?一、AB實驗全流程框架?
實驗分為5個核心環節:
實驗假設? → 實驗設計? →實驗運行? → 實驗分析? → 實驗決策?
?二、各環節核心要點詳解?
?1. 實驗假設?
?原則?:目標性、可歸因、可復用(前兩者必選)
?(1)目標性?:明確量化目標(例:留存率提升α%),避免事后歸因。
案例:紅包策略實驗需提前聲明目標:"通過簽到領現金提升DAU β%",而非實驗后找上漲指標。
實驗目標——明確要提升的核心指標及預期幅度。
- ? 模糊目標:“提升用戶活躍度”
- ? 清晰目標:“將次日留存率提升5%”
實驗策略?——具體通過什么方法實現目標。
- ? 泛泛策略:“優化用戶體驗”
- ? 具體策略:“通過簽到領紅包功能,激勵用戶次日打開App”
數據/調研支持?——用數據或用戶反饋證明策略的合理性。
- ? 主觀猜測:“用戶可能喜歡紅包”
- ? 數據支持:“調研顯示,60%沉默用戶因紅包福利回歸”
?(2)可歸因?:對照組與實驗組僅1個變量差異。
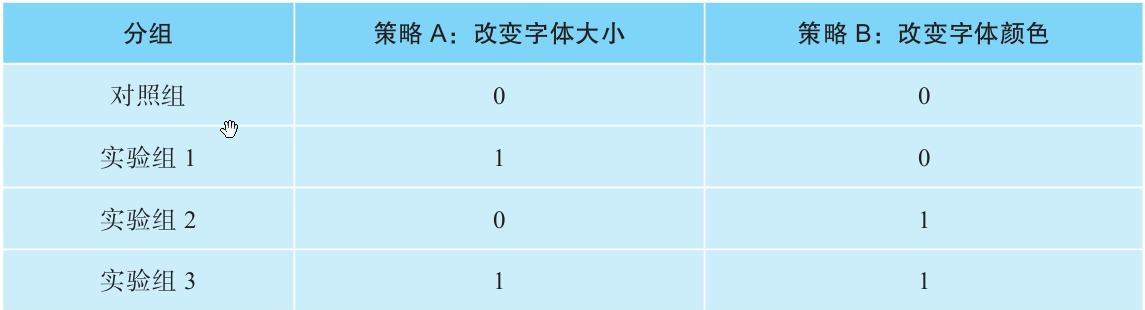
費曼案例:測試字體大小(策略A)和顏色(策略B)時,需設4組(對照+A+B+A+B組合),才能精準歸因單一策略效果。
(3)?可復用?:實驗策略能否推廣到更多用戶、場景或產品,從而放大價值。
- ? ?能復用?:比如優化“登錄按鈕顏色”可應用于全站所有頁面。
- ? ?不能復用?:比如僅針對“北京地區用戶”的限時活動。
- 成本效益高?:一次實驗,多處受益(例:推薦算法優化可復用至所有內容板塊)。
- ?資源有限?:優先做能影響80%用戶的實驗,而非僅影響5%用戶的實驗。
- 通用性?:策略是否依賴特定條件(如地域、時間段)?
- ?潛在影響?:覆蓋用戶量是否足夠大?
- ?長期價值?:是短期活動還是長期功能?
?2. 實驗設計?
??(1)樣本選擇?
- ?靜態抽樣?:按固定屬性(如地域、性別)預先分組,結果可外推全量。
案例:從女性用戶中抽10%測試,結果提升5% → 預估全量女性用戶提升5%。 - ?動態抽樣?:按行為實時觸發(例:進入購物車頁用戶),結果不可外推。
練習解析:電商價格感知實驗應在商品曝光時分流(答案B)?,確保用戶真實參與場景。

??(2)指標設計?
- ?結果指標(終極目標)?:衡量實驗最終效果的核心指標。(如電商:總收入(GMV)、人均消費額;社交App:DAU日活用戶數、用戶留存率)。
- ?過程指標?(轉化路徑)?:追蹤用戶行為鏈路,定位問題環節。(如打開App → 加購 → 發起結賬 → 完成結賬;關鍵指標:加購率、結賬轉化率)。
- ?保護指標(風險防控)??:監控實驗可能的負面影響。(如用戶流失:卸載率、跳出率;系統性能:頁面加載時間、崩潰率;成本控制:優惠券補貼金額)。
電商優惠券實驗案例
目標?:通過滿減優惠券(滿50減10)提升總收入。
- ?結果指標?:
- ?人均收入?(結賬頁面曝光用戶的人均GMV)
- ?ROI?(總收入 - 優惠券成本)
- ?過程指標?:
- 各環節轉化率(加購率→結賬率→支付成功率)
- ?保護指標?:
- 用戶投訴率、App卸載率
?關鍵點?:
- 只有看到優惠券的用戶?(結賬頁面曝光UV)才是實驗真實影響對象。
- 用人均收入而非總收入,避免流量分配不均的干擾。
??(3)流量計算
為什么需要計算最小樣本量??
