文章目錄
- 一、Kafka
- 1.Kafka核心介紹:
- ?核心架構
- ?核心特性
- ?典型應用
- 2.Kafka對 ZooKeeper 的依賴:
- 3.去 ZooKeeper 的演進之路:
- 注:(本文采用ZooKeeper3.8 + Kafka2.8.1)
- 二、Zookeeper
- 1.核心架構與特性
- 2.典型應用場景
- 3.優勢與局限
- 三、Zookeeper安裝部署
- 1.拉取鏡像
- 2.創建數據卷
- 3.創建容器
- 4.Zookeepe可視化工具-prettyZoo下載和安裝
- 5.prettyZoo使用
- 四、Kafka安裝部署
- 1.拉取鏡像
- 2.創建數據卷
- 3.創建容器
- 4.Kakfa可視化操作工具kafka-ui安裝
- 4.1、拉鏡像
- 4.2、創建容器
- 4.3、訪問kafka-ui
- 5.Kakfa可視化操作工具kafka-ui使用
- 五、Spring Boot使用Kafka
- 1.pom文件引入關鍵jar
- 2.yml文件引入配置
- 3.Topic配置
- 4.消息體創建
- 5.Producer實現
- 6.Consumer實現
- 7.啟動類配置
- 8.Controller測試發送
- 9.測試驗證
- 總結
一、Kafka
kafka官方文檔
1.Kafka核心介紹:
Apache Kafka 是由 ?Apache 軟件基金會開發的開源分布式流處理平臺,最初由 LinkedIn 團隊設計,旨在解決大規模實時數據管道問題。其核心功能是作為高吞吐、低延遲的分布式發布-訂閱消息系統,支持每秒百萬級消息處理能力。
?核心架構
?Topic(主題)?:消息的邏輯分類,生產者按主題發布數據,消費者按主題訂閱。
?Partition(分區)?:每個主題劃分為多個分區,實現數據并行處理和水平擴展。
?Broker(代理)?:Kafka 集群中的服務節點,負責存儲和路由消息。
?Producer/Consumer:生產者推送消息至 Broker,消費者從 Broker 拉取數據,支持消費者組(Consumer Group)實現負載均衡。
?核心特性
?持久化與高可靠:消息持久化到磁盤,通過多副本機制(Replication)保障數據容錯。
?水平擴展:通過分區和 Broker 動態擴容,支持萬級節點和 PB 級數據存儲。
?實時流處理:與 Spark、Flink 等框架集成,支持實時計算、日志聚合、監控報警等場景。
?典型應用
?日志收集:統一收集多源日志,供離線分析或實時監控。
?消息隊列:解耦系統組件,如電商訂單與庫存服務異步通信。
?實時推薦:基于用戶行為流(如點擊、搜索)實時生成個性化推薦。
?數據管道:作為 CDC(變更數據捕獲)工具,同步數據庫變更至數據湖或搜索引擎。
Kafka 憑借其高性能和靈活性,已成為大數據生態的核心組件,適用于金融、物聯網、電商等領域的實時數據處理需求。
2.Kafka對 ZooKeeper 的依賴:
Apache Kafka 在 ?4.0 版本之前 高度依賴 ZooKeeper,主要用于集群元數據管理(如 Broker 注冊、Topic 分區分配)、控制器選舉、消費者偏移量存儲(舊版本)等核心功能。ZooKeeper 作為分布式協調服務,承擔了 Kafka 集群的“大腦”角色,但存在運維復雜、性能瓶頸(如萬級分區下元數據同步延遲)等問題。
3.去 ZooKeeper 的演進之路:
?Kafka 2.8.0(2021年):?
首次引入 ?KRaft 模式(KIP-500)?,作為實驗性功能,允許用戶通過 KRaft 協議替代 ZooKeeper 管理元數據。但此時仍需 ZooKeeper 作為過渡支持,且未默認啟用。
?Kafka 3.3.x(2022年):?
KRaft 模式逐步穩定,支持生產環境部署,但仍需用戶手動配置切換模式。
?Kafka 4.0.0(2025年3月18日發布):?
?正式移除對 ZooKeeper 的依賴,默認僅支持 KRaft 模式。用戶無法再以 ZooKeeper 模式啟動集群,需通過 KRaft 完成元數據管理和控制器選舉。
注:(本文采用ZooKeeper3.8 + Kafka2.8.1)
我們本文還是使用kafka+zookeeper結合的方式來學習Kafka,在學習kafka的同時也能學習到zookeeper的使用,現在大部分公司還都在使用這種方式。
二、Zookeeper
Zookeeper官網
ZooKeeper 是一款由雅虎開源的分布式協調服務框架,旨在為分布式系統提供高效、可靠的一致性服務。其核心功能包括配置管理、分布式鎖、服務注冊與發現等,廣泛應用于大數據和微服務領域(如 Kafka、HBase、Dubbo)。
1.核心架構與特性
數據模型
采用樹形結構的 ?ZNode?(數據節點)存儲數據,每個節點可保存數據并包含子節點,類似于文件系統。節點分為四類:
?持久節點:長期存在,需手動刪除
?臨時節點:會話結束自動刪除
?順序節點:自動追加全局唯一序號,適用于分布式隊列
?一致性保障
基于 ?ZAB(ZooKeeper Atomic Broadcast)協議,確保數據順序一致性、原子性和可靠性。通過 ?Leader 選舉機制?(半數以上節點投票)實現高可用,集群需奇數節點(如 3、5 臺)以防止腦裂。
動態監聽(Watcher)?
客戶端可監聽節點變化(數據修改、子節點增減),觸發事件通知實現實時響應。
2.典型應用場景
?配置管理:集中存儲配置信息,動態推送到所有服務節點
?分布式鎖:通過臨時順序節點實現互斥資源訪問
?服務注冊與發現:如 Dubbo 使用 ZooKeeper 維護全局服務地址列表
?集群管理:監控節點狀態,自動處理故障切換
3.優勢與局限
?優勢:簡化分布式系統開發,提供高性能(內存存儲)和強一致性
?局限:不適用于海量數據存儲,寫性能受集群規模限制
ZooKeeper 通過封裝復雜的一致性算法,成為分布式系統的“基礎設施”,尤其適用于需要協調與狀態同步的場景。
三、Zookeeper安裝部署
1.拉取鏡像
docker pull zookeeper:3.8

