1、? 軟件開發生命周期
軟件定義時期:包括可行性研究和詳細需求分析過程,任務是確定軟件開發工程必須完成的總目標,具體分為問題定義、可行性研究、需求分析等
軟件開發時期:軟件的設計與實現,分為概要設計、詳細設計、編碼、測試等
軟件運行和維護:把軟件產品移交給用戶使用
2、? 軟件系統的文檔
分為用戶文檔和系統文檔,用戶文檔主要描述系統功能和使用方法,不涉及功能怎樣實現的,系統文檔描述系統設計、實現和測試等內容
3、? 軟件工程過程是指為獲得軟件產品,在軟件工具的支持下由軟件工程師完成的一系列軟件工程活動,包括以下4個方面
P(Plan)軟件規格說明:規定軟件的功能及其運行時的限制
D(Do)軟件開發:開發出滿足規格說明的軟件
C(Check)軟件確認:確認開發的軟件能夠滿足用戶的需求(有效性驗證)
A(Action)軟件演進:軟件在運行過程中不斷改進以滿足用戶的客戶新的需求
4、? 軟件系統工具:
通常可以按軟件過程活動將軟件工具分為軟件開發工具、軟件維護工具 、軟件管理和軟件支持工具。
軟件開發工具:需求分析工具、設計工具、編碼與排錯工具。
軟件維護工具:版本控制工具、文檔分析工具、開發信息庫工具、逆向工程工具、再工程工具。
軟件管理和軟件支持工具:項目管理工具、配置管理工具、軟件評價工具、軟件開發工具的評價和選擇。
按描述需求定義的方法可將需求分析工具分為基于自然語言或圖形描述的工具和基于形式化需求定義語言的工具。
5、? 可行性分析包括四個方面:經濟可行性、技術可行性、法律可行性、用戶使用可行性
6、? 軟件能力成熟度模型集成CMMI(Capability Maturity Model Integration for Software)
| 能力等級 | 特點 |
| Level 1 初始級 | 過程通常是隨意且混亂。組織的成功依賴于組織內人員的能力與英雄主義。常常也能產出能用的產品與服務,但它們經常超出在計劃中記錄的預算與成本。 |
| Level 2 已管理級 | 組織要確保策劃、文檔化、執行、監督和控制項目級的過程,并且需要為過程建立明確的目標,并能實現成本、進度和質量目標。 |
| Level 3 已定義級 | 企業能夠根據自身的特殊情況定義適合自己企業和項目的標準流程,將這套管理體系與流程予以制度化,同時企業開始進行項目積累,企業資產的收集 |
| Level 4 量化管理級 | 組織建立了產品質量、服務質量以及過程性能的定量目標,這一成熟度的特點是對過程性能的可預測性 |
| Level 5 優化級 | 企業的項目管理達到了最高的境界。關注與通過增量式的創新式的過程與技術改進,不斷改進過程性能。組織使用從多個項目收集來的數據對整體的組織績效進行關注。 |
6、? 軟件項目管理:為了使軟件項目能夠按照預定的成本、進度、質量順利完成,而對人員、產品、過程和項目進行分析和管理的活動。
范圍管理過程:范圍計劃編制、范圍定義(產品范圍、工作范圍)、創建WBS(工作分解結構,WBS樹形結構中最底層的被稱為工作包,是最低層次的可交付成果,它應當由唯一主題負責完成)、范圍確認、范圍控制
成本管理過程包括:成本估算、成本預算、成本控制。成本估算是對完成項目活動所需資金進行近似估算,估算方法有自頂向下估算、自底向上估算、差別估算;成本預算是將總的成本估算分配到各項活動和工作包上,來建立一個成本的基線,包含直接成本和間接成本;成本控制
進度(時間)管理過程:活動定義、活動排序、活動資源估算、活動歷時估計、制定進度計劃(涉及任務活動圖,類似前驅圖)、進度控制
質量管理:影響軟件質量的因素分為3組,分別是產品運行、產品修改、產品轉移。其中產品運行包含正確性、健壯性、效率、完整性、可用性、風險;產品修改包含可理解性、可維護性、靈活性、可測試性;產品轉移包含可移植性、可再用性、互運行性
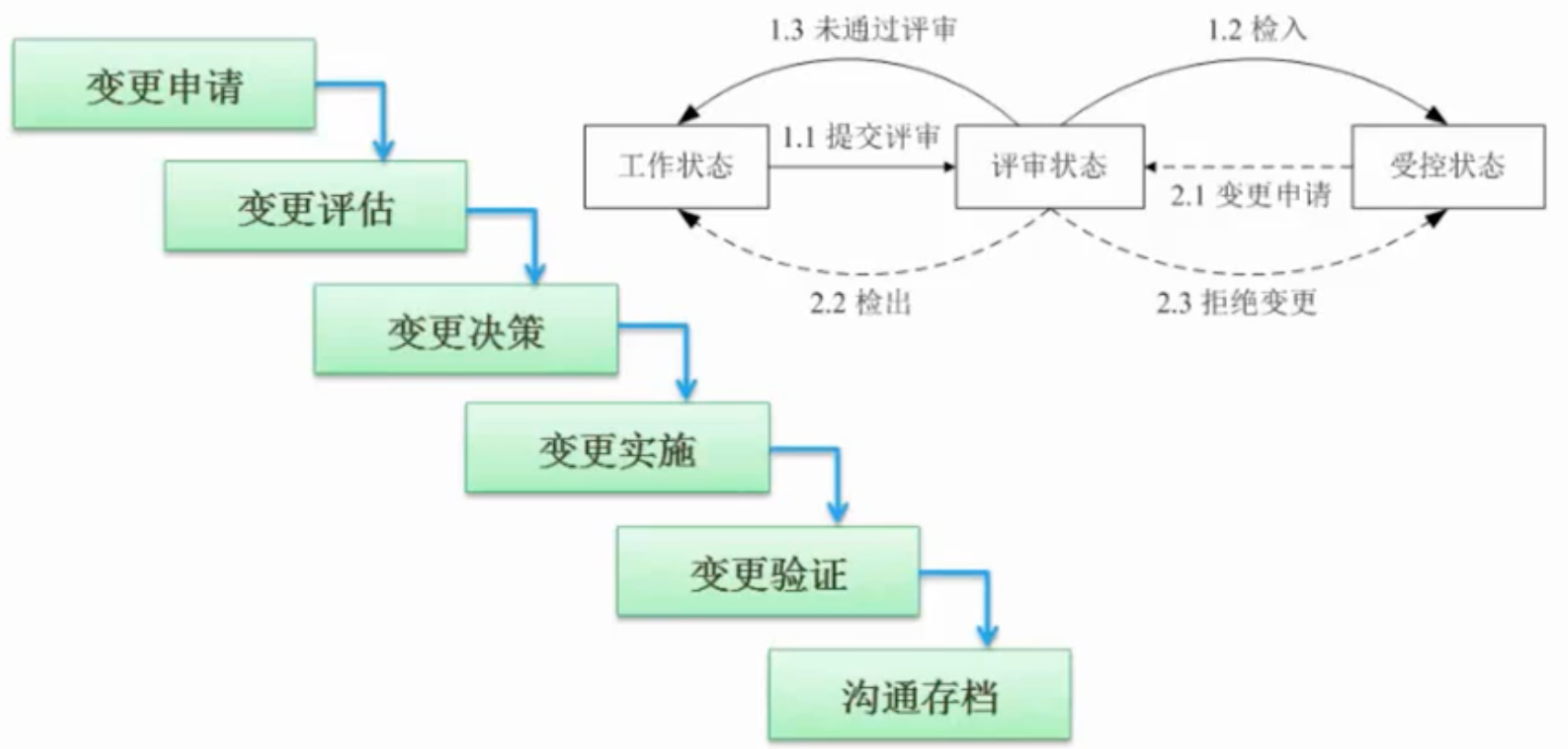
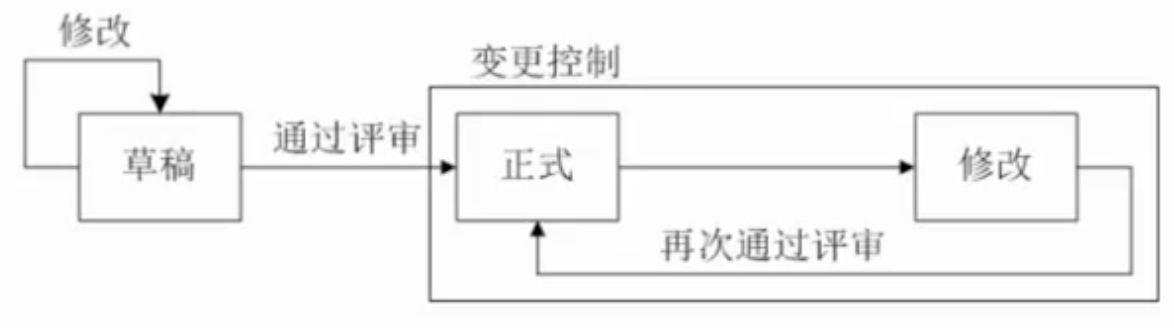
