一、 貸款批準預測數據集
1. 數據探索與理解
prompt 1:
這是訓練數據,目的是貸款批準預測數據集上訓練的深度學習模型生成的數據,旨在使用借款人信息預測貸款批準結果,它通過模擬真實貸款審批場景,幫助金融機構評估借款人風險。
請展示訓練基本信息(數據維度、特征類型、缺失值情況)

prompt 2:
請生成數據集的描述性統計摘要?

prompt 3:
在這些變量中,請識別數值型和分類型變量?

prompt 4:
請檢查目標變量(貸款批準狀態)的分布情況?
 ?prompt 5:
?prompt 5:
請分析各特征的數據質量和異常值
?prompt 6:

prompt 7:
請問要如何處理這些異常值?

prompt 8:
請按如下方法處理:
1. person_age(年齡)
當前方法: 設定18-100歲范圍,超出部分刪除或替換 評估: ? 合適,但需要優化 改進建議:
保留18-85歲作為更合理的范圍(考慮貸款業務實際)
對于異常值建議使用中位數替換而非刪除,避免數據丟失
可以創建異常值標識特征,保留異常信息
2. person_income(收入)
當前方法: 分位數截斷 + 對數變換 評估: ? 很好的方法 改進建議:
建議使用99%分位數進行截斷,保留更多正常的高收入樣本
對數變換前建議先處理0值(加小常數或使用log1p)
可以考慮按地區或行業分層處理,避免一刀切
3. person_emp_length(工作年限)
當前方法: 設定0-50年范圍 評估: ? 合適,但可以更精細 改進建議:
考慮與年齡的邏輯關系:工作年限不應超過(年齡-16)
對于負值和缺失值,建議使用0填充(表示無工作經驗)
創建工作經驗分組特征(0年、1-5年、6-15年、16+年)
4. loan_amnt(貸款金額)
當前方法: 業務規則 + 分位數截斷 評估: ? 合適 改進建議:
結合收入水平設定動態上限(如不超過年收入的10倍)
考慮貸款類型的影響(不同類型貸款金額范圍不同)
使用99.5%分位數截斷,保留合理的大額貸款
5. loan_int_rate(貸款利率)
當前方法: 設定合理范圍 + 分位數截斷 評估: ? 合適,需要結合市場情況 改進建議:
根據數據收集時間設定歷史合理范圍(如2%-30%)
考慮利率與風險等級的關系,異常高利率可能有業務含義
可以標記而非直接截斷極端利率
6. loan_percent_income(貸款占收入比例)
當前方法: 設定0%-100%范圍 評估: ?? 需要修正 改進建議:
關鍵問題:貸款占收入比例可能合理超過100%(如購房貸款)
建議設定0%-500%的范圍,或使用99%分位數截斷
重點關注0值的處理(可能表示高收入或數據錯誤)
7. cb_person_cred_hist_length(信用歷史長度)
當前方法: 保持原狀 評估: ? 合適 改進建議:
檢查是否存在負值或超過年齡的情況
建議最大值不超過(年齡-18)歲
?
2. 特征分析與可視化
prompt 9:
請針對借款人特征進行單變量分析:
年齡分布及其與貸款批準的關系
收入水平分布(包括年收入、月收入等相關指標)
工作年限分布及穩定性分析
房屋擁有情況分析
其他重要特征的分布情況

prompt 10:
請做雙變量分析
各特征與貸款批準結果的相關性分析
收入與年齡的交互效應分析
工作年限與收入的關系
房屋擁有情況對批準率的影響
使用相關性熱力圖展示特征間關系
?
prompt 11:
現在引入test數據集,請查看兩個數據集的基本信息(形狀、特征、數據類型) 檢查train和test的特征一致性,確認test集是否包含目標變量
?prompt 12:

