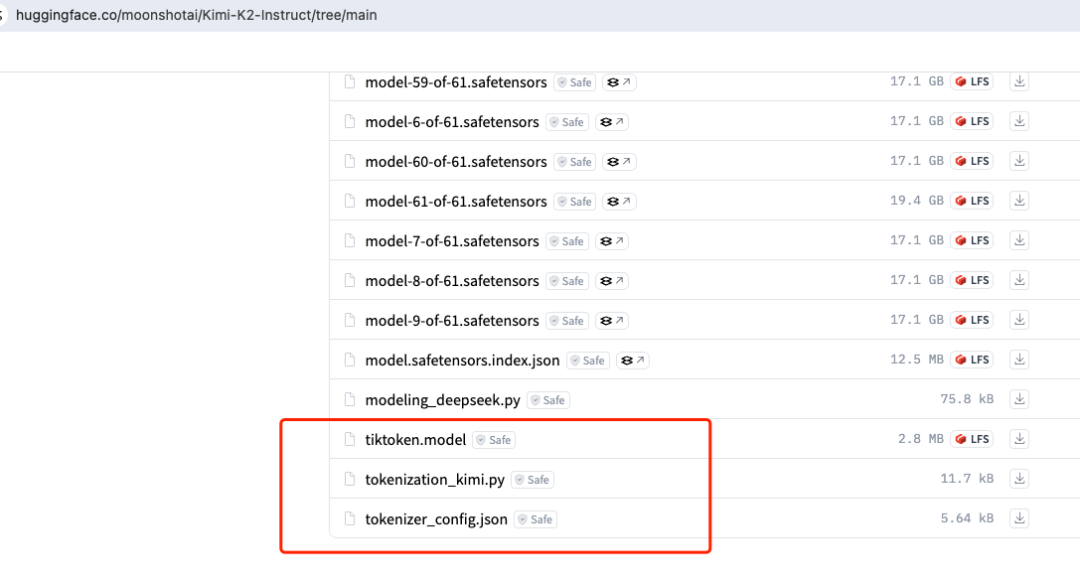
一般你們下AR模型的時候,都有這個,也就是tokenzier,tokenizer是干啥的,其實就是你的分詞字典

不光有specal的token對應的還有實際的對應的分詞對應的代碼,比如:
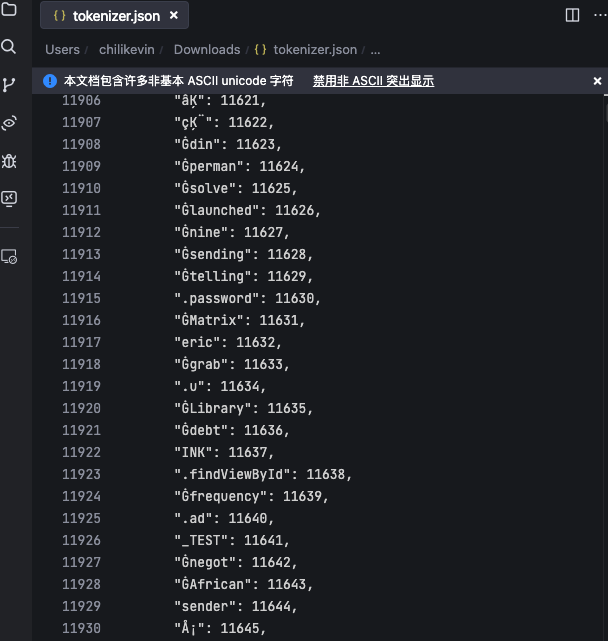
也有tokenzier沒顯示的,比如,
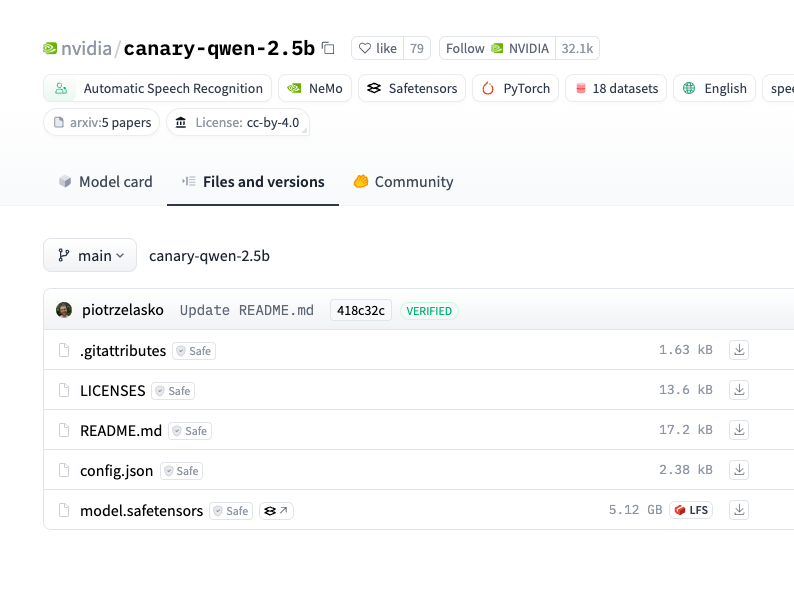
為什么呢?