配置管理:一種標識、組織和控制修改的技術,應用于整個軟件工程過程。配置管理核心內容包括版本控制(主要功能是追蹤文件的變更,記錄每個狀態變更的日期和變更者)和變更控制(不是控制變更的發生,而是對變更進行管理,確保變更有序進行)。配置管理系統中管理的是配置項(包括各種文檔、代碼和運行所需數據,主要屬性有名稱、標識符、版本、作者、日期等),所有的配置項都被保存在配置庫里,配置庫分為開發庫(隨便修改)、受控庫(修改需要走變更控制流程)、產品庫(禁止修改)
變更控制流程
版本控制流程
風險管理:主要目標是預防風險。軟件項目風險是指軟件開發過程中遇到的預算和進度等方面的問題以及這些問題對軟件項目的影響。軟件項目風險分為項目風險、技術風險、商業風險。對風險排優先級是根據風險的曝光度來進行的,曝光度等于風險的產生后果乘以風險發生的概率。
7、? 軟件過程模型:為了使軟件生命周期中的各項任務能夠有序地按照規程進行,需要一定的工作模型對各項任務給予規程約束,這樣的工作模型稱為軟件過程模型或軟件開發模型,也叫軟件生命周期模型。軟件開發模型大體可以分為三類,第一種是以軟件需求完全確定為前提的瀑布模型;第二種是在軟件開發初始階段只能提供基本需求時采用的迭代式或漸進式模型,例如噴泉模型、螺旋模型、統一過程模型和敏捷模型等;第三類是以形式化為基礎的變換模型。
瀑布模型(SDLC):是典型的軟件生命周期模型,一般將軟件開發分為需求分析、系統設計、程序設計、編碼實現、單元測試、集成測試、系統測試、運行維護
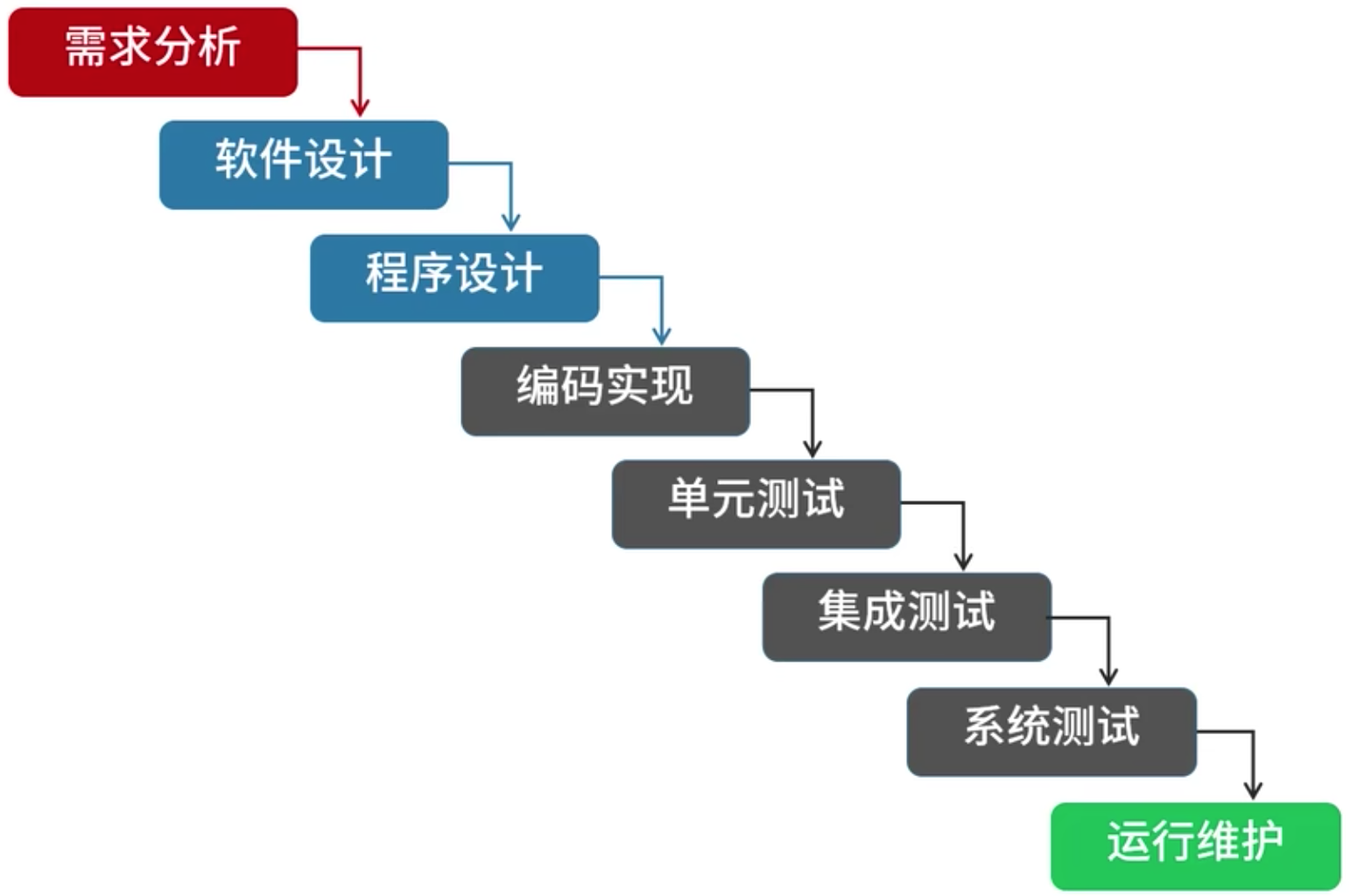
特點:
(1)嚴格區分階段,每個階段因果關系緊密相連
(2)只適合需求明確的項目
缺點:
(1)軟件需求完整性、正確性難確定
(2)嚴格串行化,很長時間才能看到結果
(3)要求每個階段一次性完全解決該階段工作,不現實
原型化模型(Prototype Model)也叫快速原型
原型模型的兩個階段:原型開發階段和目標軟件開發階段
原型分類:拋棄型原型和演化原型

特點:
(1)適合需求不明確的項目
V模型:用于需求明確和需求變更不頻繁的項目
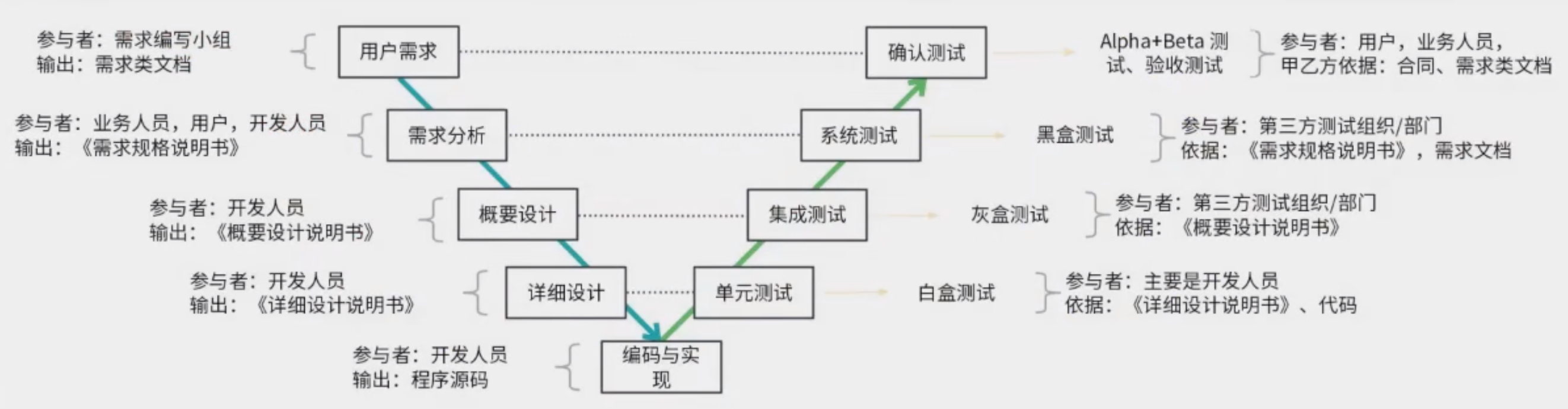
特點:
(1)測試貫穿于始終
(2)測試分階段,測試計劃提前
迭代與增量模型:首先開發核心模塊功能,用戶確認后再開發次核心模塊,最終完成項目開發,即優先級最高的服務最先交付。每一個增量或迭代都是一個完整的開發過程。
增量型:一塊一塊增加
迭代型:一輪一輪變好
敏捷模型(Agile)
價值觀:
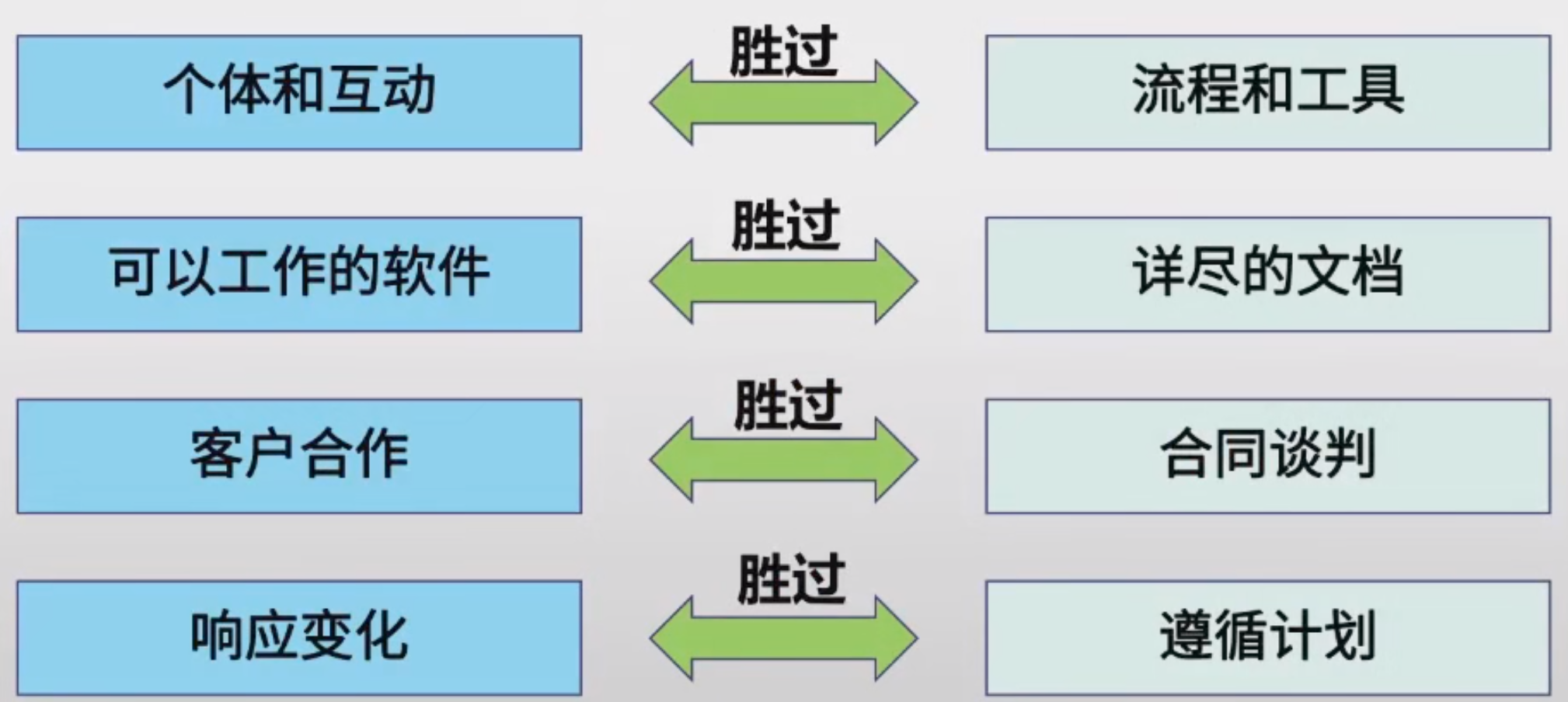
核心思想:
(1)適應型而非可預測型
(2)面向以人為本而非以過程為本
(3)迭代增量式開發過程,以原型開發思想為基礎

具體敏捷方法:
(1)極限編程(Extreme Programming,XP):提倡測試先行
4大價值觀
溝通【加強面對面溝通】
簡單【從簡單做起,不過度設計】
反饋【及時反饋】
勇氣【接受變更的勇氣】
(2)水晶系列方法:提倡機動性的方法,擁有對不同類型項目非常有效的敏捷過程
(3)并列爭球法(Scrum):側重于項目管理,是迭代的增量化過程,把每段時間的一次迭代稱為一個沖刺(Sprint)
(4)特征驅動開發方法(Feature Driven Development,FDD):
認為有效的軟件開發需要3個要素:人、過程和技術
定義了6種關鍵的項目角色:項目經理、首席架構設計師、開發經理、主程序員、程序員和領域專家
5個核心過程:開發整體對象模型、構造特征列表、計劃特征開發、特征設計和特征構建
螺旋模型(Spiral Model):是在快速原型的基礎上擴展而成,它是瀑布模型與快速原型模型的結合。這種模型把整個軟件開發流程分為多個階段,每個階段都由4部分組成:
(1)目標設定:確定目標、方案和約束
(2)風險分析:評價方案、識別風險、消除風險
(3)開發和有效性驗證:風險評估后,為系統選擇開發模型,開發軟件產品
(4)評審:對項目進行評審,以確定是否需要進入螺旋線的下一次回路
特點:
(1)支持大型軟件開發
(2)適用于面向規格說明、面向過程和面向對象的軟件開發方法
