論文鏈接:arxiv.org/pdf/2109.01134v1
推薦視頻(clip_coop的代碼邏輯講解,代碼簡單,有助于理解):CLIP和CoOp工作的簡單Pytorch復現和理解_嗶哩嗶哩_bilibili
其他參考鏈接:CoOp - CLIP 自適應Prompt工程 【一】_coop clip-CSDN博客?
?動機
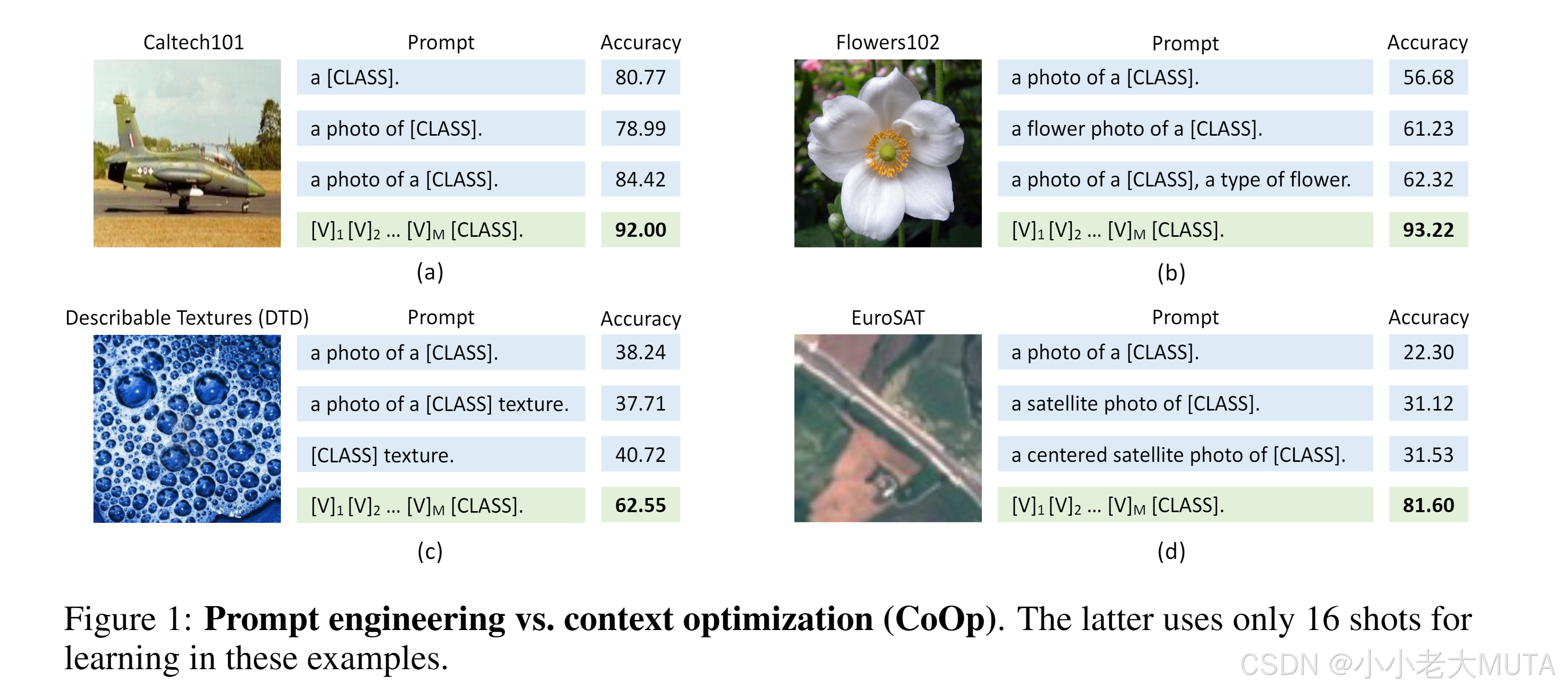
如下圖所示,有三種手工設計的prompt提示詞:
- a [class]
- a photo of [class]
- a photp of a [class]