因為它不是文本模型

,人家輸入是聲音,因為它是ASR
扯遠了,回歸主題
tokenizer之所以總是個獨立的model,因為它和transformer
不是一個網絡,它也不參與transformer訓練時候的反向傳播(和embedding層兩回事,embedding參與BP和學習),也不共享參數(其實問你為什么沒關系,你記住這點就夠了)
一個正常的流程是這樣的
傳統自回歸文本模型(如GPT/Llama)
訓練時流程:
原始文本 → tokenizer切分 → token id序列 → embedding → Transformer → 輸出概率/預測下一個token
推理時流程:
文本 → tokenizer → token id → embedding → 模型生成token id →?detokenizer(還原文本)
這個沿用了多少年的架構的有什么問題嗎?
其實是有的
靜態分詞:只能預定義/規則分割,不隨語境、下游任務改變;
詞表對非英文、代碼、特殊字符等不友好,多語言/新詞適應性差;
字符錯位/擾動很容易破壞下游表現(比如 misspell、空格丟失等,魯棒性差);
tokenizer/vocab詞表一旦定型,后期無法彌補缺失、替換麻煩。
造車上面那幾個問題的原因:
1. 詞表構建機制決定的“偏見”和局限
大部分主流tokenizer(BPE、WordPiece等)是基于英文語料統計頻率自動生成“片段”?(tokens/subwords),詞表中每個條目是按常見性排序和合并出來的。
這會導致詞表里絕大多數都是英語常用詞、前綴、后綴,以及特殊分隔符,對別的語言(中文、阿拉伯文、俄語)、編程代碼、emoji、數學符號等覆蓋不全,兼容性低。
2. 非英文/多語言適應困難
- 詞表是靜態的且容量有限,比如GPT-2的vocab僅5萬-6萬個而已
。英文組成大都在其中,其他語種即便包含,也非常零散或拆分得特別碎。
比如中文,往往被拆成單字(明/天/去/看/書),或者出現大量 UNK(未登錄詞)或‘##’前綴的生僻合成,而不是自然分詞和表達。
罕見符號/擴展字符/emoji/古文字等,因為詞表沒收錄,只能用char級別或fallback(拆為u8字節)編碼成很多token,表達效率極低。
3. 新詞/熱詞/代碼/專業類token的弱勢
領域專有名詞(如新科技名詞、代碼單詞、化學式等)未進入初始詞表時,只能被拆為很多“字符”或“常出現的前綴/后綴”碎片,模型難以捕捉其整體語義;
代碼文本常見變量、內置語法結構、斜杠點等符號,傳統tokenizer未專門優化,往往拆的四分五裂,遠不如直接字符/字節級處理。
4. 多語言詞表擴展的工程復雜性
為了多語言LLM,多數方案要顯式加大詞表,或多人手動挑選token,但詞表容量越大,embedding參數爆炸,推理速度也會下降,說到擴詞表,比如4o當時上市的時候都干到15萬左右了,大家還覺得它整挺好,它其實非常無奈,完了為了維護多模態,又得壓縮,導致一個長詞對應一個token id,才有了那時候的一些小bug,感興趣的各位自己去找當年的新聞。
有些詞永遠用不上,冗余空間浪費;而新加入的熱詞又需要重新訓練embedding才能學出屬性。
這時候如果有兄弟玩過LSTM可能會一起來,早起是沒有tokenizer,也沒BPE這玩意的,最早是char-level來建模(注意是最早,LSTM也有token level)
char-level (字符級) 建模,是指模型的輸入輸出都是“字符”,比如 ["m", "o", "d", "e", "l"],或者直接處理字節(每個字節一個embedding),其實就是字符映射為 embedding index,適用于玩具任務、OOV高風險任務、小數據集、很早期的英文句子生成等
特點是詞表極小(只需覆蓋所有常見字符或字節),無須分詞器,OOV問題天然不存在,對語種/符號極友好,即使所有中文字、標點都可編碼進固定的小字表(7000常用漢字以內都能輕松搞定)
舊的LSTM/char-RNN/ByT5等都是純char-level(或byte-level)。
那為啥都轉去token level去了呢?
