][23]。
與國際項目相比,國內項目在社區活躍度上仍存在差距。以微服務領域為例,Spring Cloud社區活躍度顯著優于Dubbo,而Dubbo又優于EJB,社區活躍度直接影響問題解決速度和框架完善度[19][73]。盡管部分國內項目通過企業資源支持實現了規模增長,但在社區自驅力、全球開發者參與廣度及問題響應效率等方面,與Kubernetes等國際頂級項目相比仍有提升空間。
開源生態合作
開源生態合作是推動技術創新與產業規模化應用的核心驅動力,主要體現在產學研協同創新及全球化合作兩大維度。在產學研協同方面,多方主體通過資源整合與聯合實踐加速技術迭代。例如,中國計算機學會主辦的GLCC 2025編程夏令營聯合阿里、百度等企業及高校,圍繞Apache HugeGraph、隱語SecretFlow等真實開源項目開展功能改進與開發,不僅為項目注入創新活力,還通過獎金激勵與實習通道構建人才培養閉環[16]。騰訊與北京大學共建“協同創新實驗室”,在人工智能、大數據領域產出的Angel項目兼顧工業可用性與學術創新性,并成功捐贈至LF AI基金會成為國內首個頂級項目,彰顯了產學研融合對技術成果轉化的推動作用[51]。此外,鴻湖萬聯與高校共建實習基地,進一步打通“科研-實踐-人才”鏈路,為開源生態持續輸送專業力量[12]。
企業間的跨領域技術協同是開源生態落地的關鍵支撐。在操作系統領域,福州市城鄉建總集團與深開鴻基于開源鴻蒙打造全國首個智慧樓宇樣板點,通過“開鴻安全數字底座”實現異構設備跨端互聯,沉淀19項成熟經驗并形成四大模塊化解決方案,為建筑行業智能化提供可復用范式[5][65]。華為云與萬安智能簽約推出基于OpenHarmony的智能建筑解決方案,通過空間單元智控器與場景交互終端實現IoT設備全域協同,展現龍頭企業技術共享對生態集群構建的引領作用[13]。數據庫領域,openGauss社區與中移動、國能集團等企業合作,推動數據庫技術在運營商、能源等關鍵行業的應用實踐;GBase與新華三聯合推出全國產化基礎架構解決方案,加速國產化技術替代進程[23][54]。此外,Dubbo通過集成Nacos、Prometheus、Istio等工具構建完整服務治理生態,TiDB整合Spark、Kafka等大數據組件,均體現了開源項目通過技術協同提升場景適配能力的特點[24][72]。
在全球化合作中,國內開源項目正積極融入國際生態,但仍面臨影響力提升的挑戰。技術輸出層面,VAST AI與Stability AI合作推出開源3D模型TripoSR,推動行業技術收斂;TiDB通過開源模式觸達全球用戶,加速產品打磨與市場拓展[27][44][45]。社區建設層面,TDengine吸引超50名外部貢獻者,openGauss明確提出與全球開源組織深度合作的愿景,體現開放協作姿態[55][57]。然而,當前合作多集中于技術應用層面,在核心標準制定與國際社區主導權方面仍需突破。未來,隨著開放原子開源基金會等組織推動超300家伙伴共建電鴻物聯產業鏈,國內開源生態需進一步平衡本土化創新與全球化協同,加速形成“供給-需求”商業閉環,推動技術成果產業化落地[1][9]。
挑戰與展望
當前挑戰
國內開源軟件在快速發展的同時,面臨技術攻堅、生態構建及商業模式三大維度的核心挑戰,需系統性應對以實現可持續發展。
在技術攻堅層面,具體項目的技術瓶頸與共性技術難題并存。部分開源項目存在場景化能力不足問題,例如MaxKB在復雜專業領域知識的準確性和深度有待提升,且存在系統集成兼容性問題;Dify的性能表現高度依賴底層模型,復雜任務需結合微調優化,同時面臨API調用成本高的壓力[41]。分布式系統運維復雜度突出,TiDB在大規模集群管理中面臨較高運維難度[24]。基礎軟件領域,3D生成模型受限于3D數據匱乏(需通過長期積累獲取)及市場需求未完全驗證(如Meta VR部門虧損、Vision Pro出貨量不及預期、騰訊字節裁撤XR部門)[74]。此外,安全合規與版本維護構成普遍挑戰,《2025 State of Open Source》報告顯示,保持軟件更新、滿足安全性和合規性要求、維護停產(EOL)版本是使用開源軟件的三大核心難題,以CentOS 7為例,其于2024年6月EOL后,40%的大型企業仍在使用,而28%的受訪者無針對其漏洞的修復計劃[46]。行業應用中,國內銀行核心系統替換傳統集中式數據庫時,需應對技術成熟度、穩定性保障及監管合規的多重考驗[23]。