用這三種提示詞去做zero-shot測試,實驗發現盡管這三種提示詞在我們人為看來區別不大,但是實際結果卻不同------>文本輸入(即提示詞)對下游數據集性能起關鍵作用。
因此,作者提出:想讓機器自己學習到最合適的prompt提示詞來獲得更好的結果。
具體方法
如下圖所示,原本在CLIP中,文本端的輸入就是人為手工設計的prompt + class(A photo if a [class]);
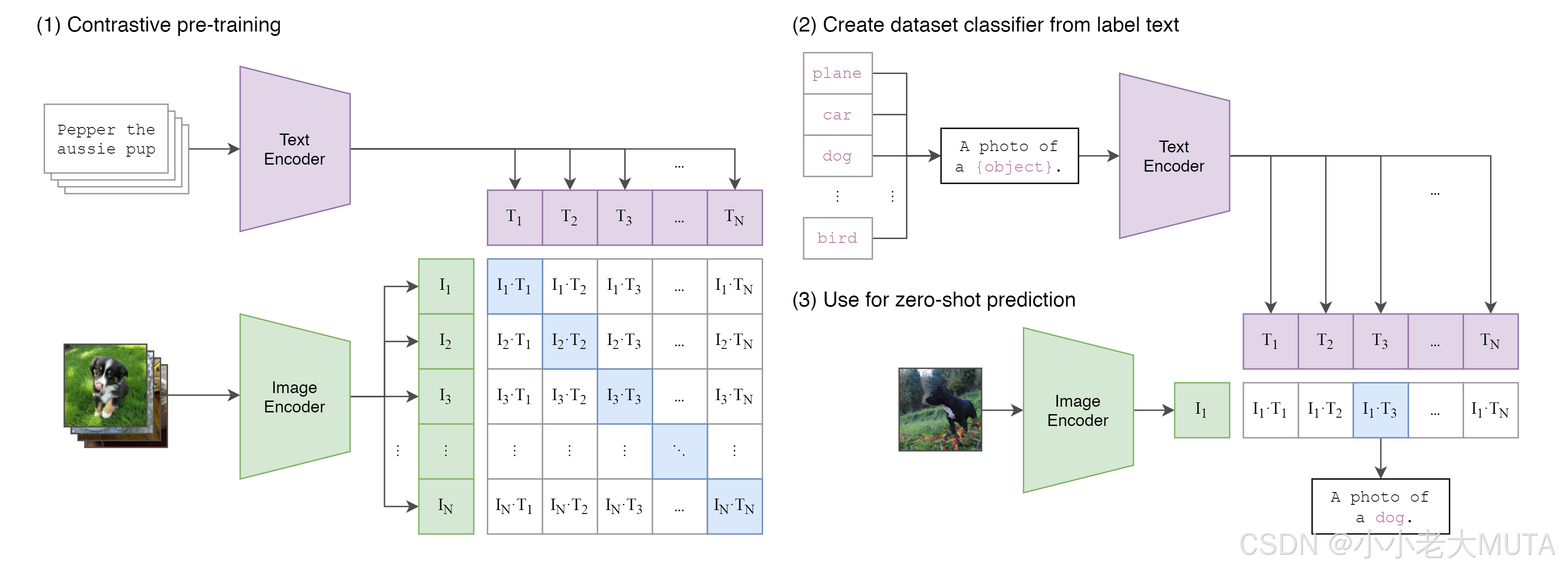
具體而言,就是
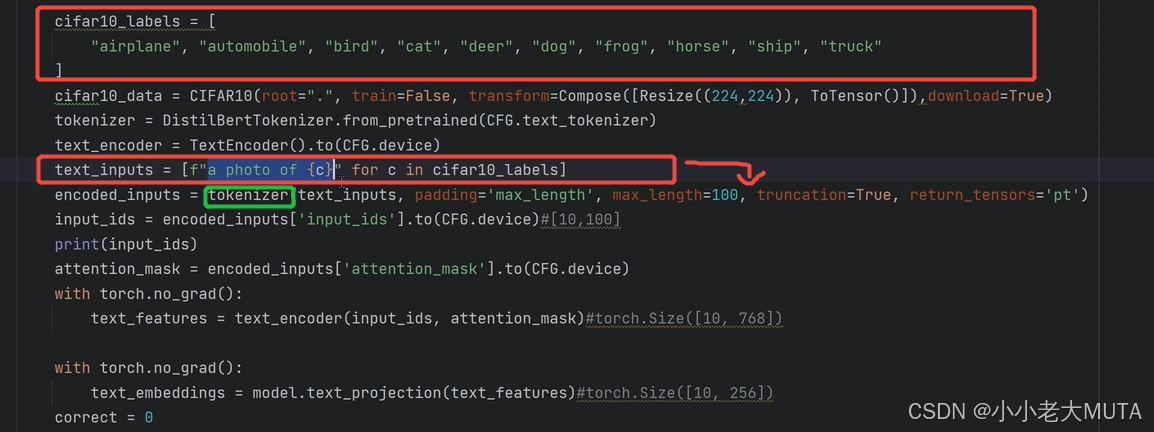