統一過程模型(RUP):描述了如何有效地利用商業的、可靠的方法開發和部署軟件,是一種重量級過程。RUP類似一個在線的指導者,它可以為所有方面和層次的程序開發者提供指導方針、模板以及事例支持
RUP軟件開發生命周期是一個二維的軟件開發模型,有9個核心工作流:
(1)業務建模:理解待開發系統所在的機構及商業運作,評估待開發系統對所在機構的影響
(2)需求:定義系統功能及用戶界面,為項目預算及計劃提供基礎
(3)分析與設計:把需求分析的結果轉化為分析與設計模型
(4)實現:把設計模型轉換為實現結果,對開發的代碼做單元測試,將不同實現人員開發的模塊集成為可執行系統
(5)測試:檢查各子系統件的交互、集成,驗證所有需求是否均被正確實現,對發現的軟件質量上的缺陷繼續歸檔,對軟件質量提出改進建議
(6)部署:打包、分發、安裝軟件,升級舊系統。培訓用戶及銷售人員,并提供技術支持
(7)配置與變更管理:跟蹤并維護系統開發過程中產生的所有制品的完整性和一致性
(8)項目管理:為軟件開發項目提供計劃、人員配置、執行、監控等方面的指導
(9)環境:為軟件開發機構提供軟件開發環境,及提供過程管理和工具的支持
RUP把軟件開發生命周期劃分為多個循環,每個循環生成產品的一個新版本,即每個迭代都是一個完整的開發過程。每個循環依次由4個連續的階段組成,分別是:
(1)初始階段:定義最終產品視圖和業務模型,確定系統范圍(生命周期目標)
(2)細化階段:設計及確定系統的體系結構,制定工作計劃及資源要求(生命周期架構)
(3)構造階段:構造產品并繼續演進需求、系統結構、計劃直至產品提交(初始運作功能)
(4)移交階段:把產品提交給用戶使用(產品發布)
RUP模型特點:
(1)用例驅動:需求分析、設計、實現和測試等活動都是用例驅動的
(2)以體系結構為中心:多維的結構,采用多個視圖來描述,典型的4+1視圖模型如下
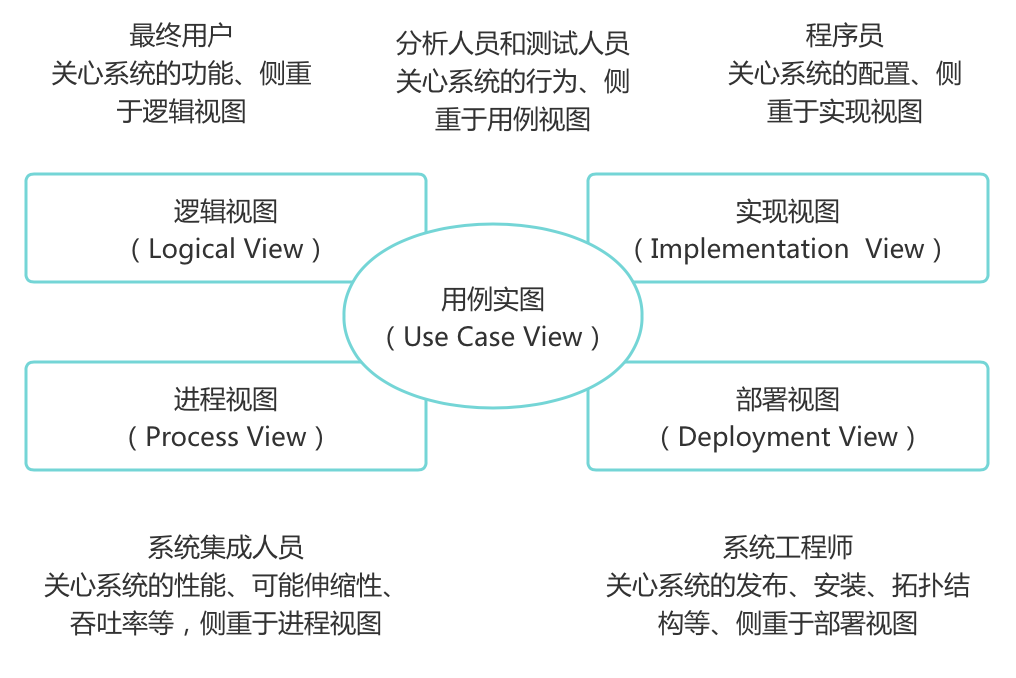
(3)迭代與增量:把整個項目開發分為多個迭代過程
形式化方法模型:建立在嚴格數學基礎上的一種軟件開發方法,它的優越性在于能夠精確地表述和研究應用問題及軟件實現
噴泉模型:一種以用戶需求為動力,以對象作為驅動的模型,適合于面向對象的開發方法,體現了面向對象的迭代和無間隙性
快速應用開發模型(Rapid Application Development,RAD):基于構件化開發與瀑布模型,適用于模塊化較高的系統開發,過程分為業務建模、數據建模、過程建模、應用生成和測試與交付
構件:軟件構件是一 個獨立可交付的功能單元,外界通過接口訪問其提供的服務。軟件構件可以被獨立地部署并由第三方任意地組裝。構件是一組通常需要同時部署的原子構件,一個原子構件是一個模塊和一組資源。原子構件是部署、版本控制和替換的基本單位。原子構件通常成組地部署,但是它也能夠被單獨部署。大多數原子構件永遠都不會被單獨部署,盡管它們可以被單獨部署。相反,大多數原子構件都屬于一個構件家族,一次部署往往涉及整個家族。
模塊、對象和構件的區別:模塊是一組類和可能的非面向對象的結構體,比如過程或者函數,一個模塊是不帶單獨資源的原子構件,一個構件可以包含多個類元素,但是一個類元素只能屬于一個構件

面向構件的編程(COP)需要下列的基本支持:
多態性(可替代性)
模塊封裝性(高層次信息的隱藏)
后期的綁定和裝載(部署獨立性)
安全性(類型和模型安全性)
常用的構件標準主要有:
EJB規范:會話Bean(Session Bean)、實體Bean(Unity Bean)、消息驅動Bean(Message-driven Bean)
COM:微軟公司,兩種對象重用方式(包含、聚合)
CORBA:三個層次分別為對象請求代理、公共對象服務和公共設施
構件的復用過程:
(1)檢索與提取構件
(2)理解與評價構件
(3)修改構件
(4)組裝構件
從構件的外部形態來看,構成一個系統的構件可分為五類:
(1)獨立而成熟的構件:得到實際運行環境多次檢驗的構件,該類構件隱藏了所有接口,用戶只需用規定好的命令進行使用。比如數據庫管理系統和操作系統等。
