導語
RabbitMQ 作為開源消息隊列的標桿產品,憑借靈活的路由機制與高可用設計,支撐著海量業務場景的消息流轉。而經典隊列(Classic Queue) 作為 RabbitMQ 最基礎、應用最廣泛的隊列類型,其底層存儲機制直接決定了消息處理的性能邊界與可用性上限。
理解經典隊列的存儲架構,不僅是掌握 RabbitMQ 核心原理的關鍵,更為生產環境的運維優化提供了理論支撐。本文將從文件目錄結構、存儲格式定義、讀寫流程到運維實踐策略,全面解析經典隊列的底層存儲實現邏輯,幫助讀者深入理解其在消息生命周期管理中的核心作用。
經典隊列介紹
RabbitMQ 作為一款歷史悠久的開源消息隊列,被廣泛應用于各個領域。在 RabbitMQ 中,用戶使用虛擬主機(Vhost)隔離資源,交換機負責路由消息,隊列則是消息存儲的最小單元。
用戶通過客戶端與 RabbitMQ 的服務端建立連接后,基于通道(Channel)實現消息的高效交互:生產者經過通道將消息發送至交換機,由交換機按綁定規則路由至目標隊列;消費者則通過通道從隊列中拉取消息,完成業務邏輯處理。
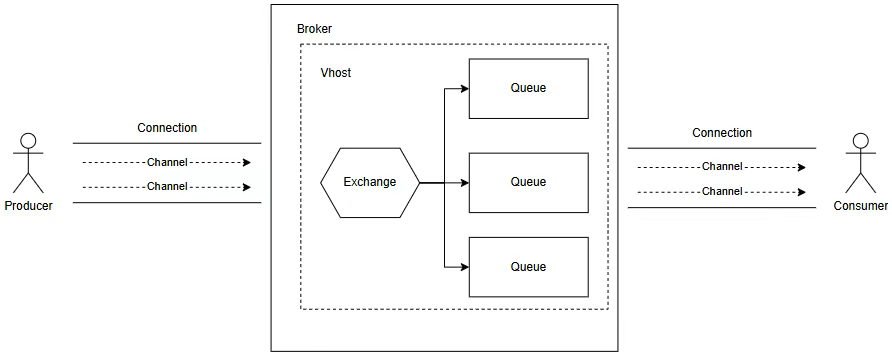
在這一過程中,隊列作為消息生命周期的核心載體,衍生出三種差異化實現:
-
