Hadoop HDFS高可用性(HA)概述
在分布式存儲領域,Hadoop分布式文件系統(HDFS)作為Hadoop生態系統的核心存儲組件,其高可用性(HA)設計一直是架構師們關注的焦點。傳統HDFS架構中,NameNode作為單一主節點管理整個文件系統的元數據,這種設計雖然簡單高效,卻存在明顯的單點故障風險——一旦NameNode宕機,整個集群將陷入癱瘓狀態。
HDFS HA的基本架構
為解決這一關鍵問題,Hadoop 2.0引入了高可用性架構,通過部署雙NameNode(Active-Standby模式)來消除單點故障。Active NameNode負責處理所有客戶端請求,而Standby NameNode則實時同步元數據變更,隨時準備接管工作。這種設計使得系統在Active節點故障時能夠實現秒級切換,將服務中斷時間控制在最小范圍內。
騰訊云技術社區的研究表明,HDFS HA的實現依賴于三個關鍵技術組件:ZooKeeper用于協調和故障檢測,JournalNode集群負責元數據同步,以及ZKFC(ZooKeeper Failover Controller)實現自動故障轉移。這種架構不僅解決了單點故障問題,還通過共享存儲設計避免了傳統SecondaryNameNode方案中可能出現的元數據丟失風險。
在Hadoop生態系統中的關鍵作用
作為大數據處理的基石,HDFS的高可用性直接影響著整個Hadoop生態系統的穩定性。51CTO的技術分析指出,HDFS HA確保了MapReduce、YARN、Hive等上層計算框架能夠持續訪問存儲數據,避免了因存儲層故障導致的計算任務中斷。特別是在金融交易、電信計費等對服務連續性要求極高的場景中,HA機制成為業務連續性的重要保障。
百度開發者社區的案例研究顯示,某大型電商平臺在部署HDFS HA后,系統年可用率從99.5%提升至99.99%,相當于每年減少約4小時的計劃外停機時間。這種提升對于處理日均PB級交易數據的平臺而言,意味著數百萬潛在訂單損失的避免。
解決的核心問題與業務價值
HDFS HA主要應對三類典型問題:首先是硬件故障,包括服務器宕機、網絡分區等意外情況;其次是軟件升級和維護期間的業務連續性保障;最后是應對突發流量峰值時的快速擴容需求。通過主備節點無縫切換,系統可以在這些場景下保持持續服務。
從技術實現角度看,HA機制帶來了多重優勢:
- 1. 故障自動恢復:通過ZKFC監控和自動切換,平均故障恢復時間(MTTR)從人工干預的分鐘級縮短至秒級
- 2. 數據一致性保障:基于QJM(Quorum Journal Manager)的元數據同步機制,確保切換過程中不會丟失已提交的寫操作
- 3. 運維透明化:管理員可以安全地進行計劃內維護,而不必擔心影響生產服務
CSDN技術專家在分析中指出,現代HDFS HA方案已能容忍N/2的JournalNode節點故障(N為集群規模),這種設計既保證了數據安全性,又避免了傳統共享存儲方案(如NAS)帶來的性能瓶頸和額外成本。隨著容器化部署的普及,HDFS HA架構還展現出良好的云原生適配性,支持在Kubernetes等平臺上實現彈性伸縮。
HDFS HA實現原理詳解
在Hadoop 2.0之前,HDFS架構存在明顯的單點故障風險——整個集群僅依賴單個NameNode管理元數據。一旦NameNode發生故障,整個HDFS集群將不可用,必須重啟NameNode才能恢復服務。這種設計缺陷嚴重影響了系統的可用性,使得7×24小時持續服務成為不可能完成的任務。HDFS高可用(HA)架構的引入徹底改變了這一局面,其核心思想是通過主備NameNode機制配合共享存儲系統,實現快速故障轉移和無縫服務接管。

?