- ?精度保障?:樣本量越大,越能檢測出細微的效果差異(如0.1%的點擊率變化)。
- ?置信度?:足夠的樣本量可降低隨機波動的干擾,確保結論可靠。
- ?案例關聯?:簽到紅包實驗需240萬用戶才能檢測0.1%的差異,但實際曝光僅60萬 → 只能檢測≥0.5%的差異。
流量不足的5種解決方案?
| ?方法? | ?適用場景? | ?案例中的體現? | ?局限性? |
|---|---|---|---|
| ?延長實驗時間? | 可累計的指標(如總訂單數) | 不適用(點擊率需按天計算) | 次日留存率等非累計指標無效 |
| ?改用低方差指標? | 接受二元指標(如"是否購買") | 用"是否點擊"替代"點擊次數" | 可能丟失關鍵信息(如金額差異) |
| ?調高檢測精度? | 業務允許較大差異(如從0.5%調至1%) | 60萬樣本只能檢0.5%差異,無法檢0.1% | 可能漏檢小但重要的效果 |
| ?過濾用戶? | 實驗受眾不精準(如非目標用戶混入) | 僅統計曝光用戶(60萬),排除未曝光者 | 需確保過濾邏輯不引入偏差 |
| ?重啟實驗? | 其他方法均無效 | 若需檢測0.1%差異,需等待流量釋放 | 延遲決策時間 |
簽到紅包實驗?
- ?實驗設計?:3種紅包樣式(A/B/C)vs 對照組(D),投放250萬用戶。
- ?關鍵數據?:
- 實際曝光用戶僅60萬 → ?真實樣本量=60萬?(非投放量250萬)。
- 最小樣本量要求:
- 檢測0.5%差異需50萬 → ?可判斷A/B>D,A>C。
- 檢測0.1%差異需240萬 → ?無法判斷B vs C或A vs B?(差異僅0.1%)。
- ?結論?:
- 曝光量不足時,小差異(<0.5%)可能被誤判為"無差異"。
- ?僅曝光用戶才計入有效樣本(未曝光用戶稀釋效果)。
Q?:為什么250萬投放用戶中,只有60萬算有效樣本?
?A?:因為紅包樣式僅對實際看到彈窗的用戶?(曝光量)產生影響,其余190萬用戶未接觸實驗策略,屬于"噪聲數據"。?Q?:若想證明B樣式比C好(差異0.1%),該怎么辦?
?A?:需將曝光量從60萬提升至240萬(方法:延長實驗時間或擴大投放范圍)。
??(4)實驗周期??
?1. 基礎計算公式?
?公式?:實驗持續時間 = 最小樣本量 / 每日有效用戶流入量
?案例假設?:
- 需檢測點擊率0.5%差異 → 最小樣本量=50萬
- 每日進入實驗用戶=10萬
- ?理論計算?:50萬/10萬=5天
?問題?:
- ?用戶重疊?:同一用戶可能多日訪問(如用戶A第1天和第3天都參與),實際獨立用戶數<50萬 → ?需延長實驗時間。
- ?指標特性?:次日留存率等指標需按天獨立計算,無法簡單累計。
?2. 關鍵影響因素與案例?
??(1) 用戶重疊效應?
- ?案例?:某社交App實驗每日新增10萬用戶,但30%為老用戶重復訪問。
- ?第1天?:獨立用戶10萬
- ?第2天?:新增7萬獨立用戶(3萬與第1天重疊)
- ?實際進度?:2天僅獲17萬獨立用戶(非20萬)→ 需延長至8天達標。
??(2) 工作日效應?
- ?案例?:電商App發現:
- 工作日:日均用戶8萬(白領活躍)
- 周末:日均用戶12萬(家庭用戶激增)
- ?對策?:至少運行7天(覆蓋完整周周期),避免僅用工作日數據導致偏差。
??(3) 季節性事件?
- ?案例?:在線教育平臺在"開學季"實驗:
- 開學前一周:用戶活躍度+200%
- 開學后:回歸正常
- ?風險?:若實驗僅覆蓋開學季,會高估效果 → 需延長至平穩期驗證。
??(4) 首因效應?