經典隊列(Classic Queue):采用輕量級索引與共享存儲架構,在單機性能與存儲效率間取得平衡,適用于高吞吐非強一致性場景;
-
仲裁隊列(Quorum Queue):基于 Raft 協議實現多副本強一致性,保障關鍵業務數據不丟失,適用于金融交易、訂單管理等關鍵業務;
-
流隊列(Stream Queue):以日志結構存儲消息流,支持回溯消費與持久化流處理,適用于實時數據分析場景。
經典隊列作為使用頻率最高的隊列,了解它的存儲機制對于理解其可用性和性能至關重要,接下來將從存儲架構、文件格式、讀寫流程等維度,深入解析經典隊列的底層實現邏輯。
存儲架構解析
目錄結構
RabbitMQ 通過虛擬主機(Vhost)實現資源隔離,每個 Vhost 有獨立的物理存儲目錄,其典型結構如下:
vhost_name/
├── msg_store_persistent/ # 共享存儲目錄,存儲大消息
│ ├── 0.rdq # 共享存儲文件
│ └── 1.rdq # 支持文件滾動
└── queues/ # 隊列專屬存儲目錄└── queue_name/ # 單個隊列目錄├── queue_name.qi # 隊列索引文件└── queue_name.qs # 隊列存儲文件
