1.C++代碼優化策略總結
- 編譯器方面:用好的編譯器并用好編譯器(支持C++11的編譯器,IntelC++(速度最快)
- GNU的C++編譯器GCC/G++(非常符合標準),Visual C++(性能折中),clang(最年輕Mac OS x)。
- 算法方面:使用更好的算法。?
- 數據結構優化:使用更好的數據結構(不同的數據結構在使用內存管理器的方式也有所不同)。
- 使用更好的庫(熟悉和掌握標準C++模板庫對于進行性能優化的開發員是必須的技能,Boost Project 和 Google Code 公開了很多有用的庫)。
- 內存優化:減少內存分配和復制(減少對內存管理器的調用是一種非常有效的優化手段)。
- 優化內存管理(內存管理器的調度,豐富的API)。
- 移除計算(對于單條的C++語句進行優化)。
- 多線程使用:提高并發性(多個處理核心執行指令)。
- 優化鎖的使用:減少鎖的使用,減少鎖的范圍,使用細粒度的鎖,采用無鎖隊列,原子鎖或線程局部存儲,鎖數據而不是代碼。
2.影響計算機優化的行為
- 計算機的物理組成本身對計算機性能的限制。
- 計算機的主內存是比較慢的(通往主內存的接口是限制執行速度的瓶頸(馮*諾伊曼瓶頸),(摩爾定理)每年處理器的核心的數量都會增加,但是計算機的性能未必會提高,因為這些核心只是等待訪問內存的機會(內存墻memory wall))。?
- 計算機內存的訪問方式(并非以字節為單位),某些內存訪問會比其他的更慢(分為一級高速緩存(cache memory)、二級高速緩存、三級高速緩存、主內存、磁盤上的虛擬內存頁)。
- 內存的容量是有限的,每個程序都會與其他程序競爭計算機資源,計算比做決定快。?
- 在處理器中,訪問內存的性能開銷遠比其他操作的性能開銷大,非對齊訪問所需要的時間是所有字節都在同一字節中的兩倍。?
- 訪問頻繁使用的內存地址的速度比訪問非頻繁使用的地址快,訪問相鄰地址的內存的速度比訪問相互遠隔的地址的內存塊。?
- 訪問線程間共享的數據比訪問非共享的數據資源慢很多。當并發線程共享數據時,同步代碼降低了并發量。?
- 有些語句隱藏了大量的計算,從語句的外表上看不出語句的性能開銷會有多大。
3.性能測量
- 90/10規則:一個程序會花費90%的運行時去執行10%的代碼。
- 只有正確且精確的測量才是準確的測量。?
- 在Windows上,clock()函數提供了可靠的毫秒級的時鐘計時功能。在Windows8和之后的版本中,GetSystemTimePreciseAsfileTime()提供了亞微秒的計時功能。
- 計算一條C++語句對內存的讀寫次數,可以估算出一句C++ 語句的性能開銷。
4.優化方法
(1)優化熱點語句
- 緩存循環結束條件值

- 從循環中移除不變性代碼

- 從循環中移除無謂的函數調用

- 從循環中移除隱含的函數調用

(2)減少函數調用開銷
函數調用開銷分析:
盡管執行函數體的開銷可能會非常大,但是調用函數的開銷與調用大多數 C++ 語句的開銷 一樣,是非常小的。不過,當函數被多次調用時,累積的開銷可能會變得巨大,因此減少 這種開銷非常重要
函數調用流程
(1) 執行代碼將一個棧幀推入到調用棧中來保存函數的參數和局部變量。
(2) 計算每個參數表達式并復制到棧幀中。
(3) 執行地址被復制到棧幀中并生成返回地址。
(4) 執行代碼將執行地址更新為函數體的第一條語句(而不是函數調用后的下一條語句)。
(5) 執行函數體中的指令。
(6) 返回地址被從棧幀中復制到指令地址中,將控制權交給函數調用后的語句。
(7) 棧幀被從棧中彈出。
函數調用的基本開銷

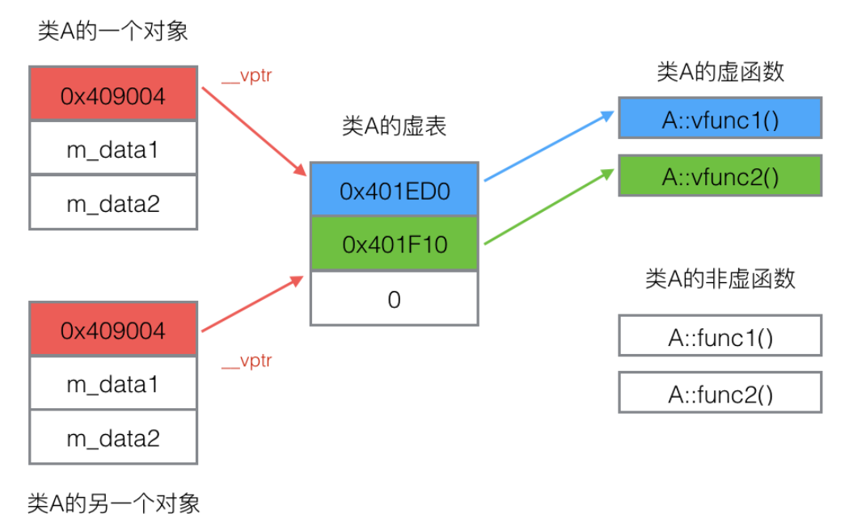
虛函數調用開銷

(3)簡短地聲明內聯函數
(4)在使用之前定義函數:當編譯器編譯對某個函數的調用時發現該函數已經被定義了,那么編譯器能夠自主選擇內聯這次函數調用
(5)移除未使用的多態性
(6)放棄不使用的接口
(7)用switch替代if-else if-else
(8)避免使用PIMPL慣用法,編譯時間少,運行增加

(8)其他常用優化方法

4.多線程優化-未完待續









)





)
)

)
