聽課(李宏毅老師的)筆記,方便梳理框架,以作復習之用。本節課主要講了Network Compression,包括為什么要壓縮,壓縮的主要手段(pruning,knowledge distillation,parameter quantization,architecture design,dynamic computation)
引言
為什么要壓縮模型?
- resource-constrained:因為有時需要把模型跑在計算資源有限的設備上,比如手表
- lower latency:比如智能駕駛,把資料從車傳到云端又傳回來,sensor需要非常及時的響應
- privacy:把資料傳到云端,則云端系統持有者就能看到我們的資料

Network Pruning
概念
有些沒有工作的參數可以剪掉,不然會占資源。就像人剛出生時沒什么神經連接,但是6歲時就很多,再長大到14歲時反而少一點了。

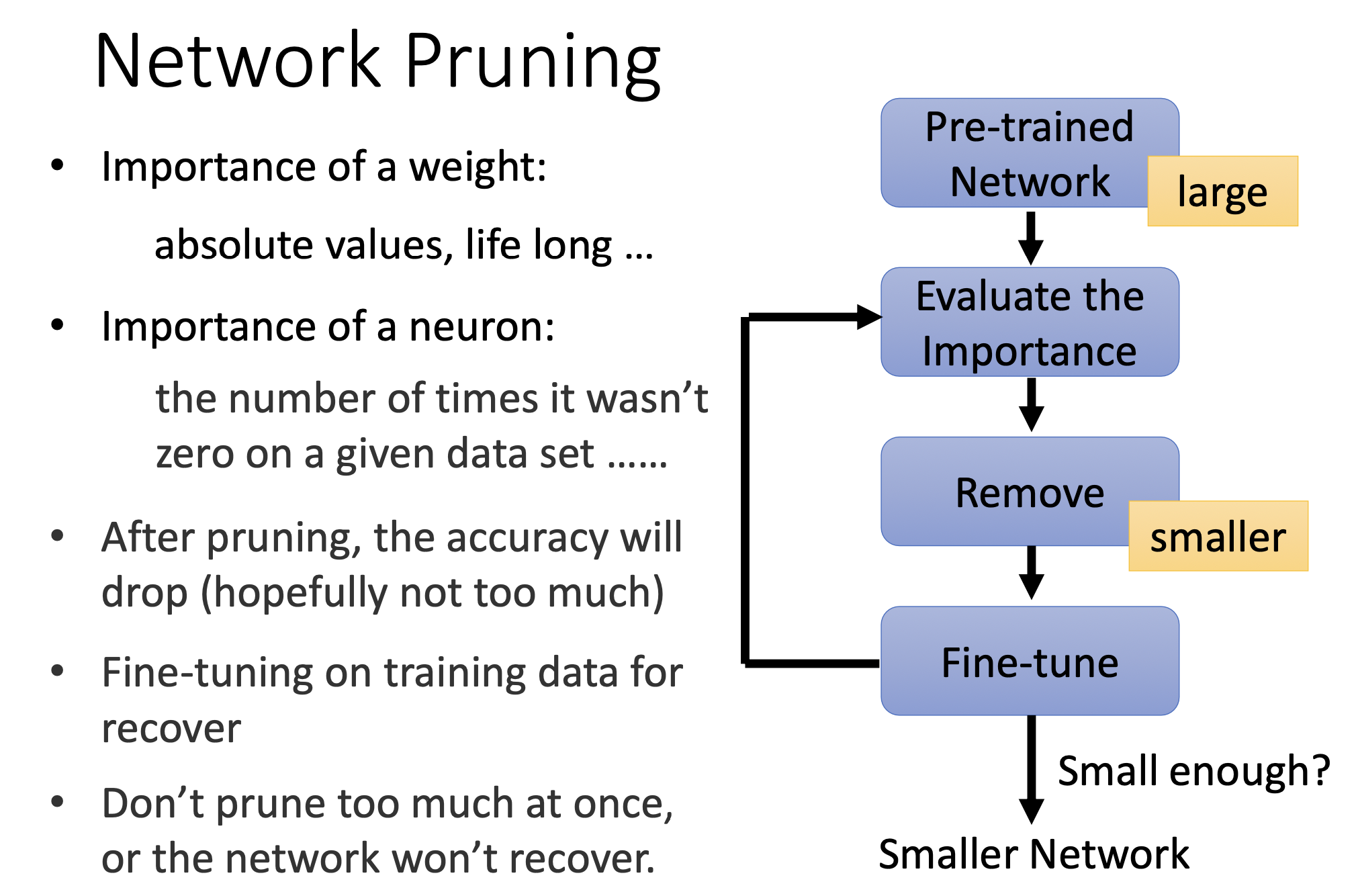
基本框架
- 預訓練(此時是大模型)
