????????????????????????????????????????????????????????圖1: DeepSpeed ZeRO++ 簡介?
大型 AI 模型正在改變數字世界。基于大型語言模型 (LLM)的 Turing-NLG、ChatGPT 和 GPT-4 等生成語言模型用途廣泛,能夠執行摘要、代碼生成和翻譯等任務。 同樣,DALL·E、Microsoft Designer 和 Bing Image Creator 等大型多模態生成模型可以生成藝術、建筑、視頻和其他數字資產,使內容創作者、建筑師和工程師能夠探索全新的創意生產力。
然而,訓練這些大型模型需要在數百甚至數千個 GPU 設備上使用大量內存和計算資源。 例如,訓練?Megatron-Turing NLG 530B模型需要使用超過 4,000 個 NVidia A100 GPU。 有效地利用這些資源需要一個復雜的優化系統,以將模型合理分配到各個設備的內存中,并有效地并行化這些設備上的計算。 同時,為了使深度學習社區能夠輕松進行大型模型訓練,這些優化必須易于使用。
DeepSpeed 的 ZeRO?優化系列為這些挑戰提供了強大的解決方案,并已廣泛用于大型深度學習模型例如TNLG-17B、Bloom-176B、MPT-7B、Jurrasic-1的訓練中 。盡管它具有變革性的能力 ,在一些關鍵場景中,ZeRO 會在 GPU 之間產生大量數據傳輸開銷,這降低了訓練效率。 這種情況特別發生在以下場景中:a) 全局batch size較小,而 GPU數量多,這導致每個 GPU 上batch size較小,需要頻繁通信;或者 b) 在低端集群上進行訓練,其中跨節點網絡帶寬有限,導致高通信延遲。在這些情況下,ZeRO 的訓練效率會受到限制。
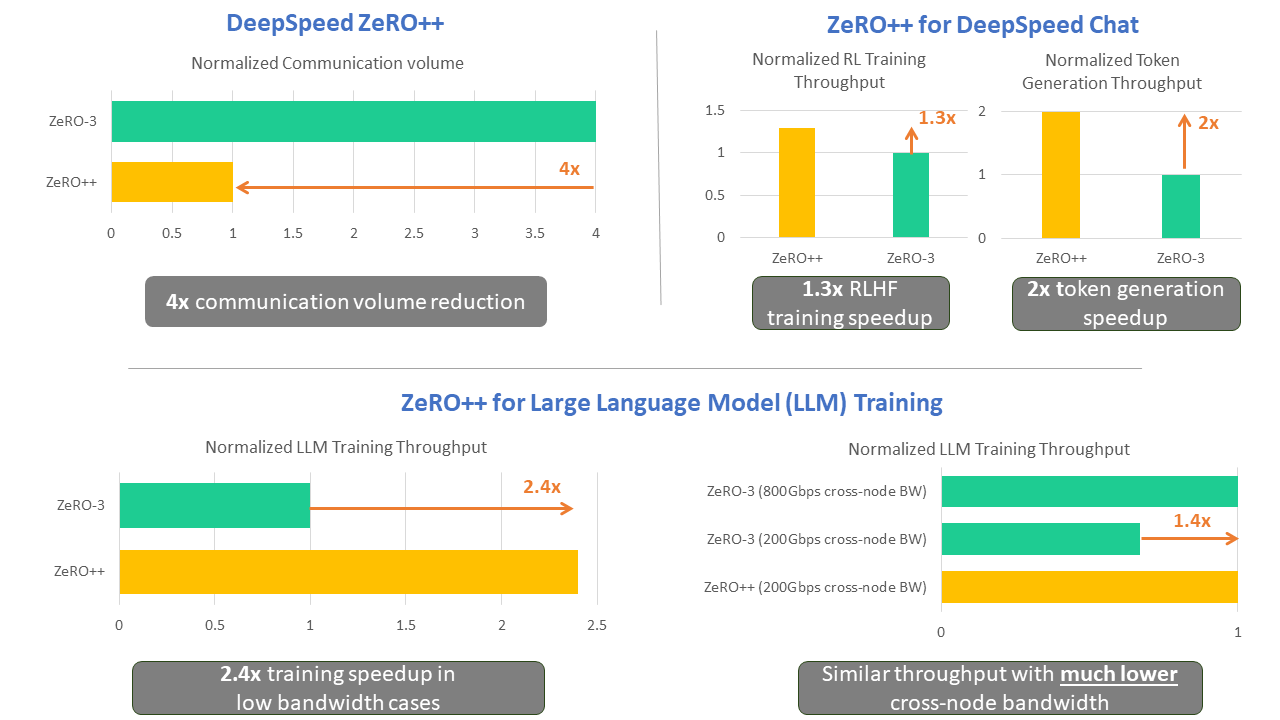
為了解決這些限制,我們發布了?ZeRO++?。 ZeRO++相比 ZeRO將總通信量減少了 4 倍,而不會影響模型質量。 這有兩個關鍵意義:
-
ZeRO++加速大型模型預訓練和微調