(2)有限制的構件:該類構件提供了接口,指出了使用的條件和前提,這種構件在裝配時,會產生資源沖突、覆蓋等影響,在使用時需要加以測試,例如各種面向對象程序設計語言中的基礎類庫等。
(3)適應性構件:該類構件進行了包裝或使用了接口技術,處理了不兼容性、資源沖突等,可以直接使用。這種構件可以不加修改地使用在各種環境,例如ActiveX等。
(4)裝配的構件:該類構件在安裝時已經裝配在操作系統、數據庫管理系統或信息系統不同層次上,使用膠水代碼就可以進行連接使用。目前一些軟件商提供的大多數軟件產品都屬于這類。
(5)可修改的構件:這類構件可以進行版本替換。 如果對原構件修改錯誤、增加新功能,可以利用重新“包裝”或寫接口來實現構件的替換。這種構件在應用系統開發中使用得比較多。
構件組裝模型

優點:易擴展、易重用、降低成本、安排任務更靈活
缺點:構件設計要求經驗豐富的架構師、設計不好的構件難重用、強調重用可能犧牲其它指標、第三方構件質量難控制
基于構件的軟件工程(Component-Base Software Engineering,CBSE):使得軟件開發不再是一切從頭開始,開發的過程主要就是構件組裝的過程,維護的過程主要就是構件升級、替換和擴充的過程,其優點是提高了軟件開發的效率。
CBSE方法由五個階段組成:
(1)需求分析和定義。需要重點闡述本系統跟曾經開發過的其他系統的相似性,具有大量可復用的成熟構件。
(2)架構設計。根據上一階段獲得的需求和定義提出架構模型。
(3)構件庫建立。構件獲取的四種途徑:
從現有構件庫中獲取符合要求的構件,直接使用或作適應性修改后使用。構件庫中的構件分類方法有三種:關鍵字分類法、刻面(Facet)分類法和超文本組織方法。因此構件庫的檢索方法也有三種:基于關鍵字的檢索法、刻面檢索法、超文本檢索法。
將遺產工程(Legacy Engineering)中具有潛在復用價值的構件提取出來,得到復用的構件。
從市場上購買現成的商業構件,即COTS(Commercial Off-The-Shelf)構件。
開發新的符合要求的構件。
(4)應用軟件構建。應用軟件的構建過程主要是構件的組裝過程
組裝技術有三種:
基于功能的組裝技術
基于數據的組裝技術
面向對象的組裝技術
組裝方式有三種:
順序組裝:按順序調用已經存在的構件,可用兩個已經存在的構件來創建一個新的構件。上一個構件的輸出,與下一個構件的輸入相兼容。
層次組裝:通常發生在一個構件直接調用另一個構件所提供的服務時。被調用構件的提供接口必須和調用構件的請求接口完全兼容
疊加組裝:通常發生在兩個或兩個以上構件放在一起來創建一個新構件的時候。多個構件合并形成新構件,新構件整合原構件的功能,對外提供新的接口。外部應用可以通過新接口來調用原有構件的接口,而原有構件不互相依賴,也不互相調用。
組裝失配問題:
由構件引起的失配
由連接子引起的失配
由于系統成分對全局體系結構的假設存在沖突引起的失配
(5)測試和發布。增量和迭代的過程
用于CBSE的構件具備以下特征:
(1)可組裝型:所有外部交互必須通過公開定義的接口進行
(2)可部署性:構件總是二進制形式的,無需在部署前編譯,能作為一個獨立實體在平臺上運行
(3)文檔化:用戶根據文檔來判斷構件是否滿足需求
(4)獨立性:可以在無其他特殊構件的情況下進行組裝和部署
(5)標準化:符合某種標準化的構件模型
8、? 逆向工程:分析程序,力圖在比源代碼更高抽象層次上建立程序的表示過程,逆向工程是設計的恢復過程。分為四個級別:
實現級:包括程序的抽象語法樹、符號表、過程的設計表示
結構級:包括反映程序分量之間相互依賴關系的信息,例如調用圖、結構圖、程序和數據結構
功能級:包括反映程序段功能及程序段之間關系的信息,比如數據和控制流模型
領域級:包括反映程序分量或程序諸實體與應用領域概念之間對應關系的信息,比如E-R模型
領域級抽象級別最高,完備性最低;實現級抽象級別最低,完備性最高。
軟件復用是指在兩次或多次不同的軟件開發過程中重復使用相同或者相似軟件軟件元素的過程。軟件元素包括需求分析文檔、設計過程、設計文檔、程序代碼、測試用例、領域知識等。