- 評估重要性(參數或者神經元的)
- 剪枝
- 微調
- 可以再次回到評估階段,循環多次
在剪枝后準確率會下降,但是可以通過微調,讓模型恢復一些。最好不要一下子剪太多,不然模型無法恢復。可以一次剪一點,比如10%。
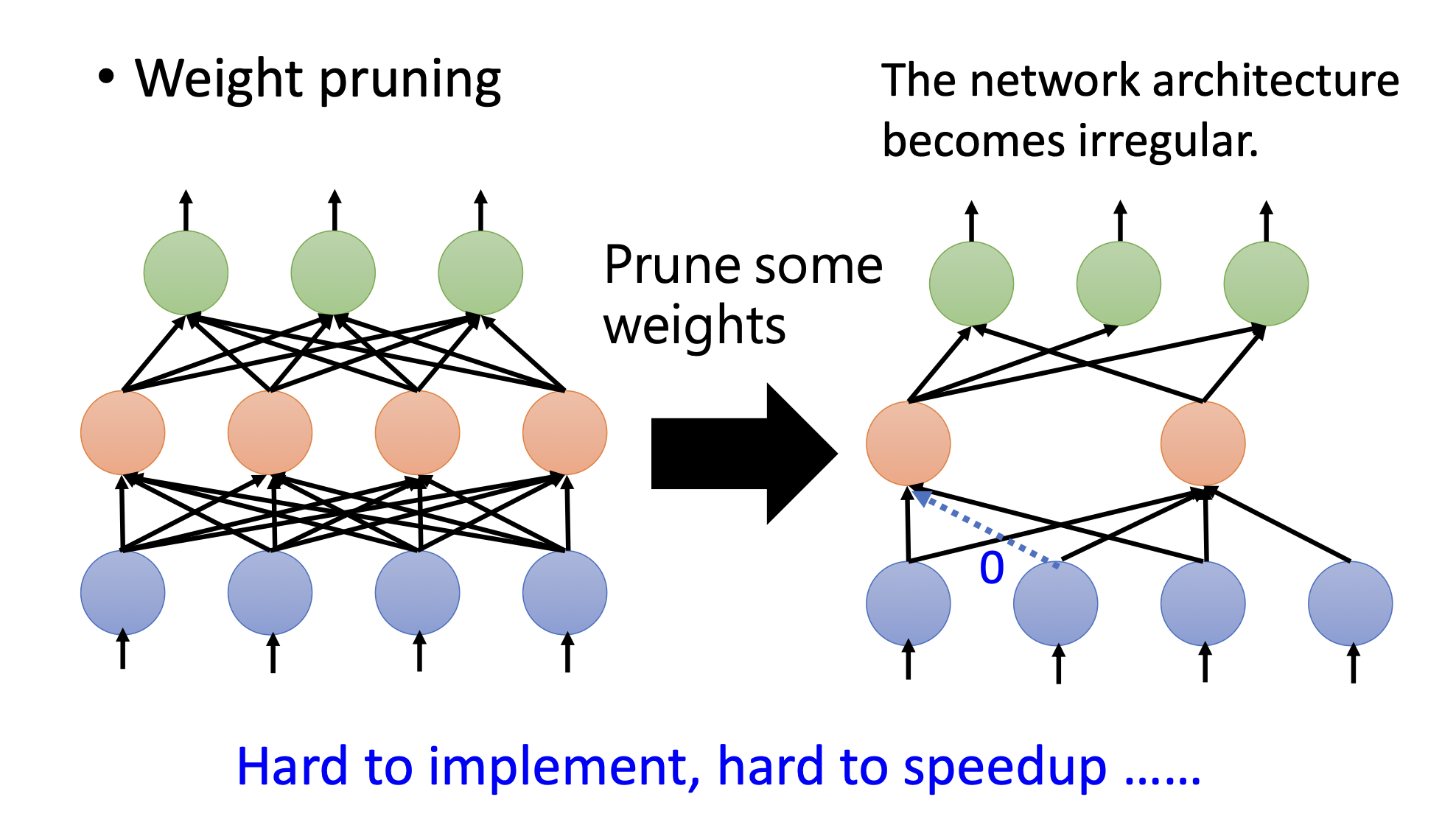
weight pruning
剪掉參數之后,模型不規則。所以用pytorch不好實踐(主要是函數庫的問題,如果寫了不規則模型的函數庫也可以),硬件也不允許。所以想通過把剪掉的參數補0來讓模型變得規則,但實際上模型并沒有變小。
