名人說:路漫漫其修遠兮,吾將上下而求索。—— 屈原《離騷》
創作者:Code_流蘇(CSDN)(一個喜歡古詩詞和編程的Coder😊)
專欄:《Python星球日記》,限時特價訂閱中ing
目錄
- 一、Seaborn 簡介
- 1. Seaborn 與 Matplotlib 的區別
- 2. 安裝與導入
- 二、高級繪圖
- 1. 分布圖:探索數據分布
- Histplot():組合直方圖和密度曲線
- 雙變量分布圖
- 2. 關系圖:探索變量關系
- scatterplot():散點圖
- lineplot():折線圖
- 帶置信區間的線圖
- 3. 分類圖:比較分組數據
- boxplot():箱線圖
- violinplot():小提琴圖
- 配對的分類圖
- 三、圖形組合
- 1. 使用 FacetGrid 繪制多個子圖
- 使用FacetGrid繪制不同類型的圖
- 2. 成對關系圖:pairplot()
- 3. 自定義配色方案
- 使用預設調色板
- 自定義連續調色板
- 在圖表中應用自定義調色板
- 四、實戰練習:多維度數據分析
- 1. 數據準備與探索
- 2. 多維度可視化分析
- 價格與克拉數的關系
- 不同切工質量的價格分布
- 使用FacetGrid創建多個維度的關系圖
- 多變量聯合分布
- 成對關系分析
- 3. 價格預測因素分析
- 五、總結與拓展
- 1. 核心要點回顧
- 2. Seaborn優勢總結
- 3. 進階學習方向
- 4. 學習資源推薦
👋 專欄介紹: Python星球日記專欄介紹(持續更新ing)
? 上一篇: Python星球日記 - 第22天:NumPy 基礎
歡迎來到Python星球日記第27天🪐!
今天我們將探索Seaborn,一個建立在Matplotlib基礎上的高級統計數據可視化庫。Seaborn提供了更優雅的界面、更美觀的默認樣式和更專業的統計圖表,讓我們能夠輕松創建出令人印象深刻的數據可視化作品。
一、Seaborn 簡介
1. Seaborn 與 Matplotlib 的區別
Seaborn是一個基于Matplotlib的Python數據可視化庫,專注于統計數據的可視化。雖然Matplotlib提供了繪圖的基礎功能,但Seaborn在此基礎上進行了多方面的增強和優化:
- 更美觀的默認樣式:Seaborn默認就提供了現代、專業的視覺風格,顏色協調且具有可讀性
- 更高級的統計圖表:內置了多種統計圖形,如小提琴圖、聯合分布圖、成對關系圖等
- 更簡潔的API:通過更少的代碼就能創建復雜的可視化效果
- 集成數據結構支持:與Pandas和NumPy深度集成,可直接使用DataFrame作為輸入
- 自動處理分類變量:能夠自動處理分類變量的映射和標簽
- 內置調色板:提供專業的配色方案,適用于各種數據可視化需求
簡單來說,Matplotlib是一個全能的底層繪圖庫,幾乎可以繪制任何圖形,但需要較多的代碼來調整和美化;而Seaborn則是一個專注于統計可視化的高級庫,提供了更簡潔的API和更美觀的默認樣式,特別適合于數據分析和探索過程中的可視化需求。
2. 安裝與導入
安裝Seaborn非常簡單:
# 使用pip安裝
pip install seaborn# 使用conda安裝
conda install seaborn

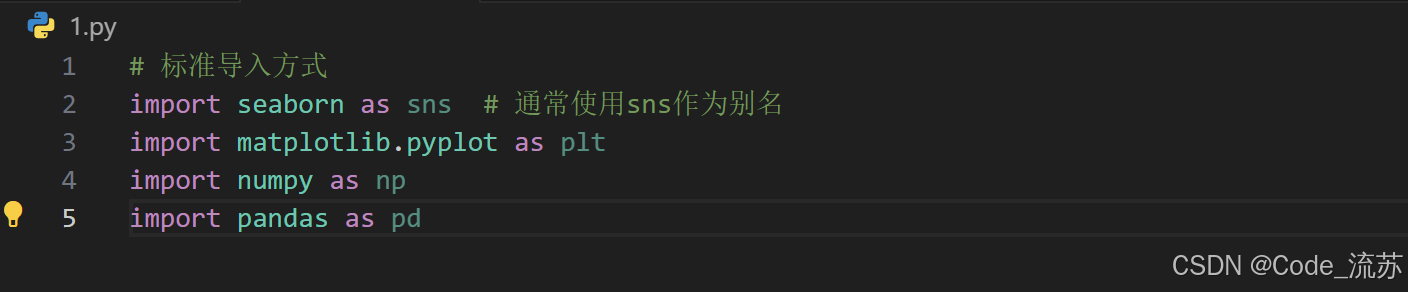
在代碼中導入Seaborn:
# 標準導入方式
import seaborn as sns # 通常使用sns作為別名
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
提示:雖然Seaborn是基于Matplotlib構建的,但通常仍需要導入
matplotlib.pyplot,因為某些操作(如調整圖表大小、顯示圖形等)仍需通過Matplotlib完成。
二、高級繪圖
Seaborn 提供了多種高級圖表類型,主要分為三類:分布圖、關系圖和分類圖。這些圖表類型能夠幫助我們深入理解數據的分布特征和變量之間的關系。
1. 分布圖:探索數據分布
