本篇博客內容是讀兩篇論文,兩篇論文連接如下:
Heterogeneous graph neural networks analysis: a survey of techniques, evaluations and applications
A Survey on Heterogeneous Graph Embedding: Methods, Techniques, Applications and Sources
Heterogeneous graph neural networks analysis: a?survey of?techniques, evaluations and?applications
Abstract
大多數GNN的目的是學習只包含單一類型的節點和邊的同構圖的嵌入向量。然而,現實世界中的實體及其相互作用往往具有多種類型,自然形成具有豐富結構和語義信息的異構圖。現有的異構圖表示學習的調查論文總結了所有可能的圖嵌入技術,對深度神經網絡模型的分析不足。為了解決這一問題,本文系統地總結和分析了現有的異構圖神經網絡(hgnn),并根據其神經網絡結構對其進行了分類。同時,收集了常用的異構圖數據集,并總結了它們的統計信息。此外,還比較了HGNN和淺嵌入模型的性能,以顯示其強大的特征。
1. Introduction
圖被廣泛用于建模復雜實體及其在各種現實場景中的關系,例如,蛋白質相互作用網絡,社會網絡,交通網絡,學術網絡以及知識圖。
現有的圖嵌入方法可分為淺嵌入模型(shallow embedding models)和深嵌入模型(deep embedding models)。
Shallow embedding methods
通常使用矩陣分解(Matrix Factorization,MF)或隨機漫步(Random Walk,RW)來學習圖表示。基于MF的模型通過構造矩陣并根據節點對相似度對其進行分解來學習嵌入向量。然而,由于時間和空間成本的原因,它們相當有限。基于RW的方法通過采樣節點序列來學習節點的表示。但是基于RW的方法需要選擇合適的步行長度,這是模型性能的關鍵。此外,基于MF的模型和基于RW的模型都不能捕獲高階非線性相互作用特征。
Deep embedding methods
為了克服淺嵌入模型存在的問題,提出了圖形神經網絡(GNN),通過先進的深度神經網絡獲得滿意的表示。GNN通過聚合每個節點的本地鄰居的特征來學習節點表示,而不需要設置節點序列。通過非線性激活函數疊加多個網絡層,GNN可以捕獲重要的高階交互信息并獲得表達性表示。
🌰
DBLP學術網絡
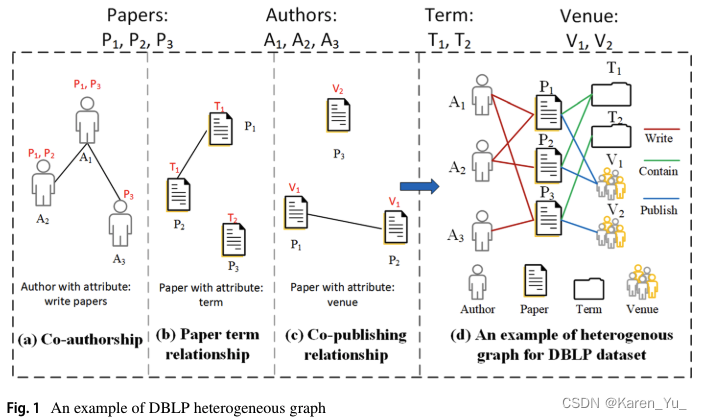
(a) A1和A2是論文P1點共同作者,A1和A3是論文P3的共同作者,A2單獨寫了論文P2
(b) P1和P2有相同的術語T1,P3用到術語T2
(c) P1和P2在V1發表,P3在V2發表
(d) 結合在一起
此時homogeneous graph(即a-c)-> heterogeneous graph
2. Related works