- ?案例?:新按鈕設計實驗:
- 第1天:點擊率+15%(用戶好奇)
- 第7天:點擊率穩定至+5%
- ?結論?:需觀察至少1周,排除短期干擾。
?3. 實驗周期設計原則?
| ?因素? | ?應對策略? | ?案例應用? |
|---|---|---|
| ?用戶重疊? | 按獨立用戶去重計算 | 社交App需從5天延長至8天 |
| ?工作日差異? | 覆蓋完整周(7天) | 電商實驗需包含周末數據 |
| ?季節性事件? | 避開大促或延長觀測期 | 教育平臺避開開學季或對比去年同期 |
| ?新奇效應? | 觀察指標是否趨于穩定(通常≥7天) | 新按鈕點擊率需7天后評估真實效果 |
?4. 一句話總結?
??"實驗周期≠簡單除法,需考慮用戶重疊、周期波動和 novelty 效應;寧可多跑3天,不要少看1周。"??
?案例點睛?:
- 若某實驗理論需5天,實際應規劃7-10天?(預留緩沖)。
- 重大策略(如改版)建議運行2周以上,覆蓋多個用戶行為周期。
?3. 實驗運行?
??(1)實驗上線?
案例背景:?假設“易購”電商App計劃上線一個新功能——“購物車底部常駐湊單推薦欄”。該功能會在用戶購物車頁面底部顯示一個固定區域,根據用戶購物車內的商品,實時推薦可以湊單滿減的商品。目標是提升湊單率和客單價。
1. 實驗上線前:準備與檢查
(1)檢查產品基本流程
案例解釋:?產品經理和測試工程師需要模擬用戶操作:
將商品加入購物車 -> 進入購物車頁面 -> 檢查底部推薦欄是否正常顯示。
點擊推薦欄商品 -> 檢查是否能順利加入購物車 -> 檢查加入后推薦欄是否實時刷新。
清空購物車 -> 檢查推薦欄是否消失或顯示合理提示(如“購物車空空如也,快去逛逛吧”)。
檢查在不同網絡環境、不同機型下的顯示和交互是否正常流暢。
負反饋檢查:?重點評估這個固定欄是否遮擋了關鍵操作(如“結算”按鈕)?是否讓頁面顯得過于擁擠?用戶是否會覺得推薦過于頻繁或打擾?設計上是否清晰告知用戶這是湊單推薦?
(2)檢查實驗設計
1-實驗組可分流 & 流量充足
實驗計劃分3組:A組(對照組,無底部推薦欄)、B組(實驗組1,顯示推薦欄)、C組(實驗組2,顯示另一種UI樣式的推薦欄)。技術團隊需確認:
用戶ID分流系統能穩定地將用戶隨機分配到A/B/C三組(可分流)。
計劃給該實驗分配總DAU的15%(A/B/C各5%)。易購App日活約2000萬,5%流量即約100萬用戶/組/天。這個量級對于觀察湊單率、客單價等核心指標的變化是足夠的(流量充足)。
2-實驗指標可計算 & 埋點數據上報
核心指標
湊單率:?(點擊推薦欄商品并加入購物車的用戶數) / (看到推薦欄的用戶數)。需要埋點:推薦欄曝光、推薦欄內商品點擊、商品加入購物車(需標記來源為“湊單推薦”)。
客單價變化:?實驗組 vs 對照組用戶平均訂單金額差異。需要依賴現有下單金額埋點。
購物車頁停留時長:?可能受新元素影響。
檢查點
新增埋點:?確認前端工程師已為“推薦欄曝光”、“推薦欄商品點擊”(需記錄點擊的商品ID和位置)、“從推薦欄加入購物車”(需打上特定來源標記)等事件完成埋點代碼開發并測試通過。
字段規范:?確認埋點上報的字段(如
event_name=cart_recommend_click,?item_id=xxx,?position=yyy,?source=zzz)符合數據團隊的規范。存儲與計算:?確認數據倉庫已準備好接收這些新事件,數據團隊已開發好ETL Pipline,能將原始日志清洗、轉換并寫入分析數據庫(如Hive表),且下游BI報表或實驗平臺能正確讀取并計算上述指標。確認數據保留時間滿足實驗分析需求(通常至少保留實驗期+后續一段時間)。
2. 實驗上線后:驗證與監控
(1)個體校驗:白名單體驗 & 日志抓包
白名單
將測試賬號加入B組(實驗組)白名單。
登錄測試賬號 -> 添加商品到購物車 -> 進入購物車頁面 ->?肉眼可見:?底部是否出現了推薦欄?樣式是否正確?推薦的商品是否相關?點擊商品是否能加入購物車?加入后推薦欄是否刷新?功能交互是否順暢?