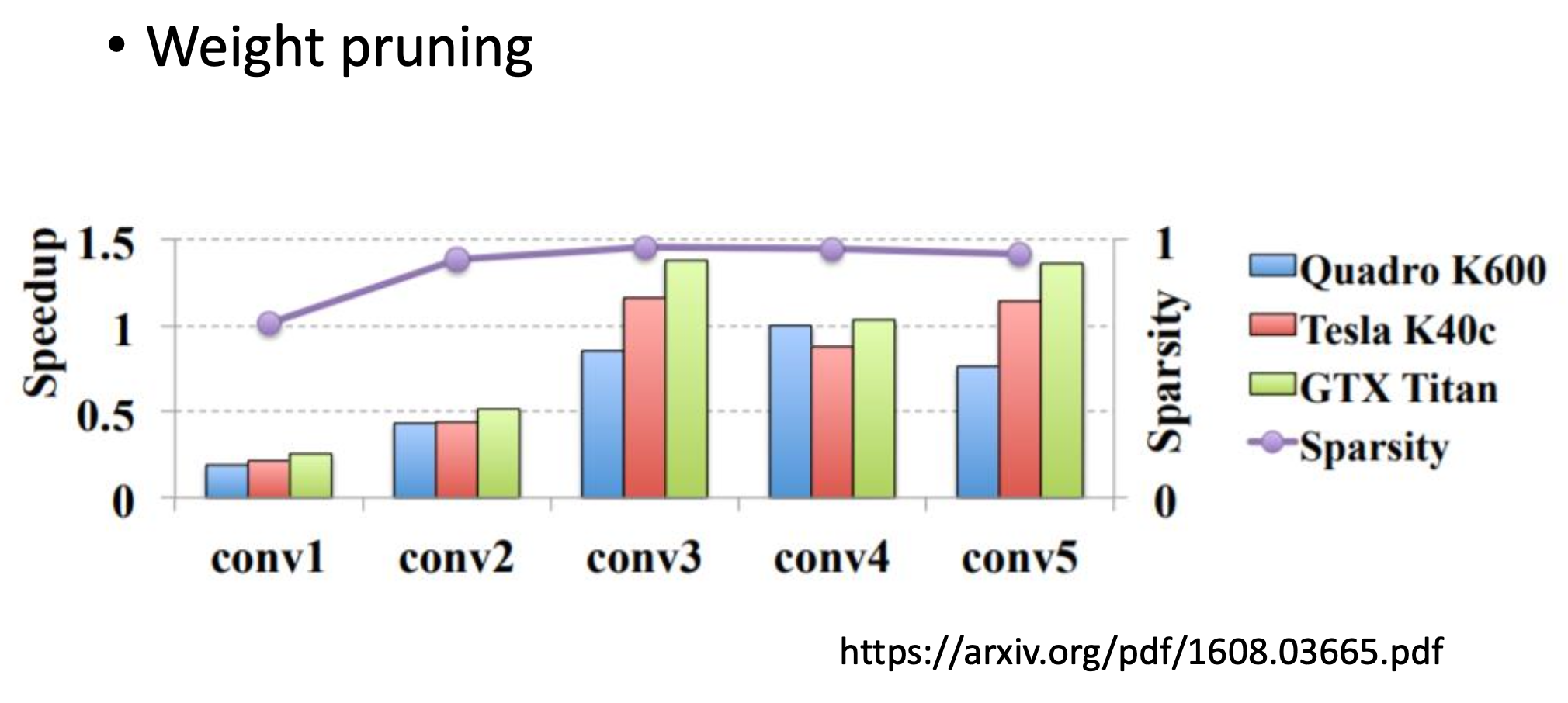
sparsity是指有多少百分比的參數被剪掉了,圖中的sparsity接近1,但基本上沒加速,多數情況下還變慢了
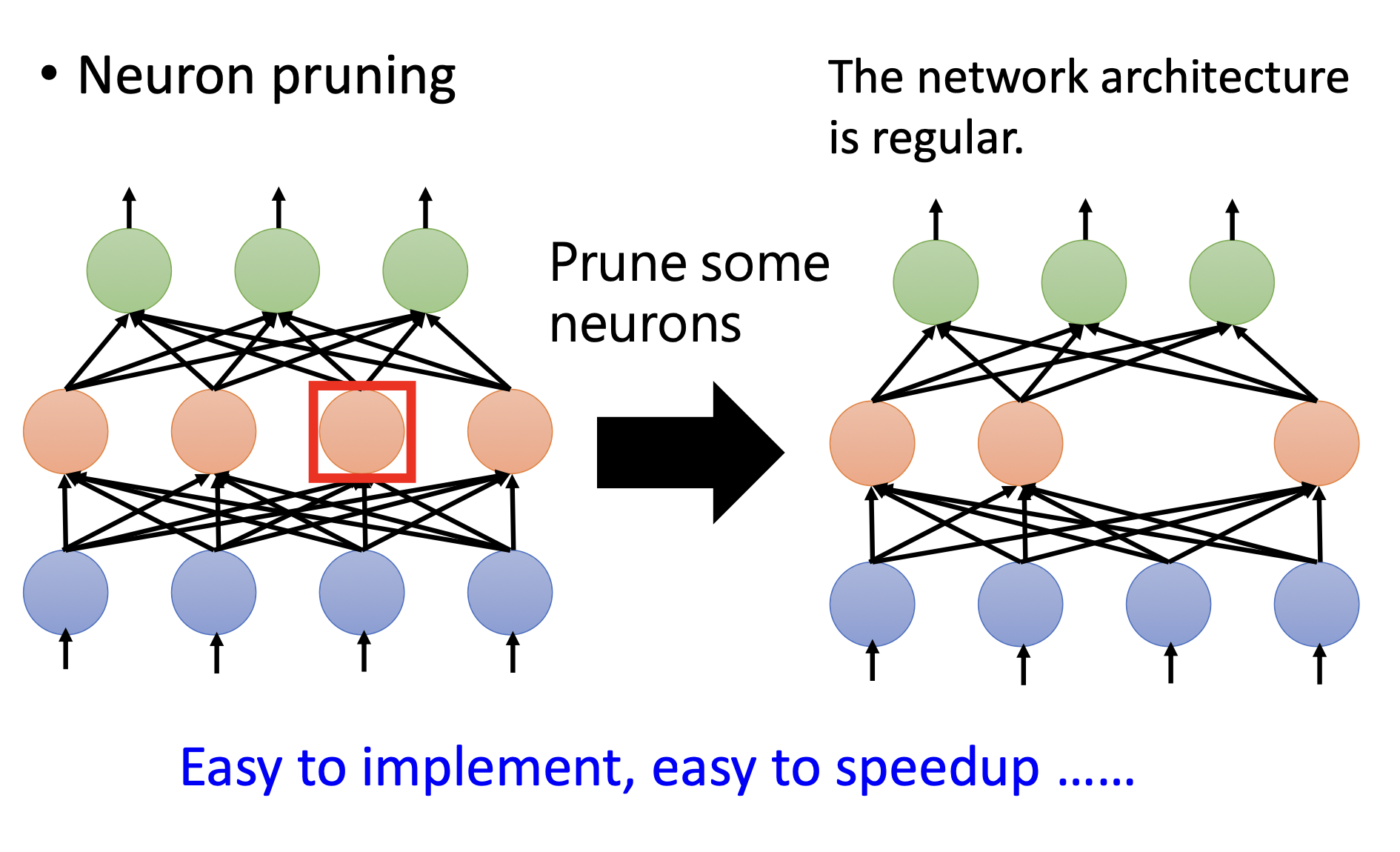
neuron pruning
Why pruning?
提出大樂透假說
為什么要先train大的再把它變成小的?怎么不直接從小的開始train?
