數據加載與保存
通用方式:
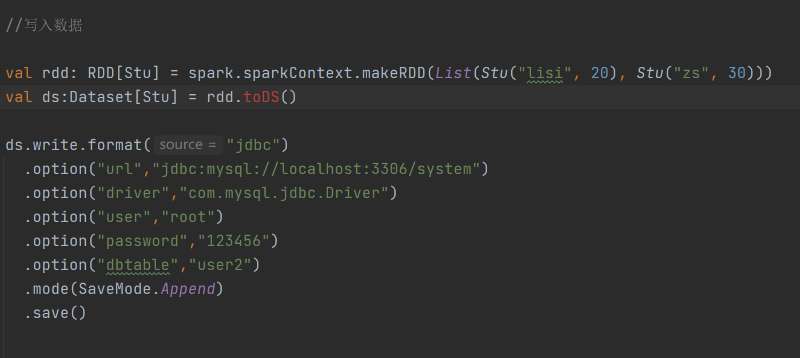
? ? ? ?通過?spark.read.load?和?df.write.save?實現數據加載與保存。可利用?format?指定數據格式,如?csv?、?jdbc?等;?option?用于設置特定參數,像?jdbc?格式下的數據庫連接信息;?load?和?save?則分別指定數據路徑。保存時還能使用?SaveMode?包含?ErrorIfExists?、?Append?、?Overwrite?、?Ignore?等模式 。
Parquet:
? ? ? 作為默認數據源,Parquet是列式存儲格式,適合存儲嵌套數據。加載和保存數據時,若為Parquet文件,無需指定?format?,按默認方式操作即可。
JSON:
? ? ? Spark SQL可自動推測JSON數據集結構,加載為?Dataset[Row]?。但要求JSON文件每行是一個JSON串,通過?spark.read.json()?加載 。
CSV:
? ? ? 讀取CSV文件時,可配置列表信息,如設置分隔符、推斷數據類型、指定表頭,使用?format("csv")?結合?option?設置相關參數。
- MySQL:
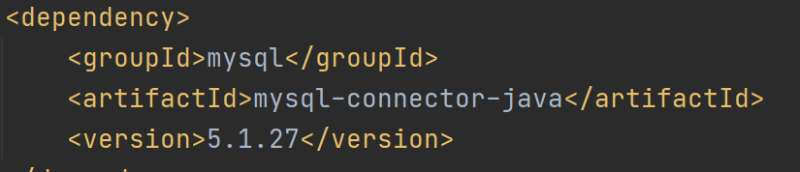
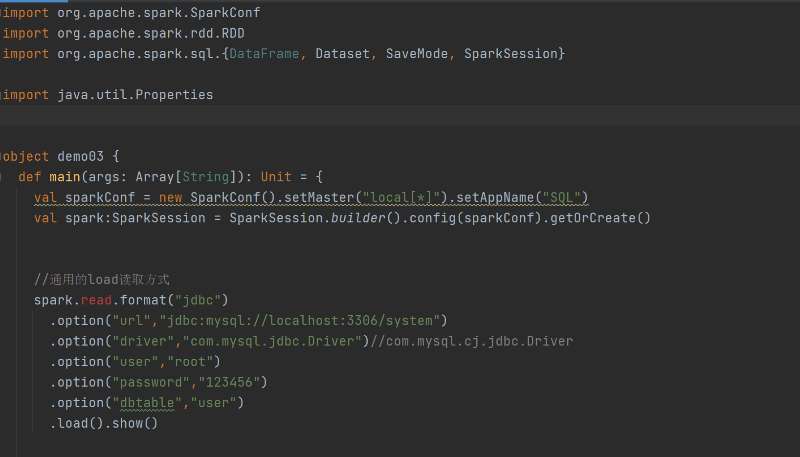
? ? ?借助JDBC,Spark SQL能從MySQL讀取數據創建?DataFrame?,計算后也可寫回。操作前需導入?mysql-connector-java?依賴,按特定語法編寫代碼實現數據讀寫。
代碼案例
導入依賴
?
?
?
?
Spark-SQL連接Hive
內嵌Hive:
使用Spark內嵌Hive無需額外配置,可直接使用,但實際生產中較少采用。
外部Hive:
在spark-shell中連接外部Hive,需將?hive-site.xml?拷貝到?conf/?目錄并修改連接地址,把MySQL驅動復制到?jars/?目錄,拷貝?core-site.xml?和?hdfs-site.xml?到?conf/?目錄,最后重啟?spark-shell?。- Spark beeline:Spark Thrift Server兼容HiveServer2,部署后可用beeline訪問。連接步驟與連接外部Hive類似,需配置相關文件并啟動Thrift Server,再用?beeline -u jdbc:hive2://node01:10000 -n root?連接 。- Spark-SQL CLI:在Spark目錄下,將MySQL驅動放入?jars/?,?hive-site.xml?放入?conf/?,運行?bin/?目錄下的?spark-sql.cmd?即可啟動,能直接執行SQL語句。
代碼操作Hive:
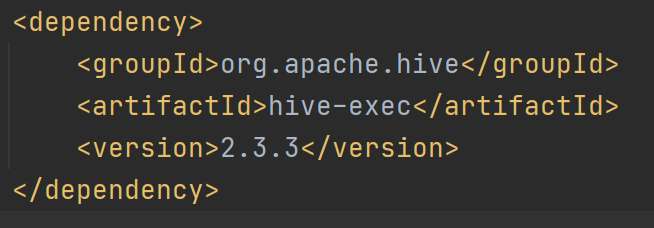
先導入?spark-hive_2.12?和?hive-exec依賴,將hive-site.xml拷貝到resources目錄中,在代碼中啟用hive支持
代碼案例
導入依賴
?
?


Java/python/JavaScript/C++/C語言/GO六種最佳實現)










(Go語言版))





