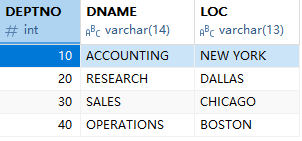
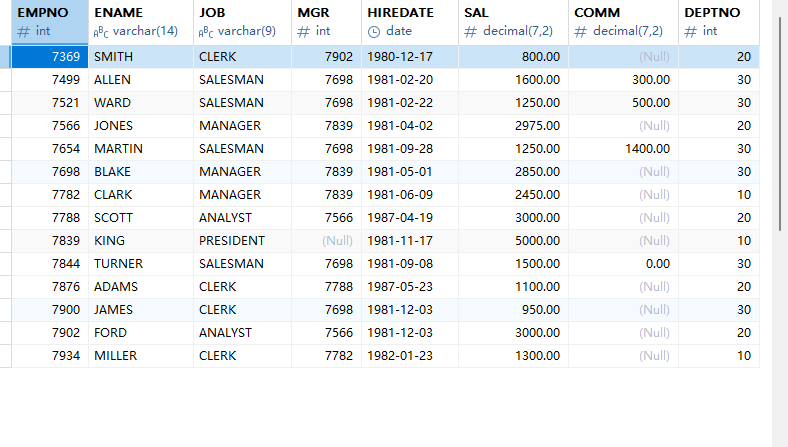
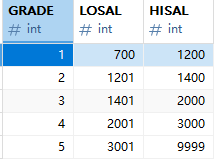
本節用到的員工信息管理表結構放到資源中,需要的同學自取。本節內容以此表為示例:
?
?
?
面試題:innodb與myisam的區別。
外鍵,事務
| 特性 | InnoDB | MyISAM |
|---|---|---|
| 事務支持 | 支持 | 不支持 |
| 外鍵 | 支持 | 不支持 |
| 鎖粒度 | 行級鎖 | 表級鎖 |
| 索引結構 | 聚簇索引 | 非聚簇索引 |
| 崩潰恢復 | 支持 | 不支持 |
| 空間效率 | 較高(但占用更多空間) | 較低(但更緊湊) |
| 寫性能 | 高(行級鎖) | 低(表級鎖) |
| 適用場景 | 事務、高并發寫 | 靜態數據、讀密集型 |
一、簡單查詢
語法:
select [?去重關鍵字distinct] 字段?from 表格名稱;
字段:*代表所有字段
select 字段? as "字段別名"... from 表格名稱;
as可以省略不寫,后面空格直接跟別名。
?查詢所有員工的編號,姓名,薪資
select empno"員工編號",ename"員工姓名",sal"員工薪資" from emp;二、限定查詢
語法:
select [?去重關鍵字distinct] 字段?from 表格名稱 [限定語法];
where >, < ,>= ,<= ,!=, between...and...,
查詢公司中工資高于2000的員工
select * from emp where sal > 2000;查詢公司中工資1000到3000的員工
select * from emp where sal between 1000 and 3000;
select * from emp where sal > 1000 and sal < 3000;查詢有獎金的員工信息
select * from emp where comm > 0查詢沒有獎金的員工信息
select * from emp where comm IS null or comm = 0查詢名稱中以S開頭 模糊匹配 %通配所有 _通配一位
select * from emp where ename like "s%" 以s開頭select * from emp where ename like "%s" 以s結尾select * from emp where ename like "%s%" 名稱中包含sselect * from emp where ename like "_o%" 第二位為o,其余無所謂查詢1981年入職的員工信息
select * from emp where HIREDATE BETWEEN '1981-01-01' and '1981-12-31'select * from emp where HIREDATE like '%1981%'查詢員工編號為7499,7521的員工信息
select * from emp where EMPNO = 7499 or EMPNO = 7521select * from emp where EMPNO in (7499,7521)三、排序查詢
語法:
select [?去重關鍵字distinct] 字段?from 表格名稱 [限定語法][排序條件];
排序關鍵字:order by
升序:asc
降序:desc
查詢員工信息,根據薪資做倒序排序
select * from emp order by asl desc;查詢員工信息,根據入職日期做降序排序,?日期一致則按薪資升序排序。
select * from emp order by hiredate desc ,sal asc;
四、多表查詢
語法:select [去重關鍵字DISTINCT] 字段 from 表格名稱 , 表格名稱 [限定語法][排序條件];
查詢所有員工信息,包含部門信息
select * from emp,dept以上查詢方式將兩張表進行簡單堆積,查詢中有無用的冗余數據,這種現象稱之為笛卡爾積效應
在查詢過程中,添加關聯條件,用來在顯示上消除笛卡爾積效應