Shallow graph embedding methods,淺嵌入方法
旨在學習圖的表示,同時保持圖的連通性。常用的方法即為MF和RW
MF
對于異構圖數據-> 投影度量嵌入(Projected Metric Embedding,PME),根據其關系類型將異構圖分解為幾個二部圖。然后,PME將每個二部圖投影到具有特定關系的語義空間中,在保留多個關系的情況下捕獲一階和二階近似。
->?預測文本嵌入(Predictive Text embedding,PTE)的嵌入框架,將文本異構網絡分解為三個子網。然后可以使用LINE來學習三個子網的節點向量表示
->?嵌入的嵌入(Embedding of Embedding,EOE)模型,該模型可以將學術異構網絡分為兩個子網。一種是詞共現網絡,另一種是作者合作網絡。它分別在子網內和子網之間嵌入節點對。
RW
DeepWalk對樣本節點序列進行隨機行走,然后將節點序列作為句子輸入到Skip-Gram中學習節點嵌入。
Node2Vec定義了對樣本節點的偏差隨機漫步策略,以適應不同的圖數據。Node2Vec使用隨機梯度下降(SGD)來獲得最優的圖嵌入。
對于異構圖,Metapath2Vec,它使用異構Skip-Gram來最大化給定節點及其異構上下文的共現概率。基于社區的問答(Community- based Question Answering,CQA)網絡,使用LSTM模型做嵌入。
深度圖嵌入方法通常由多層神經網絡結構組成,用于提取深度非線性表示,這些方法可以分為基于卷積的模型和基于自編碼器的模型(Convolution-based,Autoencoder-based)。
卷積
受卷積神經網絡(CNN)的啟發,圖卷積網絡被設計用來學習用密集低維向量表示的圖特征。現有的基于卷積的方法可以分為三類:基于頻譜的、基于空間的和基于雙曲的方法(spectral-based,spatial-based,hyperbolic-based)。
對于基于頻譜方法,從圖信號處理的角度出發,通過發展濾波器來定義圖卷積,通過尋找拉普拉斯矩陣對應的特征向量作為傅里葉基,卷積可以推廣到廣義圖。
ChebyNet的卷積過程是將拉普拉斯矩陣變換為拉普拉斯矩陣的k次冪,而不是將拉普拉斯矩陣分解以減少計算量。半監督節點分類任務->圖卷積網絡(GCN)。GCN是一階ChebyNet的近似,其最大特征值為2。由于參數較少,它比ChebyNet更有效地聚合鄰居節點的特征。
對于基于空間方法,通過聚合k-hop鄰居獲得節點的特征表示。例如,GraphSAGE(空間圖卷積方法),通過聚合局部鄰域特征來嵌入節點。為了區分相鄰節點的重要性,圖注意網絡(Graph Attention Network, GAT),通過注意機制對不同權重的相鄰節點特征進行聚合。同構圖分類的圖同構網絡(GIN),使用簡單的MLP學習節點嵌入并讀出所有節點進行圖分類。