主備NameNode架構設計
HA架構的核心在于構建Active-Standby雙節點體系。Active NameNode負責處理所有客戶端請求,而Standby NameNode則實時同步元數據變化,隨時準備接管服務。這種設計需要解決三個關鍵問題:
- 1. 元數據實時同步:確保Standby節點能及時獲取Active節點的所有狀態變更
- 2. 故障自動檢測:快速識別Active節點失效并觸發切換
- 3. 服務無縫轉移:客戶端能夠自動重定向到新的Active節點
為解決這些問題,HDFS HA引入了三個核心組件:ZKFC負責監控和故障轉移決策,JournalNode集群提供共享存儲服務,而ZooKeeper則提供分布式協調能力。這種架構下,即使Active NameNode發生硬件故障,整個切換過程可在30秒內完成,遠快于傳統手動恢復所需的數十分鐘。
QJM共享存儲系統原理
Quorum Journal Manager(QJM)是HDFS HA采用的共享存儲方案,其設計靈感源自Paxos分布式一致性協議。JournalNode集群通常由2N+1個節點組成,可容忍最多N個節點故障。這種設計實現了CAP理論中的CP平衡(一致性與分區容錯性),確保元數據變更能夠安全持久化。
當Active NameNode接收到寫請求時,會先將編輯日志(EditLog)寫入JournalNode集群。根據QJM的仲裁原則,只有當大多數(N+1)JournalNode確認寫入成功后,本次操作才會被視為完成。這種機制保證了即使部分JournalNode不可用,系統仍能繼續運作。例如,由3個JournalNode組成的集群(N=1)需要至少2個節點確認寫入,即使1個節點宕機也不影響服務。
JournalNode內部采用分段存儲機制管理EditLog。每個日志段(segment)對應一個連續的事務ID(txid)范圍,包含兩種狀態:
- ? Inprogress段:當前正在寫入的活躍段文件(如edits_inprogress_000000003)
- ? Finalized段:已完成寫入的封閉段文件(如edits_000000001-000000002)
這種設計不僅提高了日志管理的效率,還便于Standby NameNode按需拉取特定范圍的元數據變更。
元數據一致性保障機制
保證主備NameNode元數據一致性是HA架構的核心挑戰。HDFS通過多層次的同步機制實現這一目標:
- 1. Epoch編號系統:每個Active NameNode實例擁有唯一的遞增epoch編號。JournalNode會拒絕epoch值小于本地記錄的寫入請求,防止"腦裂"情況下出現雙主節點同時寫入。當發生主備切換時,新Active節點會生成更大的epoch值,確保其寫入權限的合法性。
- 2. 雙重確認機制:Active NameNode執行元數據變更時,必須完成兩個關鍵步驟:
- ? 將EditLog同步到大多數JournalNode
- ? 更新內存中的文件系統鏡像(FsImage)
只有這兩個操作都成功,才會向客戶端返回成功響應
- 3. 定期檢查點機制:Standby NameNode會定期執行檢查點操作,將EditLog合并到FsImage中。這不僅減少了故障恢復時需要重放的日志量,還通過以下流程確保數據完整性:
- ? 從JournalNode下載最新的EditLog
- ? 與本地FsImage合并生成新鏡像