select * from emp,dept where emp.deptno = dept.deptnoselect e.*,d.DNAME,d.loc from emp e,dept d where e.deptno = d.deptno查詢所有員工信息,包含員工編號、員工姓名、員工薪資、領導編號、領導姓名、領導薪資
確定需要的表格:emp e1,emp e2
確定需要的字段:e1.empno '員工編號',e1.ename '員工姓名',e1.sal '員工薪資',e2.empno '領導編號',e2.ename '領導姓名',e2.sal '領導薪資'
確定需要的關聯條件:e1.mgr = e2.empno
組裝sql:
?SELECT e1.empno '員工編號', e1.ename '員工姓名', e1.sal '員工薪資', e2.empno '領導編號', e2.ename '領導姓名', e2.sal '領導薪資' FROM emp e1, emp e2 WHERE e1.mgr = e2.empno;
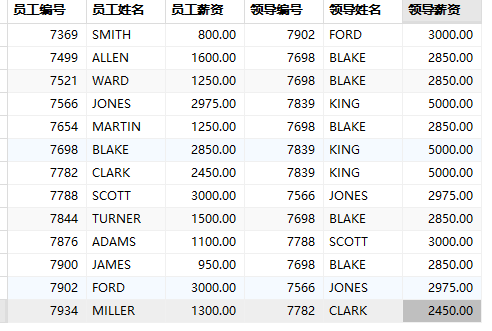
以上sql查詢完之后,顯示13條結果,KING這條數據沒有顯示(邊界值無法查詢),如果向解決邊界值問題,需要使用連接查詢
五、連接查詢
語法:
select [去重關鍵字DISTINCT] 字段 from 表格名稱 [連接條件] 表格名稱 [限定語法][排序條件];
左(外)連接:left(outer) join ...on...
右(外)連接:right(outer) join ...on...
以哪個表為重點就哪邊連接;
?查詢所有員工信息,包含員工編號、員工姓名、員工薪資、領導編號、領導姓名、領導薪資
SELECT e1.empno AS '員工編號',e1.ename AS '員工姓名',e1.sal AS '員工薪資',e2.empno AS '領導編號',e2.ename AS '領導姓名',e2.sal AS '領導薪資'
FROM emp e1
LEFT JOIN emp e2 ON e1.mgr = e2.empno;?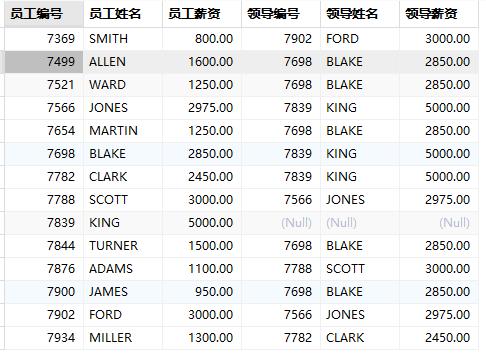
拓展語法:SQL1999語法
交叉連接:select * from emp join dept; 類似于“,”進行笛卡爾積, 查詢顯示56條結果
自然連接:select * from emp natural join dept; 自動組合共同字段,查詢顯示14條結果
join...on+條件:select * from emp join dept on emp.deptno = dept.deptno; 查詢顯示14條結果
join...using(兩邊表的共同字段):select * from emp join dept using(deptno); 查詢顯示14條結果
六、分組查詢
分組前提:需要分組的字段有重復值
語法:
select [去重關鍵字DISTINCT] 字段 from 表格名稱 [限定語法][分組條件][排序條件];
分組關鍵字:group by注意事項:
1.一旦出現分組條件,那么select后邊只允許出現統計函數和分組字段
2.分組之后如果還想使用限定條件篩選,那么不允許使用where,需要使用having
?查詢每一個部門的平均工資
確定需要的表:emp
確定需要的字段:avg(sal)
確定需要的分組條件:group by deptno
組裝sql:select avg(sal) from emp group by deptno優化sql:select deptno,avg(sal) from emp group by deptno
發現上述sql中沒有40部門(邊界值)
確定需要的表:emp e,dept d
確定需要的字段:d.deptno,avg(sal)
確定需要的分組條件:group by d.deptno
組裝sql:SELECT d.deptno, IFNULL(AVG(sal), 0) '平均工資' FROM emp e RIGHT JOIN dept d ON e.deptno = d.deptno GROUP BY d.deptno;
查詢部門的平均薪資,要求顯示平均薪資高于2000的信息
SELECT d.deptno, IFNULL(AVG(e.sal), 0) AS '平均工資'
FROM dept d