- 每個GPU上 batch size較小時: 無論是在數千個 GPU 上預訓練大型模型,還是在數百個甚至數十個 GPU 上對其進行微調,當每個 GPU 的batch size較小時,ZeRO++ 提供比 ZeRO 高 2.2 倍的吞吐量,直接減少訓練時間和成本。
- 低帶寬計算集群: ZeRO++ 使低帶寬集群能夠實現與帶寬高 4 倍的高端集群類似的吞吐量。 因此,ZeRO++ 可以跨更廣泛的集群進行高效的大型模型訓練。
-
ZeRO++加速 ChatGPT 類的 RLHF訓練
-
雖然 ZeRO++ 主要是為訓練而設計的,但它的優化也自動適用于?ZeRO-Inference,因為通信開銷對于 ZeRO 的訓練和推理同樣適用。 因此,ZeRO++ 可以提高人類反饋強化學習 (RLHF) 等算法的效率,因為RLHF結合了訓練和推理。
-
通過與 DeepSpeed-Chat 的集成,與原始 ZeRO 相比,ZeRO++ 可以將 RLHF 訓練的生成階段效率提高多達 2 倍,強化學習訓練階段效率提高多達 1.3 倍。
-
接下來,我們將更深入地解釋 ZeRO 及其通信開銷,并討論 ZeRO++ 中為解決這些問題而進行的關鍵優化。 然后我們將展示 ZeRO++ 對不同模型大小、批量大小和帶寬限制的訓練吞吐量的影響。我們還將討論 ZeRO++ 如何應用于 DeepSpeed-Chat,以加速使用 RLHF的對話模型的訓練。
ZeRO++詳解
https://github.com/deepspeedai/DeepSpeed/raw/master/blogs/zeropp/assets/images/zero-overview.gif
圖2: ZeRO optimizer 工作流程圖
ZeRO 是數據并行(Data Parallelism)的一種內存高效版本,其中模型狀態會被分割儲存在所有 GPU 上,而不需要在訓練期間使用基于gather/broadcas的通信進行復制和重建。這使 ZeRO 能夠有效地利用所有設備的聚合 GPU 內存和計算力,同時提供簡單易用的數據并行訓練。