基于雙曲方法(學習更復雜的pattern),利用雙曲圖卷積網絡(Hyperbolic GraphConvolutional Networks, HGCN)擴展了GNN的可表達性。利用指數變換將歐幾里德空間中的輸入特征映射到雙曲空間,然后利用洛倫茲模型和切線空間對圖在雙曲空間中的特征傳播進行建模(這里妹懂數學上的含義)。雙曲圖神經網絡(Hyperbolic Graph Neural Networks, HGNN)使用對數映射將輸入特征轉換到雙曲空間。雙曲圖注意網絡(Hyperbolic Graph Attention Network)擴展了雙曲空間中圖學習的自注意。利用指數變換進行雙曲特征投影,并在雙曲空間中設計基于距離的自注意機制來度量節點間的重要性。然后,它通過加權聚合更新節點嵌入。
自編碼器
圖自動編碼器(Graph Auto Encoder,GAE)通常使用深度全連接神經網絡,目的是將圖投影到以低維向量表示的潛在空間中。映射向量通過將自身解碼到輸入空間來保持原始圖形特征,以最小化構造錯誤。一個典型的工作是結構深度網絡嵌入(SDNE)。SDNE采用帶有非線性激活函數的堆疊自編碼器捕獲高度非線性的圖表示。它通過使用兩個損失函數來保持節點的一級和二級逼近。第一種方法最小化節點與其相鄰節點之間的距離,以保持一階接近性。第二種方法旨在最小化原始和重構節點表示之間的差異,使具有相似鄰域結構的節點具有相似的潛在表示。
變分圖自動編碼器(Variational Graph Auto-Encoders,VGAE)用于學習節點的低維表示。它的核心思想是將變分自動編碼器(VAE) 擴展到圖形結構化數據。VGAE使用兩層GCN作為編碼器來學習節點潛在表示的分布,表示為經驗分布。利用內積作為解碼器重構圖鄰接矩陣,優化模型參數。
通過將多層神經網絡與非線性激活函數疊加,基于神經網絡的方法能夠在圖中提取深度表示。
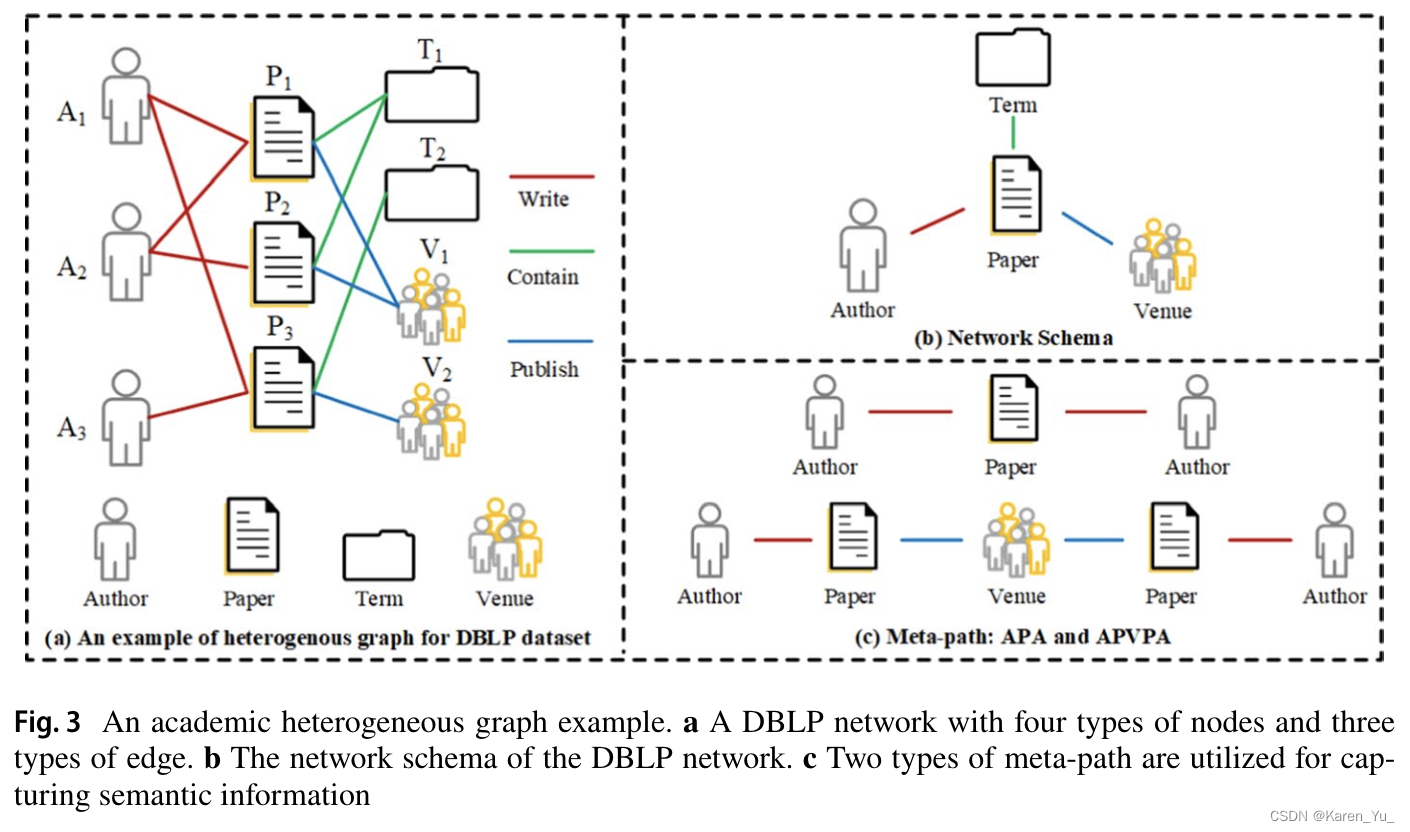
3. Preliminary
一些基礎定義


參數定義:
G:圖。V:節點集合。E:邊的集合。v:圖G中的一個節點。e:圖G中的一條邊。
節點類型映射函數,A表示節點類型的集合
邊類型映射函數,R表示邊的類型
因此對于同構圖,有
對于異構圖,有
network schema:異構圖網絡的一個meta template。定義為
。用于描述異構圖中所有節點類型和邊緣類型的范式。
metapath(似乎譯作元路徑)是在network schema上的路徑P。元路徑連接的節點對可以看作是具有特定語義的高階鄰居,不同的元路徑表示不同的語義關系。
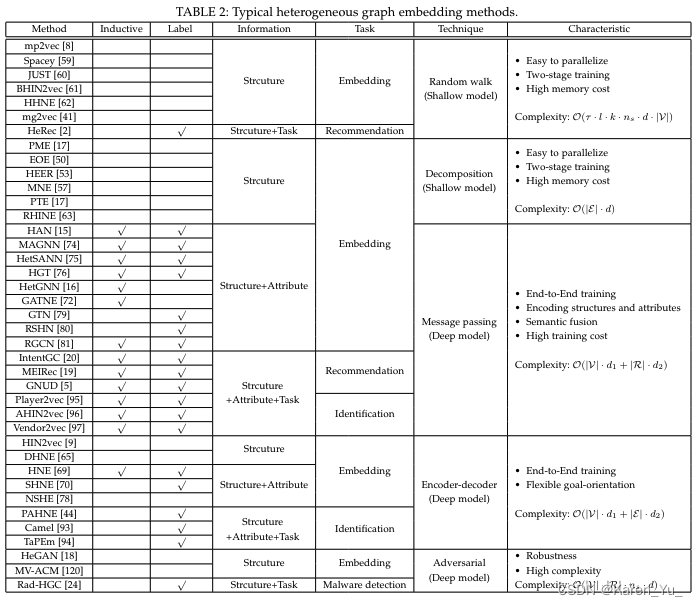
4. Methods taxonomy
HGNN方法通過高級神經網絡從異構圖的圖結構和/或節點屬性信息中學習重要信息,并將這些信息保存在節點嵌入中。根據學習模式中使用的技術,現有的HGNN模型可以分為三類,即基于卷積的模型、基于自編碼器的模型和基于對抗的模型。
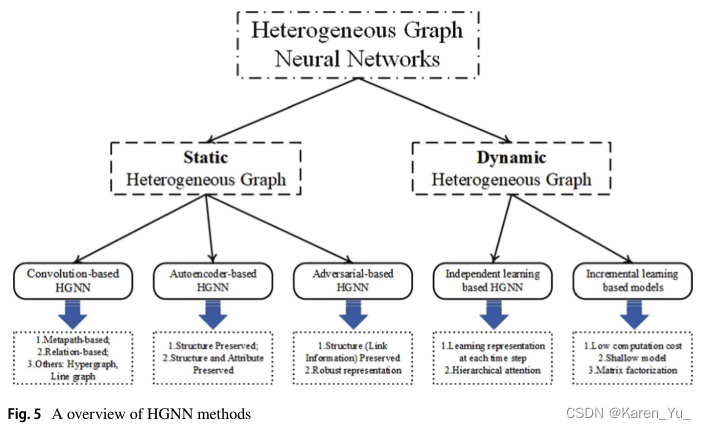
4.1 Static heterogeneous graph learning
現有的HGNN模型大多旨在捕獲靜態異構圖中沒有時間演化的復雜結構和語義信息,并希望在嵌入向量中有效地保留這些關鍵信息。靜態異構圖的hgnn模型可分為基于卷積的、基于自編碼器的和基于對抗的三種方法。
