引言:從“手動擋”到“自動駕駛”
想象我們駕駛一輛汽車,手動調節油門和換擋不僅費力,還難以應對突發狀況。我們的應用服務也一樣,在面對突然的流量增長,內存使用暴漲該如何應對。HPA(Horizontal Pod Autoscaler) 為我們提供了解決方案,它像更高級的“自動駕駛”,根據實時負載自動擴縮容。接下來我們一塊學習如何應用HPA進行配置資源請求、限制與自動伸縮策略。
一、為什么需要資源管理?
1.1 資源爭搶的災難場景
- 案例:某個Pod瘋狂占用CPU,導致同節點其他應用癱瘓。
- 后果:服務響應延遲、OOM(內存溢出)錯誤、節點崩潰。
資源管理的核心目標:
- 穩定性:為每個容器預留必要資源,避免爭搶。
- 利用率:合理分配資源,防止浪費。
二、資源請求與限制:為容器戴上“緊箍咒”
2.1 核心概念
- requests(請求):容器啟動所需的最低資源保障(如“至少需要1核CPU”)。
- limits(限制):容器能使用的資源上限(如“最多使用2核CPU”)。
2.2 配置示例
在Pod或Deployment中定義資源約束:
# deployment-with-resources.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: web-app
spec:replicas: 2template:spec:containers:- name: nginximage: nginx:latestresources:requests: # 資源請求cpu: "100m" # 0.1核CPUmemory: "128Mi" # 128MB內存limits: # 資源限制cpu: "500m" # 0.5核CPUmemory: "512Mi" # 512MB內存
2.3 資源單位詳解
- CPU:
1= 1核CPU,100m= 0.1核(毫核)。- 可超賣:多個Pod的CPU請求總和可超過節點實際CPU。
- 內存:
- 單位:
Mi(兆字節)、Gi(千兆字節)。 - 不可超賣:節點內存耗盡時,會觸發OOM Killer終止進程。
- 單位:
2.4 驗證資源分配
查看Pod資源詳情
kubectl describe pod <pod-name>
輸出示例:
Containers:nginx:Limits:cpu: 500mmemory: 512MiRequests:cpu: 100mmemory: 128Mi
監控節點資源使用
kubectl top nodes
kubectl top pods
三、HPA:水平自動擴縮容
3.1 HPA的工作原理
- 監控指標:CPU利用率、內存使用率或自定義指標(如QPS)。
- 擴縮邏輯:當指標超過閾值時,自動增加/減少Pod副本數。
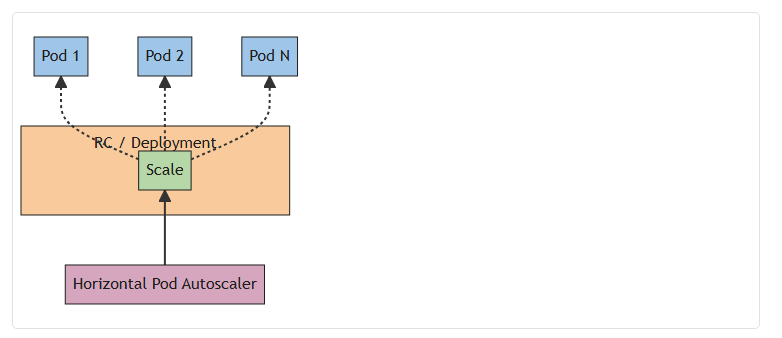
(圖:HPA根據指標變化調整Deployment的副本數)
3.2 配置HPA(CPU為例)
步驟1:部署Metrics Server
HPA依賴資源指標數據,需先安裝Metrics Server:
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
# 驗證安裝
kubectl get deployment metrics-server -n kube-system
步驟2:創建HPA策略
# 當CPU使用率超過50%時擴容,最少1個Pod,最多5個
kubectl autoscale deployment web-app --cpu-percent=50 --min=1 --max=5
或通過YAML定義:
# hpa.yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:name: web-app-hpa
spec:scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: web-appminReplicas: 1maxReplicas: 5metrics:- type: Resourceresource:name: cputarget:type: UtilizationaverageUtilization: 50
步驟3:觸發壓力測試
# 進入Pod生成CPU負載
kubectl exec -it <pod-name> -- sh
dd if=/dev/zero of=/dev/null & # 模擬CPU滿載
exit# 觀察HPA狀態
kubectl get hpa -w
輸出示例:
NAME REFERENCE TARGET MINPODS MAXPODS REPLICAS
web-app-hpa Deployment/web-app 150%/50% 1 5 3
3.3 高級配置:內存與自定義指標
基于內存的HPA
metrics:
- type: Resourceresource:name: memorytarget:type: UtilizationaverageUtilization: 80 # 內存使用率閾值80%
自定義指標(需Prometheus適配器)
metrics:
- type: Podspods:metric:name: http_requests_per_secondtarget:type: AverageValueaverageValue: 100 # 每秒請求數超過100時擴容
四、最佳實踐與陷阱避坑
4.1 資源參數優化建議
- CPU請求:根據應用基線負載設定(如Java應用初始值可設
500m)。 - 內存限制:留出至少20%緩沖,避免OOM。
4.2 常見陷阱
- 未設置limits:導致“資源吸血鬼”耗盡節點資源。
- HPA振蕩:閾值過小或指標波動大,導致副本數頻繁變化。
- 解決:適當增大擴縮容冷卻時間(
--horizontal-pod-autoscaler-downscale-stabilization)。
- 解決:適當增大擴縮容冷卻時間(
五、常見問題與解決
-
HPA不觸發擴容
- 檢查Metrics Server是否正常運行:
kubectl top pods。 - 確認Deployment的
resources.requests已設置(HPA依賴requests計算利用率)。
- 檢查Metrics Server是否正常運行:
-
Pod因OOM被終止
- 增大
memory.limits或優化應用內存使用。 - 檢查是否有內存泄漏。
- 增大
-
節點資源不足導致Pod無法調度
- 清理閑置Pod或擴容集群節點。
- 檢查
kubectl describe node的資源分配情況。
動手實驗
-
模擬流量高峰
使用壓測工具(如hey或wrk)對服務發起請求,觀察HPA如何擴容:hey -z 5m -c 100 http://<service-ip>:<port> -
動態調整HPA閾值
修改HPA的targetAverageUtilization,觀察副本數變化:kubectl edit hpa web-app-hpa
資源推薦
- Kubernetes HPA官方文檔
- Metrics Server GitHub倉庫
- Kubernetes資源配額管理
現在,我們的應用無論是突發流量還是資源擠占,Kubernetes的自動化機制都能讓系統穩如磐石。











)




)


