本文目錄
- 一、引言
- 二、Web Unlocker API 功能亮點
- 三、Web Unlocker API 實戰
- 1.配置網頁解鎖器
- 2.定位相關數據
- 3.編寫代碼
- 四、Web Scraper API
- 技術亮點
- 五、SERP API
- 技術亮點
- 六、總結
一、引言
網頁數據宛如一座蘊藏著無限價值的寶庫,無論是企業洞察市場動態、制定戰略決策,還是個人挖掘信息、滿足求知需求,網頁數據都扮演著舉足輕重的角色。然而,這座寶庫常被一道道無形的封鎖之門所阻攔,反機器人檢測機制、驗證碼驗證、IP限制等重重障礙,讓數據獲取之路困難重重。
但是,亮數據的 Web Unlocker API 宛如一把閃耀的“金鑰匙”,橫空出世。它憑借先進的技術,突破層層阻礙,致力于讓網頁數據真正“觸手可及”,可以為企業開啟通往數據寶藏的康莊大道,輕松解鎖海量有價值的信息。
二、Web Unlocker API 功能亮點
網頁解鎖器API,即Web Unlocker API,是亮數據一款強大的三合一網站解鎖和抓取解決方案,專為攻克那些最難訪問的網站而設計,實現自動化抓取數據。主要有三大亮點,分別如下:
網站解鎖方面,基于先進的AI技術,能實時主動監測并破解各類網站封鎖手段。運用瀏覽器指紋識別、驗證碼(CAPTCHA)破解、IP輪換、請求重試等自動化功能,模擬真實用戶行為,有效規避反機器人檢測,可以輕松訪問公開網頁。
自動化代理管理是第二大亮點。無需耗費大量IP資源或配置復雜的多層代理,Web Unlocker會自動針對請求挑選最佳代理網絡,全面管理基礎架構,借助動態住宅IP,保障訪問順暢成功獲取所需的重要網絡數據。
對于使用JavaScript的網站,它具備用于JavaScript渲染的內置瀏覽器。當檢測到此類網站時,能在后臺自動啟動內置瀏覽器進行渲染,完整顯示頁面上依賴JS的某些數據元素,無縫抓取準確的數據結果。此外,還支持使用自定義指紋和cookies ,進一步增強數據抓取的靈活性與隱蔽性,滿足多樣化的數據獲取需求。
三、Web Unlocker API 實戰
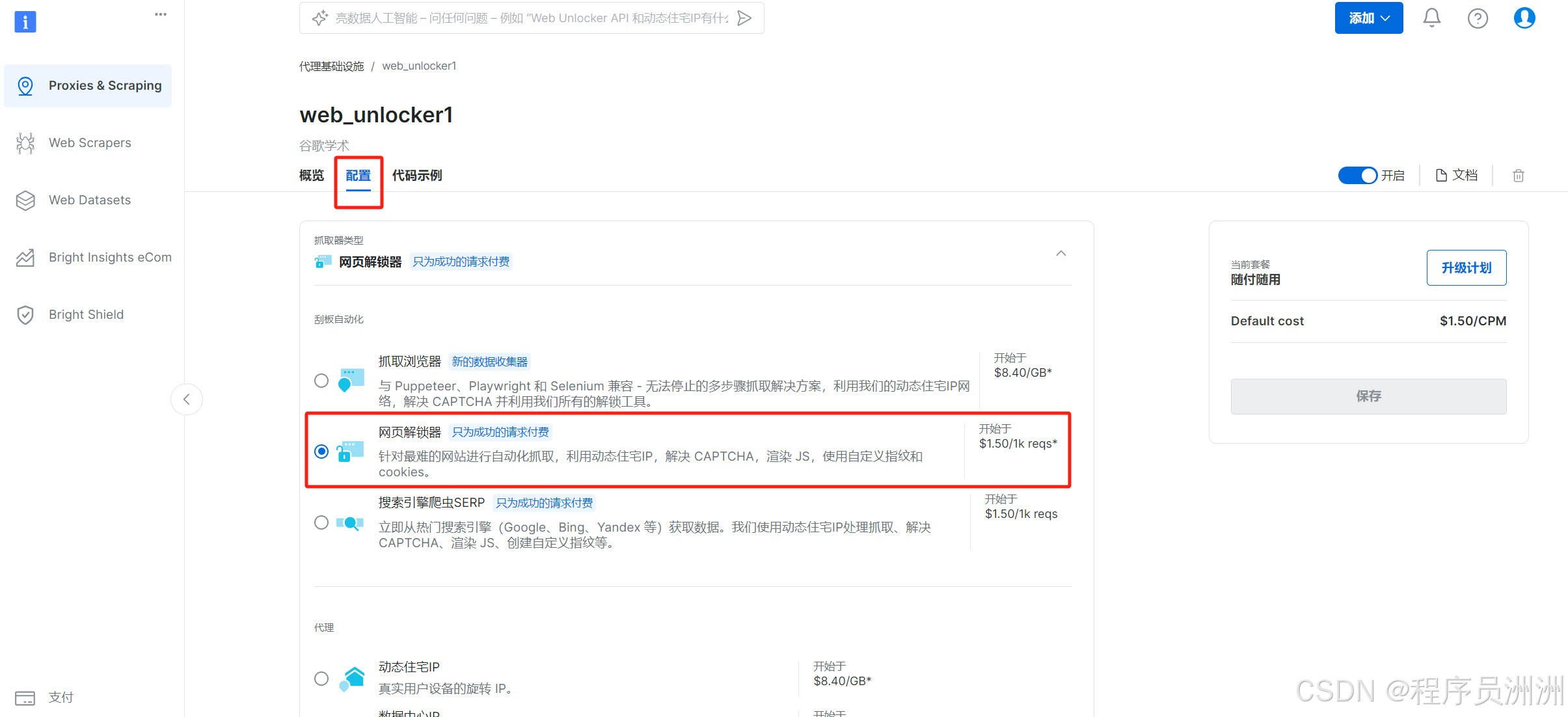
1.配置網頁解鎖器
首先在亮數據的功能頁面中,選擇“代理&抓取基礎設施”,然后選擇網頁解鎖器進行使用。