基于卷積
基于卷積的HGNN的核心思想是消息傳遞機制,鄰居節點的信息以消息的形式傳遞給中心節點,并聚合形成中心節點的嵌入。基于卷積的模型的關鍵問題是如何設計合適的異構保持策略來捕獲鄰居中包含的語義信息。
Metapath-based
基于元路徑的模型主要是通過構造基于元路徑的鄰居來保持圖的異構性。異構圖注意網絡(Heterogeneous graph Attention Network,HAN)是一種分層注意模型,學習異構圖中的節點嵌入。
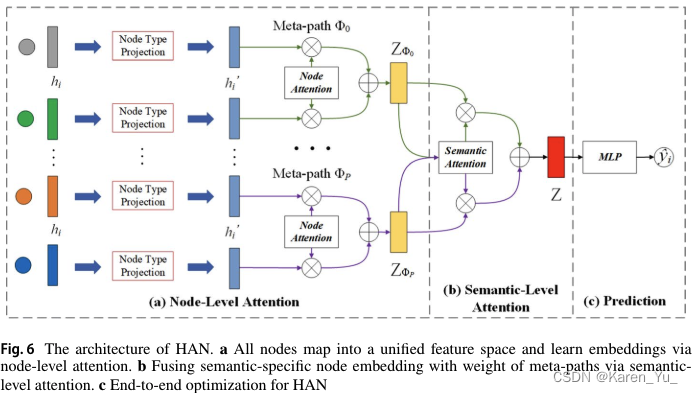
HAN設計節點級和語義級關注來計算節點和元路徑的重要性分數,以捕獲結構和語義特征。節點關注的目的是學習元路徑鄰居的重要性分數:
此處指的是元路徑m中幾點i的鄰居集合,
是在元路徑m中的節點j對節點i的重要性分數。
是重要性計算的attention vector
節點級的aggregation(聚合)定義為:
是元路徑m中的節點i嵌入的更新。每個元路徑在異構圖中捕獲一定的語義信息,HAN設計語義級聚合來融合多個元路徑的語義特征。給定一個元路徑集合
,在節點級的聚合(aggregation)上,HAN得到P個不同的語義節點嵌入
,計算重要性:
此處,,
表示投影矩陣和偏置。
是語義級的注意力向量。語義級聚合表示為:
此處,是normalized的
,目的是防止節點嵌入過于龐大。
表示可用于不同任務(如節點分類、節點聚類和鏈接預測)的最終節點嵌入。HAN是第一個將注意力網絡應用于異構圖嵌入任務的模型。
進一步->異構圖嵌入的元路徑聚合圖神經網絡(Metapath Aggregation Graph Neural Network ,MAGNN)模型。當使用元路徑維護異構性時,元路徑上的所有中間節點也都有有用的語義信息。因此,與HAN中的節點級聚合不同,MAGNN中的節點級聚合聚合元路徑中的所有節點,而不是路徑的兩個端點節點。
HAHE模型,采用與HAN相同的層次結構來學習節點的嵌入。不同的是,HAHE使用余弦相似度代替注意機制來計算兩種重要性。
Relation-based
基于關系的方法可以通過聚合一跳鄰居的特征來學習節點表示,而不需要人為設置元路徑。為了避免設置元路徑和自動學習有用的語義信息 -> Graph Transformer Networks(GTN)的嵌入方法,通過自動尋找有用的元路徑來學習節點嵌入。根據關系類型將異構圖劃分為若干子圖,并將子圖鄰接矩陣饋送到多通道GCN中學習節點嵌入。

另一種無元路徑嵌入模型稱為異構圖結構注意神經網絡(Heterogeneous Graph Structural Attention Neural Network ,HetSANN),通過聚合具有關系重要度的鄰居來學習每個節點的嵌入。首先,HetSANN選擇與其相鄰的節點,并將相鄰節點投影到所選節點空間中。隨后,HetSANN設計了一個類型感知的關注層,通過聚合具有不同關系重要度的鄰居特征來學習每個節點的嵌入。