msg_store_* 是共享存儲目錄,顧名思義是這個 Vhost 下所有隊列共享的存儲。由于 Exchange 可能會將同一條消息路由到不同的隊列,而將同一條消息存儲多次會增加磁盤空間占用,因此經典隊列會將大小超過某個閾值的消息存儲在共享存儲下,通過引用計數來管理這部分消息。
每個隊列在 queues 目錄下都有屬于自己的目錄,隊列目錄下主要有兩類文件:
-
隊列存儲:名稱為 *.qs 的文件,負責存儲這個隊列中消息大小小于這個閾值的消息。
-
隊列索引:名稱為 *.qi 的文件,負責存儲消息元數據和消息所在位置。隊列索引存儲了消息的偏移或唯一標識,通過它們可以定位到消息在隊列存儲或共享存儲中的位置,索引文件中的 Entry 和存儲文件中的 Entry 因此在邏輯上構成了一對一的映射關系。
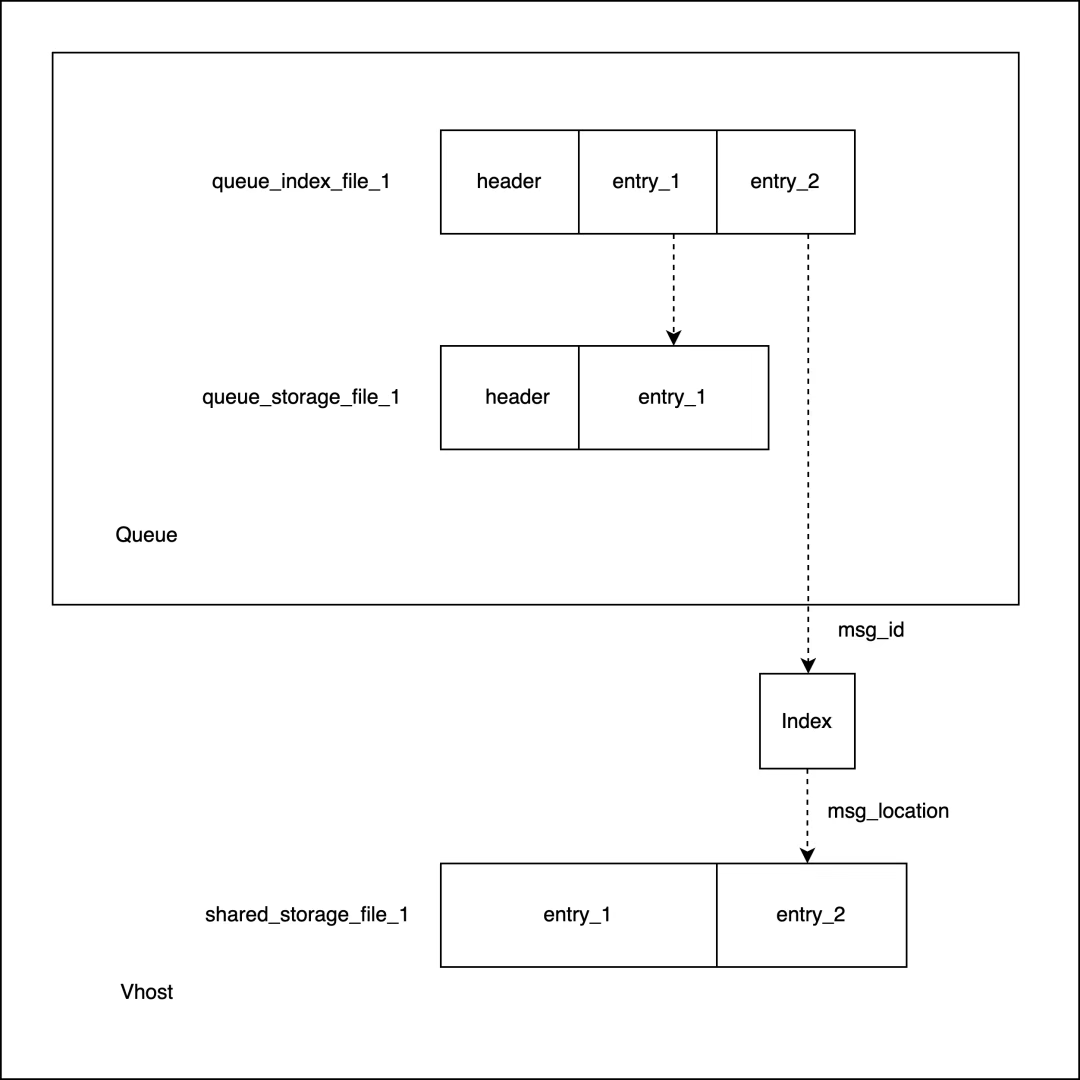
隊列索引
隊列索引文件由一個 Header 和若干 Entry 組成,Entry 的數量由 classic_queue_index_v2_segment_entry_count 這一參數控制,默認為4096。Entry 有兩種類型:Publish Entry 和 Ack Entry。
生產者將消息成功發送到隊列后會產生一個 Publish Entry,隊列將這條消息投遞給消費者并且得到消費者確認后會使用 Ack Entry 覆蓋原來的 Publish Entry,代表這條消息可以被刪除。