- ? 將新鏡像上傳回Active NameNode
這個過程使得Standby節點始終保持與Active節點近實時的狀態同步
主備狀態轉換流程
當需要進行主備切換時(無論是計劃內維護還是故障轉移),系統遵循嚴格的協議確保狀態轉換安全:
- 1. Active節點降級:當前Active節點首先停止接受新的客戶端請求,完成所有進行中的操作,并將最后的EditLog強制刷寫到JournalNode。這一步驟確保不會有未持久化的元數據變更丟失。
- 2. Standby節點準備:待切換的Standby節點確保已同步所有JournalNode中的EditLog,完成最后一次檢查點操作,并驗證其FsImage與最新EditLog的一致性。
- 3. 服務接管:新Active節點加載完整的元數據后,通知所有DataNode更新其塊報告,并開始接受客戶端請求。此時ZooKeeper會更新其存儲的Active節點信息,使客戶端能夠發現新的服務端點。
值得注意的是,整個切換過程中JournalNode集群始終保持可用,這為快速故障恢復提供了基礎。即使在極端情況下同時丟失Active和Standby NameNode,管理員仍可通過從JournalNode恢復元數據重建NameNode服務。
ZKFC故障切換流程解析
在HDFS高可用架構中,ZKFC(ZooKeeper Failover Controller)扮演著至關重要的角色。這個輕量級進程運行在每個NameNode節點上,通過與ZooKeeper集群的協同工作,實現了對NameNode狀態的實時監控和自動故障轉移功能。理解ZKFC的工作機制,是掌握HDFS高可用實現原理的關鍵環節。
ZKFC的核心組件與架構
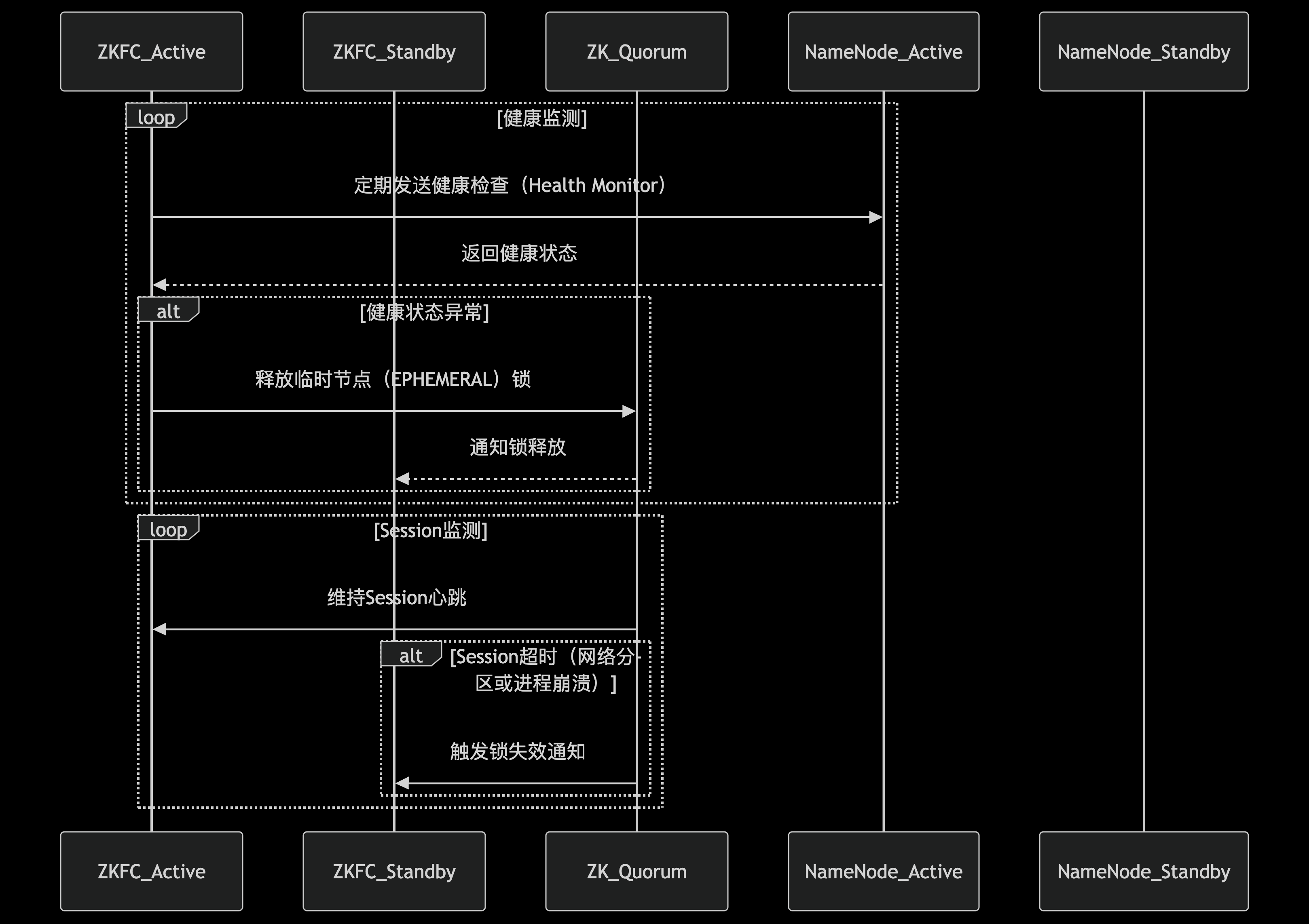
ZKFC內部由三個核心模塊構成一個精密的監控-決策-執行體系。首先是HealthMonitor模塊,它通過定期向本地NameNode發送健康檢查請求(默認每5秒一次),持續評估NameNode的運行狀態。檢查內容包括RPC響應能力、文件系統健康狀況等關鍵指標。根據檢測結果,NameNode可能被標記為四種狀態之一:初始化中(INITIALIZING)、服務正常(SERVICE_HEALTHY)、服務異常(SERVICE_UNHEALTHY)、或者連接失敗(SERVICE_NOT_RESPONDING)。
第二個關鍵組件是ActiveStandbyElector,它負責管理NameNode在ZooKeeper中的會話狀態。當本地NameNode健康時,ZKFC會在ZooKeeper中維持一個活躍會話(session)。如果該NameNode處于活動狀態,還會在ZooKeeper的指定路徑(如/hadoop-ha/${dfs.nameservices}/ActiveStandbyElectorLock)創建一個臨時節點(ephemeral node),這個節點實際上就是一把分布式鎖。ZooKeeper的特性保證了同一時刻只有一個客戶端能成功創建該節點,從而確保集群中只有一個Active NameNode。
第三個組件ZKFailoverController作為總協調者,負責處理來自HealthMonitor和ActiveStandbyElector的事件通知,并根據預設策略決定是否觸發故障轉移。這種模塊化設計使得系統各部分的職責清晰明確,便于維護和擴展。
故障檢查流程圖
?