分布圖用于可視化 單變量 或 雙變量 的分布情況,幫助我們理解數據的集中趨勢、離散程度和形狀特征。
Histplot():組合直方圖和密度曲線
Histplot()是一個便捷的函數,可以同時繪制直方圖和密度曲線:
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from matplotlib import font_manager# 動態加載字體
font_path = r"C:\Windows\Fonts\simhei.ttf"
font_manager.fontManager.addfont(font_path)
prop = font_manager.FontProperties(fname=font_path)plt.rcParams['font.family'] = prop.get_name()
plt.rcParams['axes.unicode_minus'] = False# 設置風格
sns.set_theme(style="whitegrid")# 生成數據
data = np.random.normal(0, 1, 1000)# 繪制直方圖并疊加核密度曲線
plt.figure(figsize=(10, 6))
sns.histplot(data,bins=30,kde=True,color="purple",alpha=0.6,line_kws={"color": "darkblue", "lw": 2})plt.title('標準正態分布的Histplot圖', fontsize=15)
plt.xlabel('值', fontsize=12)
plt.ylabel('頻率/密度', fontsize=12)
plt.show()
可視化效果:

雙變量分布圖
Seaborn還可以繪制雙變量的聯合分布圖:
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from matplotlib import font_manager# 動態加載字體
font_path = r"C:\Windows\Fonts\simhei.ttf"
font_manager.fontManager.addfont(font_path)
prop = font_manager.FontProperties(fname=font_path)# 生成雙變量數據
x = np.random.normal(0, 1, 1000)
y = x * 0.5 + np.random.normal(0, 1, 1000) # y與x相關# 繪制雙變量分布圖
plt.figure(figsize=(10, 6))
sns.jointplot(x=x, y=y, kind="scatter", # 類型:"scatter", "kde", "hex"color="teal", # 顏色height=8, # 圖形大小ratio=5, # 散點圖與邊緣分布圖的大小比例marginal_kws=dict(bins=25, fill=False)) # 邊緣分布圖參數plt.suptitle('雙變量聯合分布圖', y=1.02, fontsize=15)
plt.show()
可視化效果:
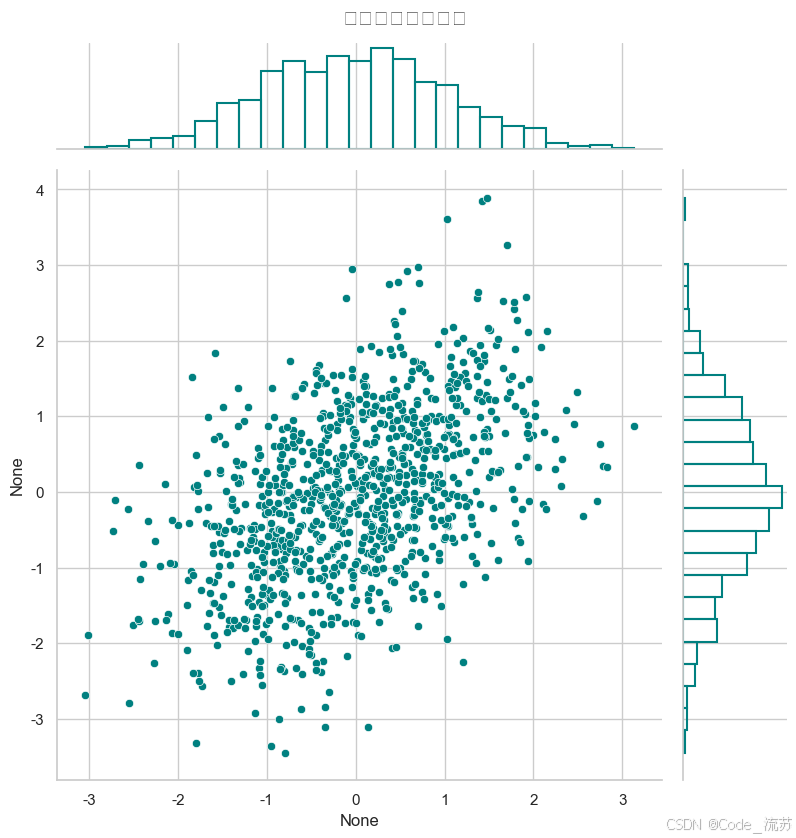
jointplot()可以生成中間的散點圖和邊緣的分布圖,非常適合觀察兩個變量的聯合分布和各自的邊緣分布。
2. 關系圖:探索變量關系
關系圖用于可視化兩個或多個變量之間的關系,幫助我們發現數據中的模式、趨勢和相關性。
scatterplot():散點圖
散點圖是觀察兩個連續變量關系的最基本工具:
import seaborn as sns
import matplotlib.pyplot as plt# 設置中文字體以避免亂碼
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 使用內置數據集
tips = sns.load_dataset("tips")# 繪制散點圖
plt.figure(figsize=(10, 6))