LEFT JOIN emp e ON d.deptno = e.deptno
GROUP BY d.deptno
HAVING IFNULL(AVG(e.sal), 0) > 2000; -- 確保在過濾時處理 NULL 值AVG(sal) > 2000七、統計查詢
平均avg? ?最大值max? ?最小值min? ?統計數量 count? ?求和 sum
拓展技術:
單行函數參考單行函數文檔。
八、子查詢
where 子查詢
當查詢的結果為單行單列或多行單列的時候
查詢比smith工資高的所有員工信息。
SELECT *
FROM emp
WHERE sal > (SELECT sal FROM emp WHERE ename = 'SMITH');?查詢公司中和經理一樣工資的員工信息
SELECT *
FROM emp
WHERE sal in (SELECT sal FROM emp WHERE job = 'manager')
?小貼士:
=ang? ? ? ? 等同于? ? ? ?in
<ang? ? ? ? 等同于? ? ? ? 比最大值小的數據
>ang? ? ? ? 等同于? ? ? ? 比最小值大的數據
<all? ? ? ? 等同于? ? ? ? 比最小值小的數據
>all? ? ? ? 等同于? ? ? ? 比最大值大的數據
?from 子查詢
當查詢的結果為多行多列
查詢部門編號、部門名稱、部門位置、部門人數、部門平均薪資
第一步:查詢部門單表信息(4條結果)
select * from dept第二步:查詢員工表,得到部門人數、部門平均(3條結果)
確定需要的表格:emp e 確定需要的字段:e.deptno deptno,count(e.empno) num,avg(e.sal) sal 確定需要的分組條件:group by e.deptno 組裝sql: select e.deptno deptno,count(e.empno) num,avg(e.sal) sal from emp e group by e.deptno
第三步:將上述sql進行左右連接查詢
確定需要的表格: dept d, (select e.deptno deptno,count(e.empno) num,avg(e.sal) sal from emp e group by e.deptno) temp 確定需要的字段:d.deptno,d.dname,d.loc,temp.num,temp.sal 確定需要的關聯條件:d.deptno = temp.deptno ? 組裝sql:SELECT d.deptno,d.dname,d.loc,temp.num,temp.sal FROM dept d LEFT JOIN (SELECT e.deptno AS deptno,COUNT(e.empno) AS num,AVG(e.sal) AS salFROM emp eGROUP BY e.deptno) temp ON d.deptno = temp.deptno;
九、分頁查詢
為什么需要分頁查詢?
語法:select [去重關鍵字DISTINCT] 字段 from 表格名稱 [限定語法][分組條件][排序條件][分頁條件]
分頁:limit n,m
n:數據索引,從0開始
m:每一頁顯示多少條
查詢第一頁員工數據,一頁顯示10條
select * from emp limit 0,10;
當n為0的時候,可以省略不寫:select * from emp limit 10;
第二頁:
select * from emp limit 10,10;
?事務
? 數據庫事務( transaction)是訪問并可能操作各種數據項的一個數據庫操作序列,這些操作要么全部執行,要么全部不執行,是一個不可分割的工作單位。事務由事務開始與事務結束之間執行的全部數據庫操作組成。
事務的四大特性:
1、原子性(Atomicity):事務中的全部操作在數據庫中是不可分割的,要么全部完成,要么全部不執行。?
2、一致性(Consistency):幾個并行執行的事務,其執行結果必須與按某一順序 串行執行的結果相一致。?
3、隔離性(Isolation):事務的執行不受其他事務的干擾,事務執行的中間結果對其他事務必須是透明的。?
4、持久性(Durability):對于任意已提交事務,系統必須保證該事務對數據庫的改變不被丟失,即使數據庫出現故障。?