與逆向工程相關的概念:重構、設計恢復、再工程和正向工程
重構是指同一抽象級別上轉換系統描述形式
設計恢復是指借助工具從已有程序中抽象出有關數據設計、總體結構設計和過程設計等方面的信息
正向工程是指不僅從現有系統中恢復設計信息,而且使用該信息去改變或重構現有系統,以改善整體質量
再工程是指在逆向工程所獲得信息的基礎上,修改或重構已有的系統,產生系統的一個新版本。再工程是對現有系統的重新開發過程,包括逆向工程、新需求的考慮過程和正向工程三個步驟
9、? 凈室軟件工程(Cleanroom Software Engineering,CSE):是一種應用數學與統計學理論以經濟的方式生產高質量軟件的工程技術,力圖通過嚴格的工程化的軟件過程達到開發中的零缺陷或接近零缺陷。凈室方法不是先制作一個產品,再去消除缺陷,而是要求在規約和設計中消除錯誤。CSE是軟件開發的一種形式化方法,使用盒結構規約進行分析和設計建模,強調正確性驗證而不是測試,使用統計的測試來獲取認證被交付的軟件的可靠性所必需的出錯率信息。
技術手段:
(1)統計過程控制下的增量式開發:控制迭代
(2)基于函數的規范和設計:盒子結構
定義3種抽象層次:行為試圖(黑盒)->有限狀態機視圖(狀態盒)->過程視圖(明盒)
(3)正確性驗證:凈室工程的核心
(4)統計測試和軟件認證:使用統計學原理,總體太大時必須采用抽樣方法
10、? 需求工程
軟件需求是指用戶對系統在功能、行為、性能、設計約束等方面的期望。

需求分類及獲取方法

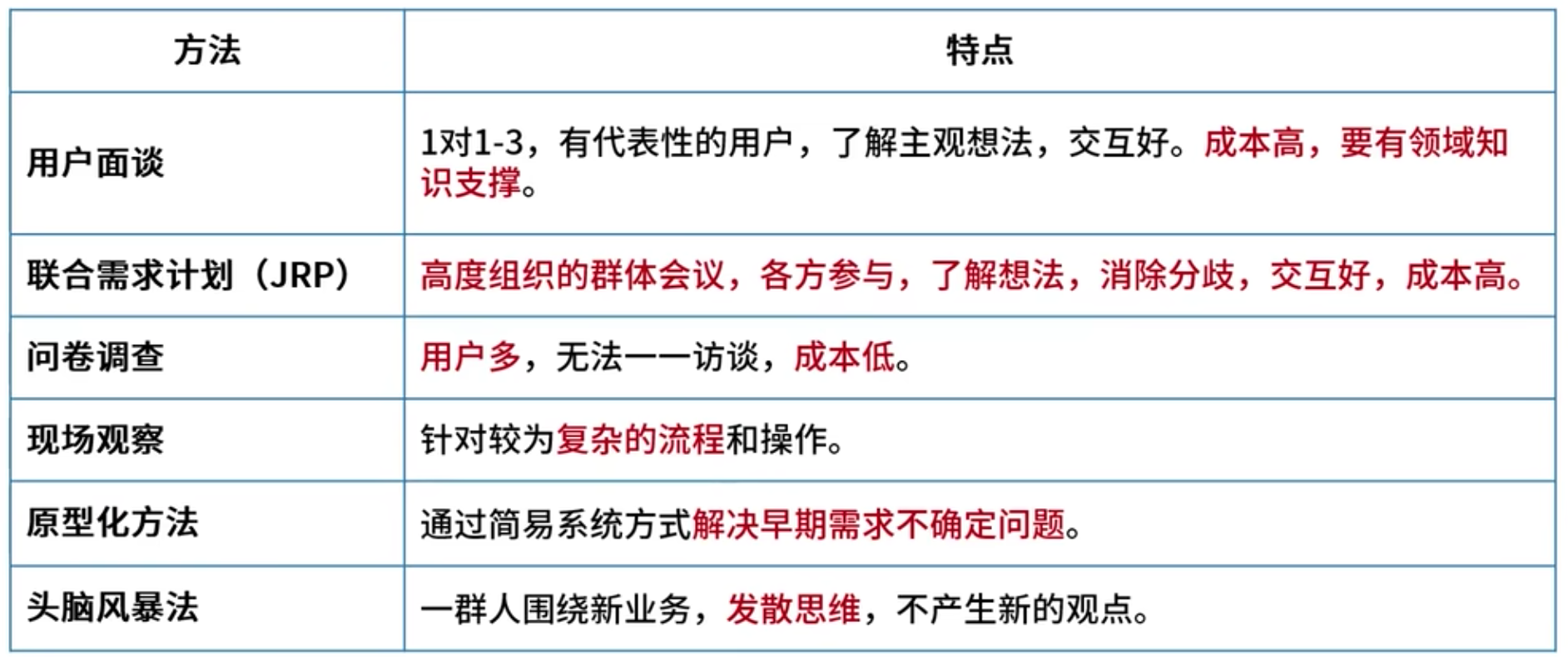
11、? 需求分析
結構化方法(Structured Analysis,SA)
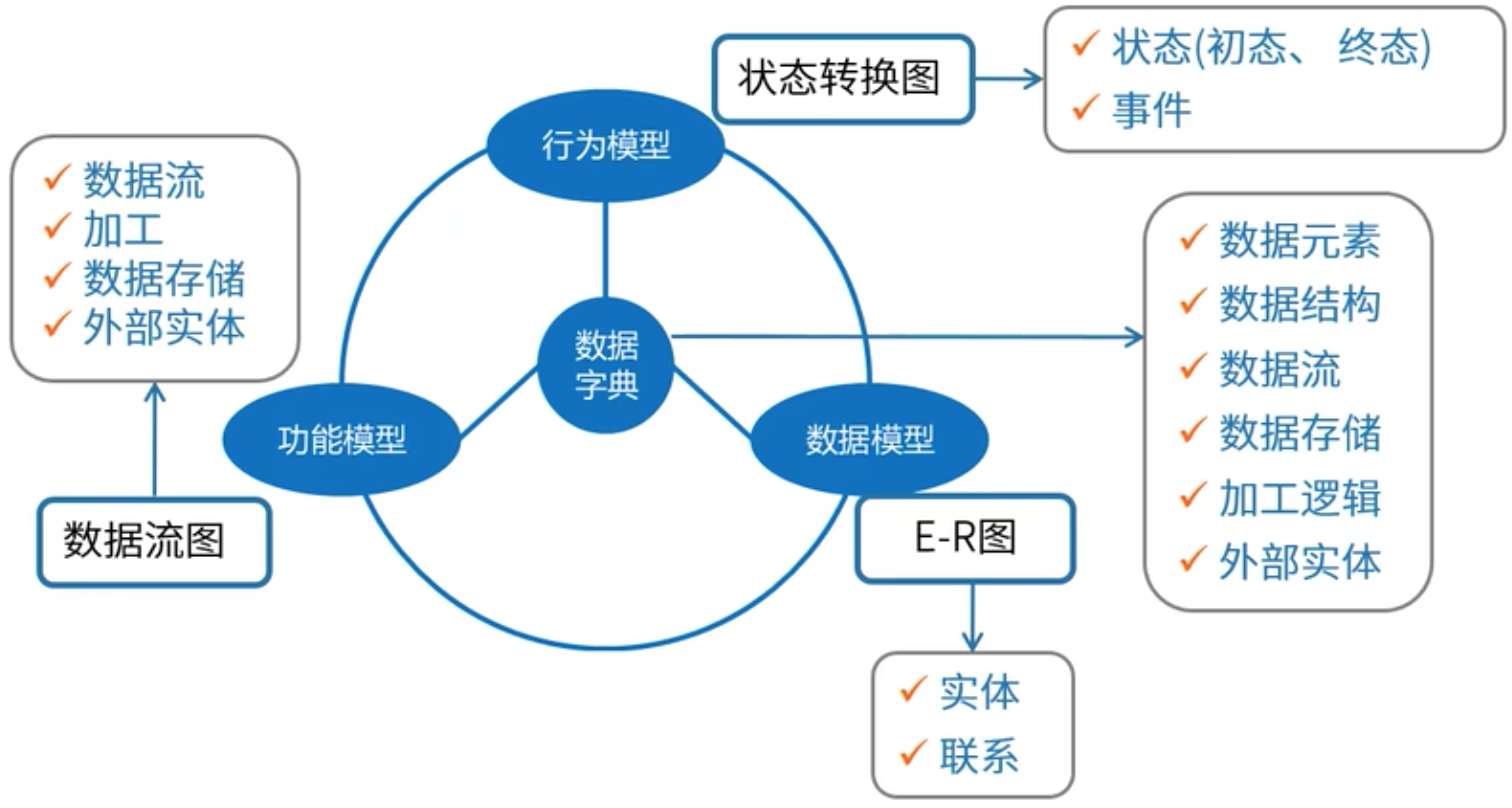
數據流圖主要有以下幾個部分組成:
數據流:由一組固定成分的數據組成,表示數據的流向。它可以是輸入、輸出或存儲在系統中的數據。每個數據流通常有一個合適的名詞,反映數據流的含義。
加工:描述了輸入數據流到輸出數據流之間的變換,也就是輸入數據流做了什么處理后變成了輸出數據流。
數據存儲:用來表示暫時存儲的數據,每個文件都有名字。流向文件的數據流表示寫文件,流出的表示讀操作。
外部實體:與系統進行信息交流的外部機構或個人
數據流圖遵循的數據平衡原則:
(1)數據守恒原則:每個加工環節的輸出數據流應該是對其輸入數據流中的數據處理后的結果
(2)守恒加工原則:對同一個加工來說,輸入數據流與輸出數據流的名字必須不同,即使它們的組成成分相同
(3)每個加工環節都必須有輸入與輸出數據流
(4)外部實體與外部實體之間不存在數據流
(5)外部實體與數據存儲之間不存在數據流
(6)數據存儲與數據存儲之間不存在數據流
(7)父圖與子圖的平衡原則:子圖的輸入輸出數據流同父圖相應加工的輸入輸出數據流必須一致
結構化分析方法中的功能模型建模過程如下:
(1)明確目標,確定系統范圍
(2)建立頂層DFD圖
(3)構建第一層DFD分解圖
(4)開發DFD層次結構圖
(5)檢查確認DFD圖
結構化分析方法中的數據模型建模過程(ER作圖步驟):
(1)確定所有的實體集合
(2)確定每個實體集包含的屬性
(3)確定實體集之間的聯系
(4)確定實體集的關鍵字
(5)確定聯系的類型
12、? 軟件設計包括體系結構設計、接口設計、數據設計和過程設計
(1)結構設計:定義軟件系統各主要部件之間的關系
(2)數據設計:將模型轉換成數據結構的定義,好的數據設計將改善程序結構和模塊劃分,降低復雜性
(3)接口設計(人機界面設計):軟件內部、軟件和操作系統之間,以及軟件和人之間如何通信
(4)過程設計:系統結構部件轉換成軟件的過程描述
13、? 軟件設計的啟發規則是對按照軟件設計原則設計的結果進行優化的規則,具體包括:改進軟件結構提高模塊獨立性;模塊規模應當適中;深度、寬度、扇出和扇入都應適當;模塊的作用域應該在控制域內;力爭降低模塊接口的復雜程度;設計單入口單出口的模塊;模塊功能應該可以預測