sns.scatterplot(x="total_bill", y="tip",hue="time", # 按"time"分組著色size="size", # 按"size"調整點大小palette="Set2", # 調色板data=tips) # 數據集# 添加圖表標題與軸標簽
plt.title('賬單金額與小費關系散點圖', fontsize=15)
plt.xlabel('賬單總額', fontsize=12)
plt.ylabel('小費', fontsize=12)# 顯示圖表
plt.tight_layout() # 自動調整布局
plt.show()
可視化效果:
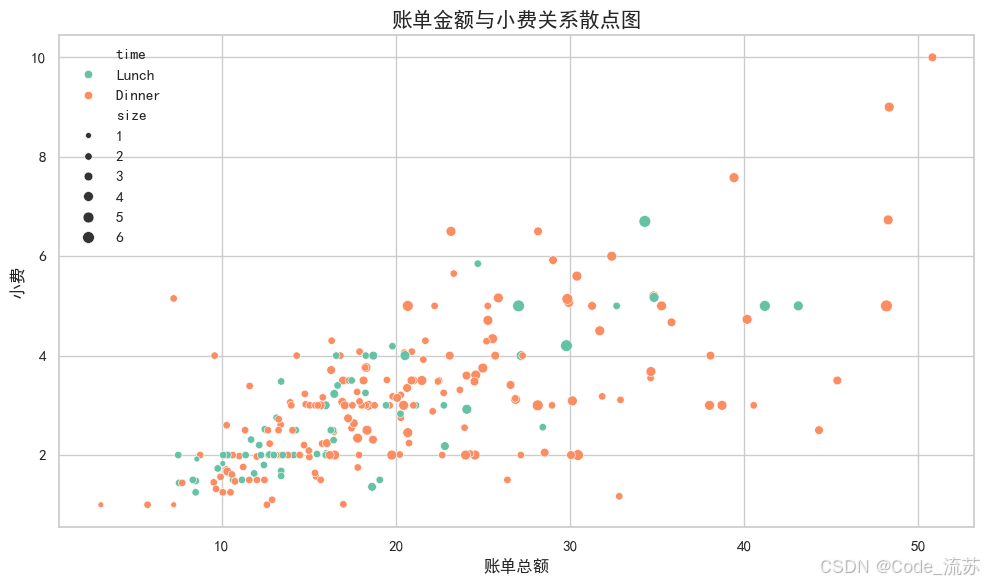
Seaborn的scatterplot()函數比Matplotlib的scatter()更強大,可以直接使用DataFrame,并且能通過hue和size參數輕松添加額外的維度。
lineplot():折線圖
折線圖適合展示隨時間或有序類別變化的趨勢:
import seaborn as sns
import matplotlib.pyplot as plt# 設置中文字體支持
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 使用內置數據集
flights = sns.load_dataset("flights")# 繪制折線圖
plt.figure(figsize=(12, 6))
sns.lineplot(data=flights,x="year", y="passengers", hue="month", # 按月份分組palette="tab10") # 調色板plt.title('1949-1960年各月航班乘客數量趨勢', fontsize=15)
plt.xlabel('年份', fontsize=12)
plt.ylabel('乘客數量', fontsize=12)
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
可視化效果:
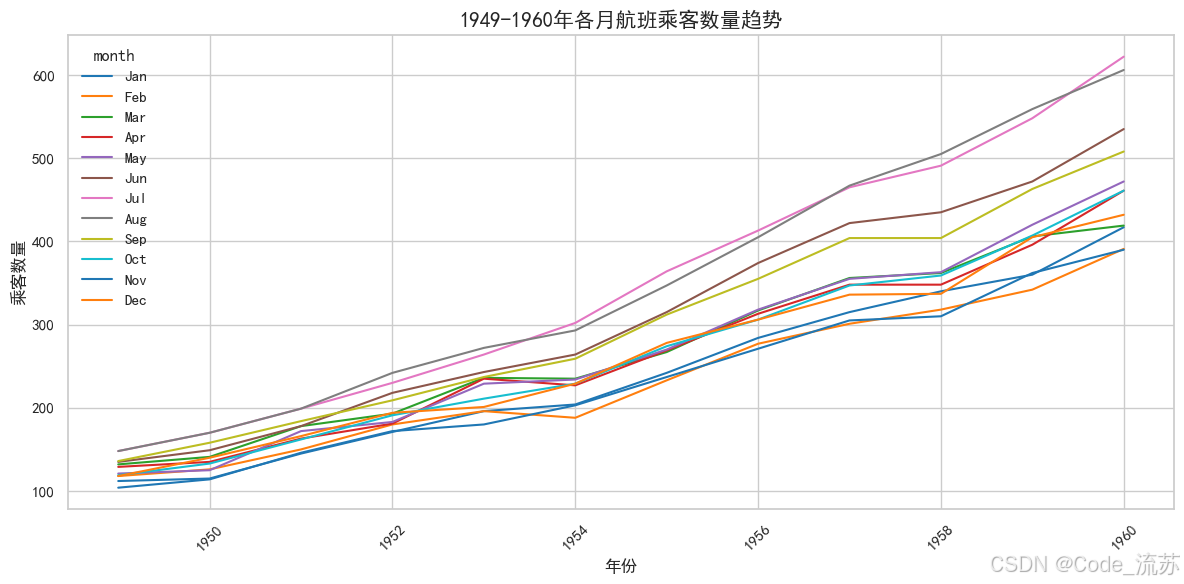
帶置信區間的線圖
Seaborn的線圖默認會顯示置信區間:
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt# 設置中文字體支持
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 生成模擬數據
np.random.seed(0)
x = np.linspace(0, 10, 100)
y = np.sin(x) + np.random.normal(0, 0.2, 100)# 創建DataFrame
df = pd.DataFrame({'x': x, 'y': y})# 繪制帶置信區間的線圖(使用新版Seaborn參數)
plt.figure(figsize=(10, 6))
sns.lineplot(x="x", y="y", data=df,errorbar=('ci', 95), # 使用新版語法替代cierr_style="band") # 誤差顯示樣式:"band"或"bars"plt.title('帶95%置信區間的線圖', fontsize=15)
plt.xlabel('X值', fontsize=12)
plt.ylabel('Y值', fontsize=12)
plt.tight_layout()
plt.show()
可視化效果:
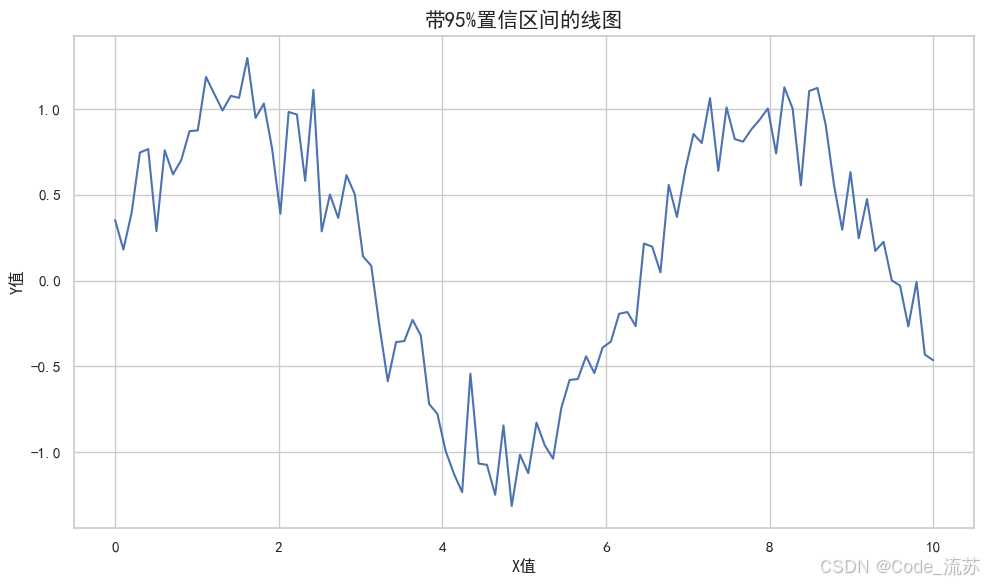
3. 分類圖:比較分組數據
分類圖用于分析和比較分類變量不同組別中數值變量的分布,是數據分析中非常實用的工具。
boxplot():箱線圖
箱線圖顯示數據的四分位數和異常值,是比較不同類別數據分布的有力工具:
import seaborn as sns
import matplotlib.pyplot as plt# 設置中文字體支持