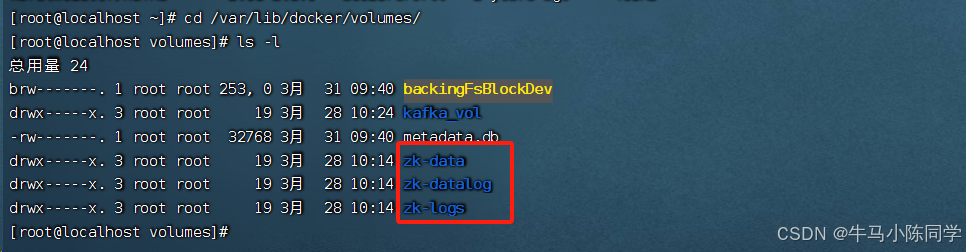
2.創建數據卷
創建數據卷,方便數據持久化
docker volume create zk-data
docker volume create zk-datalog
docker volume create zk-logs
3.創建容器
創建zookeeper-test容器,同時掛載數據卷和并指定端口映射(2181)
docker run -d --name zookeeper-test -p 2181:2181 \--env ZOO_MY_ID=1 \-v zk-data:/data \-v zk-datalog:/datalog \-v zk-logs:/logs \zookeeper:3.8

4.Zookeepe可視化工具-prettyZoo下載和安裝
PrettyZoo 是一款基于 ?Apache Curator 和 ?JavaFX 開發的開源 Zookeeper 圖形化管理客戶端,專為簡化 Zookeeper 運維設計。其核心功能包括:
?多平臺支持:提供 Windows(msi)、Mac(dmg)、Linux(deb/rpm)安裝包,無需額外安裝 Java 運行時即可運行;
?可視化操作:支持節點增刪改查(CRUD)、實時數據同步、ACL 權限配置、SSH 隧道連接,以及 JSON/XML 數據格式化與高亮顯示;
?命令行集成:內置終端支持 80% 的 Zookeeper 命令,并可直接執行四字命令(如 stat、ruok 等)監控集群狀態;
?多集群管理:可同時連接多個 Zookeeper 服務器,支持配置導入導出,提升運維效率。
該工具界面簡潔美觀,適合開發測試及中小規模環境,大幅降低 Zookeeper 的操作復雜度。
GitHub下載地址
我這里是在windows上下載使用,所以選擇windows版本。
安裝很簡單,傻瓜式安裝即可,沒有特殊配置。