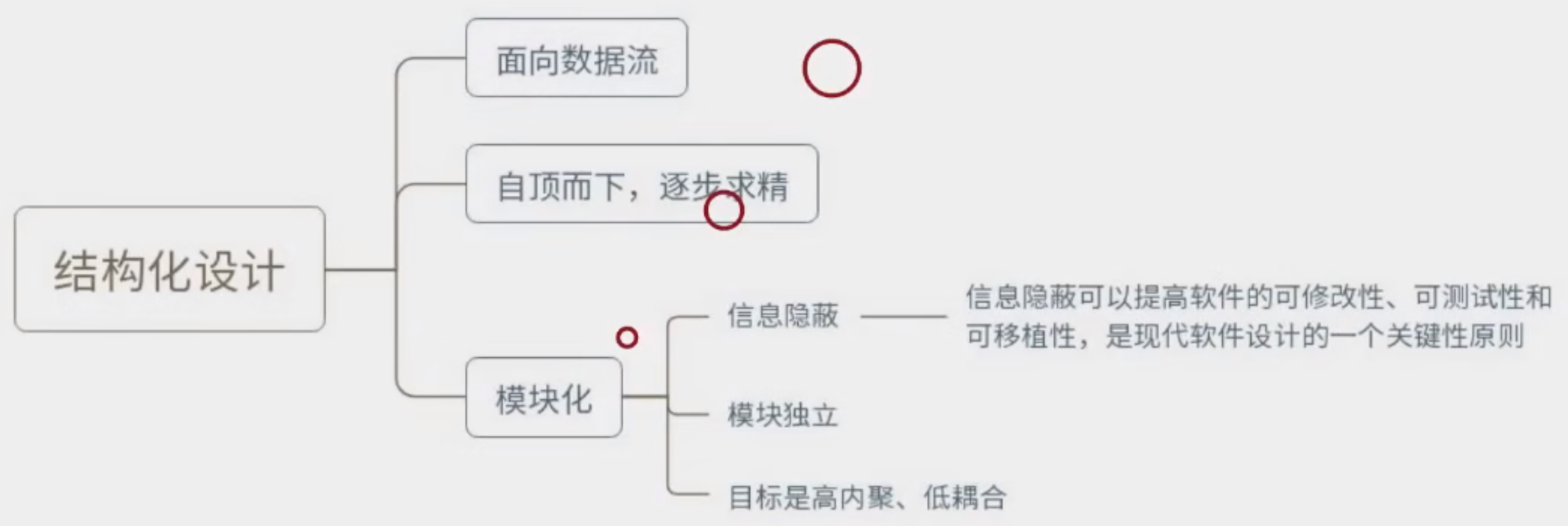
14、? 結構化設計(Structured Design,SD)是一種面向數據流的設計方法,它以需求獲取SRS和需求分析SA階段所產生的數據流圖和數據字典等文檔為基礎,是一個自頂向下、逐步求精和模塊化的過程。
模塊化要求模塊獨立性,因為有效的模塊化(即具有獨立性的模塊)軟件比較容易開發出來,另外獨立的模塊比較容易測試和維護。模塊的獨立程度可以由兩個定性標準度量,分別是內聚和耦合。
| 耦合程度 | 耦合類型 | 描述 |
| 從上到下 由低到高 | 非直接耦合 | 兩個模塊之間沒有直接關系,它們之間的關系完全通過上級模塊的控制和調用來實現 |
| 數據耦合 | 一個模塊傳給另一個模塊的參數是一個單個的數據項或者單個數據項組成的數組(值傳遞) | |
| 標記耦合 | 一個模塊傳遞給另一個模塊的參數是一個復合的數據結構(引用傳遞) | |
| 控制耦合 | 模塊之間傳遞的信息中包含用于控制模塊內部邏輯的信息 | |
| 通信耦合 | 一組模塊共用了一組輸入信息,或者它們的輸出需要整合以形成完整數據,即共享輸入或輸出 | |
| 公共耦合 | 多個模塊都訪問同一個公共數據環境,比如數據結構 | |
| 內容耦合 | 一個模塊直接訪問另一個模塊的內部數據;一個模塊不通過正常入口轉到另一個模塊的內部;兩個模塊有一部分代碼重疊;一個模塊有多個入口等 |
| 內聚程度 | 內聚類型 | 描述 |
| 從上到下 由高到低 | 功能內聚 | 完成一個單一功能,各部分缺一不可 |
| 順序內聚 | 處理元素相關,且必須順序執行,即模塊中某個成分的輸出是另一個成分的輸入 | |
| 通信內聚 | 模塊中的成分引用共同的輸入數據,或者產生相同的輸出數據 | |
| 過程內聚 | 處理元素相關,且必須按特定的次序執行 | |
| 時間內聚 | 所包含的任務必須在同一時間間隔內執行 | |
| 邏輯內聚 | 完成邏輯上相關的一組任務,使用時由調用模塊傳遞的參數確定執行的功能 | |
| 偶然內聚 | 完成一組沒有關系或者松散關系的任務 |
15、? 過程設計涉及到的圖形工具包括:數據流程圖、Jackson圖、程序流程圖(PFD,程序框圖)、系統流程圖、PAD圖、N-S流程圖(盒圖)、PDL(偽碼或結構化語言)、判定樹、判斷表、層次方框圖、Warnier圖、IPO圖
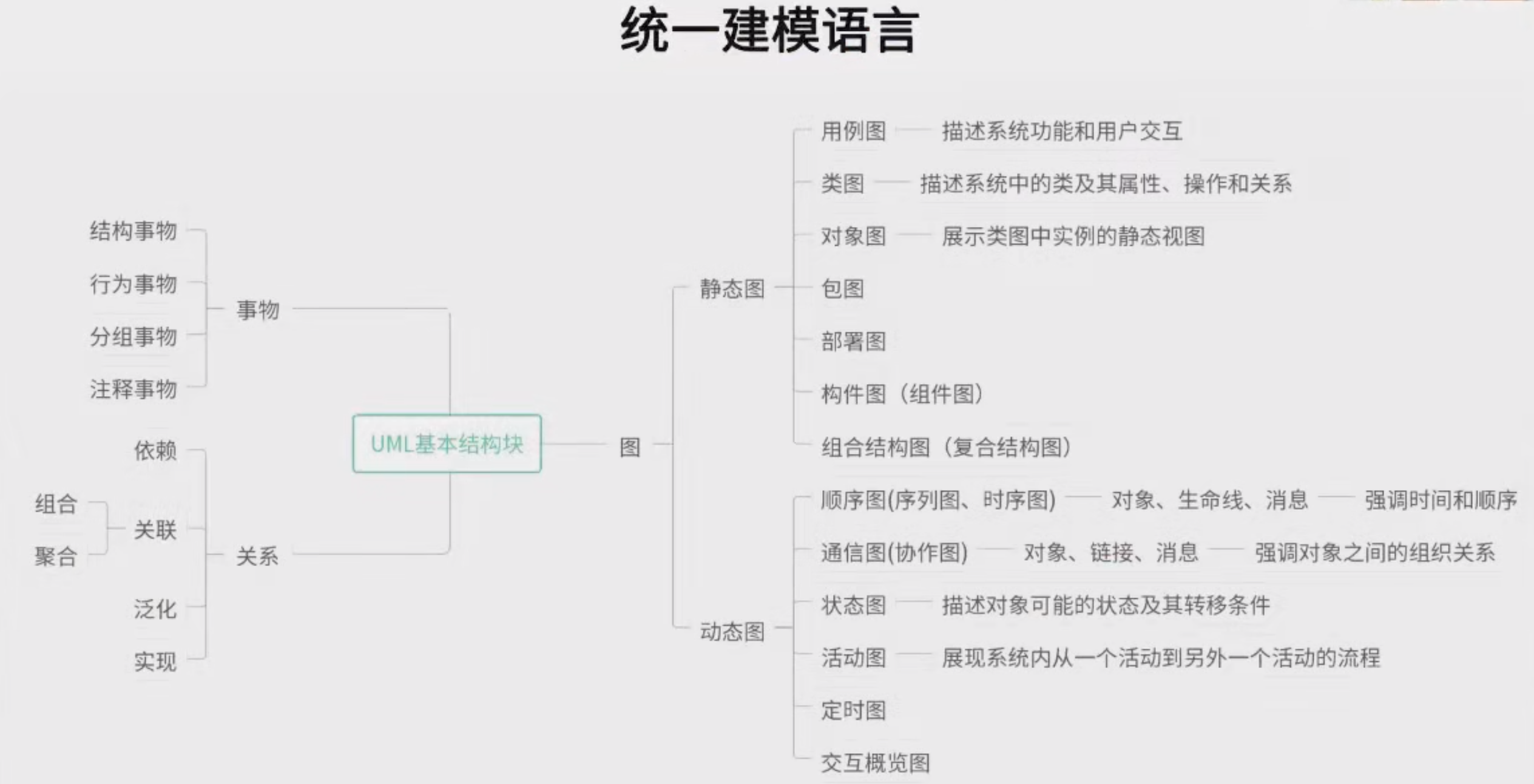
16、面向對象方法:是一種以對象、對象關系等來構建軟件系統模型的系統化方法。
優勢:符合人類的思維習慣、穩定性好、可復用性好、可維護性好
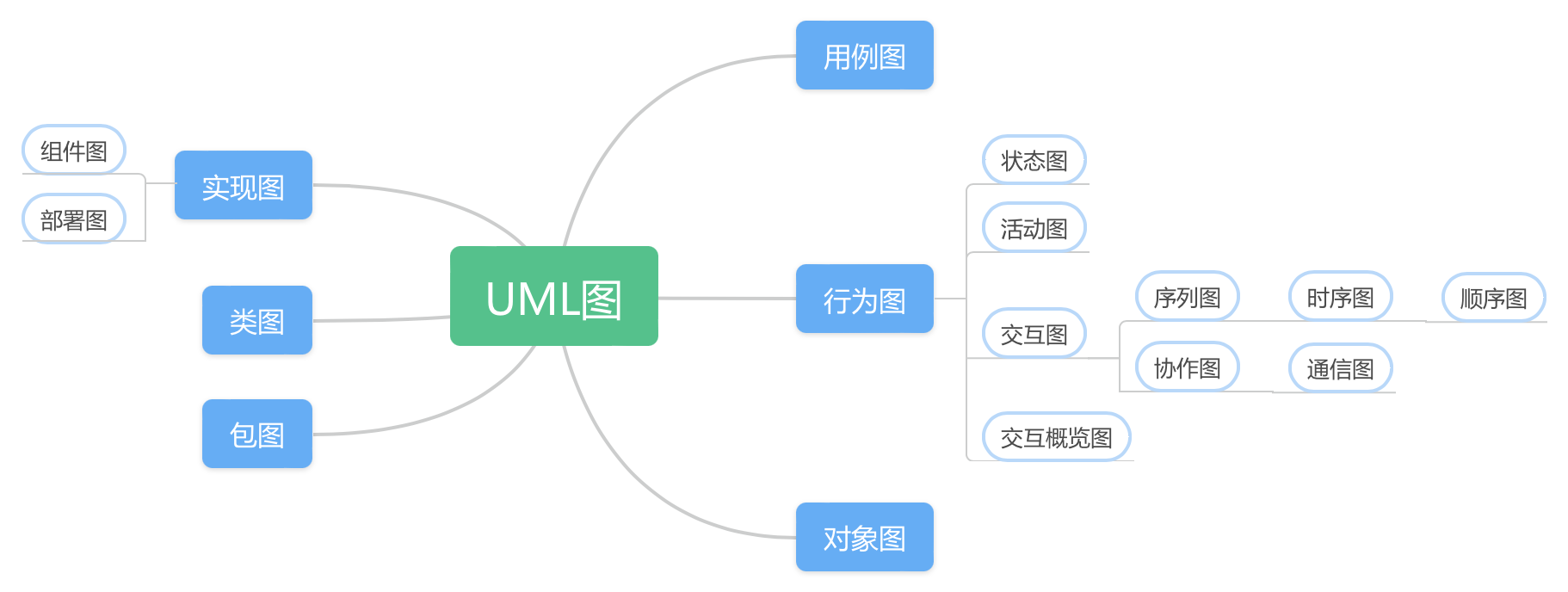
類圖展現了一組對象、接口、協作和它們之間的關系。定時圖強調消息跨越不同對象或參與者的實際時間,而不僅僅只是關心消息的相對順序。部署圖描述軟件和硬件組件之間的物理關系以及處理節點的組件分布情況。包圖是一種將模型元素(如類、接口、用例等)組織成邏輯分組的機制,以便更好地管理和理解大型或復雜的模型。
 對象模型描述系統數據結構
對象模型描述系統數據結構
動態模型描述系統控制結構
功能模型描述系統功能
功能模型指明了系統應該做什么
動態模型明確規定了什么時候做
對象模型定義做事情的實體
3種模型都涉及數據、控制和操作等共同的概念,但側重點不同,綜合起來全面地反映了對目標系統的需求,都可用于軟件的需求分析。
17、? 面向對象分析步驟:
(1)確定對象和類(類與對象層)
(2)確定結構(結構層)
(3)確定主題(主題層)
(4)確定屬性(屬性層)
(5)確定方法(服務層)
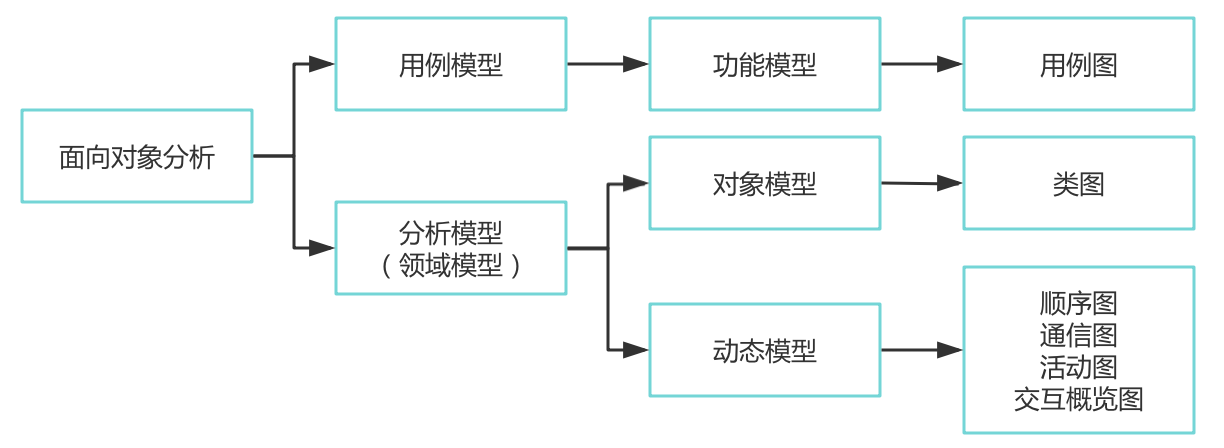
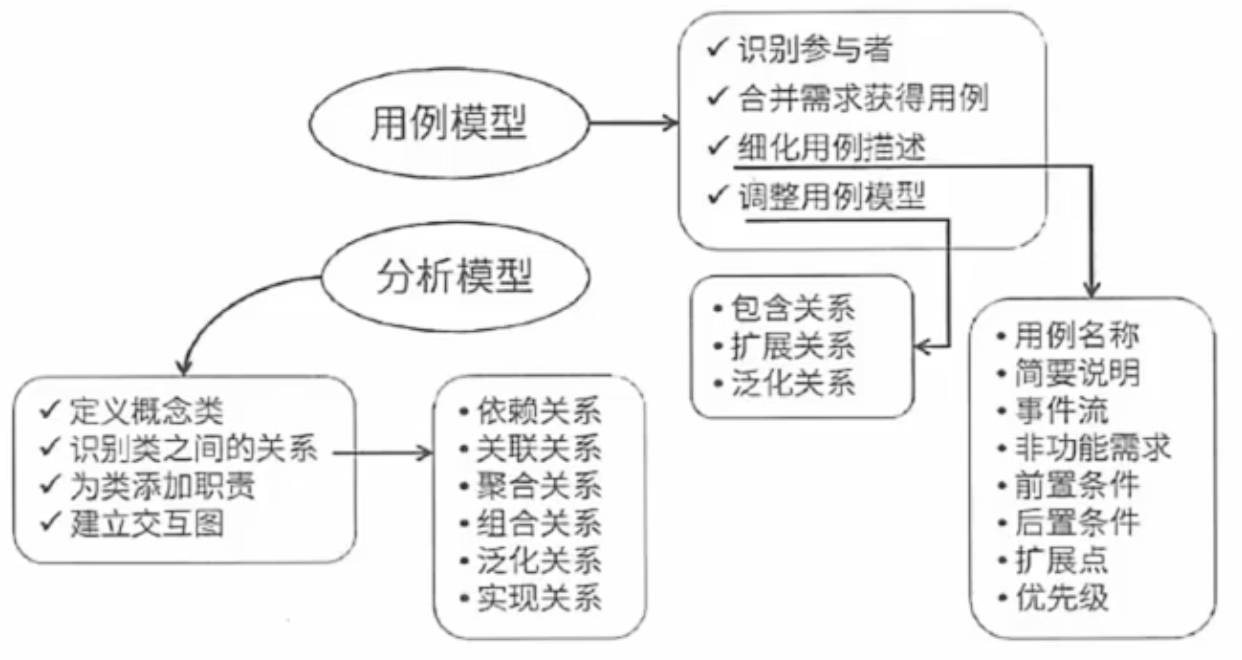
在面向對象分析中,利用用例和用例圖表示需求,從用例模型中提煉形成分析模型(領域模型),用例的實現可以用交互圖表示。從領域模型和用例模型形成類圖,用包圖和類圖形成體系結構圖。
面向對象分析原則:
(1)抽象
(2)封裝