假設模型大小為 M。在前向傳播過程中,ZeRO 執行全收集/廣播(all-gather/broadcast)操作以在需要之時為每個模型層收集參數(總共大小為 M)。 在向后傳遞中,ZeRO 對每一層的參數采用類似的通信模式來計算其局部梯度(總大小為 M)。 此外,ZeRO 在對每個局部梯度計算完畢后會立刻使用 reduce 或 reduce-scatter 通信進行平均和分割儲存(總大小為 M)。 因此,ZeRO 總共有 3M 的通信量,平均分布在兩個全收集/廣播(all-gather/broadcast)和一個減少分散/減少(reduce-scatter/reduce)操作中。
為了減少這些通信開銷,ZeRO++ 進行了三組通信優化,分別針對上述三個通信集合:\
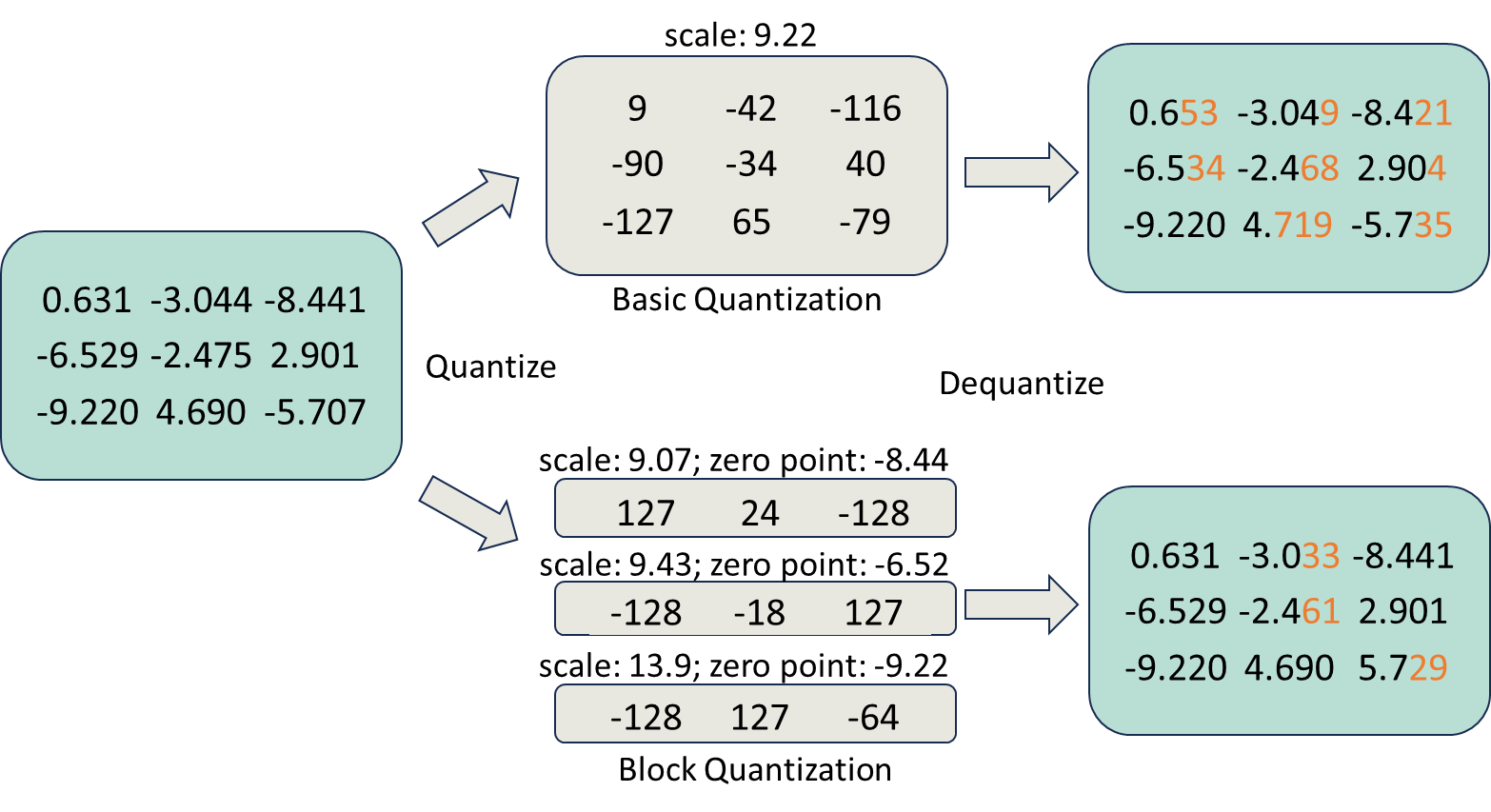
圖3:qwZ的分區量化圖例
ZeRO通信過程中的權重量化 (qwZ)
首先,為了減少 all-gather 期間的參數通信量,我們采用權重量化在通信前將每個模型參數從 FP16(兩個字節)動態縮小為 INT8(一個字節)數據類型,并在通信后對權重進行反量化。 然而,簡單地對權重進行量化會降低模型訓練的準確性。 為了保持良好的模型訓練精度,我們采用分區量化,即對模型參數的每個子集進行獨立量化。目前尚且沒有針對分區量化的高性能現有實現。 因此,我們自行從頭開始實現了一套高度優化的量化 CUDA 內核,與基本量化相比,精度提高 3 倍,速度提高 5 倍。
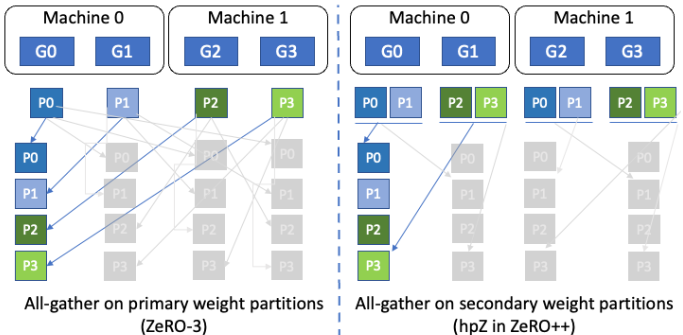
圖4: 權重的分層分割存儲(hpZ)
ZeRO模型權重的分層分割存儲 (hpZ)
其次,為了減少向后傳遞期間全收集(all-gather)權重的通信開銷,我們用 GPU 內存進行通信。 更具體地說,我們不像在 ZeRO 中那樣將整個模型權重分布在所有機器上,而是在每臺機器中維護一個完整的模型副本。 以更高的內存開銷為代價,這允許我們用機器內的模型權重全收集/廣播(all-gather/broadcast)代替昂貴的跨機器全收集/廣播(all-gather/broadcast),由于機器內通信帶寬更高,這使得通信速度大幅提升。