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 使用內置數據集
tips = sns.load_dataset("tips")# 繪制箱線圖
plt.figure(figsize=(12, 6))
sns.boxplot(x="day", y="total_bill", hue="smoker", # 按吸煙者/非吸煙者分組palette="Set3", # 調色板data=tips) # 數據集plt.title('不同天的賬單金額箱線圖', fontsize=15)
plt.xlabel('星期', fontsize=12)
plt.ylabel('賬單金額', fontsize=12)
plt.tight_layout()
plt.show()
可視化效果:
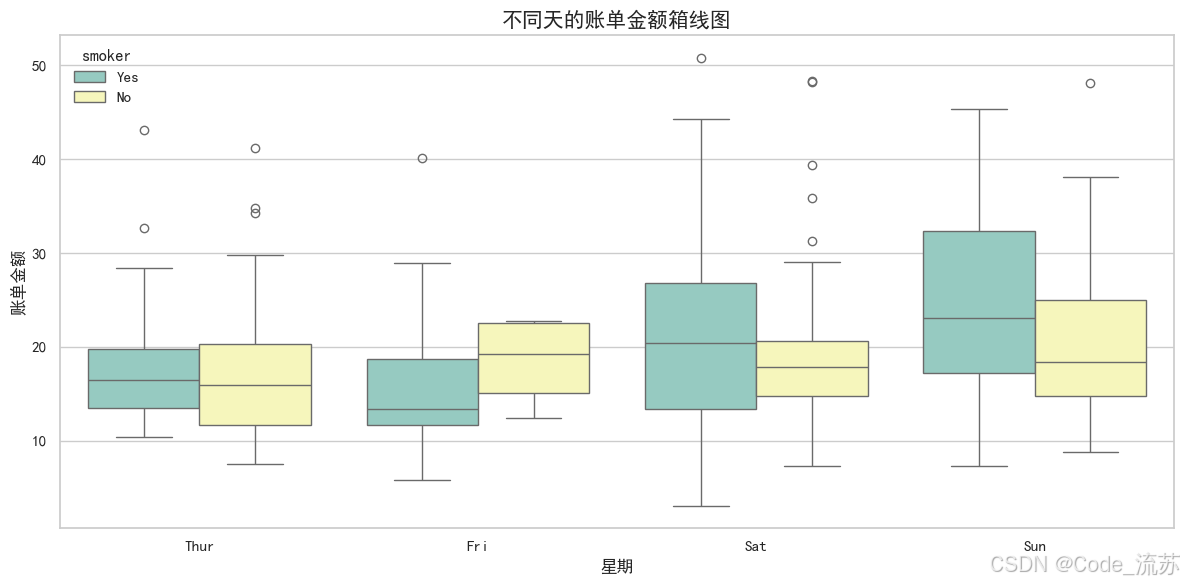
箱線圖的元素含義:
- 箱體:從第一四分位數到第三四分位數,表示中間50%的數據
- 中線:表示中位數
- 觸須:延伸到最小值和最大值,但不包括異常值
- 點:表示異常值
violinplot():小提琴圖
小提琴圖結合了箱線圖和密度圖的特點,展示了數據分布的密度和概率分布:
import seaborn as sns
import matplotlib.pyplot as plt# 中文字體支持
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 加載數據集
tips = sns.load_dataset("tips")# 繪制小提琴圖
plt.figure(figsize=(12, 6))
sns.violinplot(x="day", y="total_bill", hue="smoker", # 按吸煙者/非吸煙者分組split=True, # 拆分兩組對比inner="quart", # 內部標記:"quart", "box", "stick", "point"palette="Set2", # 調色板data=tips) # 數據集# 圖表美化
plt.title('不同天的賬單金額小提琴圖', fontsize=15)
plt.xlabel('星期', fontsize=12)
plt.ylabel('賬單金額', fontsize=12)
plt.tight_layout()plt.show()
可視化效果:
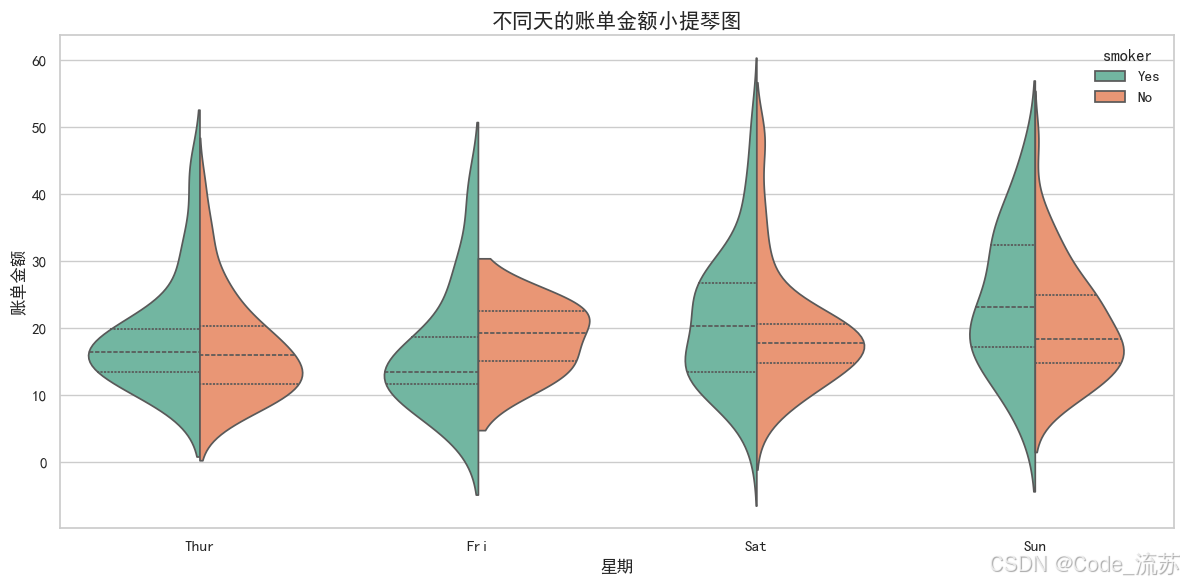
小提琴圖比箱線圖提供了更多信息,可以看到數據的完整概率密度分布。
配對的分類圖
可以組合多種類型的分類圖進行比較:
import seaborn as sns
import matplotlib.pyplot as plt# 中文字體支持
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 加載數據集
tips = sns.load_dataset("tips")# 創建一個包含箱線圖和小提琴圖的組合
f, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6), sharey=True)# 箱線圖
sns.boxplot(x="day", y="total_bill", data=tips, ax=ax1, palette="Pastel1")
ax1.set_title('箱線圖', fontsize=14)
ax1.set_xlabel('星期', fontsize=12)
ax1.set_ylabel('賬單金額', fontsize=12)# 小提琴圖
sns.violinplot(x="day", y="total_bill", data=tips, ax=ax2, palette="Pastel2")
ax2.set_title('小提琴圖', fontsize=14)
ax2.set_xlabel('星期', fontsize=12)