生態構建方面,社區活力與協作機制存在明顯短板。部分項目社區活躍度不足,如Dubbo面臨入門門檻高、官網資料不全、源碼級分享少、部署復雜等問題,制約開發者參與度[21]。用戶體驗與文檔體系不完善,OceanBase社區反饋桌面版安裝崩潰、OCP功能缺陷、文檔內容不一致等問題,反映開源生態在用戶支持環節的薄弱[46]。工具鏈協同與DevOps落地困難,45%的企業因使用超5種工具導致工具鏈碎片化,形成信息孤島;32%的企業因開發與運維團隊目標分歧引發文化沖突,僅18%的企業建立核心指標持續監控體系,自動化工具鏈“偽集成”(如權限沖突導致30%構建任務失敗)和持續反饋機制缺失(僅25%企業建立用戶反饋通道)進一步加劇生態割裂[75]。跨場景協同障礙顯著,城市治理領域因萬物互聯場景下硬件協議各異、數據孤島林立,導致運營維護成本高企、響應效率低[5][65]。
商業模式層面,市場競爭與商業化路徑面臨雙重壓力。垂直領域競爭加劇,如VAST在3D大模型領域需應對抖音、騰訊、阿里等互聯網巨頭的擠壓,行業整體面臨商業化驗證考驗[46]。開源模式下的競爭風險凸顯,開源大模型可能導致其他企業或開發者基于其進行二次開發,形成與內部業務競爭的產品,需通過持續技術優化維持優勢[15]。ToB市場對綜合能力要求嚴苛,項目成敗不僅取決于產品能力,還依賴交付能力及客戶需求理解深度[15]。資本市場環境趨緊,盡管優質AI企業仍能獲得匹配價值的資金,但整體投資標準更趨嚴格,對開源項目的商業化可持續性提出更高要求[45]。
針對上述挑戰,建議從三方面推進優化:政策層面加強對開源安全合規、版本維護及人才培養的扶持,例如設立專項基金支持EOL版本補丁開發與企業遷移;社區層面建立多元化激勵機制,提升開發者參與度,完善文檔與用戶反饋閉環,增強社區活力;產業層面推動跨行業合作,打破數據孤島與硬件協同壁壘,通過聯盟共建降低API調用成本,探索開源項目與垂直行業需求的深度融合路徑。
未來展望
在AI時代與數字經濟深度融合的背景下,中國開源軟件產業正迎來歷史性發展機遇。AI技術的滲透推動開源生態向智能化、高效化演進,例如AI與數據庫的深度融合將使數據底座更高效、智能和開放,基于數據庫的行業解決方案及人才培養成為產業發力重點[54];AI驅動的DevOps自動化(如智能測試用例生成)與低代碼工具則進一步降低技術落地門檻[75]。同時,數字經濟的擴張催生新需求,3D創作市場規模預計達2-3萬億元,VAST等項目通過降低創作成本推動3D內容大眾化[45],而中國開源開發者數量已居全球第二且增長最快,為GitHub貢獻550萬個項目,為產業創新注入持續動力[51]。
重點領域突破方向清晰顯現。工業軟件領域,華龍訊達依托開源鴻蒙核心優勢,推動工業操作系統創新,助力工業自主創新[10];龍芯則布局打印機自研芯片,覆蓋激光、噴墨等系列化產品,完成多操作系統適配[67]。物聯網與智慧城市領域,開源鴻蒙的分布式能力將實現樓宇、道路及城市基礎設施互聯互通,形成"超級手機"級網絡,衍生交通調度、能源共享等場景,數字孿生與AI交互技術的融合更推動智慧樓宇模式復制推廣[5][6];機器人領域將大量采用鴻蒙系統,統一互聯標準以加速研發、降低成本[23]。數據庫領域,openGauss計劃五年內聯合伙伴在核技術、AI及"四高"特性上突破[54],OceanBase力爭提升合作伙伴業務占比至70%,PolarDB轉型AI計算核心平臺[23],TiDB則深耕醫療、金融場景以強化性能與穩定性[24][28]。操作系統領域,理想星環OS向"空間智能操作系統"進化,軟通動力深化AI與操作系統融合以推進全球化[12][70]。此外,3D與空間智能領域因Vision Pro等設備普及需求增長,AI生產力提升與李飛飛World Labs的空間智能模型將加速技術落地[74];云原生方向,Dubbo將加強Kubernetes支持、多語言SDK開發及性能優化[72];AI生態中,DeepSeek重構全球開源AI競爭格局,MaxKB、Dify等LLM框架深化企業知識管理應用[41][49]。
生態共建與全球化布局是產業發展的關鍵戰略。生態層面,需構建開放協同的技術標準體系與完善認證體系,如華為在建筑開源鴻蒙中倡議的技術共建、標準共研和生態共享[2][8];開放原子開源基金會持續推動開源項目落地與技術成果產業化,加速產業轉型升級[1][9]。全球化層面,中國基礎軟件需突破全球市場占比不足10%的現狀,力爭進入細分領域前三以增強國際影響力[55],同時依托開源社區力量,推動openGauss等項目生態繁榮,讓中國科技公司及開發者為全球開源貢獻更多力量[51][54]。



一文解決】var let const)










——鏈接預測)




