文章目錄
- 1. 大數據概述
- 1.1 大數據的特性
- 1.2 大數據技術生態
- 1.2.1 Hadoop 的概念特性
- 1.2.2 Hadoop生態圈 — 核心組件與技術棧
- 1.2.3 Hadoop生態演進趨勢
- 2. 數據處理流程與技術棧
- 2.1 數據采集
- 2.1.1 日志采集工具
- 2.1.2 實時數據流
- 2.1.3 數據遷移
- 2.2 數據預處理
- 2.2.1 批處理
- 2.2.2 流處理
- 2.2.3 混合處理
- 2.3 數據存儲與管理
- 2.3.1 分布式文件系統
- 2.3.2 結構化/半結構化存儲
- 2.3.3 實時存儲優化
- 2.4 數據分析與挖掘
- 2.4.1 SQL引擎
- 2.4.2 OLAP分析
- 2.4.3 機器學習與AI
- 2.5 數據可視化
理解這些概念、框架、常用技術棧,后續學習、實踐中大體有個數。
1. 大數據概述
1.1 大數據的特性
- 規模性
以 PB、EB、ZB 為計量單位。(M<G<T<P<E<Z)
1GB = 1024 MB、1TB = 1024GB
1PB = 1024TB、1EB = 1024PB、1ZB = 1024EB
- 多樣性
數據來源多、類型復雜、數據關聯性強
關于數據類型:
?結構化數據——財務系統、業務系統、醫療系統等產生的數據
?半結構化數據——html文檔、xml文檔、郵件等
?非結構化數據——音視頻、圖片等
- 高速性
單位時間內流量高,數據增長速度快,且要求數據處理響應速度要快,一般要實時處理與分析 - 價值性
從大量不相關的各類數據中,挖掘出對未來趨勢、模式預測有價值的數據。如金融風控、實時健康監控、零售業的精準營銷等。 - 準確性
收集的數據要真實、準確、有意義。如根據電影評分、評論分析電影,進行購票 - 動態性
大數據是根據互聯網技術產生的實時的、動態的數據 - 可視化
數據可視化,直觀的解釋數據的意義 - 合法性
數據收集必須遵照國家政策與法律規定,且規避掉個人隱私數據、企業內部數據的收集,除非得到授權許可。
1.2 大數據技術生態
1.2.1 Hadoop 的概念特性
??Hadoop是分布式大數據處理的基礎框架,其生態圈通過模塊化組件解決了數據存儲、計算、管理和分析的全流程問題。其核心價值在于低成本處理海量數據。Hadoop底層數據存儲使用副本機制,默認為3個(高可靠);集群支持熱插拔,增刪節點后,無需重啟集群(高擴展);MapReduce支持分布式的并行計算(高效率);能自動將失敗任務重新分配(高容錯);可運行在低成本的機器上(低成本)。
??Hadoop核心設計理念:分布式存儲(HDFS) 和 分布式計算(MapReduce),并在此基礎上衍生出豐富的工具鏈。
1.2.2 Hadoop生態圈 — 核心組件與技術棧
- 存儲層
-
HDFS(Hadoop Distributed File System)

功能:分布式文件系統,將數據分塊存儲在集群節點上,支持高容錯、高吞吐。
場景:存儲原始日志、非結構化數據(如文本、圖片)。
優化:與糾刪碼(Erasure Coding)結合降低存儲成本。

-
HBase
是一個分布式,面向列的開源數據庫,適合存半結構化、非結構化數據。
功能:分布式 NoSQL 數據庫,基于 HDFS 實現低延遲隨機讀寫。

場景:實時查詢(如用戶畫像、訂單狀態)。
特點:強一致性、列式存儲、支持海量稀疏數據。 -
云存儲集成
Amazon S3、阿里云 OSS:替代 HDFS 作為存儲層,支持存算分離架構。
- 計算層
-
MapReduce