圖5: qgZ 端到端的工作流程
ZeRO通信過程中梯度量化 (qgZ)
第三,要降低梯度的reduce-scatter通信成本更具挑戰性。 因為直接應用量化來減少通信量是不可行的。 即使我們使用分區量化來降低量化誤差,梯度reduce也會累積并放大量化誤差。 為了解決這個問題,我們只在通信之前量化梯度,但在任何reduce操作之前將它們反量化到原有精度。 為了有效地做到這一點,我們發明了一種名為 qgZ 的基于 all-to-all 的新型量化梯度通信范式,它在功能上等同于壓縮的歸約-分散(reduce-scatter)操作。
qgZ 旨在解決兩個挑戰:i) 如果我們簡單地在 INT4/INT8 中實施 reduce-scatter 會導致顯著精度損失,以及 ii) 在傳統tree或ring-based reduce-scatter中使用量化需要一長串量化和反量化步驟,這直接導致誤差積累和顯著的延遲,即使我們在全精度上進行reduce。為了解決這兩個挑戰,qgZ 不使用tree或ring-based reduce-scatter算法,而是基于一種新穎的分層 all-to-all 方法。
qgZ 中有三個主要步驟:i)梯度切片重新排序,ii)節點內通信和reduce,以及 iii)節點間通信和reduce。 首先,在任何通信發生之前,我們對梯度進行切片并對張量切片重新排序,以保證通信結束時每個 GPU 上的最終梯度位置(即圖 5 中的綠色塊)是正確的。 其次,我們量化重新排序的梯度切片,在每個節點內進行 all-to-all 通信,從 all-to-all 中對接收到的梯度切片進行反量化,并進行局部reduce。 第三,我們再次量化局部reduce后的梯度,進行節點間的all-to-all通信,再次對接收到的梯度進行反量化,并計算最終的高精度梯度reduce,得到圖5中綠色塊的結果。
