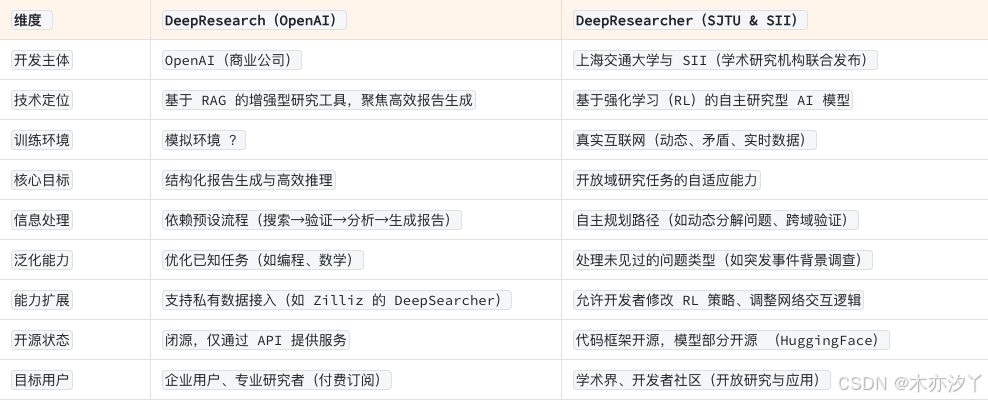
DeepResearch 的概念與功能最早由 Google 在 Gemini 系列產品中推出,用于自動化生成結構化研究報告,近期底層依賴模型Gemini升級到了2.5 Pro。而我們常規認知的DeepResearch是由OpenAI推出的一款由優化版的 o3 模型驅動專注于深度研究和分析的AI智能體產品。其主要功能包括自主分析復雜的專業信息,實時查找和綜合數百個在線資源,最終生成一份專業水準的完整報告。DeepResearch能夠運用推理能力,在互聯網上搜索、解讀和分析海量的文本、圖像和PDF文件,并根據所遇到的信息靈活調整研究方向。
DeepResearcher?個基于強化學習(RL)在真實?絡環境中端到端訓練的?主研究型 AI 模型框架,強調動態規劃與復雜任務研究能?。 模型通過與環境交互?主發展出規劃、交叉驗證、動態調整策略等能?,?需預設?作流。其核?創新在于直接處理動態、?盾的實時?絡信息,??靜態知識庫。主要是為了解決傳統 RAG 和預定義?作流在開放性問題(如學術研究、實時?絡信息整合)中的局限性, 適?于需要交叉驗證、多源信息融合的深度研究任務。
關鍵區別:
DeepResearch 是OpenAI推出的面向深度研究領域的商業化智能體產品,旨在通過?動化流程提升研究報告?成效率; (2025-02-05)
DeepResearcher 是學術研究導向的框架,探索端到端強化學習在真實網絡環境中的深度研究能?突破。(2025-04-03)
DeepResearch
OpenAI的DeepResearch是?向商業?戶的?端研究?具,聚焦于?動化?成結構化研究報告,如市場分析、學術綜述等。其核?優勢在于通過端到端強化學習優化多步驟推理能?,并整合實時?絡搜索與多模態數據處理(如圖表?成、PDF解析)。
DeepSearcher
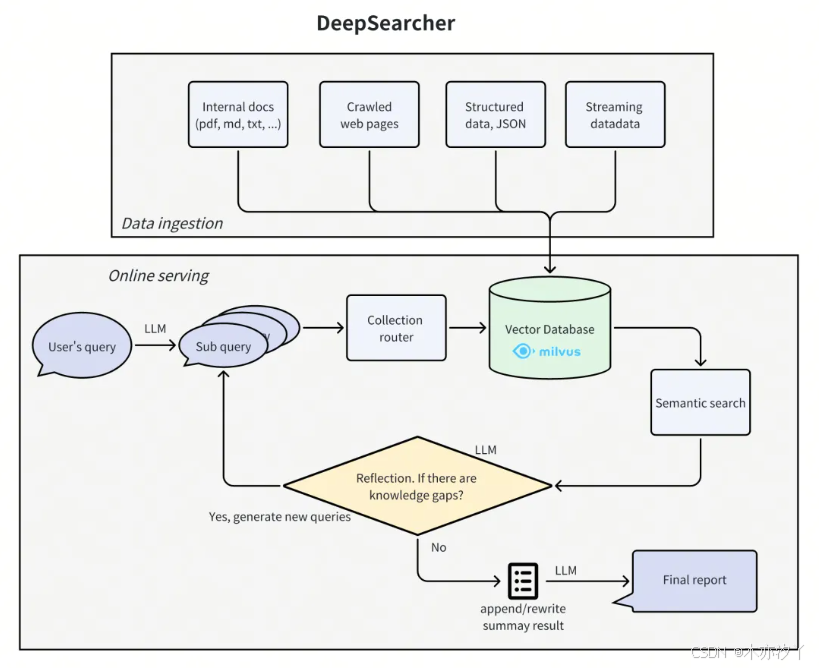
因為DeepResearch底層模型綁定了OpenAI,還沒辦法利用本地數據,所以ZillizTech借鑒了DeepResearch的Agentic RAG設計理念并定制化改造,發布了DeepSearcher開源框架,專注于企業級私有數據的?效檢索與推理,?持本地知識庫集成 (如Milvus向量數據庫)和靈活的?模型切換(如DeepSeek-R1、本地LLM),適?于需要數據隱私保護的垂直領域場景。DeepSearcher也采用了動態規劃與多步驟推理,通過將復雜問題拆解為?查詢,并迭代優化檢索結果,最終?成?質量答案。同時引入智能代理能力,實現?主決策。
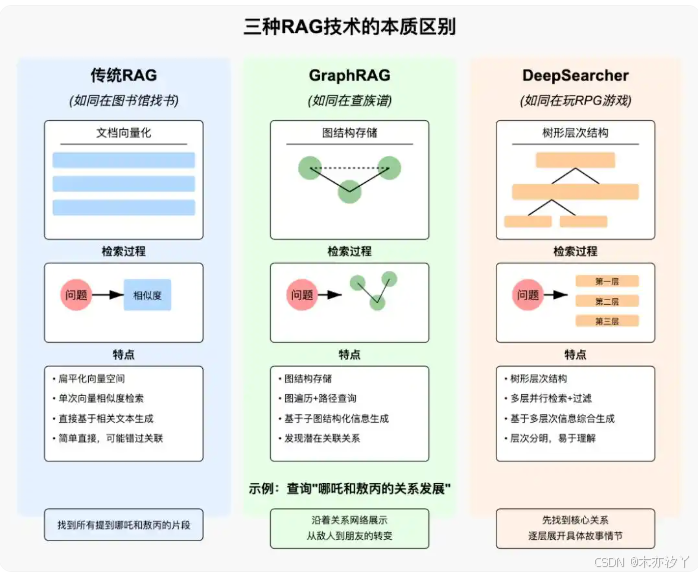