異構圖轉換器(Heterogeneous Graph Transformer ,HGT)學習異構圖表示。HGT的框架如圖7所示。HGT使用與多類型節點和邊相關的可學習參數來記錄異構性。定義了一種元關系三重關注機制,以邊緣信息作為傳遞消息的權重來計算鄰居的重要性得分。
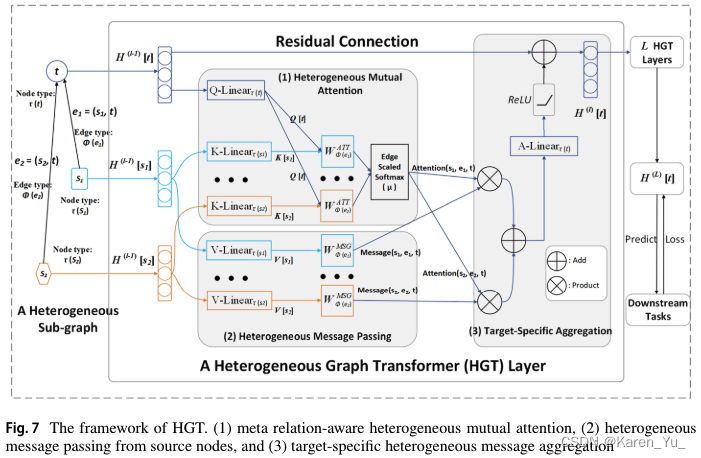
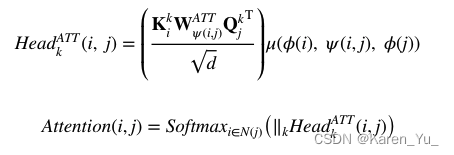

HetSANN和HGT本質上都使用分層注意機制來學習節點的表示。但與基于元路徑的模型不同的是,它們在節點級聚合中聚合的是同一關系下的節點特征,而不是同一元路徑下的節點特征。然而,HetSANN和HGT需要堆疊更多的神經網絡層來提取有用的高階交互,并生成更多的模型參數。
可解釋且高效的異構圖卷積網絡(Interpretable and Efcient Heterogeneous Graph Convolutional Network ,ie-HGCN)利用節點類型區分的GCN學習異構圖嵌入。首先,ie-HGCN將不同類型鄰居節點的表示投影到一個公共語義空間中。它考慮了由多個二部圖組成的異構圖,并將GCN用于二部圖的節點級聚合。在類型級聚合中,ie-HGCN利用注意力對不同類型的相鄰節點進行聚合,最終獲得節點嵌入。ie-HGCN有效地減少了計算量。
Others
為了學習穩健的節點嵌入 -> 異質圖結構學習(Heterogeneous Graph Structure Learning, HGSL),首次嘗試研究異質圖結構。通過節點和語義特征的相似性來學習圖的結構。將學習到的三種圖結構特征相似圖、特征傳播圖和語義圖與原始圖進行聚合,形成最優異構圖。
HHNE用于嵌入異構屬性超圖。HHNE使用全連通層和圖卷積層將多類型節點投影到一個共同的低維空間中。并定義了一個基于元組的相似性函數來保持超邊的結構。
為了解決邊緣連接的異構性問題 ->?關系結構感知異構圖神經網絡。與設置元路徑或提取關系以保持邊緣的異質性不同,RSHN將原始異構圖轉換為線形圖,并將其輸入神經網絡以嵌入邊緣特征。然后,RSHN將學習到的邊緣嵌入與原始節點特征結合,輸入到異構GNN中學習完整的節點嵌入。RSHN是一種關系結構感知的HGNN,但在RSHN中忽略了多類型節點。
基于卷積的方法遵循消息傳遞來更新節點的表示。與人工定義元路徑的方法相比,基于關系的方法可以通過比較每個網絡層中不同類型節點之間的重要性得分來選擇當前任務和數據集最有用的元路徑,從而為模型的可解釋性提供支持。然而,基于關系的方法有更多的模型參數,這增加了空間消耗。
基于編碼器
基于自編碼器的方法的主要目的是利用神經網絡作為編碼器,從節點結構和/或屬性中學習節點嵌入,并設計解碼器,最大程度地保留原始圖中的結構和/或屬性信息。根據異構圖中包含的信息不同,基于自編碼器的方法可分為結構保留和結構屬性保留兩種。
Structure only
結構保留模型通常嵌入不含節點屬性信息的異構圖。他們只需要維護圖的拓撲信息。例如HIN2Vec,如圖8所示。HIN2Vec采用元路徑解決異構性問題,通過前饋神經網絡融合元路徑和節點one-hot向量,學習節點和元路徑的表示。它通過最大化節點對中發生關系的概率來優化神經網絡。