ax2.set_ylabel('') # 共享y軸,不重復顯示標簽plt.suptitle('箱線圖 vs 小提琴圖比較', fontsize=16)
plt.tight_layout(rect=[0, 0, 1, 0.96]) # 調整布局
plt.show()
可視化效果:
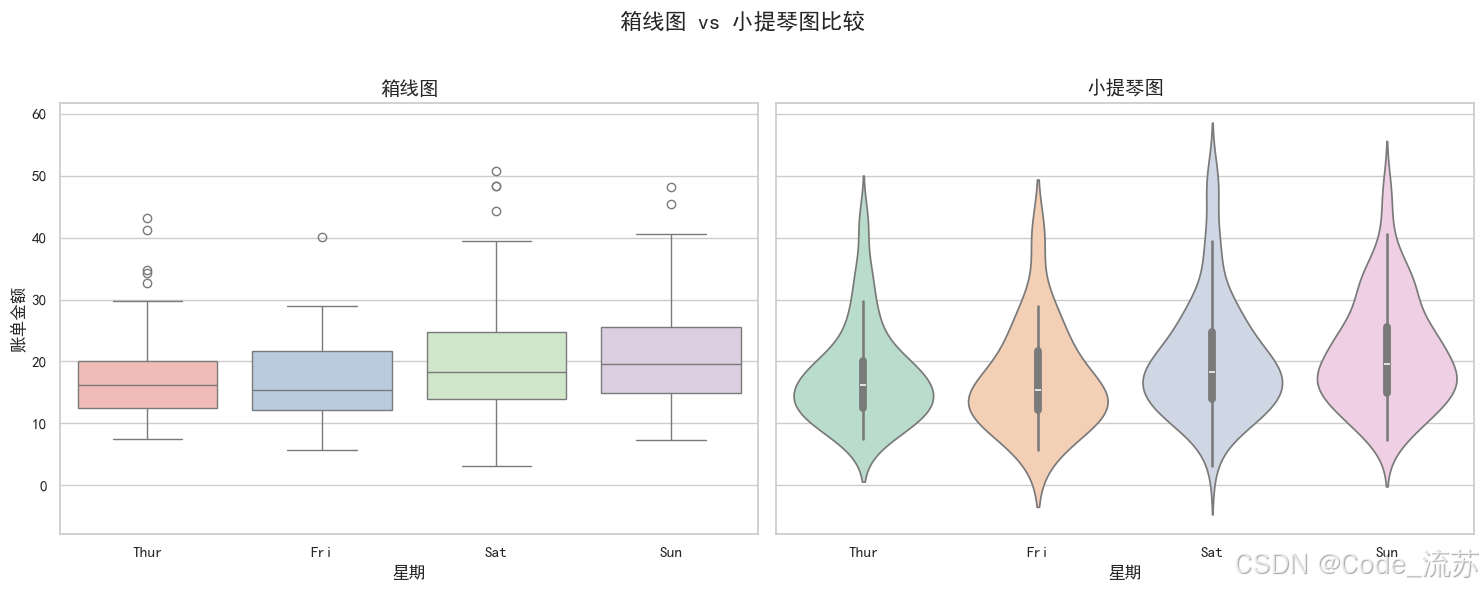
三、圖形組合
在數據分析中,我們經常需要在同一個圖形中展示多個維度的數據,或者按照某個變量的不同值創建多個子圖。Seaborn提供了強大的工具來實現這一點。
1. 使用 FacetGrid 繪制多個子圖
FacetGrid是Seaborn中最強大的功能之一,它可以按照某個分類變量的值,創建一個網格子圖,每個子圖顯示數據的不同子集。
# 使用FacetGrid創建按time和smoker分組的小提琴圖
g = sns.FacetGrid(tips, col="time", # 按列分組變量row="smoker", # 按行分組變量height=4, # 子圖高度aspect=1.2) # 寬高比# 在每個子圖上映射violinplot函數
g.map_dataframe(sns.violinplot, x="day", y="total_bill", palette="Set2")# 添加標題
g.fig.subplots_adjust(top=0.9) # 為標題騰出空間
g.fig.suptitle('按時間和吸煙狀態分組的賬單金額分布', fontsize=16)# 設置坐標軸標簽
g.set_axis_labels("星期", "賬單金額")
g.set_titles(col_template="{col_name}時段", row_template="{row_name}")plt.show()
使用FacetGrid繪制不同類型的圖
FacetGrid不僅限于繪制同一類型的圖,還可以應用不同的可視化函數:
# 創建分組的散點圖,并添加回歸線
g = sns.FacetGrid(tips, col="sex", row="smoker", height=4)# 映射regplot函數
g.map_dataframe(sns.regplot, x="total_bill", y="tip", scatter_kws={"s": 50, "alpha": 0.7},line_kws={"color": "red"})g.add_legend()
plt.show()
2. 成對關系圖:pairplot()
當我們想要探索數據集中多個變量之間的關系時,pairplot()函數非常有用,它可以創建變量之間兩兩配對的散點圖矩陣:
# 使用鳶尾花數據集
iris = sns.load_dataset("iris")# 繪制成對關系圖
sns.pairplot(iris, hue="species", # 按種類著色height=2.5, # 子圖大小diag_kind="kde", # 對角線圖形類型:"hist"或"kde"markers=["o", "s", "D"], # 不同組的標記類型palette="Set2") # 調色板plt.suptitle('鳶尾花數據集的成對關系圖', y=1.02, fontsize=16)
plt.show()
pairplot()會在對角線上繪制每個變量的分布圖,在非對角線位置繪制兩個變量之間的散點圖,非常適合探索性數據分析。
3. 自定義配色方案
Seaborn提供了豐富的調色板選項,可以根據數據類型和可視化目的選擇合適的配色方案。
使用預設調色板
# 展示Seaborn預設調色板
plt.figure(figsize=(12, 8))# 創建調色板列表
palettes = ["deep", "muted", "pastel", "bright", "dark", "colorblind"]# 繪制每種調色板
for i, palette in enumerate(palettes):plt.subplot(3, 2, i+1)# 創建5種顏色的調色板current_palette = sns.color_palette(palette, 5)# 顯示調色板sns.palplot(current_palette)plt.title(palette)plt.tight_layout()