DeepSearcher基于智能查詢路由(Query Routing)和混合檢索機制(語義+關鍵詞),即結合語義檢索(向量數據庫)與關鍵詞檢索,提升復雜問題的召回率;通過漸進式問題分解(如將主查詢拆分為多個?查詢)結合條件執?流程,降低對單?模型的依賴,?持本地化低延遲響應;并設置預算強制(Budget Enforcement),可設定 Token 或算?消耗上限,避免?限循環導致的資源浪費。
node-DeepResearch
node-DeepResearch 是一個由Jina AI?開源的 AI 智能體項目,旨在通過持續搜索和閱讀網頁,逐步推理并回答復雜問題。它基于 Gemini 語言模型和 Jina Reader 工具,能夠處理從簡單問題到多步推理的復雜任務。該項目提供了 Web Server API,方便用戶通過 HTTP 請求提交查詢并獲取實時進度更新。
node-DeepResearch 的主要功能
- 持續搜索與閱讀:基于搜索引擎(如 Brave 或 DuckDuckGo)查找相關信息,閱讀網頁內容,直到找到問題的答案或超出設定的 token 預算。
- 網頁內容處理:基于 Jina Reader 將網頁內容轉換為適合語言模型處理的純文本格式。Jina Reader 是開源工具,專門用于處理 HTML 網頁內容。
- 多步推理:處理復雜的多步問題,逐步分解問題并逐步解決。
- 實時進度反饋:通過 Web Server API 提供實時進度更新,用戶可以隨時了解查詢的進展情況。
- 靈活的查詢方式:支持從簡單的事實性問題到復雜的開放式問題,例如預測未來的趨勢或制定策略。
Local Deep Research
此外一款名為Local Deep Research的開源項目也橫空出世,憑借完全免費、本地化運行、高度可定制的特性,迅速成為技術社區的熱議焦點。
Local Deep Research是一款基于本地化部署的智能研究助手,旨在通過AI技術自動化完成復雜的信息收集、分析和報告生成任務。它的核心目標是為用戶提供零成本、高靈活、隱私安全的研究解決方案,尤其適合個人開發者、學術研究者和初創企業。與OpenAI等商業工具不同,Local Deep Research完全開源,用戶無需支付月費,且所有數據處理均在本地完成,徹底杜絕隱私泄露風險。
Local Deep Research采用輕量級模塊化架構設計,支持靈活擴展。開發者可輕松替換搜索引擎、AI模型(如切換至開源模型R1)或集成自定義工具。通過動態生成搜索關鍵詞和實時結果分析,系統能像人類研究員一樣“邊學邊改”,優化提升信息篩選效率。可并行處理加速,利用多線程技術同時處理多個搜索任務,速度提升30%以上,5小時任務可壓縮至3.5小時。
其他類似開源平替
- Hugging Face的OpenDeepResearch 復刻 OpenAI Deep Research 核心能力的開源方案,支持自主瀏覽網頁、處理文件及數據計算,性能接近閉源方案。可用于學術研究與復雜商業分析任務。