故障檢測與狀態轉換機制
ZKFC的故障檢測機制采用多層次的健康評估策略。除了基本的進程存活檢查外,還包括對NameNode關鍵服務的深度探測。當HealthMonitor檢測到本地NameNode連續多次(可配置)未能通過健康檢查時,會向ZKFailoverController發送狀態變更通知。值得注意的是,此時系統并不會立即觸發切換,而是進入一個"觀察期",避免因網絡抖動等瞬時問題導致的誤判。
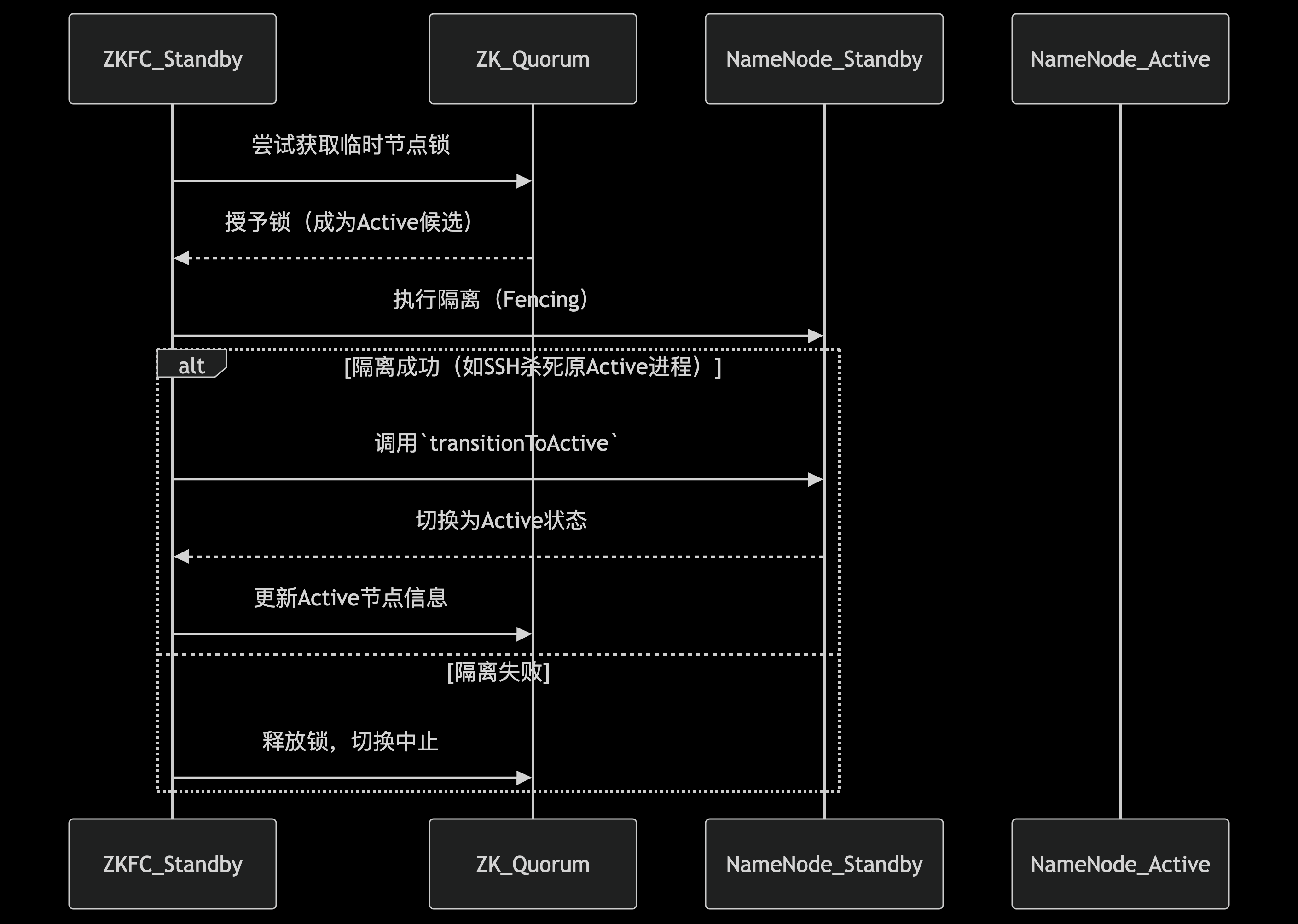
在狀態轉換過程中,ZKFC會綜合考慮多方因素做出決策。如果檢測到當前Active NameNode失效,ZKFC首先會嘗試通過"防護隔離"(fencing)機制確保原Active節點不能再進行任何寫操作。常見的隔離手段包括:通過SSH遠程終止NameNode進程、撤銷其訪問共享存儲的權限,或者調用預配置的防護腳本。這一步驟至關重要,可以防止"腦裂"(split-brain)情況的發生,即兩個NameNode同時認為自己是Active節點。
基于ZooKeeper的選舉流程
當需要進行主備切換時,ZKFC通過ZooKeeper實現了一個高效的選舉算法。所有健康的Standby NameNode都會嘗試在ZooKeeper上創建同一個臨時節點,由于ZooKeeper的強一致性保證,最終只有一個客戶端能夠創建成功。這個成功的ZKFC隨即將其監控的NameNode提升為Active狀態。
選舉過程中有幾個關鍵細節值得注意:首先,每個參與選舉的NameNode都會攜帶一個單調遞增的epoch編號,這個編號在每次主備切換時都會增加,確保系統能夠識別最新的選舉請求。其次,ZooKeeper的watcher機制使得所有參與者能夠實時感知到鎖節點的變化,一旦當前Active節點釋放鎖(通常是因為會話過期),其他節點會立即收到通知并觸發新一輪選舉。
故障切換的完整流程
一個完整的自動故障切換流程通常包含以下步驟:
- 1. HealthMonitor檢測到Active NameNode失效,通知ZKFailoverController。
- 2. ZKFC驗證問題確實存在(避免誤報),然后通過ActiveStandbyElector釋放ZooKeeper上的鎖節點。
- 3. 所有Standby NameNode的ZKFC檢測到鎖節點消失,開始新一輪選舉。
- 4. 選舉獲勝的ZKFC執行防護隔離操作,確保原Active節點不再工作。