5.prettyZoo使用
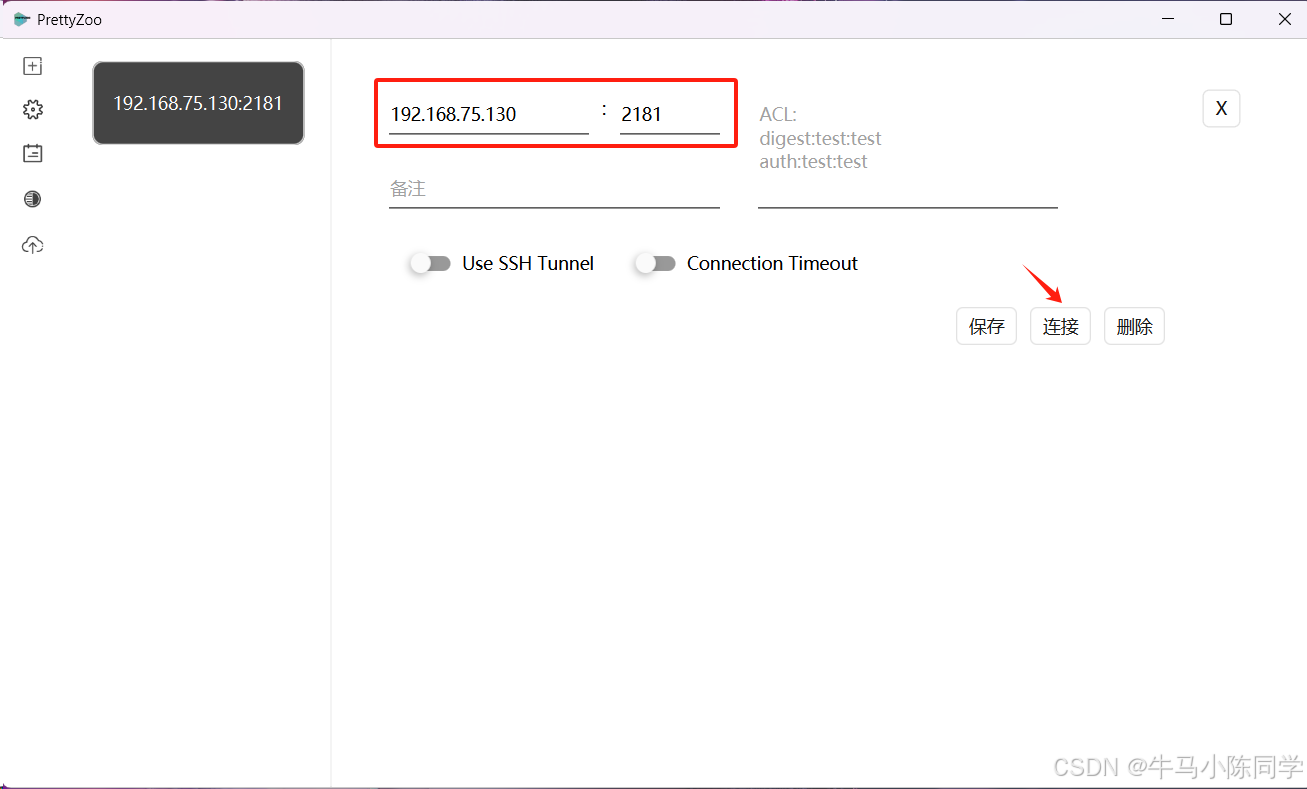
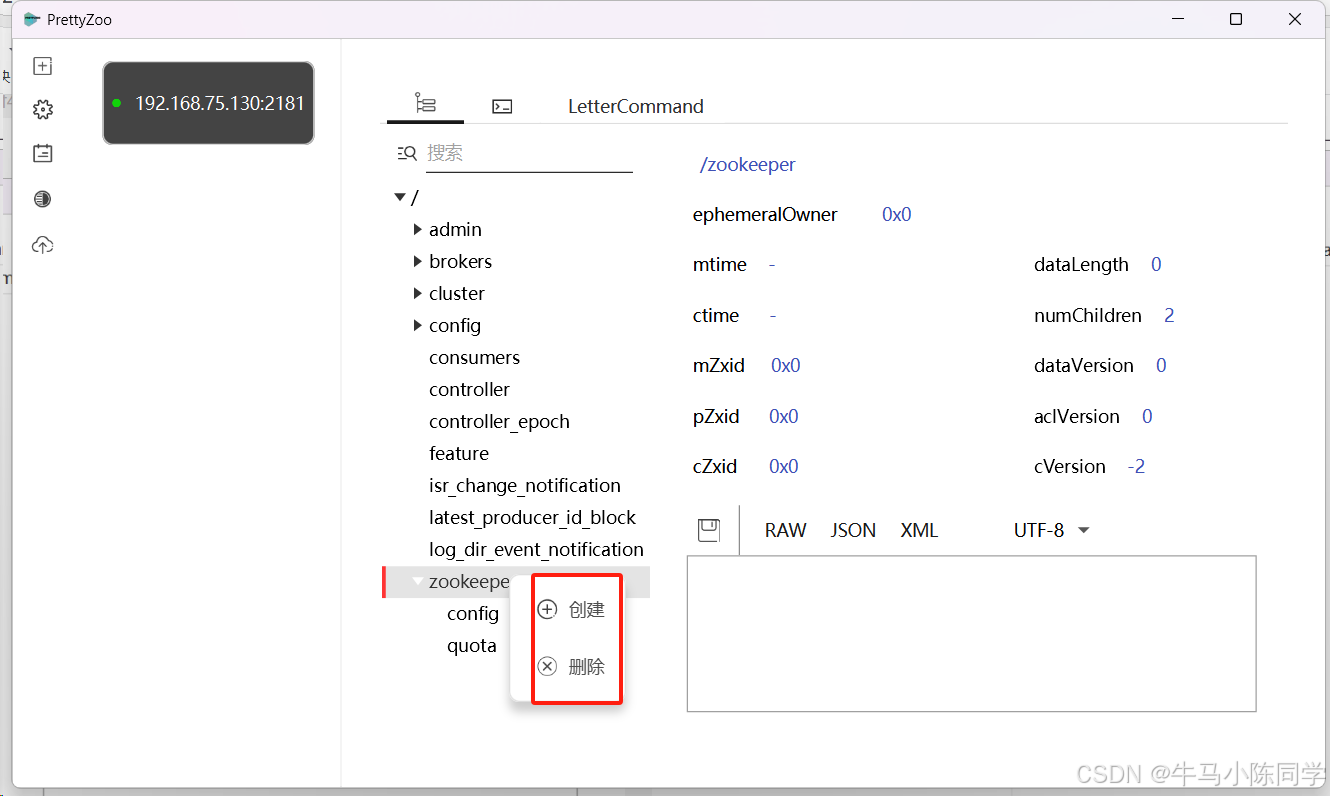
填寫IP和端口進行連接。
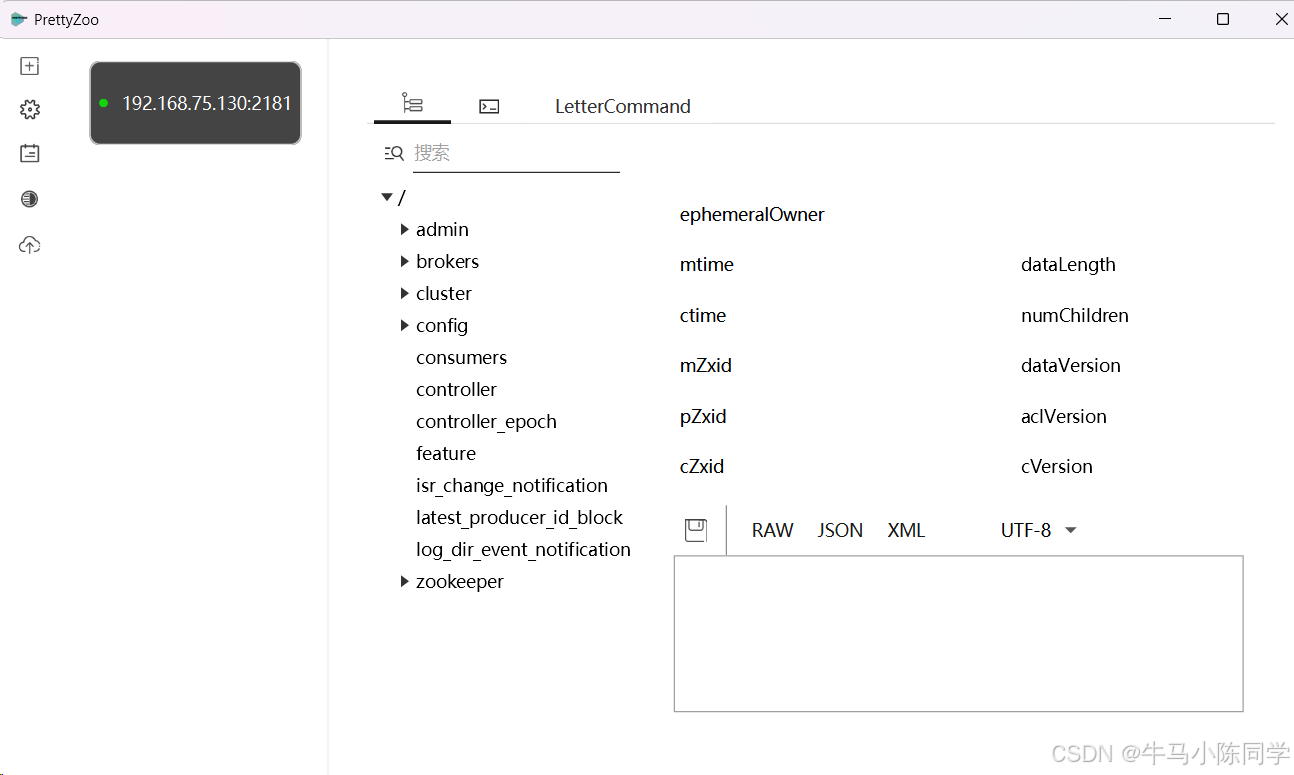
連接成功后,目錄結構就能看到了,可以直接在工具上創建和刪除節點。還可以編寫命令進行操作。工具使用就簡單介紹一下,感興趣的同學可以下載玩一玩。
四、Kafka安裝部署
1.拉取鏡像
wurstmeister/kafka 適合開發/測試,但生產環境建議使用官方或企業版(如 Confluent)。
2.13-2.8.1 代表Kafka 依賴的 ?Scala 版本為2.13,kafka自身的版本為2.8.1。
docker pull wurstmeister/kafka:2.13-2.8.1