mshumer/OpenDeepResearcher是一個以 Jupyter Notebook 為實現形式的 AI 研究工具,它模擬了人類的研究過程,通過不斷迭代搜索、篩選和整合信息,從而達到深度研究的目的。- nickscamara
/open-deep-research?實驗性開源克隆項目,輕量級且高效的 AI 研究代理,通過 Firecrawl 實現網絡數據抓取與推理模型結合 - 香港大學 Auto-Deep-Research?基于 AutoAgent 框架的全自動 AI 研究助手,支持多模型集成與靈活交互。
DeepResearcher
-
論文標題:《DeepResearcher: Scaling Deep Research via Reinforcement Learning in Real-world Environments》
-
論文地址:https://github.com/GAIR-NLP/DeepResearcher/blob/main/resources/DeepResearcher.pdf
-
代碼地址:https://github.com/GAIR-NLP/DeepResearcher
-
模型地址:https://huggingface.co/GAIR/DeepResearcher-7b
雖然像 OpenAI Deep Research 這樣的商業系統的技術細節仍然完全不透明。但研究表明,強化學習 (RL) 為改進 LLM 能力提供了一條有希望的道路。對數學和編碼任務進行大規模強化學習可以顯著提高它們的推理能力。對于開放域任務,OpenAI已經承認使用強化學習技術來增強其 DeepResearch 代理的能力,但詳細的方法仍然是其專有的并且沒有公開,在開放域任務研究中造成了重大差距。
目前將 RL 與信息檢索相結合的開源工作,例如 Search-R1、R1-Searcher 和 ReSearch,主要關注使用靜態、本地文本語料庫進行檢索增強生成 (RAG)。雖然這些方法提供了寶貴的見解,但它們從根本上無法捕捉現實世界網絡搜索環境的動態和不可預測性。受控的 RAG 設置在高度清洗的環境中運行,并具有一個關鍵的局限性假設:所有必要的信息都存在于其固定的知識庫中。這個假設在現實世界場景中崩潰了,因為信息可能缺失、過時或需要跨域合成,而這些域沒有包含在初始知識庫中。除了這個基本的局限性之外,RAG 系統也沒有考慮到大量的噪聲、搜索質量的可變性以及導航不同網絡內容格式和結構的挑戰。
DeepResearcher介紹
DeepResearcher是首次在真實網絡環境中進行端到端強化學習訓練的深度研究框架,全面研究了具有現實世界網絡搜索能力的 LLM 代理的 RL 擴展。將訓練代理直接與實時搜索引擎交互,從而學習處理開放網絡的固有的可變性和復雜性。通過在真正的網絡環境中而不是受控的模擬環境中進行訓練,挖掘了處理現實世界信息檢索和合成的不可預測性的強大能力。