1. 先給定所有的標簽labels,然后加上prompt(A photo of) 變成完整的input
2. 再使用tokenizer(bert中先wordpieces)將人能看懂的詞語映射成為768維的向量,這里又10個labels,所以是[10,768]維的輸入到Text Encoder。
下圖是coOp的方法,文本輸入端的prompt 變成了 可學習的向量 + class。
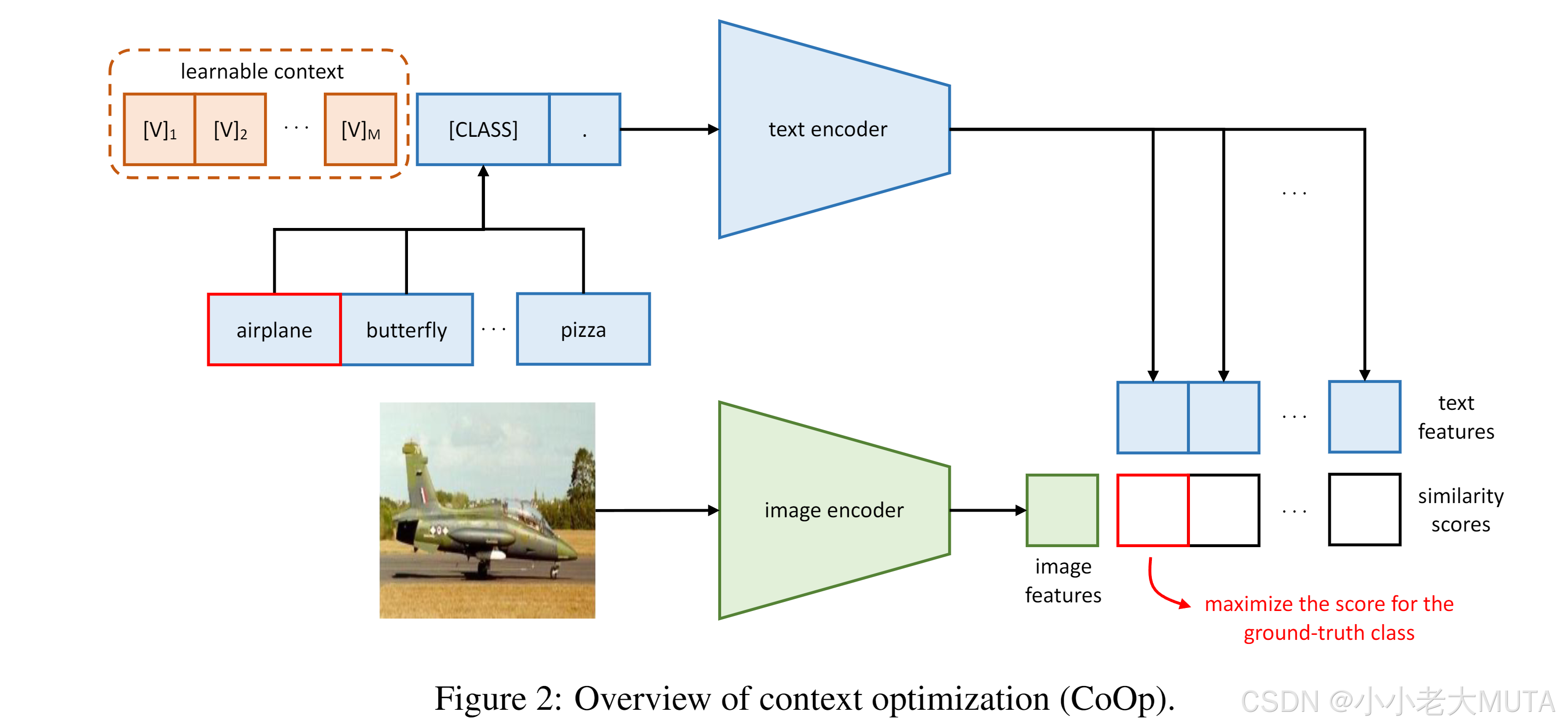
具體而言:
1. 剛開始給的還是 a photo of [class]
2. 將這個a photo of [class] 傳給預訓練好的模型,加載預訓練權重,得到學習好的這個句子對應的向量(10,4,768);
