- 2022年11月30日,OpenAI發布了ChatGPT,2023年3月15日,GPT-4引發全球轟動,讓世界上很多人認識了ai這個詞。如今已過去快兩年半,AI產品層出不窮,如GPT-4、DeepSeek、Cursor、自動駕駛等,但很多人仍對AI知之甚少,尤其是“NLP”,“大模型”、“機器學習”和“深度學習”等術語讓人困惑🤔。
- 對于普通人來說,AI是否會取代工作😨?網絡上說除雙一流以外學校搞不了AI又是什么情況😩?AI產業是否像以前一樣互聯網程序員一樣?看一些科普視頻,上來就是一頓“Attention”、“神經元”、“涌現現象”等術語,讓人感覺是在介紹AI某個領域中的一個名詞,本文將通俗易懂地解釋AI,讓什么都不懂的小白也能變成AI概念的糕手,糕手,糕糕手😎
一:區分AI技術與AI應用
-
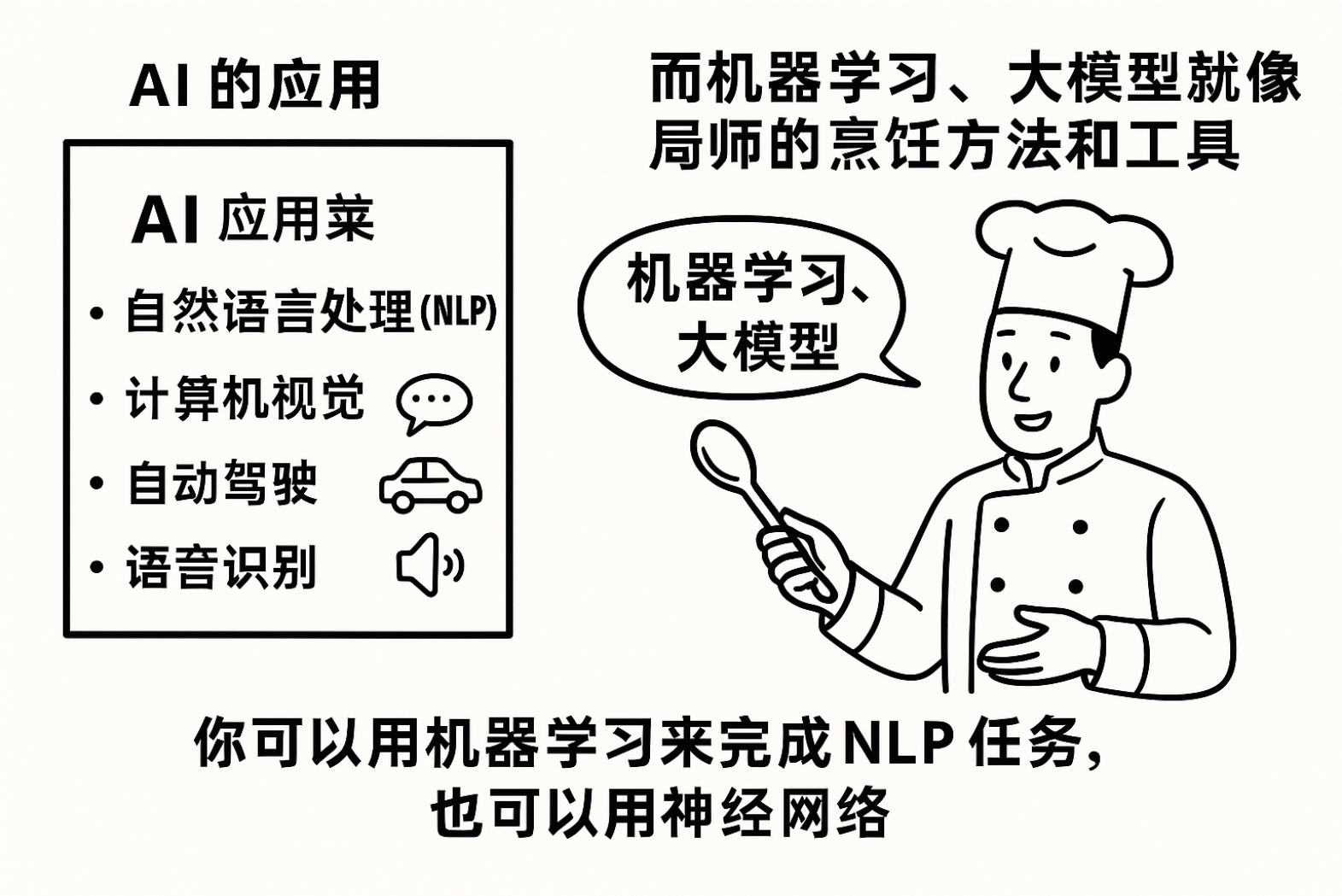
AI 的應用有:自然語言處理(NLP)、計算機視覺、自動駕駛、語音識別等。而機器學習、大語言模型等是實現這些應用的技術手段。
-
AI 的應用 就像是 餐館的菜單,上面有不同的菜肴(如自然語言處理、計算機視覺等),這些菜肴是顧客需要的服務或產品。
而 **機器學習、大模型就像是 廚師的烹飪方法和工具,它們是實現這些菜肴所用的手段。**你可以用機器來完成 NLP 任務,也可以用神經網做。
二:ChatGPT、DeepSeek是什么東西?
-
我們已經知道AI有不同的應用,而ChatGPT與DeepSeek都是NLP領域的大型語言模型(Large Language Model, LLM)。(NLP中文意思:自然語言處理。不要忘了哦)
-
這又引出了新問題:NLP是什么?大型語言模型又是什么?
NLP是什么?
-
翻譯人類語言讓計算機聽懂就是NLP,其中重點是聽懂,而不是你說“吃飯了嘛”,計算機也說“吃飯了嘛”。計算機明白了你在問它吃沒吃飯,于是計算機回答:我是機器不需要吃飯😅,或者我打算過一會兒再吃(充電)🔋。
很難想象,沒思想的計算機怎么能聽懂有思想的人說的話🤔,這其實是個困擾了幾十年的問題。
