前言
筆者在最近的項目開發中,遇到了兩個父子關系緊密相關的場景:評論樹結構、部門樹結構。具體的需求如:找出某條評論下的所有子評論id集合,找出某個部門下所有的子部門id集合。
在之前的項目開發經驗中,遞歸使用得是較少的,但作為一個在數據結構操作中遍歷樹節點的解決方案,我還是拿出來作為技術積累進行記錄以及分享。
一、什么是遞歸
1.1基本概念
這里就有必要簡單介紹一下關于遞歸的基本概念了。
在 Java 中,遞歸是指在方法的定義中調用自身的過程,遞歸是基于方法調用棧的原理實現的:當一個方法被調用時,會在調用棧中創建一個對應的棧幀,包含方法的參數、局部變量和返回地址等信息。在遞歸中,方法會在自身的定義中調用自身,這會導致多個相同方法的棧幀依次入棧。當滿足終止條件時,遞歸開始回溯,棧幀依次出棧,方法得以執行完畢。
遞歸的關鍵是定義好遞歸的終止條件和遞歸調用的條件。如果沒有適當的終止條件或遞歸調用的條件不滿足,遞歸可能會陷入無限循環,導致棧內存溢出。
1.2優缺點
優點:
-
簡化問題:遞歸能夠將復雜問題分解成更小規模的子問題,簡化了問題的解決過程;
-
實現高效算法:遞歸在某些算法中能夠實現高效的解決方法,如數據結構操作中遍歷樹節點等。
缺點:
-
棧溢出風險:遞歸可能導致方法調用棧過深,造成棧內存溢出;
-
性能損耗:遞歸調用需要創建多個棧幀,對系統資源有一定的消耗;
-
可讀性不高:遞歸的使用需要謹慎,不合理地使用可能造成代碼難以理解和調試。
1.3與迭代的區別
-
迭代(Iteration)
-
迭代常見于 for 循環中:比如有一個集合 A,對 A 進行 foreach,在內部設置條件,符合條件后將集合中某個元素的值替換成別的值。
迭代示例簡圖
@Testpublic void iterationTest(){ArrayList<String> list = new ArrayList<>();list.add("計算機技術");list.add("土木工程");list.add("市場營銷");list.forEach(val -> {if (val.contains("計算機")){log.info("迭代前的的專業名稱:{}", val);String str = val.replace(val, "計算機科學與技術");log.info("迭代后的的專業名稱:{}", str);}});}結果為:
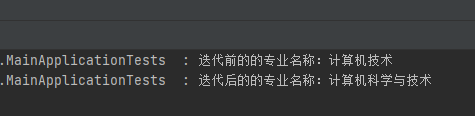
迭代結果簡圖
-
遞歸(Recursion)