DeepResearcher 與基于提示和基于 RAG 的搜索代理方法有著顯著不同:
-
強化學習 (RL): DeepResearcher 使用強化學習來訓練代理,使其能夠通過與環境交互來學習最佳行為策略。這使其能夠超越人為設計的提示,并自主地開發出有效的搜索和推理策略。
-
真實網絡環境: DeepResearcher 在真實的網絡環境中進行訓練,而不是在受控的模擬環境中。這使得它能夠處理現實世界信息檢索的復雜性和不可預測性,例如噪聲、搜索質量的可變性以及導航不同網絡內容格式和結構的挑戰。
-
端到端訓練: DeepResearcher 使用端到端訓練,這意味著整個系統,包括語言模型和搜索引擎交互模塊,都通過強化學習進行訓練。這使代理能夠學習到更全面和協調的行為策略。
-
多代理框架: DeepResearcher 采用多代理框架,其中專門的瀏覽代理負責從整個網頁中提取相關信息。這使其能夠更有效地處理網絡內容的多樣性和復雜性。
-
解決實施挑戰: DeepResearcher 針對真實網絡環境中特有的挑戰,例如 API 速率限制、網頁解析可變性、反爬蟲機制和網絡延遲問題,開發了專門的解決方案。這使得它能夠在真實網絡環境中穩定地運行。
DeepResearcher獨特地將強化學習與在真實網絡環境中的訓練相結合。與主要關注靜態、本地文本語料庫的現有 RL 方法不同,它將訓練代理直接與實時搜索引擎交互。這使得它能夠處理開放網絡的固有的可變性和復雜性,從而發展出強大的現實世界信息檢索和合成能力。DeepResearcher的方法通過直接與網絡環境的不可預測性進行交互來學習適應性搜索策略,從而克服了基于提示和 RAG 限制的方法的局限性。
端到端強化學習框架
- 不依賴人類先驗知識,讓模型自主發現解決問題的策略。
- 采用GRPO(Group Relative Policy Optimization)群體相對策略優化算法,通過直接與真實網絡搜索引擎交互來訓練代理。
- 使用F1分數作為主要獎勵指標,并對格式錯誤的回復處以懲罰,引導代理持續提升性能。
多智能體架構
DeepResearcher采用專門的多智能體架構,包括:
- 主研究代理:處理問題分析和搜索策略。
- 專門的瀏覽代理:負責從整個網頁提取相關信息。
- 智能體間協作:通過信息共享實現有效的知識提取和整合。
DeepResearcher訓練架構
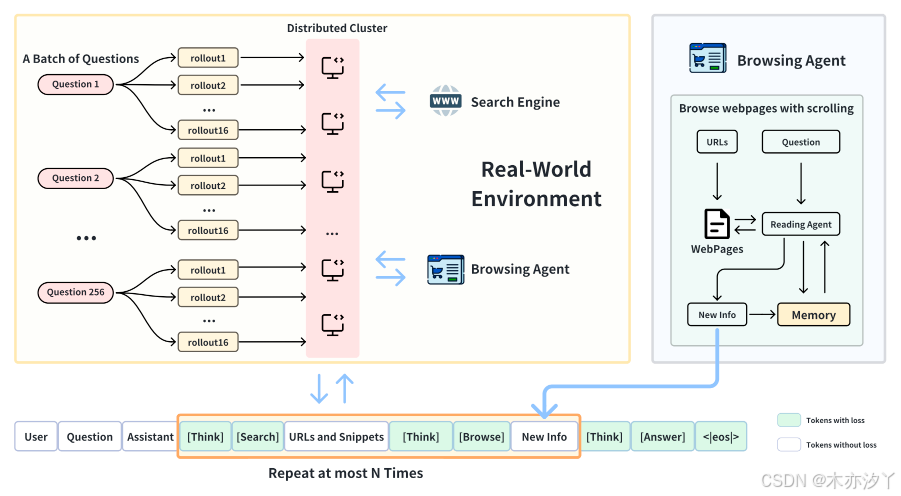
方法:深度研究推理軌跡
在 DeepResearcher 的推理軌跡中,智能體會根據用戶問題和觀測結果進行迭代推理與工具選擇,在動態的真實世界環境中通過網頁搜索解決問題。
-
推理(Reasoning):DeepResearcher 在執行具體動作之前必須先進行推理。每次推理過程都被封裝在 <think> 標簽內,遵循 DeepSeek-R1 的設定。