日志抓包
對于用戶不可見的邏輯,比如“推薦算法是否真的為B組用戶啟用了新策略”?僅靠UI無法完全確認。
技術同學在測試賬號操作時,抓取其設備與服務器的網絡請求日志。
在日志中搜索關鍵API請求(如獲取購物車信息的請求)。檢查服務器返回的響應數據中,是否包含了新設計的推薦欄數據字段(如
has_bottom_recommend: true,?recommend_items: [...])。這證明后端邏輯確實為該用戶(B組)啟用了新策略。
(2)實驗指標監控
a. 用戶數量符合分流預期
百分比分流
實驗上線后第一天(完整天),查看實驗平臺數據:進入A、B、C三組的用戶數應各在100萬左右(2000萬 * 5%)。如果發現B組只有70萬,C組有130萬,偏差 = (130-100)/100 = 30%,?遠超合理范圍(通常<5%可接受)。這必須立刻報警!需要檢查:分流服務配置是否錯誤?用戶屬性(如新老用戶)是否在組間嚴重不均衡?實驗配置是否被意外修改?
版本折損:?(假設此功能依賴App新版本)
實驗上線首日,新版本覆蓋率僅20%。
理想每組100萬用戶進入實驗,但實際每組只有 100萬 * 20% = 20萬用戶(因為只有升級了新版本的用戶才有機會觸發新功能邏輯)。這是正常現象,并非實驗下發問題。隨著新版本覆蓋率提升(比如一周后到80%),每組用戶數會逐漸接近80萬。分析數據時,要基于已升級新版本的用戶來看效果。
b. 指標符合產品常識 & 核心指標監控
埋點數據校驗
查看B組(有推薦欄)的數據:
“推薦欄曝光”事件量:是否與進入購物車頁面的用戶量大致匹配?(如果100萬用戶進入購物車,曝光量也應接近100萬)。
“推薦欄商品點擊”事件量:是否遠小于曝光量?(正常,不是每個人都會點)。
“從推薦欄加入購物車”事件量:是否小于點擊量?(正常,點擊后可能不加車)。
轉化率檢查:?點擊率(點擊/曝光)假設是5%,加入購物車率(加車/點擊)假設是30%。如果發現點擊率高達80%或加車率低至1%,明顯不符合常識!可能原因:埋點上報錯誤(如曝光事件重復上報)、推薦算法失效(推薦了完全無關或劣質商品)、UI設計有誤導性(用戶誤點)。
核心指標監控
監控B組、C組(實驗組)的湊單率、客單價、購物車頁停留時長,并與A組(對照組)對比。
同時監控:?B/C組的人均訂單數、App整體人均停留時長、核心頁面(如首頁、商詳頁)的轉化率等大盤核心指標。為什么??雖然目標是提升湊單和客單,但新功能可能帶來副作用:
推薦欄是否讓用戶覺得煩擾,導致購物車頁跳出率升高?
是否因為湊單推薦太強,用戶反而猶豫不決,降低了整體下單率?
新功能是否增加了App的資源消耗,導致卡頓,影響整體體驗?
特殊群體差異注意:?如果這個實驗只針對老用戶(比如注冊>30天的用戶),那么B/C組用戶的歷史購買頻次、客單價基線本身就可能遠高于大盤平均值(包含大量新用戶和低頻用戶)。直接拿B/C組的客單價與大盤比沒有意義,重點是比較B/C組 vs A組(同為老用戶)的差異。
c. 組間數據差異符合預期 & 均勻性檢驗
AA/BB組校驗
在本次實驗中,雖然目標是測試B/C兩種新樣式,但為了檢驗分流均勻性,可以設置:
A1組(對照組1,5%流量,無推薦欄)
A2組(對照組2,5%流量,無推薦欄)->?這就是AA組
B1組(實驗組1,5%流量,推薦欄樣式1)
B2組(實驗組2,5%流量,推薦欄樣式1)->?這就是BB組 (測試樣式1的均勻性)
C組(實驗組3,5%流量,推薦欄樣式2)
檢查
A1組 和 A2組 的各項核心指標(湊單率、客單價等)差異是否很小(在統計誤差范圍內)?如果A1的湊單率比A2顯著高很多,說明分流不均勻!可能是用戶分配不隨機,導致A1組用戶本身就更愛湊單。這會嚴重質疑后續B/C組與A組比較結果的可信度。
同理,B1組 和 B2組 的各項指標也應非常接近。如果差異顯著,說明實驗處理(樣式1)的下發或數據采集可能有問題。
意義:?AA組/BB組之間的差異是衡量實驗基礎環境(分流、數據采集)是否可靠的“金標準”。如果AA差異大,整個實驗結論都不可信。
總結