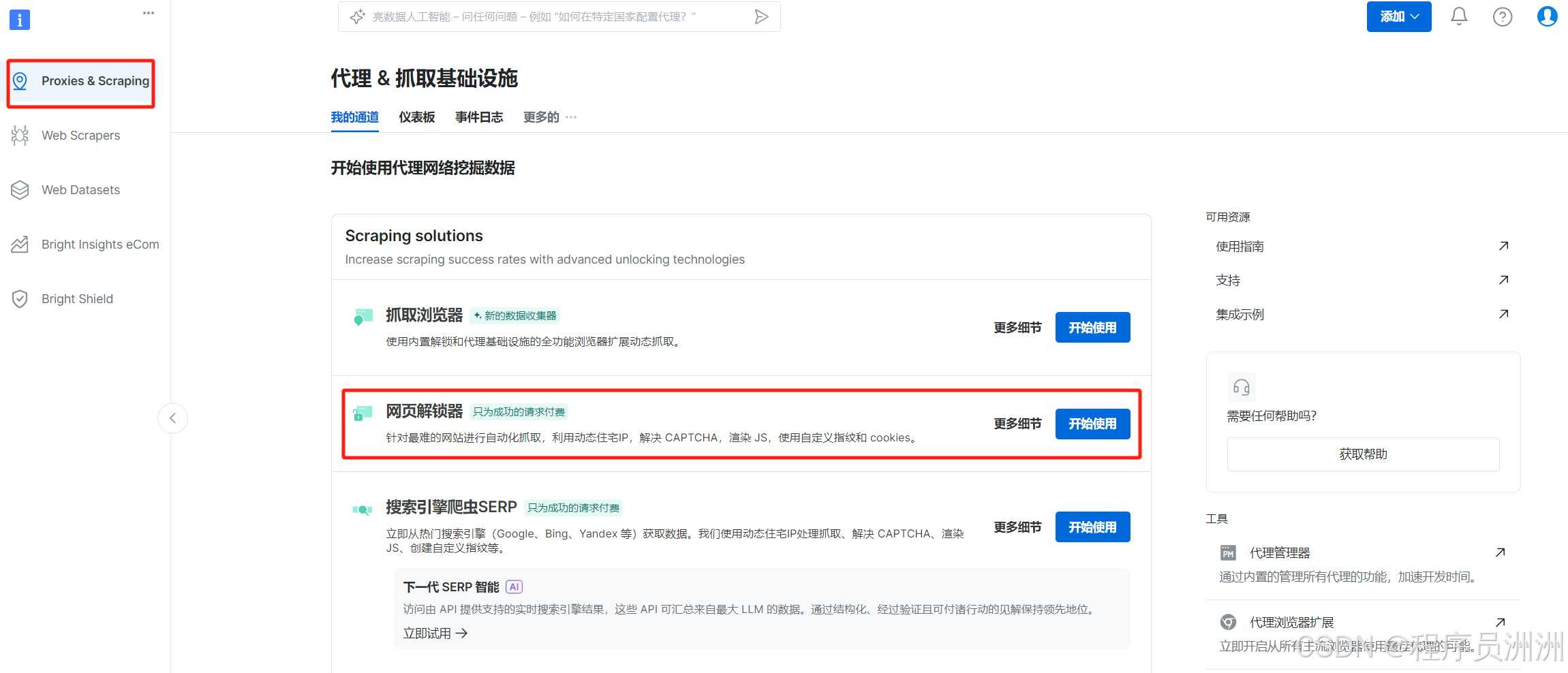
接下來操作基本設置,比如通道描述,方便我們后續進行分類管理。
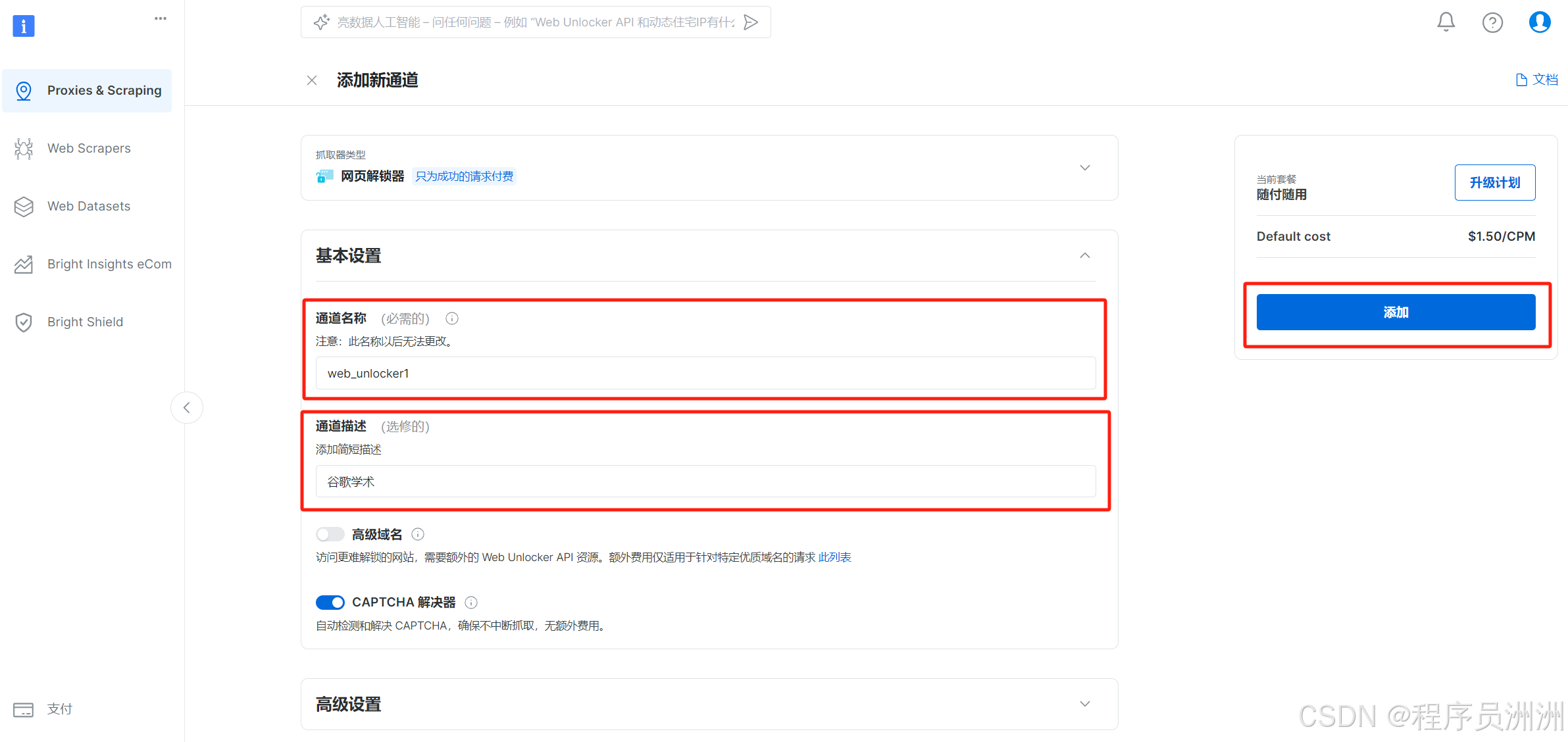
然后就會展示Web Unlocker1的詳細信息了,有API訪問信息、配置信息、代碼示例等。
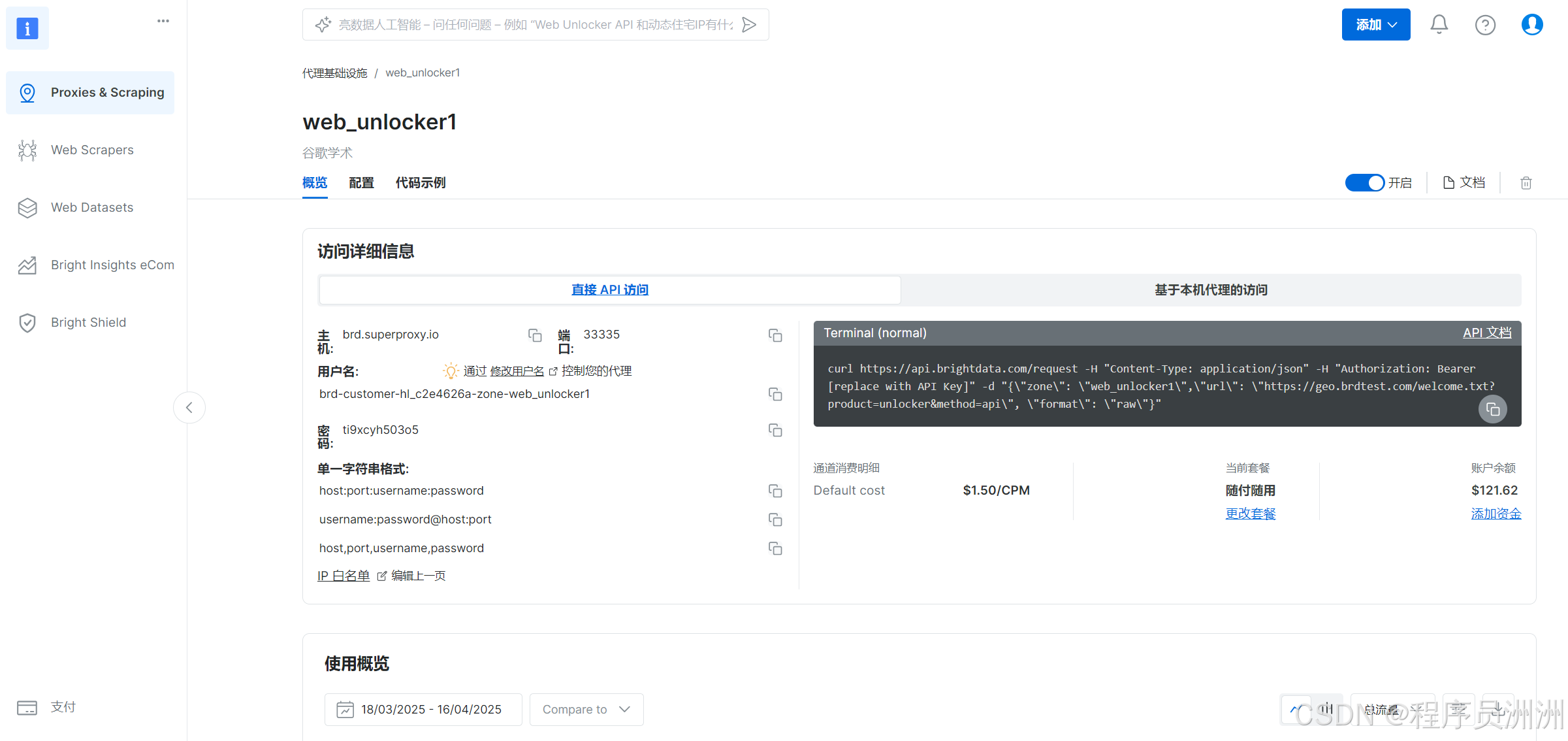
選擇“配置”,選中“網頁解鎖器”進行使用。
2.定位相關數據
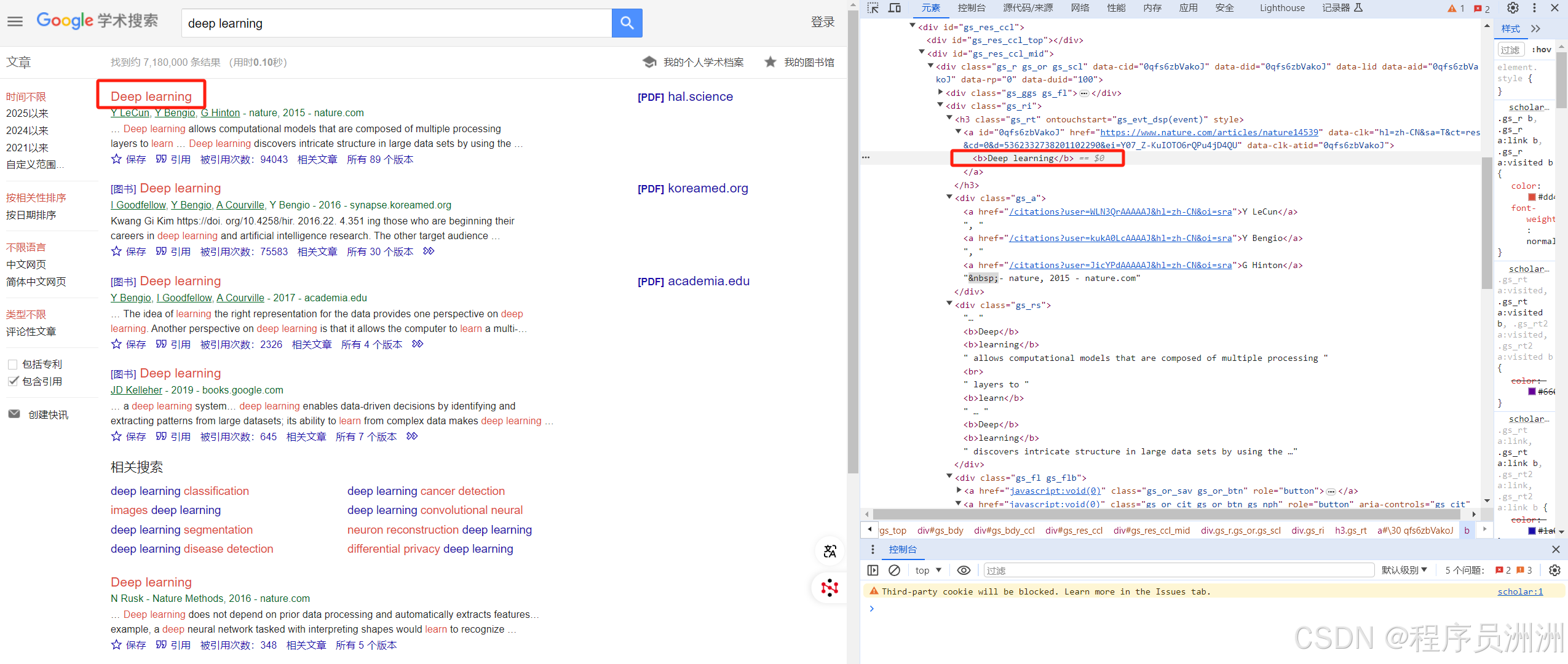
這里我們用谷歌學術作為案例,因為谷歌學術的各種防范機制手段等比較多,對IP也有一定限制,還有人機交互驗證登,現在我們通過python代碼來展示怎么使用對應的Web Unlocker API,首先進入到谷歌學術頁面,可以看到有很多論文信息,比如我們想獲取論文題目、引用次數、論文摘要等重要信息,就可以先定位到這些相關數據。
3.編寫代碼
首先,導入了必要的 Python 模塊,包括 requests 用于發送 HTTP 請求,BeautifulSoup 用于解析 HTML 內容,以及 warnings 用于處理警告信息。此外,還導入了 scholarly 模塊,這是一個專門用于爬取 Google Scholar 數據的庫。
然后配置 Bright Data亮數據的代理設置。通過定義 customer_id、zone_name 和 zone_password 來指定用戶的身份驗證信息,這些信息用于訪問 Bright Data 提供的代理服務。接著,代碼構建了一個代理 URL,并將其與 HTTP 和 HTTPS 協議關聯起來,存儲在 proxies 字典中。這樣,后續使用 requests 發送請求時,就可以通過這個代理服務器進行網絡訪問。
import requests
from bs4 import BeautifulSoup
import warnings
from scholarly import scholarly# 忽略SSL警告
warnings.filterwarnings('ignore', message='Unverified HTTPS request')# Bright Data的Web Unlocker API配置信息