語義表達效率低:
漢語一個字的信息含量比英文小,隨便一個新詞(如“碼農”)只能靠“碼”、“農”兩個單字序列表達,捕捉組合語義難,長依賴seqlen變長。
序列極長:
同長度內容,char-level序列會遠比token-level長,計算/內存/推理慢(transformer類模型自注意力時間、顯存正比于N^2,當然這個和LSTM沒啥關系,線性注意力一直是N)。
模型收斂慢,捕捉高階結構難:
大段話、句子、專業詞都被拆為單字或字節,模型要學會組合成“自然語言片段”需要更多層、更多數據,效率和泛化難度高于“合理分塊”的token-level或動態chunking方案。
但是最近有CMU的人給字符level編碼翻案

這論文針對的場景就是剛才我們說的tokenizer的問題
分詞器本身是手工預處理,對語義、語境缺乏自適應,“一刀切”方式不適合所有語種/信息結構(比如中文/代碼/DNA等)。
靜態Token也導致模型易受拼寫噪聲、字符級擾動破壞;跨領域遷移也更難。支持多語言費勁。
所以誕生了dynamic chunk機制(和我自己做的項目dc不是一回事,我那個不是分詞和char level的)和H-net
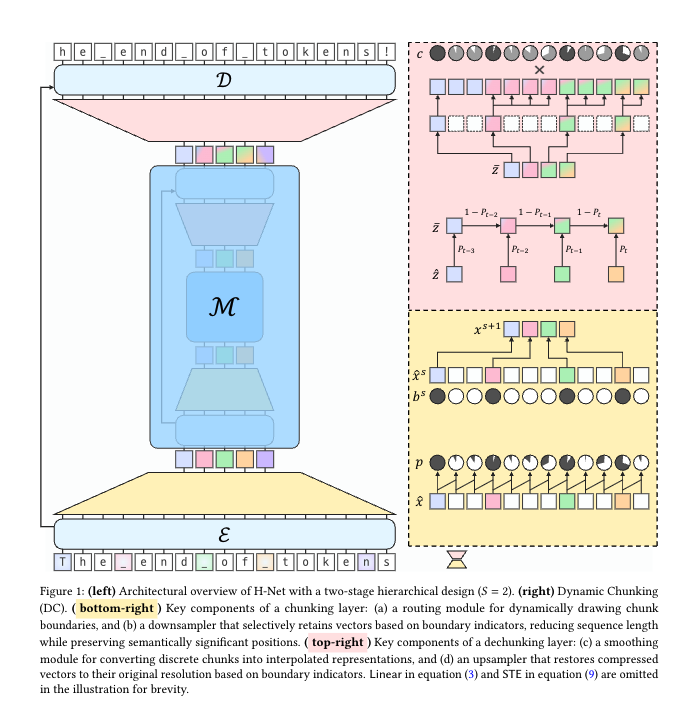
H-Net總體架構
核心思想:創造支持“動態分塊機制”(Dynamic Chunking, DC)的層次化神經網絡(H-Net),讓模型自己端到端學會:哪里是有意義的邊界,該怎么自動分段、壓縮和聚合輸入序列。
1. 架構圖如上面的圖
流程:
原始字節輸入 (從下面網上面看)→ 編碼器(Encoder)做初步字節級embedding(這也可以用Mamba SSM層,線性注意力,當然也可以transformer);
- 動態分塊模塊(DC)
模型自適應“切片”輸入序列,按上下文/內容決定block(被分詞的)位置。
主干網絡(Main Network):主要參數集中于此,對已被壓縮的chunk序列做深度建模(高語義、長距離依賴捕獲)。
解分塊(Dechunking):用上采樣/smoothing等方法,將高層chunk輸出重新映射回細粒度token,供解碼器(Decoder)輸出。
2. “分塊”與常規分詞對比:
常規 Tokenizer:全靠規則/人工預設,只能一分到底。
動態分塊DC:模型自動檢測上下文變化處(如語法/語義轉換),預測邊界概率→下采樣成chunk embedding序列,高效又自適應。
我們用一個具體例子來說明H-Net的動態分塊(Dynamic Chunking,DC)機制是怎么“自動檢測上下文變化”并形成chunk的。
示例文本
假設輸入文本為:"The end of tokens."
