編碼器+解碼器=自編碼器
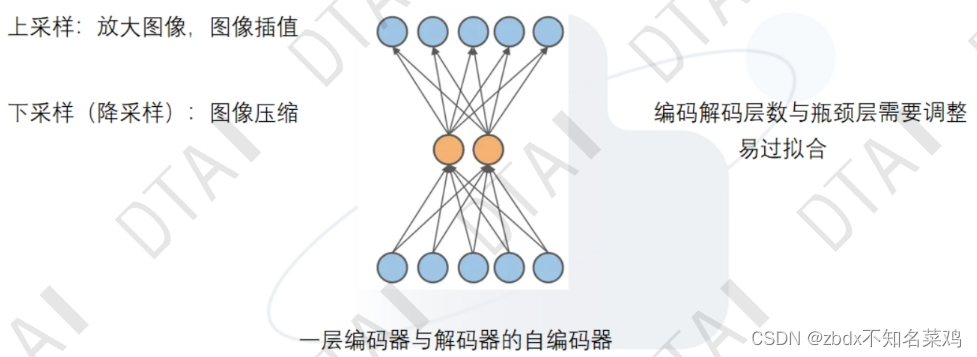
先壓縮特征,再通過特征還原。
判斷還原的和原來的是否相等
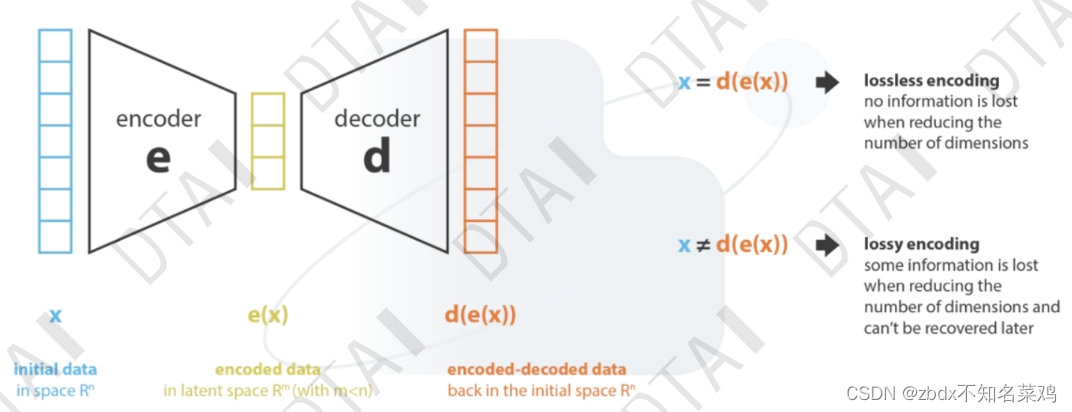
encode data 在一個“潛在空間”里。它的用途是“深度學習”的核心-學習數據的特征并簡化數據表示形式以尋找模式。
變分自編碼器:
1.
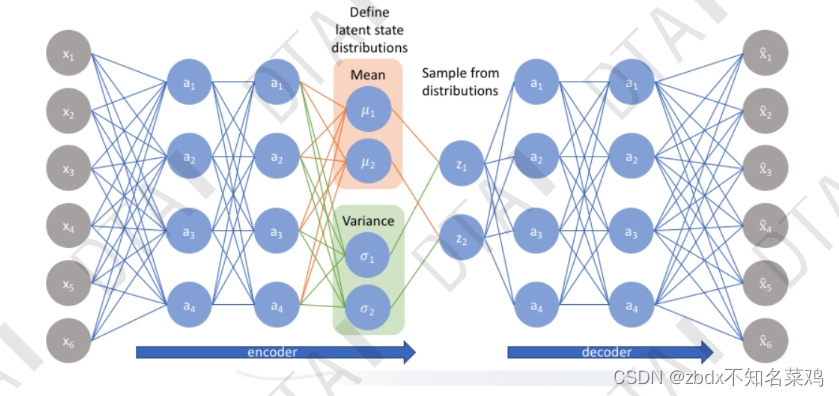
首先、假設輸入數據是符合正態分布的(大部分正常的數據都集中在99.7%中),即不同的數據都能提取出不同的σ和μ這兩個正態分布特征值。然后在這2個參數構成的正態分布函數中進行抽樣sample再解碼,就能得到和原來輸入中其他數據相似的數據。