- 5. 新的Active NameNode加載最新的元數據(通過JournalNode同步),并開始對外服務。
- 6. 所有DataNode根據心跳機制自動重新注冊到新的Active NameNode。
整個切換過程通常在幾十秒內完成(具體時間取決于配置參數如會話超時時間等),對上層應用的影響可以降到最低。Hadoop管理員可以通過調整參數如dfs.ha.fencing.methods(防護方法)、ha.zookeeper.session-timeout.ms(ZooKeeper會話超時)等來優化切換速度和可靠性。
異常處理與恢復機制
在實際生產環境中,網絡分區、ZooKeeper集群不穩定等情況時有發生。ZKFC設計了多種機制來應對這些異常場景。例如,當ZKFC與ZooKeeper集群失去連接時,它會進入一個"中立"狀態,既不會嘗試獲取Active鎖,也不會放棄現有鎖(如果是Active節點),直到連接恢復。這種保守策略避免了在網絡不穩定的情況下頻繁觸發無意義的切換。
另一個重要特性是graceful failover(優雅故障轉移),管理員可以通過命令行工具手動觸發主備切換,而不需要實際發生故障。這在計劃維護時非常有用。執行過程中,ZKFC會協調兩個NameNode完成狀態轉換,確保元數據完全同步后再進行角色切換,實現零數據丟失。
性能優化與監控建議
為了確保ZKFC的高效運行,有幾個關鍵配置參數需要注意:
- ? dfs.ha.heartbeat.interval:控制健康檢查的頻率,需要平衡及時性和系統開銷
- ? ha.zookeeper.acl:設置適當的ZooKeeper訪問權限,保障安全性
- ? dfs.ha.automatic-failover.enabled:明確是否啟用自動故障轉移功能
監控方面,除了常規的進程存活檢查外,還應特別關注:
- ? ZKFC與ZooKeeper的連接延遲
- ? 健康檢查的成功率與時延
- ? 主備切換的歷史記錄和耗時統計
- ? ZooKeeper鎖節點的狀態變化
主備切換流程圖
這些指標可以幫助管理員提前發現潛在問題,如網絡延遲增大可能導致誤判,或者JournalNode同步延遲可能延長切換時間等。
JournalNode的元數據同步機制
在HDFS高可用架構中,JournalNode集群承擔著元數據同步中樞的關鍵角色。這套基于Paxos算法的分布式系統設計,解決了傳統NFS共享存儲方案的單點故障問題,為雙NameNode提供了高可靠的元數據同步通道。
?