因為大的模型更好train,直接train小的比train完大的變小的結果差。
為什么大的更好train?有一個假說叫大樂透假說。

大樂透假說的解釋
一開始買更多彩票增加中獎率。可以把一個大的network看做是很多的sub-network。只要有一個sub-network成功,那這個大的network就能成功。
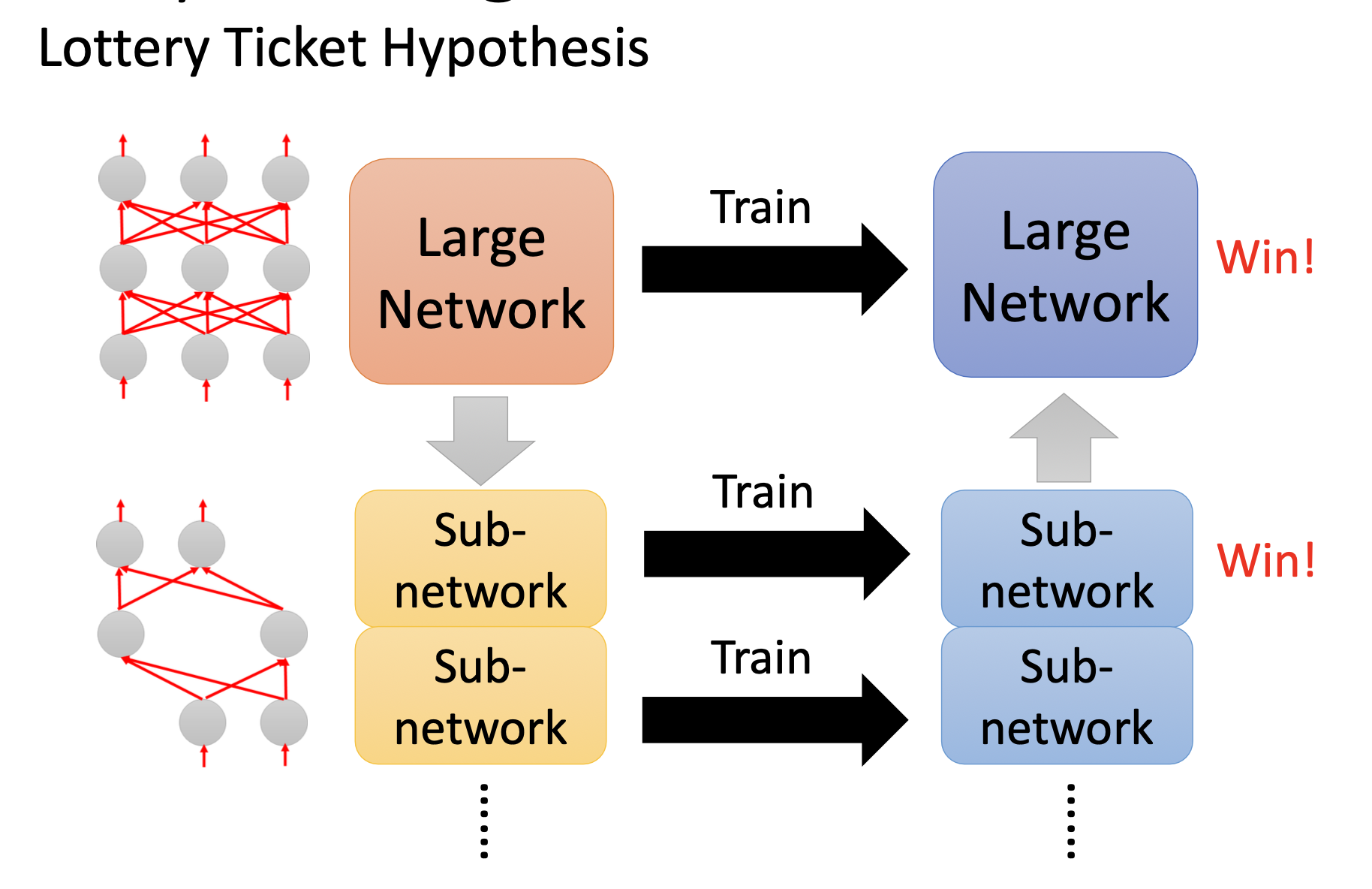
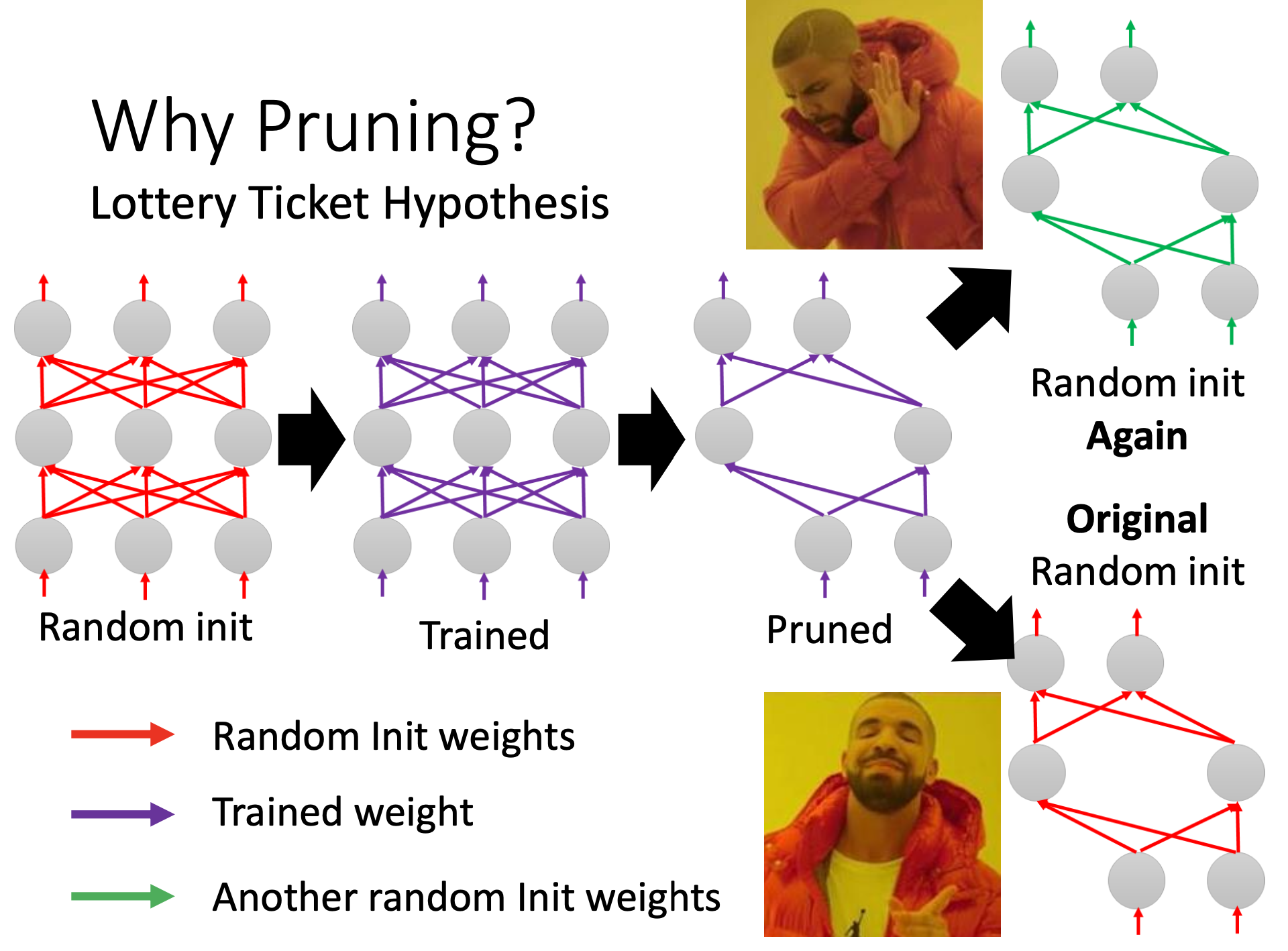