通過“易購App購物車底部湊單推薦欄”這個案例,我們可以看到AB實驗從上線前嚴謹的流程、邏輯、埋點、數據基建檢查,到上線后即時的個體功能驗證(白名單/抓包)?和核心的數據指標監控(用戶量校驗、常識校驗、核心指標監控、組間均勻性校驗)?的全過程。每一步都是為了確保實驗能夠正確運行、收集的數據準確可靠,最終得出的實驗結論(哪種方案更好)是科學可信的,從而為產品決策提供堅實依據。忽略任何一步,都可能導致實驗失敗、得出錯誤結論,甚至對線上用戶體驗和業務指標造成負面影響。
??(2)實驗停止條件 & 常見問題應對
在A/B測試中需要立即停止實驗的三種關鍵信號:實驗異常、明顯負反饋、大幅負向效果,以及三種實驗中常見的問題及其應對策略:預設精度過高、增量擴量風險、數據大幅波動。
實驗停止條件
實驗異常:?“小A,想象我們在測試一個新按鈕顏色。上線后發現,實驗組用戶壓根沒看到新按鈕(比如技術bug導致按鈕沒加載出來),或者對照組用戶反而被錯誤地分配到了新按鈕。這時數據肯定亂七八糟,不能反映真實效果。這就好比做化學實驗,試管裂了或者加錯了試劑,必須馬上停下,修好設備重新開始。”
明顯負反饋:?“假如我們測試一個更激進的廣告策略。上線后,用戶投訴激增,社交媒體上都在罵我們騷擾用戶,品牌形象受損了。這時就算數據還沒出結果,也必須立刻停下!這就像你開了一家新口味的奶茶店試營業,結果顧客喝了紛紛吐槽難喝甚至拉肚子,網上差評如潮,你還能繼續賣嗎?肯定得先關門,搞清楚問題出在哪(配方?原料?),再決定是徹底放棄這個口味還是改進后再試。”
大幅負向效果:?“這個情況是實驗本身運行正常,流量分配、用戶行為都符合預期,實驗也運行了足夠長時間(數據平穩)。但結果發現核心指標(比如用戶購買率、公司收入)大跌!除非這個下跌是我們策略故意設計的(比如測試一個減少促銷的策略,預期短期收入會降但長期用戶忠誠度會升),否則必須立即剎車。就像你給汽車換了個新引擎,試車跑了足夠里程,結果發現油耗飆升了50%,動力還下降了。這肯定不是預期結果,得馬上停下來檢查引擎是不是有缺陷。”
常見情況及應對
預設精度過高:?“小A,我們計劃做實驗前會算需要多少用戶(樣本量)。但如果算的時候要求太高(比如非要檢測出0.1%的微小提升),結果實驗跑完了,發現業務上確實有提升(比如轉化率漲了1%),但因為預設精度要求太苛刻,統計上顯示‘不顯著’。這就等于你買了個超級精確的秤,想稱一粒米的重量變化,結果秤的誤差都比米粒的變化大,當然稱不出來。應對辦法就是:要么接受這個提升(如果業務上足夠重要),要么重新設計實驗,要么延長實驗時間收集更多數據(相當于換個沒那么‘靈敏’但能測出1%變化的秤)。”
增量擴量風險:?“有時候為了省時間,實驗人員會在原有5%流量實驗的基礎上,直接再加5%流量進去(變成10%)。這聽起來省事,但其實隱藏兩個大坑:一是新加的用戶進來會引起數據波動(就像往平靜的池塘里扔石頭),需要重新等待數據穩定,這時間可能比重新開個10%流量的實驗還長;二是新舊用戶混在一起,萬一新用戶群和老用戶群本身有差異(比如渠道不同),或者分流系統在新流量上出問題,你很難區分到底是策略效果還是流量不均導致的。這就好比你做蛋糕,第一次按A配方做了小份(5%流量),覺得不錯想做大份。錯誤做法是把A配方小份蛋糕掰碎,再混入按A配方新做的大份蛋糕糊(增量擴量),然后一起烤。烤出來味道不對,你根本分不清是小份蛋糕放久了變味了,還是新蛋糕糊比例錯了,還是烤箱溫度不均。正確做法是干脆按A配方單獨新做一個完整的大蛋糕(重新分配10%流量)。除非是為了讓同一用戶始終體驗一致(比如界面改版),否則最好別增量擴量。”
數據大幅波動:?“實驗期間遇到雙十一、系統故障、明星八卦熱搜這種大事,用戶行為會劇烈變化,數據像坐過山車。這時數據的‘噪音’(方差)變大了,原來估算的樣本量可能就不夠了。就像在大風天測量旗桿高度,風把測量工具吹得晃來晃去(方差大),你測一次的結果可能很不準。你需要測很多次(相當于需要更大樣本量)或者等風停(波動結束)才能測準。實驗平臺能剔除特殊時段數據當然好,但像雙十一這種影響深遠的事件(‘日歷效應’),用戶購物習慣可能幾周都受影響,而且很難區分是活動影響還是實驗策略影響。應對核心是:預防為主,避開可預見的大波動期(如春節、大促)。萬一撞上了,最可靠的辦法是拉長實驗時間,收集更多數據,讓波動被‘平均’掉,或者等影響完全過去再分析。”