plt.show()
自定義連續調色板
# 創建不同類型的連續調色板
plt.figure(figsize=(12, 8))# 單色調色板
plt.subplot(3, 1, 1)
sns.palplot(sns.light_palette("seagreen", 10))
plt.title("單色淡色調色板 (light_palette)")# 單色深色調色板
plt.subplot(3, 1, 2)
sns.palplot(sns.dark_palette("purple", 10))
plt.title("單色深色調色板 (dark_palette)")# 雙色漸變
plt.subplot(3, 1, 3)
sns.palplot(sns.color_palette("coolwarm", 10))
plt.title("雙色漸變調色板 (coolwarm)")plt.tight_layout()
plt.show()
在圖表中應用自定義調色板
# 在圖表中應用自定義調色板
plt.figure(figsize=(12, 6))# 創建自定義調色板
custom_palette = sns.color_palette("husl", 5)# 應用到條形圖
sns.barplot(x="day", y="total_bill", hue="smoker", palette=custom_palette,data=tips)plt.title('使用自定義調色板的條形圖', fontsize=15)
plt.show()
四、實戰練習:多維度數據分析
在這個練習中,我們將使用Seaborn對一個真實數據集進行多維度分析和可視化。我們將使用Seaborn內置的鉆石數據集,它包含了近54,000顆鉆石的價格和屬性數據。
1. 數據準備與探索
import seaborn as sns# 加載鉆石數據集
diamonds = sns.load_dataset("diamonds")# 查看數據集形狀
print("數據集形狀:", diamonds.shape)# 查看前5行數據
print("\n數據集前5行:")
print(diamonds.head())# 查看數值型字段的統計信息
print("\n數據集統計信息:")
print(diamonds.describe())# 查看分類變量的唯一值
print("\n分類變量的唯一值:")
for col in ['cut', 'color', 'clarity']:unique_vals = diamonds[col].unique()print(f"{col}(共{len(unique_vals)}類): {unique_vals}")
輸出結果:
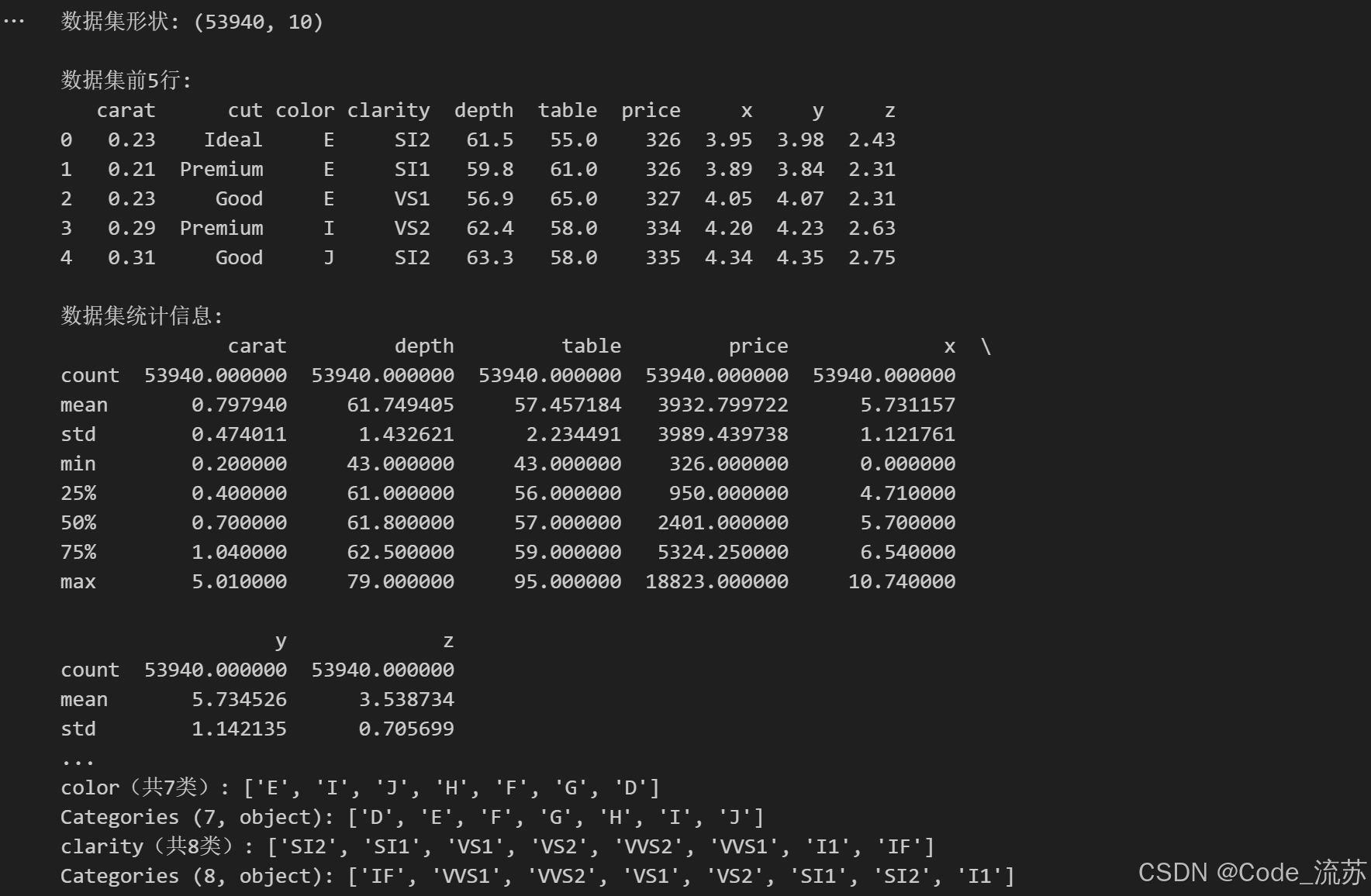
2. 多維度可視化分析
價格與克拉數的關系
# 設置Seaborn風格
sns.set_theme(style="whitegrid")# 繪制價格與克拉數的散點圖
plt.figure(figsize=(12, 8))
sns.scatterplot(x="carat", y="price", hue="cut", # 按切工質量著色size="depth", # 按深度調整點大小palette="viridis", # 使用viridis調色板sizes=(20, 200), # 點大小范圍alpha=0.7, # 透明度data=diamonds.sample(1000)) # 為了性能,隨機抽樣1000顆鉆石plt.title('鉆石價格與克拉數的關系', fontsize=16)
plt.xlabel('克拉數', fontsize=12)
plt.ylabel('價格 (美元)', fontsize=12)
plt.show()
輸出結果:
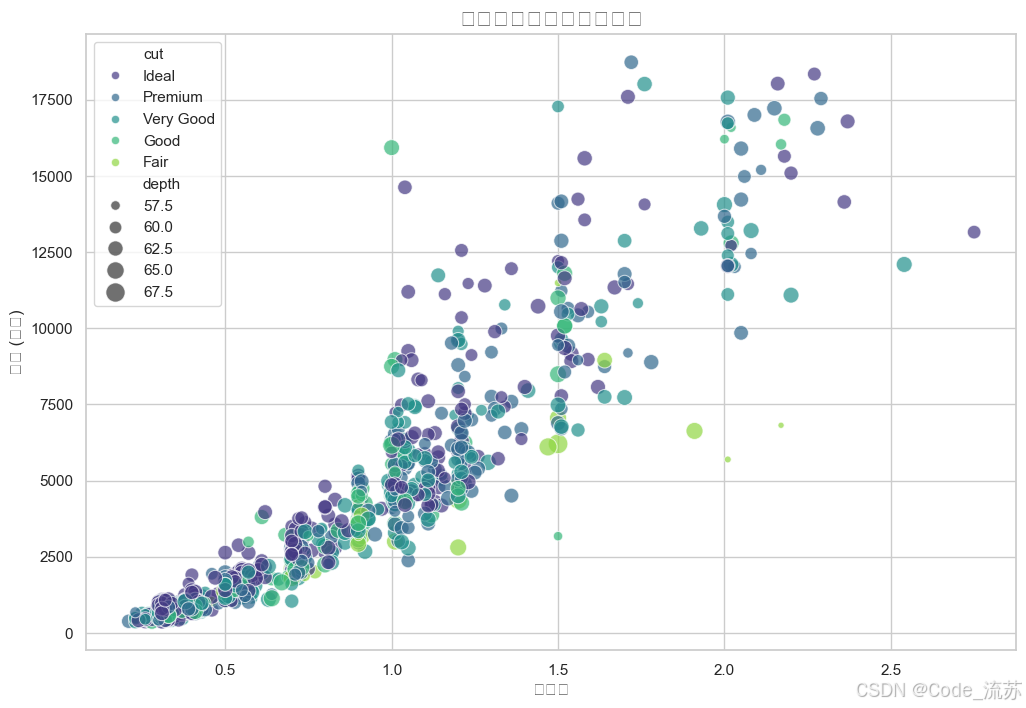