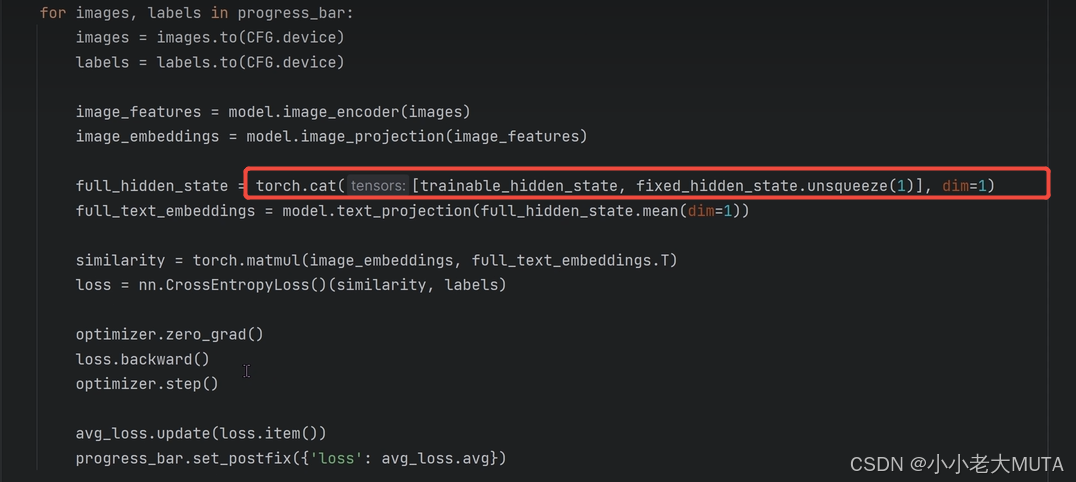
3. clip中原本就直接用這個得到的向量去和圖片做交叉熵損失找出相似度最大的類別;
4. coOp得到預訓練模型學習好的向量以后,把class類別的向量凍結住;
5. 將得到的4(A photo of [class])的前三個向量當作初始值,然后去學習;
?6. 將學習后得到的這三個向量再和[class]拼接回原來的模樣,再去?做相似度計算。
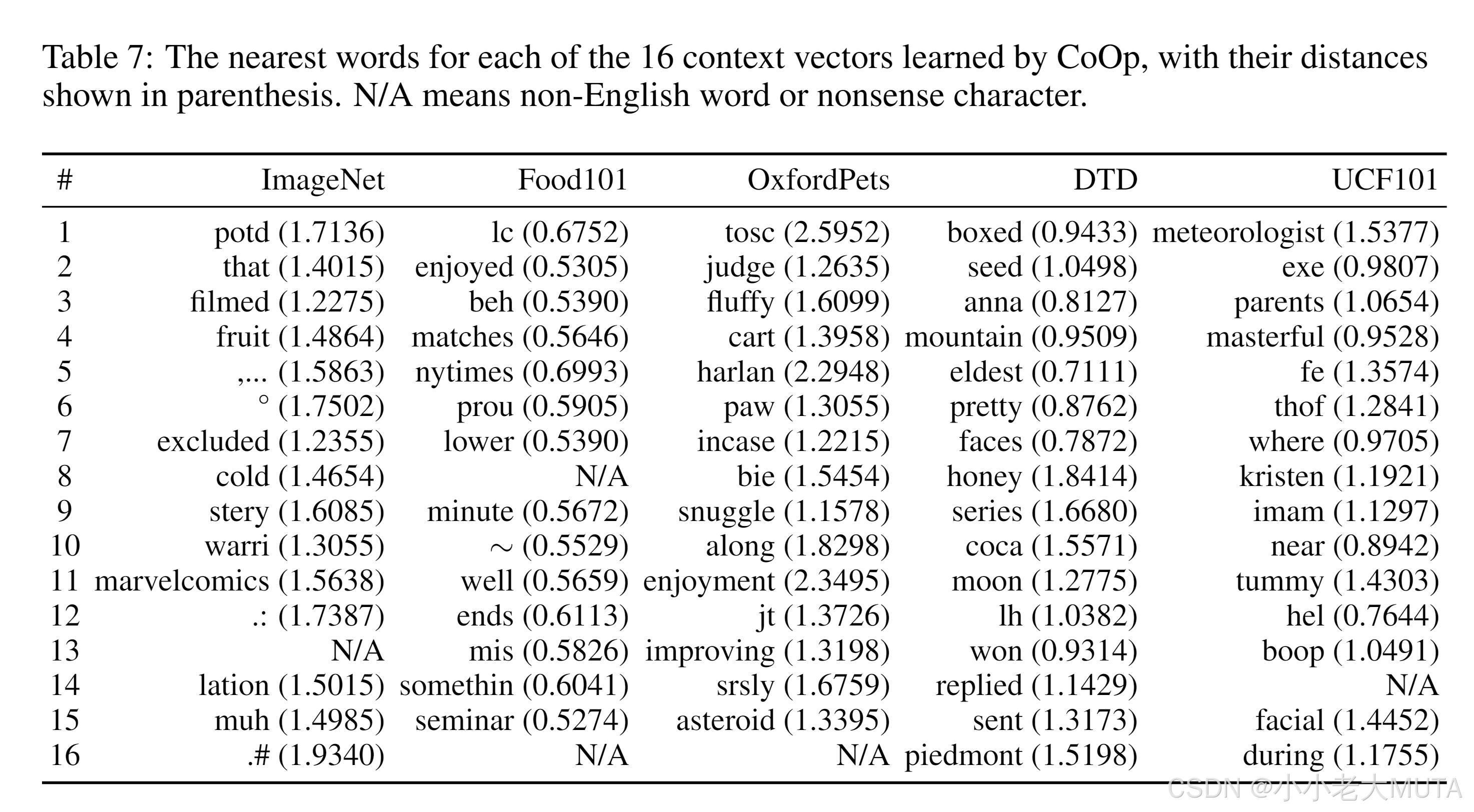
最終得到的前三個向量也就是我們學習得到的prompt,作者將每個詞向量與預訓練詞典進行歐式距離計算。 選擇最接近的向量詞,作為填充,最終構成一句話,發現其實沒有語言邏輯,人是看不懂的。
細節
其實作者考慮了兩種可學習prompt:unified context統一可學習?, class-specific context特定類別可學習
我們上面舉的例子是?unified context,也就是雖然有十個類別,但是學習到的learnable prompt 都是相同的;
還有一種class-specific context就是不同的類別對應一種learnble prompt。
還考慮了[class]在句子中的不同位置:mid or end.