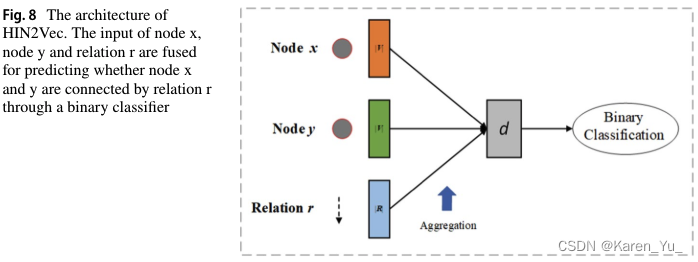
這里的條件概率定義為:
此處,分別是節點和邊的one-hot 向量,
表示投影矩陣。融合向量的所有維度之和,形成一個標量。目標函數是交叉熵損失函數:
此處,是正連接的集合。HIN2Vec可以通過最小化目標函數來學習節點嵌入和元路徑。
超圖嵌入模型,即深度超網絡嵌入(Deep Hyper-Network embedding, DHNE)。DHNE的目的是學習不可分解超邊的超圖表示。由于超邊緣節點之間有很強的關聯性,分解后的節點不能表示有用的信息,因此DHNE將每個超邊送入自編碼器中,并用這些自編碼器學習節點的嵌入。->二元相似性函數來保持局部和全局的接近性,并優化神經網絡。
簽名異構信息網絡嵌入(Signed Heterogeneous Information Network Embedding,SHINE)用于預測社交網絡中用戶未觀察到的情感。它使用異構圖來表示復雜的用戶關系,并將構造的異構圖分成三個子圖來獲得不同的語義信息。然后,SHINE利用三個自編碼器將三個子圖嵌入到低維向量中,并將三個嵌入聚合為異構圖表示用于鏈接預測。最后,利用解碼器最小化重構誤差對神經網絡進行優化。
Structure and attributes
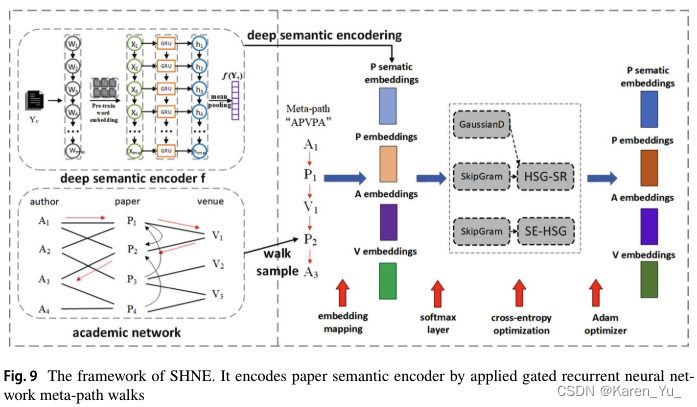
在屬性異構圖中,屬性信息通常附加在節點上。由于每個節點具有不同的屬性特征,使得同一類型的節點可能具有不同的嵌入向量。因此,屬性異構圖嵌入既保留了圖的拓撲信息,又區分了節點上屬性的差異。語義感知異構網絡嵌入(Semantic-aware Heterogeneous Network Embedding,SHNE)如圖9所示。SHNE旨在嵌入節點,聚合文本數據中的結構信息和語義信息。SHNE利用元路徑和GRU提取異構結構和文本屬性信息。它使用異構Skip-Gram模型作為編碼器來學習節點嵌入。
異構網絡嵌入(HNE)是一種以圖像和文本為節點的異構圖嵌入技術。由于每個圖像和文本的內容是排他性的,HNE需要保留每個節點的內容。因此,HNE采用CNN和全連接層來提取圖像和文本特征。它使用兩個變換矩陣作為編碼器,將不同維度的特征作為節點嵌入投影到公共空間中。然后,HNE設計節點相似度函數作為損失函數來優化模型。
為了在不設置元路徑的情況下保持圖的異質性 -> 網絡模式保持異構信息網絡嵌入(Network Schema preserving Heterogeneous information Network Embedding, NSHE),首次嘗試利用網絡模式同時保持兩兩結構和網絡模式結構來嵌入異構圖。NSHE利用GCN學習節點嵌入以保持一階接近。然后,設計了多任務學習,使用多個自編碼器從網絡模式實例中學習節點嵌入,并通過預測任務對學習到的嵌入進行優化。