JournalNode的核心架構設計
JournalNode集群通常由奇數個節點組成(最少3個),采用Quorum機制確保數據一致性。每個JournalNode獨立運行輕量級服務進程,維護著完整的edit log序列。這種去中心化設計使得系統在部分節點故障時仍能保持可用——只要超過半數的JournalNode節點存活,集群就能繼續提供服務。與傳統的NFS共享存儲相比,JournalNode方案具有更好的水平擴展能力和容錯性。
元數據寫入的原子性保證
當Active NameNode執行元數據變更時,會通過兩階段提交協議確保數據一致性:
- 1. 準備階段:Active NN將edit log條目并行發送給所有JournalNode,但并不立即提交。此時JournalNode將數據暫存于內存緩沖區,同時持久化到本地磁盤的臨時區域。
- 2. 提交階段:當收到多數JournalNode(N/2+1)的ACK響應后,Active NN廣播提交指令。JournalNode收到指令后,將臨時數據原子性地移動到正式存儲位置,并更新最后提交的事務ID(Transaction ID)。
這種設計確保了即使在網絡分區或節點故障的情況下,系統也能維持強一致性——要么所有可用JournalNode都成功提交事務,要么全部回滾。
實時同步與追趕機制
Standby NameNode通過以下機制保持與Active節點的元數據同步:
- 1. 長輪詢監聽:Standby NN持續向JournalNode集群發送攜帶最后已知事務ID的GET請求。JournalNode會保持連接開放,直到有新數據到達或超時,大幅減少輪詢開銷。
- 2. 分段批量拉取:當檢測到落后較多時(如故障恢復場景),Standby NN會自動切換為批量拉取模式,每次獲取多個事務塊,通過流水線傳輸優化同步效率。
- 3. 校驗與重試機制:每條edit log都包含CRC32校驗碼,Standby NN在應用變更前會驗證數據完整性。當發現數據損壞時,會自動從其他JournalNode節點重新拉取。
數據持久化與恢復策略
JournalNode采用多級持久化策略保障數據安全:
- 1. 內存緩沖:最新接收的edit log首先存入環形緩沖區,支持快速讀寫。
- 2. 本地磁盤存儲:數據同步寫入本地文件系統,采用滾動文件機制管理(默認每100萬條記錄或1小時生成新文件)。
- 3. 定期檢查點:與NameNode的checkpoint機制協同工作,定期將edit log合并到fsimage,減少恢復時的重放負載。
在節點崩潰恢復場景中,JournalNode啟動時會執行以下操作:
- ? 檢查最后提交的事務ID與磁盤文件的一致性
- ? 通過與其他JournalNode比對事務日志來修復潛在的不一致
- ? 重建內存中的事務索引表
性能優化關鍵技術
- 1. 批量寫入:Active NN將多個元數據操作打包成單個RPC請求發送,顯著減少網絡往返開銷。測試數據顯示,批量大小設置為100-200條時吞吐量可提升3-5倍。
- 2. 異步化處理:JournalNode采用事件驅動架構,網絡I/O、磁盤寫入和副本同步操作都在獨立線程池中執行,避免阻塞關鍵路徑。
- 3. 內存映射文件:對歷史edit log文件使用mmap技術,加速Standby NN的隨機讀取操作。
異常處理機制
當出現網絡分區或節點故障時,系統通過以下策略維持可用性:
- ? 寫入超時處理:Active NN在500ms(默認)未收到JournalNode響應時,會標記該節點為臨時不可用,轉而將數據發送給其他健康節點。
- ? 多數派原則:只要收到多數JournalNode的成功響應,就認為寫入成功,少數落后節點會通過后臺同步線程逐步追趕。
- ? 腦裂防護:結合ZKFC的fencing機制,確保故障時只有一個NameNode能向JournalNode寫入數據。
實際部署中,JournalNode集群通常與ZKFC、NameNode分開部署,避免資源競爭。對于超大規模集群(PB級以上),建議采用專用高性能SSD存儲JournalNode數據,并將RPC超時參數(dfs.journalnode.rpc-timeout.ms)根據網絡延遲情況適當調大。
HDFS HA的最佳實踐與挑戰
部署HDFS HA的最佳實踐
在Hadoop生產環境中部署HDFS高可用集群時,遵循特定配置原則和操作流程至關重要。根據Hadoop社區推薦和實際運維經驗,以下關鍵實踐已被證明能顯著提升系統穩定性:
網絡與硬件配置
建議采用專用網絡隔離JournalNode集群與常規數據傳輸通道,避免元數據同步流量與數據塊傳輸產生競爭。JournalNode節點應部署在獨立的物理服務器上,至少配置3個節點(滿足2N+1原則),每個節點配備高性能SSD存儲以降低編輯日志寫入延遲。NameNode節點建議采用相同硬件規格,確保備用節點具備同等處理能力。