簡化類比
實驗停止條件 = 開車警示燈:
異常燈(實驗異常):?儀表盤亂跳/發動機故障燈亮 -> 立即靠邊停車檢查。
投訴風暴燈(明顯負反饋):?乘客集體嘔吐/強烈抗議 -> 立即停車安撫,檢查是不是車有問題。
性能暴跌燈(大幅負向效果):?油耗猛增/動力銳減 -> 立即停車檢查,除非你故意在測試“省油模式”(犧牲動力)。
常見問題應對:
預設精度過高 = 用顯微鏡看大象:?工具太靈敏,反而看不到整體變化。換放大鏡(調整檢測目標)或者站遠點看(延長實驗/接受業務顯著性)。
增量擴量 = 新舊顏料混用:?想省顏料,把舊顏料桶里剩下的倒進新顏料桶里混合用。結果畫出來顏色不對,你搞不清是舊顏料變質了還是新顏料配方錯了。不如直接開一桶新顏料(重新分配流量)。
數據大幅波動 = 大風天測旗桿:?風大(外部事件)導致測量工具(數據)劇烈晃動(方差大)。要么多測幾次取平均(增大樣本量/延長實驗),要么等風停(避開或等待特殊時期結束)。
總結:
停止實驗是果斷止損的關鍵機制,?針對三種嚴重風險(無效實驗、用戶反感、核心傷害)設置明確的“熔斷點”。
實驗設計需務實:?樣本量計算要符合實際業務需求,避免過度追求統計顯著性而忽略業務顯著性。
“省事”可能更費事:?增量擴量看似快捷,實則引入混淆變量和等待成本,風險大于收益,應盡量避免。
數據質量是生命線:?外部沖擊會嚴重干擾實驗結果識別。核心策略是“避”大于“治”:優先避開已知波動期。若無法避免,則需顯著延長實驗時間或利用平臺功能謹慎處理數據,充分認識到重大事件的持續影響(日歷效應)。
??(4)實驗放量風險?
1. 概念:明確你要學習的是什么?
核心概念1:實驗放量 (Experiment Rollout/Ramp-up):將實驗策略(比如新的算法、功能、內容策略)逐漸應用到更大比例的用戶群體上的過程。原因可能是樣本量不足或初步效果正向。
核心概念2:辛普森悖論 (Simpson's Paradox):當把來自不同群體或不同條件(如不同放量階段)的數據合并分析時,數據展現的趨勢(如實驗組更好/更差)可能與每個子群體/子階段內的實際趨勢完全相反。關鍵在于分組權重(比例)的變化。
案例背景:某資訊產品做了一個實驗,將A類內容(點擊率較高的內容)在列表中的曝光占比提升了(實驗組)。關心的核心指標是整體點擊率(CTR)。實驗后觀察到的現象是:A類內容的CTR下降了,B類內容的CTR也下降了。這看起來實驗效果是負面的?但合并數據后發現整體CTR提升了?為什么?
2. 教授:假裝把這個概念教給一個小學生或外行
解釋放量(簡單版):想象我們在學校小賣部測試一種新口味糖果。第一天只給10個同學試吃(實驗組),其他90個同學吃原來的糖果(對照組)。如果試吃的10個同學都說好吃,我們可能第二天讓50個同學都試吃新糖果(放量了),剩下50個吃原來的。
解釋辛普森悖論(用糖果案例類比):
第一天(小范圍放量10%):試吃新糖果的10個同學,8個說好吃(好吃率80%)。吃舊糖果的90個同學,63個說好吃(好吃率70%)。新糖果看起來更好!
第二天(放量到50%):試吃新糖果的50個同學,35個說好吃(好吃率70%)。吃舊糖果的50個同學,30個說好吃(好吃率60%)。新糖果還是更好!
合并兩天數據(錯誤方式):
新糖果總好吃次數:8(第1天) + 35(第2天) = 43次。總試吃人數:10 + 50 = 60人。合并好吃率 = 43 / 60 ≈ 71.7%
舊糖果總好吃次數:63(第1天) + 30(第2天) = 93次。總試吃人數:90 + 50 = 140人。合并好吃率 = 93 / 140 ≈ 66.4%
結論:新糖果(71.7%) > 舊糖果(66.4%),看起來還是新糖果好。
發現問題(辛普森悖論出現):等等!我們明明看到每一天新糖果都比舊糖果好吃(80%>70%, 70%>60%),合并后(71.7%>66.4%)也顯示新糖果好,這好像沒悖論啊?哪里錯了?
