任務描述
今天收到一個任務,在知網上,把一位專家所有的論文全都下載下來,要保存為PDF格式。
知網不支持批量導出PDF格式論文。一個一個下載PDF,太繁瑣了。
解決方案:找到一個油猴腳本,這個腳本可以從知網批量導出論文。
腳本安裝
首先,使用 chrome 瀏覽器安裝油猴,https://www.tampermonkey.net/。
點擊導航欄的 用戶腳本,在下面的搜索框輸入 “知網”。
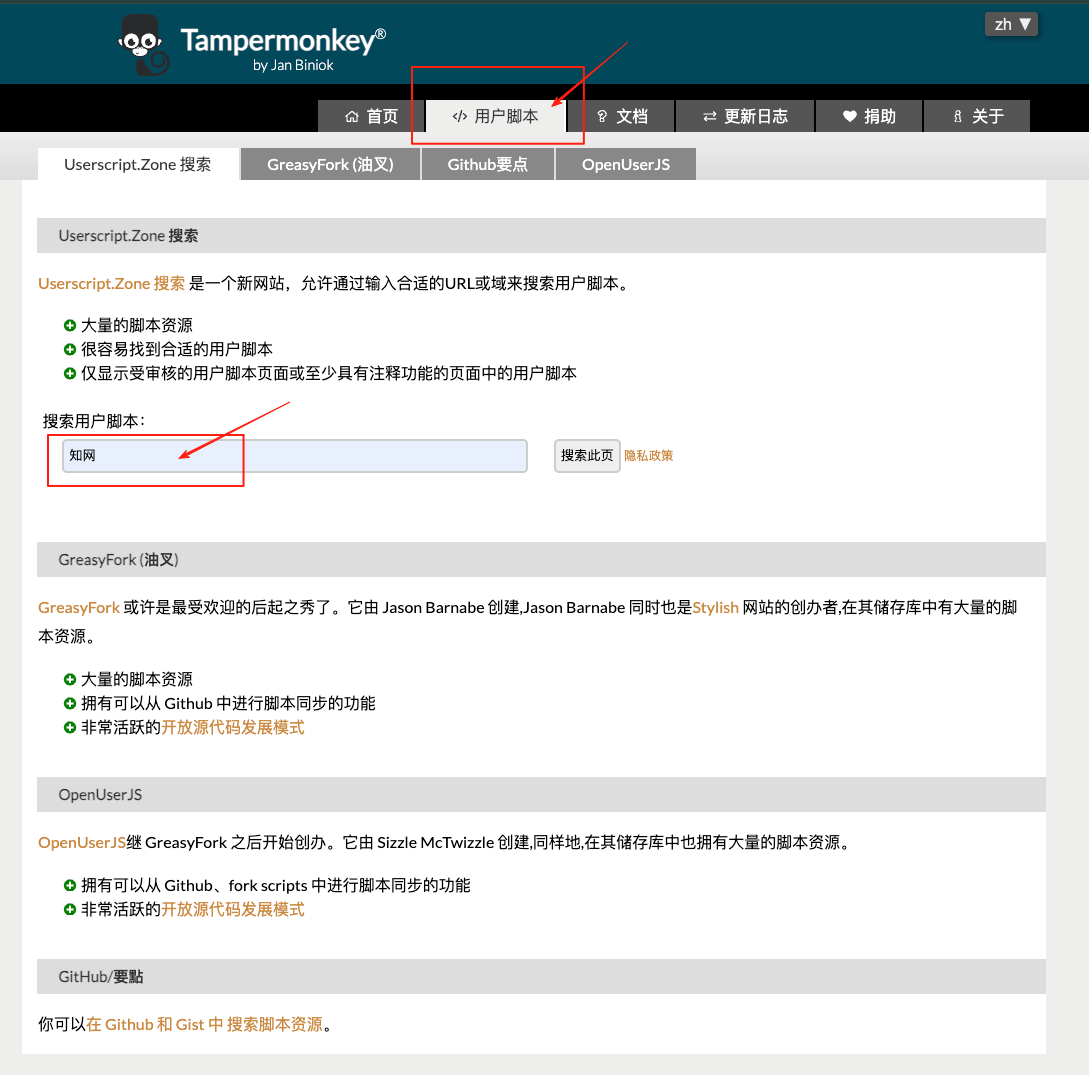
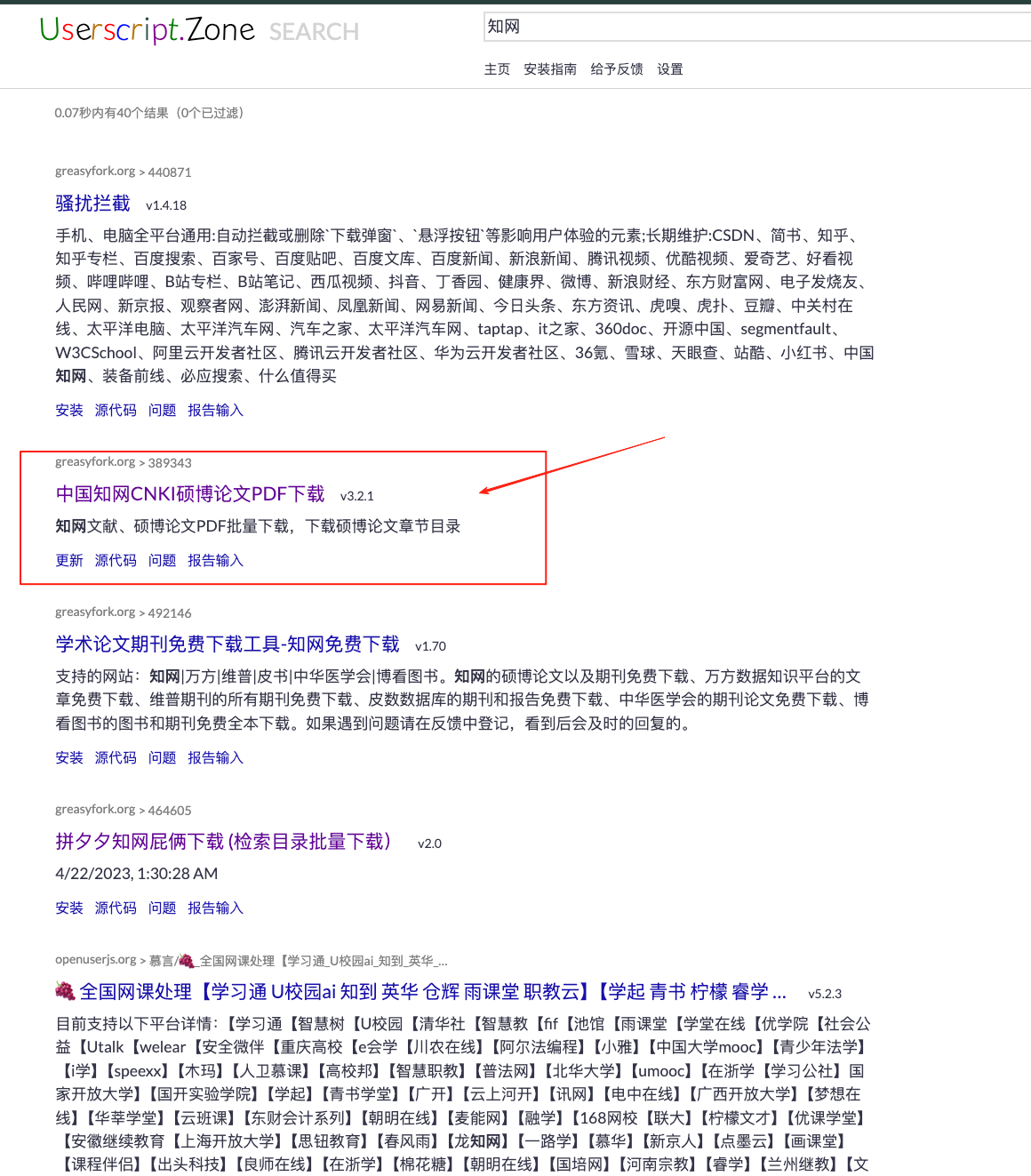
下圖是這個腳本的介紹,最后更新日期是24年12月。該腳本支持了PDF的批量下載。
腳本地址

