在深度學習中,參數(Parameters) 和 超參數(Hyperparameters) 是模型訓練中兩個核心概念,它們共同決定了模型的性能,但作用方式和優化方法截然不同。以下是詳細對比與解析:
1. 參數(Parameters) (1) 定義 參數是模型通過訓練數據自動學習得到的變量 ,直接參與前向傳播和反向傳播的計算。例如:權重(Weights)、偏置(Biases)。 (2) 特點 數據驅動 :通過梯度下降等優化算法從數據中學習。數量龐大 :深層網絡可能有數百萬到數十億個參數。存儲于模型中 :訓練后保存為模型的一部分(如.pt或.h5文件)。(3) 常見示例 參數類型 作用 示例 權重矩陣(Weights) 連接神經元,決定特征變換 全連接層的 (W^{[l]}) 偏置(Biases) 調整神經元的激活閾值 卷積層的 (b^{[l]}) 嵌入向量(Embeddings) 將離散特征映射為連續空間 詞嵌入矩陣
(4) 優化方式 反向傳播 :通過損失函數的梯度更新參數:2. 超參數(Hyperparameters) (1) 定義 超參數是訓練前人為設定的配置選項 ,控制模型的結構和訓練過程。例如:學習率、網絡層數、批量大小。 (2) 特點 人工設定 :無法通過訓練數據直接學習(但可通過自動調優技術優化)。影響全局 :決定模型的容量、訓練速度和最終性能。需實驗調優 :通常通過網格搜索、隨機搜索或貝葉斯優化確定。(3) 常見示例 超參數類型 作用 典型取值范圍 學習率(Learning Rate) 控制參數更新步長 (10^{-5}) 到 (10^{-1}) 批量大小(Batch Size) 單次訓練樣本數 32、64、128、256 網絡層數(Layers) 決定模型深度 如ResNet-18/50/101 隱藏層維度(Hidden Units) 每層神經元數量 64、128、256、512 正則化系數(λ) 控制L2正則化強度 (10^{-4}) 到 (10^{-2}) Dropout率(p) 隨機丟棄神經元的概率 0.2~0.5
(4) 優化方法 手動調參 :基于經驗或文獻推薦值。自動化調參 :
網格搜索(Grid Search):遍歷所有組合。 隨機搜索(Random Search):更高效。 貝葉斯優化(Bayesian Optimization):基于概率模型。 神經架構搜索(NAS):自動化設計網絡結構。 3. 參數 vs. 超參數對比 特性 參數(Parameters) 超參數(Hyperparameters) 是否可學習 ? 通過數據自動優化 ? 人工預設或外部調優 數量 通常極多(百萬級+) 較少(幾十個) 影響范圍 局部(單個神經元或層的變換) 全局(模型結構/訓練過程) 調整頻率 每次迭代更新 訓練前設定,偶爾調整 存儲位置 模型文件內 配置文件或代碼中
4. 關鍵注意事項 (1) 參數初始化 參數初始值(如He初始化)雖需人為設定,但屬于初始化策略 ,不是超參數(因其不參與訓練過程調控)。 (2) 動態超參數 部分超參數可動態調整(如學習率衰減、BatchNorm的動量),但仍歸類為超參數。 (3) 超參數敏感性 高敏感超參數 :學習率、網絡深度。低敏感超參數 :Dropout率(通常0.5附近均可接受)。(4) 自動化調參工具 工具推薦 :
Optuna Ray Tune Weights & Biases(W&B) 5. 代碼示例 (1) 參數查看(PyTorch) for name, param in model. named_parameters( ) : print ( f"Parameter: { name} , Shape: { param. shape} " )
(2) 超參數設置(訓練腳本)
hyperparams = { "learning_rate" : 1e - 3 , "batch_size" : 64 , "dropout_rate" : 0.5 , "hidden_units" : 128
}
model = MLP( hidden_units= hyperparams[ "hidden_units" ] , dropout= hyperparams[ "dropout_rate" ] )
optimizer = torch. optim. Adam( model. parameters( ) , lr= hyperparams[ "learning_rate" ] )
6. 總結 參數 :模型內部學得的變量,決定具體特征映射。超參數 :訓練前的配置,控制模型結構和優化過程。核心區別 :是否通過數據自動優化。最佳實踐 :
優先調優高敏感超參數(如學習率、網絡深度)。 使用自動化工具加速超參數搜索。 監控參數梯度(如出現NaN需調整超參數)。 理解二者的差異與協作方式,是高效訓練深度學習模型的基礎。
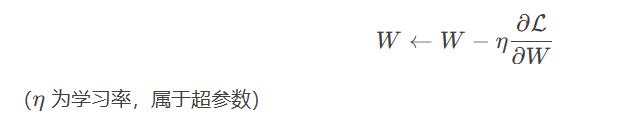

:AER內核處理流程梳理)




:BERT實戰-基于Pytorch Lightning的文本分類模型)

)



大規模語言模型淺析)