prompt 12:
基于您的情況,下一步的關鍵任務是解決特征一致性問題。這是一個嚴重的數據預處理問題,必須立即解決。
🚨 當前問題分析
核心問題: Train集有19列,Test集只有12列,說明:Train數據已經進行了特征工程(衍生了7個新特征)
Test數據還是原始狀態
兩個數據集無法直接用于建模請立即執行下面的步驟
步驟1:診斷特征差異
首先明確哪些是原始特征,哪些是衍生特征:
步驟2:重新統一處理
關鍵決策: 需要重新對兩個數據集進行同步的特征工程
有兩種選擇:
選擇A(推薦): 重新加載原始train數據,與test數據一起處理
選擇B: 基于現有train數據,反向工程出test數據的特征
步驟3:創建統一處理流程
確保所有特征工程步驟在兩個數據集上完全相同地執行
??重要提醒
絕對不能做的事:不能刪除train中的衍生特征來"匹配"test
不能單獨為test創建不同的特征工程邏輯
不能忽略這個問題直接建模必須做的事:
確保特征工程的完全一致性
驗證處理后兩個數據集的特征匹配
檢查數據分布的一致性請先執行特征對比分析,然后我們根據具體的特征差異來制定詳細的修復方案。這一步完成后,才能繼續進行EDA和建模工作。
?
?prompt 13:
請驗證數據分布的一致性

prompt 14:
請繼續對train數據進行多變量分析
不同特征組合對貸款批準的綜合影響
識別高風險和低風險借款人群體
分析特征交互作用

3. 風險評估分析?
prompt 15:
現在進行風險評估分析,請重點分析以下風險因素:
識別導致貸款拒絕的主要因素
分析不同收入水平的批準率差異
評估年齡對貸款批準的影響模式
工作穩定性(工作年限)的風險指示作用
資產狀況(房屋擁有)的風險緩解效果

4. 機器學習建模
?prompt 16:
為了構建貸款批準預測模型,請先進行數據預處理
處理缺失值(填充策略選擇和justification)
特征編碼(分類變量處理)
特征標準化/歸一化
特征選擇和工程

prompt 17:
請進行特征選擇和工程
?
prompt 18:
現在進行模型開發,數據集劃分train集和test集
請嘗試以下算法:邏輯回歸(baseline模型)
隨機森林
梯度提升樹(如XGBoost、LightGBM)
支持向量機
神經網絡