若你下載了不需要的腳本,在這里刪除:
瀏覽器的設置
批量下載論文的PDF格式的時候,會頻繁彈出窗口,所以要運行瀏覽器彈出窗口。

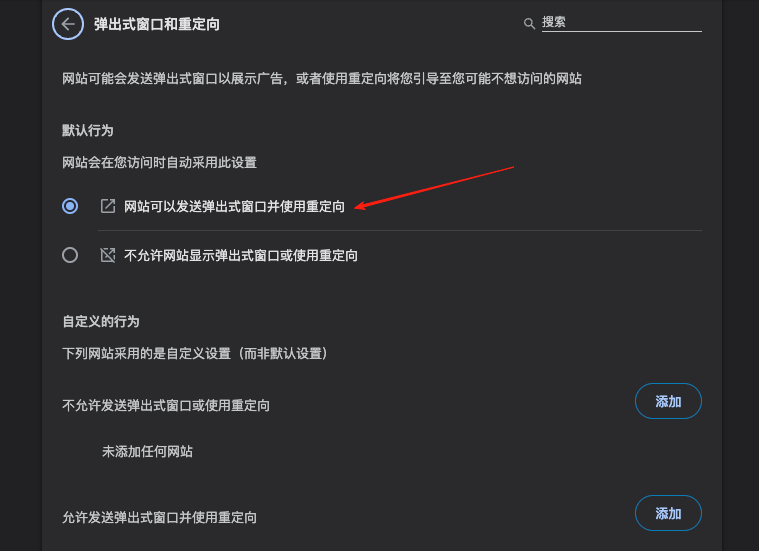
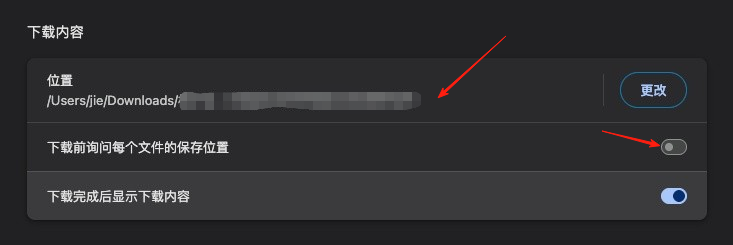
瀏覽器更改默認下載路徑,記得后面再改回來:
這樣就可以把論文直接下載到一個文件夾里面。
批量導出PDF過程
在搜索作者的時候,可能有作者會同名,要為作者選擇正確單位。
腳本安裝后,在知網的右側,會出現一個批量下載的按鈕
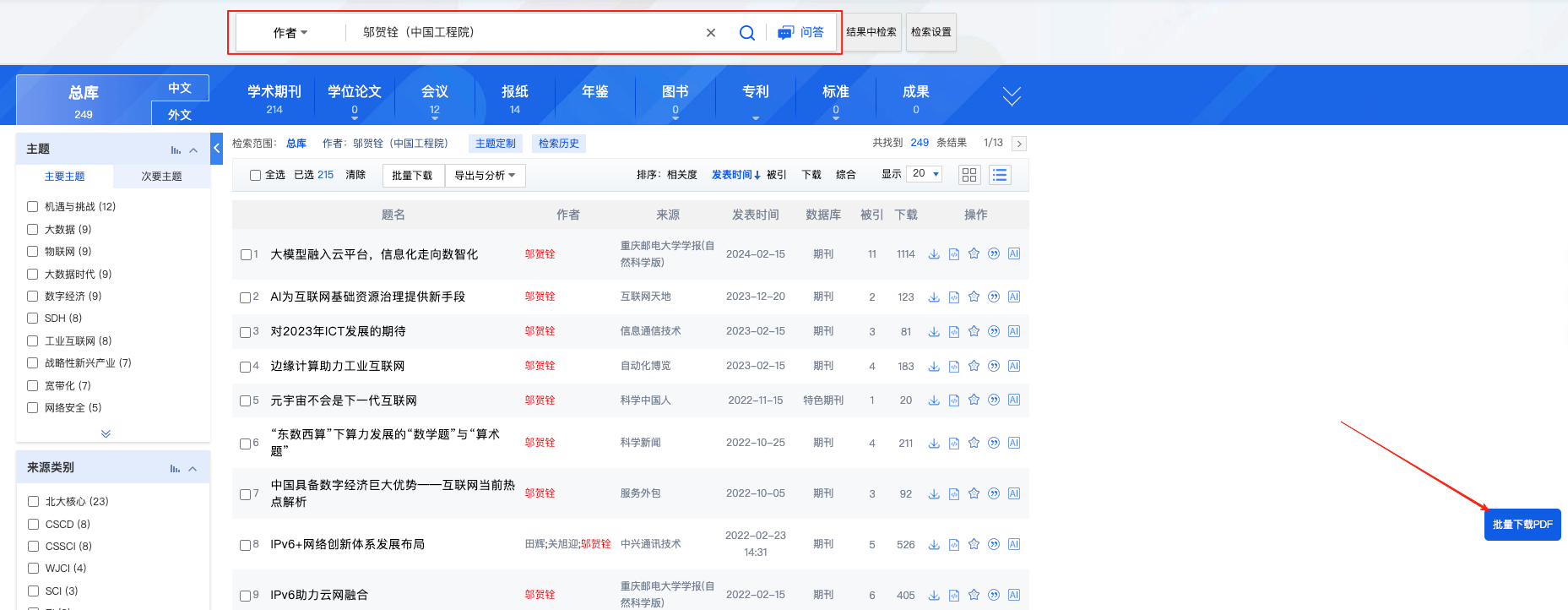
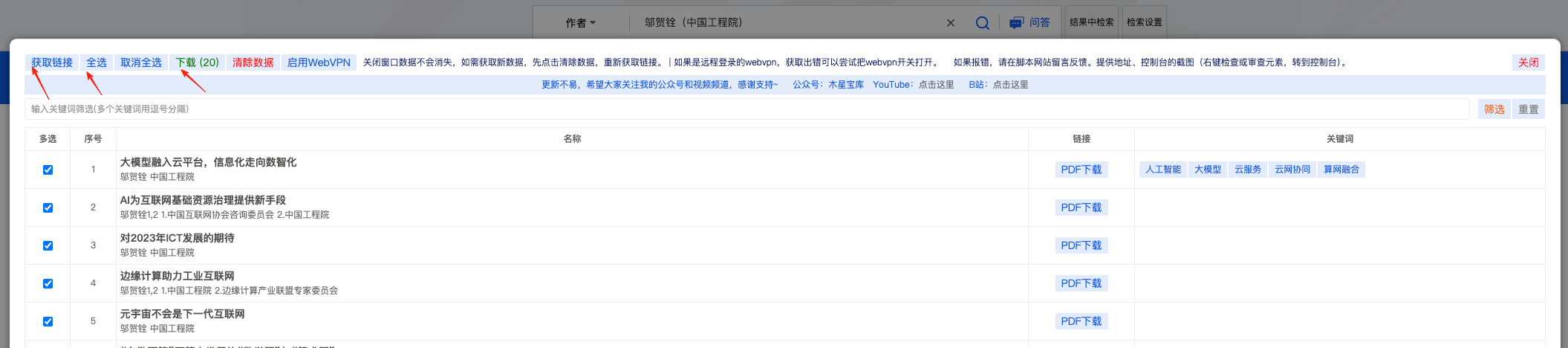