1. 傳統tokenizer分割
例如使用BPE等,會直接把它分為
["The", "end", "of", "tokens", "."]
2. H-Net動態分塊的流程與輸出
第一步:編碼各字節/字符
輸入會轉成:["T", "h", "e", " ", "e", "n", "d", " ", "o", "f", " ", "t", "o", "k", "e", "n", "s", "."]
每個字符/空格/符號作為一個輸入位置,初步embedding。
第二步:模型自動“判別”邊界概率
H-Net的routing module會對每兩個相鄰embedding進行相似度測量(比如用余弦相似度),如果發現:
如?["d", " "](即“單詞結束后是空格”)、["s", "."](單詞結束遇到句號)等位置,embedding變化大(語法/語義上有明顯切換),相似度低,邊界概率高!
而像["e", "n"]、“["o", "f"]”等(單詞內部連續字母),相似度高,邊界概率低。
這樣,模型經過訓練后,會在如下位置分塊邊界概率最高(比如):
T ? h ?e ? _ ? e ?n ?d ? _ ? o ?f ? _ ? t ? o ?k ?e ?n ?s ? .
↑ ? ? ? ?↑ ? ? ? ? ↑ ? ? ? ? ? ? ↑ ? ? ? ? ? ? ↑ ? ? ? ? ? ↑
0 ? ? ? ? 0 ? ? ? ? ?1 ? ? ? ? ? ? 0 ? ? ? ? ? ? ?0 ? ? ? ? ? 1
下劃線和句號后的邊界概率更高
第三步:根據概率做動態分塊
H-Net的downsampler會篩選出邊界概率超過一定閾值的位置,比如:
“The end”作為一個chunk
“of”作為一個chunk
“tokens.”作為一個chunk
最終分塊方式可能是:
["The end", "of", "tokens."]
或者更細粒度:
["The", "end", "of", "tokens", "."](這么分和BPE就一樣了)
chunk的大小、邊界完全由數據和上下文(而不是手工規則)自動學到,且不同上下文還能靈活變化。
第四步:聚合chunk embedding并繼續建模
被判定為一個chunk的所有原始字節embedding會聚合(池化/加權等方法),形成一個chunk級higher-level embedding,進入主干網絡進行高抽象推理,這快就不用講了,因為已經進transformer了
打個比方:
- 像是在讀句子的時候,你發現“這里信息切換了,和下文關聯對有區分了”就自動切一刀,把前面的歸為一個高抽象信息塊。如果連續的內容沒變化(比如單詞內),就不分塊。
你給模型的任何輸入,不論語言、結構、符號,只要數據里有“信息變化點”,就可能自動形成chunk。
再舉極端對照例子
"I love applepie"
普通tokenizer:["I", "love", "apple", "pie"],這就分錯了唄,分成了 apple and pie