2.創建數據卷
創建數據卷,方便數據持久化
docker volume create kafka_vol

3.創建容器
創建kafka-test容器,同時掛載數據卷和并指定端口映射(9092),并將zookeeper-test鏈接到該容器,使Kafka可以成功訪問到zookeeper-test,Kafka相關參數通過環境變量(—env)設置。
docker run -d --name kafka-test -p 9092:9092 \
--link zookeeper-test \
--env KAFKA_ZOOKEEPER_CONNECT=zookeeper-test:2181 \
--env KAFKA_ADVERTISED_HOST_NAME=192.168.75.130 \
--env KAFKA_ADVERTISED_PORT=9092 \
--env KAFKA_LOG_DIRS=/kafka/logs \
-v kafka_vol:/kafka \
wurstmeister/kafka:2.13-2.8.1

4.Kakfa可視化操作工具kafka-ui安裝
Kafka-UI 是一款開源的 Web 可視化工具,專為管理和監控 Apache Kafka 集群設計,提供輕量、高效的運維體驗。它支持多集群統一管理,可實時查看集群狀態(如 Broker、Topic、分區和消費者組詳情),并支持消息瀏覽(JSON、純文本、Avro 格式)。用戶可通過界面動態配置 Topic,管理消費者偏移量,并集成數據脫敏、權限控制等功能。其部署靈活,支持 Docker、Kubernetes 等多種方式,適合開發測試及中小規模生產環境,大幅降低 Kafka 的運維復雜度
4.1、拉鏡像
docker pull provectuslabs/kafka-ui

4.2、創建容器
docker run -it --name kafka-ui -p 8080:8080 -e DYNAMIC_CONFIG_ENABLED=true provectuslabs/kafka-ui

4.3、訪問kafka-ui
訪問地址為你部署的服務器地址:http://localhost:8080/ (http://192.168.75.130:8080/)
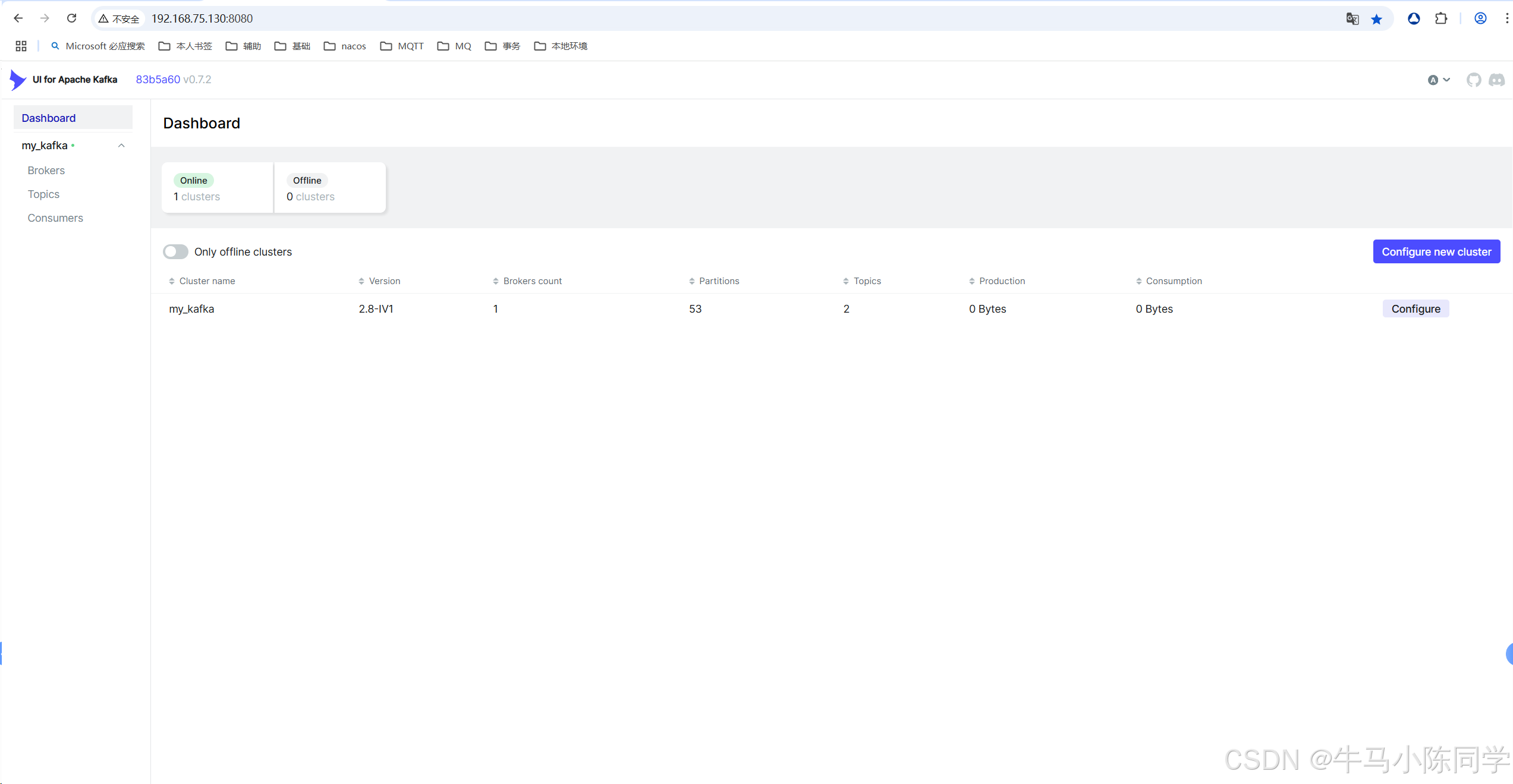
5.Kakfa可視化操作工具kafka-ui使用
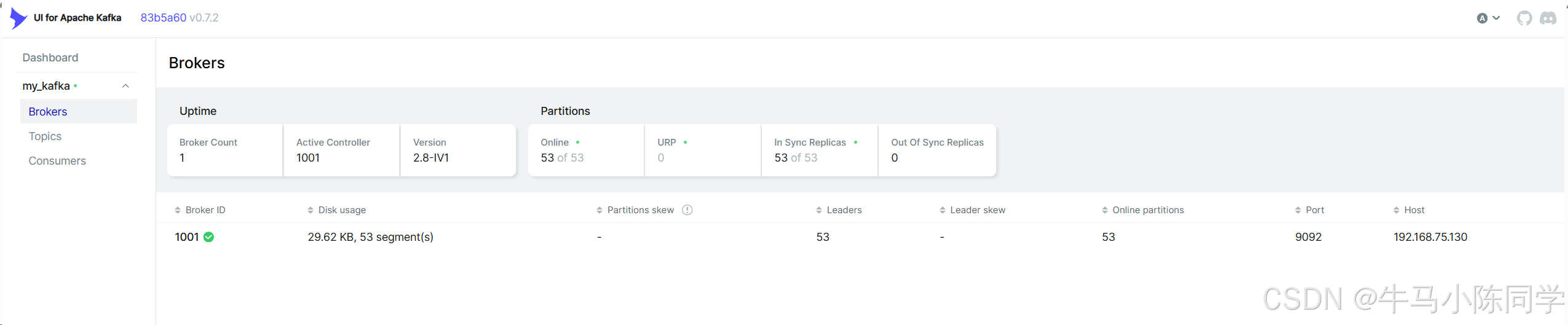
創建連接:

連接后可以查看Brokers、Consumers,可以操作Topics,可以查看消息,也可以模擬Produce生產消息等等。詳細操作功能就不再描述了,各位同學可以自行部署嘗試。


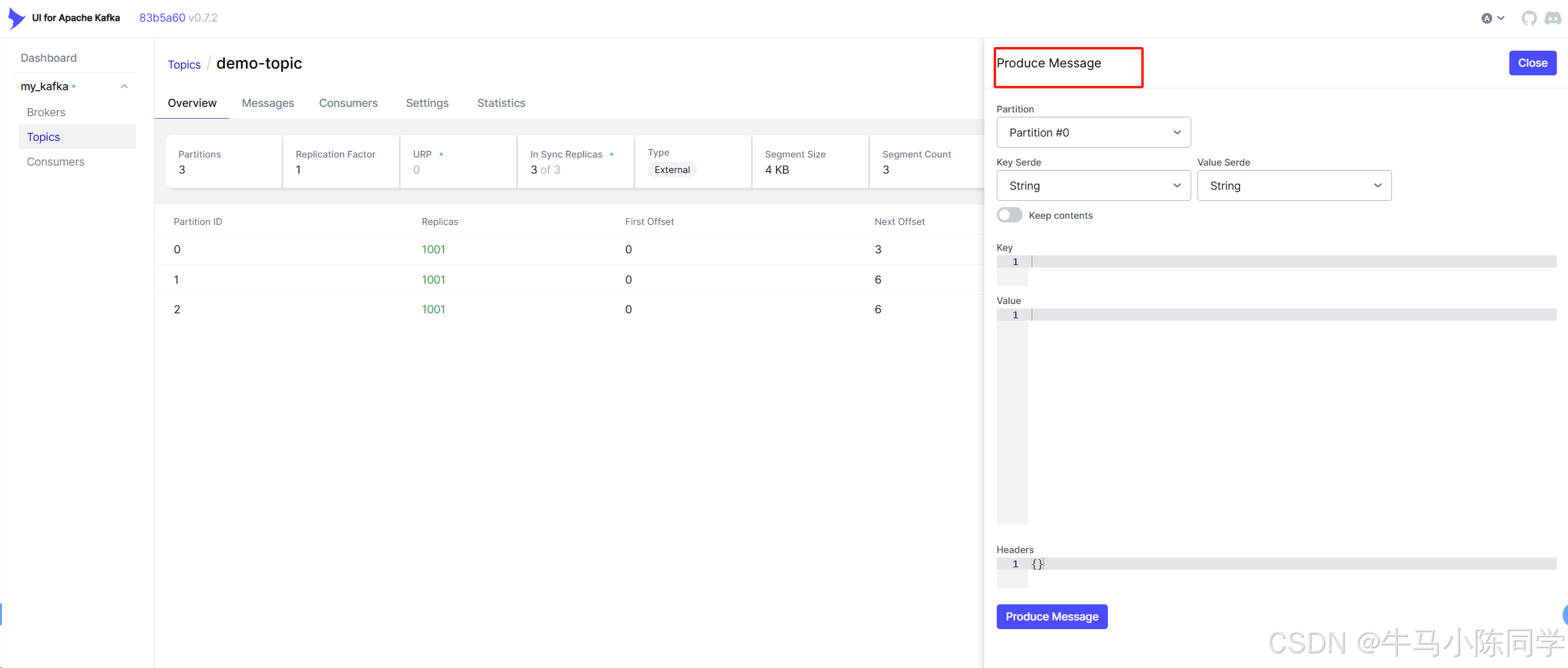
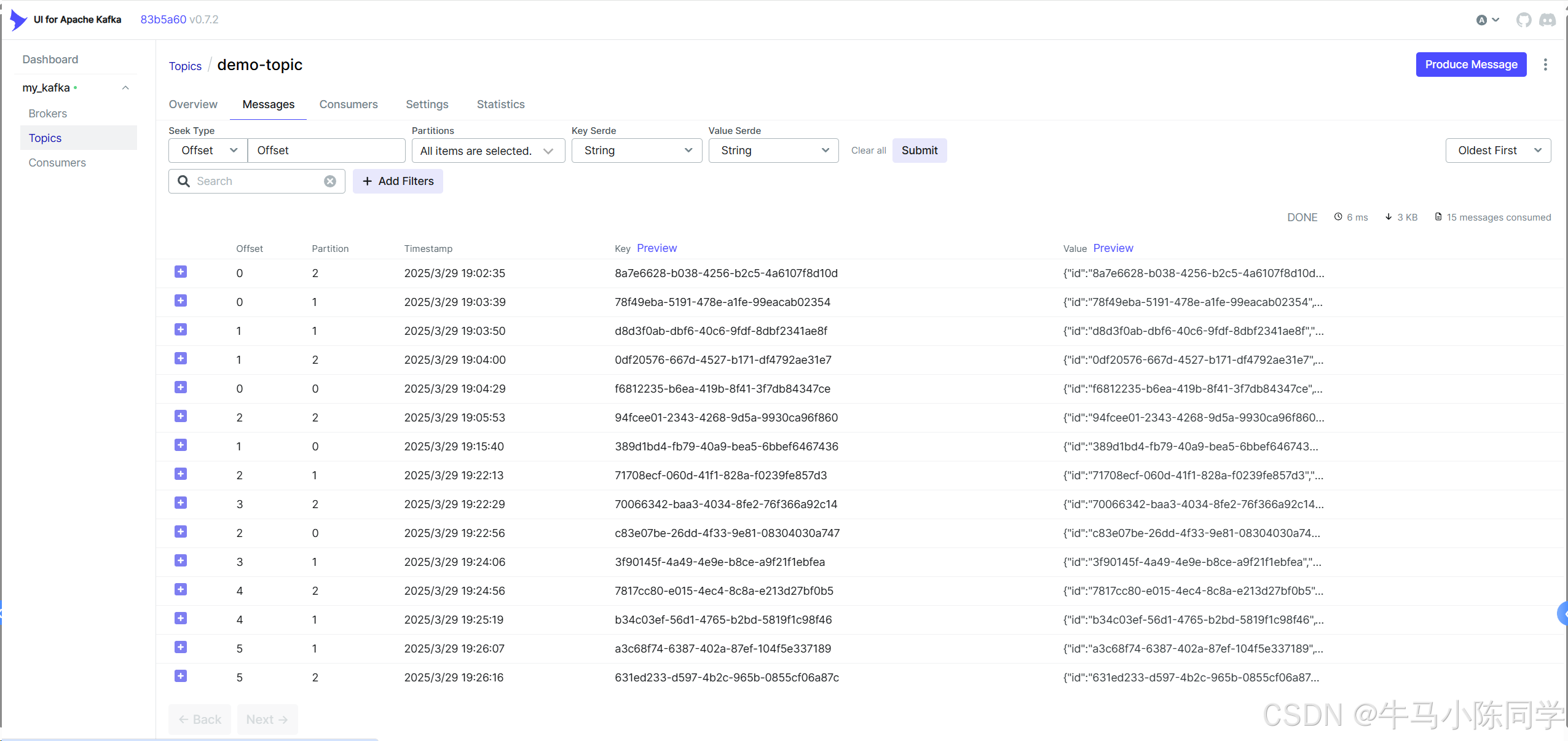
五、Spring Boot使用Kafka
因為kafka部署的是2.8.1,需要對應Spring boot 2.7.x系列,我這里使用spring boot 2.7.6進行案例。
1.pom文件引入關鍵jar
<properties><java.version>1.8</java.version><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding><!-- spring boot版本 --><spring-boot.version>2.7.6</spring-boot.version><!-- kafka版本 --><spring-kafka.version>2.8.1</spring-kafka.version></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><!-- Kafka 核心依賴 --><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId><version>${spring-kafka.version}</version></dependency><!-- Lombok 簡化代碼 --><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><!-- JSON 序列化支持 --><dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-databind</artifactId><version>2.13.3</version></dependency></dependencies>
2.yml文件引入配置
spring:kafka:# 集群地址(多個用逗號分隔)bootstrap-servers: 192.168.75.130:9092# 生產者配置producer:key-serializer: org.apache.kafka.common.serialization.StringSerializervalue-serializer: org.springframework.kafka.support.serializer.JsonSerializerretries: 3 # 失敗重試次數acks: all # 確保消息可靠投遞batch-size: 16384 # 批量發送優化# 消費者配置consumer:group-id: demo-group # 消費組IDauto-offset-reset: earliestkey-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.springframework.kafka.support.serializer.JsonDeserializerenable-auto-commit: false # 手動提交偏移量properties:spring.json.trusted.packages: "*" # 允許反序列化任意包# 監聽器配置listener:ack-mode: MANUAL # 手動ACKconcurrency: 3 # 消費線程數# 自定義主題名稱