customer_id = "brd-customer-hl_c2e4626a-zone-web_unlocker1"
zone_name = "web_unlocker1"
zone_password = "ti9xcyh503o5"# 代理設置
proxy_url = "brd.superproxy.io:33335"
proxy_auth = f"brd-customer-{customer_id}-zone-{zone_name}:{zone_password}"
proxies = {"http": f"http://{proxy_auth}@{proxy_url}","https": f"http://{proxy_auth}@{proxy_url}"
}
然后設置請求目標URL和請求頭,模擬真實請求行為。
# 目標Google Scholar的URL
target_url = "https://scholar.google.com/scholar?hl=zh-CN&as_sdt=0%2C5&q=deep+learning&oq=deep"# 模擬真實瀏覽器
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36","Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8","Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8","Accept-Encoding": "gzip, deflate, br","Referer": "https://scholar.google.com/"
}
接著就是通過亮數據向谷歌學術發送HTTP請求,獲取與“deep learning”深度學習相關的學術搜索結果,解析并打印前五個結果的標題、作者、摘要信息了。
# 使用代理發送請求
try:print("正在通過代理發送請求...")response = requests.get(target_url, proxies=proxies, headers=headers, verify=False)response.raise_for_status() # 檢查請求是否成功print(f"請求狀態碼: {response.status_code}")# 解析HTML內容soup = BeautifulSoup(response.text, "html.parser")# 使用scholarly庫獲取數據print("正在獲取Google Scholar數據...")search_query = scholarly.search_pubs('deep learning')# 檢索前5個結果for i in range(5):try:publication = next(search_query)title = publication['bib']['title']authors = ', '.join(publication['bib']['author'])abstract = publication['bib'].get('abstract', '沒有摘要可用')print(f"標題: {title}")print(f"作者: {authors}")print(f"摘要: {abstract}\n")except StopIteration:print("已獲取所有可用結果。")breakexcept Exception as e:print(f"獲取結果時出錯: {e}")except requests.exceptions.RequestException as e:print(f"請求失敗: {e}")
except Exception as e:print(f"解析失敗: {e}")
完整代碼如下:
import requests
from bs4 import BeautifulSoup
import warnings
from scholarly import scholarly# 忽略SSL警告
warnings.filterwarnings('ignore', message='Unverified HTTPS request')# 您的Bright Data憑證
customer_id = "brd-customer-hl_c2e4626a-zone-web_unlocker1"
zone_name = "web_unlocker1"
zone_password = "ti9xcyh503o5"# 代理設置
proxy_url = "brd.superproxy.io:33335"
proxy_auth = f"brd-customer-{customer_id}-zone-{zone_name}:{zone_password}"
proxies = {"http": f"http://{proxy_auth}@{proxy_url}","https": f"http://{proxy_auth}@{proxy_url}"
}# 目標Google Scholar的URL
target_url = "https://scholar.google.com/scholar?hl=zh-CN&as_sdt=0%2C5&q=deep+learning&oq=deep"# 模擬真實瀏覽器
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36","Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8","Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8","Accept-Encoding": "gzip, deflate, br","Referer": "https://scholar.google.com/"
}# 使用代理發送請求
try:print("正在通過代理發送請求...")response = requests.get(target_url, proxies=proxies, headers=headers, verify=False)response.raise_for_status() # 檢查請求是否成功print(f"請求狀態碼: {response.status_code}")# 解析HTML內容soup = BeautifulSoup(response.text, "html.parser")# 使用scholarly庫獲取數據print("正在獲取Google Scholar數據...")search_query = scholarly.search_pubs('deep learning')# 檢索前5個結果for i in range(5):try:publication = next(search_query)title = publication['bib']['title']authors = ', '.join(publication['bib']['author'])abstract = publication['bib'].get('abstract', '沒有摘要可用')print(f"標題: {title}")print(f"作者: {authors}")print(f"摘要: {abstract}\n")except StopIteration:print("已獲取所有可用結果。")breakexcept Exception as e:print(f"獲取結果時出錯: {e}")except requests.exceptions.RequestException as e:print(f"請求失敗: {e}")
except Exception as e:print(f"解析失敗: {e}")
可以看到結果如下:

四、Web Scraper API
網頁抓取 API (Web Scraper API)是亮數據一款強大的網頁數據提取工具,可通過專用端點,從 120 多個熱門域名提取最新的結構化網頁數據,且完全合規、符合道德規范。用戶無需開發和維護基礎設施,就能輕松提取大規模網頁數據,滿足各類數據需求。
技術亮點
- 高效數據處理:支持批量處理請求,單次最多可處理 5,000 個 URL ,還能進行無限制的并發抓取任務。同時具備數據發現功能,可檢測數據結構和模式,確保高效、有針對性地提取數據;數據解析功能則能將原始 HTML 高效轉換為結構化數據,簡化數據集成與分析流程,大幅提升數據處理效率。
- 靈活輸出與交付:能夠提供 JSON 或 CSV 等多種格式的結構化數據,還可通過 Webhook 或 API 交付,以 JSON、NDJSON 或 CSV、XLSX 文件獲取數據,方便用戶根據自身工作流程和需求進行選擇,量身定制數據處理流程。
- 穩定且可擴展:依托全球領先的代理基礎設施,保障無與倫比的穩定性,將故障降至最低,性能始終保持一致。同時具備出色的可擴展性,能輕松擴展抓取項目以滿足不斷增長的數據需求,在擴展規模的同時維持最佳性能,并且內置基礎設施和解封功能,無需用戶維護代理和解封設施,就能從任意地理位置輕松抓取數據,避免驗證碼和封鎖問題。

五、SERP API