H-Net:可能["I", "love", "applepie"] 或 ["I love", "applepie"](因為"applepie"常一起出現),這兩個分都沒毛病
代碼場景:"def run_fast(x):"
普通tokenizer:["def", "run", "_", "fast", "(", "x", ")", ":"],這么分也比較扯了(當然你們大多數看不見這么差的,是因為代碼量大,special token和輔助字符機制讓你們不止于碰到這么離譜的,我就是舉個例子)
H-Net:可能["def", "run_fast", "(", "x", "):"],甚至整個函數名+參數合成chunk
所以,動態分塊DC讓模型“自動發現結構”,而不是簡單、固定地分詞或分字,大大增強了理解、壓縮和表達的能力。
我們最后再做一下流程對比
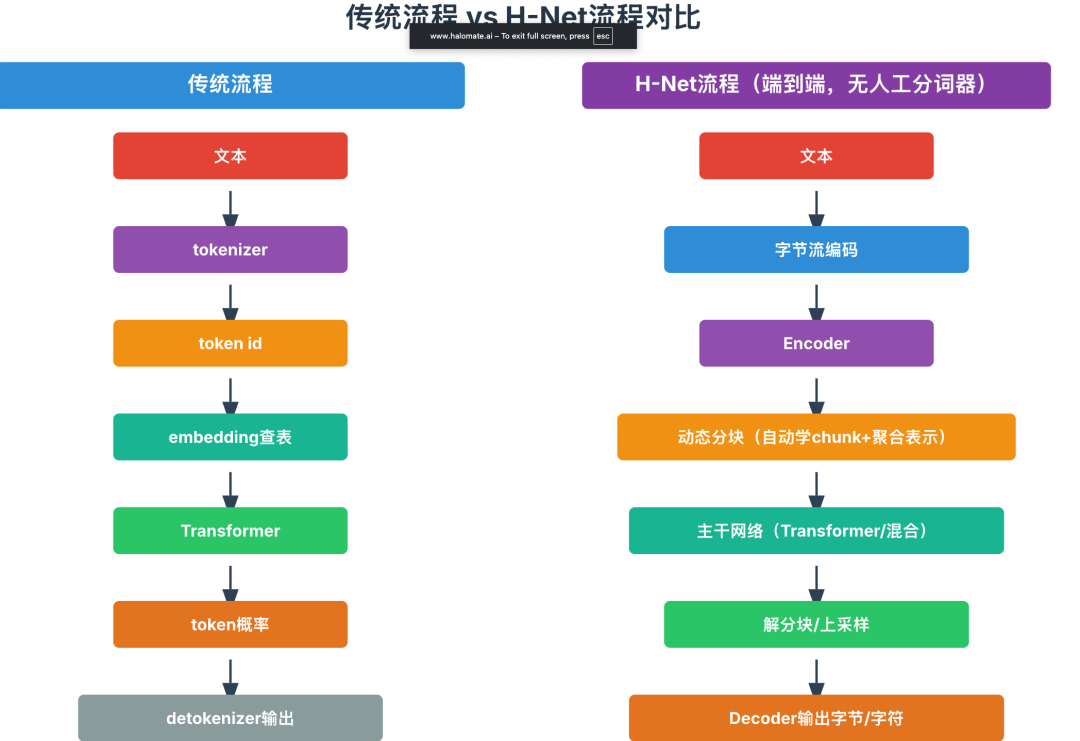
總結一下就是其實就是encoder+dc做了tokenizer的事了,然后上采樣+decoder做了softmax到詞表的logit
這么一上圖就沒那么抽象了,至于主干那塊其實愿意用trasformer還是ssm,或者mamba甚至混著來(現在不都流行這樣嗎,隔一層一遍,確實能省掉一部分因為指數注意力造成的算力壓力),就看你想怎么折騰了
最后看一下效果:
A. 語言建模主任務(英文+多語言)
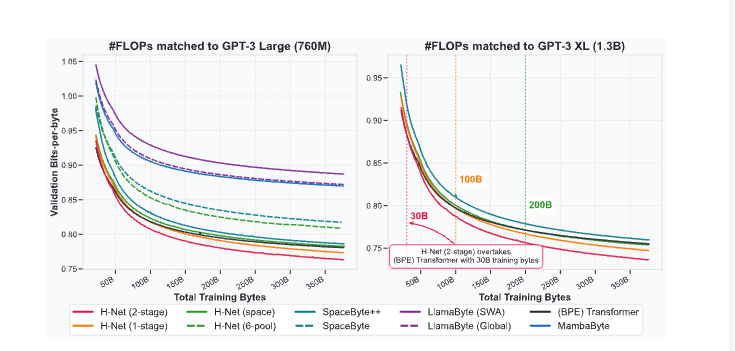
1.?驗證困惑度/壓縮效率(BPB)
H-Net(動態分塊)在相同訓練數據和算力預算下
1-stage結構已可匹配傳統BPE-Transformer的困惑度;
2-stage遞歸結構大幅超越:
H-Net (1-stage): BPB ≈ BPE Transformer
H-Net (2-stage): BPB 顯著低于同算力BPE Transformer
訓練曲線顯示,H-Net隨數據量增加,性能提升更快,最終收斂值更低(見下圖)。
2.?多語言與代碼/DNA建模
H-Net對中文、代碼、DNA等特殊輸入類型展現強大優勢,尤其是沒有自然token邊界的文本數據。
中文建模時,BPB顯著優于Llama3/Transformer等多語支持模型。
代碼建模同理,chunk壓縮率更高,表現優于詞表法。
DNA建模?性能提升極大,數據效率比等參數Transformer高3.6倍(可用更少數據達到同樣困惑度)。
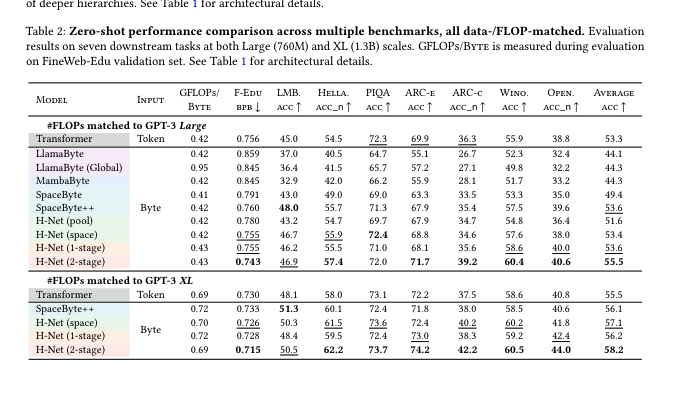
B. 下游通用任務表現
大規模zero-shot評測在LAMBADA、HellaSwag、PIQA、ARC-e、ARC-c、Winograd、OpenBook等七大benchmark任務上,H-Net(2-stage)平均分比傳統BPE Transformer高2%~3%?