prompt 19:
嘗試使用XGBoost模型

prompt 20:
繼續使用LightGBM模型
prompt 21:
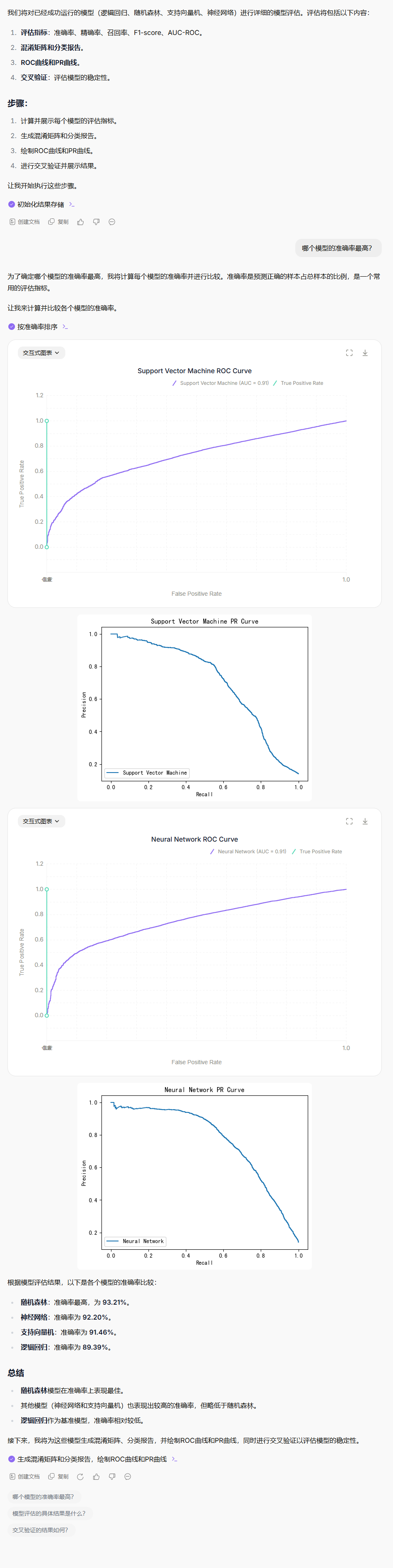
在現有的模型中,請進行模型評估,
使用適當的評估指標(準確率、精確率、召回率、F1-score、AUC-ROC)
生成混淆矩陣和分類報告
繪制ROC曲線和PR曲線
交叉驗證評估模型穩定性
 ?
?
 ?
?
prompt 22:
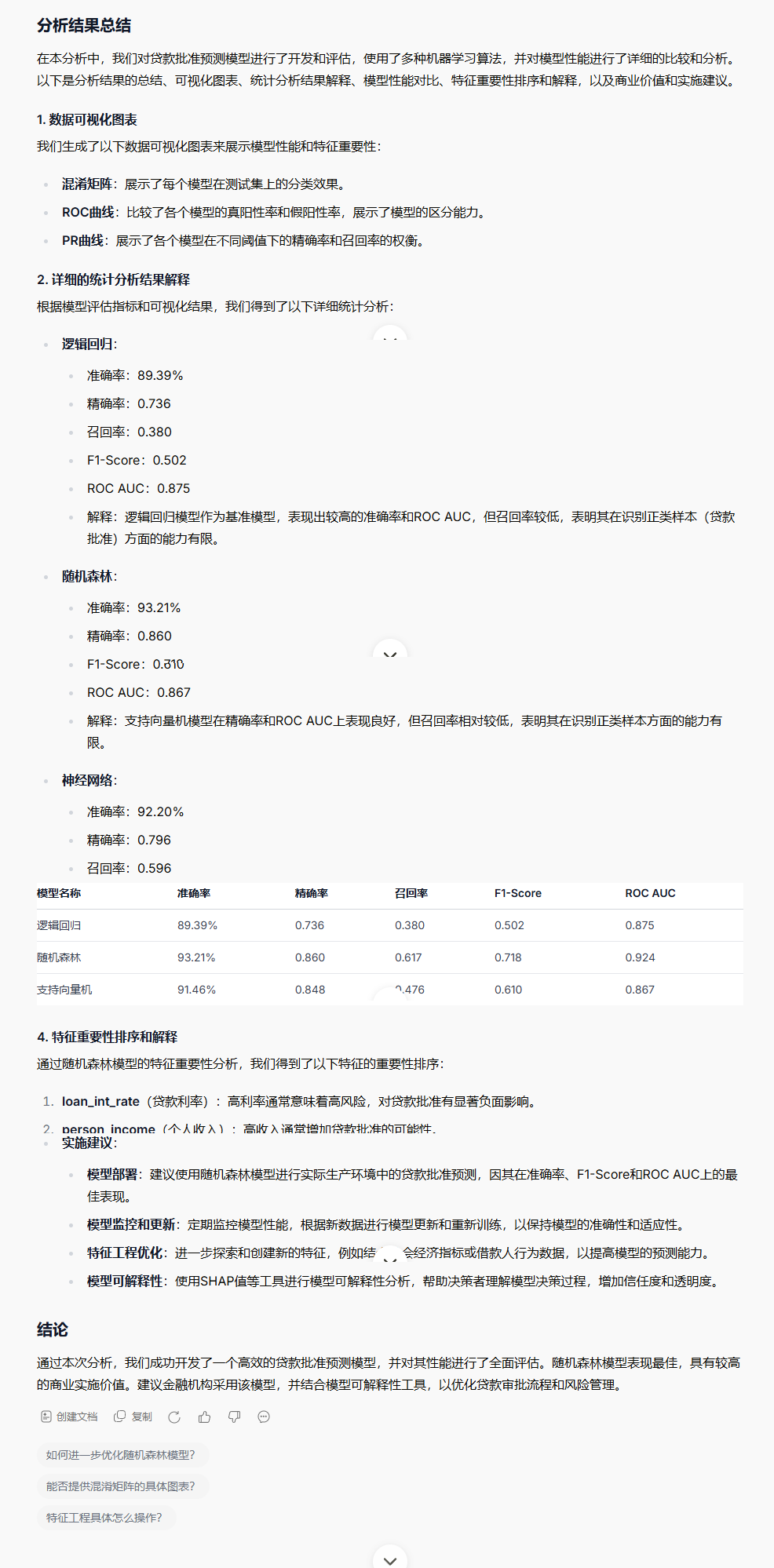
請總結上面的分析結果,
請做結果展示并確保分析結果包含:清晰的數據可視化圖表(使用seaborn/matplotlib)
詳細的統計分析結果解釋
模型性能對比表格
特征重要性排序和解釋
商業價值和實施建議
?







和WordPiece 是什么)



、提示詞模板(PromptTemplate))


:AER內核處理流程梳理)




:BERT實戰-基于Pytorch Lightning的文本分類模型)