點擊右側批量下載的按鈕之后,會彈出下述界面。
- 獲取鏈接:捕獲知網當前界面的全部論文
- 全選:選中全部論文
- 下載:下載選中的論文
- 清除數據:在下一次獲取鏈接的時候,需要先清除數據
在使用的過程中,下載達到40篇以上的論文的時候,知網就會頻繁的彈出驗證碼。然后要求重新登錄。這個驗證的過程會難受一些。
【優化方案】:拼多多,淘寶 花個幾塊錢,可以買個他們自己搭建的知網鏡像網站賬號,他們的網站不會有這么多的驗證碼。
論文下載篇數驗證
論文如果重復下載了,文件會重命名,重復的文件會以括號加數字結尾,直接刪除就行。
下述的Python腳本,輔助用戶找出漏掉的論文。
知網可以批量導出論文的BibTex格式的參考文獻的引用格式。
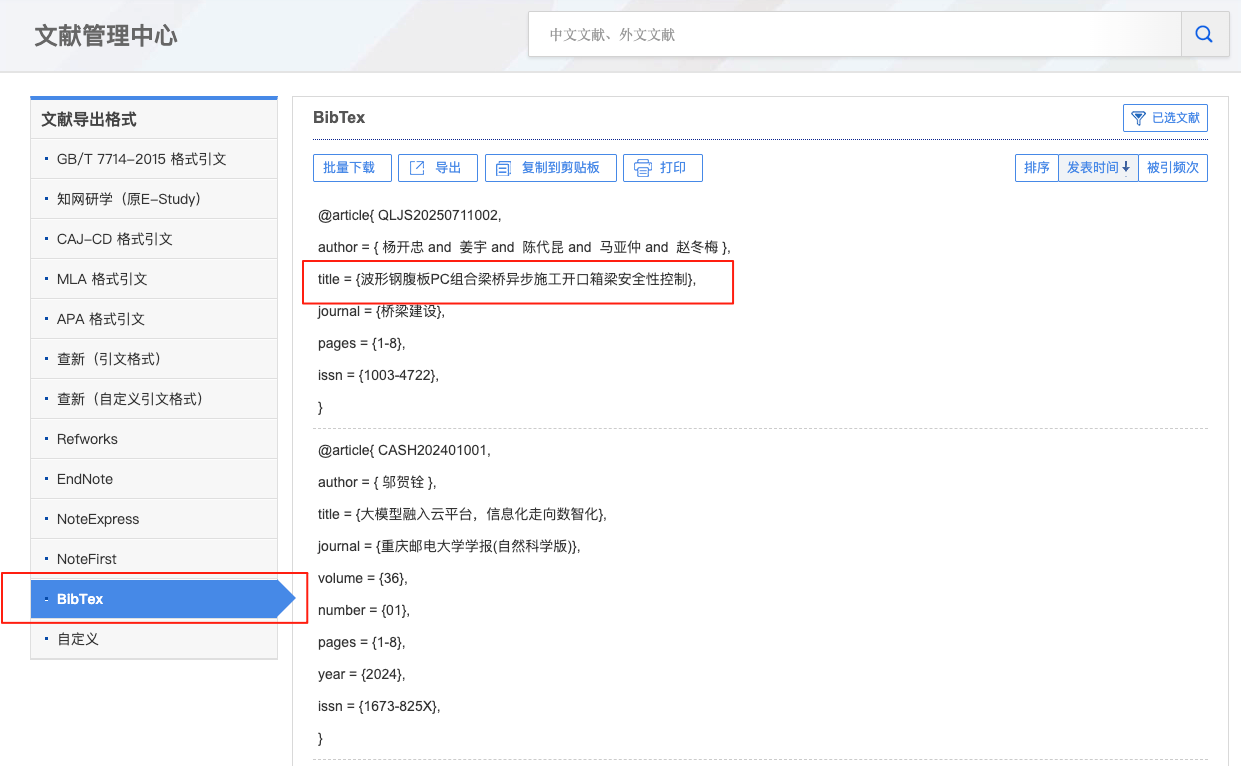
bib格式的導出文件的論文名字為:title = {xxx}。可以使用正則表達式匹配到論文的標題。與下載文件夾的論文對比,就可以找出哪些論文還沒下載了。
實現代碼如下:
import re
import osfile_bib = "BibTex批量導出的參考格式.bib"
source_dir = "論文下載的文件夾"with open(file_bib, "r") as f:text = f.read()data = re.findall("title = {(.*?)}", text)# 已下載的論文
down_papers = [name.split("_")[0] for name in os.listdir(source_dir)]for idx, paper_name in enumerate(data):if paper_name not in down_papers:page = idx // 20 + 1print(paper_name, page)
輸出結果是論文名和對應的頁碼數。知網一頁20篇論文,用bib的下標數量除以20,就知道該論文所在的頁碼數了。這樣方便后續手動下載。

參考資料
- https://blog.csdn.net/qq_43210428/article/details/144588820

——鏈接預測)





)





相關算法題)



)