這種分層方法的原因是為了減少跨節點通信量。 更準確地說,給定每個節點 N 個 GPU、M 的模型大小和 Z 的量化比率,單跳 all-to-all 將生成 M*N/Z 跨節點流量。 相比之下,通過這種分層方法,我們將每個 GPU 的跨節點流量從 M/Z 減少到 M/(Z*N)。 因此,總通信量從 M*N/Z 減少到 M*N/(Z*N) = M/Z。 我們通過重疊節點內和節點間通信以及融合 CUDA 內核來進一步優化 qgZ 的端到端延遲(張量切片重新排序 (Tensor Slice Reordering)+ 節點內量化(Intra-node quantization))和(節點內反量化 (Intra-node Dequantization) + 節點內梯度整合 (Intra-node Reduction) + 節點間量化(inter-node quantization))。
| Communication Volume | Forward all-gather on weights | Backward all-gather on weights | Backward reduce-scatter on gradients | Total |
|---|---|---|---|---|
| ZeRO | M | M | M | 3M |
| ZeRO++ | 0.5M | 0 | 0.25M | 0.75M |
通信總量優化
通過結合以上所有三個組件,我們將跨節點通信量從 3M 減少到 0.75M。 更具體地說,我們使用 qwZ 將模型權重的前向全收集/廣播從 M 減少到 0.5M。 我們使用 hpZ 消除了反向傳播期間的跨節點 all-gather,將通信從 M 減少到 0。最后,我們使用 qgZ 將反向傳播期間的跨節點 reduce-scatter 通信從 M 減少到 0.25M。
ZeRO++ 加速大型語言模型訓練
在這里,我們展示了 ZeRO++ 在 384 個 Nvidia V100 GPU 上的真實 LLM 訓練場景的測試結果。
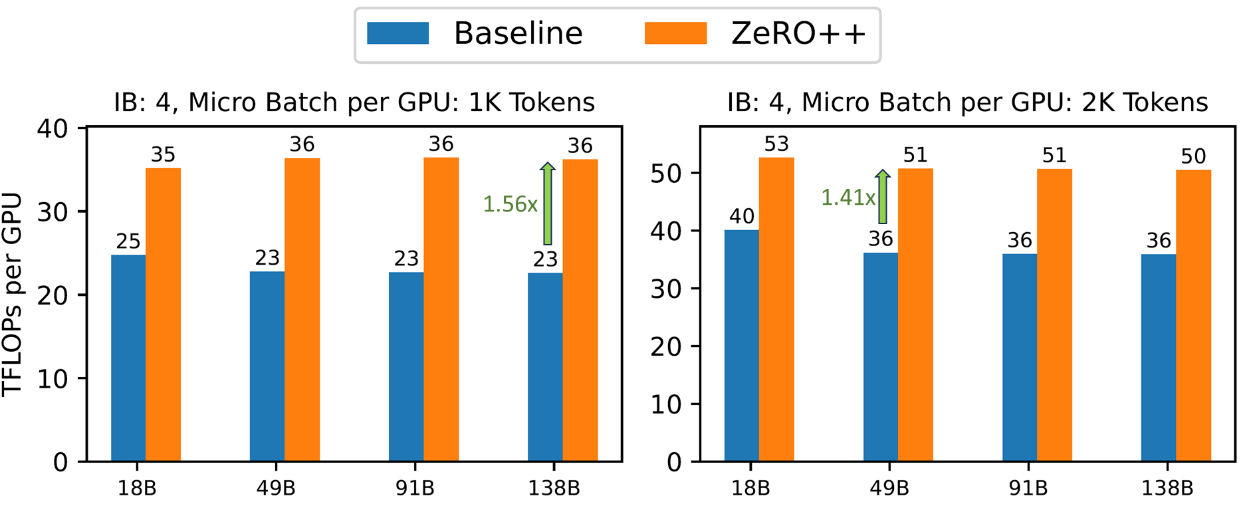