kafka:topic:demo: demo-topic3.Topic配置
@Configuration
public class KafkaTopicConfig {@Value("${kafka.topic.demo}")private String demoTopic;@Beanpublic NewTopic demoTopic() {return TopicBuilder.name(demoTopic)// 分區數.partitions(3)// 副本數.replicas(1).config(TopicConfig.RETENTION_MS_CONFIG, "604800000") // 保留7天.build();}
}
4.消息體創建
@Data
@AllArgsConstructor
@NoArgsConstructor
public class DemoMessage {private String id;// 內容private String content;// 時間戳private LocalDateTime timestamp;
}5.Producer實現
@Slf4j
@Service
public class KafkaProducerService {private final KafkaTemplate<String, Object> kafkaTemplate;@Autowiredpublic KafkaProducerService(KafkaTemplate<String, Object> kafkaTemplate) {this.kafkaTemplate = kafkaTemplate;}// 發送消息(支持回調)public void sendMessage(String topic, DemoMessage message) {// 普通發送消息(支持回調)kafkaTemplate.send(topic, message.getId(), message).addCallback(success -> {if (success != null) {log.info("發送成功: Topic={}, Offset={}",success.getRecordMetadata().topic(),success.getRecordMetadata().offset());}},ex -> log.error("發送失敗: {}", ex.getMessage()));// 事務性發送消息(支持回調)
// kafkaTemplate.executeInTransaction(operations -> {
// operations.send(topic, message.getId(), message)
// .addCallback(
// success -> {
// if (success != null) {
// log.info("發送成功: Topic={}, Offset={}",
// success.getRecordMetadata().topic(),
// success.getRecordMetadata().offset());
// }
// },