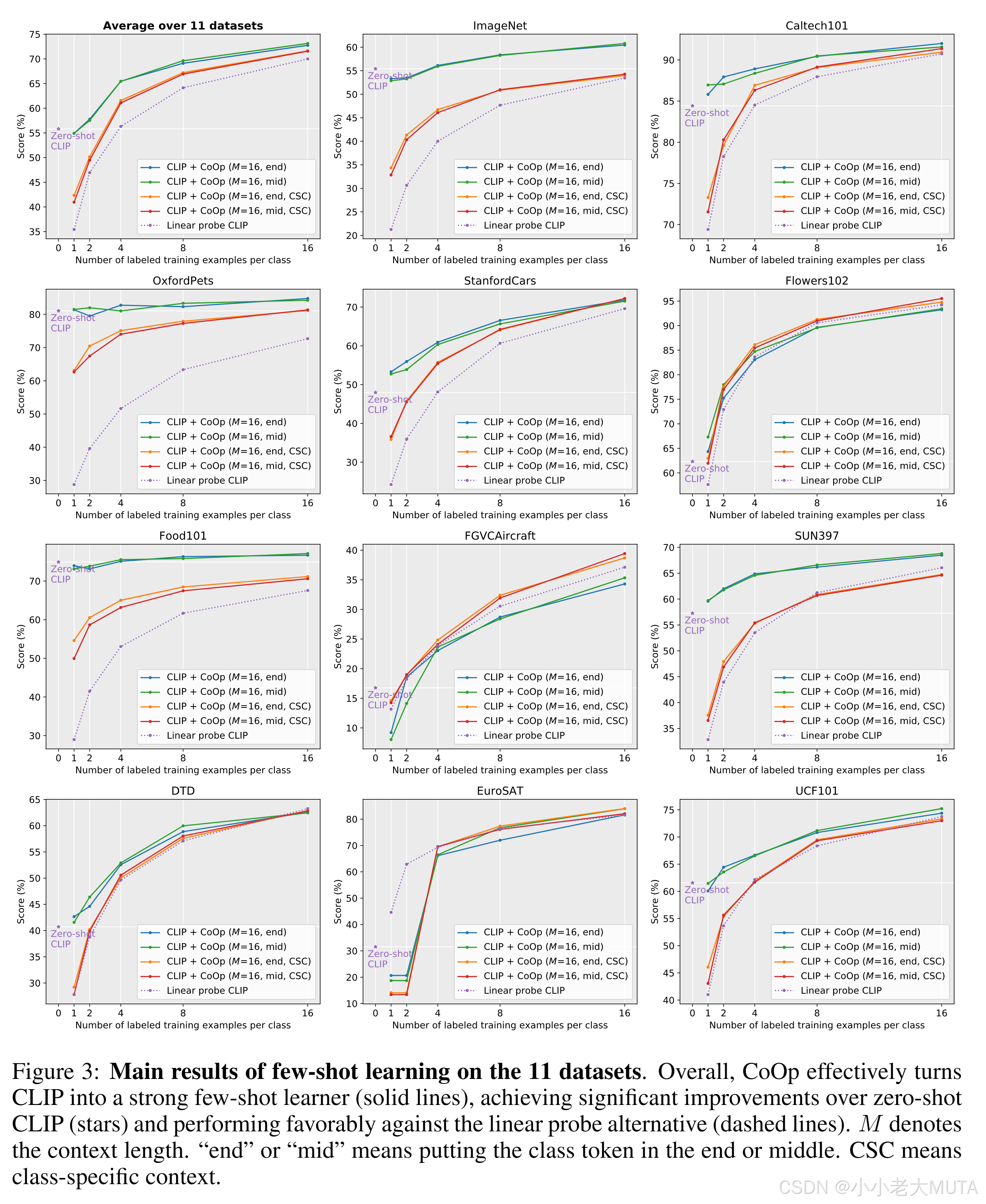
下面是實驗結果:
都是少樣本訓練(0-16個樣本量)
- ?大部分數據集下, CoOp的效果會明顯好于 Linear Probe 形式。且對于 Base model,只有在 8 到 16個 數據集以上的 Few-Shot 才會比 CLIP 的 Zero-Shot 更具優勢。
- Prompt詞語的 語句序列構成, [CLASS] 在中間 和 在末尾 影響較少,說明 文本Encoder 對于 Prompt詞的排序序列 有更強的魯棒性。
- 統一可學習向量unfiied context 與特定可學習向量class-specific context?相比, ?明顯發現 unified context 的效果會更好一些。
結果3 是因為:訓練的數據參數比?統一可學習向量?多的多,然而在 Few-Shot 數據量明顯不夠,如果要對class-specific context有更好的效果,就需要更多的參數來去擬合。
![[論文閱讀] 人工智能 + 軟件工程 | 開源軟件中的GenAI自白:開發者如何用、項目如何管、代碼質量受何影響?](http://pic.xiahunao.cn/[論文閱讀] 人工智能 + 軟件工程 | 開源軟件中的GenAI自白:開發者如何用、項目如何管、代碼質量受何影響?)












![[Element]修改el-pagination背景色](http://pic.xiahunao.cn/[Element]修改el-pagination背景色)




和`SysVinit ` 筆記250718)