功能:經典的批處理框架,分 Map(映射)和 Reduce(歸約)兩階段。
局限:磁盤 I/O 開銷大,適合離線場景(如歷史數據統計)。


-
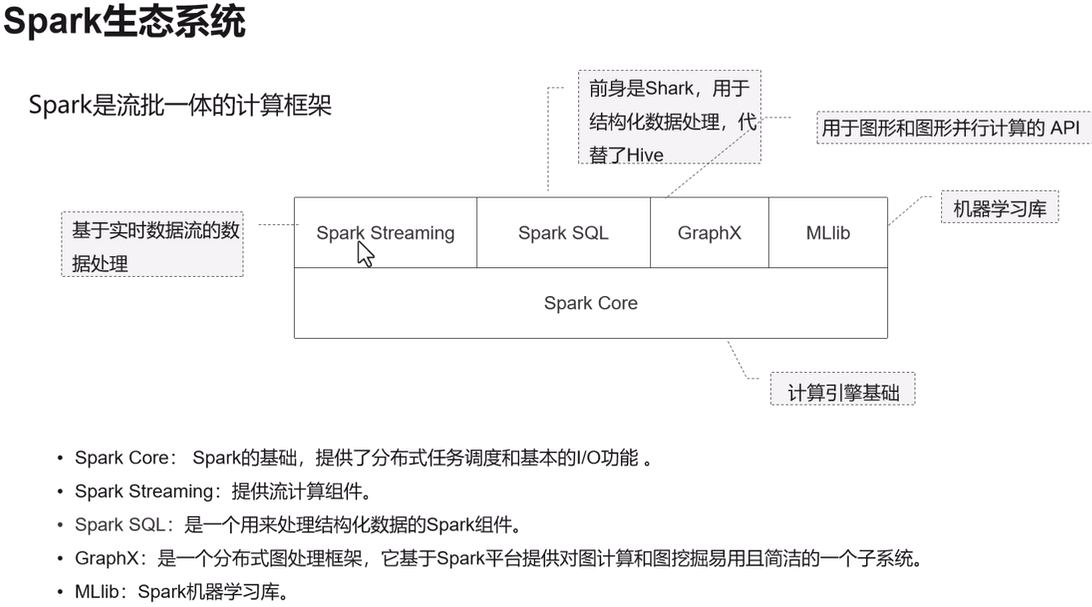
Spark
功能:基于內存的分布式計算引擎,兼容 MapReduce 但性能提升 10~100 倍。
場景:ETL、機器學習(MLlib)、圖計算(GraphX)。
優勢:支持 SQL(Spark SQL)、流處理(Spark Streaming)。
Spark支持實時計算,支持離線計算,基于內存計算,支持迭代計算。
-
Tez
功能:優化 Hive/Pig 等工具的 DAG(有向無環圖)執行效率,替代傳統 MapReduce。
- 資源管理與調度
-
YARN(Yet Another Resource Negotiator)
功能:Hadoop 2.0 引入的資源管理器,解耦計算與資源調度。
作用:支持多計算框架(如 MapReduce、Spark、Flink)共享集群資源。
。
- 數據管理與查詢
-
Hive
是一個基于Hadoop的數據倉庫ETL工具,完成數據提取、轉換、加載的功能。
功能:基于 HDFS 的數據倉庫工具,通過 SQL(HiveQL)查詢大規模數據,解決結構化數據的查詢與統計。
 優化:LLAP(Live Long and Process)實現近實時查詢。
優化:LLAP(Live Long and Process)實現近實時查詢。 -
Presto/Trino
功能:分布式 SQL 查詢引擎,支持跨數據源(HDFS、MySQL、Kafka)聯邦查詢。
場景:交互式分析,替代 Hive 執行復雜查詢。 -
Impala
功能:MPP(大規模并行處理)引擎,提供低延遲 SQL 查詢(類似 Hive 但更高效)。
- 數據采集與同步
-
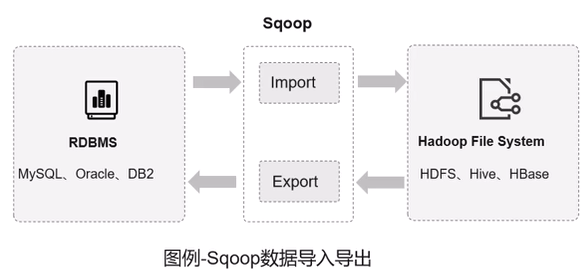
Sqoop
是一個在HDFS和RDMS間傳數據的工具,負責關系型數據庫(MySQL/Oracle)與 Hadoop(HDFS/Hive)之間的批量數據遷移。

-
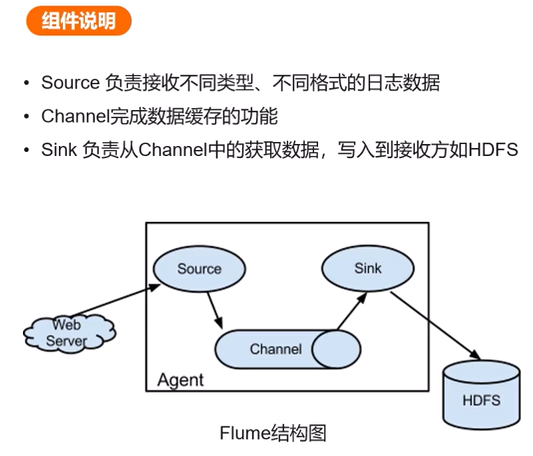
Flume
功能:是一個大數據集日志收集的框架,分布式日志采集工具,支持多級數據管道和容錯傳輸。