// ex -> log.error("發送失敗: {}", ex.getMessage())
// );
// return true;
// });}
}
6.Consumer實現
@Slf4j
@Service
public class KafkaConsumerService {@KafkaListener(topics = "${kafka.topic.demo}", groupId = "demo-group")public void consumeMessage(@Payload DemoMessage message, Acknowledgment ack) {try {log.info("收到消息: Content={}", message.getContent());// 冪等處理if (isMessageProcessed(message.getId())) {log.warn("消息已處理: ID={}", message.getId());ack.acknowledge();return;}// 業務處理// ...// 手動提交偏移量ack.acknowledge();} catch (Exception e) {log.error("處理異常: {}", e.getMessage());}}private boolean isMessageProcessed(String messageId) {// 實現冪等檢查(如查數據庫)return false;}
}
7.啟動類配置
@EnableKafka
@SpringBootApplication
public class MyKafkaApplication {public static void main(String[] args) {SpringApplication.run(MyKafkaApplication.class, args);}}8.Controller測試發送
@RestController
@RequestMapping("/kafka")
public class kafakTestController {@Autowiredprivate KafkaProducerService producerService;@RequestMapping("/sendMessage")public String sendMessage(@RequestParam(value = "message") String message) {DemoMessage message1 = new DemoMessage(UUID.randomUUID().toString(),message,LocalDateTime.now());producerService.sendMessage("demo-topic", message1);return "消息發送成功!";}
}
9.測試驗證
模擬生產者生產消息,驗證生產者和消費者是否正常工作。測試可用。
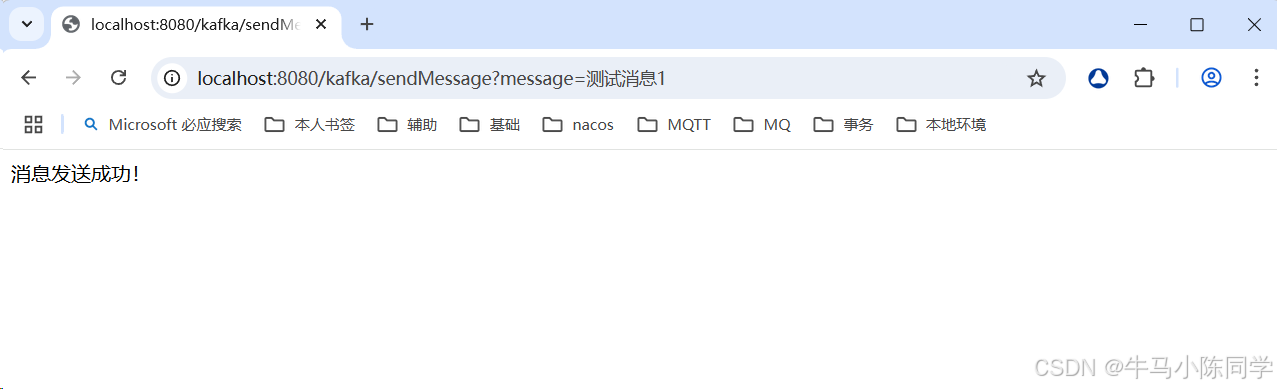

總結
總結了kafka使用的完整教程,加強一下自己對于kafka的整體概念,給想使用kafka的同學們入個門。

)


)
![[王陽明代數講義]琴語言類型系統工程特性](http://pic.xiahunao.cn/[王陽明代數講義]琴語言類型系統工程特性)
推導)
高德地圖定位插件)


如何學習英語)
)





)

容忍度(Toleration))