(3)繼承
(4)分類
(5)聚合
(6)關聯
(7)消息通信
(8)粒度控制
(9)行為分析
面向對象需求分析建模:


(1)邊界類:用于封裝在用例內、外流動的信息或數據流,位于系統與外界的交接處。包括機器接口和人機交互,比如顯示屏、窗體、打印機接口、通信協議、對話框、菜單、購物車、報表、二維碼等。
(2)控制類:用于控制用例工作的類,一般由動賓結構的短語轉化而來,包括應用邏輯、業務邏輯、數據訪問邏輯,比如身份驗證器。
(3)實體類:需要持久化的數據或者文件,比如學生類、課程類
用例之間的關系有以下三種:
泛化關系:一個用例可以被特別列舉為一個或多個子用例。
包含關系:一個用例(基礎用例)的行為包含了另一個用例(包含用例)的行為。基礎用例可以看到包含用例,并依賴于包含用例的執行結果,但二者不能訪問對方的屬性。
擴展關系:把新的行為加入到已有的用例中,來獲得新用例,其中新用例叫擴展用例,原有用例叫基礎用例。擴展關系屬于一種特殊的泛化關系,實際上是增加接口,是抽象類的泛化關系。
“登錄系統”用例與“注冊課程”用例之間是包含關系;“參加考試”用例與“參加補考”用例之間是擴展關系。
類之間的關系有:
依賴關系:當一個類使用了另一個類時,它們之間就存在依賴關系。這種關系可以是編譯時的依賴,也可以是運行時的依賴。例如,一個類可能是另一個類的成員屬性、方法返回值類型、方法參數類型或局部變量。
關聯關系:是雙向的依賴關系,表示類與類或類與接口之間的結構化關系,在代碼中,關聯類有一個成員變量保存的是被關聯類的引用。
泛化關系:是依賴關系的一種特例,通常是指繼承關系。
聚合關系:關聯關系的一種特例,體現的是整體與部分的關系,整體與部分之間是可以分離的,各自具有各自的生命周期。部分可以屬于多個整體對象,也可以為多個整體對象共享。
組合關系:是關聯關系的一種特例,比聚合更強,同樣體現整體與部分的關系,但整體與部分之間不可以分離的,整體的生命周期結束也就意味著部分的生命周期結束。
實現關系:當一個類實現一個接口時,它們之間存在的就是實現關系。
順序圖描述了對象之間交互過程中的時間順序,側重點在對象按時間順序的消息交換。
協作圖(通信圖)描述了對象之間組織協作關系,側重點在對象如何協同工作。
數據流圖作為一種圖形化工具,用來說明業務處理過程、系統邊界內所包含的功能和系統中的數據流。
程序流程圖以圖形化的方式展示應用程序從數據輸入開始到獲得輸出數據為止的邏輯過程,描述處理過程的控制流。
兩者之間的區別主要有:
(1)數據流圖中的處理過程可并行;程序流程圖在某個時間點只能處于某一個處理過程
(2)數據流圖展現系統的數據流;程序流程圖展現系統的控制流
(3)數據流圖展現全局的處理過程,過程之間遵循不同的計時標準;程序流程圖中處理過程遵循一致的計時標準
(4)數據流圖適用于系統分析中的邏輯建模階段;程序流程圖適用于系統設計中的物理模型階段
活動圖和狀態圖的差別:
(1)描述對象不同。狀態圖描述對象狀態及狀態之間的轉移,以狀態為中心;活動圖描述從活動到活動的控制流,以活動為中心。
(2)使用場合不同。狀態圖描述對象在其生命期中的行為狀態變化;活動圖描述過程的流程變化。
活動圖和流程圖的區別:
(1)描述重點不同:流程圖著重描述處理過程,它的主要控制結構是順序、分支和循環,各個處理過程之間有嚴格的順序和時間關系。而活動圖描述的是對象活動的順序關系所遵循的規則,它著重表現的是系統的行為,而非系統的處理過程。
(2)并發活動的表示:活動圖能夠表示并發活動的情形,而流程圖則不能。
(3)面向對象與面向過程:活動圖是面向對象的,而流程圖是面向過程的。
(4)順序指定:流程圖明確地指定了每個處理過程的先后順序,而活動圖僅描述了活動和必要的工作順序
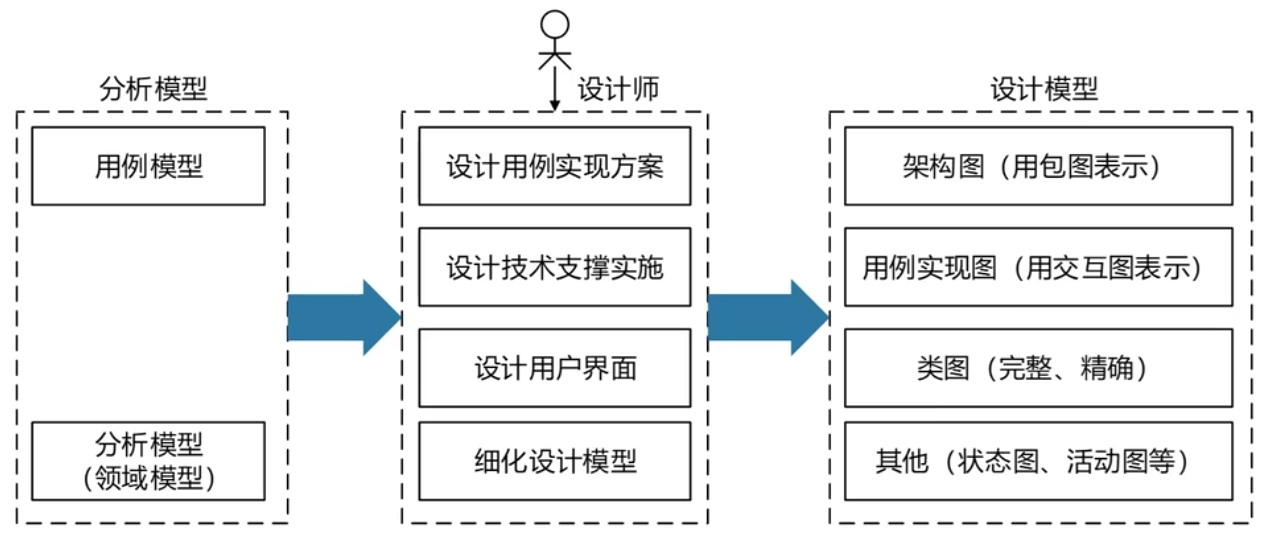
18、? 面向對象設計過程:
(1)建立軟件體系結構環境圖
(2)體系結構設計
(3)子系統設計
(4)對象設計
面向對象的分析模型主要由頂層架構圖、用例與用例圖、領域概念模型構成。設計模型包含以包圖表示的軟件體系結構圖、以交互圖表示的用例實現圖、完整精確的類圖、針對復雜對象的狀態圖和用以描述流程化處理過程的活動圖等。