-
Kafka
功能:高吞吐消息隊列,用于實時數據流接入(如日志、傳感器數據)。
- 工作流與治理
-
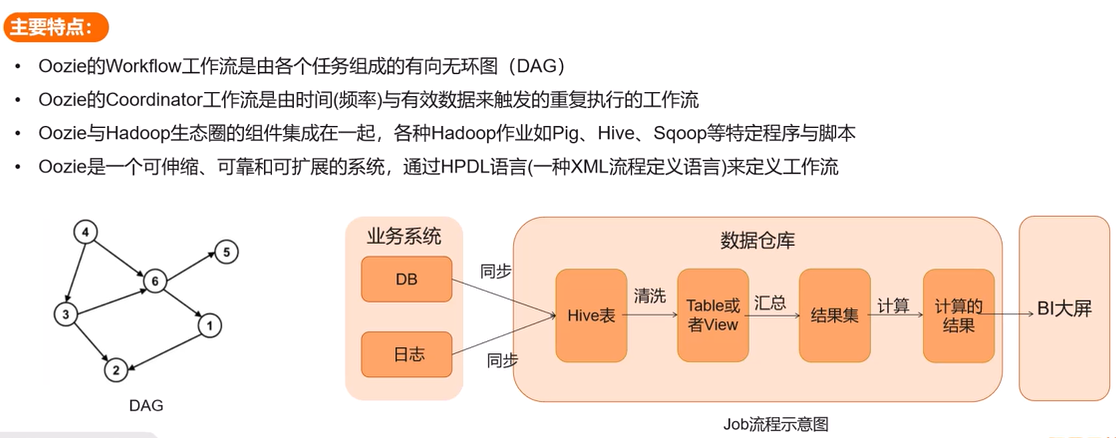
Oozie
功能:Hadoop 任務調度工具,支持復雜依賴關系的批處理作業編排,是一個管理Hadoop相關作業的工作流調度系統。
運行在Java Servlet容器中,用于定時調度任務、按執行的邏輯順序調度多個任務。
-
Atlas
功能:元數據管理與數據治理,支持數據血緣追蹤和合規審計。
-
Ranger
功能:統一權限管理框架,控制 HDFS、Hive、Kafka 等組件的訪問權限。
- 其他重要組件
- Mahout
分布式機器學習庫,專注于大規模數據集的機器學習算法(如分類、聚類、推薦系統)。
特點:
- 提供可擴展的算法實現,適合處理 TB 級數據。
- 支持多種計算框架(MapReduce → Spark → Flink)。
- 強調數學抽象,允許用戶自定義算法擴展。
優勢:支持超大規模數據集訓練;算法可定制性強,適合科研和特殊業務需求;無縫對接 HDFS、Hive 等數據源。
劣勢:需熟悉分布式計算和線性代數抽象,開發門檻高;落后于 Spark MLlib、TensorFlow 等框架。相比主流框架(如 PyTorch),更新和維護較慢。
- Pig
功能:主要用于簡化大規模數據集的復雜處理與分析任務。
核心特性:Pig 腳本會被解析為邏輯執行計劃(DAG),經過優化器優化后轉換為 MapReduce 任務,自動處理數據分區、任務并行度等細節。
優勢:Pig 更適合批處理場景,語法更貼近 SQL;Spark 則在迭代計算和實時處理上性能更優。逐漸支持在 Kubernetes 上運行,并與云存儲(如 Amazon S3)集成,推動存算分離架構

- ZoopKeeper
功能:是一個分布式協調服務,用于解決分布式系統中的一致性、配置管理、命名服務、分布式鎖等問題。

- Ambari
是 Hadoop 生態中的 集群管理與監控工具,旨在簡化 Hadoop 組件的部署、配置、運維和監控,提供 Web UI 和 REST API,降低大數據平臺的管理門檻。