DIME將用戶嵌入到稀疏的社交網絡中。為了解決新興社交網絡中的稀疏性問題,DIME定義了多個屬性增強元路徑來捕獲用戶之間的各種語義信息。它使用自編碼器學習用戶在每個元路徑上的嵌入,并將所有基于元路徑的嵌入融合在一起以獲得完整的用戶表示。
正則化圖形編碼器(Regularized Graph Auto-Encoders,RGAE)模型將異構圖形轉換為多個視圖,并基于每個視圖學習節點嵌入。RGAE使用多個GCN層作為編碼器來學習每個視圖的嵌入,并將它們聚合在一起作為異構圖嵌入。然后,RGAE通過內部生成操作重建每個視圖的鄰接矩陣,以最小化原始鄰接矩陣與每個視圖的鄰接矩陣之間的差異。
與基于卷積的模型不同,基于自編碼器的模型不使用任何監督信號,它們學習無監督編碼器-解碼器架構中節點的表示,并通過重構誤差來優化模型。這使得基于自編碼器的模型能夠比基于卷積的模型應用于更多的任務和應用場景。
基于對抗
基于對抗的方法主要利用生成式對抗網絡(GAN)通過生成器和鑒別器之間的對抗訓練來學習魯棒節點嵌入。將GAN擴展到異構圖嵌入任務中。現有的基于對抗性的方法利用節點對之間的關系來判斷節點的真假。這意味著基于對抗的方法只維護異構圖中的交互信息,而忽略節點屬性。
異構圖嵌入框架(HeGAN),基于對抗性原理嵌入異構圖。為了適應異構環境,它擴展了鑒別器和生成器與關系感知相關聯。具體來說,對于給定的關系,一個節點是真還是假是由鑒別器決定的,生成器可以生成一個假節點來模擬真節點。
多視圖對抗性完井模型(MV-ACM)。根據多視圖架構,MV-ACM應用對抗學習,通過不同類型的關系捕獲每個節點的互補信息,以獲得完整和魯棒的節點表示。其中,生成器試圖生成互補最多的視圖,以完成每個視圖中每個節點的信息;判別器試圖區分生成的視圖是否與每個視圖中每個節點互補。在生成器和鑒別器之間進行極大極小博弈后,生成器可以學習每個關系的潛在互易性。最后,MV-ACM將學習到的互向性與原始視圖表示融合在一起,得到互補表示。
AGA2Vec使用元路徑捕獲節點之間具有語義信息的高階接近性。它通過融合基于元路徑的鄰居和相應的元路徑重要性來初始化每個節點的嵌入。
AGNE-HIN,利用GAN獲得保持關系的節點嵌入。AGNE-HIN從高斯分布中采樣節點,并整合擾動形成對抗性輸入數據,以提高節點表示的魯棒性。
與上述兩種方法都是判別方法不同,基于對抗的方法屬于深度生成模型,其目的是通過對抗訓練生成節點嵌入。這樣,基于對抗的方法可以通過迭代生成對抗優化獲得更魯棒的表示。
4.2 Dynamic heterogeneous graph learning
動態異構圖會隨著時間的推移而變化,即圖中的實體和相互作用會隨著時間的變化而變化。根據處理時間屬性的策略不同,動態異構圖學習可以大致分為基于獨立學習的模型和基于增量學習的模型兩大類。
基于獨立學習的模型
與HAN類似,DyHAN也利用層次關注來提取復雜的異質性。但是HAN和DyHAN的主要區別在于DyHAN使用了一個額外的注意層來學習動態異構圖隨時間的演化信息。首先,DyHAN提出節點級聚合,通過自關注收集具有相同類型鄰居的鄰居特征。
與DyHAN類似,DyHATR 也使用分層注意來保持圖中的異質性。然而,DyHATR和DyHAN之間的主要區別在于DyHATR使用RNN來發現重要的進化信息。