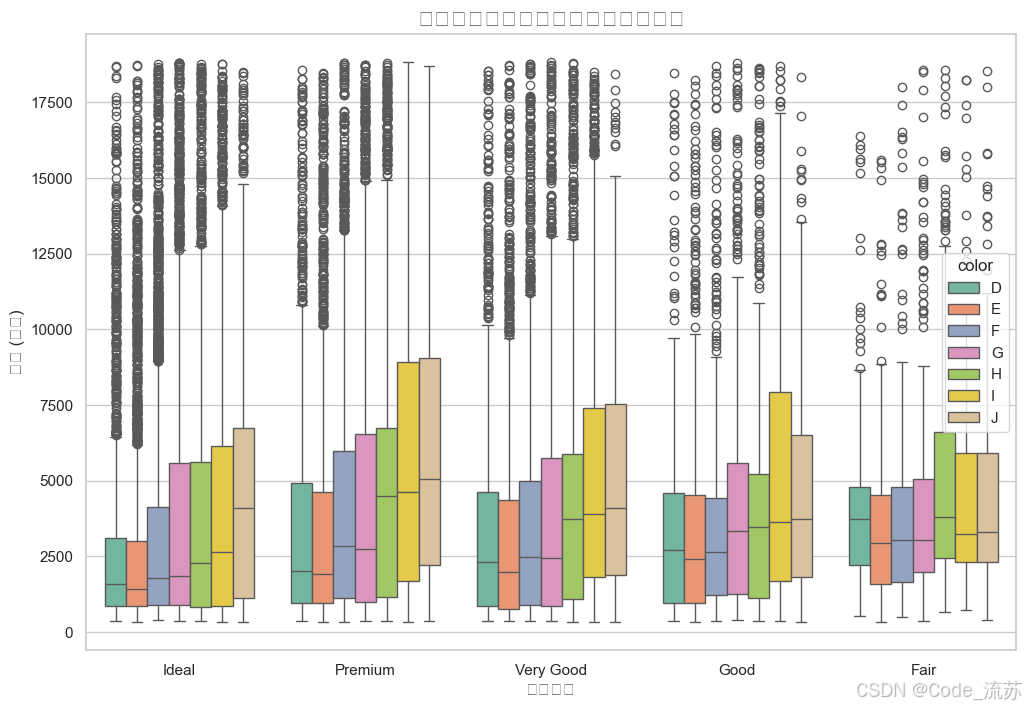
不同切工質量的價格分布
# 繪制不同切工質量的價格分布
plt.figure(figsize=(12, 8))
sns.boxplot(x="cut", y="price", hue="color", # 按顏色分組palette="Set2", # 使用Set2調色板data=diamonds) # 使用全部數據plt.title('不同切工質量和顏色的鉆石價格分布', fontsize=16)
plt.xlabel('切工質量', fontsize=12)
plt.ylabel('價格 (美元)', fontsize=12)
plt.xticks(rotation=0)
plt.show()
輸出結果:
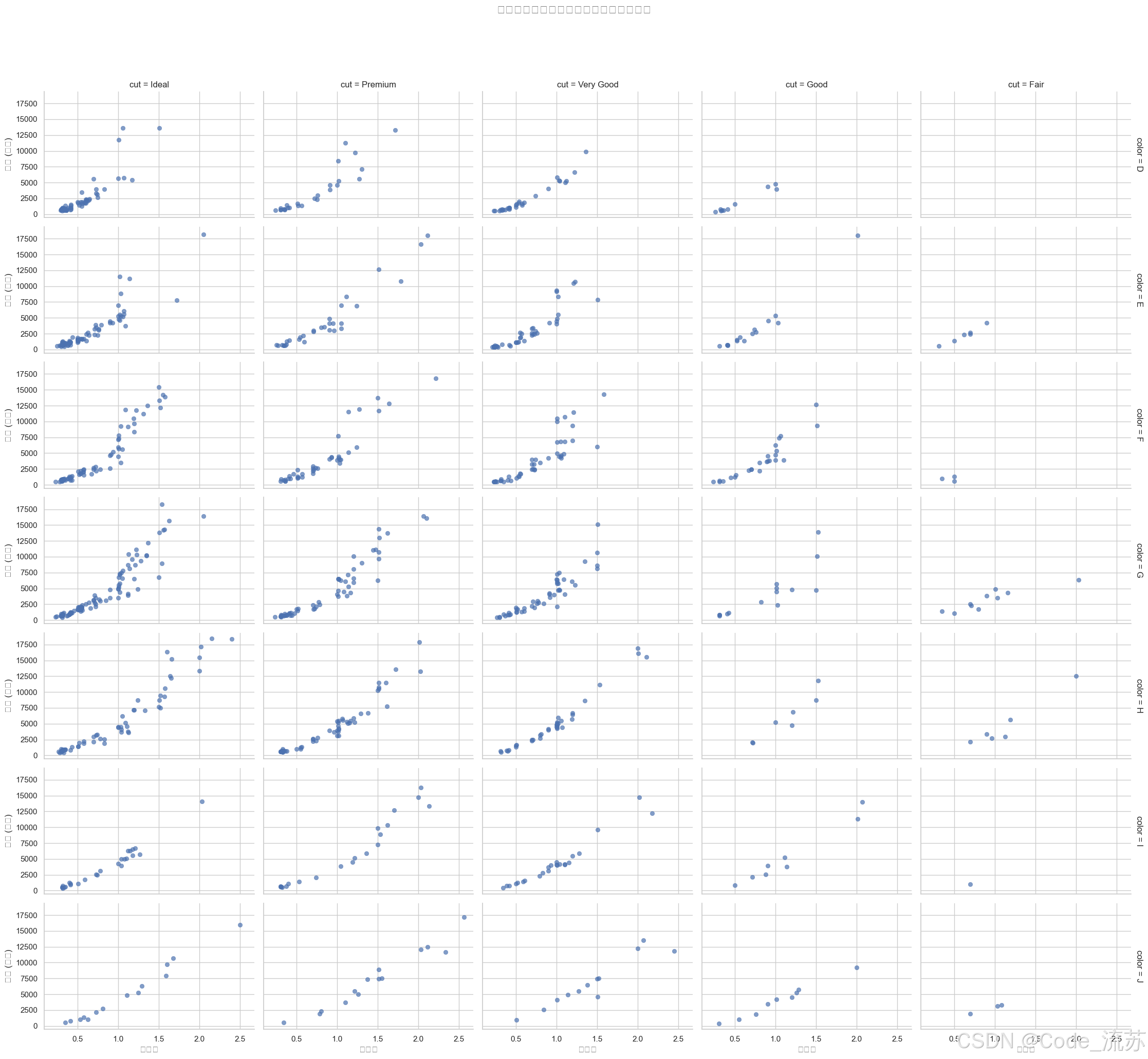
使用FacetGrid創建多個維度的關系圖
# 創建按切工質量和顏色分組的散點圖
g = sns.FacetGrid(diamonds.sample(1000), col="cut", # 按列分組變量row="color", # 按行分組變量height=3, # 子圖高度aspect=1.5, # 寬高比margin_titles=True)# 在每個子圖上映射散點圖
g.map_dataframe(sns.scatterplot, x="carat", y="price", alpha=0.7,edgecolor=None)# 添加標題
g.fig.subplots_adjust(top=0.9)
g.fig.suptitle('不同切工和顏色的鉆石價格與克拉數關系', fontsize=16)# 設置坐標軸標簽
g.set_axis_labels("克拉數", "價格 (美元)")plt.show()
輸出結果:
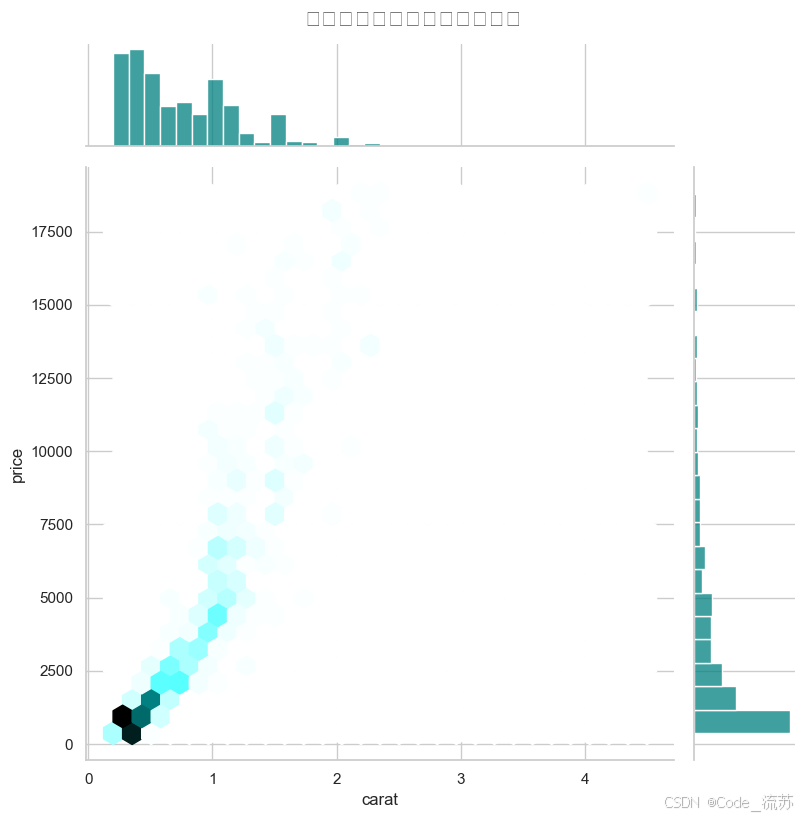
多變量聯合分布
# 探索price, carat和depth的聯合分布
plt.figure(figsize=(10, 8))
sns.jointplot(x="carat", y="price", data=diamonds.sample(1000),kind="hex", # 使用六邊形箱height=8, # 圖形大小ratio=5, # 散點圖與邊緣分布圖的大小比例color="teal") # 顏色plt.suptitle('鉆石價格與克拉數的聯合分布', y=1.02, fontsize=16)
plt.show()
輸出結果:
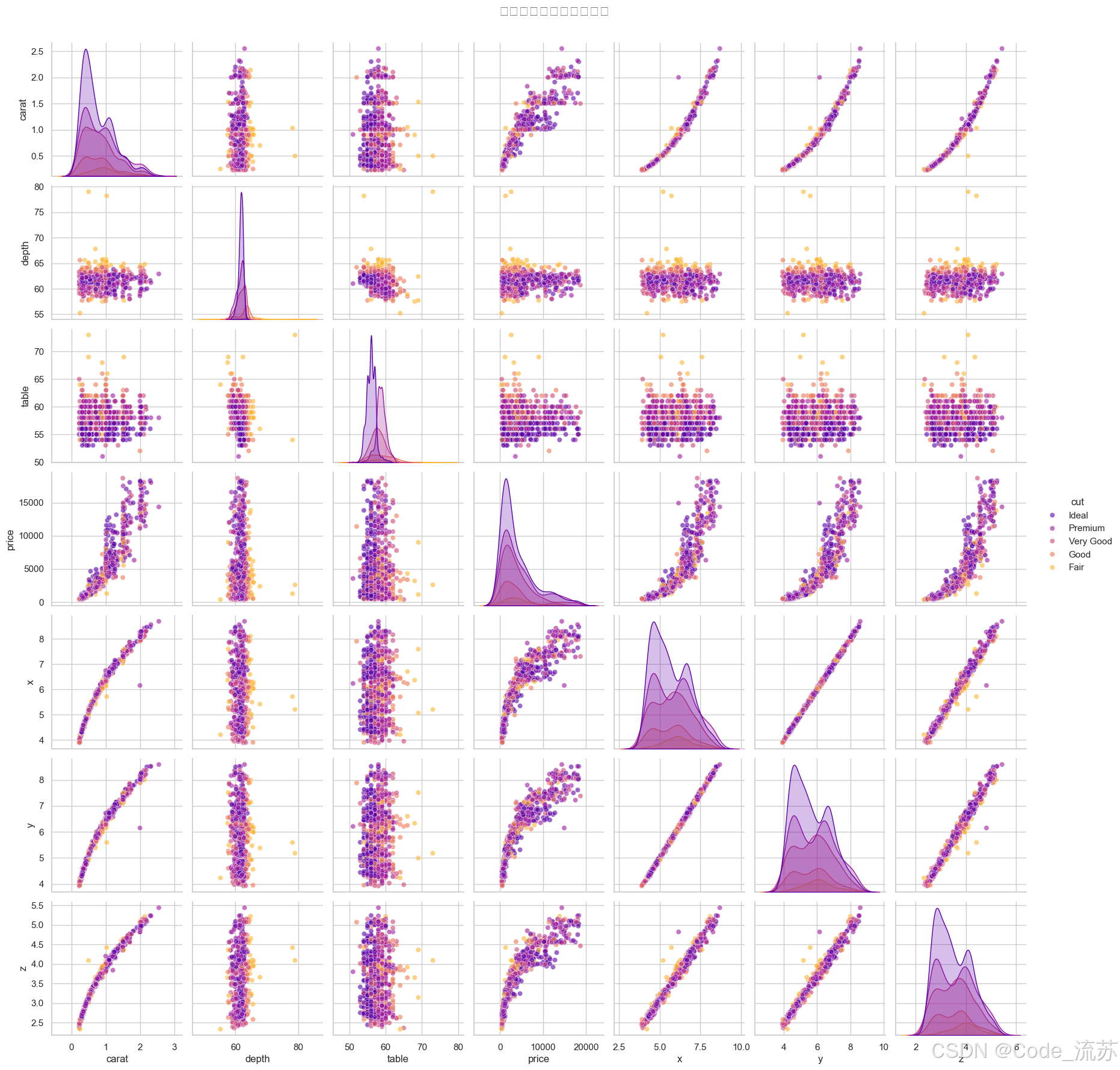
成對關系分析
# 選擇數值變量進行成對關系分析
diamonds_sample = diamonds.sample(1000) # 抽樣以提高性能
numeric_cols = ['carat', 'depth', 'table', 'price', 'x', 'y', 'z']# 繪制成對關系圖
sns.pairplot(diamonds_sample[numeric_cols + ['cut']], hue="cut", # 按切工質量著色height=2.5, # 子圖大小diag_kind="kde", # 對角線圖形類型plot_kws={"alpha": 0.6}, # 散點圖參數palette="plasma") # 調色板plt.suptitle('鉆石數據集的成對關系圖', y=1.02, fontsize=16)
plt.show()
輸出結果:
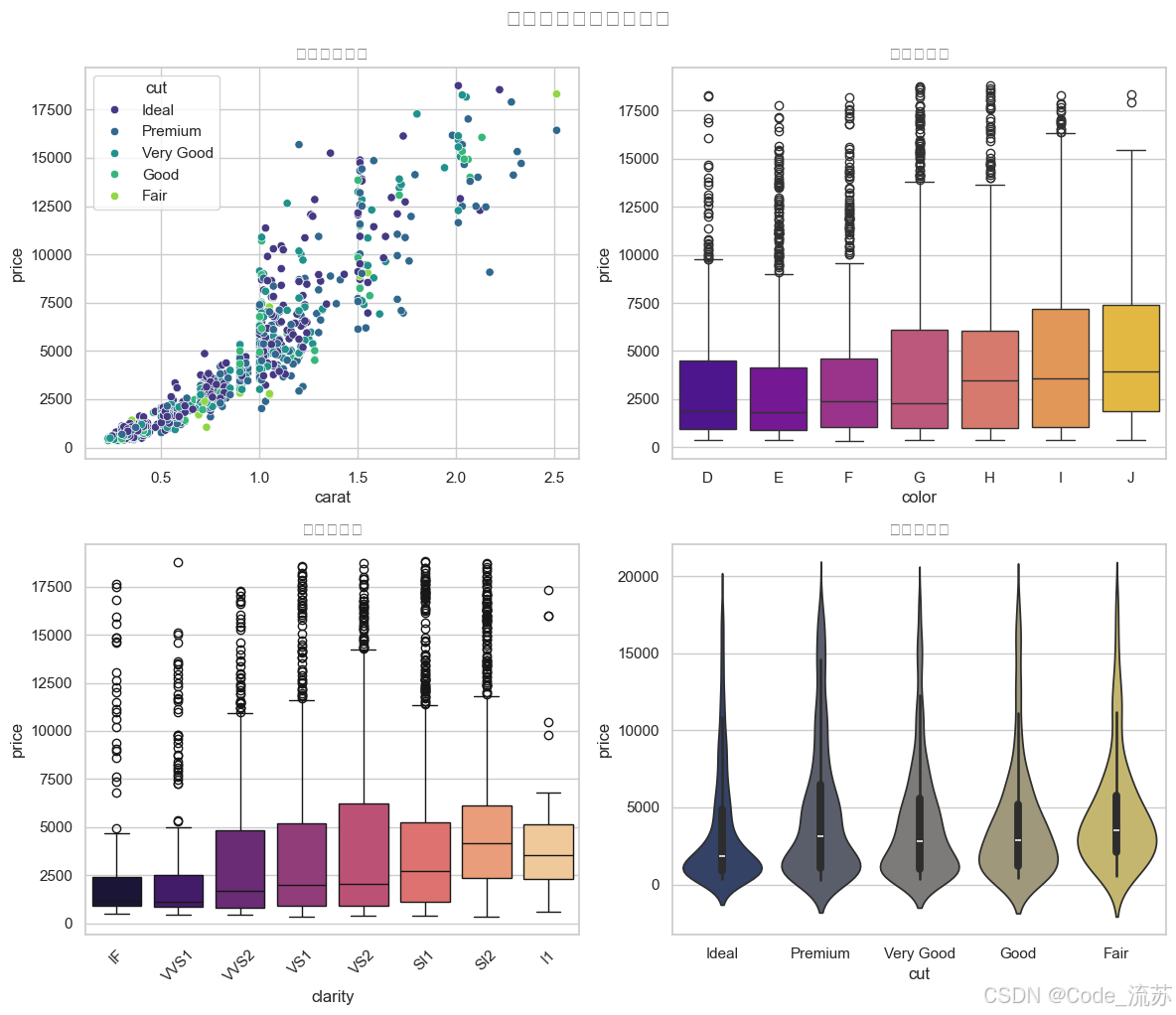
3. 價格預測因素分析
# 分析哪些因素對鉆石價格影響最大
plt.figure(figsize=(12, 10))# 創建一個包含4個子圖的面板
plt.subplot(2, 2, 1)
sns.scatterplot(x="carat", y="price", hue="cut", palette="viridis", data=diamonds.sample(1000))