SERP API 是亮數據一款用于輕松抓取搜索引擎結果頁面(SERP)數據的工具。能自動適應搜索引擎結構和算法的變化,從 Google、Bing、DuckDuckGo 等所有主流搜索引擎,像真實用戶一樣抓取大量數據 。提供 JSON 或 HTML 格式的結構化數據輸出,支持定制化搜索參數,助力用戶獲取精準的搜索結果數據。
技術亮點
- 自適應與精準抓取:可自動調整適應不斷變化的 SERP,結合各種定制化搜索參數,充分考慮搜索歷史、設備、位置等因素,如同真實用戶操作般精準抓取數據,避免因位置等原因被搜索引擎屏蔽 。
- 高效快速響應:數據輸出速度超快,能在短時間內以 JSON 或 HTML 格式快速、準確地輸出數據,滿足用戶對時效性的需求,即使在高峰時段也能高效處理大量抓取任務。
- 成本效益與易用性:采用成功后付款模式,僅在成功發送抓取請求后收費,節省運營成本。用戶無需操心維護,可專注于抓取所需數據,使用便捷。
六、總結
在數據驅動的當今時代,網頁數據無疑是一座亟待挖掘的富礦。亮數據的 Web Unlocker API、Web Scraper API 以及 SERP API,構成了一套全面且強大的數據獲取解決方案。
Web Unlocker API 憑借先進 AI 技術,巧妙突破網站封鎖,自動管理代理網絡,支持 JavaScript 渲染,為數據抓取掃除障礙,讓解鎖網站變得輕而易舉。Web Scraper API 則以高效的數據處理能力,支持批量與并發抓取,提供多種靈活的數據輸出格式,依托穩定且可擴展的基礎設施,實現從熱門域名的合規、精準數據提取。SERP API 更是能夠自動適應搜索引擎的頻繁變化,依據定制化參數精準抓取,快速輸出數據,以成功付費模式降低成本,使用便捷。
無論是企業期望通過海量數據進行深度市場分析、精準制定戰略,還是個人為學術研究、興趣探索收集資料,亮數據的這一系列 API
都能成為得力助手。它們打破數據獲取的重重壁壘,助力用戶輕松解鎖網頁數據的無限價值,開啟數據驅動發展的新征程。不要猶豫,立即嘗試亮數據的API產品(跳轉鏈接),讓數據獲取變得高效、智能、無阻礙。







和解碼器(Decoder))


框架學習)
,還有CAUSAL_LM,QUESTION_ANS)



——決策樹)

——PPO 算法在 RLHF 中的原理與實現詳解)
)