關鍵參數調優
在hdfs-site.xml中,dfs.journalnode.edits.dir應指向高性能存儲設備,并定期清理歷史編輯日志。ZKFC的健康檢查間隔(ha.zookeeper.session-timeout.ms)需要根據網絡延遲調整,典型值為5-15秒。對于大規模集群,應增大dfs.namenode.shared.edits.dir的寫入緩沖區(dfs.journalnode.output-buffer-size),默認4MB可提升至8-16MB。
安全配置要點
啟用Kerberos認證時,必須為每個JournalNode配置獨立keytab文件,并確保ZKFC進程具備訪問ZooKeeper的權限。建議設置dfs.ha.fencing.methods包含SSH和shell兩種隔離方法,防止腦裂場景下出現雙主節點。例如:
<property><name>dfs.ha.fencing.methods</name><value>sshfence(hdfs@nn1),shell(/path/to/fence_script.sh)</value>
</property>監控體系構建
除了基礎的健康狀態監控外,需要特別關注JournalNode的QJM(Quorum Journal Manager)指標,包括:
- ?
JournalTransactionLag:反映Standby NN同步延遲 - ?
LastWriterEpoch:檢測編輯日志寫入連續性 - ?
RpcRequestQueueSize:評估JournalNode處理能力
推薦使用Prometheus+Grafana組合實現指標可視化,設置dfs.journalnode.metrics.*相關參數暴露關鍵指標。
運維過程中的典型挑戰與解決方案
腦裂場景處理
當ZKFC因網絡分區無法與ZooKeeper通信時,可能出現兩個NameNode同時處于Active狀態。此時依賴預配置的隔離機制至關重要。某電商平臺案例顯示,通過組合SSH隔離(終止原Active NN進程)和STONITH(Shoot The Other Node In The Head)硬件級隔離,可將故障恢復時間控制在30秒內。關鍵配置包括:
<property><name>dfs.ha.fencing.ssh.connect-timeout</name><value>30000</value>
</property>
<property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/home/hdfs/.ssh/id_rsa</value>
</property>JournalNode性能瓶頸
在寫入密集型場景下,JournalNode可能成為系統瓶頸。某金融機構的測試數據顯示,當每秒編輯日志操作超過5000次時,3節點JournalNode集群的寫入延遲從平均2ms驟增至50ms。解決方案包括:
- 1. 升級至JournalNode 3.0+版本,支持批處理寫入
- 2. 調整
dfs.journalnode.threads參數至CPU核心數的2倍 - 3. 采用RDMA網絡降低節點間通信延遲
- 4. 定期使用
hdfs dfsadmin -getJournalState命令檢查集群一致性
ZKFC誤切換問題
由于GC暫停或系統負載過高導致NameNode響應延遲,可能觸發ZKFC誤判。某電信運營商通過以下改進將誤切換率降低90%:
- ? 設置
ha.health-monitor.connect-retry-interval.ms為漸進式增長間隔(初始1秒,最大10秒) - ? 增加
ha.health-monitor.rpc-timeout.ms至60秒 - ? 在ZKFC中實現動態健康評分機制,綜合考量JVM狀態和系統負載
元數據同步異常
當Active NN與JournalNode集群間出現持續網絡中斷時,可能導致編輯日志斷裂。此時需要人工介入處理:
- 1. 使用
hdfs dfsadmin -fetchImage從最新狀態的NN獲取元數據鏡像 - 2. 通過
hdfs namenode -bootstrapStandby重建備用節點 - 3. 驗證JournalNode序列號連續性(
journalnode -getJournalStatus)
某云服務商開發了自動化修復工具,可將此過程從小時級縮短至分鐘級。
版本升級與兼容性管理
HDFS HA集群的版本升級需要特殊處理流程。實踐證明,滾動升級策略配合以下步驟可最大限度減少服務中斷:
- 1. 首先升級JournalNode集群并驗證QJM協議版本兼容性