Publish Entry 存儲了這條消息的元數據,包括 MsgId、SeqId、存儲位置、消息屬性和是否持久化的標識。
MsgId 是 RabbitMQ 為每條消息隨機生成的 GUID,用來確定消息在共享存儲的位置。
SeqId 是這條消息在隊列中的序號,用來決定消息在隊列索引和隊列存儲中的位置。
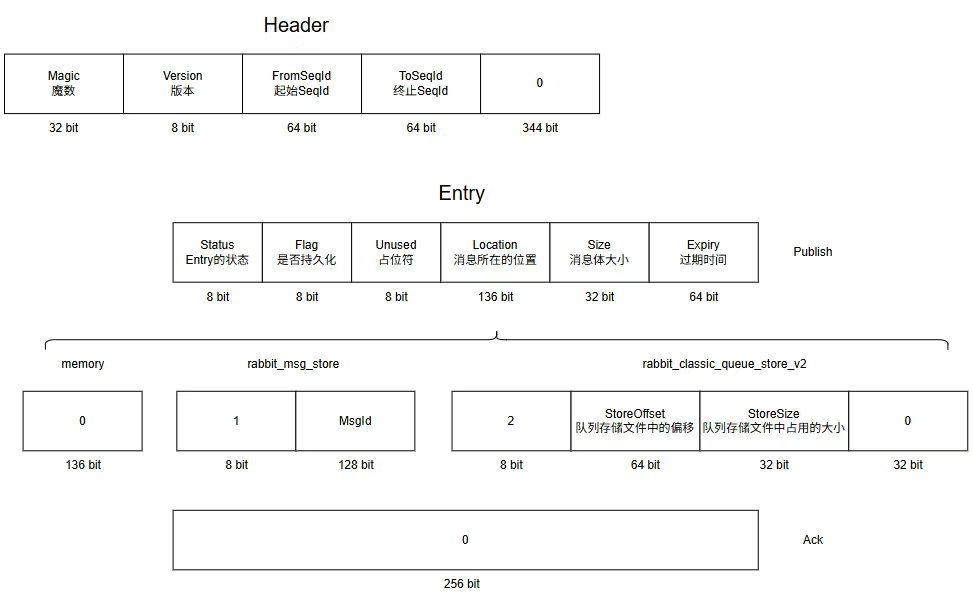
隊列存儲
隊列存儲文件和索引文件是一對一的關系,當隊列刪除它的索引文件時,也會刪除對應的存儲文件。隊列存儲文件的結構與索引文件類似,也是由 Header 和 Entry 構成。Header 和 Entry 的具體組成如下所示。

共享存儲
ETS 是 Erlang 內置的單機 KV 存儲,共享存儲使用 ETS 維護了兩個組件:
-
Index:是 MsgId 到消息位置的映射。
-
FileSummary:文件到文件統計信息的映射。
經典隊列在讀取消息時通過索引文件中的 Publish Entry 獲取到 MsgId 后還需要從 Index 中獲取消息的具體位置,包括這條消息所在的文件、偏移以及它的引用計數。相同 MsgId 的多條消息只會被寫入一次,刪除消息時,它的引用計數會被減一。文件統計信息中記錄了文件中有效數據的數量,這在整理文件時會被用到。