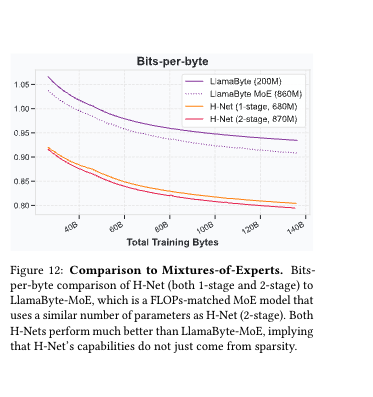
對比Mix-of-Experts(MoE) 、SpaceByte、LlamaByte等各種優化方法,H-Net也依然表現勝出,這里吐槽作者為什么方MOE,不過頁能理解,雖然不是一個層面的,但是,也都是優化手段,姑且理解為主干(FFN)稀疏vs壓縮冗余吧, 反正它敢比,我就敢把這個也粘過來了

C. 魯棒性和泛化能力
抗文本擾動魯棒性:在HellaSwag的五種perturbation(如隨機大小寫、字符重復、丟drop、混亂語法)測試下,H-Net魯棒性-平均準確度遠超過BPE Transformer和所有對照組。
可解釋性更強:Chunk邊界分布可視化表明模型學出的邊界多能對應詞/短語/語法塊,而不是簡單機械分詞。
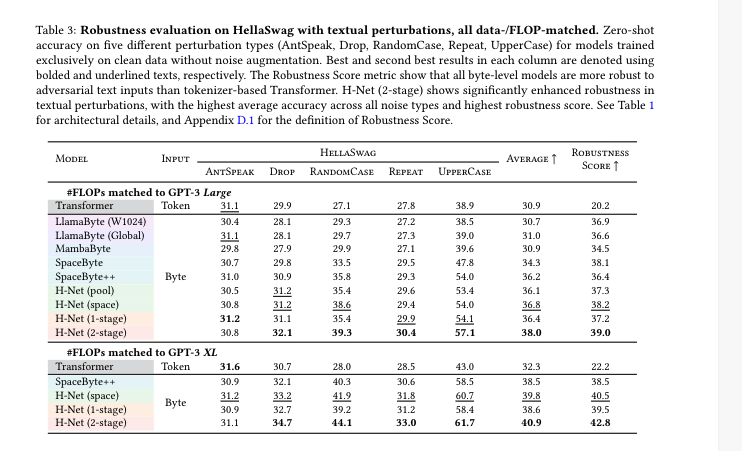
D. 數據/計算效率
同樣訓練數據和FLOPs下,H-Net能用更少數據、更少算力達到等同或更優效果,尤其在"hardcase"領域(如代碼/DNA/多語種)差距巨大。
總之還成,我為什么講這個呢,因為現在大家都在反transformer架構,但是也不能光喊口號,這個至少做出了一部分的關鍵工作(雖然tokenizer不屬于transformer,但是它也是現在網絡的基礎啊),如果你把主干全換成ssm類的比如mamba,那就徹底告別現在的網絡了,不過我覺得從主流視角看,這類的工作至少還要5年,因為transformer本身也都在外圍進行線性化的優化,而transformer非線性的部分的attention短期我沒看到能被取代的可能性。

)







)