- 2. 將Standby NN升級至新版本并完成元數據同步
- 3. 通過
hdfs haadmin -failover主動切換主備節點 - 4. 升級原Active NN節點
關鍵檢查點包括:
- ? 確認
dfs.journalnode.rpc-address在新舊版本間保持一致 - ? 驗證ZKFC的ACL權限在升級后未被重置
- ? 檢查
dfs.ha.automatic-failover.enabled配置是否保持為true
對于與上層組件(如Hive、Spark)的兼容性問題,典型案例是Hive metastore仍指向舊NN地址。解決方案包括:
- ? 批量更新metastore中SDS表的LOCATION字段
- ? 配置HDFS客戶端使用邏輯服務ID(如
hdfs://mycluster)而非物理地址 - ? 在core-site.xml中設置
fs.defaultFS為HA集群名稱服務
未來展望:HDFS HA的發展方向
云原生架構下的HDFS HA演進
隨著Kubernetes成為容器編排的事實標準,HDFS與云原生技術的融合正成為重要趨勢。最新實踐表明,通過將NameNode、JournalNode等組件容器化部署為Kubernetes StatefulSet,可以實現更靈活的彈性擴縮容。云原生AI工作負載的興起(如白皮書《Cloud Native AI Whitepaper》所述)對存儲系統提出了新要求,HDFS HA需要適應微服務架構下的動態資源調度特性。未來可能出現的"Serverless HDFS"模式,將允許按需啟動NameNode實例,結合Kubernetes的Volcano調度器優化批處理作業的資源分配。
智能化的故障預測與自愈機制
傳統ZKFC基于心跳超時的故障檢測存在滯后性,新興的AIOps技術為HA系統帶來變革可能。通過收集NameNode的JVM指標、操作系統性能數據以及歷史故障模式,機器學習模型可以實現:
- ? 基于時間序列預測的故障預判(在節點完全宕機前觸發優雅切換)
- ? 自適應閾值調整(根據負載動態設置心跳超時閾值)
- ? 根因分析輔助決策(區分網絡分區與真實節點故障)
華為云等廠商已在實驗性項目中驗證,這類技術可將故障切換時間縮短30%以上,同時降低誤切換概率。
跨地域元數據同步的突破
當前JournalNode的Quorum寫入機制在跨地域部署時面臨延遲挑戰。學術界提出的"分層日志同步"方案值得關注:
- 1. 區域內部采用強一致性同步
- 2. 跨區域通過異步復制+沖突解決算法保證最終一致性
- 3. 引入向量時鐘技術追蹤元數據修改順序
阿里云在2023年的測試中實現了北京-上海雙活部署,元數據同步延遲控制在500ms內。未來可能結合RDMA網絡優化JournalNode通信協議,進一步降低同步開銷。
存儲計算分離架構的適配優化
現代大數據平臺普遍采用存儲計算分離架構,這對HDFS HA提出新要求:
- ? 輕量化NameNode:剝離數據塊管理功能,專注命名空間服務
- ? 持久化內存應用:使用Intel Optane PMem加速EditLog寫入
- ? 對象存儲集成:通過HDFS-Ozone Connector實現元數據與數據的分離高可用
Cloudera CDP7已支持將NameNode元數據存儲在外部數據庫,這種設計可能成為未來標準,使HA部署不再依賴JournalNode集群。
安全增強與多租戶隔離
隨著企業級應用深化,HDFS HA需要在安全領域持續改進:
- 1. 零信任架構整合:每次主備切換時動態輪換Kerberos憑證
- 2. TEE可信執行環境:在SGX enclave中運行關鍵切換邏輯
- 3. 細粒度審計追蹤:記錄所有HA操作到區塊鏈日志
某金融機構POC項目顯示,這些措施可使系統通過金融級安全認證,同時保持亞秒級故障恢復能力。
邊緣計算場景的輕量級方案
針對邊緣設備資源受限的特點,新興的"微型HA"方案正在發展:
- ? 基于Raft共識算法替代ZKFC(減少ZooKeeper依賴)
- ? 差分元數據同步(僅傳輸修改部分)
- ? 智能壓縮算法處理EditLog
華為邊緣AI解決方案已實現500MB內存占用下的雙節點HA部署,為IoT場景提供新可能。
性能監控體系的智能化重構
傳統基于SNMP的監控體系難以滿足現代需求,下一代監控方案可能包含:
- ? 分布式追蹤集成(通過OpenTelemetry捕獲全鏈路HA事件)
- ? 因果推理引擎(分析切換延遲與底層硬件狀態的關聯)
- ? 預測性容量規劃(基于工作負載預測提前擴容JournalNode集群)
某電信運營商在實驗環境中部署的AI監控系統,成功將計劃外停機減少了45%。




)





)




)

)