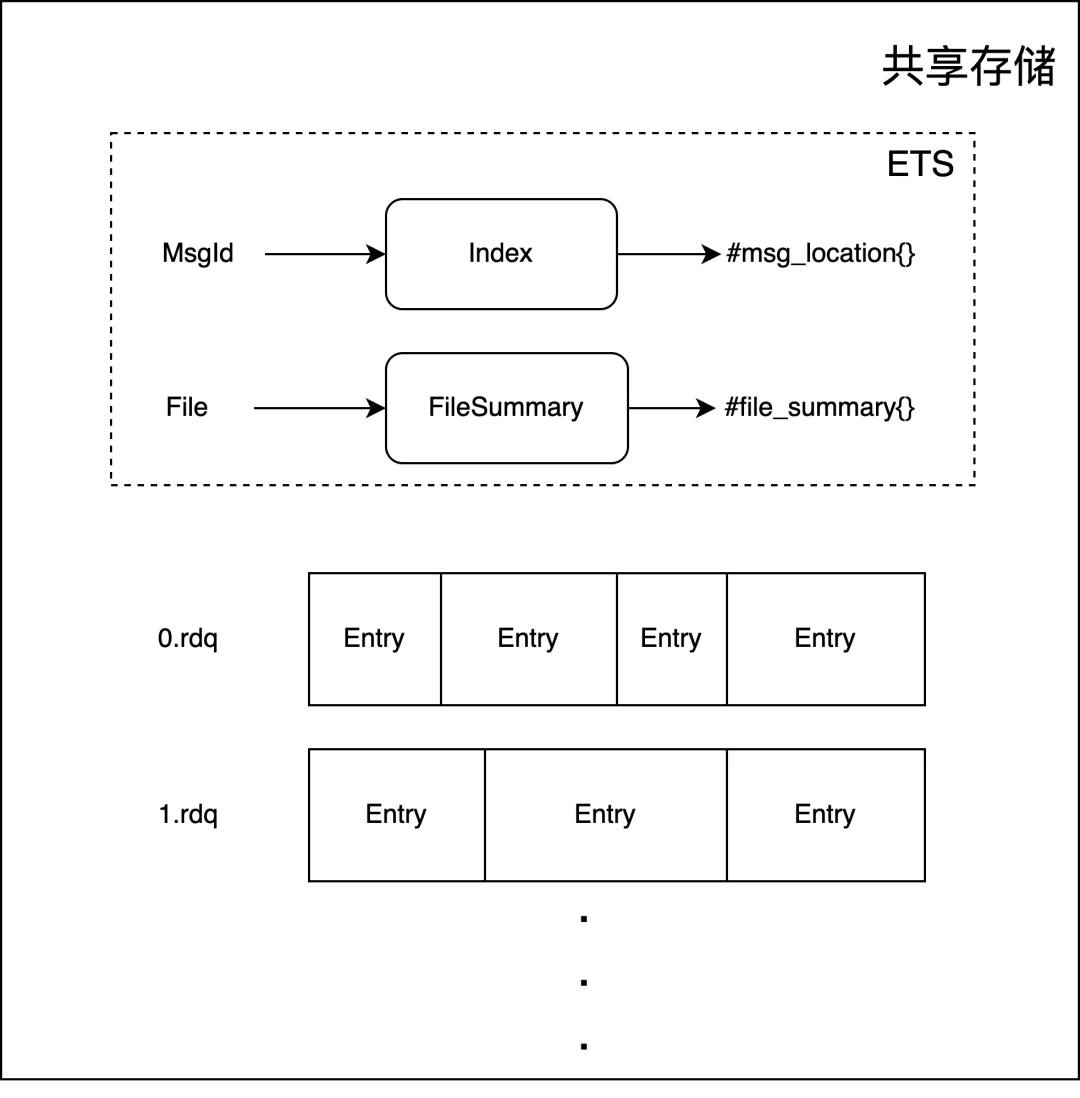
共享存儲文件的大小由參數 msg_store_file_size_limit 控制,默認為16MB。每個文件由若干個 Entry 組成,每個 Entry 的具體組成如下所示。

核心工作流程
消息寫入
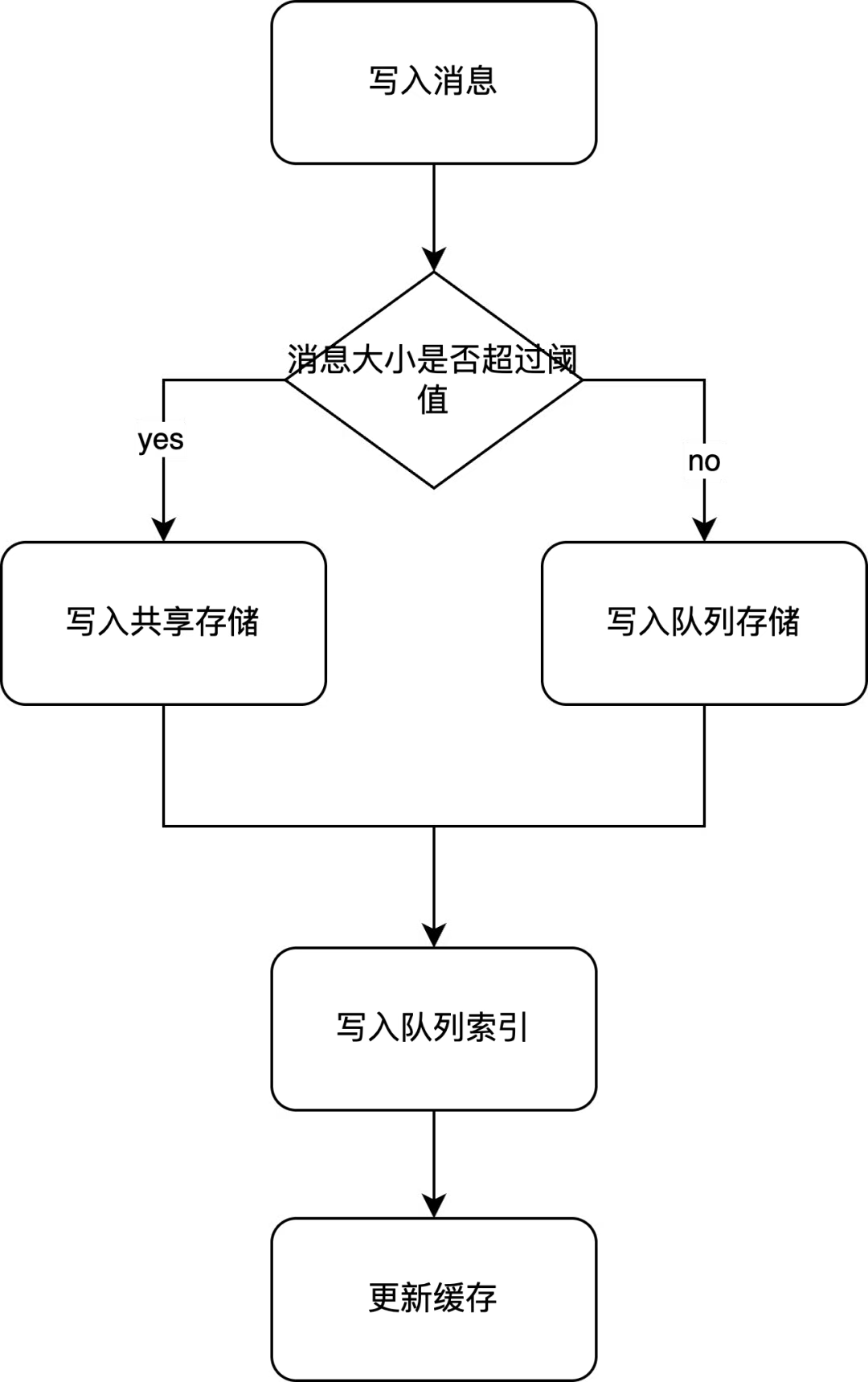
RabbitMQ 根據消息大小決定將消息寫入到哪個存儲。如果消息大小大于或等于某個值(由參數 queue_index_embed_msgs_below 控制,默認為4KB),RabbitMQ 會將其存于共享存儲中,否則會存于隊列存儲中。
將消息寫入存儲時會直接寫到內部緩沖區:
-
隊列存儲內部的緩沖區大小由參數 classic_queue_store_v2_max_cache_size 控制,默認為512KB。
-
共享存儲內部的緩沖區大小則固定為1MB。將消息寫入到共享存儲時除了需要寫入到緩沖區外,還需要更新它內部的 Index 和 FileSummary 組件。