圖6: 在 384 個 V100 GPU 上的各種模型大小下 ZeRO++ 與 ZeRO 的吞吐量,節點間使用 4 個 Infiniband (IB) 進行互連,每個以 100 Gbps 運行。
在GPU小batch size情況下ZeRO++實現更高的訓練效率
高帶寬集群:?如圖 6 所示,我們首先展示了 ZeRO++ 相對于 ZeRO 的吞吐量改進,針對不同的模型大小和微批量(micro-batch size)大小,測試使用 4x Infiniband (IB) 以實現 400Gbps 跨節點互連帶寬,每個以 100Gbps 運行。 在 micro-batch size為每 GPU 1k tokens時,ZeRO++ 比 ZeRO-3 的吞吐量提高了 28% 到 36%。 對于 2k tokens micro-batch size大小,ZeRO++ 比 ZeRO-3 實現了 24% 到 29% 的吞吐量增益。
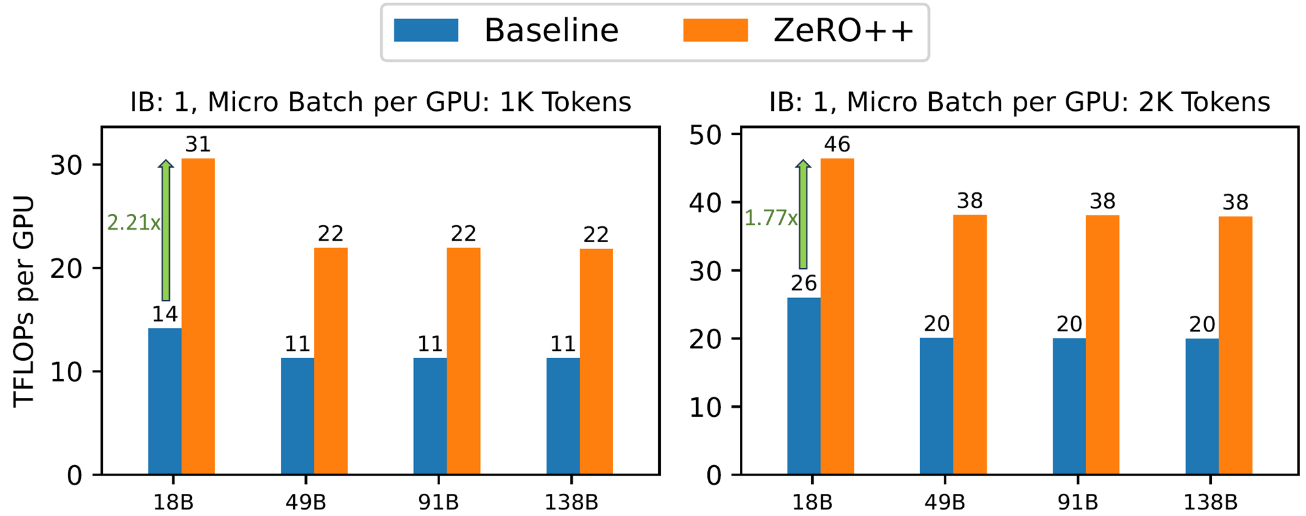
圖7: 在 384 個 V00 GPU 上 100Gbps 跨節點帶寬時各種 LLM 的吞吐量
低帶寬集群:?在 100Gbps等低帶寬網絡環境中,ZeRO++ 的性能明顯優于 ZeRO-3。 如圖 7 所示,與 ZeRO-3 相比,ZeRO++ 在端到端吞吐量方面實現了高達 2.2 倍的加速。 平均而言,ZeRO++ 比 ZeRO-3 基線實現了大約 2 倍的加速。
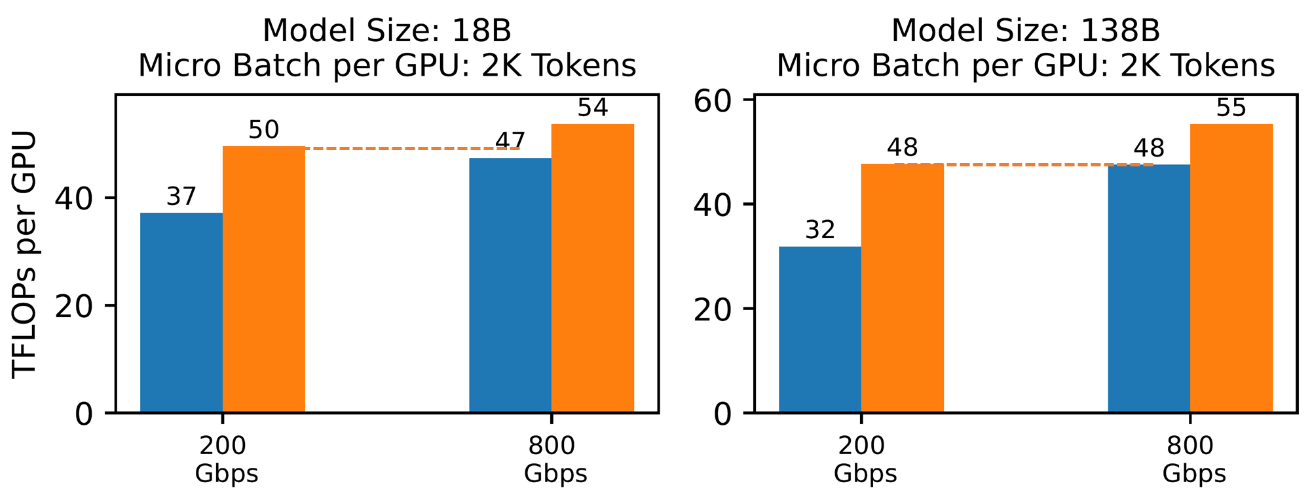
圖8: ZeRO++ 以顯著降低的帶寬實現高帶寬集群性能
實現高帶寬ZeRO和低帶寬ZeRO++集群之間的模型訓練效率等效
此外,與 ZeRO 在高得多的帶寬環境下相比,ZeRO ++ 可以在低帶寬集群中實現相當的系統吞吐量。 如圖 8 所示,對于 18B 和 138B 模型大小,具有 200Gbps 跨節點帶寬的 ZeRO++ 可以達到與 800Gbps 跨節點帶寬的 ZeRO-3 相似的 TFLOP。
