Transformer中的位置編碼PE(position encoding)
1.提出背景
transformer模型的attention機制并沒有包含位置信息,即一句話中詞語在不同的位置時在transformer中是沒有區別的
2.解決背景
給encoder層和decoder層的輸入添加了一個額外的向量Positional Encoding(PE),與embedding維度一致
embedding維度:
- 句子:詞向量的維度大小,如512
- 圖片:通道數
實際應用中,會對位置信息向量如[1,2,…,16]先進行位置編碼,位置編碼的維度可以先保持與句子編碼維度一致,如512。再通過一個線性層,將維度降為需要的通道數,最后再進行信息合并。
3. 創建一個位置編碼器PE
需要的輸入設置
- 序列的最大長度 max_seq_len,如1000
- 編碼向量的維度 d_model,如512或128
主體邏輯
- 計算PE矩陣
- 重新定義嵌入層:將嵌入層的權重替換為PE(不可訓練)
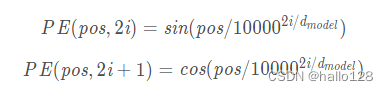
PE為二維矩陣,大小跟輸入embedding的維度一樣,行表示詞語,列表示詞向量;pos 表示詞語在句子中的位置;dmodel表示詞向量的維度;i表示詞向量的位置。因此,上述公式表示在每個詞語的詞向量的偶數位置添加sin變量,奇數位置添加cos變量,以此來填滿整個PE矩陣,然后加到input embedding中去,這樣便完成位置編碼的引入了。
參考:https://blog.csdn.net/qq_34771726/article/details/102918440
class PositionalEncoding(nn.Module):def __init__(self, max_seq_len: int, d_model: int):super().__init__()# Assume d_model is an even number for convenienceassert d_model % 2 == 0 # 為了編碼方便# ---1.計算PE矩陣# 位置編碼二維矩陣PE的大小: [max_seq_len, d_model]pe = torch.zeros(max_seq_len, d_model) # 初始化為零矩陣# 行:i向量 [0,1,2,..., 999] 表示每個時間步ti_seq = torch.linspace(0, max_seq_len - 1, max_seq_len)# 列:j向量 [0,2,4,6,8] 表示偶數位j_seq = torch.linspace(0, d_model - 2, d_model // 2) #(0, 8, 5)# 生成網格數據: 2個矩陣[1000, 5]pos, two_i = torch.meshgrid(i_seq, j_seq)pe_2i = torch.sin(pos / 10000**(two_i / d_model)) # 偶數位sinpe_2i_1 = torch.cos(pos / 10000**(two_i / d_model)) # 奇數位cos# stack拼接到第2個維度[0,1,2],在把3維重塑為2維pe = torch.stack((pe_2i, pe_2i_1), 2).reshape(max_seq_len, d_model)# ---2.定義嵌入層self.embedding = nn.Embedding(max_seq_len, d_model) # 定義了一個嵌入層self.embedding.weight.data = pe # 使用位置編碼計算好的嵌入矩陣對其進行初始化self.embedding.requires_grad_(False) # 將其參數設為不可訓練def forward(self, t):# 調用嵌入層方法# t表示抽取的時間點向量: [32, 43, 85, 31, 86, 90, 67, 61, 50, 33, 87, 48, 31, 48, 48, 93]return self.embedding(t)
4.調用位置編碼器PE
- 對輸入的位置向量,如[1,2,…,16]. 先經過PE編碼為詞向量長度: [16, 1, 128]
- 與原圖x拼接,即x+t
- 先經過一個線性層,將詞向量維度轉換為與圖片通道數一致
- 與原圖相加拼接
‘’‘
對輸入時間點的位置編碼
’‘’
# 1. 設置位置編碼器PE
max_seq_len = 1000 # 最大序列長度
d_model = 128 # 編碼向量的維度
pe = PositionalEncoding(max_seq_len, d_model)
pe# 2.隨機抽取時間點
n_steps = 100
batch_size = 16
t1 = torch.randint(0, n_steps, (batch_size, )) # 隨機抽取16個時間點# 3.對時間點進行PE編碼
p1 = pe(t1)
p1 # 得到位置編碼結果[1000, 128]將編碼后的時間與原圖進行拼接
‘’‘
將編碼后的時間與原圖進行拼接
’‘’
pe_dim = 128 # 詞向量維度
channel = 1 # 圖片通道數C
n = 16 # 圖片批量大小(也就是上面時間t的步數)# 1.先經過一個線性層,將詞向量維度轉換為與圖片通道數一致
# 設置映射空間層
pe_linear = nn.Sequential(nn.Linear(pe_dim, channel), nn.ReLU(),nn.Linear(channel, channel))
# 將128的詞詞向量維度轉換為1的圖片通道數
pe_v = pe_linear(p1).reshape(n, -1, 1, 1) # (1, 128) -> (1,1) -> (1,1,1)
# pe_linear: 降維 128 -> 1 通道數
# reshape: 整理維度 [n, C, 1, 1]# 2.將整理后的位置編碼與圖片連接
# 原圖
x = torch.randn(1, 28, 28) # 拼接
x + pe_v
# [16, 1, 28, 28]
# 16: 數據批量大小(時間點的個數 - batch_size)
# 1: 通道數
# 28*28: 圖片大小





)

綜述)

、狀態后端選擇和調優等有所了解)







)