緩沖區大小超過限制后會 Flush 其中的數據,值得注意的是,Flush 時不會調用 Fsync,而是調用 Write 將數據寫入到操作系統的 Page Cache 上。這種方式通過犧牲數據安全性以獲得更低的延遲,如果需要更強的數據安全性應使用仲裁隊列。
存儲寫入完成后需要在隊列索引文件中寫入 Publish Entry,此時消息被認為成功寫入了。之后還要更新內存中的消息緩存,以加速消息讀取。
消息讀取
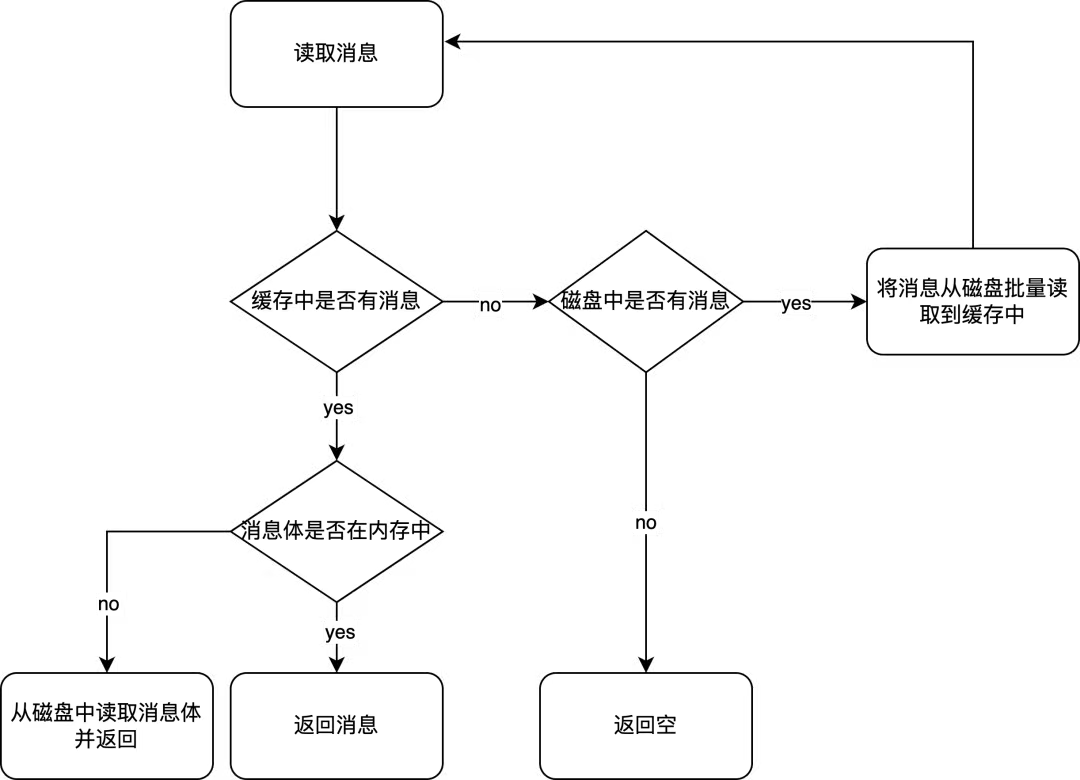
經典隊列在內存中維護了專門的緩存來提升讀取性能,底層存儲會根據隊列的消費速率批量讀取不超過2048條消息到緩存中。讀取消息時會先檢查緩存中是否有這條消息,如果有則直接返回,否則會先將消息批量讀取到緩存。
將消息從磁盤批量讀取到內存中需要先到隊列索引中讀取元數據,然后分別到隊列存儲和共享存儲中讀取消息體,并將它們組裝到一起。即便緩存中有消息,但是實際的消息體仍然可能不在緩存中,因為過大(>12KB)過少(<10條)的消息的消息體并不會被讀到緩存里,需要在投遞消息時逐條去磁盤中讀取消息體。
文件整理
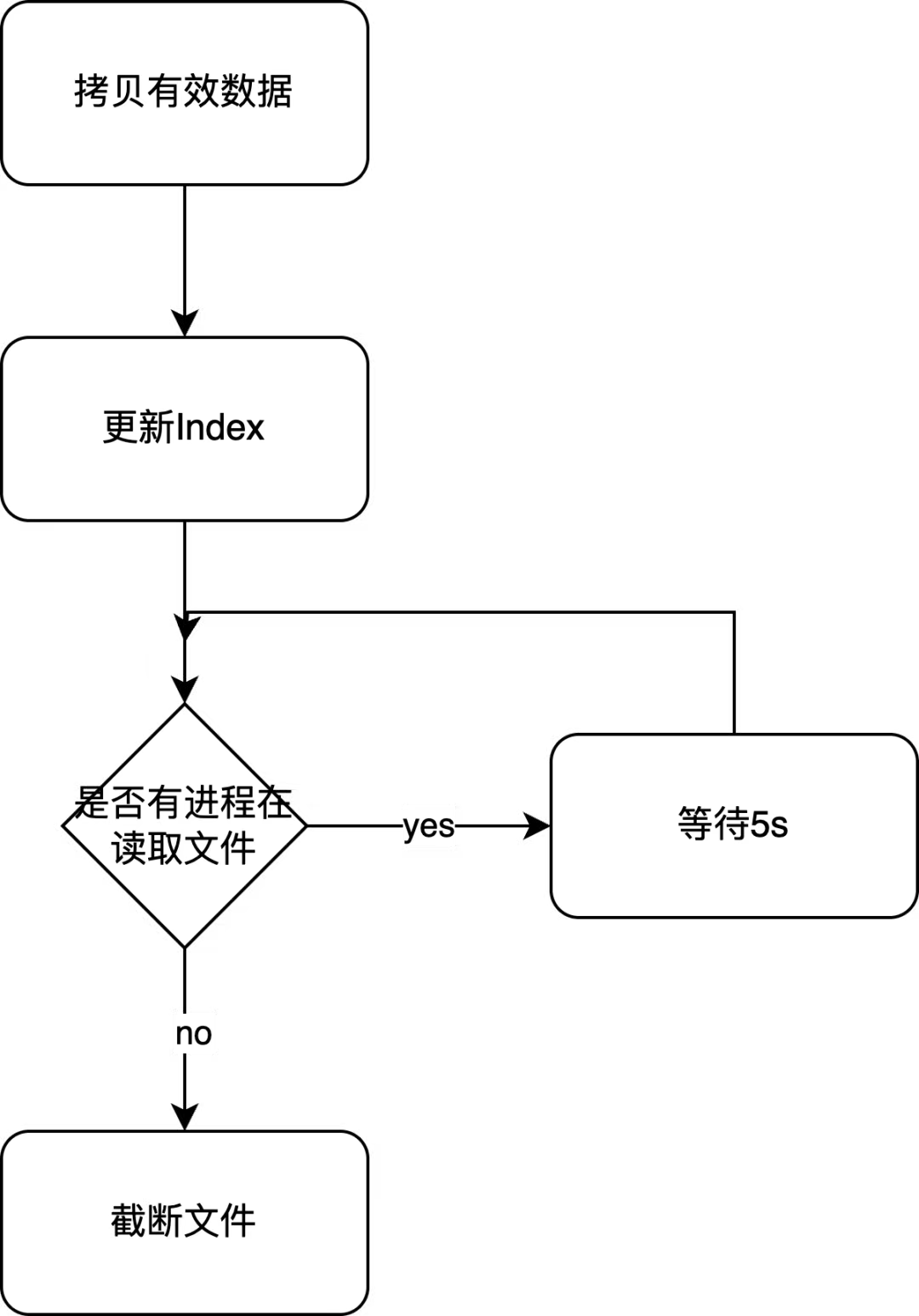
共享存儲會定時整理有效數據占比低于一半的文件以回收空間。整個過程分為三步:
- 將文件末尾的有效數據拷貝到文件前面的無效數據處。
- 更新 Index 組件。
- 在沒有進程讀取文件后截斷文件。