在進行對比,反向優化。?
流程圖:
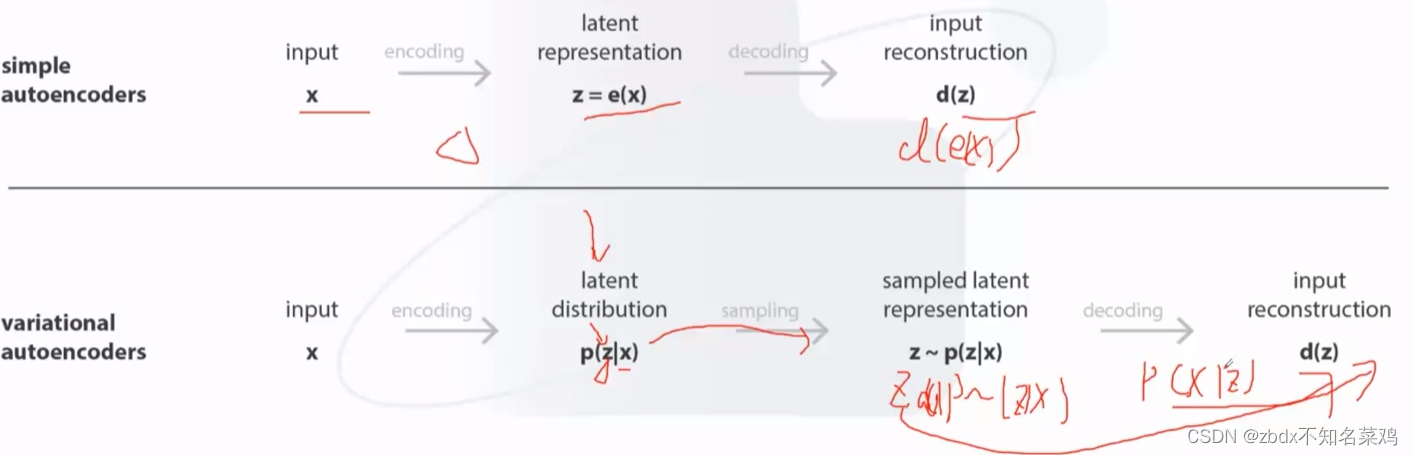
為了讓隱空間的新分布和原分布很相似,然后再對擬合出的新分布抽樣出新的數據(這些數據包含了原數據的大量特征),就可以當作是原數據了。
損失函數:
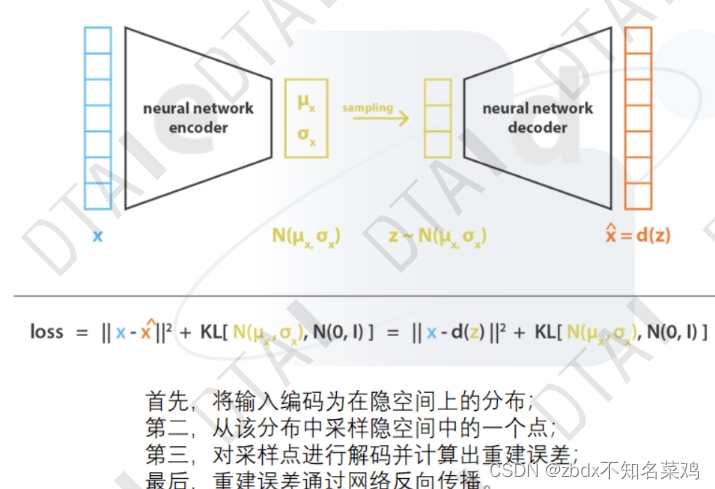
KL散度:衡量兩個分布的相似度




)
)
)




Addin控件 3 事件功能類)