1.2.3 Hadoop生態演進趨勢
- 云原生轉型
存儲層:HDFS 逐步被云對象存儲(S3/OSS)替代,實現存算分離。
計算層:Spark/Flink 等框架支持 Kubernetes 調度,提升彈性擴縮容能力。 - 實時化與流批一體
MapReduce 被 Spark/Flink 取代,Flink 成為流處理首選(低延遲、Exactly-Once 語義)。 - SQL 化與自動化
Hive LLAP、Flink SQL 等工具降低開發門檻,推動數據分析平民化。 - 與 AI 生態融合
Spark MLlib、TensorFlow on YARN 支持大規模機器學習模型訓練。
??隨著云原生和實時計算的發展,其組件(如 HDFS、MapReduce)會逐漸被優化或替代。未來 Hadoop 將更多以混合架構形式存在(如 Hive on S3、Spark on K8s),與云服務、實時引擎(Flink)深度整合。
2. 數據處理流程與技術棧
大數據處理流程:
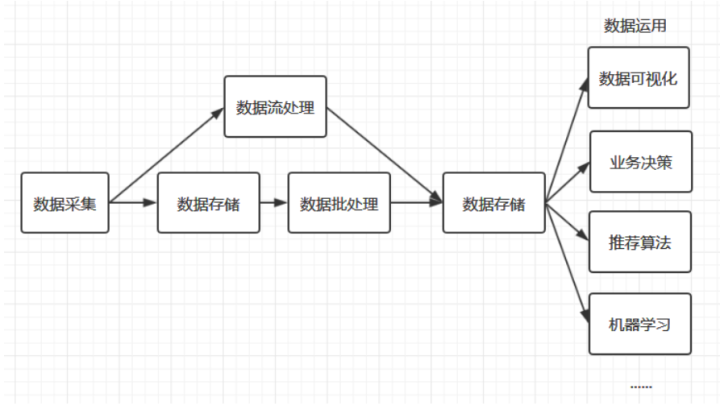
2.1 數據采集
2.1.1 日志采集工具
Flume:分布式日志收集系統,適用于多服務器場景。Logstash:支持多種數據源的采集與聚合,常與Elasticsearch、Kibana(ELK棧)結合使用。
2.1.2 實時數據流
Kafka:高吞吐量消息隊列,用于數據緩沖和實時流處理。Canal:基于MySQL Binlog的實時數據同步工具,用于數據庫增量數據抽取。
2.1.3 數據遷移
Sqoop:關系型數據庫與Hadoop生態(HDFS/Hive/HBase)間的批量數據遷移。DataX:插件化數據同步工具,支持全量與增量數據遷移。
2.2 數據預處理
2.2.1 批處理
Apache Spark:基于內存的分布式計算引擎,支持復雜ETL和機器學習。Hadoop MapReduce:經典的離線處理框架,適合大規模數據批量計算。
2.2.2 流處理
流處理主導:Flink因低延遲和狀態管理優勢逐漸取代Storm,成為實時計算首選。
Apache Flink:低延遲的真流處理框架,支持流批一體和狀態計算。Spark Streaming:微批處理模式,與Spark生態無縫集成。
2.2.3 混合處理
Flink SQL:通過SQL實現流批統一處理,簡化開發流程
2.3 數據存儲與管理
2.3.1 分布式文件系統
HDFS:Hadoop生態核心存儲,支持海量非結構化數據存儲。云存儲:Amazon S3、阿里云OSS等對象存儲服務。
2.3.2 結構化/半結構化存儲
HBase:面向列的分布式NoSQL數據庫,適合隨機讀寫場景。MongoDB:文檔型數據庫,靈活存儲半結構化數據。
2.3.3 實時存儲優化
Kudu:兼顧隨機讀寫與批量分析的列式存儲系統,與HDFS互補。Alluxio:內存加速的分布式存儲抽象層,提升跨系統數據訪問效率。
2.4 數據分析與挖掘
2.4.1 SQL引擎
Hive:基于Hadoop的SQL查詢工具,將SQL轉換為MapReduce任務。Presto:分布式MPP查詢引擎,支持跨數據源(HDFS、RDBMS等)快速查詢。
2.4.2 OLAP分析
Apache Kylin:預計算多維分析引擎,適用于亞秒級查詢響應。ClickHouse:高性能列式數據庫,適合實時分析場景。
2.4.3 機器學習與AI
TensorFlow、PyTorch:分布式模型訓練與推理框架。Spark MLlib:集成于Spark的機器學習庫
2.5 數據可視化
Tableau、Power BI:交互式數據可視化與報表生成。
的完整示例及配置說明( banner.txt 文件和配置文件屬性信息))

圖像濾波-----中值模糊函數medianBlur())


暴力娛樂篇30)






數據降維(scikitlearn))
)

的生命周期及應用場景)