-
網頁搜索工具(Web Search Tool):DeepResearcher 通過生成 JSON 格式的請求來調用網頁搜索工具。搜索結果以結構化格式返回,每條結果包含標題(title)、URL 和摘要(snippet)。當前實現使用固定的 top-k(如 10) 作為搜索結果的檢索參數。未來工作可以探索基于 LLM 的動態參數優化 以提升搜索效率。
-
網頁瀏覽智能體(Web Browsing Agent):網頁瀏覽智能體為 DeepResearcher 系統提供可靠、與問題相關、且可增量更新的信息。具體而言,它對每個查詢維護一個短期記憶庫。當收到網頁瀏覽請求時,智能體首先處理 URL 的第一頁內容,然后基于查詢、歷史記憶和新獲取的網頁內容執行兩種操作: 1. 判斷是否需要繼續讀取下一個 URL / 頁面片段,或者停止瀏覽。 2. 將相關信息追加到短期記憶庫。 當智能體決定停止瀏覽時,它會整理短期記憶庫中的新增信息并將其返回給 DeepResearcher 系統。
-
回答生成(Answering):當模型判斷已獲取足夠信息后,它會生成最終答案,并將其封裝在 <answer></answer> 標簽內返回給用戶。
挑戰:動態真實世界網絡環境中的挑戰
挑戰一:單次高并發請求:GRPO 的實現導致了大量的采樣迭代,從而導致大量的搜索查詢和網頁抓取操作(例如,4096 個),導致延遲很長。為了解決這個問題,我們創建了一個包含 50 個節點的分布式 CPU 服務器集群,專門設計用于管理 RL rollout 過程中生成的工具請求。每個服務器負責處理這些請求的一部分,處理搜索結果并根據語言模型確定的 URL 抓取網頁以進行進一步閱讀。
挑戰二:管理網頁抓取和 API 限制:在抓取階段,系統經常遇到網絡服務器部署的反爬蟲措施,這可能會導致返回無關內容或完全無法響應。同樣,在與搜索引擎或 LLM API 接口時,可能會出現諸如提供商速率限制(例如,每秒 200 次)之類的限制。為了緩解這些問題,我們實現了一個強大的重試機制,有效地解決了 API 調用或網頁抓取過程中遇到的異常。此外,我們引入了搜索結果的緩存策略:如果在預定的時期(例如,7 天)內進行了相同的搜索查詢,則系統會從緩存中檢索結果。這種方法不僅可以減少 API 調用頻率,還可以幫助管理相關成本,尤其是像 Google Search API 這樣的昂貴服務。
挑戰三:通過多代理方法優化信息提取:我們采用了一種多代理框架,其中專門的閱讀代理負責從抓取的網頁中提取相關信息。由于許多網頁都很長,并且可能只包含有限的相關內容,因此這些頁面被劃分為較小的片段。閱讀代理通過從第一頁開始按順序處理內容來模仿人類行為。在假設 URL 的初始片段主要包含無關信息的情況下,該網頁可能無法產生效益,可以被跳過,這種方法可以更有效地分配資源,并提高整體信息提取的準確性。
數據:構建依賴搜索的訓練數據集
1. 數據來源:
- 開放域問答數據集: DeepResearcher 利用了現有的開放域問答數據集,這些數據集包含單跳和多跳問題,需要通過在線搜索才能找到準確的答案。具體而言,它使用了以下數據集:
- 單跳場景: NaturalQuestions (NQ) 和 TriviaQA (TQ)
- 多跳場景: HotpotQA 和 2WikiMultiHopQA (2Wiki)
2. 數據清洗:
- 低質量問題過濾: 為了確保數據質量,DeepResearcher 排除了可能導致不可靠或有問題搜索結果的問題,如時間敏感問題、高度主觀查詢、潛在有害或違反政策的內容。
- 數據清洗工具: DeepSeek-R1 被用于數據清洗,通過精心設計的評估提示來識別和標記問題。
3. 污染檢測:
-
防止模型依賴記憶: 為了確保模型真正學習使用搜索工具,而不是僅僅依靠記憶,DeepResearcher 實施了污染檢測程序。對于每個候選問題,它從將用于訓練的基礎模型中隨機采樣 10 個響應,并檢查任何響應是否包含正確答案。如果模型表現出先驗知識(即在沒有搜索的情況下產生正確答案),則該問題將從訓練集中排除。
4. 數據集規模和分布:
-
最終訓練數據集: DeepResearcher 的最終訓練數據集包含 80,000 個示例,NQ:TQ:HotpotQA:2Wiki 的分布比例為 1:1:3:3。這種比例故意強調了多跳場景(75% 的示例),因為這些場景更好地反映了深度研究問題所需的復雜信息搜索行為。
DeepResearcher 的數據集構建和處理過程旨在確保數據質量,并防止模型僅僅依賴記憶,而是真正學習使用搜索工具進行深度研究。
優勢:涌現的泛化能力
DeepResearcher 強化學習擴展(RL Scaling)訓練是確保模型泛化能力的關鍵機制。通過在海量真實網絡查詢中不斷試錯和優化,模型能夠逐步建立起對搜索策略的深刻理解,而非簡單記憶特定查詢 - 響應對。
- 規劃能?:能夠在解決多跳問題時制定初始計劃并動態調整。
- 交叉驗證:不?即采納?次搜索結果,?是通過后續步驟驗證其準確性。
- ?我反思:當檢索信息與預期不符時,能夠反思并重定向研究?向。
- 誠實度:當?法找到確定答案時能夠承認局限性。
DeepResearcher性能和泛化能力
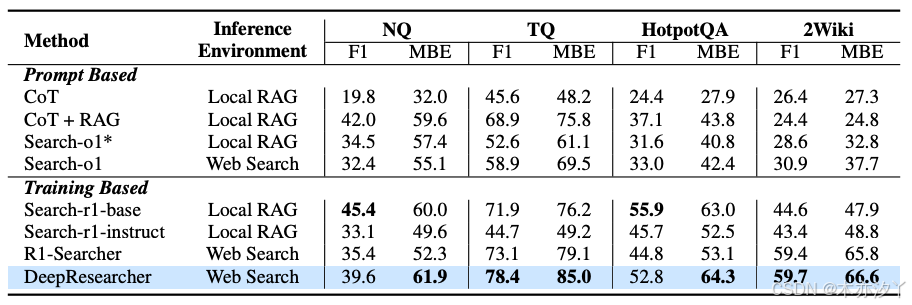
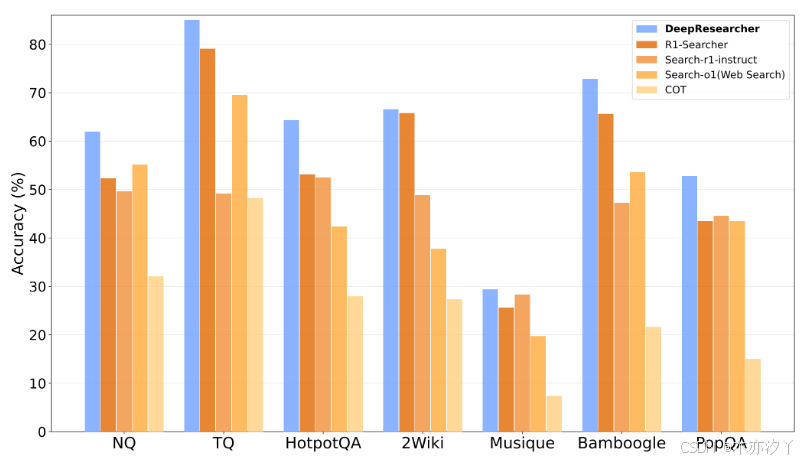
DeepResearcher 在各類評估基準上均表現出色。在訓練領域內(ID )的測試中(包括 NQ、TQ、HotpotQA 和 2Wiki 數據集),系統比提示工程 Agent 提高了 28.9 點的性能,比基于 RAG 的 RL Agent 提高了高達 7.2 點。這一結果特別顯著,因為它表明即使在高度競爭的基準測試中,真實環境訓練仍能帶來明顯的性能提升。?
