文章目錄
- 前言
- 爬取初嘗試與亂碼問題
- 編碼知識科普
- UTF - 8
- GBK
- Unicode
- Python中的編碼轉換
- 其他編碼補充知識
- GBK
- GB18030
- GB2312
- UTF(UCS Transfer Format)
- Unicode
- 總結

前言
在Python爬蟲的過程中,我嘗試爬取一本小說,遇到GBK亂碼問題,以下是我的解決辦法。
爬取初嘗試與亂碼問題
爬取的過程我采用了常見的套路,先獲取網頁源代碼,以下是我最初的代碼:
# -*- coding:UTF-8 -*-
from bs4 import BeautifulSoup
import requestsif __name__ == '__main__':url='https://www.biquge186.com/shu/4192/89510154.html'page_req=requests.get(url)html=page_req.textbf=BeautifulSoup( html)texts = bf.find_all('div',id='content')print(texts[0].text.replace('\xa0'*8,'\n\n'))
然而,運行代碼后,結果卻出現了亂碼。我在瀏覽器中查看網頁代碼,發現該網頁采用的是GBK編碼,而我爬取的內容需要進行轉碼處理。出現亂碼的原因是爬取的所有網頁無論何種編碼格式,都轉化為UTF - 8格式進行存儲,與源代碼編碼格式不同。
編碼知識科普
UTF - 8
UTF - 8通用性比較好,是用以解決國際上字符的一種多字節編碼。它對英文使用8位(即一個字節),中文使用24位(三個字節)來編碼。UTF - 8編碼的文字可以在各國各種支持UTF8字符集的瀏覽器上顯示,也就是說,網頁和瀏覽器的編碼都得是UTF - 8才行。
GBK
GBK是國家編碼,通用性比UTF - 8差,GB2312之類的都算是GBK編碼。GBK包含全部中文字符,而UTF - 8則包含全世界所有國家需要用到的字符。
Unicode
Unicode是一種二進制編碼,所有UTF - 8和GBK編碼都得通過Unicode編碼進行轉譯,即UTF - 8和GBK編碼之間不能直接轉換。
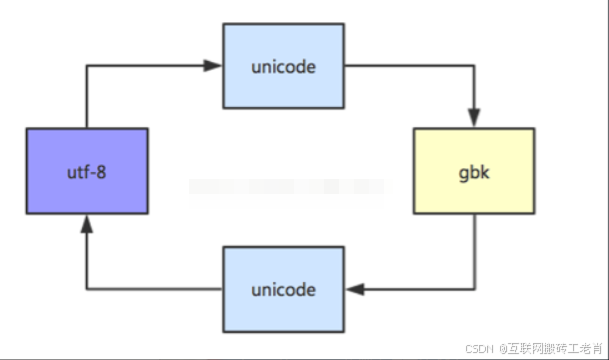
Python中的編碼轉換
在Python中,編碼轉換用到了兩個函數decode()和encode()。例如:html=page_req.text.encode('iso - 8859 - 1').decode('utf - 8') ,其中encode('iso - 8859 - 1') 是將GBK編碼編碼成Unicode編碼,decode('gbk') 是從Unicode編碼解碼成GBK字符串。
由于PyCharm只能顯示來自Unicode的漢字,我對代碼進行了修改:
# -*- coding:UTF-8 -*-
from bs4 import BeautifulSoup
import requestsif __name__ == '__main__':url='http://www.biquge.com.tw/18_18998/8750558.html'page_req=requests.get(url)html=page_req.text.encode('iso - 8859 - 1')bf=BeautifulSoup( html)texts = bf.find_all('div',id='content')print(texts[0].text.replace('\xa0'*8,'\n\n'))
修改代碼后,亂碼問題得到了解決。
其他編碼補充知識
GBK
簡單而言,GBK是對GB2312的進一步擴展(K是漢語拼音kuo zhan(擴展)中“擴”字的聲母),收錄了21886個漢字和符號,完全兼容GB2312。
GB18030
GB18030收錄了70244個漢字和字符,更加全面,與GB 2312 - 1980和GBK兼容。GB18030支持少數民族的漢字,也包含了繁體漢字和日韓漢字,其編碼是單、雙、四字節變長編碼的。
GB2312
當國人得到計算機后,就要對漢字進行編碼。在ASCII碼表的基礎上,小于127的字符意義與原來相同;而將兩個大于127的字節連在一起,來表示漢字,前一個字節從0xA1(161)到0xF7(247)共87個字節,稱為高字節,后一個字節從0xA1(161)到0xFE(254)共94個字節,稱為低字節,兩者可組合出約8000種組合,用來表示6763個簡體漢字、數學符號、羅馬字母、日文字等。在重新編碼的數字、標點、字母是兩字節長的編碼,這些稱為“全角”字符;而原來在ASCII碼表的127以下的稱為“半角”字符。簡單而言,GB2312就是在ASCII基礎上的簡體漢字擴展。
UTF(UCS Transfer Format)
UTF是在互聯網上使用最廣的一種Unicode的實現方式。我們最常用的是UTF - 8,表示每次8個位傳輸數據,除此之外還有UTF - 16。UTF - 8編碼的“你好中國!hello,123”長這樣:你好中国!hello,123
Unicode
準確來說,Unicode不是編碼格式,而是字符集。這個字符集包含了世界上目前所有的符號。另外,在原來有些字符可以用一個字節即8位來表示的,在Unicode中將所有字符的長度全部統一為16位,因此字符是定長的。例如\u4f60\u597d\u4e2d\u56fd\uff01\u0068\u0065\u006c\u006c\u006f\uff0c\u0031\u0032\u0033 表示的就是“你好中國!hello,123”。
總結
通過這次爬取數據的經歷,我對Python爬蟲中的編碼問題有了更深入的理解,也掌握了如何解決GBK編碼網頁爬取時的亂碼問題,這里留筆記記錄一下。







——支持向量機)











![[特殊字符] MySQL MCP 開發實戰:打造智能數據庫操作助手](http://pic.xiahunao.cn/[特殊字符] MySQL MCP 開發實戰:打造智能數據庫操作助手)