當采用面向對象的設計方法描述對象模型時,通常使用類圖表達類的內部屬性和行為,以及類集合之間的交互關系;采用狀態圖定義對象的內部行為。
19、? 面向對象設計的7大原則

(1)單一職責原則(Single Responsibility Principle,SRP):類的職責主要包括數據職責和行為職責兩個方面,數據職責通過屬性來體現,行為職責通過方法體現。一個類承擔的職責越多,它復用的可能性越小。一個對象應該只包含單一的職責,并且該職責應該被完整地封裝在一個類中。單一職責原則是實現高內聚、低耦合的指導方針。
(2)開閉原則(Open-Closed Principle,OCP):一個軟件實體應當對擴展開放,對修改關閉。也就是說在設計模塊的時候,應當使這個模塊可以在不被修改的前提下被擴展。軟件實體可以指一個軟件模塊、一個由多個類組成的局部結構或一個獨立的類。抽象化是開閉原則的關鍵。
(3)里氏代換原則(Liskov Substitution Principle,LSP):所有引用基類(父類)的地方必須能透明地使用其子類的對象。里氏代換原則是實現開閉原則的重要方式之一,由于使用基類對象的地方都可以使用子類,因此在程序中盡量使用基類類型來對對象進行定義,而在運行時再確定其子類類型,用子類對象替換父類對象(即常說的多態)。
(4)依賴倒轉原則(Dependence Inversion Principle,DIP):高層模塊不應該依賴于底層模塊,它們都應該依賴抽象。抽象不應該依賴于細節,細節應該依賴于抽象。要針對接口編程,不要針對實現編程。開閉原則是面向對象設計的目標,依賴倒轉原則是面向對象設計的主要手段。
(5)接口隔離原則(Interface Segregation Principle,ISP):使用多個專門的接口,而不使用單一的總接口。
(6)合成復用原則(Composite Reuse Principle,CRP):也叫組合/聚合復用原則,即盡量使用對象組合,而不是繼承來達到復用的目的。
(7)迪米特法則(Law of Demeter,LoD)又稱最少知識原則(Least Knowledge Principle,LKP):只與自己朋友之間通信,每個軟件單位對其他的單位都只有最少的知識,而且局限于那些與本單位密切相關的軟件單位。
20、? 面向對象軟件的測試分為4個層次:算法層(單元測試)、類層(模塊測試)、模版層(集成測試)、系統層(系統測試)
21、? 測試原則:
(1)盡早、不斷地進行測試
(2)程序員避免測試自己設計的程序
(3)既要選擇有效、合理的數據,也要選擇無效、不合理的數據
(4)修改后應進行回歸測試
(5)尚未發現的錯誤數量與該程序已發現錯誤數成正比
22、? 測試分類
動態測試:通過運行被測試程序,對得到的運行結果與預期的結果進行比較分析,同時分析運行效率和健壯性等。包括黑盒測試、白盒測試和灰盒測試
靜態測試:被測試程序不運行,只依靠分析或檢查源程序的語句、結構、過程等來檢查程序是否有錯誤。包括桌前檢查、代碼走查和代碼審查
其它測試:AB測試、Web測試、鏈接測試、表單測試
23、? 測試用例設計
黑盒測試用例測試方法:等價類劃分、邊界值分析、錯誤推測、因果圖
白盒測試用例測試方法:基本路徑測試、循環覆蓋測試、邏輯覆蓋測試(語句覆蓋、判定(分支)覆蓋、條件覆蓋、判定條件覆蓋、組合覆蓋、路徑覆蓋)
24、? 測試階段
(1)單元測試:先用靜態測試方法測試,再通過動態測試方法測試
(2)集成測試:一般采用白盒測試與黑盒測試的結合方法進行
(3)系統測試:本階段測試內容包含功能測試、性能測試、健壯性測試、安裝測試、壓力測試、可靠性測試、安全性測試等
(4)驗收測試:最后一階段的測試,這階段應進行Alpha測試和Beta測試。Alpha測試是指軟件在開發環境下由用戶進行的測試。Beta測試是指軟件在實際環境中由多個用戶進行的測試
25、? 系統維護分為:糾錯性維護、適應性維護、完善性維護、預防性維護



