| 階段 | 時間范圍 | 技術特點 | 代表方法/模型 | 應用舉例 |
|---|---|---|---|---|
| 規則驅動階段 | 1950s–1980s | 基于人工編寫規則,語言學為主 | 句法規則、詞典匹配 | 早期機器翻譯、圖靈測試 |
| 統計學習階段 | 1990s–2010 | 依賴大規模語料,采用統計與概率模型 | N-gram、HMM、CRF | 情感分析、搜索引擎、拼寫糾正 |
| 神經網絡階段 | 2010–2017 | 引入深度學習,提升語言理解建模能力 | Word2Vec、RNN、LSTM、Seq2Seq | 智能問答、語音識別 |
| 預訓練大模型階段 | 2018至今 | 采用Transformer架構,模型參數大規模增長 | BERT、GPT、T5、ChatGPT、DeepSeek等 | 多任務通用語言處理、對話系統 |
-
規則驅動階段:意思就是讓機器明白主謂賓定狀補、什么名詞動詞名詞短語……但很顯然,套一萬個規則也難以讓一臺只會010101的機器明白你在說什么。
-
統計學習階段:這時候,科學家們將統計學引入來解決問題。將人們日常對話收集成庫(語料庫),通過統計發現對話數據中的規律來實現計算機“理解”人說的話。
- 在第三小結,會構建一個簡單的N-Gram模型,讓你大概知道什么是模型與統計學習階段是在干什么。所以先別急。
-
神經網絡階段:科學家們發現統計效果很好后,擴大了語料庫,加入了矩陣、向量計算(這不是本文重點,但可以是下一篇)和人工設計特征(早期有,后期減少),計算機硬件發展為該階段的提供算力支持。
-
預訓練大模型階段:
- 先說大模型,大模型就是有參數量大(億級甚至千億級)、數據量大、算力需求高特點的神經網絡模型。
- 預訓練:就像是一個體育比賽的人,不管這個人參與什么體育項目,先把體能練好了,再訓練具體項目。
| 階段 | 目的 | 數據類型 | 示例任務 |
|---|---|---|---|
| 預訓練 | 學通用語言能力 | 無標注語料 | 預測遮蓋詞、下一個詞等 |
| 微調 | 學任務特定能力 | 有標注數據 | 分類、翻譯、問答等 |

大型語言模型是什么?