鑒于 ZeRO++ 出色的可擴展性,我們將 ZeRO++ 視為用于訓練大型 AI 模型的下一代 ZeRO。
DeepSpeed-Chat 與ZeRO++結合用于 RLHF 訓練
RLHF訓練簡介
ChatGPT 類模型由 LLM 提供支持,并使用 RLHF 進行微調。 RLHF 由生成(推理)階段和訓練階段組成。 在生成階段,演員(actor)模型將部分對話作為輸入,并使用一系列前向傳遞生成響應。 然后在訓練階段,評論(critic)模型根據質量對生成的響應進行排名,為演員模型提供強化信號。 使用這些排名對參與者模型進行微調,使其能夠在后續迭代中生成更準確和適當的響應。
RLHF 訓練帶來了巨大的內存壓力,因為它使用了四種模型(演員、參考、評論、獎勵)。 常見的解決方案是采用低秩自適應訓練 (LoRA) 來解決 RLHF 的內存壓力。 LoRA 凍結了預訓練模型的權重,并將可訓練的秩分解矩陣注入到 Transformer 架構的每一層中,顯著減少了可訓練參數的數量。 LoRA 通過減少內存使用來加速 RLHF,允許更大的批處理(batch)大小,從而大大提高吞吐量。
DeepSpeed-Chat with ZeRO++ 用于 RLHF 訓練
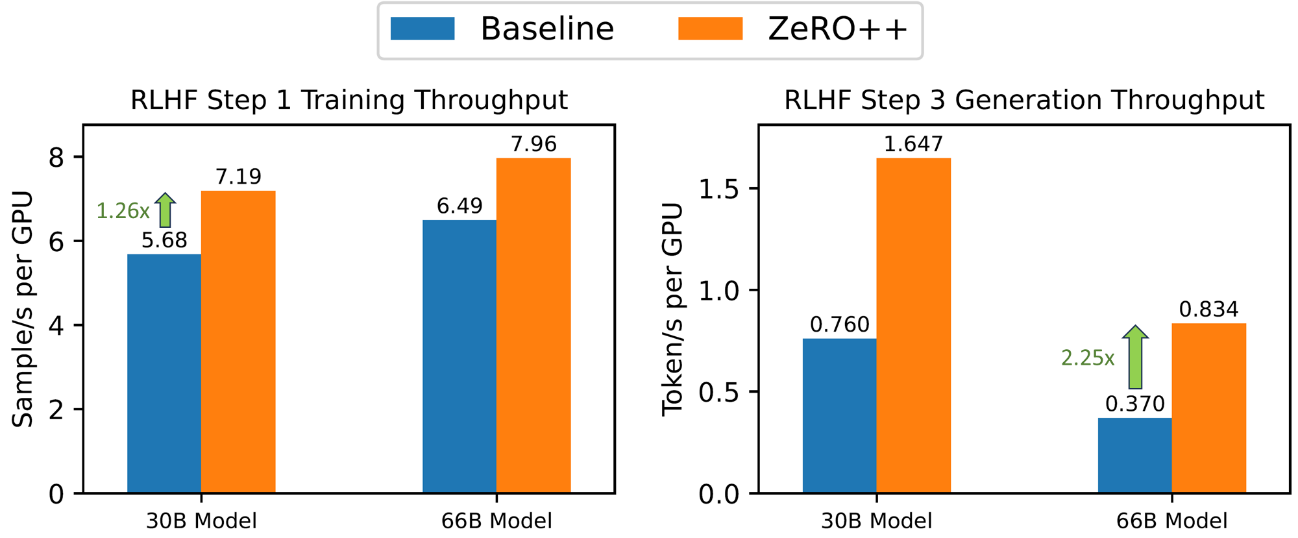
圖9: ZeRO++ 加速了 RLHF 訓練的生成和訓練階段
ZeRO++在RLHF + LoRA的場景下有著獨特的應用,因為大多數模型權重都被凍結了。 這意味著 ZeRO++ 可以將這些凍結的權重量化保存到INT4/8 中,而不是將它們存儲在 fp16 中并在每次通信操作之前對其進行量化。 通信后的反量化仍然是為了讓權重為計算做好準備,但反量化后的權重在計算后被簡單地丟棄。
以這種方式使用 ZeRO++ 進行 RLHF 訓練可以減少內存使用和通信量。 這意味著通過減少通信以及由于減少內存使用而啟用更大的批處理大小來提高訓練吞吐量。 在生成階段,ZeRO++ 使用 hpZ 將所有權重通信保持在每個節點內,以利用更高的節點內通信帶寬,減少通信量,進一步提高生成吞吐量。