關鍵點(權重變化):錯在合并掩蓋了結構變化。第一天只有10%的人吃新糖(好吃率高80%),第二天有50%的人吃新糖(好吃率降到70%)。當我們簡單合并兩天數據時,第二天(好吃率較低但占比大增)的數據拉低了新糖的總好吃率。同時,舊糖第一天占90%(好吃率70%),第二天只占50%(好吃率60%),第二天(好吃率較低但占比大減)的數據沒有像新糖那樣顯著拉低舊糖的總好吃率。結果就是,新糖的總好吃率(71.7%)雖然還是比舊糖(66.4%)高,但這個優勢(71.7% - 66.4% = 5.3%)比第一天觀察到的優勢(80%-70%=10%)和第二天(70%-60%=10%)都要小得多!如果權重變化更極端,甚至可能出現合并后優勢消失或反轉(真正的悖論)。案例2屬于優勢被合并稀釋(但未反轉),是辛普森悖論原理的體現(權重變化影響合并結果),展示了合并可能扭曲對效應大小的判斷。
3. 回顧:檢查理解中的漏洞,回到原始材料
回顧案例數據
對照組 (舊策略): A曝光占比10%, CTR=20%; B曝光占比90%, CTR=5%;?整體CTR = (10% * 20%) + (90% * 5%) = 2% + 4.5% = 6.5%
實驗組 (新策略:A提權): A曝光占比50%, CTR=15%; B曝光占比50%, CTR=4%;?整體CTR = (50% * 15%) + (50% * 4%) = 7.5% + 2% = 9.5%
觀察現象:A的CTR從20%降到15%, B的CTR從5%降到4%。但整體CTR從6.5%升到了9.5%!
解答問題 :
實驗提升了整體的點擊率嗎??是的!整體CTR從6.5%提升到了9.5%。
為什么A、B的點擊率都下降?
A類下降 (15% < 20%):因為實驗組把A的曝光占比大幅提高(從10%到50%)。想象一下,原來列表里10條信息只有1條是A類(精品),用戶看到會眼前一亮去點。現在列表里10條信息有5條都是A類(精品),用戶可能覺得“怎么都是這種?有點膩/不稀罕了”,或者精品內容本身供應質量跟不上突然增加的需求(邊際效應遞減),導致A類本身的吸引力相對下降(CTR下降)。簡單說:好東西一下子給太多,大家反而不那么珍惜了。
B類下降 (4% < 5%):因為A類曝光占比大增,擠占了B類的曝光空間(從90%降到50%)。原來用戶瀏覽時,大部分時間看到的是B類,偶爾看到A類精品會點。現在用戶一半時間都在看A類(即使CTR降了,但15%仍遠高于B的5%),用戶有限的注意力和點擊更多地被A類吸引走了,留給B類的關注和點擊自然就變少了(CTR下降)。簡單說:精品搶走了普通品的風頭和點擊機會。
這種提升點擊率的方法可能有什么潛在問題?