- 你應該已經知道了,大型語言模型是一種大模型。
三:一個基礎NLP模型實現:N-Gram模型
-
-Gram 模型是一種基于統計的語言模型,其核心思想是:一個詞(或字)出現的概率,只依賴于它前面的 n?1n-1n?1 個詞(或字),用來解決已知的上下文生成合理的文本問題。
-
工作原理:
- 將文本序列拆分為連續的 N 個詞(或字)的組合,稱為“N-Gram”。
- 通過統計語料中各個 N-Gram 出現的頻率,估計下一個詞(或字)出現的概率。
-
計算公式
-
模型流程
- 收集語料
- 切分為 N-Gram
- 統計每種 N-Gram 出現頻率
- 根據頻率計算概率
- 根據歷史詞語預測下一個詞

from collections import defaultdict, Counter
import random
# 第一步:創建語料庫
corpus = ["我早上去了圖書館","我早上聽了一節英語課","我中午看了一部電影","我中午睡了一會兒","我晚上寫了一篇作文","我晚上復習了功課",
]# 第二步:分詞函數(按字分詞,這里只是按照字符分詞)
def split_words(text):return [char for char in text]# 第三步:統計Bigram詞頻(Bigram 是一個N-Gram 模型中的特例,其中N=2,即考慮連續的兩個詞或字符的組合。)
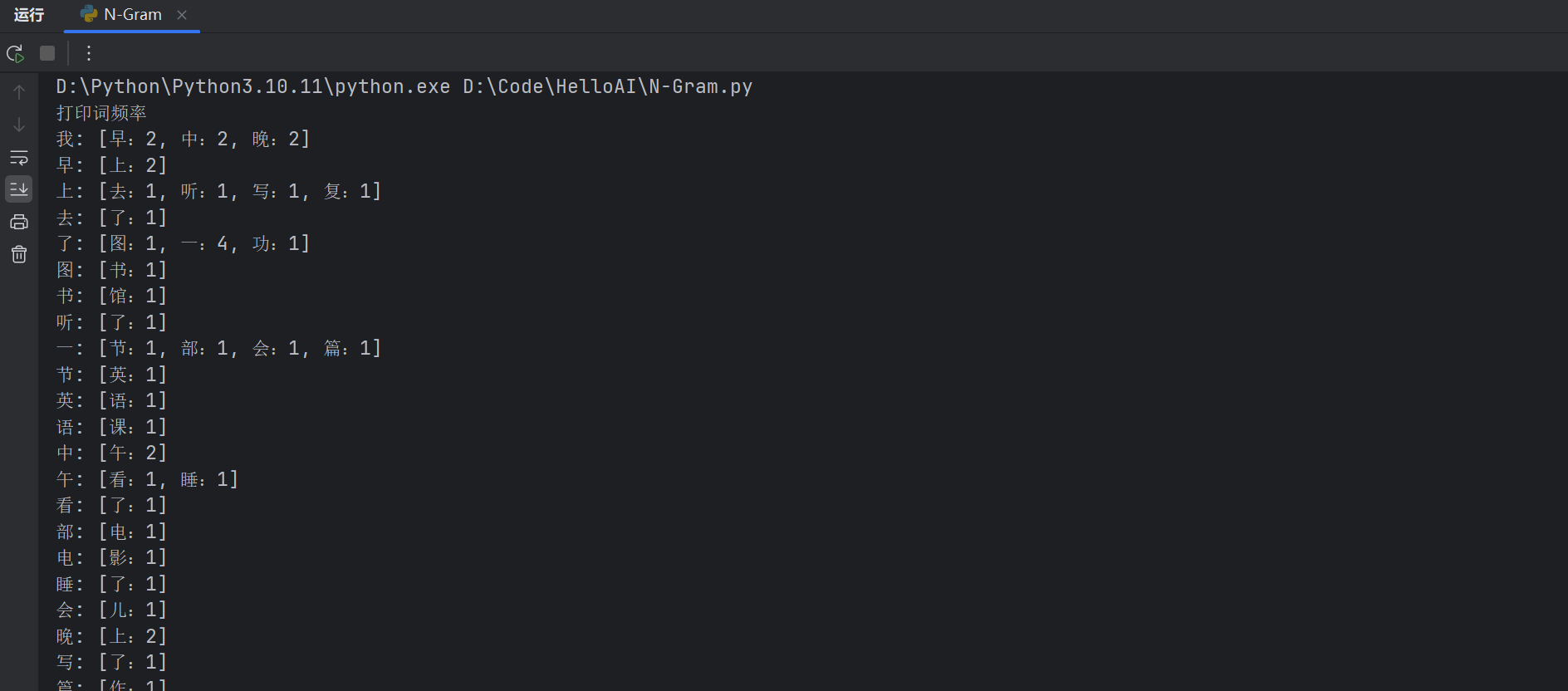
bigram_freq = defaultdict(Counter)
for sentence in corpus:words = split_words(sentence)for i in range(len(words) - 1):first, second = words[i], words[i+1]bigram_freq[first][second] += 1