ZeRO++ 已集成到 DeepSpeed-Chat 中,以支持 ChatGPT 類模型的 RLHF 訓練。 在圖 9 中,我們比較了不同大小的 actor 模型的 RLHF 生成吞吐量。測試配置為 32個V100 GPU ,actor 模型大小為30B 和 66B以測試 ZeRO 和 ZeRO++性能。 結果表明,ZeRO++ 的 RLHF 生成吞吐量比 ZeRO 高出 2.25 倍。 我們還展示了在 16 個 V100 GPU 上訓練階段的加速,其中 ZeRO++ 實現了比 ZeRO 高 1.26 倍的吞吐量,這是由于 ZeRO++ 支持的更低通信量和更大批量大小。
DeepSpeed ZeRO++現已發布!
我們非常高興能夠發布 DeepSpeed ZeRO++ 并讓 AI 社區中的每個人都可以使用它。請訪問我們的 GitHub 頁面以獲取?LLM訓練教程。 用于 DeepSpeed-Chat 的 ZeRO++ 將在未來幾周內發布。
有關 ZeRO++ 的更多技術細節,請查看我們的arxiv論文。
DeepSpeed-ZeRO++ 是 DeepSpeed 生態系統的一部分。 要了解更多信息,請訪問我們的網站,在那里您可以找到詳細的博客文章、教程和有用的文檔。
您還可以在我們的英文 Twitter、日文 Twitter?和中文知乎?上獲取最新的 DeepSpeed 新聞。
DeepSpeed 歡迎您的貢獻! 我們鼓勵您在 DeepSpeed GitHub 頁面上報告問題、貢獻 PR 并加入討論。 有關更多詳細信息,請參閱我們的貢獻指南。 我們對與大學、研究實驗室和公司的合作持開放態度。 對于此類請求(以及其他不適合 GitHub 的請求),請直接發送電子郵件至?deepspeed-info@microsoft.com。
和解碼器(Decoder))


框架學習)
,還有CAUSAL_LM,QUESTION_ANS)



——決策樹)

——PPO 算法在 RLHF 中的原理與實現詳解)
)







——圖像的直方圖、圖像直方圖的均衡化)