plt.title('克拉數與價格')plt.subplot(2, 2, 2)
sns.boxplot(x="color", y="price", palette="plasma", data=diamonds.sample(5000))
plt.title('顏色與價格')plt.subplot(2, 2, 3)
sns.boxplot(x="clarity", y="price", palette="magma", data=diamonds.sample(5000))
plt.title('凈度與價格')
plt.xticks(rotation=45)plt.subplot(2, 2, 4)
sns.violinplot(x="cut", y="price", palette="cividis", data=diamonds.sample(5000))
plt.title('切工與價格')plt.tight_layout()
plt.suptitle('鉆石價格影響因素分析', y=1.02, fontsize=16)
plt.show()
可視化結果:
五、總結與拓展
1. 核心要點回顧
在本文中,我們學習了:
- Seaborn的基本概念:它是建立在Matplotlib基礎上的高級統計數據可視化庫
- Seaborn與Matplotlib的區別:Seaborn提供了更美觀的默認樣式和更高級的統計圖表
- 分布圖:通過
distplot()、kdeplot()等函數可視化數據分布 - 關系圖:使用
scatterplot()、lineplot()等探索變量之間的關系 - 分類圖:通過
boxplot()、violinplot()等比較不同類別的數據分布 - 圖形組合:使用
FacetGrid創建多維度的可視化,實現數據的深入探索 - 自定義配色:利用Seaborn豐富的調色板選項美化可視化效果
2. Seaborn優勢總結
- 高級接口:簡化了創建常見統計圖表的過程
- 美觀的默認樣式:減少了樣式調整的工作量
- 與Pandas無縫集成:直接支持DataFrame作為輸入
- 統計功能內置:自動計算并顯示置信區間、回歸線等統計信息
- 分組可視化能力:輕松實現按類別分組的多維度可視化
3. 進階學習方向
如果你想進一步提升Seaborn可視化技能,可以探索以下內容:
- 高級統計圖表:如回歸圖(
regplot)、殘差圖(residplot)、二元核密度圖(kdeplot) - 矩陣可視化:使用
heatmap()和clustermap()可視化大型數據矩陣 - 復雜圖形定制:深入學習Seaborn與Matplotlib的結合使用,實現高度定制化的可視化
- 交互式擴展:結合Plotly或Bokeh,為Seaborn圖表添加交互功能
- 深色模式:使用
set_theme(style="darkgrid")實現暗色背景的可視化效果
4. 學習資源推薦
- 官方文檔:Seaborn官方文檔
- 圖例集:Seaborn示例圖庫
- 在線教程:Datacamp、Coursera上的Python數據可視化課程
- 書籍:《Python for Data Analysis》和《Python Data Science Handbook》中的可視化章節
在下一篇文章中,我們將探索如何將我們學到的數據分析和可視化技能應用于實際項目,從數據獲取、清洗到分析和可視化的完整工作流程。
練習題:
- 嘗試使用Seaborn的
lmplot()函數,創建一個包含回歸線的散點圖,并按照某個分類變量分組。 - 使用任意開放數據集,創建一個FacetGrid,展示至少3個變量之間的關系。
- 探索Seaborn的
catplot()函數,嘗試使用不同的kind參數創建不同類型的分類圖,比較它們的優缺點。
希望這篇文章能幫助你掌握Seaborn的強大功能,創建更加專業和美觀的數據可視化作品!如有問題,歡迎在評論區留言交流!
創作者:Code_流蘇(CSDN)(一個喜歡古詩詞和編程的Coder😊)
如果你對今天的內容有任何問題,或者想分享你的學習心得,歡迎在評論區留言討論!




)

)




第五期)