# 打印詞頻率
# print("打印詞頻率")
# for first, counter in bigram_freq.items():
# freq_list = [f"{second}:{freq}" for second, freq in counter.items()]
# print(f"{first}: [{', '.join(freq_list)}]")# 第四步:計算Bigram概率(轉為概率分布)
bigram_prob = {}
for first, counter in bigram_freq.items():total = sum(counter.values())bigram_prob[first] = {second: count / total for second, count in counter.items()}
# print("詞頻概率為:", bigram_prob)# 第五步:根據前綴生成下一個字
def predict_next_char(prev_char):if prev_char not in bigram_prob:return Nonecandidates = list(bigram_prob[prev_char].items())chars, probs = zip(*candidates)return random.choices(chars, probs)[0]# 第六步:輸入前綴,生成文本
def generate_text(start_char, length=10):result = [start_char]current = start_charfor _ in range(length - 1):next_char = predict_next_char(current)if not next_char:breakresult.append(next_char)current = next_charreturn ''.join(result)# 示例
print(generate_text("我"))- 代碼不難,不懂問AI就好了。
- https://github.com/Qiuner/HelloAI ,這里會陸續復現幾個ai發展的經典模型
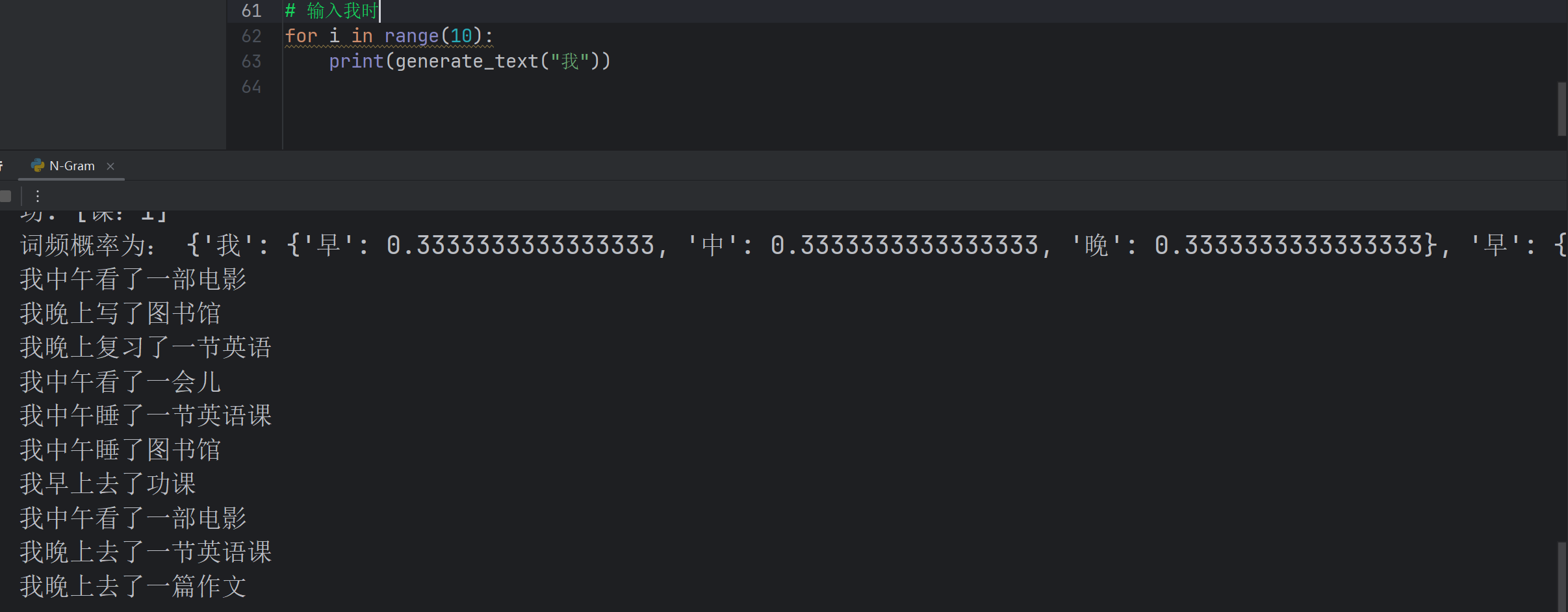
- 可以看到,出現了我早晨去了功課這樣不存在詞庫的句子
- 實際要做的更多
尾與推薦
-
N-Gram模型是不是讓你覺得非常簡單?簡單就對了,**這是1913年提出的模型,在1950年被引入NLP。**而現在是2025年,AI已經過Word2Vec 、RNN、 HMM、Transformer、BERT、GPT……等模型,且上面這些只是AI中NLP領域的。
-
推薦:
注
- 本文的一些術語并列,因根據我日常看到的詞頻率而并列,可能其并非并列關系。

你好,我是Qiuner. 為幫助別人少走彎路而寫博客 這是我的 github https://github.com/Qiuner? gitee https://gitee.com/Qiuner 🌹
如果本篇文章幫到了你 不妨點個贊吧~ 我會很高興的 😄 (^ ~ ^) 。想看更多 那就點個關注吧 我會盡力帶來有趣的內容 😎。
代碼都在github或gitee上,如有需要可以去上面自行下載。記得給我點星星哦😍
如果你遇到了問題,自己沒法解決,可以去我掘金評論區問。私信看不完,CSDN評論區可能會漏看 掘金賬號 https://juejin.cn/user/1942157160101860 掘金賬號
更多專欄:
- 📊 一圖讀懂系列
- 📝 一文讀懂系列
- 🌟 持續更新
- 🎯 人生經驗
掘金賬號 CSDN賬號
感謝訂閱專欄 三連文章



——圖像的直方圖、圖像直方圖的均衡化)






 - V10 SP1桌面操作系統ARM64編譯QT-5.15.12版本)