用戶體驗單一化/疲勞:?過度依賴高CTR內容(A類)可能導致信息繭房或內容同質化,用戶容易感到厭倦,長期留存可能下降。就像天天吃山珍海味也會膩。
犧牲內容多樣性/生態健康:?過度擠壓B類內容的曝光,可能讓優質但CTR相對不突出的B類內容(如深度報道、小眾興趣)失去生存空間,破壞平臺內容生態的多樣性和健康度。
依賴“低質”高CTR內容風險:?如果A類內容的高CTR是靠標題黨、低俗、獵奇等“不良”手段獲得的,這種提升方式損害平臺長期價值和品牌形象,不可持續。
指標單一陷阱:?只關注整體CTR提升,可能掩蓋了其他重要指標的惡化,比如用戶閱讀時長、分享率、滿意度、留存率等。用戶可能點了很多A類,但很快就關掉了(閱讀深度淺)。
辛普森悖論的警示:?這個案例本身展示了只看分項指標(A CTR降, B CTR降)會得出錯誤結論(實驗負向),而合并計算整體指標(整體CTR)才反映真實效果(正向)。這提醒我們在分析實驗,尤其是涉及流量分配變化(放量)或用戶群體結構變化時,必須謹慎選擇分析維度(整體 vs 分層),警惕辛普森悖論。?放量過程中流量分配比例的變化,是誘發辛普森悖論的高風險場景。
4. 簡化:用最簡潔清晰的語言概括核心
實驗放量:好實驗初步驗證后,逐步開放給更多用戶用。
辛普森悖論陷阱:在放量時,如果不同階段或不同用戶群的實驗/對照組比例變化很大,簡單合并所有數據來看實驗效果好壞,可能會得出完全錯誤或者嚴重失真的結論(比如把好效果算小了,甚至誤判成壞效果)。
案例核心解釋:
實驗通過大幅增加高點擊率(A類)內容的曝光占比來提升整體點擊率。
A類CTR下降:因為一下子給太多,用戶不覺得稀罕/內容跟不上。
B類CTR下降:因為A類搶走了用戶的注意力和點擊。
整體CTR上升:因為用戶點得更多的A類(雖然效率降了點)取代了大量用戶不怎么點的B類。高點擊率內容占據的版面大幅增加是主因。
潛在問題:
用戶可能看膩(單一化)。
其他內容被擠壓死(生態破壞)。
可能鼓勵了壞內容(標題黨)。
可能只看點擊率,忽略了其他重要指標(短期主義)。
放量分析時,必須注意流量結構變化,防止辛普森悖論誤導判斷。
總結:這個案例生動地展示了實驗放量過程中辛普森悖論的威力。它告訴我們:
合并數據需謹慎:?當實驗組/對照組的流量分配比例在放量過程中發生變化時,直接加總所有數據評估實驗效果是危險的,可能嚴重低估甚至顛倒真實的效應。
理解現象背后的“為什么”:?A/B類CTR雙降但整體CTR提升,根源在于曝光結構的巨大改變(A占比激增)?和用戶注意力的競爭(A搶B的點擊)。高CTR的A類獲得了不成比例的巨大曝光增量,是整體提升的關鍵驅動力。
指標選擇與長期視角:?單純追求整體CTR提升可能帶來內容生態惡化和用戶體驗下降等長期風險。需要結合多樣性、用戶滿意度、留存率等綜合指標評估。
?4. 實驗分析?
??(1)明確影響范圍?
- 只分析真正受策略影響的用戶。
案例:購物車優惠券實驗應分析打開購物車頁的用戶?(非全站用戶),避免未曝光用戶稀釋效果(表16-6)。
??(2)確保組間可比性?
- 避免幸存者偏差:不直接對比"點擊彈窗用戶" vs "未點擊用戶"(本身行為差異大)。
??(3)維度細分?
- 按設備、時段、用戶類型等細分,發現隱藏洞見。
費曼案例:深夜時段(0-3點)用戶消費時長提升顯著 → 針對性優化該時段內容推薦(圖16-2)。
??(4)統計學解讀?
- ?P值<0.05?:拒絕原假設(效果顯著)
- ?P值>0.05且功效>0.8?:大概率無差異
練習解析:- 實驗效果置信區間[0.0025, 0.0499]且提升5% → 統計與業務均顯著(答案A)
?5. 實驗決策?
??(1)決策依據?
- 核心指標是否達預期(需提前定義業務顯著性)
- 成本收益權衡(開發/維護成本 vs 收益)
- 負面影響的容忍度(如DAU提升但收入下降)
??(2)三種結果?
- ?發布?:效果正向且保護指標達標(例:實驗組2紅包策略ROI最優 → 放量至95%)
- ?下線?:核心指標負向或用戶投訴激增
- ?重新實驗?:效果不顯著或實驗條件未滿足
??(3)實驗報告要素?
- 背景目標 → 方案設計 → 數據分析 → 結論與后續計劃
?三、關鍵方法論提煉?
| ?環節? | ?核心思維? | ?避坑指南? |
|---|---|---|
| 實驗假設 | 目標先行,避免盲目探索 | 拒絕"大海撈針式實驗" |
| 實驗設計 | 流量均勻,指標分層監控 | 動態抽樣結果不可外推全量 |
| 實驗分析 | 歸因到人,細分維度找洞見 | 警惕幸存者偏差和辛普森悖論 |
| 實驗決策 | 平衡統計顯著與業務價值 | 成本過高時需更高收益覆蓋 |



![[論文閱讀] 人工智能 + 軟件工程 | 開源軟件中的GenAI自白:開發者如何用、項目如何管、代碼質量受何影響?](http://pic.xiahunao.cn/[論文閱讀] 人工智能 + 軟件工程 | 開源軟件中的GenAI自白:開發者如何用、項目如何管、代碼質量受何影響?)












![[Element]修改el-pagination背景色](http://pic.xiahunao.cn/[Element]修改el-pagination背景色)