遞歸的例子會在下一小節詳細給出。
二、實際案例
下面筆者以遞歸獲取某個評論id下面所有的子級評論id為例子,向大家介紹這個遞歸的過程。
首先,這里給出一個簡單的數據庫評論表的 demo,id 是主鍵id 也是評論唯一 id,parent_id 是該條評論的父評論 id,status 為1表示審核通過的狀態。
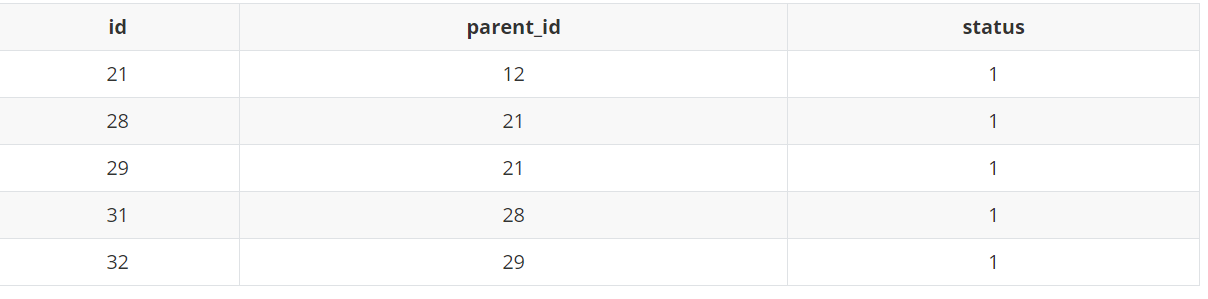
其中,我們可以簡單發現:這里21為第一層,28和29為第二層、31和32為第三層,草圖如下所示:
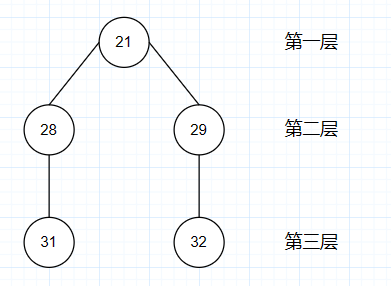
評論id簡單層級示意圖
那么,我們如何將21、28、29、31、32都放進一個集合里返回呢?下面的代碼示例可以給你一個參考。
但是,在看代碼之前,有個問題請你思考一下:
從21開始后,遍歷的路線是21-28-29?還是21-28-31?還是21-29-32?或者是21-28-31-29-32?
下面是經過脫敏處理后的參看代碼示例,注釋都寫得比較清楚了:
/*** 這里可以看作是外部接口的調用,會得到遞歸的結果* @param id*/private List<Integer> getIdListMethod(Integer id){ArrayList<Integer> idList = new ArrayList<>();this.getAllIdByRecursion(id, idList);log.info("遞歸后得到的id集合:{}", idList);return idList;}/*** 這里是遞歸的過程* @param id* @param idList*/private void getAllIdByRecursion(Integer id, List<Integer> idList){LambdaQueryWrapper<Comment> wrapper = new LambdaQueryWrapper<>();//先把該id下所有的第一級子id找到wrapper.eq(Comment::getParentId, id).eq(Comment::getStatus, NumberUtils.INTEGER_ONE);List<Comment> commentList = this.list(wrapper);for (Comment children : commentList){this.getAllIdByRecursion(children.getId(), idList);}log.info("放入集合的id為:{}", id);idList.add(id);}上面問題的答案是:遞歸后得到的id集合:[21,28,31,29,32],原因就是:迭代會從一棵樹開始遍歷到底,沒有元素了再從頭開始遍歷,依次迭代,類似于深度優先遍歷。
比如:21下面有兩個子id:28和29,那么會先走21-28-31這棵樹,到底了后接著按照29-32遍歷。
三、改進方案
我根據自己的開發經驗,可以從控制遞歸層數和改用 Stream 這兩種辦法來對遞歸進行改進。
3.1控制遞歸層數
JVM 默認控制的遞歸最大深度限制在 1000 層,可以通過設置 JVM 參數來控制其深度,如:
java -Xss5m #表示將每個線程的棧內存大小設置為5MB,已經是比較大了或者在代碼層面對遞歸的層數進行控制:
int depth = 0;//遞歸方法調用for (int i = 0; i < 20; i++) {depth++;}if (depth > 100){//其它操作}3.1用 Stream 遍歷
核心思路是:先數據庫全量查詢(10萬條以內),內存中使用 Stream 流操作、Lambda 表達式、Java 地址引用進行篩選。
適用于數據總量不多的情況,如:部門樹,部門數量一般情況是比較固定的,一個組織或者公司最多也就幾百上千個部門。
四、文章小結
筆者確實不推薦在項目中過度使用遞歸,但是合理使用的話也能成為解決特定問題的一個利器,至于怎么拿捏這個度,那就要看大家的具體情況了。
Java 項目中對使用遞歸的理解分享到這里就結束了,文章如有不足和錯誤,或者你有更好的解決思路,歡迎大家的指正和交流!
文章轉載自:CodeBlogMan
原文鏈接:https://www.cnblogs.com/CodeBlogMan/p/18180395
體驗地址:引邁 - JNPF快速開發平臺_低代碼開發平臺_零代碼開發平臺_流程設計器_表單引擎_工作流引擎_軟件架構






)






redis的命令總結)


)


)