DyHGCN模型,學習動態異構圖表示,用于信息擴散預測。利用GCN學習每個關系下的節點嵌入,并通過啟發式策略聚合來自不同關系的嵌入,而不是使用DyHAN和DyHATR中的分層關注。
基于獨立學習的模型本質上是利用層次注意來學習動態異構圖表示。與han、HGT等靜態圖的分層注意模型相比,基于自主學習的模型增加了額外的注意機制來捕捉時間演化的信息。但是這種架構會導致高的計算消耗。
基于增量學習的模型
DyHNE是一種基于增量學習的方法,該方法基于矩陣攝動理論,在考慮異構性和進化信息的同時學習節點嵌入。DyHNE通過保留一階和二階元路徑近似來維持異質性。DyHNE利用基于元路徑的鄰接矩陣的擾動,捕捉異構圖的動態變化。
Change2Vec 將Metapath2Vec中使用的異構Skip-Gram擴展到動態異構圖學習。它設計了四個節點演化場景來建模動態變化,并利用Metapath2Vec來學習變化節點的嵌入。
基于增量學習的模型通常通過幾種傳統技術來學習表示,例如矩陣分解或基于隨機游動的淺學習框架。嚴格來說,這種學習方法不涉及HGNN模型。因此,如何將增量學習框架擴展到深度HGNN模型是實現高效學習模式的重要研究問題。
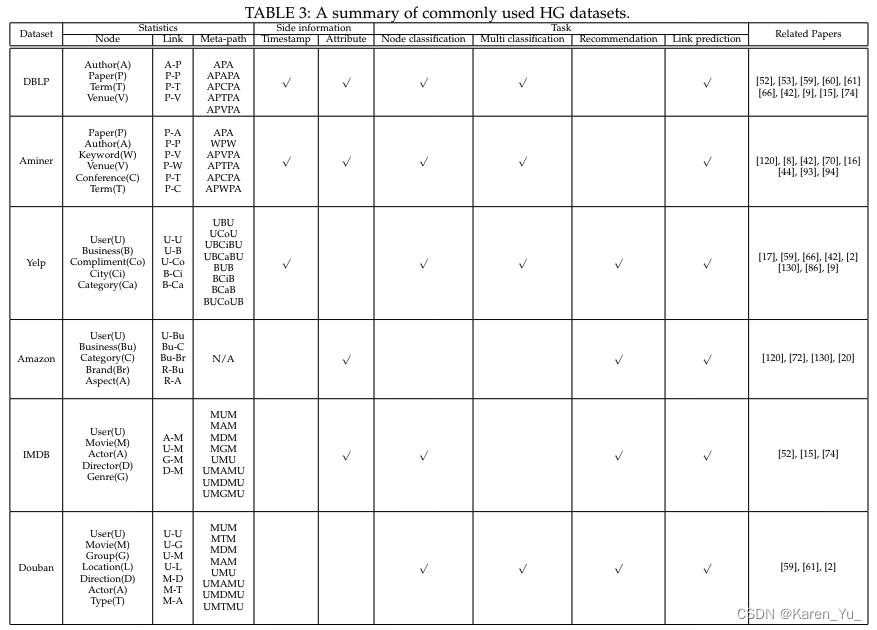
5. Metrics, datasets and evaluations
不同下游任務的評價指標、數據集
(見原文)
6. Applications
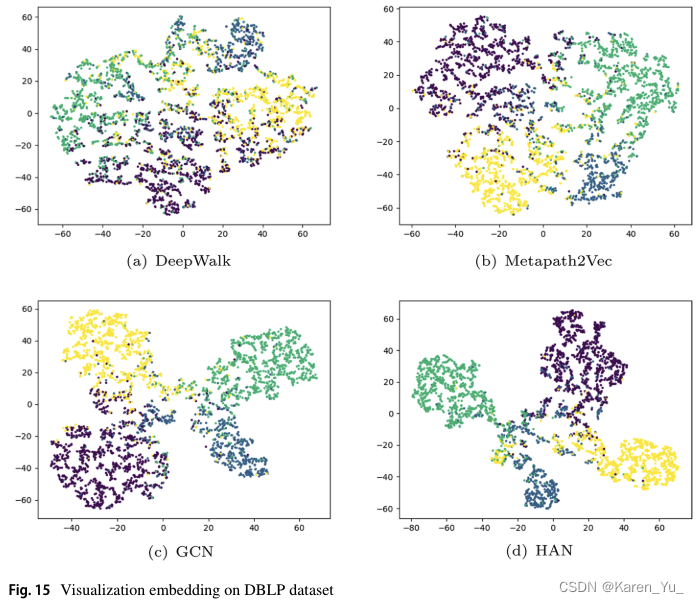
應用
Linkage identifcation and?recommendation
Recommendation and?identifcation on?academic network
E?commerce recommendation and?security
Anomaly detection
A Survey on Heterogeneous Graph Embedding: Methods, Techniques, Applications and Sources
Abstract
異構圖(HGs)也被稱為異構信息網絡,在現實世界中無處不在;因此,HG嵌入,其目的是在低維空間中學習表征,同時為下游任務(例如,節點/圖分類,節點聚類,鏈接預測)保留異構結構和語義,近年來引起了相當大的關注。
1. Introduction
HG是一種功能強大的模型,它能夠在現實世界的數據中包含豐富的語義和結構信息。
傳統上,為了學習HG嵌入,已經提出了矩陣(例如鄰接矩陣)分解方法來生成HG中的潛在維特征。然而,分解大規模矩陣的計算成本通常非常昂貴,并且還存在統計性能缺陷。
異構圖嵌入(即異構圖表示學習),旨在學習映射輸入空間的函數
2. Preliminary
基礎定義
3. Method Taxonomy
內容差不多

、狀態后端選擇和調優等有所了解)







)


)


的DID)



——隨機梯度下降法|文末送書)