實驗證明大樂透假說
剪枝之后的小network,如果里面的參數都是random init的而不是沒剪枝之前的,那就train不起來(對應綠色的參數);但是如果是用的剪枝之前的參數,相應位置的參數一一對應(紅色的參數),這個小網絡就能train。
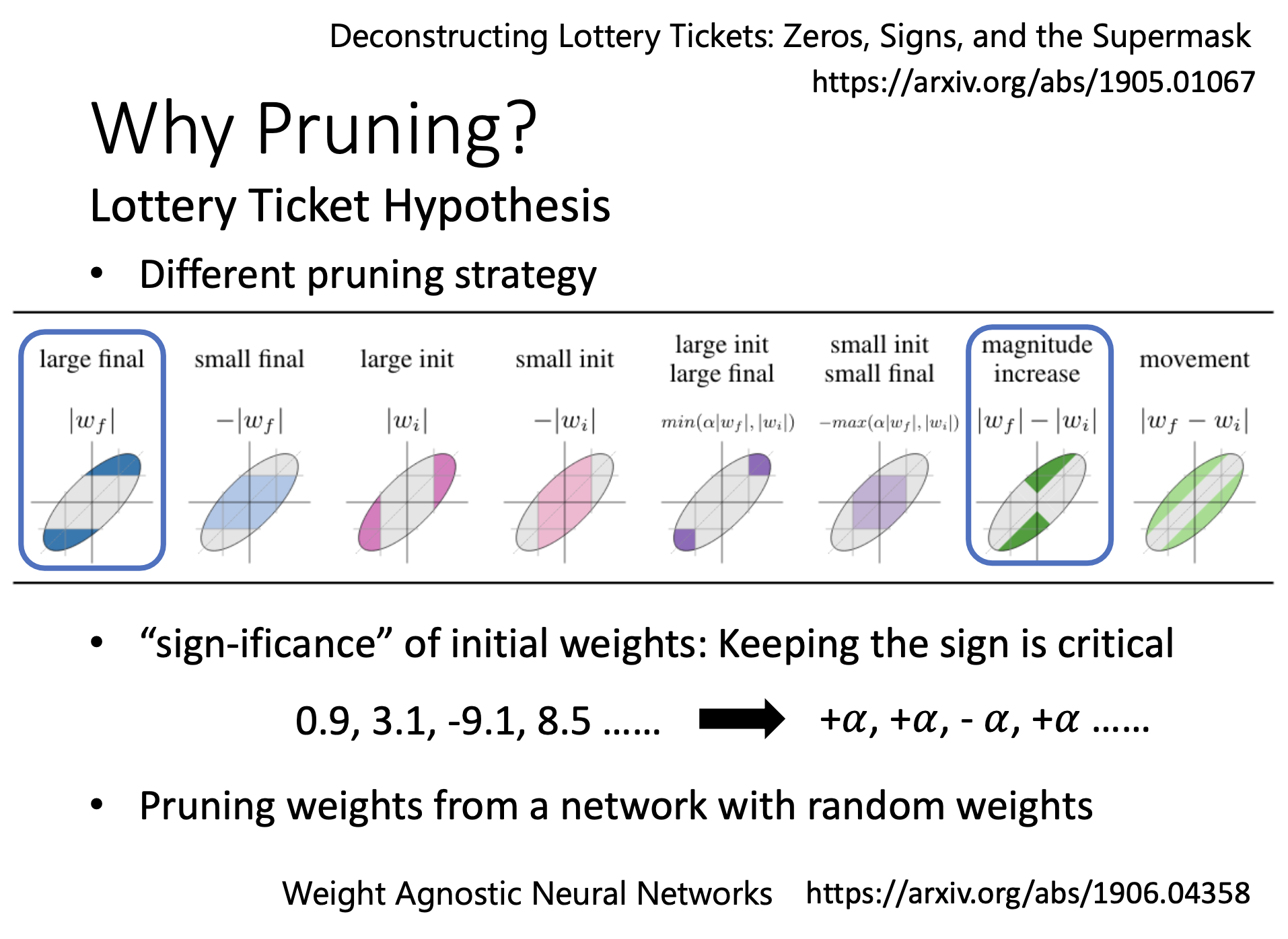
正負號是初始化參數能不能訓練得起來的關鍵,絕對值不重要
反駁大樂透假說
- 直接train小的也可以,只要多點epoch(Scratch-B)
- 大樂透假說只在特定條件下起作用(小learning rate, unstructured)
這里的unstructured指的是以weight為單位prune才能觀察到大樂透現象。


![[藍橋杯]真題講解:抓娃娃(思維+二分)](http://pic.xiahunao.cn/[藍橋杯]真題講解:抓娃娃(思維+二分))

)









)


)

 分支管理)