RabbitMQ 會將文件中的無效數據置0,稱為空洞(blank holes)。在文件整理時,RabbitMQ 從最后一條有效消息開始查看其是否能填補前面的空洞,如果可以就將其拷貝到前面,如果它比前面的任何一個空洞都大,那么這一次的文件整理將無法釋放任何空間,這是為了防止意外覆蓋被移動過的消息。Index 組件中存儲了消息的位置,拷貝完成后需要更新對應消息的位置。在沒有進程讀取文件后就可以截斷這個文件以節省磁盤空間。
運維實踐
發送確認
為了提高消息發送的可靠性,我們推薦用戶打開發送確認(Confirm)。RabbitMQ 會在將消息從緩沖區 Flush 到磁盤后向客戶端發送 Confirm,此時生產者可以認為這條消息已經被成功發送到隊列。
消費確認
為了提高消息消費的可靠性,我們推薦用戶打開手動確認(Manual Ack)。RabbitMQ 在收到 Ack后會寫入 Entry 到隊列索引中,只有在索引文件中的所有 Publish Entry 全部被 Ack 后,才會刪除該文件。如果消費者在發送 Ack 前宕機了,RabbitMQ 會重復投遞這條消息,確保消息能真正被消費掉。未被客戶端 Ack 的消息會堆積在內存中,如果數量過多則可能觸發內存水位限制,甚至導致服務端 OOM。因此在用戶打開手動確認后,我們建議用戶設置一次最多能預取(prefetch count)的消息數量,避免大量消息堆積在客戶端和服務端內存中。