臟讀 幻讀
MySQL數據庫事務測試
mysql的事務是默認提交機制
事務提交機制有兩種:自動提交,手動提交
修改數據庫事務提交機制:
關閉自動提交:set autocommit = 0;開啟自動提交:set autocommit = 1;
如果關閉自動提交,那么在發生增刪改以后需要程序員提交(commit)或回滾(rollback)
? MySQL數據庫事務隔離級別
MySQL 提供了四種事務隔離級別,以確保數據的一致性和完整性。這四種隔離級別分別是:讀未提交(Read Uncommitted)、讀已提交(Read Committed)、可重復讀(Repeatable Read)和可串行化(Serializable)
讀未提交(Read Uncommitted):
????????定義:事務可以讀取其他未提交事務的更改。????????問題:可能導致臟讀(Dirty Read)
????????適用場景:對數據一致性要求不高的場景。
讀已提交(Read Committed):(oracle默認級別)????????定義:事務只能讀取其他已提交事務的更改。
????????問題:避免了臟讀,但可能導致不可重復讀(Non-repeatable Read)
????????適用場景:大多數數據庫系統的默認隔離級別,如oracle。
可重復讀(Repeatable Read):(MySQL默認級別)????????定義:在同一事務中多次讀取相同數據時,結果一致。
????????問題:避免了臟讀和不可重復讀,但可能導致幻讀(Phantompead)。
????????適用場景:MySQL 的默認隔離級別,適用于大部分應用。
可串行化(serializable):
????????定義:最高的隔離級別,事務按順序逐個執行,完全隔離。
????????問題:避免了臟讀、不可重復讀和幻讀,但并發性能最差。
????????適用場景:對數據一致性要求極高的場景。
臟讀(Dirty Read)?。
? ?定義?:讀取到其他事務未提交的修改數據,若該事務回滾則導致數據無效
? ?示例?:事務A修改賬戶余額后未提交,事務B讀取到該臨時值;若事務A回滾,事務B基于臟數據操作將引發錯誤不可重復讀(Non-repeatable Read)?
? ?定義?:同一事務內多次讀取同一數據,因其他事務已提交的修改導致結果不一致
? ?示例?:事務A第一次查詢余額為1000元,事務B修改為800元并提交后,事務A再次查詢結果變為800元幻讀(Phantom Read)?
? ?定義?:同一事務內兩次范圍查詢的結果行數不同,因其他事務插入或刪除數據
? ?示例?:事務A首次查詢年齡>30的用戶共10人,事務B新增1人后,事務A再次查詢結果為11人
隔離級別測試:
數據庫默認隔離級別查看:?
- 查看全局默認隔離級別(5.7版本之前):
SELECT @@global.tx_isolation; - 查看全局默認隔離級別(5.7版本之后):
SELECT @@global.transaction_isolation; - 查看當前會話隔離級別(5.7版本之前):
SELECT @@session.tx_isolation; - 查看當前會話隔離級別(5.7版本之后):
SELECT @@session.transaction_isolation;
第一步:修改數據庫隔離級別
SET [GLOBAL|SESSION} TRANSACTION ISOLATION LEVEL
[READ UNCOMMITTED|READ COMMITTED|REPEATABLE READ|SERIALIZABLE]
第二步:設置手動提交
set autocommit = 0;第三步:開啟事務
start transaction;第四步:測試業務
update t_person set sal = sal-500 where id = 1;update t_person set sal = sal+500 where id = 3;?索引、優化、b+tree后續再了解。
python連接數據庫
安裝模塊pymysql
第一步:導入模塊
import pymysql?第二步:創建連接
conn = pymysql.connect
(host='locohost', user='user', password='password', port=3306,database='database')第三步:創建數據庫對象
cursor = conn.cursor()?第四步:執行sql語句
sql = "select * from emp"#通過數據庫對象執行sql
cont = cursor.execute(sql)
#執行sql語句,返回查詢結果的行數。
result = cursor.fetchall()
#執行 execute() 后查詢的所有結果第五步:關閉連接
cursor.close()
conn.close()傳參問題
- 方式一:直接字符串拼接
把變量(如?username、password、id?)拼接到 SQL 語句里,有嚴重 SQL 注入風險?,比如用戶輸入惡意內容可篡改查詢邏輯。
示例:sql = "select * from t_user where username = '" +username+ "' and password = '" +password+ "'" - 方式二:簡單格式化拼接(仍有風險)
用?%?做占位符拼接參數,看似規范但本質還是字符串拼接,仍可能被 SQL 注入?(如輸入?lufei' or 1=1 --?可繞過校驗 )sql = "select * from t_user where username = '%s' and password = '%s'"%(username,password) - 方式三:參數化查詢(推薦)
用?%s?做占位符,但實際執行時由數據庫驅動自動處理參數轉義,可有效避免 SQL 注入?,是安全的傳參方式sql = "select * from t_user where username = %(name)s and password = %(pwd)s" cursor.execute(sql, {"name": username, "pwd": password})








——requests庫)

)