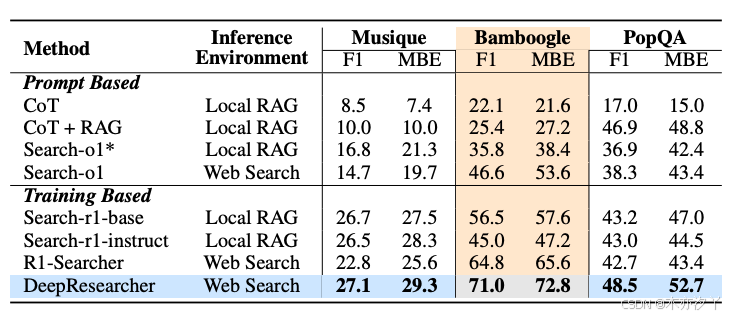
而在領域外(OOD)數據集上的表現也相當出色。在 MuSiQue、Bamboogle 和 PopQA 這三個與訓練數據差異較大的測試集上,DeepResearcher 一致超越所有其他基線方法。這種跨領域的泛化能力證明系統不只是記住了特定分布的問答模式,而是真正學習了通用的研究技能。模型能夠將在一種問題類型上學到的推理和搜索策略遷移到全新的問題領域,這對于實際應用至關重要。?
小結
DeepResearcher 創新性地提出了在真實世界網絡環境中進行端到端強化學習訓練深度研究智能體的框架,有效解決了傳統方法在開放域任務中的局限性,通過多智能體架構和技術創新,顯著提升了智能體的研究能力和泛化性,并揭示了涌現的規劃、交叉驗證、反思和誠實等認知行為,?主規劃研究路徑(如分解復雜問題為?任務),動態交叉驗證信息可靠性(如對?盾搜索結果發起第?輪驗證),處理開放域未?過的問題類型(泛化能?顯著優于傳統?法),強調了真實世界環境對于訓練魯棒智能體的根本重要性。
總結
兩者雖然都采用 端到端強化學習(RL) 訓練,但目標和環境存在本質差異。
OpenAI 的 DeepResearch,基于 o3 模型的 RL 訓練專注于優化多步驟推理,例如通過“思維令牌”模擬人類邏輯推導過程,但其訓練環境可能依賴 模擬網絡環境 。上海交大 DeepResearcher,直接在 真實網絡環境 中訓練,通過 RL Scaling 實現自主規劃、交叉驗證與動態調整策略。例如,回答“電影先驅”問題時,模型會主動發起多輪搜索以驗證信息可靠性。
OpenAI 的 DeepResearch 聚焦于 商業場景的效率提升(如快速生成報告),而 上海交大 DeepResearcher 開創了 自主研究型 AI 的新范式,通過真實環境 RL 賦予模型類人研究行為。




)






)



的完整示例及配置說明( banner.txt 文件和配置文件屬性信息))

圖像濾波-----中值模糊函數medianBlur())


暴力娛樂篇30)