保證隊列盡可能短
保持生產和消費速率一致可以減少消息堆積。RabbitMQ 會在發現索引文件中的消息全部被消費后刪除索引文件和對應的存儲文件,這樣可以減少磁盤空間占用。隊列的堆積數量少意味著多數讀取都可以從緩存中直接讀取到消息體,從而提升讀取性能。
總結
本文全面探討了 RabbitMQ 經典隊列的底層存儲機制,包括其整體架構、實現原理及運維實踐。經典隊列的底層存儲由隊列索引和消息存儲兩大模塊構成,其中消息存儲又細分為共享存儲和隊列存儲,通過精心設計的文件結構和內存管理策略,實現了高效的消息讀寫與存儲管理。文章詳細解析了隊列索引、消息存儲(包括共享存儲和隊列存儲)的文件結構,介紹了消息讀取與寫入的流程,以及文件整理的邏輯。在運維實踐方面,強調了發送確認、消費確認與保持隊列盡可能短的重要性,并給出了相應的配置建議。希望通過本文的介紹,可以幫助大家深入理解 RabbitMQ 經典隊列的底層存儲機制,為實際應用中的性能優化與故障排查提供有力支持。
)




 v3.0.2 新特性 為非類npm環境引入 globalTypesPath 選項)






)


線性表(上):SeqList 順序表)

)
)
